Python深度学习基于Tensorflow(3)Tensorflow 构建模型
文章目录
- 数据导入和数据可视化
- 数据集制作以及预处理
- 模型结构
- 低阶 API 构建模型
- 中阶 API 构建模型
- 高阶 API 构建模型
- 保存和导入模型
这里以实际项目CIFAR-10为例,分别使用低阶,中阶,高阶 API 搭建模型。
这里以CIFAR-10为数据集,CIFAR-10为小型数据集,一共包含10个类别的 RGB 彩色图像:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。图像的尺寸为 32×32(像素),3个通道 ,数据集中一共有 50000 张训练圄片和 10000 张测试图像。CIFAR-10数据集有3个版本,这里使用Python版本。
数据导入和数据可视化
这里不用书中给的CIFAR-10数据,直接使用TensorFlow自带的玩意导入数据,可能需要魔法,其实TensorFlow中的数据特别的经典。
![![[Pasted image 20240506194103.png]]](https://img-blog.csdnimg.cn/direct/9c9c049d535c44c888ffb3cd14fbb40f.png)
接下来导入cifar10数据集并进行可视化展示
import matplotlib.pyplot as plt
import tensorflow as tf(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train.shape, y_train.shape, x_test.shape, y_test.shape
# ((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))index_name = {0:'airplane',1:'automobile',2:'bird',3:'cat',4:'deer',5:'dog',6:'frog',7:'horse',8:'ship',9:'truck'
}def plot_100_img(imgs, labels):fig = plt.figure(figsize=(20,20))for i in range(10):for j in range(10):plt.subplot(10,10,i*10+j+1)plt.imshow(imgs[i*10+j])plt.title(index_name[labels[i*10+j][0]])plt.axis('off')plt.show()plot_100_img(x_test[:100])
![![[Pasted image 20240506200312.png]]](https://img-blog.csdnimg.cn/direct/23ed0ee4b8a749cfb7dadc3e0c31749b.png)
数据集制作以及预处理
数据集预处理很简单就能实现,直接一行代码。
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))# 提取出一行数据
# train_data.take(1).get_single_element()
这里接着对数据预处理操作,也很容易就能实现。
def process_data(img, label):img = tf.cast(img, tf.float32) / 255.0return img, labeltrain_data = train_data.map(process_data)# 提取出一行数据
# train_data.take(1).get_single_element()
这里对数据还有一些存储和提取操作
dataset 中 shuffle()、repeat()、batch()、prefetch()等函数的主要功能如下。
1)repeat(count=None) 表示重复此数据集 count 次,实际上,我们看到 repeat 往往是接在 shuffle 后面的。为何要这么做,而不是反过来,先 repeat 再 shuffle 呢? 如果shuffle 在 repeat 之后,epoch 与 epoch 之间的边界就会模糊,出现未遍历完数据,已经计算过的数据又出现的情况。
2)shuffle(buffer_size, seed=None, reshuffle_each_iteration=None) 表示将数据打乱,数值越大,混乱程度越大。为了完全打乱,buffer_size 应等于数据集的数量。
3)batch(batch_size, drop_remainder=False) 表示按照顺序取出 batch_size 大小数据,最后一次输出可能小于batch ,如果程序指定了每次必须输入进批次的大小,那么应将drop_remainder 设置为 True 以防止产生较小的批次,默认为 False。
4)prefetch(buffer_size) 表示使用一个后台线程以及一个buffer来缓存batch,提前为模型的执行程序准备好数据。一般来说,buffer的大小应该至少和每一步训练消耗的batch数量一致,也就是 GPU/TPU 的数量。我们也可以使用AUTOTUNE来设置。创建一个Dataset便可从该数据集中预提取元素,注意:examples.prefetch(2) 表示将预取2个元素(2个示例),而examples.batch(20).prefetch(2) 表示将预取2个元素(2个批次,每个批次有20个示例),buffer_size 表示预提取时将缓冲的最大元素数返回 Dataset。
![![[Pasted image 20240506201344.png]]](https://img-blog.csdnimg.cn/direct/537beb2425ed45f5a6d5949ea3385224.png)
最后我们对数据进行一些缓存操作
learning_rate = 0.0002
batch_size = 64
training_steps = 40000
display_step = 1000AUTOTUNE = tf.data.experimental.AUTOTUNE
train_data = train_data.map(process_data).shuffle(5000).repeat(training_steps).batch(batch_size).prefetch(buffer_size=AUTOTUNE)
目前数据准备完毕!
模型结构
模型的结构如下,现在使用低阶,中阶,高阶 API 来构建这一个模型
![![[Pasted image 20240506202450.png]]](https://img-blog.csdnimg.cn/direct/1984f35550ae458baa1343ea5194e236.png)
低阶 API 构建模型
import matplotlib.pyplot as plt
import tensorflow as tf## 定义模型
class CustomModel(tf.Module):def __init__(self, name=None):super(CustomModel, self).__init__(name=name)self.w1 = tf.Variable(tf.initializers.RandomNormal()([32*32*3, 256]))self.b1 = tf.Variable(tf.initializers.RandomNormal()([256]))self.w2 = tf.Variable(tf.initializers.RandomNormal()([256, 128]))self.b2 = tf.Variable(tf.initializers.RandomNormal()([128]))self.w3 = tf.Variable(tf.initializers.RandomNormal()([128, 64]))self.b3 = tf.Variable(tf.initializers.RandomNormal()([64]))self.w4 = tf.Variable(tf.initializers.RandomNormal()([64, 10]))self.b4 = tf.Variable(tf.initializers.RandomNormal()([10]))def __call__(self, x):x = tf.cast(x, tf.float32)x = tf.reshape(x, [x.shape[0], -1])x = tf.nn.relu(x @ self.w1 + self.b1)x = tf.nn.relu(x @ self.w2 + self.b2)x = tf.nn.relu(x @ self.w3 + self.b3)x = tf.nn.softmax(x @ self.w4 + self.b4)return x
model = CustomModel()## 定义损失
def compute_loss(y, y_pred):y_pred = tf.clip_by_value(y_pred, 1e-9, 1.)loss = tf.keras.losses.sparse_categorical_crossentropy(y, y_pred)return tf.reduce_mean(loss)## 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002)## 定义准确率
def compute_accuracy(y, y_pred):correct_pred = tf.equal(tf.argmax(y_pred, axis=1), tf.cast(tf.reshape(y, -1), tf.int64))correct_pred = tf.cast(correct_pred, tf.float32)return tf.reduce_mean(correct_pred)## 定义一次epoch
def train_one_epoch(x, y):with tf.GradientTape() as tape:y_pred = model(x)loss = compute_loss(y, y_pred)accuracy = compute_accuracy(y, y_pred)grads = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(grads, model.trainable_variables))return loss.numpy(), accuracy.numpy()## 开始训练loss_list, acc_list = [], []
for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1):loss, acc = train_one_epoch(batch_x, batch_y)loss_list.append(loss)acc_list.append(acc)if i % 10 == 0:print(f'第{i}次训练->', 'loss:' ,loss, 'acc:', acc)
中阶 API 构建模型
## 定义模型
class CustomModel(tf.Module):def __init__(self):super(CustomModel, self).__init__()self.flatten = tf.keras.layers.Flatten()self.dense_1 = tf.keras.layers.Dense(256, activation='relu')self.dense_2 = tf.keras.layers.Dense(128, activation='relu')self.dense_3 = tf.keras.layers.Dense(64, activation='relu')self.dense_4 = tf.keras.layers.Dense(10, activation='softmax')def __call__(self, x):x = self.flatten(x)x = self.dense_1(x)x = self.dense_2(x)x = self.dense_3(x)x = self.dense_4(x)return xmodel = CustomModel()## 定义损失以及准确率
compute_loss = tf.keras.losses.SparseCategoricalCrossentropy()
train_loss = tf.keras.metrics.Mean()
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()## 定义优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002)## 定义一次epoch
def train_one_epoch(x, y):with tf.GradientTape() as tape:y_pred = model(x)loss = compute_loss(y, y_pred)grads = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(grads, model.trainable_variables))train_loss(loss)train_accuracy(y, y_pred)## 开始训练
loss_list, accuracy_list = [], []
for i, (batch_x, batch_y) in enumerate(train_data.take(1000), 1):train_one_epoch(batch_x, batch_y)loss_list.append(train_loss.result())accuracy_list.append(train_accuracy.result())if i % 10 == 0:print(f"第{i}次训练: loss: {train_loss.result()} accuarcy: {train_accuracy.result()}")
高阶 API 构建模型
## 定义模型
model = tf.keras.Sequential([tf.keras.layers.Input(shape=[32,32,3]),tf.keras.layers.Flatten(),tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(10, activation='softmax'),
])## 定义optimizer,loss, accuracy
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0002),loss = tf.keras.losses.SparseCategoricalCrossentropy(),metrics=['accuracy']
)## 开始训练
model.fit(train_data.take(10000))
保存和导入模型
保存模型
tf.keras.models.save_model(model, 'model_folder')
导入模型
model = tf.keras.models.load_model('model_folder')
相关文章:
Python深度学习基于Tensorflow(3)Tensorflow 构建模型
文章目录 数据导入和数据可视化数据集制作以及预处理模型结构低阶 API 构建模型中阶 API 构建模型高阶 API 构建模型保存和导入模型 这里以实际项目CIFAR-10为例,分别使用低阶,中阶,高阶 API 搭建模型。 这里以CIFAR-10为数据集,C…...
火爆多年的抖音小店,2024年想要入驻需要什么条件呢?
大家好,我是电商糖果 我相信现在只要会上网的年轻人,对抖音小店一定不会感觉陌生。 它最近几年的风头,可是远远超过某宝,某多多了。 不少抖音用户也有了在抖音购物的习惯,现在的抖音上入驻了上百万家电商商家。 这…...
STM32G030C8T6:EEPROM读写实验(I2C通信)
本专栏记录STM32开发各个功能的详细过程,方便自己后续查看,当然也供正在入门STM32单片机的兄弟们参考; 本小节的目标是,系统主频64 MHZ,采用高速外部晶振,实现PB11,PB10 引脚模拟I2C 时序,对M24C08 的EEPRO…...
使用Git管理github的代码库-上
1、下载安装Git https://download.csdn.net/download/notfindjob/11451730?spm1001.2014.3001.5503 2、注册一个github的账号(已经注册的,可略过这一步) 3、打开git命令行,配置github账号 git config --global user.name &quo…...
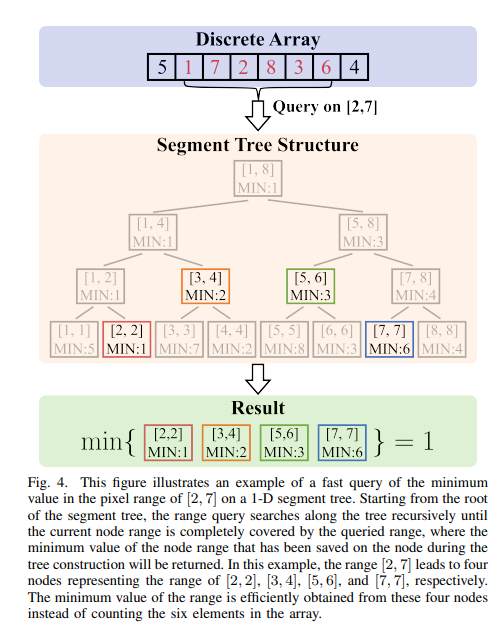
经典文献阅读之--D-Map(无需射线投射的高分辨率激光雷达传感器的占据栅格地图)
0. 简介 占用地图是机器人系统中推理环境未知和已知区域的基本组成部分。《Occupancy Grid Mapping without Ray-Casting for High-resolution LiDAR Sensors》介绍了一种高分辨率LiDAR传感器的高效占用地图框架,称为D-Map。该框架引入了三个主要创新来解决占用地图…...
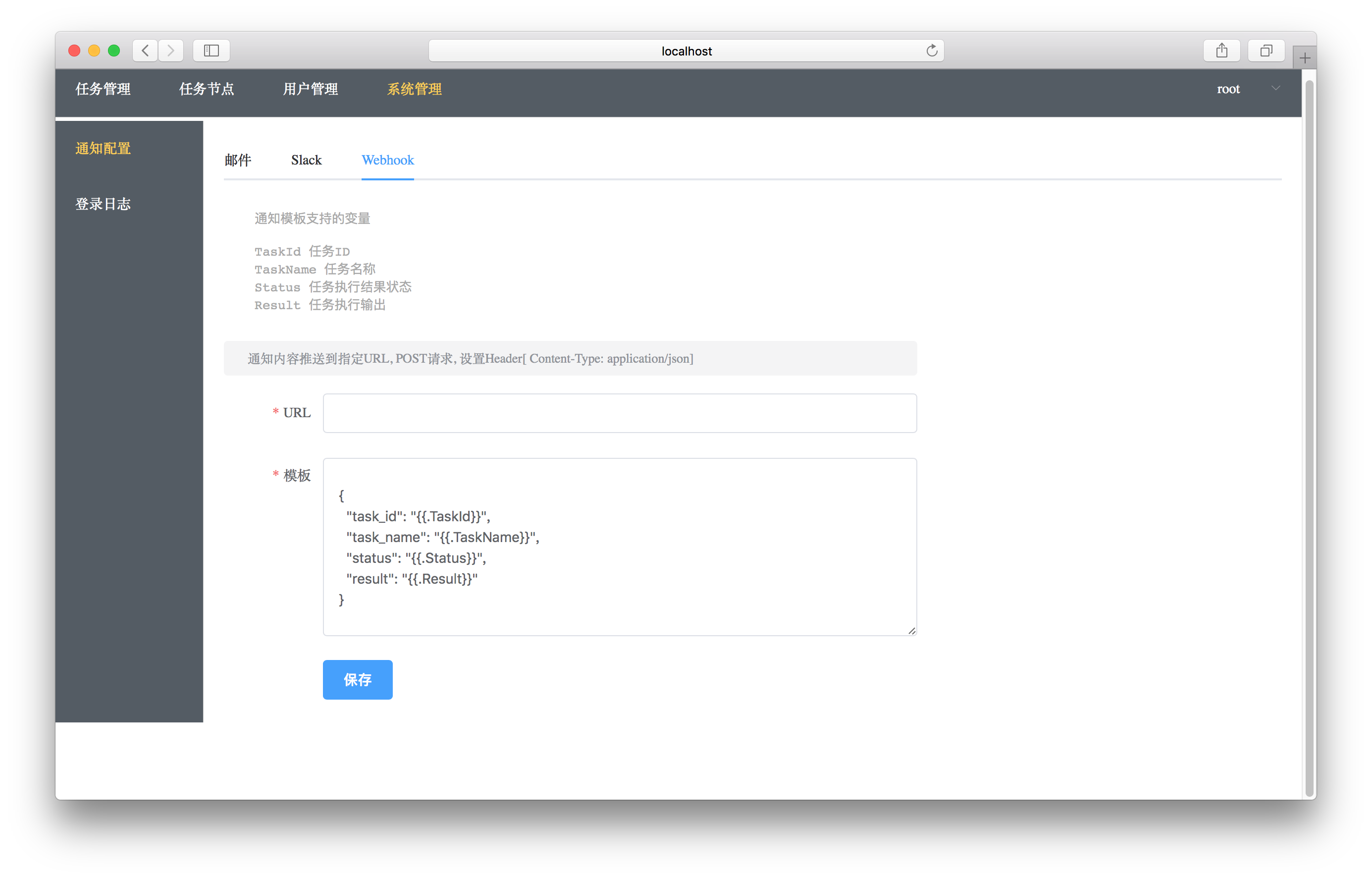
开源免费的定时任务管理系统:Gocron
Gocron:精准调度未来,你的全能定时任务管理工具!- 精选真开源,释放新价值。 概览 Gocron是github上一个开源免费的定时任务管理系统。它使用Go语言开发,是一个轻量级定时任务集中调度和管理系统,用于替代L…...

从零开始详解OpenCV车道线检测
前言 车道线检测是智能驾驶和智能交通系统中的重要组成部分,对于提高道路安全、交通效率和驾驶舒适性具有重要意义。在本篇文章中将介绍使用OpenCV进行车道线的检测 详解 导入包 import cv2 import matplotlib.pyplot as plt import numpy as np读入图像并灰度化…...

【Java代码审计】逻辑漏洞篇
【Java代码审计】逻辑漏洞篇 逻辑漏洞概述常见逻辑漏洞点 逻辑漏洞概述 逻辑漏洞一般是由于源程序自身逻辑存在缺陷,导致攻击者可以对逻辑缺陷进行深层次的利用。逻辑漏洞出现较为频繁的地方一般是登录验证逻辑、验证码校验逻辑、密码找回逻辑、权限校验逻辑以及支…...

SSH简介
SSH,全名叫Secure Shell,你可以想象它是一个超级安全的管道,专门用来远程操控电脑的。就好比你在家用遥控器指挥远处的电视换台,但比这高级多了,因为它是专门为电脑设计的。 为什么需要SSH? 在互联网的早期…...

Oracle的高级分组函数grouping和grouping_id
在网上对Oracle的高级分组函数grouping和grouping_id的讲解并不多,特别是grouping_id,还有解说有误的。经过1天研究,已经完全掌握了两个函数的作用和用法,下面简单的讲述即可明白。下面给大家分享。 GROUPING 函数 语法:grouping(表达式) 作用: GROUPING将超聚…...

SqlServer 查询数据库 和 数据表 大小的语句
–Sqlserver 查询数据库 大小 SELECT * FROM (SELECT DB_NAME(database_id) AS DatabaseName,type_desc AS FileType,name AS FileName,size * 8 / 1024/1024 AS FileSizeGBFROM sys.master_filesWHERE type 0 -- 数据文件AND state 0 -- 在线状态 ) T1 ORDER BY FileSizeG…...

特殊类的设计与单例模式
1、特殊类的设计 如何设计出一个创建出的对象只能在堆上的类?将类的默认构造函数设置为私有,再将类的拷贝构造函数设置为delete,设置静态函数GetObj,内部调用new HeapOnly,这样就只能在堆上开辟空间。 class HeapOnly…...

MySQL从入门到高级 --- 6.函数
文章目录 第六章:6.函数6.1 聚合函数6.2 数学函数6.3 字符串函数6.4 日期函数6.4.1 日期格式 6.5 控制流函数6.5.1 if逻辑判断语句6.5.2 case when语句 6.6 窗口函数6.6.1 序号函数6.6.2 开窗聚合函数6.6.3 分布函数6.6.4 前后函数6.6.5 头尾函数6.6.6 其他函数6.7 …...

Qt---信号和槽
一、信号和槽机制 所谓信号槽,实际就是观察者模式。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号(signal)。这种发出是没有目的的,类似广播。如果有对象对这个信号…...
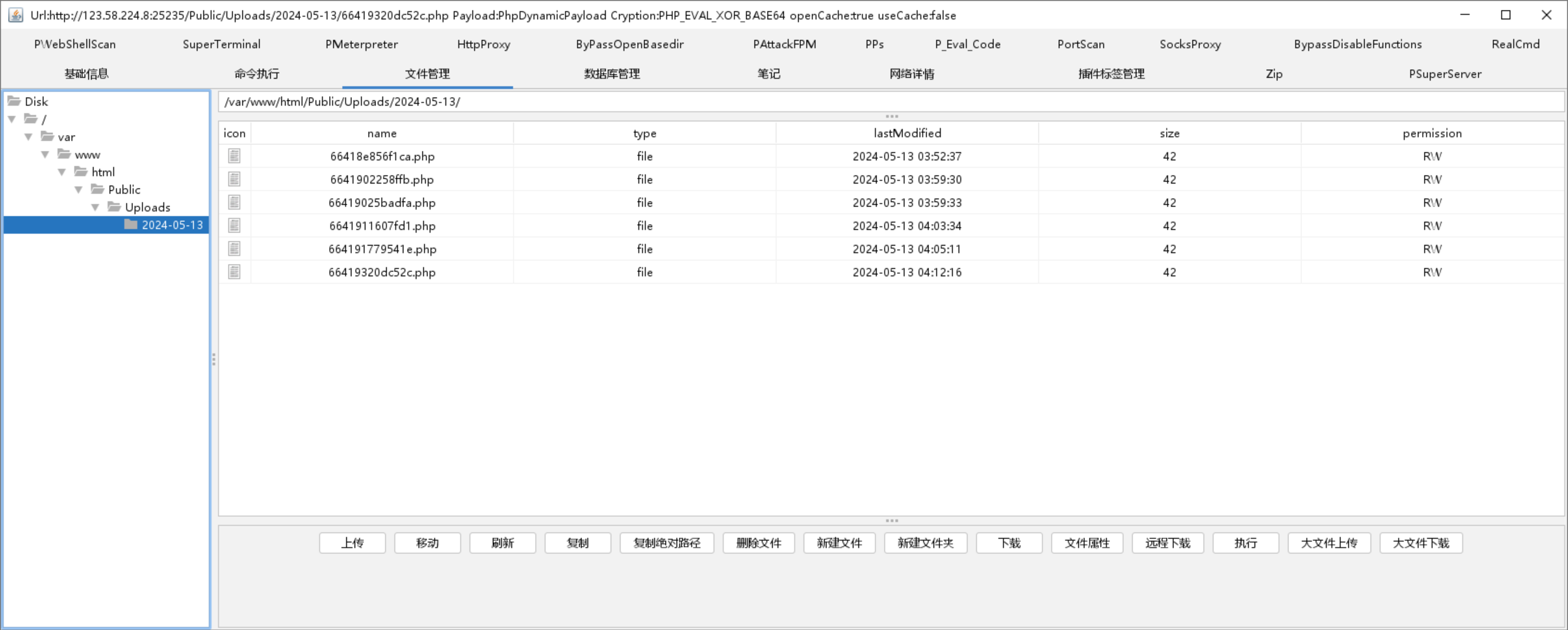
POCEXP编写—文件上传案例
POC&EXP编写—文件上传案例 1. 前言2. 文件上传案例2.1. Burp抓包2.2. 基础代码实践2.2.1. 优化代码 2.3. 整体代码2.3.1. 木马测试 1. 前言 之前的文章基本上都是一些相对来说都是验证类的或者说是一些代码执行类的,相对来说都不是太复杂,而这篇会…...
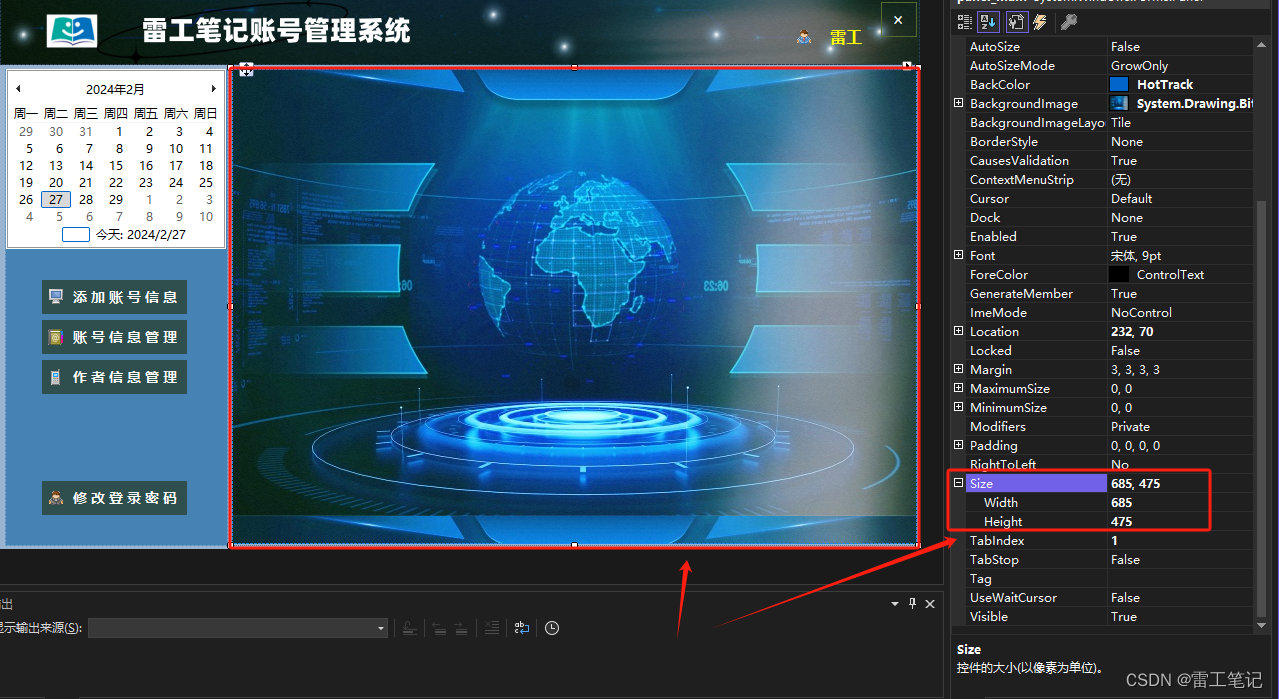
C#知识|上位机UI设计-详情窗体设计思路及流程(实例)
哈喽,你好啊,我是雷工! 上两节练习记录了登录窗体和主窗体的实现过程,本节继续练习内容窗体的实现,以下为练习笔记。 01 详情窗体效果展示: 02 添加窗体并设置属性 在之前练习项目的基础上添加一个Windows窗体,设置名称为:FrmIPManage.cs 设置窗体的边框和标题栏的外…...

目标检测——印度车辆数据集
引言 亲爱的读者们,您是否在寻找某个特定的数据集,用于研究或项目实践?欢迎您在评论区留言,或者通过公众号私信告诉我,您想要的数据集的类型主题。小编会竭尽全力为您寻找,并在找到后第一时间与您分享。 …...

Zotero Word中插入带超链接的参考文献
Zotero 超链接 找了好多原代码,最接近能实施的为: https://blog.csdn.net/weixin_47244593/article/details/129072589 但是,就是向他说的一样会报错,我修改了代码,遇见报错的地方会直接跳过不执行,事后找…...

如何在服务器上下载,解压github上的代码
在github上找到对应仓库,找到平时download zip的地方,右键它,复制链接。在远程的终端里使用wget 链接 命令就可以得到zip了。 解压方法: -c :新建打包文件 -t :查看打包文件的内容含有哪些文件名 -x &…...
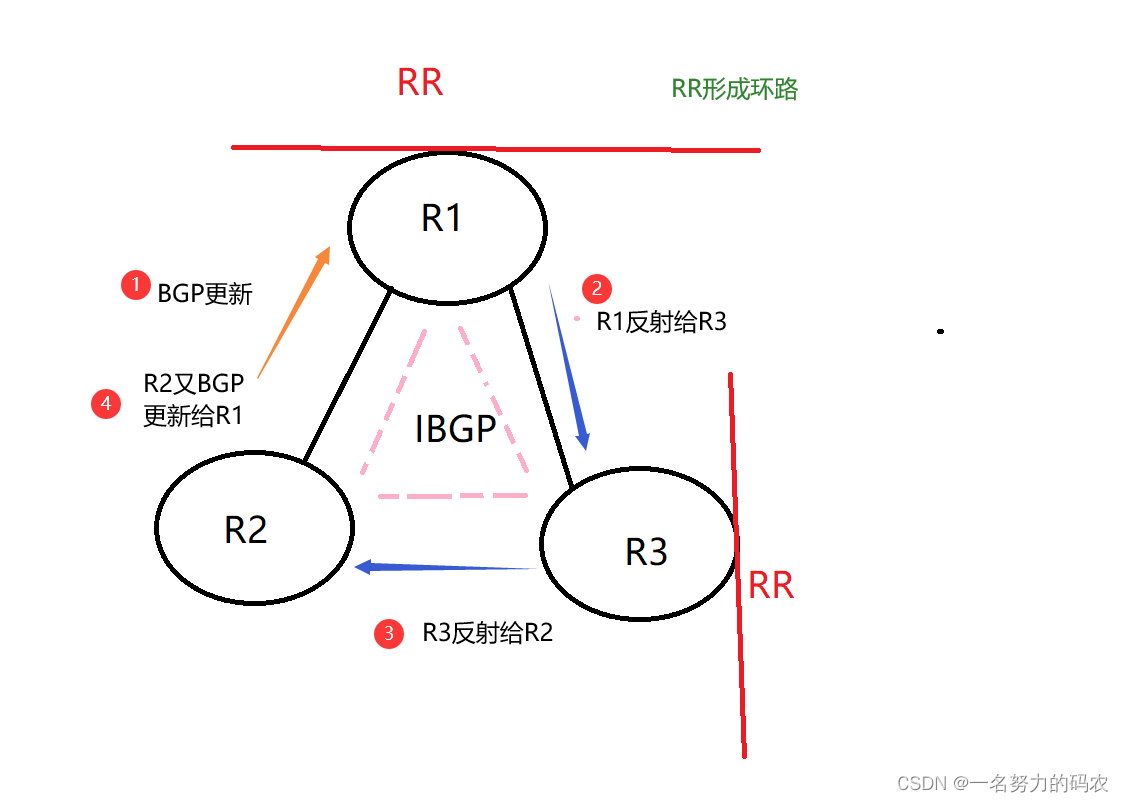
BGP学习二:BGP通告原则,BGP反射器,BGP路径属性细致讲解,新手小白无负担
目录 一.AS号 二.BGP路由生成 1.network 2.import-route引入 三.BGP通告原则 1.只发布最优且有效的路由 2.从EBGP获取的路由,会发布给所有对等体 3.水平分割原则 4.IBGP学习BGP默认不发送给EBGP,但如果也从IGP学习到了这条路由,就发…...

c语言csv文件?_?C语言中读取和写入csv文件的标准文件操作函数实现.txt
用map实现slice去重最常用也最稳妥,核心是将元素作为key存入map[interface{}]struct{},再遍历构建新slice;注意元素需可比较,结构体不可含slice/map/func,该方法保持顺序但不并发安全。用 map 实现 slice 去重最常用也…...

VisualCppRedist AIO:Windows系统运行库终极解决方案
VisualCppRedist AIO:Windows系统运行库终极解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在安装新软件或游戏时,突…...

Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生
Windows右键菜单终极清理:3个简单步骤让您的右键菜单重获新生 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 我们都有过这样的经历:在桌…...

开发上下文管理工具:原理、实现与工程实践
1. 项目概述:一个为开发者量身定制的上下文管理工具如果你和我一样,每天要在多个项目、多种技术栈、甚至多个开发环境之间反复横跳,那你一定对“上下文切换”这个词深恶痛绝。我说的不是操作系统的上下文切换,而是我们开发者大脑里…...

基于SpringBoot的共享汽车管理系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的共享汽车管理系统以解决当前共享汽车行业在资源调度效率、用户服务体验以及数据安全等方面存在的核心问题。随着城…...

网安工具系列python系列【仅供参考】:Python实战:利用fofa API高效搜索网络资产
Python实战:利用fofa API高效搜索网络资产 Python实战:利用fofa API高效搜索网络资产 1. 从零开始:为什么你需要一个自动化的资产搜索工具? 2. 动手前的准备:你的fofa账户和Python环境 2.1 获取你的fofa API凭证 2.2 搭建Python脚本环境 3. 核心代码拆解:一行行理解搜索脚…...

Rust嵌入式开发实战:开源机械爪控制库openclaw-rs架构解析与应用
1. 项目概述:当Rust遇上开源机械爪最近在逛GitHub的时候,偶然发现了一个挺有意思的项目——neul-labs/openclaw-rs。光看名字,你大概能猜到它是个用Rust语言写的、跟机械爪(Claw)相关的开源项目。没错,这正…...

Adafruit IO物联网平台:从零构建环境监测与报警系统
1. 项目概述:为什么你需要一个像Adafruit IO这样的物联网平台?如果你玩过Arduino、树莓派或者任何单片机,肯定遇到过这样的场景:费了老大劲写代码让传感器读出数据,结果这些数据要么在串口监视器里一闪而过,…...

组合模式实战:统一处理树形结构,提升代码简洁性与可维护性
1. 项目概述:从“树”到“森林”的统一管理哲学在软件开发的日常里,我们常常会遇到一种让人头疼的结构:部分与整体的层次关系。想象一下,你正在开发一个图形界面系统,里面有简单的按钮、文本框,也有复杂的面…...

Node js 后端服务如何优雅集成 Taotoken 提供的多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务如何优雅集成 Taotoken 提供的多模型能力 应用场景类,描述一个 Node.js 后端服务需要动态选择不同大模…...