salmon使用体验
文章目录
- salmon转录本定量
- brief
- 模式一:fastq作为输入文件
- 需要特别注意得地方
- 模式二: bam文件作为输入
salmon转录本定量
brief
第一点是,通常说的转录组分析其中有一项是转录本定量,这是一个很trick的说话,说成定量/quantify要适合一些。
因为我们可以根据 reads summary的方式分为两种定量,一种是 transcript-level quantify,一种是 gene-level quantify。
第二点 transcript-level quantify根据比对方式又可以细分:
Transcript quantification 大致分为两类:
- Alignment-based transcript quantification
这里的比对也要作出区分,一种是和基因组比对(aligns reads to the reference genome),一种是和转录组比对(aligns reads to the reference transcriptome)。
和基因组比对后,可以利用Cufflinks or StringTie 等tools,不仅可以测算已知转录本丰度还可以发现新的转录本
和转录组比对后,可以利用RSEM or eXpress or Salmon-Aln 等tools进行转录本丰度的测算 - Alignment-free transcript quantification
就是直接 assign reads directly to transcripts,比如ailfish, Salmon-SMEM,quasi-mapping, and kallisto 这些工具可以实现。
conda activate NGS
conda config --add channels biocondaconda search salmon
conda install salmonsalmon --help
salmon v0.14.1
Usage: salmon -h|–help or
salmon -v|–version or
salmon -c|–cite or
salmon [–no-version-check] [-h | options]Commands:
index Create a salmon index
quant Quantify a sample
alevin single cell analysis
swim Perform super-secret operation
quantmerge Merge multiple quantifications into a single file
模式一:fastq作为输入文件
# step 1
# make salmon map index
# The index is a structure that salmon uses to quasi-map RNA-seq reads during quantification.
wget https://ftp.ensembl.org/pub/release-111/fasta/macaca_mulatta/cdna/Macaca_mulatta.Mmul_10.cdna.all.fa.gz# 软件作者希望制作 decoy awere transcriptome,我没管,直接运行下下面的口令
salmon index -t ./Macaca_fascicularis.Macaca_fascicularis_6.0.cdna.all.fa.gz -i ./Macaca_fascicularis.Macaca_fascicularis_6.0.cdna.all.salmon.indexls Macaca_fascicularis.Macaca_fascicularis_6.0.cdna.all.salmon.index/
# duplicate_clusters.tsv hash.bin header.json indexing.log quasi_index.log refInfo.json rsd.bin sa.bin txpInfo.bin versionInfo.json
# make index done # step 2
# rawdata QC
datadir="/public/Project_datasets/HY0007/Macaca_fascicularis_RNA-seq/PM-XS05KF2023080038-05四川大学6个食蟹猴普通真核有参转录组建库测序分析任务单/ANNO_XS05KF2023080038_PM-XS05KF2023080038-05_2023-11-02_16-01-18_22C2TNLT3/Rawdata"
mkdir 20240426-NGS-6samples
cd 20240426-NGS-6samples/mkdir qc
ls ${datadir}/ |while read id ;do echo ${datadir}/${id}/${id}_R1.fq.gz;done > qc.txt
ls ${datadir}/ |while read id ;do echo ${datadir}/${id}/${id}_R2.fq.gz;done >> qc.txtcat qc.txt |while read id ;do (fastqc -o ./qc $id &);done
multiqc ./qc -o ./multiqc# trim-adaptor
###
cat qc.txt |grep "R1" >1.txt
cat qc.txt |grep "R2" >2.txt
paste 1.txt 2.txt > trim.txt
cat trim.txt |while read id;do a=($id) && echo /public/home/djs/software/TrimGalore-master/trim_galore -q 25 --phred33 --stringency 3 -o ./Clean_data --paired ${a[0]} ${a[1]}; done > parafly.txt# conda install -c bioconda parafly
nohup ParaFly -c parafly.txt -CPU 15 >>out.log 2>>err.log &###
cd Clean_data
mkdir {Fastqc,Multiqc}ls |grep "val.*fq" |while read id ;do (fastqc -o ./Fastqc ./$id &);done
multiqc ./Fastqc -o ./Multiqc# step3 map to reference
index="/public/home/djs/reference/macaca_fascicularis/Macaca_fascicularis.Macaca_fascicularis_6.0.cdna.all.salmon.index/"
# 双端测序
cd /public/home/djs/huiyu/project/HY0007/20240426-NGS-6samples/Clean_datals *val*gz|cut -d"_" -f 1|sort -u |while read id;do
echo salmon quant -i $index -l ISF --gcBias \-1 ${id}_R1_val_1.fq.gz -2 ${id}_R2_val_2.fq.gz -p 2 \-o ../salmon_output/${id}_output
done > paired_salmon.shnohup ParaFly -c paired_salmon.sh -CPU 12 >>out.log 2>>err.log &# quantify result
ls
# aux_info cmd_info.json lib_format_counts.json libParams logs quant.sf
head quant.sf
# ENSMFAT00000064841.2 354 110.000 37.761624 31.000
# ENSMFAT00000064566.2 372 126.000 107.406974 101.000
# ENSMFAT00000061855.2 336 96.000 108.422787 77.680
# ENSMFAT00000061921.2 336 96.000 67.838005 48.603
# ENSMFAT00000061935.2 336 96.000 185.240776 132.717
# ENSMFAT00000097936.1 252 45.460 20.632500 7.000
# ENSMFAT00000064576.2 348 107.929 130.356210 105.000
# ENSMFAT00000064726.2 339 98.000 60.160059 44.000
# ENSMFAT00000064735.2 267 52.000 10.307143 4.000## 进入R工作
# 进入R做一下 FPKM得转换countToTpm <- function(counts, effLen)
countToTpm <- function(counts, effLen){rate <- log(counts) - log(effLen)denom <- log(sum(exp(rate)))exp(rate - denom + log(1e6))
}countToFpkm <- function(counts, effLen){N <- sum(counts)exp( log(counts) + log(1e9) - log(effLen) - log(N) )
}fpkmToTpm <- function(fpkm){exp(log(fpkm) - log(sum(fpkm)) + log(1e6))
}df <- read.table("quant.sf",header=T)
# 过滤低表达基因
df <- df[df$NumReads >=10,]
# normalization
df$fpkm <- countToFpkm(df$NumReads,df$EffectiveLength)
df$tpm <- countToTpm(df$NumReads,df$EffectiveLength)
write.csv(df,file="quant_filter_transform.csv",row.names=F)files <- list.files()
dlist <- lapply(files,function(file){read.table(paste("./",file,"/quant_filter_transform.csv",sep=""),header=T,sep=",")})
需要特别注意得地方
- 参数 —libType A 的设置,一般情况是 --libType ISF 或者 --libType A 让软件自己推测。
模式二: bam文件作为输入
这个bam文件是fastq文件与参考转录组比对的结果,注意不是与参考基因组的比对结果。
然后 transcripts.fa 是参考转录组文件(这种模式下,可以不用建议参考转录组的index)。
> ./bin/salmon quant -t transcripts.fa -l <LIBTYPE> -a aln.bam -o salmon_quant
# quantify result
ls
# aux_info cmd_info.json lib_format_counts.json libParams logs quant.sf
head quant.sf
# ENSMFAT00000064841.2 354 110.000 37.761624 31.000
# ENSMFAT00000064566.2 372 126.000 107.406974 101.000
# ENSMFAT00000061855.2 336 96.000 108.422787 77.680
# ENSMFAT00000061921.2 336 96.000 67.838005 48.603
# ENSMFAT00000061935.2 336 96.000 185.240776 132.717
# ENSMFAT00000097936.1 252 45.460 20.632500 7.000
# ENSMFAT00000064576.2 348 107.929 130.356210 105.000
# ENSMFAT00000064726.2 339 98.000 60.160059 44.000
# ENSMFAT00000064735.2 267 52.000 10.307143 4.000
相关文章:
salmon使用体验
文章目录 salmon转录本定量brief模式一:fastq作为输入文件需要特别注意得地方 模式二: bam文件作为输入 salmon转录本定量 brief 第一点是,通常说的转录组分析其中有一项是转录本定量,这是一个很trick的说话,说成定量…...

Ubuntu 20.04 安装 Ansible
使用官方的 Ubuntu PPA 更新包列表: apt update安装软件属性常用命令 apt install software-properties-common添加 Ansible PPA 到系统: add-apt-repository --yes --update ppa:ansible/ansible再次更新包列表以包括新添加的 PPA: apt …...

TypeScript学习笔记:强类型JavaScript的优雅之旅
在前端开发领域,JavaScript以其灵活性和广泛的支持度成为无可争议的王者。然而,随着项目规模的增长,JavaScript的动态类型特性开始暴露出一些问题,比如代码的可维护性、类型错误难以提前发现等。为了解决这些问题,Micr…...
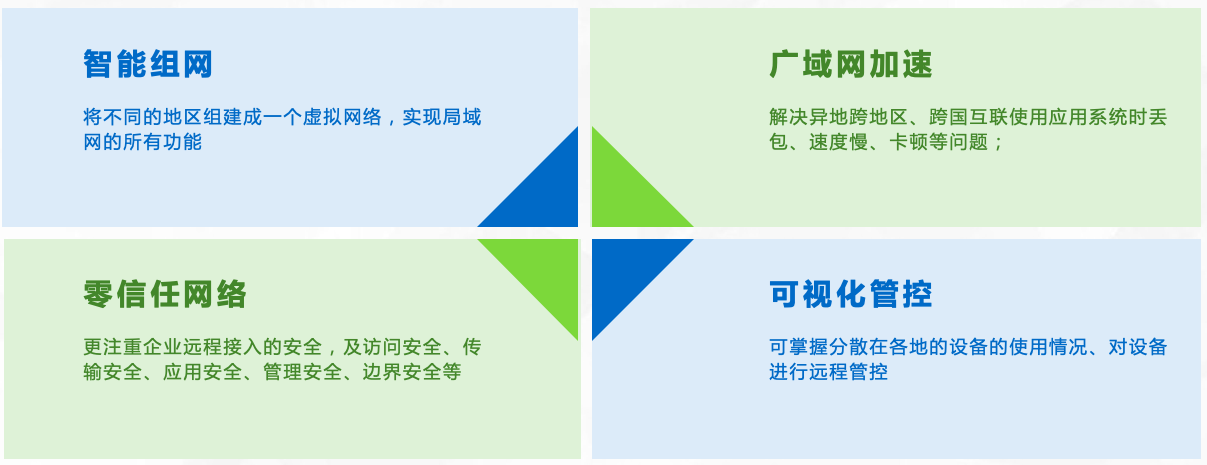
监控异地组网怎么组网?
监控异地组网是指在不同地域的网络环境下,实现对监控设备的远程访问和管理。在传统的网络环境下,由于网络限制和设备配置等问题,监控设备的远程访问往往受到一定的限制和困扰。为了解决这个问题,引入了天联组网技术,实…...
将本地托管模型与 Elastic AI Assistant 结合使用的好处
作者:来自 Elastic James Spiteri, Dhrumil Patel 当今公共部门组织利用生成式人工智能解决安全挑战的一种方式。 凭借其筛选大量数据以发现异常模式的能力,生成式人工智能现在在帮助团队保护其组织免受网络威胁方面发挥着关键作用。 它还可以帮助安全专…...

Linux的内核态和用户态
一、Linux操作系统运行在两种不同的运行模式下:内核态(Kernel Mode)和用户态(User Mode) 内核态(Kernel Mode): 内核态也称为特权模式或系统模式,是操作系统内核执行代码…...

springboot利用Redis的Geo数据类型,获取附近店铺的坐标位置和距离列表
文章目录 GEO介绍GEO命令行应用添加地理坐标位置获取指定单位半径的全部地理位置列表springboot 的实际应用 GEO介绍 在Redis 3.2版本中,新增了一种数据类型:GEO,它主要用于存储地理位置信息,并对存储的信息进行操作。 GEO实际上…...

Vitis HLS 学习笔记--理解串流Stream(2)
目录 1. 简介 2. 极简的对比 3. 硬件模块的多次触发 4. 进一步探讨 do-while 5. 总结 1. 简介 在这篇博文中《Vitis HLS 学习笔记--AXI_STREAM_TO_MASTER-CSDN博客》,我分享了关于 AXI Stream 接口的实际应用案例。然而,尽管文章中提供了代码示例&…...

Golang | Leetcode Golang题解之第80题删除有序数组中的重复项II
题目: 题解: func removeDuplicates(nums []int) int {n : len(nums)if n < 2 {return n}slow, fast : 2, 2for fast < n {if nums[slow-2] ! nums[fast] {nums[slow] nums[fast]slow}fast}return slow }...

uniapp自定义websocket类实现socket通信、心跳检测、连接检测、重连机制
uniapp自定义websocket类实现socket通信、心跳检测、检测连接、重连机制,仿vue-socket插件功能实现发送序列号进行连接检测,发送消息时42【key,value】格式,根据后端返回数据和需要接收到的数据做nsend与onSocketMessage的修改 //使用socket…...
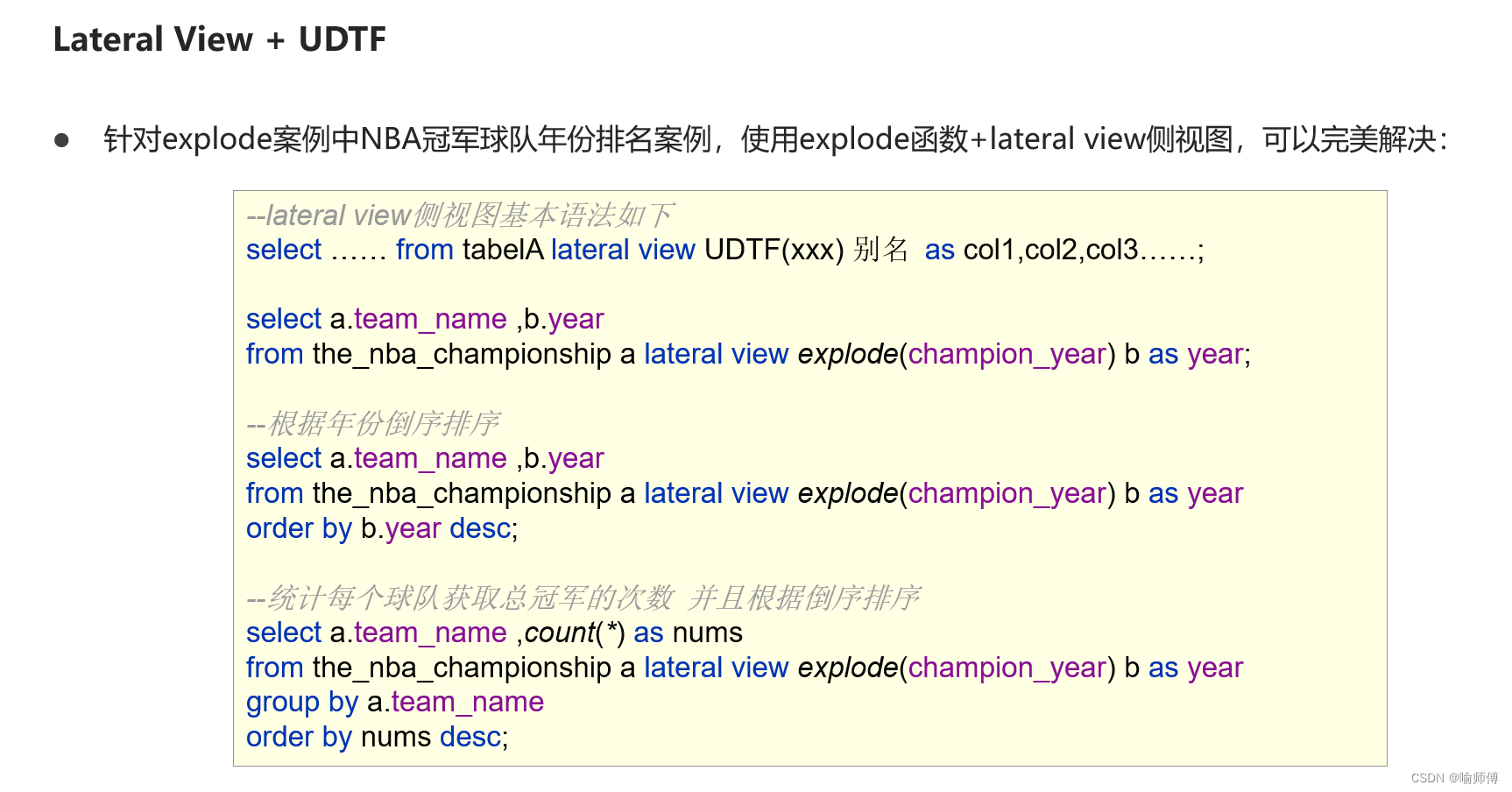
Hive UDTF之explode函数、Lateral View侧视图
Hive UDTF之explode函数 Hive 中的 explode() 函数是一种用于处理数组类型数据的 User-Defined Table-Generating Function (UDTF)。它将数组拆分成多行,每个数组元素对应生成的一行数据。这在处理嵌套数据结构时非常有用,例如处理 JSON 格式的数据。 …...

智慧公厕打造智慧城市新标杆
公共厕所作为城市基础设施的重要组成部分,直接关系到市民的生活品质和城市形象。传统的公厕管理方式存在着许多问题,如环境脏乱、清洁不及时等,给市民带来了诸多不便和不满。而智慧公厕作为一种全新的管理模式,通过物联网、大数据…...

字节发布文生图模型PuLID:高效身份ID特征定制,单张图像克隆AI虚拟分身
前言 字节研究团队近日提出了一种新型的文生图身份ID定制方法PuLID(Pure and Lightning ID Customization)。相较于传统的微调方法,PuLID无需复杂的参数优化就可以实现高效的身份ID定制,且能最大程度减少对原始模型行为的干扰。 PuLID是通过将轻量级的…...
SpringBoot启动流程分析之创建SpringApplication对象(一)
SpringBoot启动流程分析之创建SpringApplication对象(一) 目录: 文章目录 SpringBoot启动流程分析之创建SpringApplication对象(一)1、SpringApplication的构造方法1.1、推断应用程序类型1.2、设置Initializers1.3、设置Listener1.4、推断main方法所在类 流程分析…...

SSH简介 特点以及作用
引言 SSH(Secure Shell)是一种用于安全远程访问和数据传输的网络协议。它提供了一种安全的机制,使得用户可以在不安全的网络中安全地进行远程登录、命令执行和文件传输。SSH通过加密技术和认证机制来保护数据的安全性,防止数据在…...
MQTT服务搭建及python使用示例
1、MQTT协议 1.1、MQTT介绍 MQTT(Message Queuing Telemetry Transport)是一种轻量级的、基于发布/订阅模式的通信协议,通常用于物联网设备之间的通讯。它具有低带宽、低功耗和开放性等特点,适合在网络带宽有限或者网络连接不稳定…...

Ubuntu如何设置中文输入法
概述 Ubuntu 是一个基于 Debian 构建的开源操作系统,拥有广泛的用户群体和强大的社区支持。是免费、开源的操作系统。被设计为一个适用于个人电脑、服务器和云平台的通用操作系统。Ubuntu的目标是提供一个稳定、易于使用和免费的操作系统,以促进人们在计…...

PostgreSQL的pg_dump和 pg_dumpall 异同点
PostgreSQL的pg_dump和 pg_dumpall 异同点 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777pg_dump 和 pg_dum…...
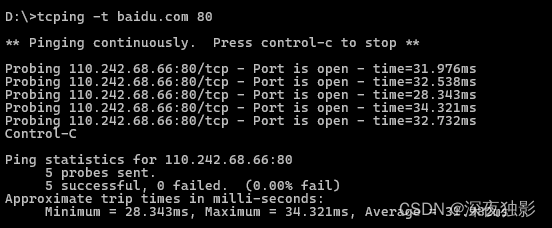
【Ping】Windows 网络延迟测试 ping 、telnet、tcping 工具
ping 命令 属于网络层的ICMP协议,只能检查 IP 的连通性或网络连接速度, 无法检测IP的端口状态。 telnet telnet命令,属于应用层的协议,用于远程登录,也可用于检测IP的端口状态。但是功能有限,只能检测一时…...

DuDuTalk:4G桌面拾音设备在银行网点服务场景的应用价值
随着科技的飞速发展,银行业也在不断地寻求创新以提高服务质量和效率。在这个过程中,4G桌面拾音设备作为一种新型的智能设备,其在银行网点服务场景中的应用价值逐渐凸显出来。本文将从多个角度探讨4G桌面拾音设备在银行网点服务场景的应用价值…...

SAP ECC老司机避坑指南:FAGLGVTR和F.07年结操作,这5个细节不注意就白干了
SAP ECC年结实战:FAGLGVTR与F.07操作中的5个致命陷阱 每到年末,财务部门的紧张气氛总是格外浓厚。对于使用SAP ECC系统的企业来说,年结操作就像一场没有彩排的现场演出——任何一个小失误都可能导致数据混乱、报表错误,甚至影响整…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...

别再“另存为”了!职场人90%的无效内耗都源于这一个操作。企业文档如何管理?
加班到晚上八点,职场人小林终于改完了项目方案,随手点了“另存为”,命名为“方案_最终版.doc“后发到了工作群。本以为可以安心下班,群里却炸锅了:“小林,你这个最终版和我手里的不一样啊?”“我…...

手把手教你用YOLOv5训练VisDrone2019数据集:搞定无人机航拍小目标检测
无人机视角下的目标检测实战:YOLOv5与VisDrone2019数据集深度适配指南 无人机航拍图像的目标检测一直是计算机视觉领域的难点与热点。VisDrone2019作为当前最权威的无人机视角数据集之一,包含了丰富的场景变化和极具挑战性的小目标检测任务。本文将带您从…...

基于树莓派与AstroPrint搭建无线3D打印控制中心实战指南
1. 项目概述:为什么需要无线3D打印控制?如果你和我一样,是个喜欢折腾3D打印机的创客或爱好者,那你肯定经历过这样的场景:为了打印一个模型,需要先在电脑上用切片软件生成G-code文件,然后找到读卡…...

3D设计工作流的终极桥梁:如何用stltostp高效解决STL到STEP格式转换难题
3D设计工作流的终极桥梁:如何用stltostp高效解决STL到STEP格式转换难题 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 当你在3D打印与CAD设计之间切换时,是否经常遇到这…...

怎样免费去掉图片水印?2026年免费去水印工具推荐|在线vs软件对比
在日常工作和生活中,我们经常会遇到带有水印的图片。无论是来自社交媒体平台、在线图库还是其他来源,这些水印往往影响图片的使用效果。2026年,市面上出现了多种免费去水印工具,它们采用不同的技术方案,适用于不同的使…...

避坑指南:香橙派串口开发中orangepiEnv.txt与armbianEnv.txt的配置差异详解
香橙派串口开发实战:系统配置差异与深度调试指南 当你在深夜调试香橙派串口时,突然发现修改的配置文件毫无反应——这种经历相信不少开发者都遇到过。问题的根源往往不在于代码本身,而是隐藏在系统环境中的配置差异。本文将带你深入剖析香橙派…...

如何利用Dask集成ydata-profiling实现大规模数据处理:2024终极指南
如何利用Dask集成ydata-profiling实现大规模数据处理:2024终极指南 【免费下载链接】fg-data-profiling 1 Line of code data quality profiling & exploratory data analysis for Pandas and Spark DataFrames. 项目地址: https://gitcode.com/gh_mirrors/y…...

如何快速定制ydata-profiling报告模板:CSS样式修改完全指南
如何快速定制ydata-profiling报告模板:CSS样式修改完全指南 【免费下载链接】fg-data-profiling 1 Line of code data quality profiling & exploratory data analysis for Pandas and Spark DataFrames. 项目地址: https://gitcode.com/gh_mirrors/yd/fg-da…...