【hive】transform脚本
文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Transform
- 一、介绍
- 二、实现
- 1.脚本上传到本地
- 2.脚本上传到hdfs
- 三、几个需要注意的点
- 1.脚本名不要写全路径
- 2.using后面语句中,带不带"python"的问题
- 3.py脚本Shebang:#!/usr/bin/env python
一、介绍
和udf差不多的作用,支持用python实现。通过标准输入流从hive读取数据,内部处理完再通过标准输出流将处理结果返回给hive。实现流程上比udf要更简单灵活一些,只需要上传脚本=>add file加载到分布式缓存=>使用。
二、实现
先定义一个名为transform.py的脚本,将传入的两个字段值都+1。
#!/usr/bin/env python
import sysfor line in sys.stdin:try:x, y = map(float, line.strip().split('\t'))x += 1y += 1print('\t'.join(map(str, [x, y])))except ValueError as e:print('\t'.join([r'\N'] * 2))
上面对输入流按照
\t分隔是因为hive中的数据在传递到py脚本时,多个字段间默认会用\t分隔拼接为字符串,并且空值null会被转为字符串\N。同样将处理结果返回给hive时,如果多个字段,为了hive能够正确解析,也需要用\t拼接输出,单独的\N在hive中也会被重新解释为null。
除了单独的\N会被重新解释为null外,还有一种情况也会被hive解释为null,就是脚本里返回的字段个数小于hive中接收的字段个数时,hive中多余的字段会被赋值为null。

1.脚本上传到本地
这里的本地指的是hive主服务hive server2所在的节点,也就是我们客户端连接的那个机器。
先上传到主服务机器下的某个路径:
# 文件上传路径
[root@node1 HiveLib]# readlink -e transform.py
/root/HiveLib/transform.py
上传后通过add file命令将脚本添加到分布式缓存,之后就可以直接使用了。
-- 添加到分布式缓存
add file /root/HiveLib/transform.py;-- 创建一个临时表测试执行
with `table` as (select '1' as id, '1.6789' as col1, '7.13' as col2union allselect '2' as id, '11.568' as col1, null as col2union allselect '3' as id, '26.09761' as col1, '71.89002' as col2
)
-- as后面接收脚本返回值的字段也可以指定字段类型, eg:(col1 double, col2 double), 省略时默认都是字符串string类型
select transform (col1, col2) using 'transform.py' as (col1, col2) from `table`;

2.脚本上传到hdfs
这种方式和本地实现基本一致,只不过需要将脚本上传到hdfs中,add file时后面跟的是hdfs路径。
[root@node1 HiveLib]# hadoop fs -put ./transform.py /user/hive/lib
[root@node1 HiveLib]# hadoop fs -ls /user/hive/lib
Found 2 items
-rw-r--r-- 3 root supergroup 4164 2022-12-18 00:48 /user/hive/lib/hive_udf-1.0-SNAPSHOT.jar
-rw-r--r-- 3 root supergroup 257 2024-05-05 19:13 /user/hive/lib/transform.py
sql客户端中执行:
-- 脚本路径换为hdfs路径
add file hdfs://node1:8020/user/hive/lib/transform.py;with `table` as (select '1' as id, '1.6789' as col1, '7.13' as col2union allselect '2' as id, '11.568' as col1, null as col2union allselect '3' as id, '26.09761' as col1, '71.89002' as col2
)
select transform (col1, col2) using 'transform.py' as (col1, col2) from `table`;

三、几个需要注意的点
1.脚本名不要写全路径
using语句后面指定脚本只写脚本名即可,不要写全路径。全路径的话会报错[08S01][20000] Error while processing statement: FAILED: Execution Error, return code 20000 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Unable to initialize custom script.,参考
https://stackoverflow.com/questions/15106127/i-met-an-error-when-i-using-hive-transform-features,我也不太理解为什么有这要求,先照做就行。

2.using后面语句中,带不带"python"的问题
这里说的是sql语句中,是using 'transform.py'还是using 'python transform.py'的问题。可以不带python这个关键字,但是前提脚本中必须指定了Shebang,类似于#!/usr/bin/env python这样,指定脚本的解释器。如果指定Shebang,using后面带不带python都可以,如果脚本中没指定,using后面必须带python这个关键字,否则报错。
看到有人说需要给py脚本
chmod +x transform.py赋予可执行权限,实际操作中经过验证本地和hdfs都不需要。
3.py脚本Shebang:#!/usr/bin/env python
Shebang(也称为Hashbang)是一个源于Unix系统中的概念,特别是在类Unix操作系统中广泛使用。它是指脚本文件第一行以#!开头的特殊注释行,用于指定该脚本应该由哪个解释器程序来执行。这个名称来源于这两个起始字符—井号(#)和叹号(!)。
主要解释下#!/usr/bin/env python和#!/usr/bin/python的区别。两者都是用来指定该脚本的解释器,但是前者比后者有更好的兼容性,可以理解为:后者是指定了一个固定的解释器路径,虽然多数情况下遵循规范解释器路径会在该目录下,但是并不能保证一定存在。而前者逻辑上等价于env | grep python,它是从当前所有的环境变量中按照一定的优先级顺序去找python解释器,最先找到哪个就用哪个执行,所以可以有效避免路径指定错误的问题,推荐前面这种写法。
[root@node1 HiveLib]# which python
/root/anaconda3/bin/python
[root@node1 HiveLib]# which env
/usr/bin/env
[root@node1 HiveLib]# env | grep python
CONDA_PYTHON_EXE=/root/anaconda3/bin/python
相关文章:
【hive】transform脚本
文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManualTransform 一、介绍二、实现1.脚本上传到本地2.脚本上传到hdfs 三、几个需要注意的点1.脚本名不要写全路径2.using后面语句中,带不带"python"的问题3.py脚本Shebang…...

5款可用于LLMs的爬虫工具/方案
5款可用于LLMs的爬虫工具/方案 Crawl4AI 功能: 提取语义标记的数据块为JSON格式,提供干净的HTML和Markdown文件。 用途: 适用于RAG(检索增强生成)、微调以及AI聊天机器人的开发。 特点: 高效数据提取,支持LLM格式,多U…...

投影、选择转SQL语言
使用以下两个表进行举例,第一个表为R表,第二个表为S表 R.AR.BR.C123456789 S.AS.BS.C101112131415161718 1、投影转SQL语言: 兀 A,B,C (R) 等价于select A,B,C from R 解释: 兀:相当于select (R):相当于from R…...

系统加固-自用
一、windows 1、概述 (1)、权限最高:system(系统账户),权限比administrator权限还高 (2)、常见操作系统安全漏洞类型 缓冲区溢出漏洞TCP/IP协议漏洞web应用安全漏洞开放端口的安全漏洞 2、系统安全加固方法 (1)、系统不显示上次登录的用户名 进入…...

Java面试题:阐述Java中的自动装箱与拆箱机制,以及使用它们时可能遇到的性能问题
在Java中,自动装箱(Autoboxing)和拆箱(Unboxing)是Java 5引入的特性,它们允许基本数据类型和对应的包装类之间的自动转换。 自动装箱 自动装箱是指将基本数据类型(如int、double等)…...

初识sql注入--手工注入
目录 可能使用的sql函数 入侵网站方式 1、文件上传漏洞 2、rce 3、sql注入 SQL注入 什么是sql注入 进行SQL注入 实验环境 开始实验(使用information_shema数据库) 1、进入靶场 2、报列数 下面来解释一下为什么要照上面SQL语句写 url编码 单…...

OceanBase 缺少 dbms_obfuscation_toolkit.md5 包函数的解决方案
因为 dbms_obfuscation_toolkit.md5 是一个 Oracle 不推荐继续使用的函数,所以 OceanBase 没有对其兼容,取而代之的是兼容了 dbms_crypto.hash,其用法详见这篇 KB 但是,并不是所有业务都接受修改源码,因为复杂系统里&…...

Java---类和对象第一节
目录 1.面向对象初步认识 1.1什么是面向对象 1.2面向对象和面向过程的区别 2.类的定义和使用 2.1简单认识类 2.2类的定义格式 2.3类的实例化 2.4类和对象的说明 3.this关键字 3.1访问本类成员变量 3.2调用构造方法初始化成员变量 3.3this引用的特性 4.对象的构造以…...

Zeller公式的应用:给定日期,确定周几
开篇 本篇文章依然是对于日期相关函数的实现。 问题概要 给定一个日期,返回为周几 思路分析 这个问题的思路只是对于Zeller公式的直接引用,不存在其他逻辑。公式详情可参考Zeller公式百科 代码实现 #include <stdio.h>// 根据Zeller公式计算 int …...

程序链接和运行 - 笔记
1 linux下程序a连接b.so后,运行时如何找到调用的函数 在Linux下,当程序A连接了动态链接库B(.so文件)后,在运行时,程序A会使用动态链接器(dynamic linker)来解析并加载动态链接库B中的函数。动态链接器会在系统中搜索动态链接库,并将它们加载到程序的地址空间中。 当…...
pyqt 按钮常用格式Qss设置
pyqt 按钮常用格式Qss设置 QSS介绍按钮常用的QSS设置效果代码 QSS介绍 Qt Style Sheets (QSS) 是 Qt 框架中用于定制应用程序界面样式的一种语言。它类似于网页开发中的 CSS(Cascading Style Sheets),但专门为 Qt 应用程序设计。使用 QSS&am…...

websevere服务器从零搭建到上线(一)|阻塞、非阻塞、同步、异步
文章目录 数据准备(阻塞和非阻塞)、数据读写(同步和异步)小总结(陈硕老师的总结) 知识拓展同步执行实例异步编程实例 八股 数据准备(阻塞和非阻塞)、数据读写(同步和异步) 无论是什么样的IO都包含两个阶段:数据准备和数据读写。 我们的网络IO…...

【C++】引用传递 常量引用
在C中,引用传递和常量引用是两个常用的概念,主要用于函数参数传递。它们提供了对变量或对象更有效率和更安全的访问方式。 引用传递(Pass by Reference) 引用传递意味着当你将变量作为参数传递给函数时,你实际上是传…...

Docker停止不了
报错信息 意思是,docker.socket可能也会把docker服务启动起来 解决 检查服务状态 systemctl status dockersystemctl is-enabled docker停止docker.socket systemctl stop docker.socket停止docker systemctl stop docker知识扩展 安装了docker后,…...

【网络】为什么TCP需要四次挥手?
在网络通信中,TCP(传输控制协议)是一种可靠的、面向连接的协议,它在数据传输过程中保证了数据的可靠性和顺序性。而TCP的连接建立过程只需要三次握手,但是TCP的挥手过程却需要四次挥手,这是为什么呢&#x…...
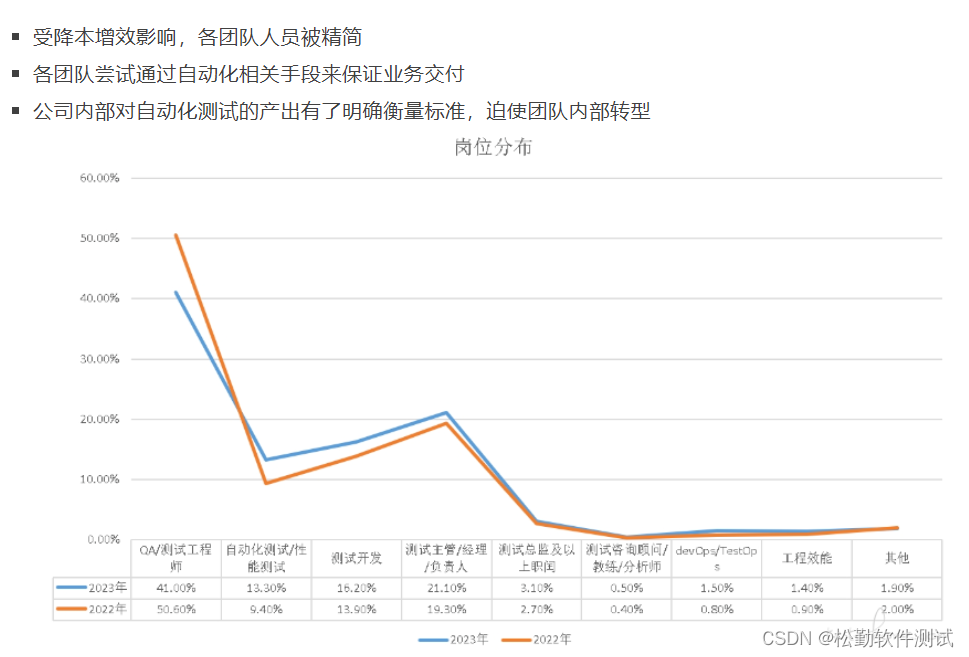
2024自动化测试市场分析
大家都说2024年软件测试讲会卷的更厉害,从原来的功能测试到现在自动化测试,那么2024年是否可以学习自动化冲一把,我们先看一下2023年自动化测试在测试行业中的分析: 1.市场需求增长: 随着技术的进步和企业对软件质量的要求日益提高,自动化测试在测试行…...

什么是机器视觉应用解决方案?
机器视觉应用解决方案通常指的是利用视觉系统自动检测、处理和分析图像的技术方案,以便执行各种工业或研究任务,如质量控制、自动检测、导航和识别等。在LabVIEW环境中,这些解决方案通常涉及到硬件和软件的紧密集成,以实现高效的数…...

使用 scrapyd 部署 scrapy
1.scrapyd 是什么? Scrapyd 是一个用于部署和运行 Scrapy 爬虫项目的服务器应用程序。它使得你可以通过 HTTP 命令来部署、管理和执行多个 Scrapy 爬虫,非常适合持续集成和生产环境中的爬虫部署。 2.安装scrapyd 并使用 2.1 安装 scrapyd F:\scrapydTes…...

Python计算器程序代码
from tkinter import * import random class App: def __init__(self, master): self.master master self.initwidgets() #表达式的值 self.expr None def initwidgets(self): #定义一个输入组件 self.show Label(relief SUNKEN, font (Courier New, 24), width 25, bg …...

图像分割各种算子算法-可直接使用(Canny、Roberts、Sobel)
Canny算子: import numpy as np import cv2 as cv from matplotlib import pyplot as pltimg cv.imread("../test_1_1.png") edges cv.Canny(img, 100, 200)plt.subplot(121),plt.imshow(img,cmap gray) plt.title(Original Image), plt.xticks([]), …...

告别黑框!树莓派4B远程桌面完整指南:从VNC配置到RealVNC/XRDP方案选择与优化
树莓派4B远程桌面终极方案:告别黑框与卡顿的实战指南 对于许多树莓派开发者而言,那个令人沮丧的黑色方框已经成为远程连接体验的代名词。当你满怀期待地输入IP地址,等待的却是一个无法操作的空白界面,这种挫败感足以让任何人抓狂。…...

HTTPS单向认证、双向认证、抓包原理与反抓包策略详解
HTTPS单向认证、双向认证、抓包原理与反抓包策略详解 一、HTTPS单向认证 HTTPS单向认证是只要求站点部署 SSL证书,客户端会去验证服务器的身份,而服务器不会去验证客户端的身份。这种认证方式相对简单,但可以提供一定的 安全性。任何用户都可…...

CentOS 7服务器部署:NFS共享、Nginx-RTMP流媒体与Qt无GUI环境全攻略
1. 项目概述与核心思路最近在华为云的一台CentOS 7.4 64位服务器版ECS上,完整部署了一套用于音视频处理和后台服务的开发环境。这个环境的核心目标,是为一个需要处理视频流、提供Web服务,并能方便地进行跨机文件共享和Qt程序编译的后台系统打…...

EMD vs NEMD:分子动力学算热导率,新手到底该选哪个?
EMD与NEMD方法实战指南:如何为你的热导率计算选择最佳方案 在纳米材料和新型功能材料的研究中,热导率的精确计算是理解材料热输运性能的关键。面对平衡态分子动力学(EMD)和非平衡态分子动力学(NEMD)两种主流方法,许多研究者常常陷入选择困境。…...

7天掌握FontForge:免费开源字体编辑器的完整使用指南
7天掌握FontForge:免费开源字体编辑器的完整使用指南 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾梦想设计属于自己的字体?无论是…...
)
R语言+ggplot2:手把手教你绘制Cell期刊同款世界地图采样图(附完整代码与数据)
R语言ggplot2:手把手教你绘制Cell期刊同款世界地图采样图(附完整代码与数据) 在科研论文中,一张精美的世界地图采样图往往能直观展示研究样本的全球分布,为论文增色不少。顶级期刊如Cell、Nature、Science上的文章&…...

避坑指南:为什么你的mqtt.fx连不上OneNET?Token生成与参数配置的3个关键细节
避坑指南:为什么你的mqtt.fx连不上OneNET?Token生成与参数配置的3个关键细节 当你深夜调试MQTT设备,反复检查代码却依然看到刺眼的"离线"状态时,那种挫败感我深有体会。OneNET作为国内主流物联网平台,其MQTT…...

CANN/asc-devkit SoftMax接口
SoftMax 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...
;RGRRQPIPKA)
HCV Core Protein (59-68);RGRRQPIPKA
一、基础信息多肽名称:丙型肝炎病毒 核心蛋白片段 (59-68) 英文名称:HCV Core Protein (59-68) 三字母序列:Arg-Gly-Arg-Arg-Gln-Pro-Ile-Pro-Lys-Ala 单字母序列:RGRRQPIPKA 氨基酸数量:10 aa 结构特征:线…...
:解决专家坍缩的工业级方案)
DeepSeek MoE训练稳定性突破(动态负载均衡+梯度裁剪双保险):解决专家坍缩的工业级方案
更多请点击: https://kaifayun.com 第一章:DeepSeek MoE架构解析 DeepSeek MoE(Mixture of Experts)是一种面向大语言模型高效推理与训练的稀疏化架构设计,其核心思想是在保持模型总参数量庞大的前提下,仅…...