Spring Cloud LoadBalancer 4.1.2
LoadBalancer位于Spring Cloud Commons 模块
Spring Cloud 提供了自己的客户端负载均衡器抽象和实现。对于负载均衡机制,添加了 ReactiveLoadBalancer 接口,并为其提供了基于Round-Robin和Random的实现。为了让实例从反应式中进行选择,使用了 ServiceInstanceListSupplier 。目前,我们支持基于服务发现的 ServiceInstanceListSupplier 实现,它使用类路径中提供的发现客户端从服务发现中检索可用实例。
可以通过将 spring.cloud.loadbalancer.enabled 的值设置为 false 来禁用 Spring Cloud LoadBalancer。
Spring Cloud LoadBalancer 入门
我们提供了一个启动器,允许您在 Spring Boot 应用程序中轻松添加 Spring Cloud LoadBalancer。为了使用它,只需将 org.springframework.cloud:spring-cloud-starter-loadbalancer 添加到构建文件中的 Spring Cloud 依赖项中。
传递您自己的 Spring Cloud LoadBalancer 配置
您还可以使用 @LoadBalancerClient 注释来传递您自己的负载均衡器客户端配置,传递负载均衡器客户端的名称和配置类,如下所示:
@Configuration
@LoadBalancerClient(//下面的value值大小写一定要和consul里面的名字一样,必须一样value = "cloud-payment-service",configuration = RestTemplateConfig.class)
public class RestTemplateConfig
{//使用的是RestTemplate@Bean@LoadBalanced //使用@LoadBalanced注解赋予RestTemplate负载均衡的能力public RestTemplate restTemplate(){return new RestTemplate();}//这里使用的是webClient@Bean@LoadBalancedpublic WebClient.Builder loadBalancedWebClientBuilder() {return WebClient.builder();}@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);}
}为了使您自己的 LoadBalancer 配置更容易,我们在 ServiceInstanceListSupplier 类中添加了 builder() 方法。
您还可以使用我们的替代预定义配置来代替默认配置,方法是将 spring.cloud.loadbalancer.configurations 属性的值设置为 zone-preference 以使用 ZonePreferenceServiceInstanceListSupplier 进行缓存或设置为 health-check 将 HealthCheckServiceInstanceListSupplier 与缓存一起使用。
您还可以通过 @LoadBalancerClients 注释传递多个配置(针对多个负载均衡器客户端),如以下示例所示:
@Configuration
@LoadBalancerClients({@LoadBalancerClient(value = "stores", configuration = StoresLoadBalancerClientConfiguration.class), @LoadBalancerClient(value = "customers", configuration = CustomersLoadBalancerClientConfiguration.class)})
public class MyConfiguration {@Bean@LoadBalancedpublic WebClient.Builder loadBalancedWebClientBuilder() {return WebClient.builder();}
}Spring Cloud LoadBalancer 生命周期
LoadBalancerLifecycle bean 提供名为 onStart(Request<RC> request) 、 onStartRequest(Request<RC> request, Response<T> lbResponse) 和 onComplete(CompletionContext<RES, T, RC> completionContext) 的回调方法,您应该实现这些方法来指定之前应该执行哪些操作以及负载均衡之后。
onStart(Request<RC> request) 将 Request 对象作为参数。它包含用于选择适当实例的数据,包括下游客户端请求和提示。 onStartRequest 还采用 Request 对象以及 Response<T> 对象作为参数。另一方面, CompletionContext 对象被提供给 onComplete(CompletionContext<RES, T, RC> completionContext) 方法。它包含 LoadBalancer Response ,包括选定的服务实例、针对该服务实例执行的请求的 Status 以及(如果可用)返回到下游客户端的响应,以及(如果发生异常)对应的 Throwable 。
Spring Cloud LoadBalancer 统计
我们提供了一个名为 MicrometerStatsLoadBalancerLifecycle 的 LoadBalancerLifecycle bean,它使用 Micrometer 提供负载平衡调用的统计信息。
为了将此 bean 添加到您的应用程序上下文中,请将 spring.cloud.loadbalancer.stats.micrometer.enabled 的值设置为 true 并让 MeterRegistry 可用(例如,通过添加 Spring将执行器启动到您的项目)。
MicrometerStatsLoadBalancerLifecycle 在 MeterRegistry 中注册以下计量表:
loadbalancer.requests.active :一个仪表,允许您监视任何服务实例当前活动请求的数量(通过标签提供的服务实例数据);
loadbalancer.requests.success :一个计时器,用于测量已结束将响应传递给底层客户端的任何负载平衡请求的执行时间;
loadbalancer.requests.failed :一个计时器,用于测量任何以异常结束的负载均衡请求的执行时间;
loadbalancer.requests.discard :一个计数器,用于测量丢弃的负载平衡请求的数量,即 LoadBalancer 尚未检索到运行请求的服务实例的请求。
配置单独的 LoadBalancerClient
可以使用不同的前缀 spring.cloud.loadbalancer.clients.<clientId>. 单独配置各个负载均衡器客户端,其中 clientId 是负载均衡器的名称。默认配置值可以在 spring.cloud.loadbalancer. 命名空间中设置,并将优先与客户端特定值合并
application.yml
spring:cloud:loadbalancer:health-check:initial-delay: 1sclients:myclient:health-check:interval: 30s上面的示例将生成一个与 initial-delay=1s 和 interval=30s 合并的运行状况检查 @ConfigurationProperties 对象。
除以下全局属性外,每个客户端配置属性适用于大多数属性:
spring.cloud.loadbalancer.enabled - 全局启用或禁用负载平衡
spring.cloud.loadbalancer.retry.enabled - 全局启用或禁用负载平衡重试。如果全局启用它,您仍然可以使用 client 前缀属性禁用特定客户端的重试,但反之则不然
spring.cloud.loadbalancer.cache.enabled - 全局启用或禁用 LoadBalancer 缓存。如果全局启用它,您仍然可以通过创建在 ServiceInstanceListSupplier 委托层次结构中不包含 CachingServiceInstanceListSupplier 的自定义配置来禁用特定客户端的缓存,但反之则不然。
spring.cloud.loadbalancer.stats.micrometer.enabled - 全局启用或禁用 LoadBalancer Micrometer 指标
[[-aot-and-native-image-support]] == AOT 和本机映像支持
从 4.0.0 开始,Spring Cloud LoadBalancer 支持 Spring AOT 转换和原生镜像。但是,要使用此功能,您需要显式定义您的 LoadBalancerClient 服务 ID。您可以通过使用 @LoadBalancerClient 注释的 value 或 name 属性或作为 spring.cloud.loadbalancer.eager-load.clients 属性的值来执行此操作。
LoadBalancer上下文的即时加载
Spring Cloud LoadBalancer 为每个服务 id 创建一个单独的 Spring 子上下文。默认情况下,每当对服务 ID 的第一个请求进行负载平衡时,这些上下文都会被延迟初始化。
您可以选择立即加载这些上下文。为此,请使用 spring.cloud.loadbalancer.eager-load.clients 属性指定要执行预加载的服务 ID,例如:
spring.cloud-loadbalancer.eager-load.clients[0]=my-first-client
spring.cloud-loadbalancer.eager-load.clients[1]=my-second-client负载均衡算法之间的切换
默认情况下使用的 ReactiveLoadBalancer 实现是 RoundRobinLoadBalancer 。要切换到不同的实现(对于选定的服务或所有服务),您可以使用自定义 LoadBalancer 配置机制。
例如,可以通过 @LoadBalancerClient 注释传递以下配置以切换为使用 RandomLoadBalancer :
public class CustomLoadBalancerConfiguration {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),name);}
}作为 @LoadBalancerClient 或 @LoadBalancerClients 配置参数传递的类不应使用 @Configuration 进行注释,或者位于组件扫描范围之外。
Spring Cloud LoadBalancer 缓存
除了每次必须选择实例时通过 DiscoveryClient 检索实例的基本 ServiceInstanceListSupplier 实现之外,我们还提供了两种缓存实现。
即为:可以先将实例缓存起来,每次直接从缓存中选取实例
如果类路径中有 com.github.ben-manes.caffeine:caffeine ,则将使用基于 Caffeine的实现。有关如何配置它的信息,请参阅 LoadBalancerCacheConfiguration 部分。
如果您使用 Caffeine,还可以通过在 spring.cloud.loadbalancer.cache.caffeine.spec 属性中传递您自己的 Caffeine 规范来覆盖 LoadBalancer 的默认 Caffeine 缓存设置。
警告:传递您自己的 Caffeine 规范将覆盖任何其他 LoadBalancerCache 设置,包括常规 LoadBalancer 缓存配置字段,例如 ttl 和 capacity 。
默认 LoadBalancer 缓存实现
如果类路径中没有 Caffeine,则将使用 spring-cloud-starter-loadbalancer 自动附带的 DefaultLoadBalancerCache 。有关如何配置它的信息,请参阅 LoadBalancerCacheConfiguration 部分。
要使用 Caffeine 而不是默认缓存,请将 com.github.ben-manes.caffeine:caffeine 依赖项添加到类路径。
负载均衡器缓存配置
您可以设置自己的 ttl 值(写入后的时间,在此之后条目应过期),表示为 Duration ,通过传递符合 Spring 的 String 将 String 引导到 Duration 转换器语法。作为 spring.cloud.loadbalancer.cache.ttl 属性的值。您还可以通过设置 spring.cloud.loadbalancer.cache.capacity 属性的值来设置自己的LoadBalancer缓存初始容量。
默认设置包括将 ttl 设置为 35 秒,默认 initialCapacity 为 256 。
您还可以通过将 spring.cloud.loadbalancer.cache.enabled 的值设置为 false 来完全禁用 loadBalancer 缓存。
注意:
尽管基本的非缓存实现对于原型设计和测试很有用,但它的效率比缓存版本低得多,因此我们建议在生产中始终使用缓存版本。如果 DiscoveryClient 实现已完成缓存,例如 EurekaDiscoveryClient ,则应禁用负载均衡器缓存以防止双重缓存。
加权负载平衡
为了启用加权负载平衡,我们提供 WeightedServiceInstanceListSupplier 。我们使用 WeightFunction 来计算每个实例的权重。默认情况下,我们尝试从元数据映射中读取并解析权重(键为 weight )。
如果元数据映射中没有指定权重,我们默认该实例的权重为1。
您可以通过将 spring.cloud.loadbalancer.configurations 的值设置为 weighted 或提供您自己的 ServiceInstanceListSupplier bean 来配置它,例如:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withWeighted().withCaching().build(context);}
}您还可以通过提供 WeightFunction 来自定义权重计算逻辑。
您可以使用此示例配置使所有实例具有随机权重:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withWeighted(instance -> ThreadLocalRandom.current().nextInt(1, 101)).withCaching().build(context);}
}基于区域的负载平衡
为了启用基于区域的负载平衡,我们提供 ZonePreferenceServiceInstanceListSupplier 。我们使用 DiscoveryClient 特定的 zone 配置(例如 eureka.instance.metadata-map.zone )来选择客户端尝试过滤可用服务实例的区域。
您还可以通过设置 spring.cloud.loadbalancer.zone 属性的值来覆盖 DiscoveryClient 特定区域设置。
目前,仅使用 Eureka Discovery 客户端来设置 LoadBalancer 区域。对于其他发现客户端,请设置 spring.cloud.loadbalancer.zone 属性。更多仪器即将推出。
为了确定检索到的 ServiceInstance 的区域,我们检查其元数据映射中 "zone" 键下的值。
ZonePreferenceServiceInstanceListSupplier 过滤检索到的实例并仅返回同一区域内的实例。如果区域是 null 或者同一区域内没有实例,则返回所有检索到的实例。
为了使用基于区域的负载平衡方法,您必须在自定义配置中实例化 ZonePreferenceServiceInstanceListSupplier bean。
我们使用委托来处理 ServiceInstanceListSupplier bean。我们建议使用 DiscoveryClientServiceInstanceListSupplier 委托,用 CachingServiceInstanceListSupplier 包装它以利用 LoadBalancer 缓存机制,然后将生成的 bean 传递到 ZonePreferenceServiceInstanceListSupplier 的构造函数中。
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withCaching().withZonePreference().build(context);}
}LoadBalancer 的实例健康检查
可以为 LoadBalancer 启用计划的运行状况检查。 HealthCheckServiceInstanceListSupplier 就是为此提供的。它定期验证委托 ServiceInstanceListSupplier 提供的实例是否仍然存在,并且只返回健康的实例,除非没有 - 然后它返回所有检索到的实例。
这种机制在使用 SimpleDiscoveryClient 时特别有用。对于由实际服务注册表支持的客户端,没有必要使用它,因为我们在查询外部 ServiceDiscovery 后已经获得了健康的实例。
如果使用任何服务发现支持的供应商,通常不需要添加此运行状况检查机制,因为我们直接从服务注册表检索实例的运行状况。
LoadBalancer 的相同实例首选项
您可以设置 LoadBalancer,使其优先选择之前选择的实例(如果该实例可用)。
为此,您需要使用 SameInstancePreferenceServiceInstanceListSupplier 。您可以通过将 spring.cloud.loadbalancer.configurations 的值设置为 same-instance-preference 或提供您自己的 ServiceInstanceListSupplier bean 来配置它 - 例如:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withSameInstancePreference().build(context);}}LoadBalancer 基于请求的粘性会话
您可以设置 LoadBalancer,使其优先使用请求 cookie 中提供的 instanceId 实例。如果请求通过 ClientRequestContext 或 ServerHttpRequestContext 传递到 LoadBalancer(SC LoadBalancer 交换过滤器函数和过滤器使用这些请求),我们目前支持此操作。
为此,您需要使用 RequestBasedStickySessionServiceInstanceListSupplier 。您可以通过将 spring.cloud.loadbalancer.configurations 的值设置为 request-based-sticky-session 或提供您自己的 ServiceInstanceListSupplier bean 来配置它 - 例如:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withRequestBasedStickySession().build(context);}}对于该功能,在转发请求之前更新选定的服务实例(如果原始请求 cookie 中的服务实例不可用,则该实例可能与原始请求 cookie 中的服务实例不同)很有用。为此,请将 spring.cloud.loadbalancer.sticky-session.add-service-instance-cookie 的值设置为 true 。
基于提示的负载平衡
我们还提供了 HintBasedServiceInstanceListSupplier ,它是基于提示的实例选择的 ServiceInstanceListSupplier 实现。
HintBasedServiceInstanceListSupplier 检查提示请求标头(默认标头名称为 X-SC-LB-Hint ,但您可以通过更改 spring.cloud.loadbalancer.hint-header-name 属性的值来修改它),并且,如果找到提示请求标头,则使用标头中传递的提示值来过滤服务实例。
如果未添加提示标头, HintBasedServiceInstanceListSupplier 将使用属性中的提示值来过滤服务实例。
如果未通过标头或属性设置提示,则返回委托提供的所有服务实例。
过滤时, HintBasedServiceInstanceListSupplier 查找在其 metadataMap 中的 hint 键下设置了匹配值的服务实例。如果没有找到匹配的实例,则返回委托提供的所有实例。
您可以使用以下示例配置来进行设置:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withCaching().withHints().build(context);}
}转换负载平衡的 HTTP 请求
您可以使用所选的 ServiceInstance 来转换负载平衡的HTTP请求。
对于 RestTemplate 和 RestClient ,您需要按如下方式实现和定义 LoadBalancerRequestTransformer :
@Bean
public LoadBalancerRequestTransformer transformer() {return new LoadBalancerRequestTransformer() {@Overridepublic HttpRequest transformRequest(HttpRequest request, ServiceInstance instance) {return new HttpRequestWrapper(request) {@Overridepublic HttpHeaders getHeaders() {HttpHeaders headers = new HttpHeaders();headers.putAll(super.getHeaders());headers.add("X-InstanceId", instance.getInstanceId());return headers;}};}};
}对于 WebClient ,您需要实现并定义 LoadBalancerClientRequestTransformer ,如下所示:
@Bean
public LoadBalancerClientRequestTransformer transformer() {return new LoadBalancerClientRequestTransformer() {@Overridepublic ClientRequest transformRequest(ClientRequest request, ServiceInstance instance) {return ClientRequest.from(request).header("X-InstanceId", instance.getInstanceId()).build();}};
}如果定义了多个转换器,它们将按照定义 Bean 的顺序应用。或者,您可以使用 LoadBalancerRequestTransformer.DEFAULT_ORDER 或 LoadBalancerClientRequestTransformer.DEFAULT_ORDER 指定顺序。
Spring Cloud LoadBalancer 子集
SubsetServiceInstanceListSupplier 实现确定性子集算法,以在 ServiceInstanceListSupplier 委托层次结构中选择有限数量的实例。
您可以通过将 spring.cloud.loadbalancer.configurations 的值设置为 subset 或提供您自己的 ServiceInstanceListSupplier bean 来配置它 - 例如:
public class CustomLoadBalancerConfiguration {@Beanpublic ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(ConfigurableApplicationContext context) {return ServiceInstanceListSupplier.builder().withDiscoveryClient().withSubset().withCaching().build(context);}}默认情况下,每个服务实例都会分配一个唯一的 instanceId ,不同的 instanceId 值通常会选择不同的子集。正常情况下,无需关注。但是,如果需要让多个实例选择相同的子集,则可以使用 spring.cloud.loadbalancer.subset.instance-id (支持占位符)进行设置。
默认情况下,子集的大小设置为 100。您也可以使用 spring.cloud.loadbalancer.subset.size 进行设置。
相关文章:

Spring Cloud LoadBalancer 4.1.2
LoadBalancer位于Spring Cloud Commons 模块 Spring Cloud 提供了自己的客户端负载均衡器抽象和实现。对于负载均衡机制,添加了 ReactiveLoadBalancer 接口,并为其提供了基于Round-Robin和Random的实现。为了让实例从反应式中进行选择,使用了…...
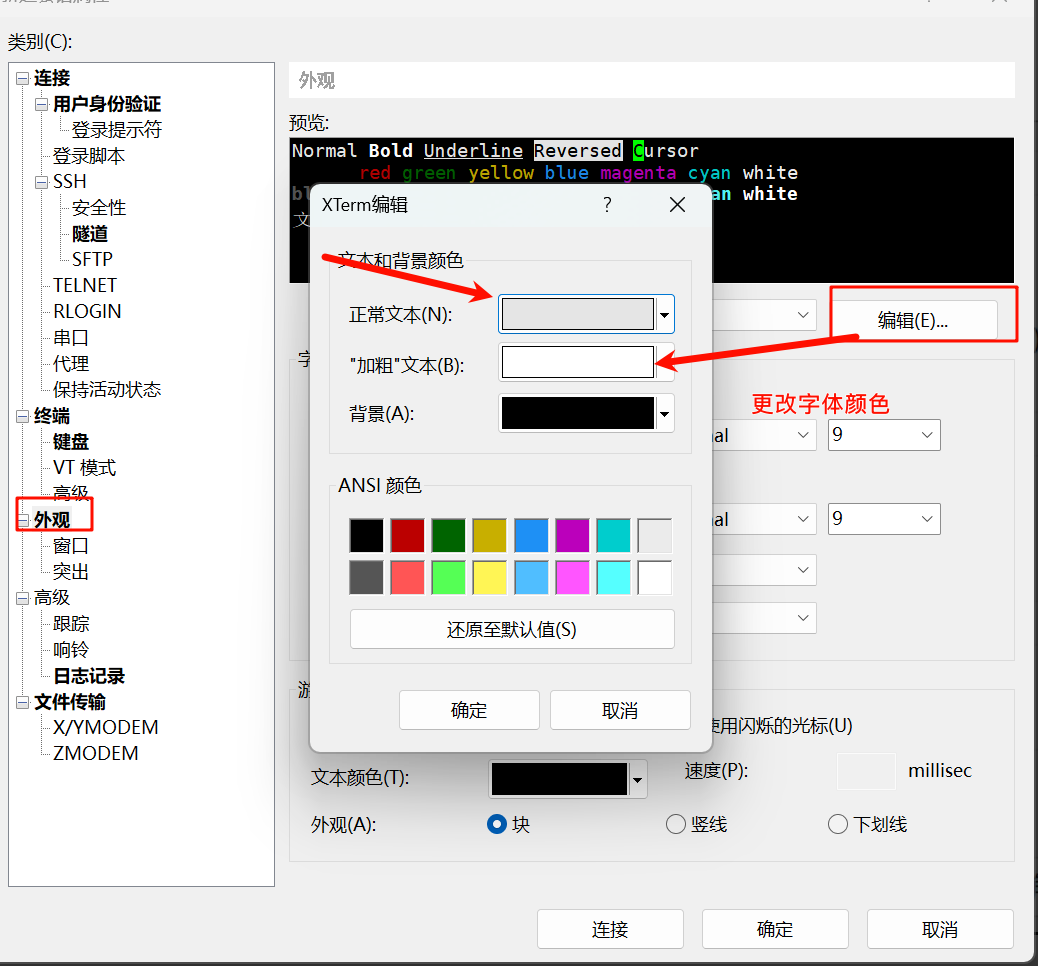
使用Xshell工具连接ubuntu-方便快捷
使用Xshell连接ubuntu 在命令行输入 “sudo apt-get install openssh-server”安装openssh-server 开启 ssh-server,在命令行输入 “service ssh start”,然后输入密码即可...

leetcode22 括号生成-组合型回溯
题目 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 解析 func generateParenthesis(n int) …...
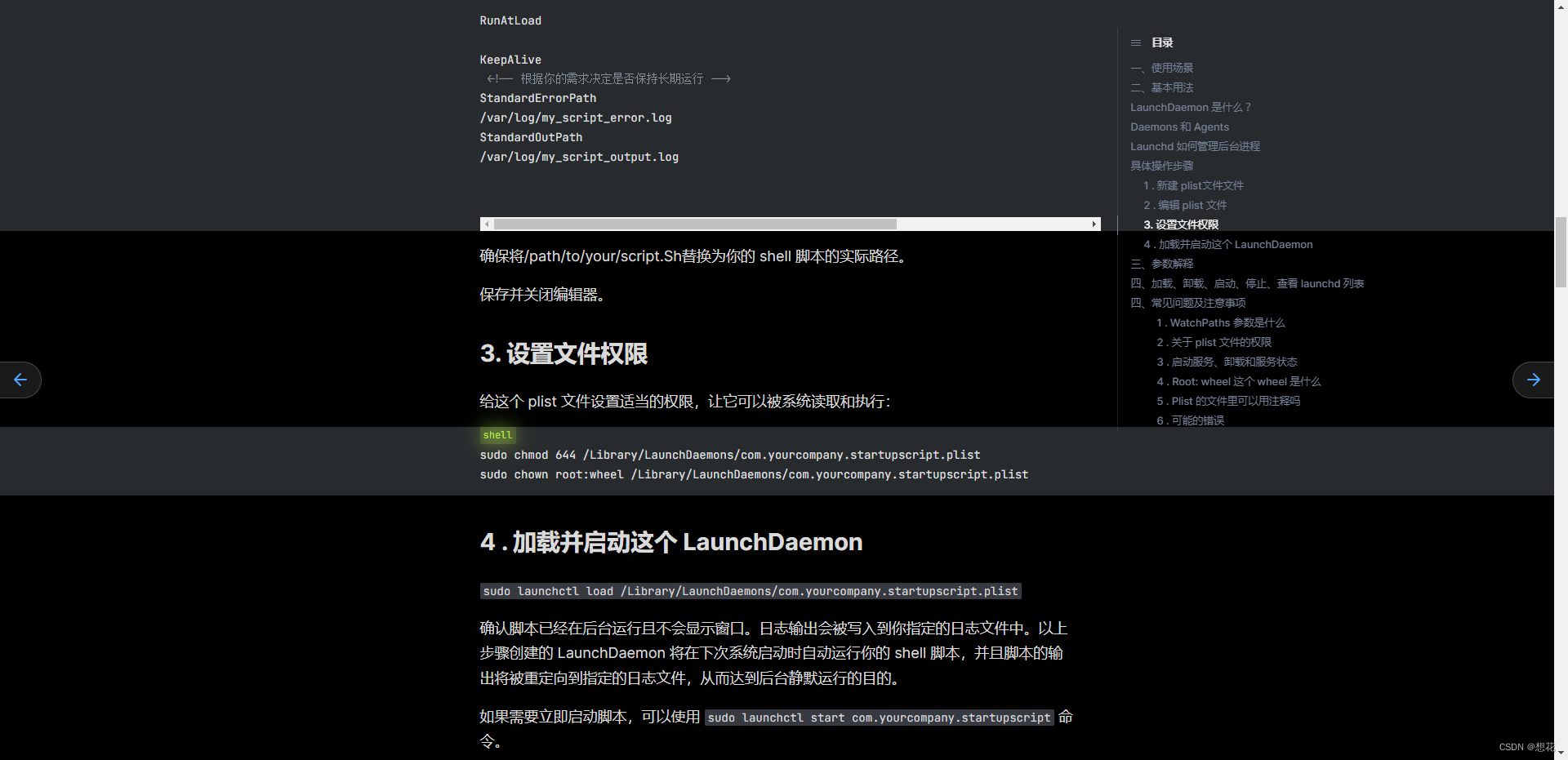
mac定时任务、自启动任务
https://quail.ink/mynotes/p/mac-startup-configuration-detailed-explanation <?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.d…...

重磅 | 国家标准《网络安全技术 零信任参考体系架构》正式发布
根据2024年4月25日国家市场监督管理总局、国家标准化管理委员会发布的中华人民共和国国家标准公告(2024年第6号),其中易安联参编的国家标准GB/T 43696-2024《网络安全技术 零信任参考体系架构》正式发布,并于2024年11月1日正式施行…...
【C++】可变参数模板简单介绍
前言 可变参数模板是C11中的新特性,它能够让我们创建可以接收可变参数的函数模板和类模板,相比C98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数是一个巨大的改进,通过系统系统推演数据的类型…...
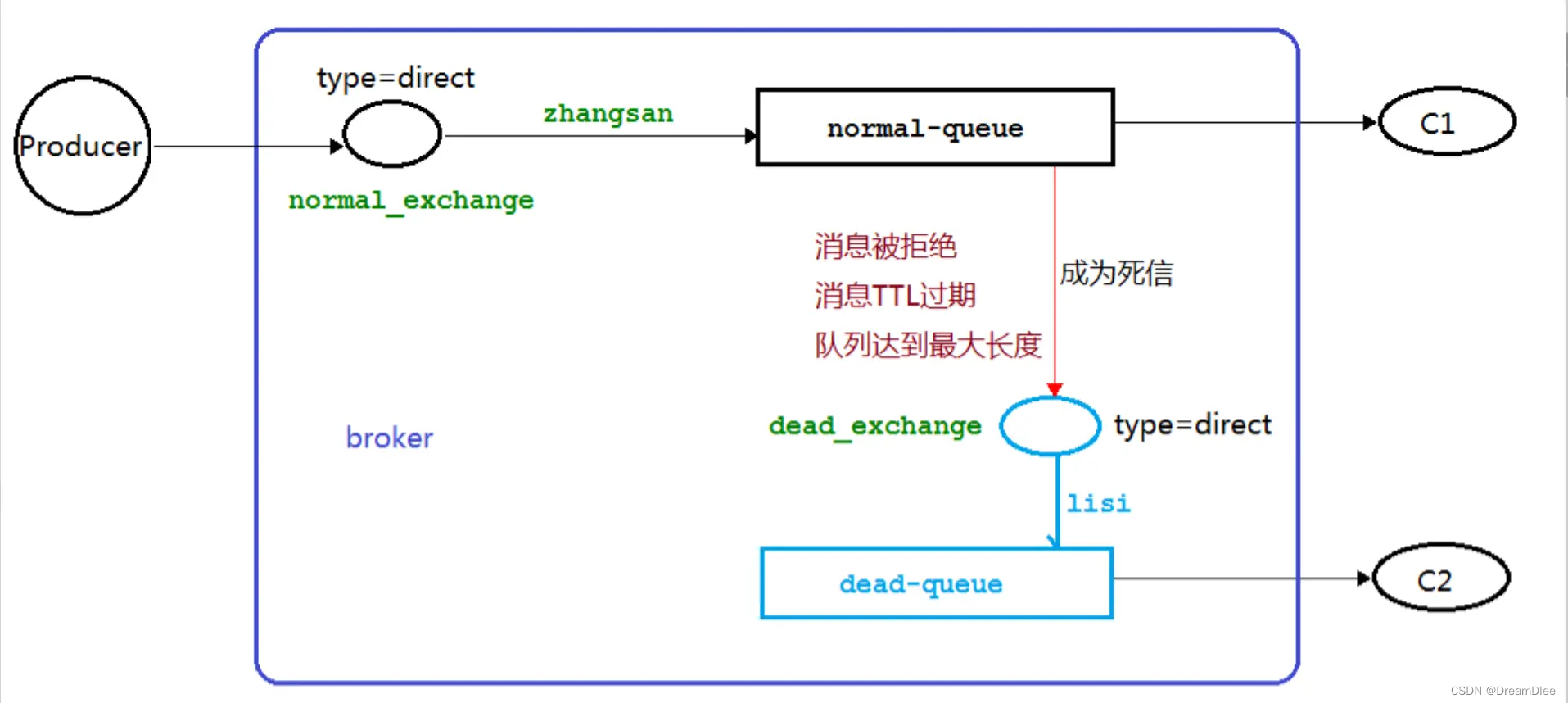
RabbitMQ--死信队列
目录 一、死信队列介绍 1.死信 2.死信的来源 2.1 TTL 2.2 死信的来源 3.死信队列 4.死信队列的用途 二、死信队列的实现 1.导入依赖 pom.xml 2.application.properties 3.配置类 4.生产者 5.业务消费者(正常消费者) 6.死信队列消费者 一、…...

微信小程序毕业设计-基于Java后端的微信小程序源码150套(附源码+数据库+演示视频+LW)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 🧡今天给大家分享150的微信小程序毕业设计,后台用Java开发,这些项目都经过精心挑选,涵盖了不同的实战主题和用例,可做毕业设…...

提前预知职业天赋!霍兰德职业兴趣测试API接口给你精准推荐
霍兰德职业倾向测验,它是美国著名职业指导专家J.霍兰德(HOLLAND)编制的,他的职业选择理论把职业分为六种不同类型,即现实型、研究型、艺术型、社会型、企业型、常规型。霍兰德认为,每个人都是这…...

js强大的运算符:??、??=
学习目标: js中强大的运算符 ?? 非空运算符 学习内容: ?? 非空运算符 注意:?? 运算符被称为非空运算符。如果第一个参数不是 null/undefined 将返回第一个参数,否则返回第二个参数 之前: 给变量设置默认值时…...
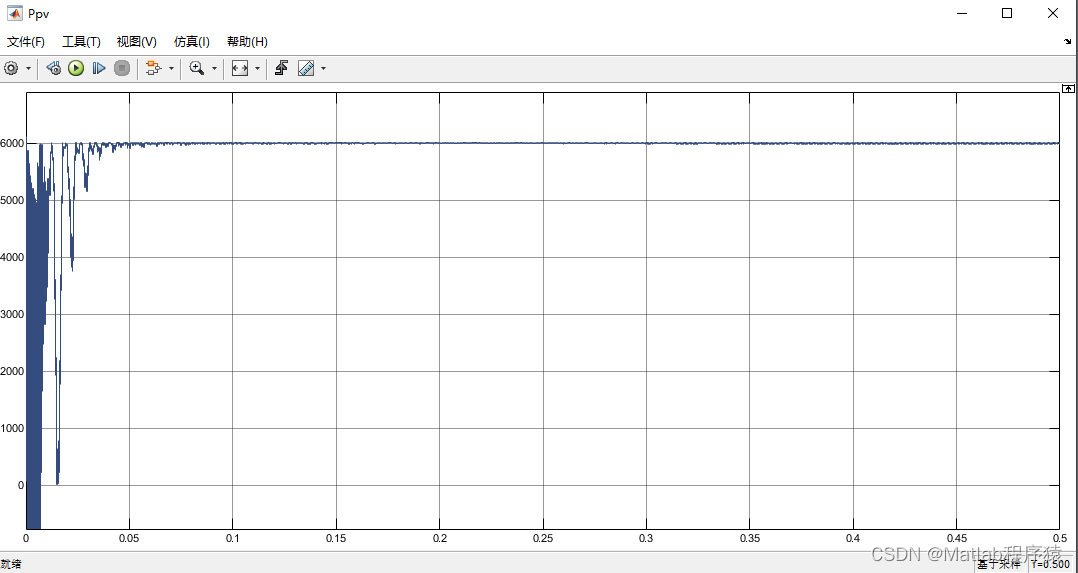
【MATLAB源码-第207期】基于matlab的单相光伏并网系统仿真,并网策略采用基于扰动观测法的MPPT模型和使用电压电流双闭环SPWM控制。
操作环境: MATLAB 2022a 1、算法描述 本文将重点分析光伏发电最大功率点跟踪(MPPT)技术和逆变器的并网控制技术,并在Simulink环境下建立模拟系统,以体现这些技术的应用与效果。文章结构如下:首先简介光伏…...

java发送请求-二次开发-get请求json
这里有2个判断 如果param为空则对url发送请求 再继续判断有值时,接口参数时json还是namevalue格式 因为json是带{,所以可以先写为param包含{}, 反之就是请求格式是url?param 请求json要带参数,所以需要使用setEntity方法, 最…...

Typescript高级: 对泛型和多态的应用, 实现Java中的ArrayList和LinkedList
ArrayList 1 ) 概述 在Java中,ArrayList是一个非常常用且强大的数据结构,它提供了动态数组的功能能够方便地添加、删除和访问元素。在TypeScript中,虽然并没有内置的ArrayList类型但我们可以通过类与接口来模拟实现ArrayList的功能 2 &…...
说明)
正则表达式常用特殊字符(元字符)说明
正则表达式中包含多种特殊字符(也称作元字符),它们具有特定的含义,用于构建复杂的匹配模式。以下是一些常用的特殊字符序列及其含义: \d - 匹配任何数字,等同于 [0-9]。\D - 匹配任何非数字字符࿰…...

使用hdc TCP模式无线方式连接OpenHarmony设备
本文将介绍如何使用hdc工具 tcp模式以无线的方式连接OpenHarmony设备。 1. usb连接方式切换为tcp模式。 将usb线将OpenHarmony设备和电脑端连接,并且将两个连接至同一个局域网。 # 执行 tmode port port-number,port-number设置为端口号。 hdc tmode …...

杂记-记一次前端打包问题解决过程
背景 若干年没更新发布的前端项目,突然来了个小需求,需求完成耗时5min,打包问题解决2小时 问题 error commander12.0.0: The engine “node” is incompatible with this module. Expected version “>18”. Got “10.22.1” 这个错误…...

维修ABB示教器主板DSQC679 3HAC 033624-001 /R机器人液晶显示屏深圳捷达工控维修
ABB 机器人示教器是工业环境中用于对机器人系统进行编程和控制的重要工具。这些手持设备允许操作员与机器人交互、输入命令并教它们特定的动作和任务。 每个 ABB 机器人示教器均专为用户友好型操作而设计,具有直观的界面和易于使用的人体工学设计。有多种型号可供选…...

原子学习笔记3——点亮 LED
一、应用层操控设备的两种方式 应用层如何操控底层硬件,同样也是通过文件 I/O 的方式来实现,设备文件便是各种硬件设备向应用层提供的一个接口,应用层通过对设备文件的 I/O 操作来操控硬件设备,譬如 LCD 显示屏、串口、按键、摄像…...

齐护K210系列教程(十八)_识别条码
识别条码 联系我们 将识别到的条形码内容打印输出并显示 测试条形码可以到如下网站得到:http://www.jsons.cn/barcode/ 4,课程资源 课程程序下载:【18条形码】 联系我们 扫码 或者点这里加群了解更多! Created by qdprobot...

K折交叉验证
训练数据稀缺,无法构成验证集。 所以我们将训练数据分为k个子集。 执行k次模型训练和验证。每次在k-1个子集上进行训练, 并在剩余的一个子集(该轮没有训练的子集)上进行验证。 最后,这k次实验结果取平均来估计训练和验…...

终极指南:如何在ComfyUI中实现AI动作迁移与姿态控制
终极指南:如何在ComfyUI中实现AI动作迁移与姿态控制 【免费下载链接】ComfyUI-MimicMotionWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-MimicMotionWrapper ComfyUI-MimicMotionWrapper是一个基于腾讯MimicMotion技术的ComfyUI插件&#…...

5分钟掌握AML模组管理器:XCOM 2模组管理终极指南
5分钟掌握AML模组管理器:XCOM 2模组管理终极指南 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/xco…...

OpenRGB终极指南:一个软件统一管理所有RGB设备,告别多软件混乱
OpenRGB终极指南:一个软件统一管理所有RGB设备,告别多软件混乱 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgramm…...

XOutput终极教程:轻松将任意手柄转换为Xbox控制器
XOutput终极教程:轻松将任意手柄转换为Xbox控制器 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput XOutput是一款强大的开源工具,能够将DirectInput设备(如各类老式游戏…...

WinUtil:一键解决Windows系统优化与软件安装的终极指南
WinUtil:一键解决Windows系统优化与软件安装的终极指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否曾为新电脑安装系统…...

三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南
三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对堆积如山的古典乐谱束手无策?那些泛黄…...

Steam创意工坊下载器深度解析:WorkshopDL架构揭秘与实战指南
Steam创意工坊下载器深度解析:WorkshopDL架构揭秘与实战指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 在跨平台游戏生态日益成熟的今天,Steam创意…...

专业级抖音资源自动化采集方案:douyin-downloader企业级部署指南
专业级抖音资源自动化采集方案:douyin-downloader企业级部署指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...

3步掌握抖音批量下载:终极免费无水印下载器完整指南
3步掌握抖音批量下载:终极免费无水印下载器完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

如何在15分钟内搭建个人游戏串流服务器:Sunshine跨平台游戏串流终极指南
如何在15分钟内搭建个人游戏串流服务器:Sunshine跨平台游戏串流终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏大作吗?…...