Linux磁盘IO、网络IO、零拷贝详解
一、什么是I/O?
在计算机操作系统中,所谓的I/O就是输入(input)和输出(output),也可以理解为读(read)和写(write),针对不同的对象,I/O模式可以划分为磁盘IO模型和网络IO模型
二、IO操作本质是用户空间和内核空间的转换,规则如下:
- 内存空间分为用户空间和内核空间,也称为用户缓冲区和内核缓冲区
- 用户的应用程序不能直接操作内核空间,需要将数据从内核空间拷贝到用户空间才能使用
- 无论是read操作,还是write操作,都只能在内核空间里执行
- 磁盘IO操作、网络请求加载到内存的数据一开始都是先放到内核缓冲区的
三、IO调用步骤之读(read)操作和写(write)

注:绿色的图型表示数据存储的位置,绿色的箭头则表示数据的复制
图1解析:
1、从左到右:Linux IO包含两部分,磁盘IO(Disk I/O)和网络IO(Network I/O)
2、从上到下:存储又被划分为三部分:用户空间(User space)、内核空间(Kerner space)及物理设备(Physical devices)
从上到下,为什么划分为三层?
Linux操作系统为了安全考虑,其内核管理了几乎所有的硬件设备,不允许用户进程直接访问。因此,逻辑上计算机被分为用户空间和内核空间(外设及其驱动是被划分在内核空间的)
运行在用户空间的进程就是用户态,运行在内核空间的进程就是内核态。用户态的进程,访问不了内核空间的数据,所以就需要由内核态的进程把数据拷贝到用户态。
3、缓存I/O(Buffered I/O)
3.1、磁盘IO(Disk I/O):
读操作:当应用程序调用read()方法时,操作系统检查内核缓冲区是否存在需要的数据,如果存在,那么就直接把内核空间的数据copy到用户空间,供用户的应用程序使用;如果内核缓冲区没有需要的数据,则通过DMA方式从磁盘中读取数据到内核缓冲区(DMA Copy),然后把内核空间的数据copy到用户空间(Cpu Copy)(上图绿色实线部分)
写操作:当应用程序调用write()方法时,应用程序将数据从用户空间copy到内核空间的缓冲区(如果用户空间没有相应的数据,则需要从磁盘-->内核缓冲区-->用户缓冲区依次读取),这时对用户程序来说写操作就已经完成,至于什么时候把数据再写到磁盘,由操作系统决定。操作系统将要写入磁盘的数据先保存于系统为写缓存分配的内存空间中,当保存到内存池中的数据达到一个程度时,便将数据保存在硬盘中。这样可以减少实际的磁盘操作,有效的保护磁盘免于重复的读写操作而导致的损坏,也能减少写入所需的时间。除非应用程序显式的调用了sync命令,立即把数据写入磁盘。如果应用程序没准备好写的数据,则必须先从磁盘读取数据才能执行写操作,这时会涉及到四次缓冲区的copy:
a、第一次从磁盘的缓冲区读取数据到内核缓冲区(DMA Copy);
b、第二次从内核缓冲区复制到用户缓冲区(Cpu Copy);
c、第三次从用户缓冲区写到内核缓冲区(Cpu Copy);
d、第四次从内核缓冲区写到磁盘(DMA Copy);(上图绿色实线部分双向箭头)
磁盘IO延时:
- 寻道时间:把磁头移动到指定磁道上所经历的时间
- 旋转延时间:指定扇区移动到磁头下面所经历的时间
- 传输时间:数据的传输时间(数据读出或写入的时间)
Page cache 和Buffer cache:
Page cache也叫页缓冲或文件缓冲。是由好几个磁盘块构成,大小通常是4K,在64位系统上为8K。构成的几个磁盘块在物理磁盘上不一定连续,文件的组织单位为一页,也就是一个Page cache大小。Page cache是建立在文件系统(Ex4)之上的,因此其缓存的是逻辑数据。Buffer cache是建立在块层之上的,因此其缓存的是物理辑数据。Linux大约在2.4.10之后,Page cache与Buffer cache合并了
(所以图中Buffer cache是灰色的,为了更容易理解IO原理,黄色和灰色部分都可以不考虑了)
DMA(直接内存访问)方式:
DMA是一种与CPU共享内存总线的设备,它可以代替CPU,把数据从内存到设备之间进行拷贝。仅在传送一个或多个数据块的开始和结束时,才需CPU干预(发送DMA中断),整块数据的传送是在DMA的控制器的控制下完成的。
3.2、网络I/O(Network I/O)
读操作:网络IO即可以从物理磁盘中读数据,也可以从socket中读数据(从网卡中获取)。当从物理磁盘中读数据的时候,其流程和磁盘IO的读操作一样。当从socket中读数据,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直接客户端发送了数据,该应用程序才会被唤醒,从Socket协议栈(即网卡)中读取客户端发送的数据到内核空间(DMA copy),然后把内核空间的数据copy到用户空间
写操作:为了简化描述,我们假设网络IO的数据从磁盘中获取,读写操作流程如下:
- 当应用程序调用read()方法时,通过DMA方式将数据从磁盘拷贝到内核缓冲区(DMA copy);
- 由cpu控制,将内核缓冲区的数据拷贝到用户空间的缓冲区中,供应用程序使用(CPU copy);
- 当应用程序调用write()方法时,cpu会把用户缓冲区的数据copy到内核缓冲区的Socket Buffer中(CPU copy);
- 最后通过DMA方式将内核空间中的Socket Buffer拷贝到Socket协议栈(即网卡设备)中传输(DMA copy);
网络IO的延时:网络IO主要延时是由服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时 决定。一般为几十到几千毫秒,受环境影响较大。所以一般来说,网络IO延时要大于磁盘IO延时

缓存I/O的一致性和安全性:如果出现进程死,内核死,掉电这样事件发生。数据会丢失吗?
- 进程死:如果数据还处在application cache或clib cache的时候,数据会丢失;
- 内核死:即使进入了page cache(完成了write),如果没有进行sync操作,数据还是会丢失;
- 掉电:进行了sync,数据就一定写入了磁盘了吗?答案是:不一定;
- 注意到图1中,磁盘旁边的绿色图型了吗?它表示的是磁盘上的缓存。写数据达到一个程度时才真正写入磁盘
缓存I/O的缺点:在缓存I/O机制中,DMA方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输。这样的话,数据 在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。对于某些特殊的应用程序来说,避开操作系统内核缓冲区,而直接在应用程序地址空间和磁盘之间传输数据,会比使用操作系统内核缓冲区获取更好的性能,因此引入"Direct I/O"。
4、直接I/O(Direct I/O)
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持。
进程在打开文件的时候设置对文件的访问模式为 O_DIRECT ,这样就等于告诉操作系统进程在接下来使用 read() 或者 write() 系统调用去读写文件的时候使用的是直接 I/O 方式,所传输的数据均不经过操作系统内核缓存空间。
直接I/O优点:减少操作系统缓冲区和用户地址空间的拷贝次数。降低CPU开销和内存带宽 。对于某些应用程序来说简单是福音,将会大大提高性能。
直接I/O缺点:直接 I/O 并不总能让人如意。直接 I/O 的开销也很大,应用程序没有控制好读写,将会导致磁盘读写的效率低下。磁盘的读写是通过磁头的切换到不同的磁道上读取和写入数据,如果需要写入数据在磁盘位置相隔比较远,就会导致寻道的时间大大增加,写入读取的效率大大降低。
Direct I/O 本质是 DMA 设备把数据从用户空间拷贝到设备,或是从设备拷贝到用户空间。
5、mmap
mmap 本质是内存共享机制,它把 page cache 地址空间映射到用户空间,换句话说,mmap 是一种特殊的 Buffered I/O

offset 是文件中映射的起始位置,length 是映射的长度。
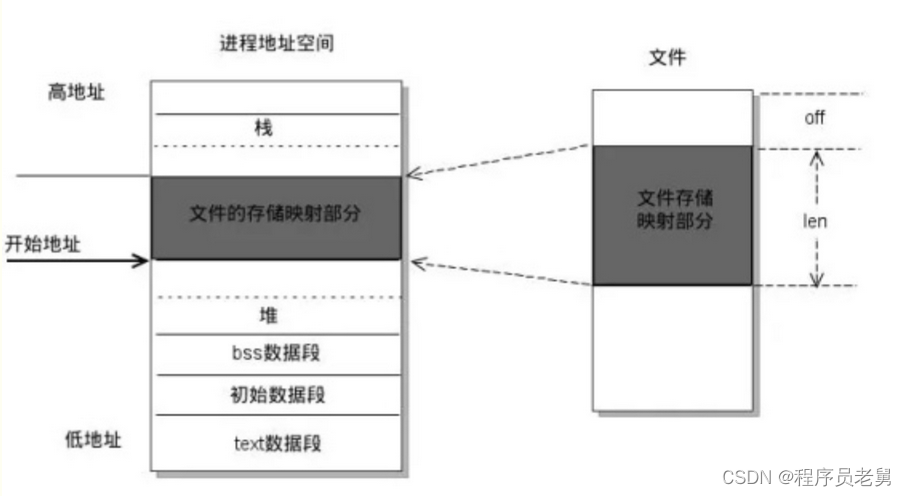
mmap内存映射原理:

mmap 内存映射过程:
-
- 进程在虚拟地址空间中为映射创建虚拟映射区域。
- 内核把文件物理地址和进程虚拟地址进行映射。
- 进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。
- 换句话说,在调用 mmap 后,只是在进程的虚拟空间中分配了一段空间,真实的物理地址还不会分配的。
- 当进程第一次访问这段空间(当作内存一样),CPU 陷入 OS 内核执行异常处理。然后异常处理会在这个时间分配物理内存,并用文件的内容填充这片内存,然后才返回进程的上下文,这时进程才会感知到这片内存里有数据。
mmap本质:
mmap 本质是内存共享机制,它把 page cache 地址空间映射到用户空间,换句话说,mmap 是一种特殊的 Buffered I/O。
因为底层有 CPU 的 MMU 支持,自然会转换到物理区域,对于进程而言是无感知。所以,磁盘数据加载到 page cache 后,用户进 程可以通过指针操作直接读写 page cache,不再需要系统调用和内存拷贝。
因此,offset 必须是按 page size 对齐的(不对齐的话就会映射失败)。
mmap 映射区域大小必须是物理页大小(page size)的整倍数(32 位系统中通常是 4k)。length 对齐是靠内核来保证的,比如文件长度是 10KB,你映射了 5KB,那么内核会将其扩充到 8KB。
6、Linux五大网络IO模型
1.BIO:阻塞模式IO
举个例子:
一个人去 商店买一把菜刀,
他到商店问老板有没有菜刀(发起系统调用)
如果有(表示在内核缓冲区有需要的数据)
老板直接把菜刀给买家(从内核缓冲区拷贝到用户缓冲区)
这个过程买家一直在等待如果没有,商店老板会向工厂下订单(IO操作,等待数据准备好)
工厂把菜刀运给老板(进入到内核缓冲区)
老板把菜刀给买家(从内核缓冲区拷贝到用户缓冲区)
这个过程买家一直在等待
是同步io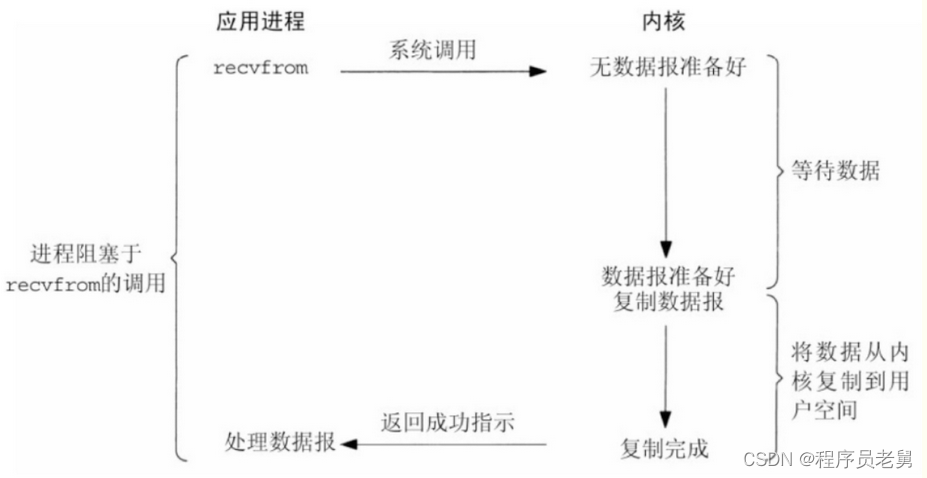
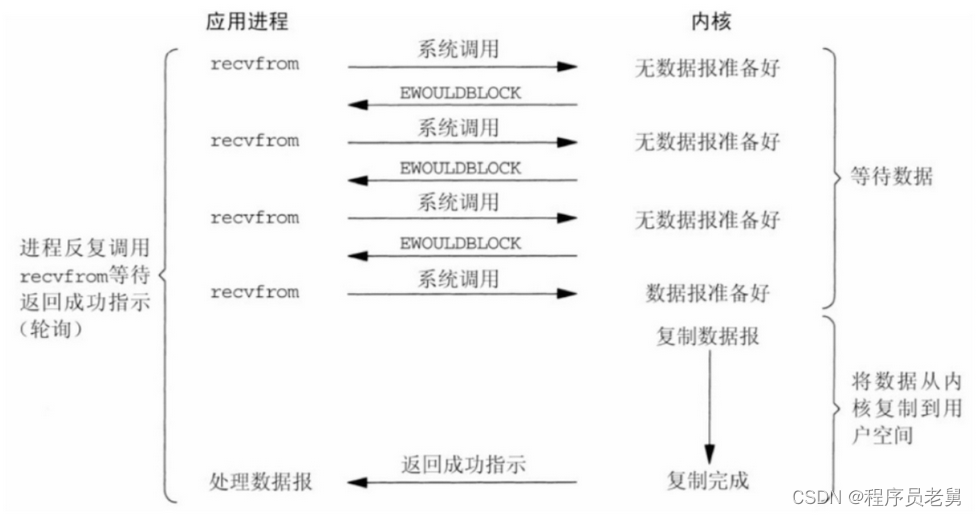
2.NIO:非阻塞模式IO
用户进程发起请求,如果数据没有准备好,那么立刻告知用户进程未准备好;此时用户进程可选择继续发起请求、或者先去做其他事情,稍后再回来继续发请求,直到被告知数据准备完毕,可以开始接收为止; 数据会由用户进程完成拷贝
举个例子:
一个人去 商店买一把菜刀,
他到商店问老板有没有菜刀(发起系统调用)
老板说没有,在向工厂进货(返回状态)
买家去别地方玩了会,又回来问,菜刀到了么(发起系统调用)
老板说还没有(返回状态)
买家又去玩了会(不断轮询)
最后一次再问,菜刀有了(数据准备好了)
老板把菜刀递给买家(从内核缓冲区拷贝到用户缓冲区)
整个过程轮询+等待:轮询时没有等待,可以做其他事,从内核缓冲区拷贝到用户缓冲区需要等待
是同步io
3.I/O多路复用模型
类似BIO,只不过找了一个代理,来挂起等待,并能同时监听多个请求; 数据会由用户进程完成拷贝
举个例子:多个人去 一个商店买菜刀,
多个人给老板打电话,说我要买菜刀(发起系统调用)
老板把每个人都记录下来(放到select中)
老板去工厂进货(IO操作)
有货了,再挨个通知买到的人,来取刀(通知/返回可读条件)
买家来到商店等待,老板把到给买家(从内核缓冲区拷贝到用户缓冲区)
多路复用:老板可以同时接受很多请求(select模型最大1024个,epoll模型),
但是老板把到给买家这个过程,还需要等待,
是同步io
select本质也是轮询最多可以监听1024个,而epoll模型是事件驱动,好了会主动告诉你
-select:小明,你写好了么?小红你写好了么?.......
-epoll:同学写好了,举手告诉老师来检查(nginx、tornado用的是epoll)windows平台不支持epoll,用的是select

4.信号驱动IO
事先发出一个请求,当有数据后会返回一个标识回调,这时你可以去请求数据(不是轮询请求,而是收到返回标识后请求)。好比银行排号,当叫到你的时候,你就可以去处理业务了(复制数据时阻塞)。
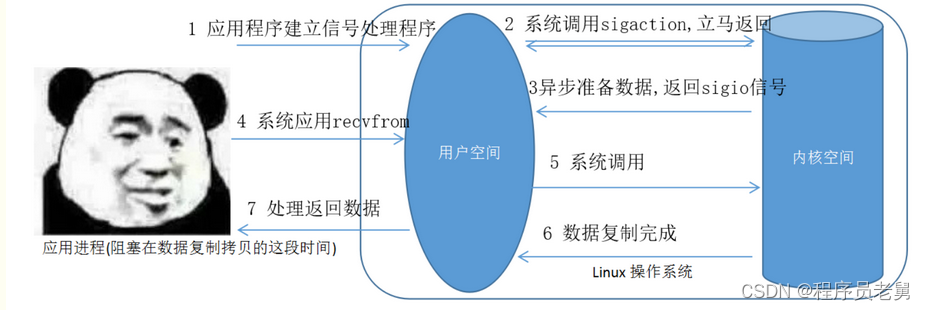
信号驱动IO,调用sigaltion系统调用,当内核中IO数据就绪时以SIGIO信号通知请求进程,请求进程再把数据从内核读入到用户空间,这一步是阻塞的。
5.异步IO--AIO
发起请求立刻得到回复,不用挂起等待; 数据会由内核进程主动完成拷贝,目前不成熟
举个例子:还是买菜刀
现在是网上下单到商店(系统调用)
商店确认(返回)
商店去进货(io操作)
商店收到货把货发个卖家(从内核缓冲区拷贝到用户缓冲区)
买家收到货(指定信号)整个过程无等待
异步io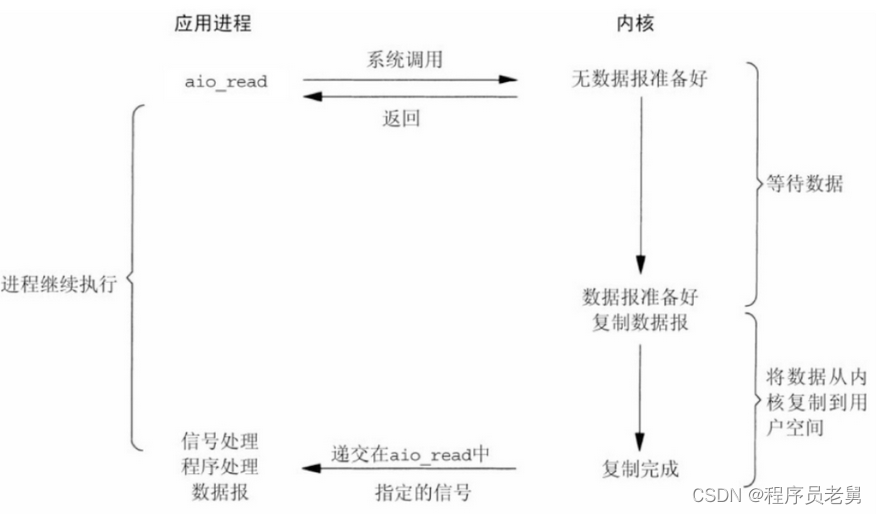
总结:
- 同步I/O与异步I/O判断依据是,是否会导致用户进程阻塞
- BIO中socket直接阻塞等待(用户进程主动等待,并在拷贝时也等待)
- NIO中将数据从内核空间拷贝到用户空间时阻塞(用户进程主动询问,并在拷贝时等待)
- IO Multiplexing中select等函数为阻塞、拷贝数据时也阻塞(用户进程主动等待,并在拷贝时也等待)
- AIO中从始至终用户进程都没有阻塞(用户进程是被动的)
相关文章:
Linux磁盘IO、网络IO、零拷贝详解
一、什么是I/O? 在计算机操作系统中,所谓的I/O就是输入(input)和输出(output),也可以理解为读(read)和写(write),针对不同的对象,I/O模式可以划分…...

工业交换机外壳材质大比拼,看看哪种外壳适合你
在工业领域里,交换机就像我们的网络心脏,时刻跳动着确保信息畅通无阻。而它的外壳,就是保护这颗“心脏”的铠甲。今天,咱们就来聊聊这些铠甲——工业交换机外壳的材质和防护等级,看看它们如何守护我们的网络世界。 首…...

智慧公厕的技术基础、保障技术和应用价值
近年来,随着信息技术的快速发展,智慧公厕逐渐成为城市管理的热点项目。智慧公厕利用物联网技术与大数据、云计算、网络通信、自动化控制等先进技术相结合,公共厕所的管理变得更加快捷高效,实现了真正的智能化使用和智慧化管理。下…...

思腾合力受邀参加VALSE 2024视觉与学习青年学者研讨会
在充满学术氛围的五月,思腾合力荣幸受邀参加了于2024年5月5-7日在重庆举行的第十四届VALSE大会。作为视觉与学习领域的顶级交流平台,VALSE大会每年都吸引着全国专家与学者的目光。 本次大会不仅延续了往届的高水平学术研讨,还进一步拓宽了研究…...

geotrust dv通配符证书800
Geotrust是成立时间较久的正规CA认证机构,在过去的几十年间颁发了无数的SSL证书,这些SSL证书被各个开发者使用,受到大多数浏览器的信任。而Geotrust旗下的DV通配符证书因其广泛的应用范围受到了用户的青睐。今天就随SSL盾小编了解Geotrust旗下…...
SpringBoot工作原理
优点:自动装配,起步依赖 起步依赖 原理就是maven的依赖传递 【A依赖B、B依赖C….,则我导入依赖A的时候,B,C都会被maven加载进来】 重点看看自动装配 概念: 当Spring容器启动后,一些配置类、…...
【Spring】Spring 整合 Junit、MyBatis
一、 Spring 整合 Junit <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache…...

【JVM基础篇】JVM入门介绍
JVM入门介绍 为什么学习JVM 岗位要求 解决工作中遇到的问题 性能调优 真实案例 导出超大文件,系统崩溃从数据库中查询超大量数据出错消费者消费来不及导致系统崩溃Mq消息队列接受消息导致的内存泄漏业务高峰期系统失去响应 初识JVM 什么是JVM? JV…...
理解函数对象)
《21天学通C++》(第二十一章)理解函数对象
什么是函数对象? 函数对象是一种特殊类型的类,它重载了函数调用操作符 operator(),使得类的实例可以像函数一样被调用。 什么是谓词? 谓词是指一个能够返回布尔值(true或false)的函数或函数对象 1.一元函数…...
2024.1.1 IntelliJ IDEA 使用记录
2024.1.1 IntelliJ IDEA 使用记录 下载设置文件编码maven 配置 插件可以中文语言包安装lombok 插件Smart Tomcat ( 根据需要安装)Smart Tomcat 配置 热部署(非必须的)解决Intellij IDEA运行报Command line is too long的问题 项目导入java 设置maven 配置…...

扩展van Emde Boas树以支持卫星数据:设计与实现
扩展van Emde Boas树以支持卫星数据:设计与实现 1. 引言2. vEB树的基本概念3. 支持卫星数据的vEB树设计3.1 数据结构的扩展3.2 操作的修改3.3 卫星数据的存储和检索 4. 详细设计和实现4.1 定义卫星数据结构体4.2 修改vEB树节点结构4.3 插入操作的伪代码4.4 C语言实现…...

玩游戏专用远程控制软件
玩游戏专用远程控制软件:实现远程游戏的新体验 随着网络技术的不断发展和创新,远程控制软件已经逐渐渗透到我们生活的方方面面,尤其是在游戏领域。玩游戏专用远程控制软件,作为这一趋势下的产物,为玩家提供了全新的游…...

机器人规划控制——工程化——心得日记-20240510
近一周一直在调试机器人过迷宫形路线,这种路线特点是障碍物之间距离较小且障碍物也比较多,基本机器人会一直发生干涉检测,请求全局路径,然后再控制机器人前进。 遇到一个特别有趣的问题,当然最后查出来原因也感觉比较…...

2024年成都市标杆场景项目申报条件对象、奖励和认定材料流程
一、申报条件 (一)申报主体需注册成立两年以上,具备独立法人资格,在成都有固定经营或者生产场地,上两年度主营业务收入年均1000万元以上或上两年度主营业务收入增长率年均10%以上; (二&#x…...

前端Vue uView 组件<u-search> 自定义右侧搜索按钮样式
前言 uView 文档的效果不是ui设计的样式 需要重新编辑 原效果 ui设计效果 解决方案 设置里说明的需要传一个样式对象 这个对象 需要写在 script 标签里面 这里需要遵循驼峰命名 比如font-size 改为 fontSize lineHeight和textAlign为水平锤子居中效果 searchStyle: {ba…...
【Linux网络编程】I/O多路转接之select
select 1.初识select2.了解select基本概念和接口介绍3.select服务器4.select特点及优缺点总结 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励,我们一起努力吧!😃😃…...

三下乡社会实践投稿攻略在这里
在当今信息爆炸的时代,如何让自己的声音被更多人听到,成为许多人和企业所关心的问题。其中,向各大媒体网站投稿,成为了一种常见的宣传方式。但是,如何投稿各大媒体网站?新闻媒体发文策略又有哪些呢…...
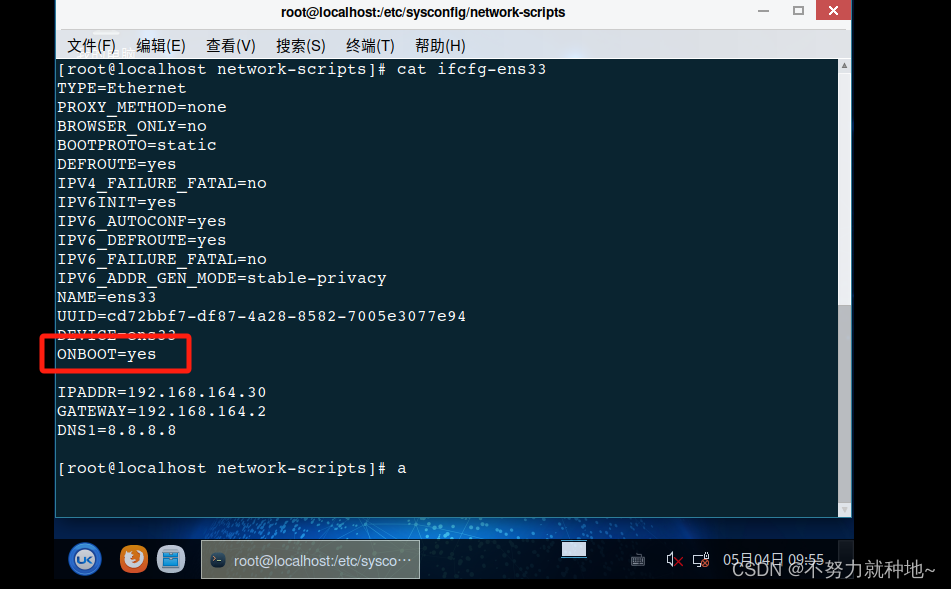
银河麒麟桌面版开机后网络无法自动链接 麒麟系统开机没有连接ens33
1.每次虚拟机开机启动麒麟操作系统,都要输入账号,密码。 进入点击这个ens33 内网才连接 2. 如何开机就脸上呢? 2.1. 进入 cd /etc/sysconfig/network-scripts 2.2 修改参数 onbootyes 改为yes 2.3 重启即可 a. 直接重启机器查看是否正常&…...

vue+onlyOffice+java : 集成在线编辑word并保存
1.docker部署onlyOffice 1.1拉取最新版onlyOffice镜像 sudo docker pull onlyoffice/documentserver 1.2运行以下命令运行容器 其中 -v 后的第一部分是挂载自己的linux的哪个目录 # 启动docker容器,默认启动端口为80,可以进行修改 docker run -i -t …...

linux上用Jmter进行压测
在上一篇中安装好了Jmeter环境,在这一篇中将主要分享如何使用jmeter在linux中进行单机压测。 1.项目部署 在这里我们先简单部署一下测试环境,所用到的项目环境是个jar包,先在linux上home目录下新建app目录,然后通过rz命令将项目ja…...
Transformer不只是NLP的宠儿:看CMX如何用交叉注意力玩转多模态语义分割
Transformer跨界多模态语义分割:CMX如何用交叉注意力重塑RGB-X融合范式 当视觉Transformer在ImageNet分类任务中首次超越CNN时,很少有人预见到这项源自自然语言处理的技术会在计算机视觉的各个领域引发如此深刻的变革。特别是在需要密集预测的语义分割任…...

用tcpreplay+Wireshark搭建网络攻防实验环境:手把手教你复现渗透测试流量
实战指南:用tcpreplay与Wireshark构建网络攻防实验环境 在网络安全领域,理论知识的掌握固然重要,但真正的技能提升往往来自于实战演练。然而,直接在真实网络环境中进行渗透测试或攻击模拟不仅存在法律风险,还可能对生…...

Cogito-V1-Preview-Llama-3B开发环境配置:从零开始安装Python及必备库
Cogito-V1-Preview-Llama-3B开发环境配置:从零开始安装Python及必备库 想玩转Cogito-V1-Preview-Llama-3B这样的AI模型,第一步不是研究复杂的算法,而是把“地基”打好。这个地基,就是你的开发环境。很多朋友兴致勃勃地下载了模型…...

腾讯优图4B模型实测:轻量级多模态AI,图片描述、图表分析、目标检测,一个模型全解决
腾讯优图4B模型实测:轻量级多模态AI,图片描述、图表分析、目标检测,一个模型全解决 1. 开箱体验:4B参数的全能选手 当我第一次在CSDN星图镜像广场看到这个只有4B参数的腾讯优图多模态模型时,说实话是持怀疑态度的。毕…...

实战指南:基于快马生成tomcat生产级配置,涵盖https、集群与性能调优
今天想和大家分享一个实战经验:如何在生产环境中配置Tomcat服务器。作为一个长期和Tomcat打交道的开发者,我深知生产环境配置和本地开发环境的巨大差异。最近在InsCode(快马)平台上实践了一套完整的配置方案,效果很不错,这里把关键…...

SeqGPT-560M实现YOLOv8目标检测:智能图像分析实战
SeqGPT-560M实现YOLOv8目标检测:智能图像分析实战 1. 引言 在计算机视觉领域,目标检测一直是个核心且具有挑战性的任务。传统的YOLOv8模型虽然检测速度快、准确率高,但在处理复杂场景时,往往需要额外的语义理解能力来提升检测精…...

Umi-OCR:彻底解决你的文字识别难题,这3大功能让你效率翻倍!
Umi-OCR:彻底解决你的文字识别难题,这3大功能让你效率翻倍! 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址…...

OpenClaw技能开发入门:为nanobot编写自定义文件处理器
OpenClaw技能开发入门:为nanobot编写自定义文件处理器 1. 为什么需要自定义技能 去年夏天,我发现自己每周都要花两小时手动整理项目文档——把分散在各处的Markdown文件合并、去重、重新编号。当我第三次在重复劳动中睡着时,终于决定用Open…...
)
Python MCP服务性能翻倍实录:基于asyncpg+uvloop+Pydantic V2的模板优化路径(QPS从83→417实测数据)
第一章:Python MCP服务性能翻倍实录:基于asyncpguvloopPydantic V2的模板优化路径(QPS从83→417实测数据) 在高并发MCP(Microservice Control Plane)服务场景中,原基于Flask SQLAlchemy CPyth…...

3步快速恢复ROG游戏本色彩配置文件的终极指南
3步快速恢复ROG游戏本色彩配置文件的终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: https://gitcode.…...