使用java远程提交flink任务到yarn集群
使用java远程提交flink任务到yarn集群
背景
由于业务需要,使用命令行的方式提交flink任务比较麻烦,要么将后端任务部署到大数据集群,要么弄一个提交机,感觉都不是很离线。经过一些调研,发现可以实现远程的任务发布。接下来就记录一下实现过程。这里用flink on yarn 的Application模式实现
环境准备
- 大数据集群,只要有hadoop就行
- 后端服务器,linux mac都行,windows不行
正式开始
1. 上传flink jar包到hdfs
去flink官网下载你需要的版本,我这里用的是flink-1.18.1,把flink lib目录下的jar包传到hdfs中。
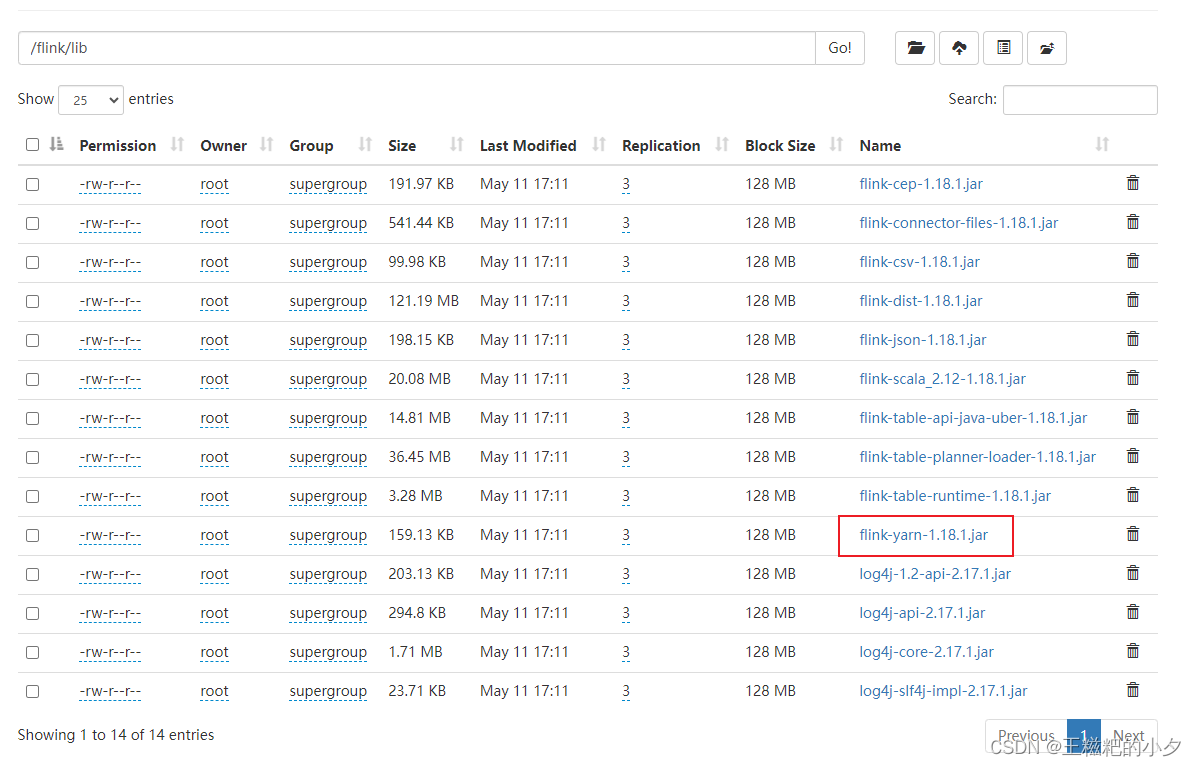
其中flink-yarn-1.18.1.jar需要大家自己去maven仓库下载。
2. 编写一段flink代码
随便写一段flink代码就行,我们目的是测试
package com.azt;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Random;
import java.util.concurrent.TimeUnit;public class WordCount {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.addSource(new SourceFunction<String>() {@Overridepublic void run(SourceContext<String> ctx) throws Exception {String[] words = {"spark", "flink", "hadoop", "hdfs", "yarn"};Random random = new Random();while (true) {ctx.collect(words[random.nextInt(words.length)]);TimeUnit.SECONDS.sleep(1);}}@Overridepublic void cancel() {}});source.print();env.execute();}
}3. 打包第二步的代码,上传到hdfs
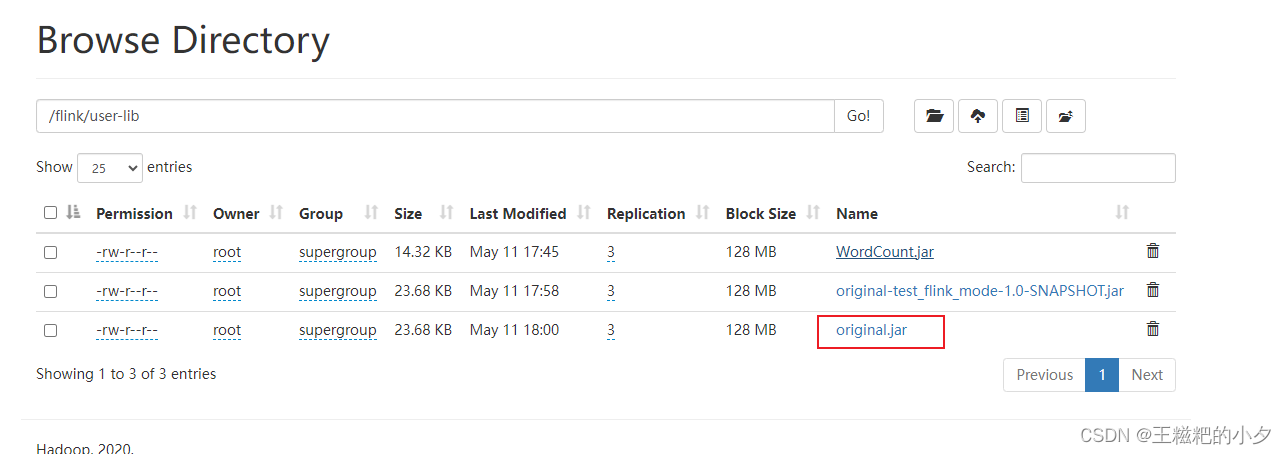
4. 拷贝配置文件
- 拷贝flink conf下的所有文件到java项目的resource中
- 拷贝hadoop配置文件到到java项目的resource中
具体看截图
5. 编写java远程提交任务的程序
这一步有个注意的地方就是,如果你跟我一样是windows电脑,那么本地用idea提交会报错;如果你是mac或者linux,那么可以直接在idea中提交任务。
package com.test;import org.apache.flink.client.deployment.ClusterDeploymentException;
import org.apache.flink.client.deployment.ClusterSpecification;
import org.apache.flink.client.deployment.application.ApplicationConfiguration;
import org.apache.flink.client.program.ClusterClient;
import org.apache.flink.client.program.ClusterClientProvider;
import org.apache.flink.configuration.*;
import org.apache.flink.runtime.client.JobStatusMessage;
import org.apache.flink.yarn.YarnClientYarnClusterInformationRetriever;
import org.apache.flink.yarn.YarnClusterDescriptor;
import org.apache.flink.yarn.YarnClusterInformationRetriever;
import org.apache.flink.yarn.configuration.YarnConfigOptions;
import org.apache.flink.yarn.configuration.YarnDeploymentTarget;import org.apache.flink.yarn.configuration.YarnLogConfigUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.yarn.api.records.ApplicationId;
import org.apache.hadoop.yarn.client.api.YarnClient;
import org.apache.hadoop.yarn.conf.YarnConfiguration;import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CompletableFuture;import static org.apache.flink.configuration.MemorySize.MemoryUnit.MEGA_BYTES;/*** @date :2021/5/12 7:16 下午*/
public class Main {public static void main(String[] args) throws Exception {///home/root/flink/lib/libSystem.setProperty("HADOOP_USER_NAME","root");
// String configurationDirectory = "C:\\project\\test_flink_mode\\src\\main\\resources\\conf";String configurationDirectory = "/export/server/flink-1.18.1/conf";org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());String flinkLibs = "hdfs://node1.itcast.cn/flink/lib";String userJarPath = "hdfs://node1.itcast.cn/flink/user-lib/original.jar";String flinkDistJar = "hdfs://node1.itcast.cn/flink/lib/flink-yarn-1.18.1.jar";YarnClient yarnClient = YarnClient.createYarnClient();YarnConfiguration yarnConfiguration = new YarnConfiguration();yarnClient.init(yarnConfiguration);yarnClient.start();YarnClusterInformationRetriever clusterInformationRetriever = YarnClientYarnClusterInformationRetriever.create(yarnClient);//获取flink的配置Configuration flinkConfiguration = GlobalConfiguration.loadConfiguration(configurationDirectory);flinkConfiguration.set(CheckpointingOptions.INCREMENTAL_CHECKPOINTS, true);flinkConfiguration.set(PipelineOptions.JARS,Collections.singletonList(userJarPath));YarnLogConfigUtil.setLogConfigFileInConfig(flinkConfiguration,configurationDirectory);Path remoteLib = new Path(flinkLibs);flinkConfiguration.set(YarnConfigOptions.PROVIDED_LIB_DIRS,Collections.singletonList(remoteLib.toString()));flinkConfiguration.set(YarnConfigOptions.FLINK_DIST_JAR,flinkDistJar);//设置为application模式flinkConfiguration.set(DeploymentOptions.TARGET,YarnDeploymentTarget.APPLICATION.getName());//yarn application nameflinkConfiguration.set(YarnConfigOptions.APPLICATION_NAME, "jobname");//设置配置,可以设置很多flinkConfiguration.set(JobManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1024",MEGA_BYTES));flinkConfiguration.set(TaskManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1024",MEGA_BYTES));flinkConfiguration.set(TaskManagerOptions.NUM_TASK_SLOTS, 4);flinkConfiguration.setInteger("parallelism.default", 4);ClusterSpecification clusterSpecification = new ClusterSpecification.ClusterSpecificationBuilder().createClusterSpecification();// 设置用户jar的参数和主类ApplicationConfiguration appConfig = new ApplicationConfiguration(args,"com.azt.WordCount");YarnClusterDescriptor yarnClusterDescriptor = new YarnClusterDescriptor(flinkConfiguration,yarnConfiguration,yarnClient,clusterInformationRetriever,true);ClusterClientProvider<ApplicationId> clusterClientProvider = null;try {clusterClientProvider = yarnClusterDescriptor.deployApplicationCluster(clusterSpecification,appConfig);} catch (ClusterDeploymentException e){e.printStackTrace();}ClusterClient<ApplicationId> clusterClient = clusterClientProvider.getClusterClient();System.out.println(clusterClient.getWebInterfaceURL());ApplicationId applicationId = clusterClient.getClusterId();System.out.println(applicationId);Collection<JobStatusMessage> jobStatusMessages = clusterClient.listJobs().get();int counts = 30;while (jobStatusMessages.size() == 0 && counts > 0) {Thread.sleep(1000);counts--;jobStatusMessages = clusterClient.listJobs().get();if (jobStatusMessages.size() > 0) {break;}}if (jobStatusMessages.size() > 0) {List<String> jids = new ArrayList<>();for (JobStatusMessage jobStatusMessage : jobStatusMessages) {jids.add(jobStatusMessage.getJobId().toHexString());}System.out.println(String.join(",",jids));}}
}由于我这里是windows电脑,所以我打包放到服务器上去运行
执行命令 :
java -cp test_flink_mode-1.0-SNAPSHOT.jar com.test.Main
不出以外的话,会打印如下日志
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
http://node2:33811
application_1715418089838_0017
6d4d6ed5277a62fc9a3a274c4f34a468
复制打印的url连接,就可以打开flink的webui了,在yarn的前端页面中也可以看到flink任务。
相关文章:
使用java远程提交flink任务到yarn集群
使用java远程提交flink任务到yarn集群 背景 由于业务需要,使用命令行的方式提交flink任务比较麻烦,要么将后端任务部署到大数据集群,要么弄一个提交机,感觉都不是很离线。经过一些调研,发现可以实现远程的任务发布。…...
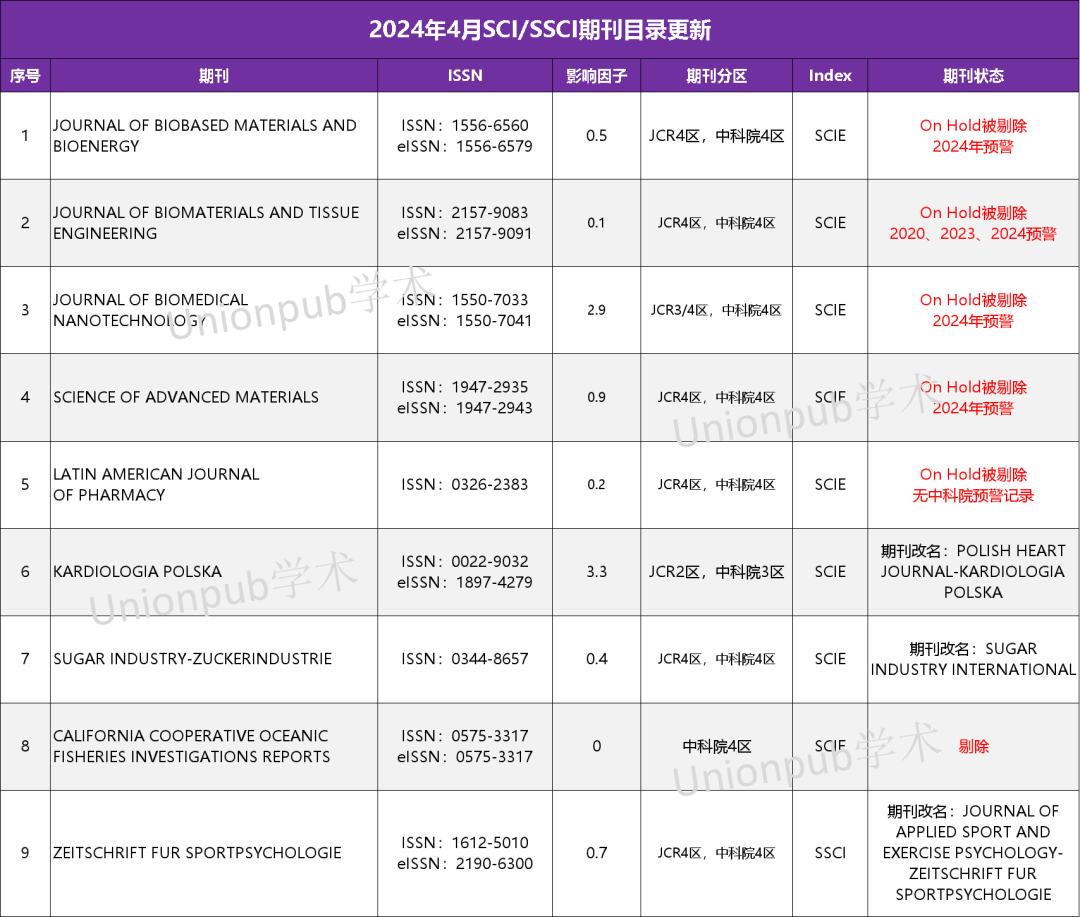
麻了!新增4.1分,CCF-C类,2区毕业神刊,被标记On Hold!
本周投稿推荐 SSCI • 2区社科类,3.0-4.0(社科均可) EI • 计算机工程类(接收广,录用极快) SCI&EI • 4区生物医学类,1.5-2.0(录用率99%) • 1区工程类&#…...

tomcat 的启动流程
tomcat 的启动流程 中 使用的Lifecycle 生命流程 。在这里还使用了设计模式中的模板模式(LifecycleBase 是一个模板类) init()方法 start() 方法 container 的处理...

YOLOv9全网最新改进系列::YOLOv9完美融合双卷积核(DualConv)来构建轻量级深度神经网络,目标检测模型有效涨点神器!!!
YOLOv9全网最新改进系列::YOLOv9完美融合双卷积核(DualConv)来构建轻量级深度神经网络,目标检测模型有效涨点神器!!! YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er …...

PCIE协议-2-事务层规范-MEM/IO/CFG request rules
2.2.7 内存、I/O和配置请求规则 以下规则适用于所有内存、I/O和配置请求。每种类型的请求还有特定的额外规则。 所有内存、I/O和配置请求除了常见的头标字段外,还包括以下字段:requester ID[15:0]和Tag[9:0],形成事务ID。Last DW BE[3:0] a…...
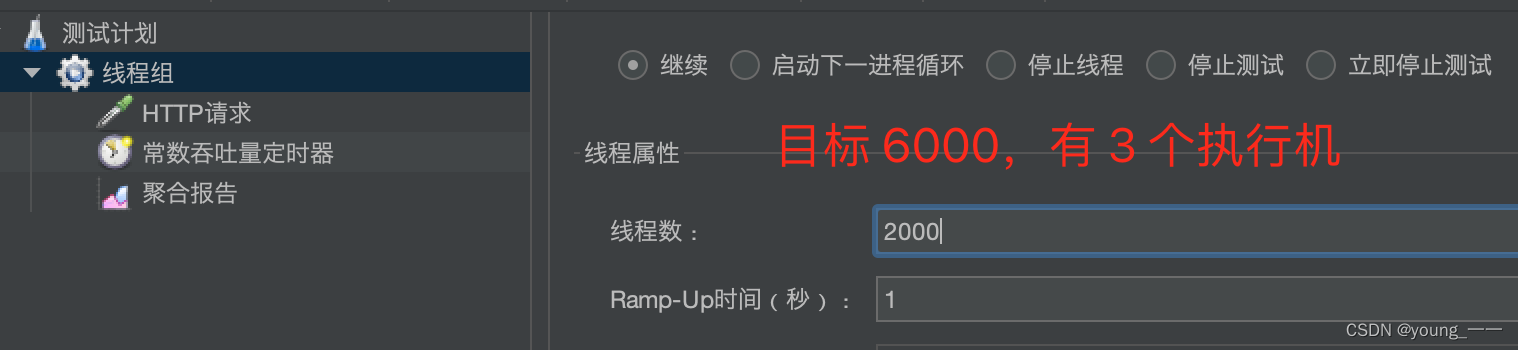
jmeter分布式集群压测
目的:通过多台机器同时运行 性能压测 脚本,模拟更好的并发压力 简单点:就是一个人(控制机controler/调度机 master)做一个项目的时候,压力有点大,会导致结果不理想,这时候找几个人&a…...

美国加州正测试ChatGPT等生成式AI,在4大部门应用
5月11日,美联社消息,美国加州政府正在测试ChatGPT等生成式AI,应用在税收和收费管理部、交通部、公共卫生部以及卫生与公众服务部4大部门。 测试时间6个月,为其提供技术支持的一共有5家公司,分别是OpenAI、Anthropic、…...
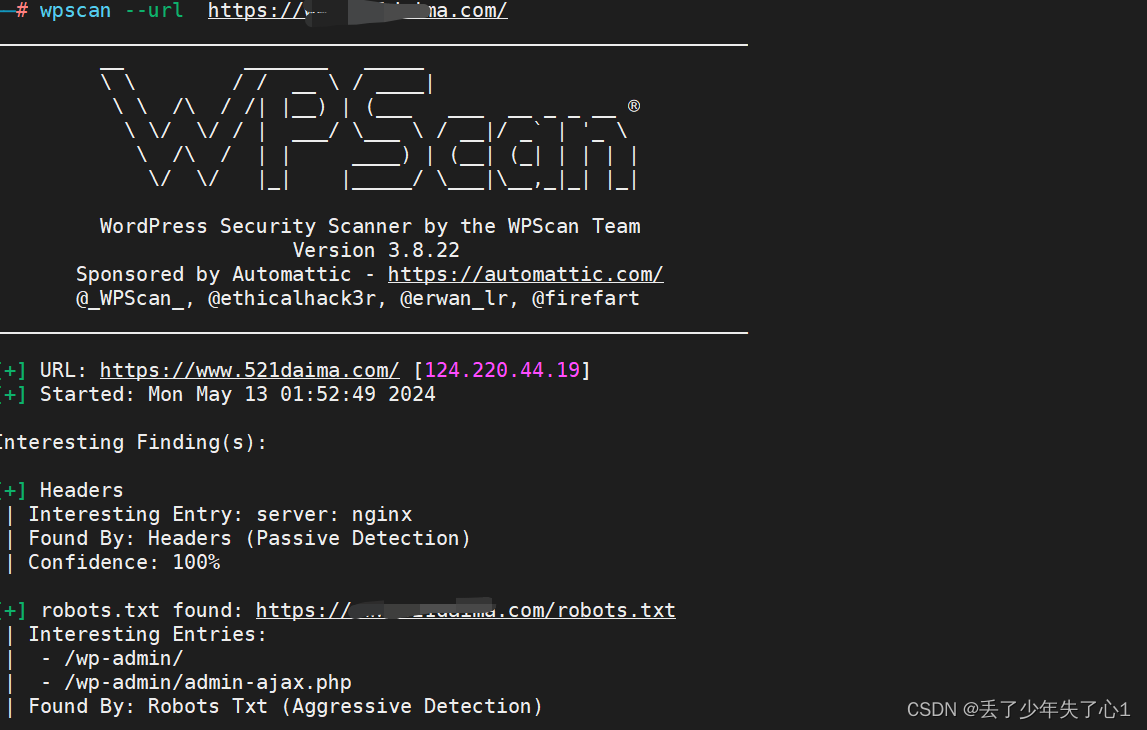
【Kali Linux工具篇】wpscan的基本介绍与使用
介绍 WPScan是Kali Linux默认自带的一款漏洞扫描工具,它采用Ruby编写,能够扫描WordPress网站中的多种安全漏洞,其中包括主题漏洞、插件漏洞和WordPress本身的漏洞。最新版本WPScan的数据库中包含超过18000种插件漏洞和2600种主题漏洞&#x…...

C#算法之计数排序
算法释义:计数排序是一种非基于比较的排序算法,它不依赖于比较操作来确定元素的顺序,而是通过键值索引直接确定元素的输出位置。计数排序适用于一定范围内的整数排序。为什么说是一定范围之内呢?原因如下:计数排序的复…...
EasyExcel简单使用
EasyExcel简单使用 之前一直用的Apache POI来做数据的导入导出,但听说阿里的EasyExcel也拥有POI的功能的同时,在处理大数据量的导入导出的时候性能上比POI更好,所以就来尝试使用一下 导入Maven依赖: <dependency><…...

Notes客户端中的漫游功能
大家好,才是真的好。 故事,首先是从一个小图标开始的,很多人问我Domino公共通讯录中,个人文档前面有一个绿色小球图标,这是什么意思? 我的答案:这是Notes客户端中的漫游功能。 说到漫游&…...

为什么要内存对齐?
首先,我们介绍一下结构体内存对齐的规则: 1.第一个成员在与结构体偏移量为0的地址处。 2.其他成员变量要对其到某个数字(对齐数)的整数倍的地址处。 注:对齐数编译器默认的一个对齐数与该成员大小的较小值ÿ…...
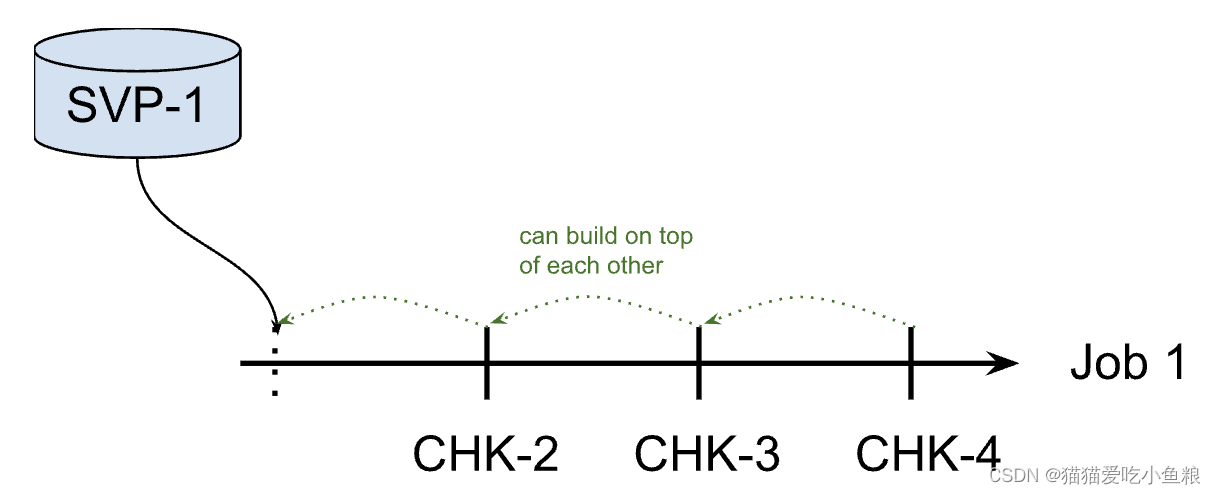
23、Flink 的 Savepoints 详解
Savepoints 1.什么是 Savepoints Savepoint 是依据 Flink checkpointing 机制所创建的流作业执行状态的镜像,可以使用 Savepoint 进行 Flink 作业的停止、重启或更新。 Savepoint 由两部分组成:稳定存储(例如 HDFS,S3ÿ…...
【Unity】Unity项目转抖音小游戏(二)云数据库和云函数
业务需求,开始接触一下抖音小游戏相关的内容,开发过程中记录一下流程。 抖音云官方文档:https://developer.open-douyin.com/docs/resource/zh-CN/developer/tools/cloud/develop-guide/cloud-function-debug 1.开通抖音云环境 抖音云地址&a…...

SpringBoot集成jasypt对yml文件指定参数加密并自定义@bean隐藏密钥
1、查看SpringBoot和jasypt对应版本。 Jasypt 1.9.x 通常与 Spring Boot 1.5.x 相对应。 Jasypt 2.1.x 通常与 Spring Boot 2.0.x 相对应。 Jasypt 3.x 通常与 Spring Boot 2.1.x相对应。 2、引入maven <dependency><groupId>com.github.ulisesbocchio</groupI…...
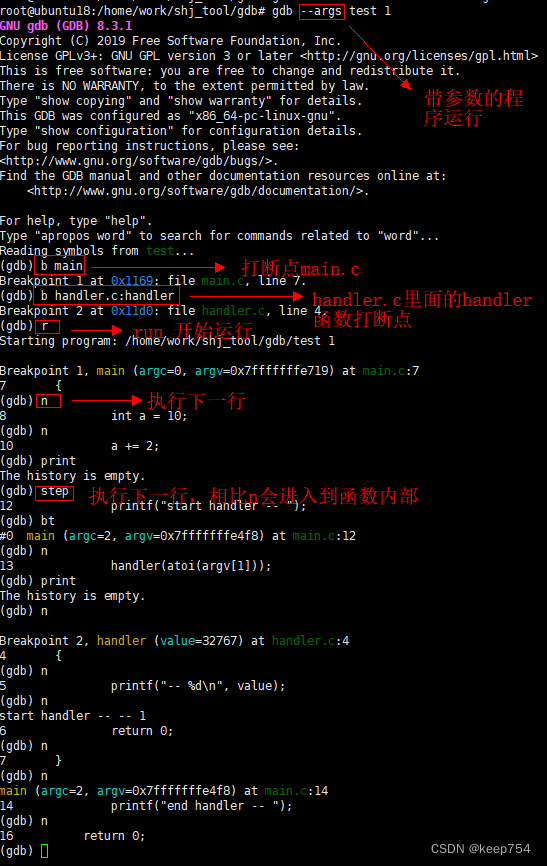
GDB的使用
即目标机直接使用GDB调试 源码安装: Index of /gnu/gdb 或者 wget https://ftp.gnu.org/gnu/gdb/gdb-8.3.1.tar.gz ./configure make main install 编译报错解决方法: 解决编译安装gdb-10.1 unistd.h:663:3: error: #error “Please include con…...

Linux处理用户输入
目录 一、传递参数 1.1 读取参数 1.2 读取脚本名 二、跟踪参数 三、移动参数 四、处理选项 4.1 查找选项 4.1.1 处理简单选项 4.1.2 分离参数和选项 4.1.3 处理含值的选项 五、选项标准化 5.1 使用 getopt 命令 5.1.1 命令格式 5.1.2 在脚本中使用getopt 5.2 使用…...

【代码笔记】高并发场景下问题解决思路
高并发指的是在单位时间内,瞬时流量激增,系统需要同时处理大量并行的请求或操作。这种情况通常出现在面向大量用户或服务的分布式系统中,尤其是当用户请求高度集中时,比如促销活动、秒杀活动、注册抢课、热点事件、定时任务调度等…...

【Docker系列】Linux部署Docker Compose
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

基于SSM的文化遗产的保护与旅游开发系统(有报告)。Javaee项目。ssm项目。
演示视频: 基于SSM的文化遗产的保护与旅游开发系统(有报告)。Javaee项目。ssm项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,…...
)
别再硬啃旧SDK了!用Unity 2021.3 + OpenXR搞定Vive Pro Eye眼动数据采集(附避坑指南)
现代VR眼动追踪开发指南:Unity 2021.3与OpenXR实战 在VR技术快速迭代的今天,眼动追踪已成为提升沉浸感的关键技术。Vive Pro Eye作为行业标杆设备,其开发方式正经历从私有SDK到开放标准的重大转变。本文将带你跨越技术代沟,掌握基…...

从‘乱码’到‘可读’:我是如何用LayoutLMv3和Tesseract拯救一份无法复制的PDF合同的
从‘乱码’到‘可读’:我是如何用LayoutLMv3和Tesseract拯救一份无法复制的PDF合同的 那天下午,法务部的同事急匆匆地推开了我的办公室门,手里拿着一份标着"紧急"的PDF合同。"这份合同扫描件里的文字全都无法选中,…...

硬件工程选型解析:钡特电源VB60-24S12LD与金升阳URB2412LD-60WR3同属工业高可靠
在工业硬件研发、设备调试与批量量产工作中,大功率工业DC-DC模块的工况适配性、结构规范性与运行稳定性,是硬件研发工程师重点核查的核心指标,直接决定工控设备、电力终端、智能装备的长期运行可靠性。在60W级国产直流电源模块品类中…...

如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南
如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南 【免费下载链接】nunif Misc; latest version of waifu2x; 2D video to stereo 3D video conversion 项目地址: https://gitcode.com/gh_mirrors/nu/nunif 你是否曾想过在VR头显中观看你的电脑…...

AI大模型核心:Prompt、Tool、Skill、Agent,一篇彻底搞懂它们之间的区别与实战应用!
如果你最近在用AI大模型,一定会被这四个词绕晕:Prompt、Tool、Skill、Agent。 这篇文章用最通俗的语言,一次性讲透四个概念的本质、核心区别。一、讲清楚每个概念到底是什么? 1、Prompt 本质上是人类给大模型的单次文本指令&#…...

野兽派不是乱来:拆解Midjourney V6中色彩暴力、笔触失序与构图反叛的5层参数逻辑
更多请点击: https://kaifayun.com 第一章:野兽派不是乱来:Midjourney V6的美学暴动宣言 Midjourney V6 不是一次平滑迭代,而是一场蓄谋已久的视觉政变——它将“语义精确性”与“风格不可预测性”焊死在同一张提示词底片上。当 …...

GBase 8a数据库实际支持的索引类型详解
本文继续说明为什么列存不依赖传统 B-Tree 索引,南大通用GBase 8a数据库(gbase database) 实际使用了哪些替代机制,以及怎样在列存环境下做到真正有效的查询加速。虽然传统 B-Tree 索引在列存引擎上效果有限,GBase 8a数据库仍然支…...

使用电脑快速测试 PROFINET 设备通讯
Anybus PROFINET主站仿真工具介绍日常对客户进行技术支持的时候,我们发现工厂自动化领域的不同部门不同职能的人员对于工业通讯设备都面临着一些使用的困难,例如设备研发人员,尤其是嵌入式研发部门,对于工厂自动化使用的工业通讯协…...

如何用openpilot升级你的驾驶体验:让300+车型秒变智能座驾
如何用openpilot升级你的驾驶体验:让300车型秒变智能座驾 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tren…...

CMake基础:常用内部变量和环境变量的引用
目录 1.常用 CMake 变量 1.1.编译与构建控制 1.2.路径与目录变量 1.3.项目信息变量 1.4.系统与平台变量 1.5.工具链与交叉编译 1.6.测试与安装变量 1.7.高级编译选项 2.常用环境变量 2.1.编译器与工具链 2.2.依赖库路径 2.3.CMake 专用环境变量 2.4.系统环境变量P…...