Spring Data JPA的作用和用法
Spring Data JPA 是 Spring 框架的一个模块,它提供了一种数据访问抽象,允许以一种声明式和简洁的方式来处理数据库操作。它基于 Java Persistence API (JPA),是一个行业标准的 ORM(对象关系映射)规范,用于将 Java 对象映射到数据库表中。
Spring Data JPA 的作用:
-
简化数据访问层: 通过使用 Spring Data JPA,开发者可以避免编写大量的样板代码,如 SQL 查询和结果集映射。
-
声明式事务管理: 它与 Spring 的声明式事务管理集成,可以轻松地管理事务。
-
强大的查询方法: 它支持声明式查询方法,允许通过方法名定义查询,而不需要编写 SQL 语句。
-
支持多种数据库: 由于它基于 JPA,因此可以与多种数据库兼容。
-
缓存机制: 它提供了一个查询缓存机制,可以提高应用程序的性能。
-
分页和排序: 它支持分页和排序,使得处理大量数据集更加方便。
Spring Data JPA 的用法:
-
添加依赖: 在项目中添加 Spring Data JPA 的依赖。
-
配置数据源: 在
application.properties或application.yml文件中配置数据库连接信息。 -
定义实体: 创建与数据库表对应的 Java 类,使用 JPA 注解来映射类和数据库表之间的关系。
-
创建仓库接口: 扩展
JpaRepository接口来创建自定义的仓库接口。 -
使用查询方法: 通过定义方法名来创建查询,或者使用
@Query注解编写自定义的 JPQL 或 SQL 查询。 -
事务管理: 使用 Spring 的事务管理注解,如
@Transactional,来管理事务。
示例:
假设有一个 User 实体和一个对应的 UserRepository 接口。
// User 实体类
@Entity
public class User {@Idprivate Long id;private String name;// getters and setters
}// UserRepository 接口
public interface UserRepository extends JpaRepository<User, Long> {// 通过方法名定义查询List<User> findByName(String name);// 使用 @Query 注解定义查询@Query("SELECT u FROM User u WHERE u.name = ?1")User findUserByName(String name);
}
在服务层或业务逻辑层,可以这样使用 UserRepository:
@Service
public class UserService {private final UserRepository userRepository;@Autowiredpublic UserService(UserRepository userRepository) {this.userRepository = userRepository;}public List<User> getUsersByName(String name) {return userRepository.findByName(name);}public User getUserByName(String name) {return userRepository.findUserByName(name);}
}
这样,就不需要编写任何 SQL 语句或处理事务,Spring Data JPA 会处理这些。
Spring Data JPA 是一个功能强大的工具,它极大地简化了数据访问层的开发,并且提高了代码的可读性和可维护性。
高级特性:
-
自定义查询方法: 除了使用方法名定义查询,还可以使用
@Query注解来编写自定义的JPQL或SQL查询。 -
继承和多态: Spring Data JPA支持继承,可以处理实体类的继承关系,包括单表继承和多表继承。
-
审计功能: 通过使用
@CreatedDate和@LastModifiedDate注解,可以自动记录实体的创建和修改时间。 -
软删除: 通过
@Version或@LastModifiedDate注解,可以实现乐观锁,防止并发修改。 -
事件发布: Spring Data JPA提供了事件发布机制,可以在实体被保存、更新或删除时触发事件。
-
聚合根: 在复杂事务中,可以使用聚合根来封装多个实体的操作,确保数据的一致性。
最佳实践:
-
避免复杂的查询: 尽量使用Spring Data JPA提供的声明式查询方法,避免编写复杂的JPQL或SQL查询。
-
使用DTO: 当需要从多个表中获取数据时,可以使用数据传输对象(DTO)来封装查询结果,而不是使用复杂的JOIN操作。
-
使用事务管理: 确保正确使用Spring的事务管理注解,如
@Transactional,来管理事务的边界。 -
避免大对象: 避免在实体类中使用大对象或集合,这可能会导致性能问题。
-
使用缓存: 考虑使用Spring Data JPA的缓存机制,如
@Cacheable注解,来提高性能。 -
避免过度使用继承: 虽然Spring Data JPA支持继承,但过度使用继承可能会导致复杂的关系和难以维护的代码。
-
使用分页和排序: 当处理大量数据时,使用分页和排序可以提高性能和用户体验。
-
避免不必要的加载: 使用
@OneToMany或@ManyToMany注解时,避免不必要的级联加载,这可能会导致性能问题。 -
使用异步操作: 对于耗时的数据库操作,可以考虑使用异步方法,如
@Async注解,来提高响应速度。 -
监控和优化: 使用Spring Data JPA的监控和分析工具,如Spring Boot Actuator,来监控应用程序的性能,并根据需要进行优化。
通过遵循这些最佳实践,可以充分利用Spring Data JPA的强大功能,同时保持代码的可读性和可维护性。
示例:
假设有一个复杂的查询需求,需要从多个表中获取数据并进行复杂的处理。可以定义一个DTO来封装查询结果:
public class UserDTO {private String userName;private List<String> roles;// getters and setters
}@Repository
public interface UserRepository extends JpaRepository<User, Long> {@Query("SELECT new com.example.UserDTO(u.name, r.name) FROM User u LEFT JOIN u.roles r WHERE u.id = :userId")UserDTO findUserDTOById(@Param("userId") Long userId);
}
在这个例子中,定义了一个UserDTO类来封装用户名称和角色名称。在UserRepository接口中,使用@Query注解定义了一个自定义查询,它从User表和Role表中获取数据,并返回一个UserDTO对象。
这样,就避免了使用复杂的JOIN操作,同时保持了代码的清晰和可维护性。
总的来说,Spring Data JPA是一个功能强大且灵活的数据访问框架,通过合理的使用和遵循最佳实践,可以大大提高开发效率和应用程序的性能。
相关文章:

Spring Data JPA的作用和用法
Spring Data JPA 是 Spring 框架的一个模块,它提供了一种数据访问抽象,允许以一种声明式和简洁的方式来处理数据库操作。它基于 Java Persistence API (JPA),是一个行业标准的 ORM(对象关系映射)规范,用于将…...
【go项目01_学习记录08】
学习记录 1 模板文件1.1 articlesStoreHandler() 使用模板文件1.2 统一模板 1 模板文件 重构 articlesCreateHandler() 和 articlesStoreHandler() 函数,将 HTML 抽离并放置于独立的模板文件中。 1.1 articlesStoreHandler() 使用模板文件 . . . func articlesSt…...

Java中的线程
一、创建线程的几种方式? ① 通过继承Thread类并重写run方法 ,实现简单但不可以继承其他类 Thread底层也是实现了Runnable接口,重写的是run而不是start方法 ②实现Runnable接口并重写run方法, 避免了单继承的局限性ÿ…...
(完整代码))
顺序表的实现(迈入数据结构的大门)(完整代码)
seqlist.h #pragma once typedef int SLDataType;#include<stdio.h> #include<stdlib.h> #include<assert.h>typedef struct SeqList {SLDataType* a;int size; // 有效数据个数int capacity; // 空间容量 }SL;//初始化和销毁 void SLInit(SL* ps); void SL…...

neo4j-5.11.0安装APOC插件or配置允许使用过程的权限
在已经安装好neo4j和jdk的情况下安装apoc组件,之前使用neo4j-community-4.4.30,可以找到配置apoc-4.4.0.22-all.jar,但是高版本neo4j对应没有apoc-X.X.X-all.jar。解决如下所示: 1.安装好JDK与neo4j 已经安装对应版本的JDK 17.0…...

mybatis 中 #{}和 ${}的区别是什么?
在 MyBatis 中,#{} 和 ${} 是两种用于参数替换的语法,但它们之间存在一些重要的区别,主要体现在安全性、预编译和动态 SQL 上。 安全性: #{}:这是预编译处理,MyBatis 会为传入的参数生成 PreparedStatement…...

深入解析C#中的接口设计原则
深入解析C#中的接口设计原则 目录 深入解析C#中的接口设计原则 一、接口设计的SOLID原则 二、接口设计的最佳实践 三、接口设计的高级技术 四、结论 接口在面向对象编程中扮演着至关重要的角色。它们是定义行为契约的一种方式,允许实现者提供这些行为的具体实现…...

106短信群发平台在金融和法务行业的应用分析
一、金融行业应用 1.客户通知与提醒:银行、证券、保险等金融机构经常需要向客户发送各类通知和提醒,如账户余额变动、交易确认、扣费通知、理财产品到期提醒等。106短信群发平台可以快速、准确地将这些信息发送到客户的手机上,确保客户及时获…...
Spring AOP(2)
目录 Spring AOP详解 PointCut 切面优先级Order 切点表达式 execution表达式 切点表达式示例 annotation 自定义注解MyAspect 切面类 添加自定义注解 Spring AOP详解 PointCut 上面代码存在一个问题, 就是对于excution(* com.example.demo.controller.*.*(..))的大量重…...

Spring-依赖注入的处理过程
前置知识 1 入口 DefaultListableBeanFactory#resolveDependency 2 每个依赖都有对应的DependencyDescriptor 3 自定绑定候选对象处理器AutowireCapableBeanFactory 注入处理 我们可以看到接口AutowireCapableBeanFactory中有两个方法。 第一个是单个注入: Null…...

2.用python爬取的保存在text文件中的格式为MP4的视频url
文章目录 一、url的保存格式二、MP4视频获取 一、url的保存格式 爬取的视频名字和url保存在text文件中,每一个视频都是一个单独的text,其中text的文件名就是视频的名字,text内容是视频的下载url,并且所有的text都保存在同一个文件…...
Java基于B/S医院绩效考核管理平台系统源码java+springboot+MySQL医院智慧绩效管理系统源码
Java基于B/S医院绩效考核管理平台系统源码javaspringbootMySQL医院智慧绩效管理系统源码 医院绩效考核系统是一个关键的管理工具,旨在评估和优化医院内部各部门、科室和员工的绩效。一个有效的绩效考核系统不仅能帮助医院实现其战略目标,还能提升医疗服…...
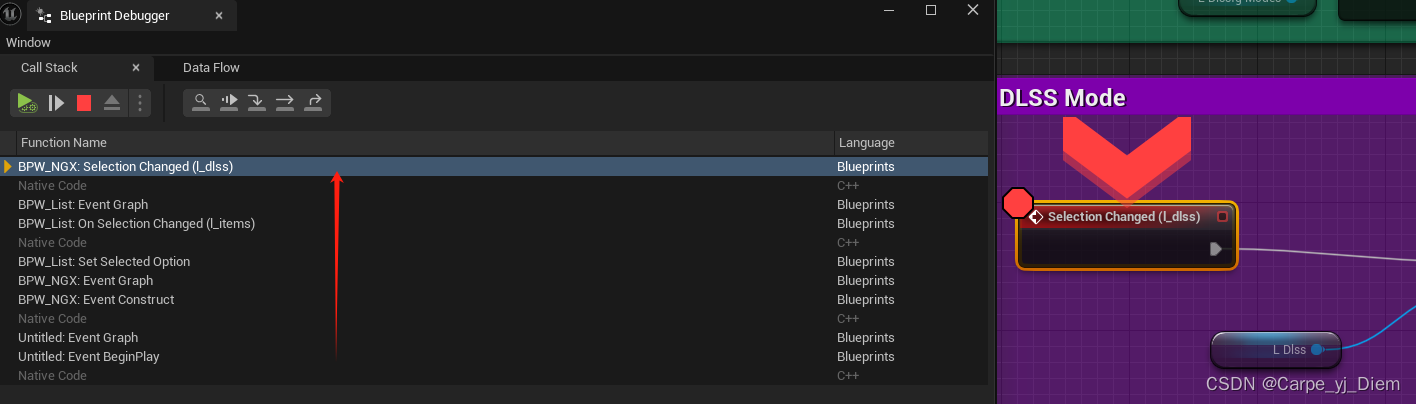
UE 蓝图堆栈调试
蓝图打断点后如果想查看断点前的执行逻辑,Tools→Debug→BlueprintDebugger 然后打断点运行,执行顺序是从下往上...

UE4_摄像机_使用摄像机的技巧
学习笔记,不喜勿喷!祝愿生活越来越好! 知识点: a.相机跟随。 b.相机抖动。 c.摄像机移动 d.四元数插值(保证正确旋转方向)。 e.相机注视跟踪。 1、新建关卡序列,并给小车添加动画。 2、创…...
ssm115乐购游戏商城系统+vue
毕业生学历证明系统 设计与实现 内容摘要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统毕业生学历信息管理难…...
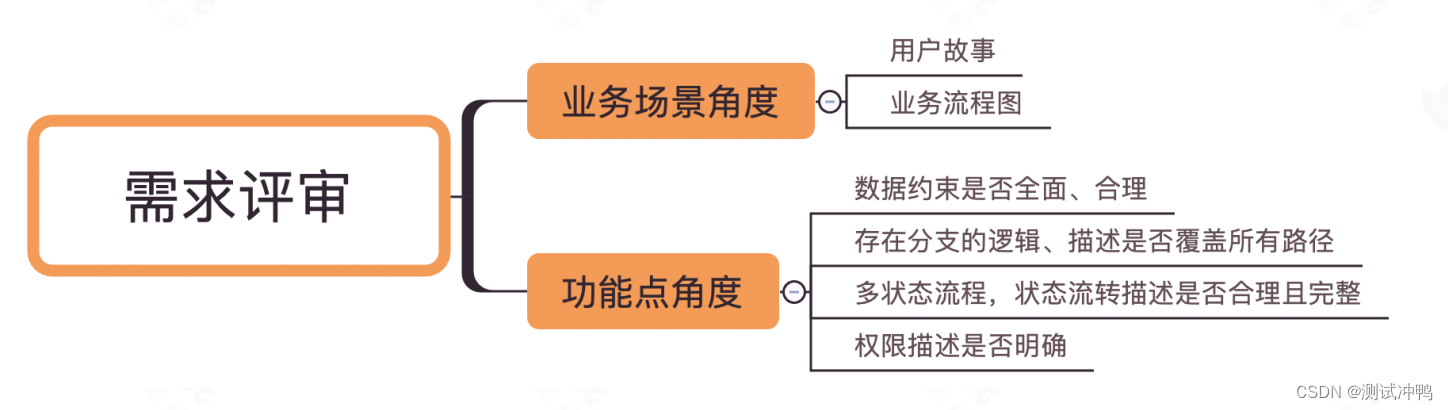
【可实战】被测需求理解(需求文档是啥样的、从哪些角度进行需求评审、需求分析需要分析出哪些内容、如何提高需求分析能力)
产品人员会产出一个需求文档,然后组织一个需求的宣讲。测试人员的任务就是在需求宣讲当中,分析需求有没有存在一些问题,然后在需求宣讲结束之后通过分析需求文档,分析里面的测试点并预估一个排期。 一、需求文档是什么样的&#x…...

伪类和伪元素的区别是什么?
一、两者的定义 1.伪类(pseudo-class)是一个以冒号作为前缀,被添加到一个选择器末尾的关键字,当你希望样式在特定状态才被呈现到指定的元素时,你可以往元素的选择器后面加上对应的伪类。 2.伪元素用于创建一些不在文档…...
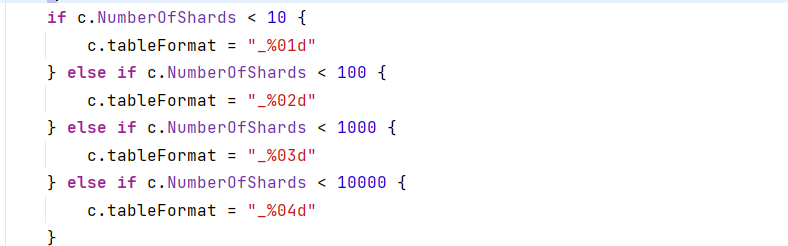
gorm-sharding分表插件升级版
代码地址: GitHub - 137/gorm-sharding: Sharding 是一个高性能的 Gorm 分表中间件。它基于 Conn 层做 SQL 拦截、AST 解析、分表路由、自增主键填充,带来的额外开销极小。对开发者友好、透明,使用上与普通 SQL、Gorm 查询无差别.解决了原生s…...

MoviePy(Python音视频开发)
音视频基础帧率、码率、分辨率视频格式H.264和H.265视频压缩算法 Moviepy常见剪辑类VideoFlieClipImageFlieClipColorClipTextClipCompositeVideoClipAudioFlieClipCompositeAudioClip 常见操作音视频的读入与导出截取音视频 音视频基础 帧率、码率、分辨率 体积(V…...

Spring中的FileCopyUtils:文件复制的利器与详解
1. 概述 在Spring框架中,FileCopyUtils是一个用于文件复制操作的实用工具类。它提供了一系列静态方法,简化了文件从输入流到输出流、从文件到文件等的复制过程。这些方法都基于NIO(New I/O)技术,提供了高效的文件复制…...

如何评估拓客数据的有效性?避开无效内耗,精准提效
当下企业拓客越来越注重精细化,不少团队投入大量精力收集数据,却陷入“数据越多,效果越差”的困境——空号、无效线索、非目标客群占据大半,不仅浪费人力成本,更拖慢增长节奏。其实,拓客的核心不在于“量”…...

Python模板引擎批量生成文章:Jinja2与Pandas实战指南
1. 项目概述:一个能帮你批量生成文章的自动化工具 如果你也经常需要处理大量内容创作任务,比如运营多个自媒体账号、管理企业博客矩阵,或者为产品生成海量描述性文案,那你一定对“重复劳动”这个词深恶痛绝。手动一篇篇地写&#…...

Stardew Valley Mod开发:使用OpenClaw主题框架快速构建原生风格UI
1. 项目概述:一个为Stardew Valley Mod开发者量身打造的主题框架如果你是一位《星露谷物语》(Stardew Valley)的模组(Mod)开发者,或者正打算踏入这个充满创造力的社区,那么你很可能已经体会过&a…...

3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器
3分钟搞定!FigmaCN终极中文插件:让英文界面秒变中文的免费神器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?专业术…...

AWE Designer生成的awb文件到底是什么?一份给嵌入式音频开发者的二进制文件解析与烧录避坑指南
AWB文件深度解析:嵌入式音频开发者的二进制文件操作指南 在嵌入式音频开发领域,AWE Designer工具链生成的AWB文件常常让开发者感到神秘又困惑。这个看似普通的二进制文件,实际上承载着音频算法实现的核心逻辑。许多开发者在烧录AWB文件到Flas…...

Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线
Task人工智能:如何用Go语言工具构建高效的ML模型训练流水线 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task 在当今的机器学习开发中&#x…...

MISC实战:从受损pcap到关键数据提取的全链路取证分析
1. 受损pcap文件修复实战指南 遇到打不开的流量包文件就像拿到一张破损的地图,明明知道宝藏就在里面却无从下手。我处理过上百个损坏的pcap文件,最常见的报错是"Not a pcap/pcapng file"或"File has invalid header"。这时候别急着…...

TegraRcmGUI完整指南:Windows上最简单快速的Switch注入工具教程
TegraRcmGUI完整指南:Windows上最简单快速的Switch注入工具教程 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是Windows平台上最简…...

Boss-Key:办公隐私保护神器,一键隐藏敏感窗口的智能解决方案
Boss-Key:办公隐私保护神器,一键隐藏敏感窗口的智能解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在当今…...

告别网盘下载烦恼:3步解锁9大网盘高效下载新体验
告别网盘下载烦恼:3步解锁9大网盘高效下载新体验 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...