多模态大语言模型的演化:综述
24年2月意大利三所研究大学和机构的论文“The ®Evolution of Multimodal Large Language Models: A Survey”。
连接文本和视觉模态在生成智能中起着至关重要的作用。由于这个原因,在大语言模型成功的启发下,大量的研究工作被投入到多模态大语言模型(MLLMs)的开发中。这些模型可以无缝集成视觉和文本模态,包括输入和输出,同时提供基于对话的界面和指令跟随功能。本文全面回顾最近基于视觉的MLLM,分析了它们的架构选择、多模态对齐策略和训练技术。还对这些模型进行了广泛任务的详细分析,包括视觉基础、图像生成和编辑、视觉理解和特定领域的应用。此外,汇编和描述了训练数据集和评估基准,并在性能和计算要求方面对现有模型进行了比较。
如图所示多模态大语言模型(MLLMs)的通用架构,由视觉编码器、语言模型和将视觉输入连接到文本空间的适配器模块组成。
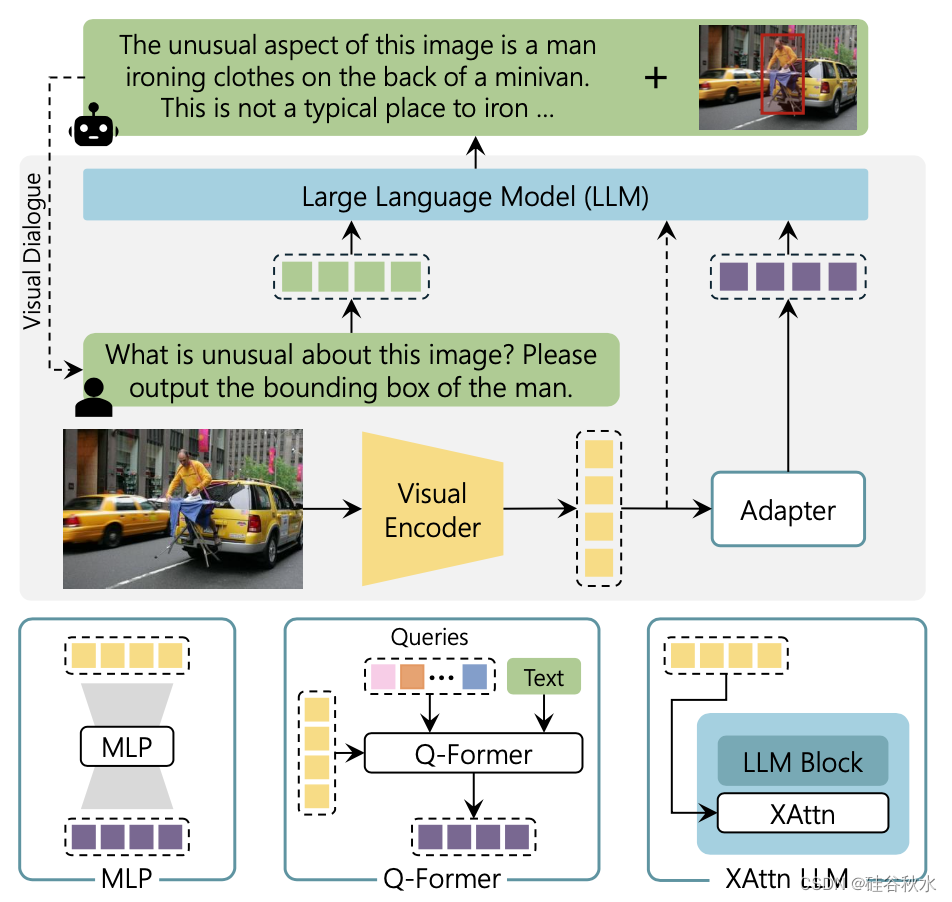
MLLM的发展与LLM的发展路径相似,Flamingo(Alayrac2022)第一个在视觉语言领域探索大规模上下文学习。然后,视觉指令调整(Liu 2023e)迅速成为多模态领域最突出的训练范式,以及使用PEFT技术微调LLM。任何MLLM至少包含三个组件:用作与用户接口的LLM主干、一个(或多个)视觉编码器和一个或多个视觉到语言适配器模块。LLM主干的流行选择通常属于LLaMA家族(Touvron 2023a/b),因为它们的权重是可以自由访问的,它们仅根据公共数据进行训练,并且它们拥有不同的大小以适应各种用例。此外,它们的衍生版本也很受欢迎,如Alpaca(Taori2023)和Vicuna(Chiang2022)。前者根据使用GPT-3编写的指令微调LLaMA,而后者利用与ChatGPT的用户共享对话(OpenAI,2022)。替代方案是OPT(Zhang2022b)、Magneto(Wang2023b)、MPT(MosaicML,2023),以及T5(Raffel2020)的指令调优(Chung2022)或多种语言(Xue2020)。
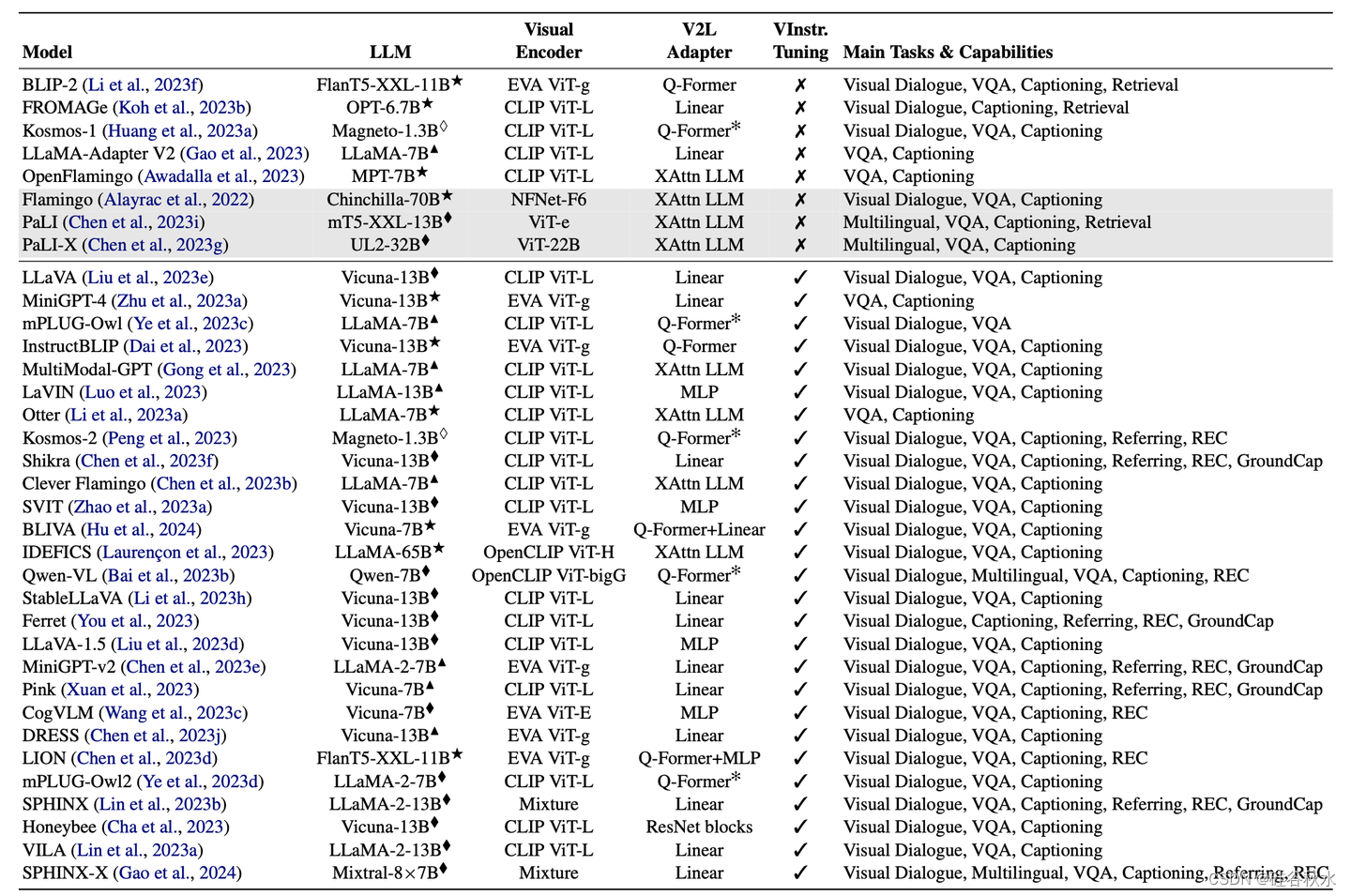
下表是用于视觉到语言任务的多面手MLLMs摘要。对于每个模型,在其最佳配置中使用的LLM (♢: LLM训练从无到有;♦: LLM微调;▲: LLM与PEFT技术的微调;*:冷冻LLM)。这个✻ 标记表示所报告的视觉到语言适配器的变型,而灰色表示模型不公开。
MLLM的视觉任务
标准MLLM可以处理视觉理解任务,如VQA、字幕和多回合对话。然而,最近在处理更细粒度的视觉任务方面出现了兴趣,例如视觉落地和图像生成。
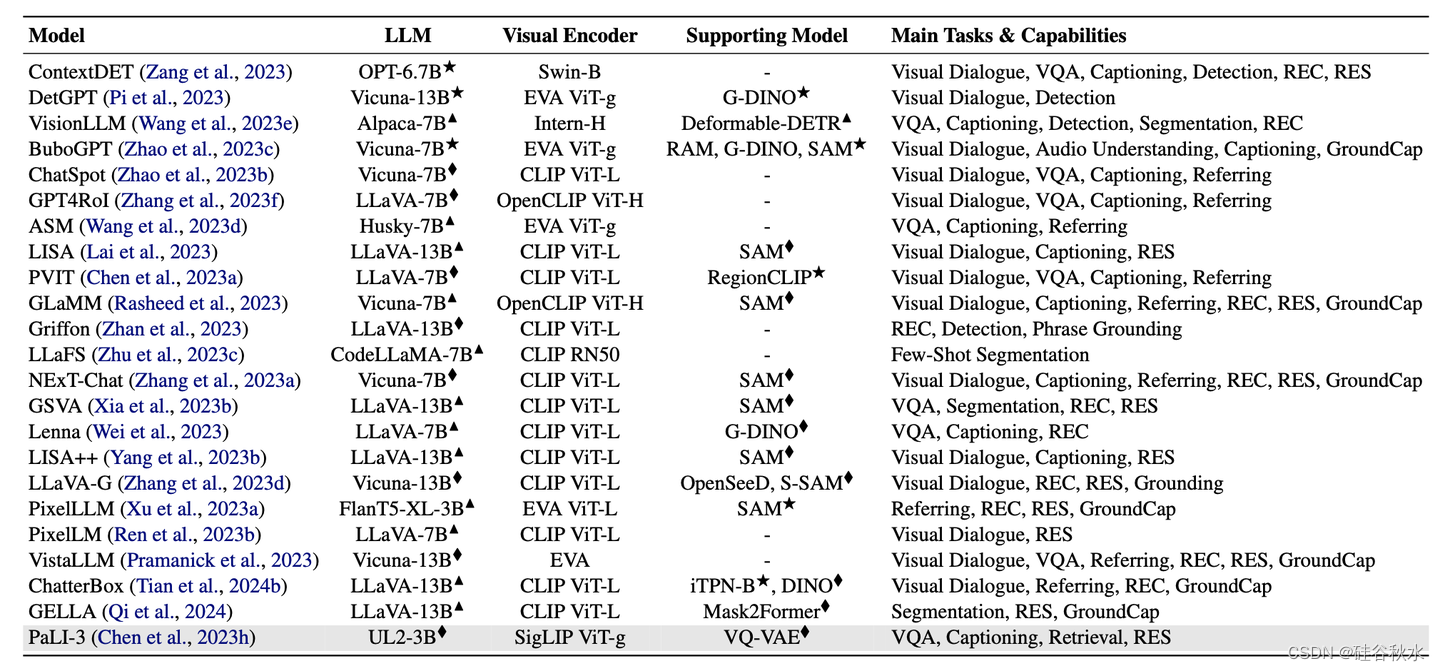
下表所示为MLLMs的总结,包括专门为视觉落地和区块级(region-level)理解而设计的组件。对于每个模型,其最佳配置中使用的LLM,在某些情况下使用预训练MLLM的权重初始化,以及用于执行任务的任何支持模型 (♦: 微调;▲: 使用PEFT技术进行微调;*:冻结)。灰色表示型号不公开。
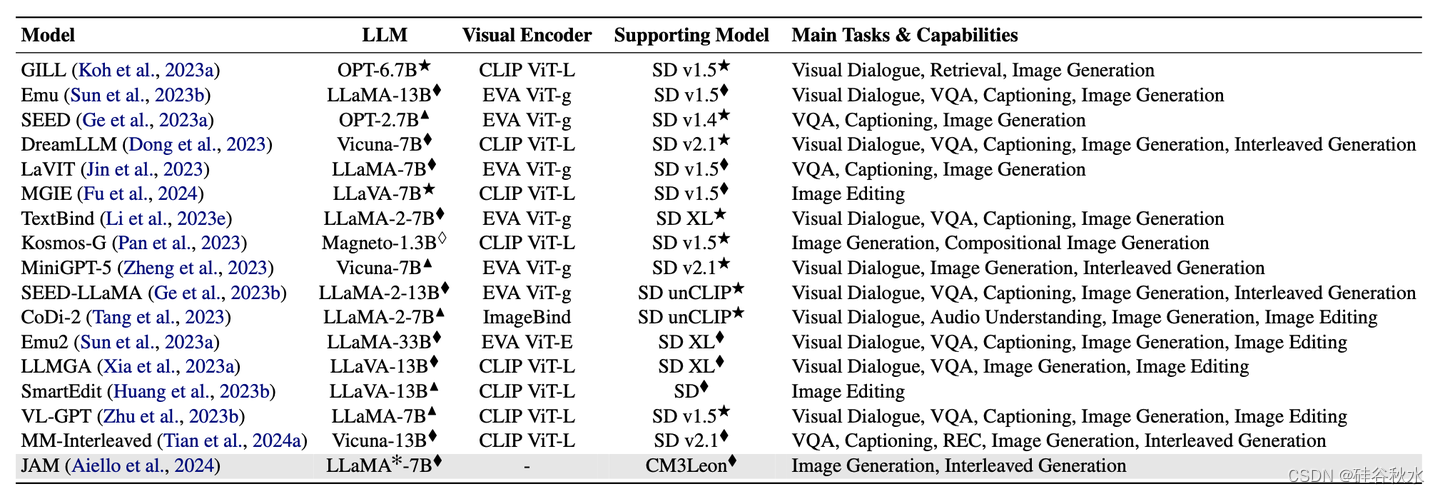
下表是MLLMs概述,其中包含专门为图像生成和编辑设计的组件。对于每个模型,LLM (✻: LLM变型),在某些情况下使用预训练MLLM的权重初始化,以及用于执行任务的任何支持模型 (♢: 从头开始训练;♦: 微调;▲: 使用PEFT技术进行微调;*:冻结)。灰色表示型号不公开。
视觉-语言适配器
来自不同模态的输入的同时存在,强调了一个能够在这些单模态域内描绘潜在对应关系模块的必要性。这些模块被称为“适配器”,旨在促进视觉域和文本域之间的互操作性。在常见的MLLMs中使用了一系列不同的适配器,从基本架构(如线性层或MLP)到高级方法(如基于Transformer的解决方案,以Q-Former模型为例),以及添加到LLM的条件交叉注意层。
线性和MLP投影。将视觉输入投影到文本嵌入中的最直接的方法包括学习线性映射,该线性映射将视觉特征转换为与文本对应物相同的维度。一些方法,如LLaMA Adapter(Gao2023)和FROMAGe(Koh2023b),仅使用单个线性层来执行多模态连接,而LLaVA-1.5(Liu2023d)采用了两层MLP,显示出改进的多模态能力。尽管线性投影在早期MLLMs中被广泛采用,但最近即使在对视觉输入有更高级理解的方法中,线性投影的使用也被证明是非常有效的(Chen2023f;Lin2023a;Wang2023c;You2023;Zhao2023a)。因此,这是一种简单而有效的将视觉特征与文本对应特征对齐的技术。另一种方法(Cha2023)提出用卷积层代替线性层,证明了适度的改进。
Q-Former。它是在BLIP-2中提出的基于Transformer模型(Li2023f),然后在其他几种方法中使用(Chen2023d;Dai2023;Hu2024)。它的特点是其适应性强的架构,由两个共享相互自注意层的Transformer块组成,有助于视觉和文本表示之间的对齐过程。它涉及一组可学习的查询,这些查询在自注意层内交互,并通过交叉注意机制与视觉特征交互。文本和视觉元素通过模块内的共享自注意进行交流。
从Q-Former中汲取灵感,推出了各种修改版本。在这方面,mPLUG-Owl模型(Ye2023c,d)简化了Q-Former架构,并提出了一种视觉抽象器组件,该组件将视觉信息压缩为不同的可学习token来操作,导出语义更丰富的视觉表示。在同一条线上,Qwen VL(Bai 2023b)使用单层交叉注意模块压缩视觉特征,该模块具有也包含2D位置编码的可学习查询。
添加的交叉注意层。这种方法已经在Flamingo(Alayrac2022)中提出,在LLM的现有预训练层之间集成了密集的交叉注意块。新添加的层通常与零-初始化tanh-门控机制相结合,以确保在初始化时,条件模型充当其原始版本。额外的交叉注意层的使用要求从头开始训练它们,与其他替代方案相比,增加了可训练参数的数量。为了降低计算复杂性,该策略通常与基于Perceiver的组件配对(Jaegle 2021),该组件在视觉tokens被馈送到LLM之前减少视觉tokens的数量。自引入以来,几个模型(Awadalla2023;Chen2023b;Laurençon2024;Li2023a)使用该技术将视觉模态与底层LLM连接起来,显示出增强的训练稳定性和改进的性能。
多模态的训练
从预训练的LLM开始,MLLM的训练经历了一个单步或两步的过程。在这两种情况下,都使用标准的交叉熵损失来预测下一个token,作为自回归目标。
单步训练。LLaMA Adapter(Gao 2023)探索了这种可能性,它引入了额外的可训练参数来封装视觉知识,同时管理纯文本指令学习。为了实现这一点,模型使用图像-文本对和指令,在单独的参数上进行联合训练。同时,(Koh 2023b)中提出的模型将两个对比损失合并用于图像文本检索来适应最终损失函数。在训练过程中,仅更新三个线性层。在另一条线上,Kosmos-1(Huang 2023a)考虑了冻结的视觉主干,并从头开始训练1.3B参数的语言模型。
Flamingo(Alayrac 2022)及其开源变型(Awadalla 2023;Laurençon 2021),相反,训练交叉注意层和基于Perceiver的组件,将视觉特征与冻结的LLM块连接起来。此外,Otter(Li 2023a)扩展了Flamingo的训练,增强其上下文能力。
考虑到目前可用的训练数据量,SPHINX-X(Gao et al.,2024)等方法选择执行单一的一体式训练阶段,在该阶段更新所有模型组件,也可能使用纯文本数据来保持LLM的会话能力。
两步训练。在两个训练步中的第一个步,目标是将图像特征与文本嵌入空间对齐。在这一步之后,产出往往是零散的,不连贯。因此,第二步是提高多时间会话能力。LLaVA(Liu 2023)是最早引入视觉指令跟随训练方案之一,该训练方案作为更新多模态适配器和LLM参数的第二训练步来执行。相反,在第一步,只有多模态适配器是可训练的。不同的是,MiniGPT-4(Zhu 2023a)值得注意的是,它只训练了负责两步多模态对齐的线性层。在第二步,它使用过滤后的数据,这些数据在第一步之后通过模型本身收集和细化而得。
另一种方法,如Instruction-BLIP(Dai2023)所示,涉及视觉编码器和LLM的冻结。在这两步训练中,只有Q-Former和连接模块是可训练的。与以前视觉主干保持冻结的方法相反,mPLUG Owl(Ye 2023)在初始阶段对其进行更新,有助于捕获低级和高级视觉信息。此外,在第二步中,仅使用文本和多模态数据来增加一致性。不同的是,Shikra(Chen 2023f)更新了两步的所有权重,唯一的例外是保持冻结的视觉主干。
训练数据。在第一(或单个)训练步,通常使用来自不同来源的图像-文本对,使用数据集,如LAION-2B(Schuhmann2022)、LAION-400M(Schuhman2021)、Conceptual Caption(Sharma2018)、COYO-700M(Byeon2022)和DataComp(Gadre2023)。一些方法(Lin2023a)将这些方法与一个或多个数据集结合使用,这些数据集的特征是文本与通常从网络上刮取的图像交织,例如WebLI(Chen2023i)、MMC4(Zhu2023d)、MMDialog(Feng2023b)和OBELICS(Laurençon2023)。为了解决先前数据集中的偏差和噪声问题,StableLLaVA(Li 2023h)引入了新收集的数据,用于第一步。这种方法利用ChatGPT生成包括图像生成提示和基于内容的对话的数据,并利用stable diffusion(Rombach 2022)生成相应的图像。
相反,接下来的阶段利用数据集进行可视化指令调优。其中,常用的LLaVA指令(Liu 2023e)用GPT-4生成的指令扩展了COCO(Lin 2014)。根据这一趋势,Zhao(2023a)通过结合人工和生成的数据,以高质量和多样性扩大了维度。此外,还提出了其他多回合对话数据集,如(Dai 2023)中介绍的将26个公开可用的数据集转换为其视觉指令后续版本的数据集,旨在通过更稳健的指令减少幻觉的LRV指令(Liu 2023),以及专注于文本丰富图像的LLaVAR(Zhang 2023)。
其他一些模态和应用
视频理解。尽管大部分重新搜索都集中在图像上,但一些工作提出了专门用于处理视频序列的MLLM。这些模型独立处理视频帧,使用基于CLIP的主干来提取帧级特征,然后将这些特征与池化机制(Li 2023;Maaz2023)或基于Q-Former的解决方案(Li2023g;Ren2021)相结合。视觉特征和语言模型之间的联系主要遵循与图像MLLM相同的趋势,线性投影是最常见的选择。然而,也有一些尝试开发视频专用适配器(Liu2023g;Ma2023a),可以捕捉细粒度的时间信息。除了对视频帧进行编码外,一些方法(Munasinghe2023;Zhang2023b)还利用音频特征来丰富输入视频序列的表示。
如下表是基于视频的MLLMs摘要。对于每个模型,在其最佳配置中使用的LLM,在某些情况下,使用预训练的MLLM的权重初始化(*:冻结LLM;♦: LLM微调;▲: 使用PEFT技术的LLM微调)。

任何模态模型。到目前为止,几乎所有描述的模型都将单一模态作为LLM的输入。然而,大量工作的重点是设计能够处理多种模态的有效解决方案。这通常是通过通过诸如Q-Former(Chen2023c;Panagopoulou2023)和Perceiver(Zhao2023d)的Transformer块来对准多模态特征,或者通过利用ImageBind(Gird-har2022)来有效地提取固有多模态的特征(Su2024)来实现的。图像、视频和音频是最常见的处理模态。此外,一些工作还有效地编码3D数据(Yin2023c)和IMU传感器信号(Moon2021)。虽然所有这些解决方案都可以管理多模态输入,但像NExT-GPT(Wu2023b)和Unified IO 2(Lu2021)这样的方法也能够生成不同模态的输出。
特定域的MLLMs。除了处理通用视觉输入外,一些研究工作还致力于为特定领域和应用程序开发MLLM,要么从预训练的LLM开始训练模型,要么用特定域的数据微调现有的MLLM。一些例子是为文档分析和文本密集型视觉输入设计的MLLMs(Lv2023;Ye2023a),为嵌入式人工智能和机器人提出的MLLMs(Dress2022;Mu2021),以及为医学(Li2023c)和自动驾驶(Xu2023b)等特定域量身定制的MLLM。
如下表是为特定域应用程序设计的MLLM摘要。对于每个模型,在其最佳配置中使用的LLM,在某些情况下,使用预训练MLLM的权重初始化(*:冻结LLM;♦: LLM微调;▲: 使用PEFT技术的LLM微调)。灰色表示型号不公开。
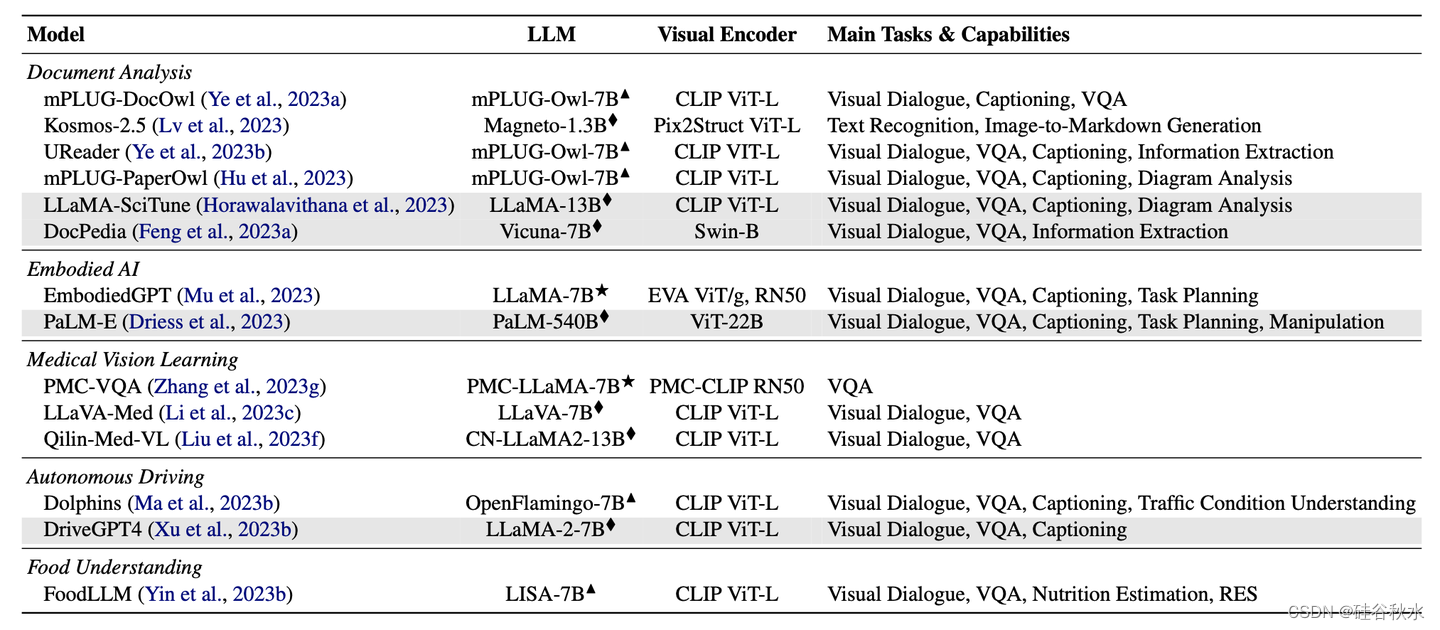
MLLMs是在不同的基准上进行评估的,同时考虑到更经典的视觉理解和识别技能以及先进的多模态对话能力。下表显示了最常见的MLLMs在标准VQA和字幕数据集以及专门为评估MLLMs而设计的基准上性能,其中对VQA、图像字幕和MLLM评估的14个评估基准性能分析。最佳成绩以粗体显示,次佳成绩以下划线显示:
相关文章:
多模态大语言模型的演化:综述
24年2月意大利三所研究大学和机构的论文“The Evolution of Multimodal Large Language Models: A Survey”。 连接文本和视觉模态在生成智能中起着至关重要的作用。由于这个原因,在大语言模型成功的启发下,大量的研究工作被投入到多模态大语言模型&…...
Qt---绘图和绘图设备
一、QPainter绘图 绘图事件 void paintEvent() 声明一个画家对象,OPainter painter(this) this指定绘图设备 画线、画圆、画矩形、画文字 设置画笔QPen 设置画笔宽度、风格 设置画刷QBrush 设置画刷风格 代码示例: #includ…...

【2024】前端,该卷什么呢?
✅顺便推个机会,技术大厂,部门捞人,前后端可投。 2024ChatGPT 的炸裂式发展,很多大佬都亲自入场整活儿,你不得不说,人工智能时代的未来已来,大势所趋,不可阻挡。随着生成式AI的迅猛发…...
C++干货--引用
前言: C的引用,是学习C的重点之一,它与指针的作用有重叠的部分,但是它绝不是完全取代指针(后面我们也会简单的分析)。 引用的概念: 引用 不是新定义一个变量 ,而 是给已存在变量取了一个别名 …...

部署 Sentinel 控制台:实现流量管理和监控
序言 Sentinel 是阿里巴巴开源的一款流量防护与监控平台,它可以帮助开发者有效地管理微服务的流量,实现流量控制、熔断降级、系统负载保护等功能。本文将介绍如何在项目中部署和配置 Sentinel 控制台,实现微服务的流量防护和监控。 一、Sen…...

10、Go Gin 连接Redis以及CookieSession
一、Redis 在Go语言中,使用Gin框架结合Redis数据库可以构建高性能的Web应用程序。Gin是一个轻量级的HTTP框架,提供了快速构建RESTful API的能力;而Redis则是一个高性能的键值存储系统,常用于缓存、消息队列、计数器等多种场景 1、…...
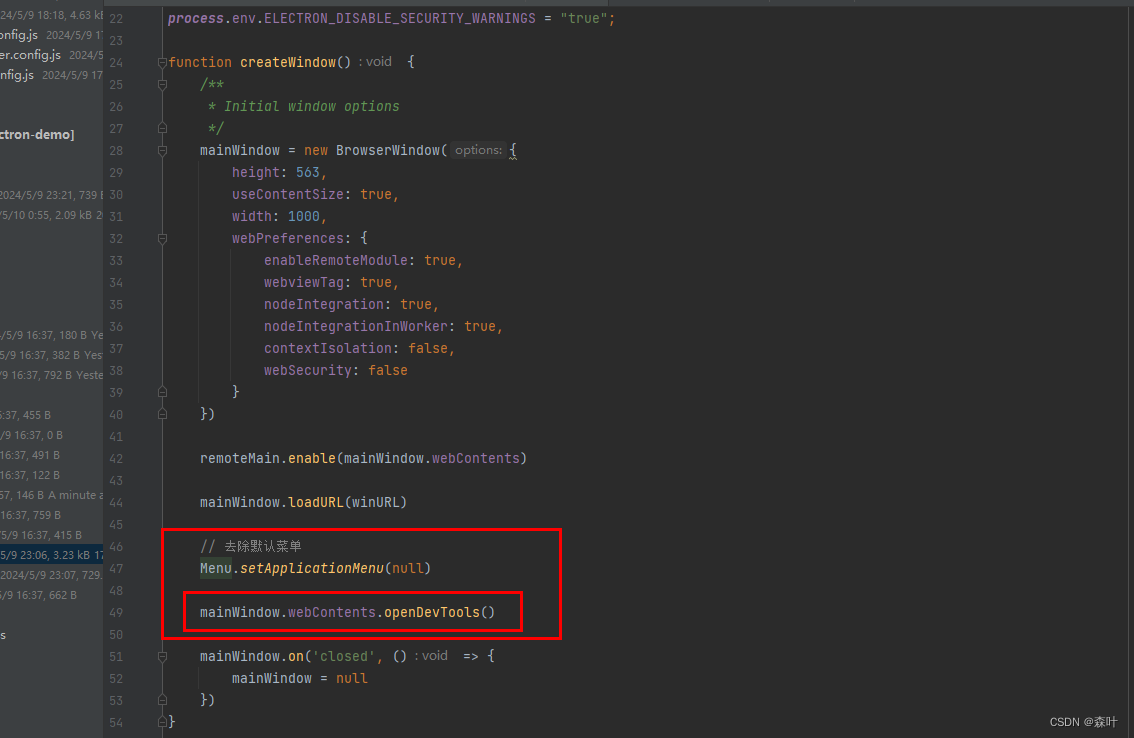
Electron-Vue 脚手架避坑实录,兼容Win11,升级electron22,清理控制台错误
去年的还是有用的,大家继续看,今年再补充一些Electron-Vue 异常处理方案 M1 和 Window10_electron异常处理-CSDN博客 代码gitee.com地址 electron-demo: electron 22 初始代码开发和讲解 升级electron为22版本(这个版本承上启下,…...

国外新闻媒体推广:多元化媒体分发投放-大舍传媒
前言 :随着全球化的进程,国外新闻市场呈现出快速发展的趋势。在这个趋势下,国外新闻媒体推广成为了各行业企业宣传业务的重要一环。本文将重点介绍大舍传媒的多元化媒体分发投放服务,以及对国外新闻媒体推广的意义。 1. 多元化媒…...

【Windows】回忆Win98
回忆Win98,又看到了这个Excel界面,上次还是十多年前的计算机课上 1、安装环境 Win11家庭版,23H2,VMware Workstation Pro 16 , 2、安装步骤及参考 虚拟机里的硬盘设置成SATA(否则各种错误),安装MSDOS7.1ÿ…...

探索QChart:Qt中的数据可视化艺术
目录标题 1. QChart概述2. 创建QChart对象3. 添加数据系列(Series)4. 定制图表外观5. 交互与动画6. 图表布局与管理7. 实例代码与解析8. 总结 在数字化的世界里,数据是新的石油。然而,原始数据本身往往难以理解,数据可…...
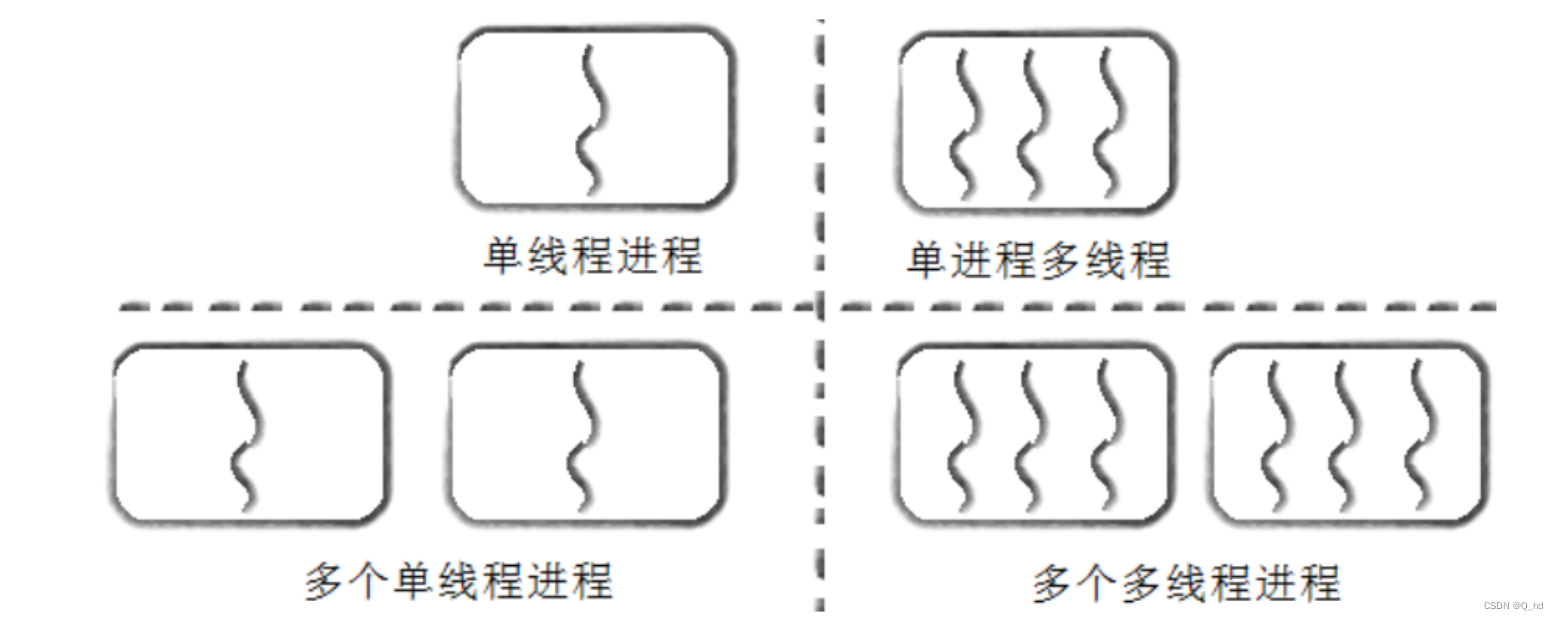
【Linux】线程机制解析:理解、优势与Linux系统应用
文章目录 前言:1. 线程概念1.1. 什么是线程1.2. 线程得优点:1.3. 线程的缺点线程异常线程的用途 2. 线程的理解(Linux 系统为例)2.1. 为什么要设计Linux“线程"?2.2. 什么是进程?2.3. 关于调度的问题2…...

java中简单工厂模式,工厂方法模式和抽象工厂模式的区别和联系?
在Java中,简单工厂模式、工厂方法模式和抽象工厂模式都是创建型设计模式,用于解耦对象的创建过程,提高系统的灵活性和可扩展性。它们之间既有相似之处也有明显的区别: 简单工厂模式(Simple Factory Pattern࿰…...

SERVER_DOWN 表示该服务器已经宕机或无法访问
[{"type":"MASTER","host":"/nodes/master/ds-master-0.ds-master-headless:5678","event":"SERVER_DOWN","warningLevel":"SERIOUS"}] 该JSON数据描述了一个事件通知,具体地&am…...

深度论证-高速走线控制100欧姆阻抗一定是最好的选择吗?
高速先生成员--黄刚 对于高速差分信号到底需要控制多少欧姆的阻抗,高速先生相信大部分工程师首先都会看下例如信号的协议文档或者芯片的文档,看看里面有没有推荐的控制阻抗值。例如像PCIE信号,在4.0之后的阻抗会明确要求按照85欧姆来控制&…...

【文末福利送资料】深度探索GPT模型,竟然10个字都不会说?
目录 导读 自回归模型 那么什么时候停下呢? 该停下来,但是概率不让啊 GPT欠缺的两种能力 目录 导读 自回归模型 那么什么时候停下呢? 该停下来,但是概率不让啊 GPT欠缺的两种能力 缺少规划 反省和修订 所有的人工智能…...

一些近来对内网攻防的思考
我知道我最近托更托了很久了,其实也不是小编懒啊 这小编也是一直在写,但是遇到的问题比较多(我太菜了),所以一直拖着。 但是总不能不更吧 那就讲一下进来的一些内网攻防的思考吧 1.CrossC2上线Linux到CS(成功) …...
数据结构--顺序表和链表的区别
顺序表和链表之间各有优劣,我们不能以偏概全,所以我们在使用时要关注任务的注重点,以此来确定我们要使用两者中的哪一个。 不同点: 存储空间上: 顺序表在物理结构上是一定连续的,而链表(这里以带头双向循环…...

【技术分享】 OPC UA安全策略证书简述
那什么是OPC UA证书?用途是什么? 简单来说它是身份验证和权限识别。 OPC UA使用X.509证书标准,该标准定义了标准的公钥格式。建立UA会话的时候,客户端和服务器应用程序会协商一个安全通信通道。数字证书(X.509&#x…...
【Neo4jJDK开箱即用的安装全流程】
neo4j:命令行本地访问loclhost neo4j:命令行本地访问loclhost2 neo4j操作 Neo4j桌面版数据库导出导入 Neo4j安装与配置以及JDK安装与配置教程(超详细) Neo4j 安装、使用教程 Neo4j安装教程 Neo4J桌面版的配置和连接Pycharm jdk-neo对应版本 JDK ORACLE中…...
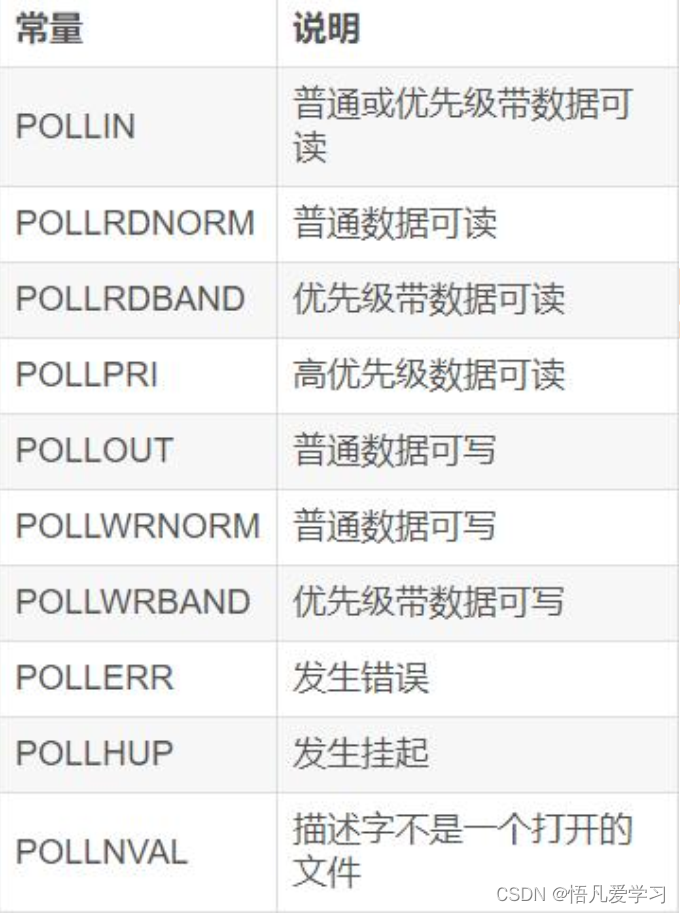
Linux 操作系统多路IO复用
1.多路IO复用 多路I/O复用是通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。 这个机制能够通过select/poll/eroll等来使用。这些函数都可以同时监视多…...

KaTrain围棋AI:5步开启专业级围棋训练新时代 [特殊字符]
KaTrain围棋AI:5步开启专业级围棋训练新时代 🎯 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否渴望提升围棋水平,却苦于缺乏专业指导&am…...

408 每日一题 Day 2:二叉树的重构与遍历
一、题目描述 已知一棵二叉树的前序遍历序列为 ABDECFG,中序遍历序列为 DBEAFCG,则该二叉树的后序遍历序列是? A. DEBFGCAB. DEBFCGAC. DEBFGACD. DEBFAGC 二、考点分析项目内容核心知识点二叉树的遍历、根据遍历序列重构二叉树难度⭐⭐⭐408…...

动态图神经网络实现多商品时序协同预测
1. 项目概述:为什么传统时序模型在多商品预测中频频“掉链子”你有没有遇到过这样的场景:一家区域连锁超市的运营团队,每天盯着几十种SKU的销售数据发愁——酸奶销量突然飙升,但库存系统还在按上周的均值补货;新款保温…...

详细讲解 Spring MVC 的 HandlerInterceptor 接口
目录 一、核心定位 二、接口完整定义 三、三个核心方法详解(执行顺序 作用) 1. preHandle () —— 【请求前置处理】 2. postHandle () —— 【请求后置处理】 3. afterCompletion () —— 【请求完成清理】 四、执行流程(生命周期&a…...

为什么你的双色调总像PPT?揭秘Midjourney v6中未公开的--tint权重衰减算法与Gamma校准阈值
更多请点击: https://kaifayun.com 第一章:双色调视觉失真的本质归因 双色调视觉失真并非单纯由显示设备或图像压缩引发的表层现象,其根本源于人眼视锥细胞响应函数与数字色彩空间映射之间的结构性不匹配。当图像被强制量化为仅含两种色调&a…...

全志T113-i平台UB37三模无线模组驱动移植与调试实战
1. 项目概述:当国产工业芯遇上新一代无线技术最近在做一个挺有意思的项目,客户想在一块国产的工业级核心板上,集成最新的星闪(NearLink)无线通信功能。核心板用的是全志的T113-i,无线模组是支持Wi-Fi 6、蓝…...

Python数据流式处理:Streaming深度解析与实战
Python数据流式处理:Streaming深度解析与实战 引言 在Python开发中,数据流式处理是处理大数据和实时数据的关键技术。作为一名从Rust转向Python的后端开发者,我深刻体会到流式处理在处理海量数据时的优势。Python提供了多种流式处理工具&…...

c语言之pubnub库代码示例
好的,这是 PubNub 在 FreeRTOS 平台上的核心接口代码示例: PubNub 核心接口示例 1. 初始化与配置 #include "pubnub_api.h" #include "pubnub_coreapi.h" #include "pubnub_pubsubapi.h"...

CDCS金融算法挑战赛终极指南:甜橙金融与融360实战案例深度解析
CDCS金融算法挑战赛终极指南:甜橙金融与融360实战案例深度解析 【免费下载链接】CDCS Chinese Data Competitions Solutions 项目地址: https://gitcode.com/gh_mirrors/cd/CDCS CDCS(Chinese Data Competitions Solutions)是中国数据…...

TMS320VC5502PGF300:TI TMS320C55x系列定点DSP,300MHz,176-LQFP封装
TMS320VC5502PGF300:C55x低功耗DSP的300MHz经典音频处理方案在语音识别、音频编解码和通信基带处理等实时信号处理应用中,处理器的能效比(单位功耗下的算力)往往是系统设计的核心约束。高性能处理器虽然算力强劲,但较高…...