28、Flink 为管理状态自定义序列化
为管理状态自定义序列化
a)概述
对状态使用自定义序列化,包含如何提供自定义状态序列化程序、实现允许状态模式演变的序列化程序。
b)使用自定义状态序列化程序
注册托管 operator 或 keyed 状态时,需要 StateDescriptor 来指定状态的名称以及有关状态类型的信息,Flink 的类型序列化框架使用类型信息为状态创建适当的序列化程序。
可以让 Flink 使用自定义的序列化程序来序列化托管状态,只需使用自定义的 TypeSerializer 实现直接实例化StateDescriptor:
public class CustomTypeSerializer extends TypeSerializer<Tuple2<String, Integer>> {...};ListStateDescriptor<Tuple2<String, Integer>> descriptor =new ListStateDescriptor<>("state-name",new CustomTypeSerializer());checkpointedState = getRuntimeContext().getListState(descriptor);
c)状态序列化器与模式演化
包含状态序列化和模式进化相关的面向用户的抽象,以及 Flink 如何与这些抽象交互的必要内部细节。
从保存点恢复时,Flink 允许更改用于读取和写入先前注册状态的序列化程序,当状态恢复时,将为该状态注册一个新的序列化程序(即用于访问已恢复作业中的状态的 StateDescriptor 附带的序列化程序);这个新的序列化程序可能具有与以前的序列化程序不同的模式;因此,在实现状态序列化程序时,除了读取/写入数据的基本逻辑外,还需要实现如何更改序列化模式。
模式可能会在以下几种情况下发生变化:
-
状态类型的数据模式已经改变。即从用作状态的 POJO 中添加或删除字段;一般来说,在更改数据模式后,需要升级序列化程序的序列化格式。
-
序列化程序的配置已更改。为了使新的执行具有写入的状态模式的信息并检测模式是否已经改变,在获取 operator 状态的保存点时,需要将状态序列化器的快照与状态字节一起写入。
TypeSerializerSnapshot 抽象
public interface TypeSerializerSnapshot<T> {int getCurrentVersion();void writeSnapshot(DataOuputView out) throws IOException;void readSnapshot(int readVersion, DataInputView in, ClassLoader userCodeClassLoader) throws IOException;TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(TypeSerializerSnapshot<T> oldSerializerSnapshot);TypeSerializer<T> restoreSerializer();
}
public abstract class TypeSerializer<T> { // ...public abstract TypeSerializerSnapshot<T> snapshotConfiguration();
}
序列化程序的 TypeSerializerSnapshot 是一个时间点信息,它是关于状态序列化程序写入 schema 的唯一记录,以及还原与给定时间点相同的序列化程序所必需的附加信息;
在 writeSnapshot 和 readSnapshot 方法中定义了在恢复时作为序列化程序快照应写入和读取的逻辑。
注意:快照自己的写入模式可能也需要随着时间的推移而更改(例如,当希望向快照添加更多有关序列化程序的信息时);为了便于实现这一点,使用 getCurrentVersion 方法中定义的当前版本号对快照进行版本控制;在还原时,从保存点读取序列化程序快照时,写入快照的 schema 的版本将提供给 readSnapshot 方法,以便读取可以实现处理不同的版本。
在恢复时,应在 resolveSchemaCompatibility 方法中实现检测新序列化程序的 schema 是否已更改的逻辑;当在 operator 的恢复执行中,以前注册的状态再次向新的序列化程序注册时,旧的序列化程序快照将通过此方法提供给新的序列化器快照;此方法返回表示兼容性解析结果的 TypeSerializerSchemaCompatibility,它可以是以下内容之一:
- TypeSerializerSchemaCompatility.compatibleAsIs():此结果表示新的序列化程序是兼容的,即新的序列化器与以前的序列化程序具有相同的 schema。新的序列化程序可能已在 resolveSchemaCompatibility 方法中重新配置,因此它是兼容的。
- TypeSerializerSchemaCompatibility.compatibleAfterMigration():此结果表示新的序列化程序具有不同的序列化架构,可以通过使用以前的序列化程序(识别旧架构)将字节读取到状态对象中,然后使用新的序列化器(识别新架构)将对象重写回字节,从而从旧架构迁移。
- TypeSerializerSchemaCompatibility.incompatible():此结果表示新的序列化程序具有不同的序列化 schema,但无法从旧架构迁移。
在需要迁移的情况下如何获得上一个序列化程序?
序列化程序的 TypeSerializerSnapshot 的另一个重要作用是,它充当还原以前的序列化程序的工厂;即 TypeSerializerSnapshot 应该实现 restoreSerializer 方法来实例化一个序列化程序实例,该序列化程序实例可以识别以前的序列化程序的 schema 和配置,因此可以安全地读取以前的序列化程序器写入的数据。
Flink 如何与 TypeSerializer 和 TypeSerializerSnapshot 抽象交互
根据状态后端的不同,状态后端与抽象交互略有不同。
堆外状态后端(例如 RocksDBStateBackend)
- 向具有 schema A 的状态序列化程序注册新状态;
- 该状态已注册的 TypeSerializer 用于在每次状态访问时读取/写入状态;
- 状态写在 schema A 中;
- 获取保存点;
- 序列化程序快照是通过 TypeSerializer#snapshotConfiguration 方法提取的;
- 序列化程序快照被写入保存点,以及已经序列化的状态字节(使用 schema A);
- 执行恢复时使用具有 schema B 的新状态序列化程序重新访问恢复的状态字节;
- 将还原以前的状态序列化程序的快照;
- 状态字节在还原时不进行反序列化,只加载回状态后端(因此,仍在 schema A 中);
- 在接收到新的序列化程序后,通过 TypeSerializer#resolveSchemaCompatibility 将以前的序列化程序的快照提供给新的序列化器的快照,以检查架构兼容性;
- 将状态后端中的状态字节从 schema A迁移到 schema B;
- 如果兼容性解决方案反映出架构已更改并且可以进行迁移,则执行架构迁移。
- 识别 schema A 的前一个状态序列化程序将通过 TypeSerializerSnapshot#restoreSerializer() 从序列化程序快照中获得,并用于将状态字节反序列化为对象,这些对象又会使用识别 schema B 的新序列化程序重新写入,以完成迁移。
- 在继续处理之前,已访问状态的所有条目都会一起迁移;
- 如果解析表示不兼容,则状态访问将失败并出现异常。
堆状态后端(例如MemoryStateBackend、FsStateBackend)
- 向具有 schema A 的状态序列化程序注册新状态;
- 已注册的 TypeSerializer 由状态后端维护;
- 取一个保存点,用 schema A 序列化所有状态;
- 序列化程序快照是通过 TypeSerializer#snapshotConfiguration 方法提取的;
- 序列化程序快照被写入保存点;
- 状态对象现在被序列化到保存点,用 schema A 编写;
- 恢复时,将状态反序列化为堆中的对象;
- 将还原以前的状态序列化程序的快照;
- 识别 schema A 的上一个序列化程序是通过 TypeSerializerSnapshot#restoreSerializer() 从序列化程序快照中获得的,用于将状态字节反序列化为对象;
- 从现在起,所有的状态都已经被反序列化了;
- 执行恢复时使用具有 schema B 的新状态序列化程序重新访问以前的状态;
- 在接收到新的序列化程序后,通过 TypeSerializer#resolveSchemaCompatibility 将以前的序列化程序的快照提供给新的序列化器的快照,以检查架构兼容性;
- 如果兼容性检查表明需要迁移,则在这种情况下不会发生任何事情,因为对于堆后端,所有状态都已反序列化为对象;
- 如果解析表示不兼容,则状态访问将失败并出现异常;
- 取另一个保存点,用 schema B 序列化所有状态;
- 与步骤2相同,但现在状态字节都在 schema B 中。
d)预定义的便捷的 TypeSerializerSnapshot 类
Flink 提供了两个典型场景的 TypeSerializerSnapshot 的抽象基类:SimpleTypeSerializerSnapshot 和CompositeTypeSerializerSnapshot。
提供这些预定义快照作为其序列化程序快照的序列化程序必须具有自己的独立子类实现。
实现 SimpleTypeSerializerSnapshot
SimpleTypeSerializerSnapshot 适用于没有任何状态或配置的序列化程序,意味着序列化程序的序列化 schema 仅由序列化程序的类定义。
当使用 SimpleTypeSerializerSnapshot 作为序列化程序的快照类时,兼容性解析只有两个可能的结果:
- TypeSerializerSchemaCompatibility.compatibleAsIs():新的序列化程序类保持相同;
- TypeSerializerSchemaCompatility.uncompatible():新的序列化程序类与上一个不同;
示例使用 SimpleTypeSerializerSnapshot,以 Flink 的 IntSerializer 为例:
public class IntSerializerSnapshot extends SimpleTypeSerializerSnapshot<Integer> {public IntSerializerSnapshot() {super(() -> IntSerializer.INSTANCE);}
}
IntSerializer 没有状态或配置,序列化格式仅由序列化程序类本身定义,并且只能由另一个 IntSerializer 读取,它适合SimpleTypeSerializerSnapshot 的用例。
SimpleTypeSerializerSnapshot 的父类构造函数需要相应序列化程序实例的提供,而不管快照当前是在还原还是在快照期间写入;该实例提供者用于创建还原序列化程序,以及用于验证新序列化程序是否属于相同的预期序列化程序类的类型检查。
实现 CompositeTypeSerializerSnapshot
CompositeTypeSerializerSnapshot 适用于依赖多个嵌套序列化程序进行序列化的序列化程序。
将依赖于多个嵌套序列化程序的序列化程序称为 “外部” 序列化程序;例如,MapSerializer、ListSerializer 和 GenericArraySerializer等;当考虑 MapSerializer 的键和值序列化程序时将是嵌套的序列化程序,而 MapSerialize 器本身是“外部”序列化程序。
外部序列化程序的快照还应包含嵌套序列化程序的 snapshot,以便可以独立检查嵌套序列化程序之间的兼容性;在解决外部序列化程序的兼容性时,需要考虑每个嵌套序列化程序的兼容。
提供 CompositeTypeSerializerSnapshot 是为了帮助实现这类复合序列化程序的快照,它处理读取和写入嵌套序列化程序快照,以及在考虑所有嵌套序列化程序兼容性的情况下解析最终兼容性结果。
示例使用 CompositeTypeSerializerSnapshot,以 Flink 的 MapSerializer 为例:
public class MapSerializerSnapshot<K, V> extends CompositeTypeSerializerSnapshot<Map<K, V>, MapSerializer> {private static final int CURRENT_VERSION = 1;public MapSerializerSnapshot() {super(MapSerializer.class);}public MapSerializerSnapshot(MapSerializer<K, V> mapSerializer) {super(mapSerializer);}@Overridepublic int getCurrentOuterSnapshotVersion() {return CURRENT_VERSION;}@Overrideprotected MapSerializer createOuterSerializerWithNestedSerializers(TypeSerializer<?>[] nestedSerializers) {TypeSerializer<K> keySerializer = (TypeSerializer<K>) nestedSerializers[0];TypeSerializer<V> valueSerializer = (TypeSerializer<V>) nestedSerializers[1];return new MapSerializer<>(keySerializer, valueSerializer);}@Overrideprotected TypeSerializer<?>[] getNestedSerializers(MapSerializer outerSerializer) {return new TypeSerializer<?>[] { outerSerializer.getKeySerializer(), outerSerializer.getValueSerializer() };}
}
实现为 CompositeTypeSerializerSnapshot 的子类时,必须实现以下三种方法:
- getCurrentOuterSnapshotVersion():此方法定义当前外部序列化程序快照的序列化二进制格式的版本。
- getNestedSerializers(TypeSerializer):给定外部序列化程序,返回其嵌套的序列化程序。
- createOuterSerializerWithNestedSerializers(TypeSerializer[]):给定嵌套的序列化程序,创建外部序列化程序的实例。
上面的示例是 CompositeTypeSerializerSnapshot,除了嵌套的序列化程序的快照之外,没有任何额外的信息要进行快照;可以预期其外部快照版本永远不需要更新。
然而,其他一些序列化程序包含一些额外的静态配置,这些配置需要与嵌套组件序列化程序一起持久化,例如 Flink 的 GenericArraySerializer 除了嵌套的元素序列化程序之外,还包含数组元素类型的类作为配置。
此时需要在 CompositeTypeSerializerSnapshot 上实现另外三个方法:
- writeOuterSnapshot(DataOutputView):定义如何写入外部快照信息。
- readOuterSnapshot(int,DataInputView,ClassLoader):定义如何读取外部快照信息。
- resolveOuterSchemaCompatibility(TypeSerializerSnapshot):基于外部快照信息检查兼容性。
默认,CompositeTypeSerializerSnapshot 假设没有任何外部快照信息可供读取/写入,因此上述方法的默认实现为空;如果子类具有外部快照信息,那么必须实现这三种方法。
以下是 CompositeTypeSerializerSnapshot 如何用于具有外部快照信息的复合序列化程序快照的示例,以 Flink 的GenericArraySerializer 为例:
public final class GenericArraySerializerSnapshot<C> extends CompositeTypeSerializerSnapshot<C[], GenericArraySerializer> {private static final int CURRENT_VERSION = 1;private Class<C> componentClass;public GenericArraySerializerSnapshot() {super(GenericArraySerializer.class);}public GenericArraySerializerSnapshot(GenericArraySerializer<C> genericArraySerializer) {super(genericArraySerializer);this.componentClass = genericArraySerializer.getComponentClass();}@Overrideprotected int getCurrentOuterSnapshotVersion() {return CURRENT_VERSION;}@Overrideprotected void writeOuterSnapshot(DataOutputView out) throws IOException {out.writeUTF(componentClass.getName());}@Overrideprotected void readOuterSnapshot(int readOuterSnapshotVersion, DataInputView in, ClassLoader userCodeClassLoader) throws IOException {this.componentClass = InstantiationUtil.resolveClassByName(in, userCodeClassLoader);}@Override protected OuterSchemaCompatibility resolveOuterSchemaCompatibility(TypeSerializerSnapshot<C[]> oldSerializerSnapshot) {GenericArraySerializerSnapshot<C[]> oldGenericArraySerializerSnapshot = (GenericArraySerializerSnapshot<C[]>) oldSerializerSnapshot;return (this.componentClass == oldGenericArraySerializerSnapshot.componentClass) ? OuterSchemaCompatibility.COMPATIBLE_AS_IS : OuterSchemaCompatibility.INCOMPATIBLE;}@Overrideprotected GenericArraySerializer createOuterSerializerWithNestedSerializers(TypeSerializer<?>[] nestedSerializers) {TypeSerializer<C> componentSerializer = (TypeSerializer<C>) nestedSerializers[0];return new GenericArraySerializer<>(componentClass, componentSerializer);}@Overrideprotected TypeSerializer<?>[] getNestedSerializers(GenericArraySerializer outerSerializer) {return new TypeSerializer<?>[] { outerSerializer.getComponentSerializer() };}
}
注意:
- 由于此 CompositeTypeSerializerSnapshot 实现具有,作为快照一部分写入的外部快照信息,因此每当外部快照信息的序列化格式发生更改时,都必须提升由 getCurrentOuterSnapshotVersion() 定义的外部快照版本。
- 在编写组件类时,避免使用 Java 序列化,只编写类名,并在读回快照时动态加载它;
e)最佳实践
Flink 通过实例化的类名恢复序列化程序的快照
序列化程序的快照是如何序列化已注册状态的唯一记录,它是读取保存点中状态的入口点;为了能够恢复和访问以前的状态,必须能够恢复以前的状态序列化程序的快照。
Flink 首先实例化具有类名(与快照字节一起写入)的 TypeSerializerSnapshot 来恢复序列化程序快照;为了避免意外更改类名或实例化失败,TypeSerializerSnapshot 类应该:
- 避免被实现为匿名类或嵌套类;
- 具有用于实例化的公共空值构造函数;
避免在不同的序列化程序之间共享相同的 TypeSerializerSnapshot 类
由于 schema 兼容性检查通过序列化程序快照进行,因此让多个序列化程序返回与其快照相同的 TypeSerializerSnapshot 类会使TypeSerializerSnapshot#resolveSchemaCompatibility 和 TypeSerializerSnapshot#restoreSerializer() 方法的实现复杂化。
单个序列化程序的序列化 schema、配置以及如何恢复它,应该合并到它自己专用的 TypeSerializerSnapshot 类中。
避免对序列化程序快照内容使用 Java 序列化
在向持久化序列化程序快照写入内容时,不应使用 Java 序列化;例如,一个序列化程序需要将其目标类型的类作为其快照的一部分进行持久化,应通过编写类名来持久化有关类的信息,而不是使用 Java 直接序列化类;读取快照时,会读取类名,并通过该名称动态加载类。
可以确保始终可以安全地读取序列化程序快照;如果类型类是使用 Java 序列化持久化的,一旦类实现发生变化,快照就可能不再可读,并且根据 Java 序列化的具体情况,快照不再是二进制兼容的。
4.注册自定义序列化器-待验证
如果在 Flink 程序中使用了 Flink 类型序列化器无法进行序列化的用户自定义类型,Flink 会回退到通用的 Kryo 序列化器;可以使用 Kryo 注册自己的序列化器或序列化系统,比如 Google Protobuf 或 Apache Thrift。
使用方法是在 Flink 程序中的 ExecutionConfig 注册类类型以及序列化器。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 为类型注册序列化器类
env.getConfig().registerTypeWithKryoSerializer(MyCustomType.class, MyCustomSerializer.class);// 为类型注册序列化器实例
MySerializer mySerializer = new MySerializer();
env.getConfig().registerTypeWithKryoSerializer(MyCustomType.class, mySerializer);
需要确保你的自定义序列化器继承了 Kryo 的序列化器类,对于 Google Protobuf 或 Apache Thrift,这一点已经做好了。
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 使用 Kryo 注册 Google Protobuf 序列化器
env.getConfig().registerTypeWithKryoSerializer(MyCustomType.class, ProtobufSerializer.class);// 注册 Apache Thrift 序列化器为标准序列化器
// TBaseSerializer 需要初始化为默认的 kryo 序列化器
env.getConfig().addDefaultKryoSerializer(MyCustomType.class, TBaseSerializer.class);
为了使上面的例子正常工作,需要在 Maven 项目文件中(pom.xml)包含必要的依赖,为 Apache Thrift 添加以下依赖:
<dependency><groupId>com.twitter</groupId><artifactId>chill-thrift</artifactId><version>0.7.6</version><!-- exclusions for dependency conversion --><exclusions><exclusion><groupId>com.esotericsoftware.kryo</groupId><artifactId>kryo</artifactId></exclusion></exclusions>
</dependency>
<!-- libthrift is required by chill-thrift -->
<dependency><groupId>org.apache.thrift</groupId><artifactId>libthrift</artifactId><version>0.11.0</version><exclusions><exclusion><groupId>javax.servlet</groupId><artifactId>servlet-api</artifactId></exclusion><exclusion><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId></exclusion></exclusions>
</dependency>
对于 Google Protobuf 需要添加以下 Maven 依赖:
<dependency><groupId>com.twitter</groupId><artifactId>chill-protobuf</artifactId><version>0.7.6</version><!-- exclusions for dependency conversion --><exclusions><exclusion><groupId>com.esotericsoftware.kryo</groupId><artifactId>kryo</artifactId></exclusion></exclusions>
</dependency>
<!-- We need protobuf for chill-protobuf -->
<dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.7.0</version>
</dependency>
请根据需要调整两个依赖库的版本。
使用 Kryo JavaSerializer 的问题
如果你为自定义类型注册 Kryo 的 JavaSerializer,即使你提交的 jar 中包含了自定义类型的类,也可能会遇到 ClassNotFoundException 异常;这是由于 Kryo JavaSerializer 的一个已知问题,它可能使用了错误的类加载器。
在这种情况下,应该使用 org.apache.flink.api.java.typeutils.runtime.kryo.JavaSerializer 来解决这个问题;这个类是在 Flink 中对 JavaSerializer 的重新实现,可以确保使用用户代码的类加载器。
相关文章:

28、Flink 为管理状态自定义序列化
为管理状态自定义序列化 a)概述 对状态使用自定义序列化,包含如何提供自定义状态序列化程序、实现允许状态模式演变的序列化程序。 b)使用自定义状态序列化程序 注册托管 operator 或 keyed 状态时,需要 StateDescriptor 来指…...
【强训笔记】day17
NO.1 思路:用一个字符串实现,stoi函数可以转化为数字并且去除前导0。 代码实现: #include <iostream> #include<string> using namespace std;string s;int main() {cin>>s;for(int i0;i<s.size();i){if(s[i]%20) s[…...
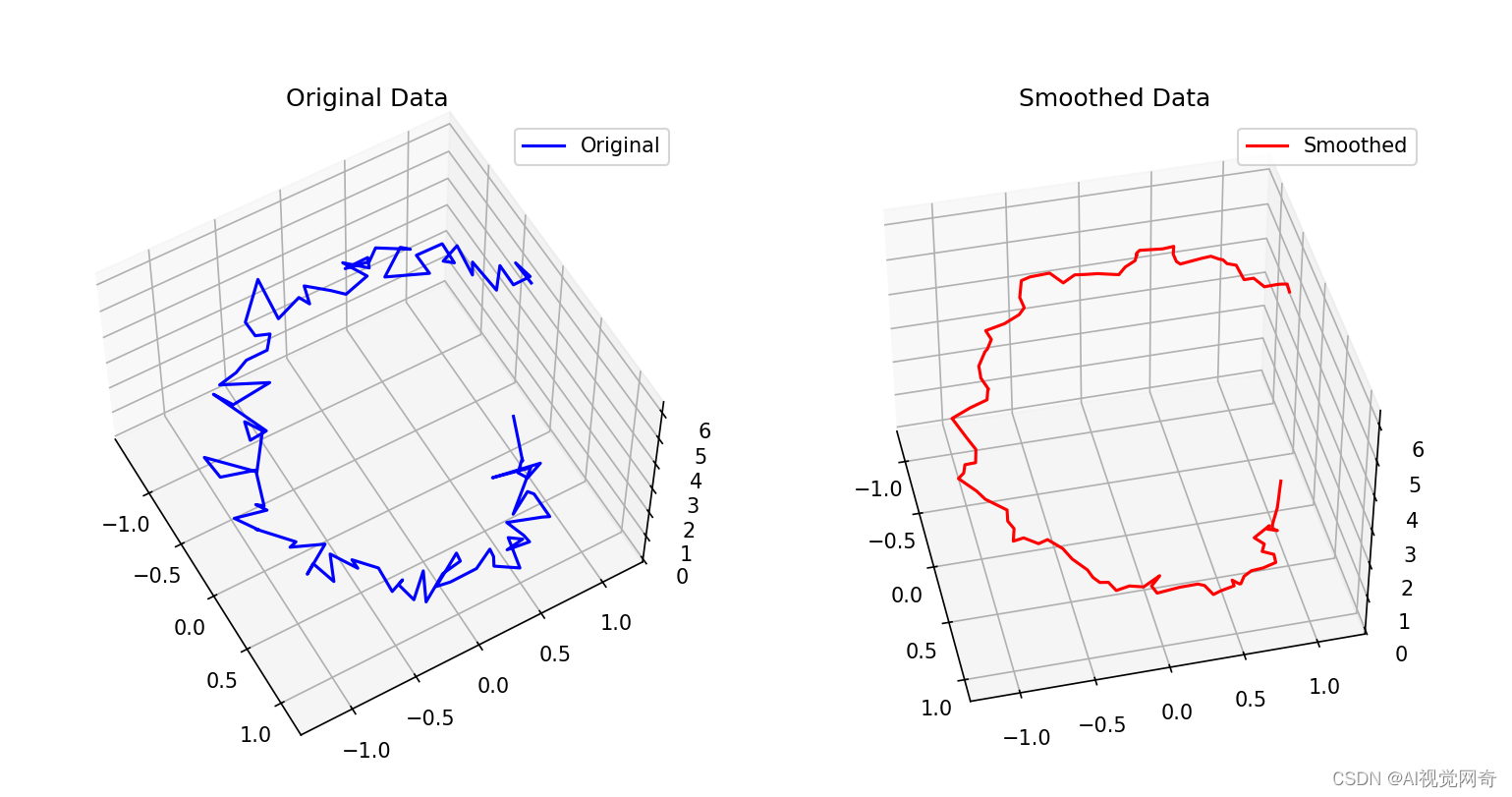
平滑 3d 坐标
3d平滑 import torch import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3Dclass SmoothOperator:def smooth(self, vertices):# 使用一维平均池化进行平滑vertices_smooth F.avg_pool1d(vertices.p…...

Go解析的数据类型可能含有不同数据结构的处理方式
最近做一个需求,各种业务消息都会往我的消息队列中写各种类型的数据,服务端需要接受各种不同的参数然后转换为本地数据结构,Go语言不确定上游传过来的数值是什么类型,然后又下面四种解决方案。 1. 类型断言和类型切换 func (Mis…...

Java网络编程基础
Java网络编程基础主要涉及进程间通信、网络通信协议、IP地址和端口以及Java提供的网络应用编程接口等核心概念。 进程间通信是Java网络编程的基础。进程是运行中的程序,而进程间通信则是指不同进程之间进行数据交换和共享信息的过程。在Java中,进程间的…...

鸿蒙DevEco Studio 4.1 Release-模拟器启动方式错误
软件版本:DevEco Studio 4.1 Release 报错提示: 没有权限查看处理指导 Size on Disk 显示1.0MB 尝试方案(统统无效): 1、“windows虚拟机监控程序平台”、"虚拟机平台"已开启 启用CPU虚拟化 2、C…...
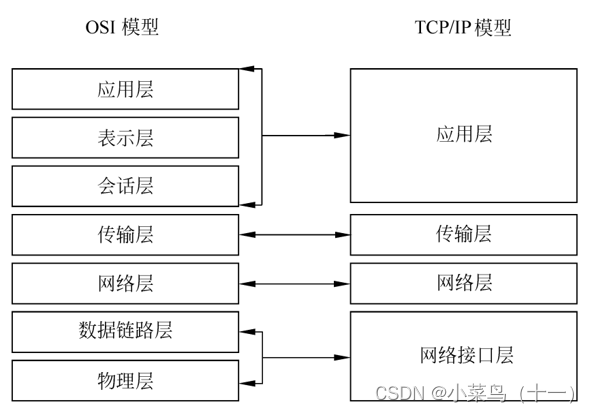
Linux与windows网络管理
文章目录 一、TCP/IP1.1、TCP/IP概念TCP/IP是什么TCP/IP的作用TCP/IP的特点TCP/IP的工作原理 1.2、TCP/IP网络发展史1.3、OSI网络模型1.4、TCP/IP网络模型1.5、linux中配置网络网络配置文件位置DNS配置文件主机名配置文件常用网络查看命令 1.6、windows中配置网络CMD中网络常用…...

一站式、低成本 | 等保一体机安全解决方案
方案建设背景 等级保护是我国关于信息安全的基本政策,相关政策制度要求单位开展等级保护工作。单位信息系统存在的安全隐患和不足,进行安全整改之后,提高信息系统的信息安全防护能力,降低系统被攻击的风险,维护单位良…...

Grafana(CVE-2021-43798)、Apache Druid 代码执行漏洞
文章目录 一、Grafana 8.x 插件模块目录穿越漏洞(CVE-2021-43798)二、Apache Druid 代码执行漏洞(CVE-2021-25646) 一、Grafana 8.x 插件模块目录穿越漏洞(CVE-2021-43798) Grafana是一个系统监测工具。 利…...
AI赋能EasyCVR视频汇聚/视频监控平台加快医院安防体系数字化转型升级
近来,云南镇雄一医院发生持刀伤人事件持续发酵,目前已造成2人死亡21人受伤。此类事件在医院层出不穷,有的是因为医患纠纷、有的是因为打架斗殴。而且在每日大量流动的人口中,一些不法分子也将罪恶的手伸到了医院,实行扒…...
)
Cocos Creator 3.x 实现触摸拖动物体(record)
参考:如何实现拖动物体 - Creator 3.x - Cocos中文社区 //注册触摸事件 node.on(Node.EventType.TOUCH_MOVE, this.onTouchMove, this); //事件回调函数 onTouchMove(event) {const location event.getUILocation();event.target.setWorldPosition(location.x, lo…...

漏桶算法:稳定处理大量突发流量的秘密武器!
漏桶算法的介绍 我们经常会遇到这样一种情况:数据包的发送速率不稳定,而网络的带宽有限。如果在短时间内有大量的数据包涌入,那么网络就会出现拥塞,数据包的丢失率就会增大。为了解决这个问题,人们提出了一种叫做“漏…...

淘宝数据分析——Python爬虫模式♥
大数据时代, 数据收集不仅是科学研究的基石, 更是企业决策的关键。 然而,如何高效地收集数据 成了摆在我们面前的一项重要任务。 本文将为你揭示, 一系列实时数据采集方法, 助你在信息洪流中, 找到…...
5G消息和5G阅信的释义与区别 | 赛邮科普
5G消息和5G阅信的释义与区别 | 赛邮科普 在 5G 技术全面普及的当下,历史悠久的短信服务也迎来了前所未有的变革。5G 阅信和 5G 消息就是应运而生的两种短信形态,为企业和消费者带来更加丰富的功能和更加优质的体验。 这两个产品名字和形态都比较接近&am…...

数据结构第一次实验
删除进程未完成 代码: #include "stdio.h" #include <stdlib.h> #include <conio.h> #define getpch(type) (type*)malloc(sizeof(type)) #define NULL 0// PCB struct pcb{// char name[10];// char state;// int super;int ntime;int …...
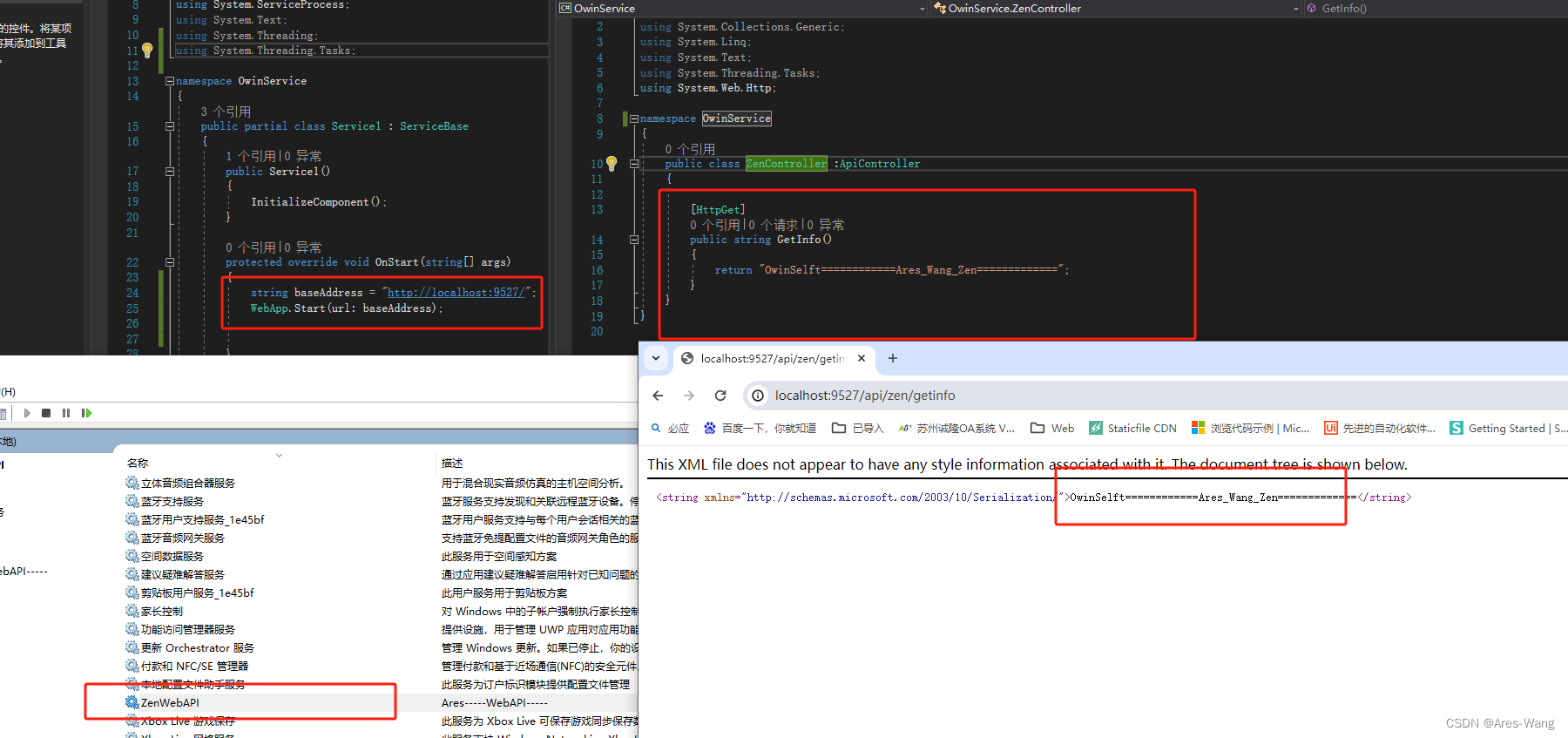
.NET WebService \ WCF \ WebAPI 部署总结 以及 window 服务 调试,webservice 的安全验证
一、webservice 部署只能部署IIS上, 比较简单,就不做说明了 安全验证: Formwindow身份加个参数,token 定时更新可以Soapheader 》》》soapheader验证 首先要新建一个类 且这个类必须继承SoapHeader类 且这个类型必须有一个无参…...
自动化运维管理工具 Ansible-----【inventory 主机清单和playbook剧本】
目录 一、inventory 主机清单 1.1inventory 中的变量 1.1.1主机变量 1.1.2组变量 1.1.3组嵌套 二、Ansible 的脚本 ------ playbook(剧本) 2.1 playbook介绍 2.2playbook格式 2.3playbooks 的组成 2.4playbook编写 2.5运行playbook 2.5.1ans…...

java static 关键字
在Java中,static是一个关键字,用于创建类级别的成员(字段、方法、块)。static成员属于类本身,而不是类的实例,因此可以直接通过类名访问,而不需要创建类的实例。 1. 静态字段(Stati…...
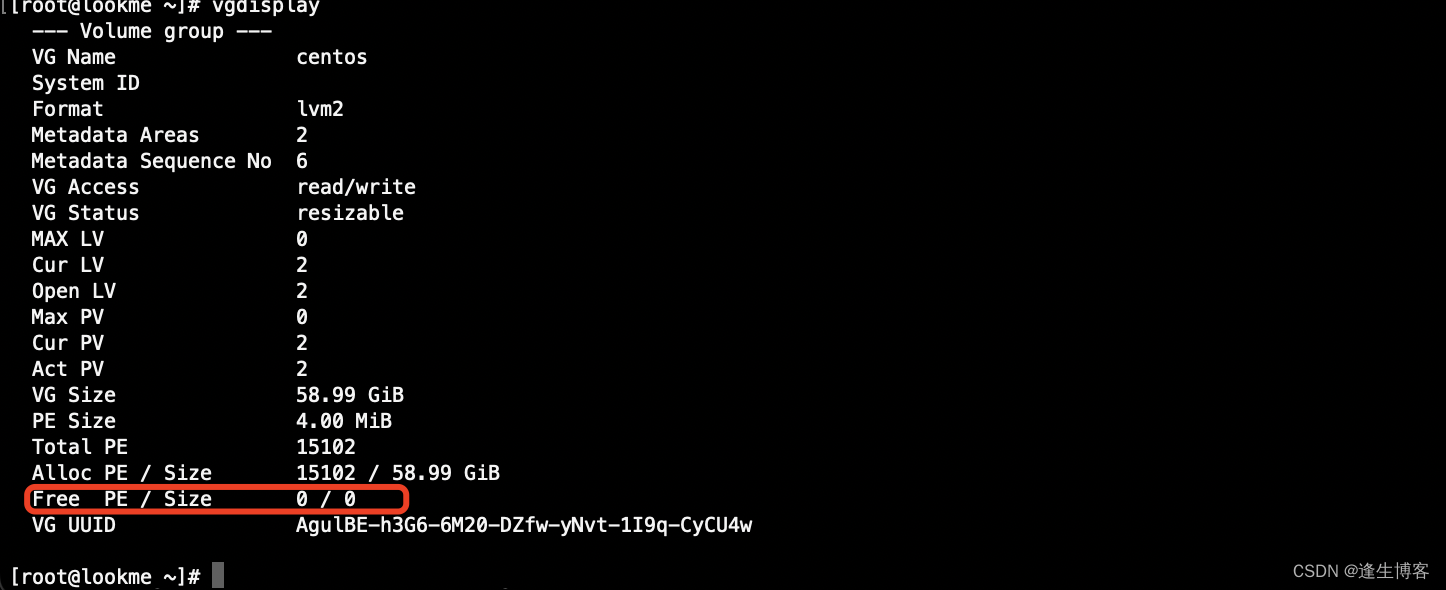
CentOS 磁盘扩容与创建分区
文章目录 未分配空间创建新分区重启服务器添加物理卷扩展逻辑卷 操作前确认已给服务器增加硬盘或虚拟机已修改硬盘大小(必须重启服务才会生效)。 未分配空间 示例说明:原服务器只有40G,修改虚拟机硬盘大小再增加20G后硬盘变为60G。…...

Java面试八股之什么是Java反射
什么是Java反射 基本概念 反射是Java语言的一个重要特性,它允许我们在运行时分析类、接口、字段、方法等组件的信息,并能够动态地操作这些组件,包括创建对象、调用方法、访问和修改字段值等。简单来说,反射提供了在程序运行时对…...

VM振弦采集模块精度实测:从标准信号源到误差分析全流程
1. 项目概述与核心价值最近在做一个岩土工程安全监测的项目,其中有个环节让我琢磨了好一阵子:如何准确地评估我们用的那批VM振弦采集模块的测量精度。这玩意儿在结构健康监测、桥梁隧道、边坡稳定性监测里用得非常多,核心任务就是读取振弦式传…...

企业级Agent开发保姆级教程:从入门到交付,看这一篇就够了
一、背景介绍及核心要点企业级Agent开发正在从探索期迅速迈向规模化落地期。2023年Gartner在最新AI成熟度曲线报告中指出,超过68%的全球大型企业已将多Agent协同列入未来3年核心投资清单。首先,Agent已不再是单一对话机器人,而是集成RAG知识库…...

1987年7月14日晚上19-21点出生性格、运势和命运
1987年6月28日,距离二十四节气中的“小暑”(通常在7月6-8日)约8-10天。小暑意为“天气开始炎热但未到极致”,是盛夏的序曲。这个时节的哲学,与个人成长有着奇妙的呼应。性格的“小暑特质”:温润与韧性 小暑…...

福建话TTS落地难?手把手教你绕过ElevenLabs官方未公开的闽东方言/莆仙话语音注入方案,限时可复现
更多请点击: https://kaifayun.com 第一章:福建话TTS落地难?手把手教你绕过ElevenLabs官方未公开的闽东方言/莆仙话语音注入方案,限时可复现 ElevenLabs 官方 API 当前仅支持普通话、粤语等主流中文变体,对闽东方言&a…...

Minecraft性能监控终极指南:如何用Spark快速诊断服务器卡顿
Minecraft性能监控终极指南:如何用Spark快速诊断服务器卡顿 【免费下载链接】spark A performance profiler for Minecraft clients, servers, and proxies. 项目地址: https://gitcode.com/gh_mirrors/spark6/spark Minecraft服务器性能优化一直是管理员面临…...

Magma高可用部署:如何构建企业级可靠网络基础设施
Magma高可用部署:如何构建企业级可靠网络基础设施 【免费下载链接】magma Platform for building access networks and modular network services 项目地址: https://gitcode.com/gh_mirrors/mag/magma Magma是构建接入网络和模块化网络服务的强大平台&#…...

【大模型12步学习路线 · 第12步 · ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM看懂Spec
【大模型12步学习路线 第12步 ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM"看懂"Spec 时序图 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ①原理篇 —— 最后一步,Veri-Copilot v1.0 大结局。 前…...
进程篇·三:深度硬核!全面起底 Linux 进程状态变化与内核链表动态解绑)
Re: Linux系统篇(十八)进程篇·三:深度硬核!全面起底 Linux 进程状态变化与内核链表动态解绑
◆ 博主名称: 晓此方-CSDN博客 大家好,欢迎来到晓此方的博客。 ⭐️Linux系列个人专栏: 【主题曲】Linux ⭐️此方的GitHub: github_此方 ⭐️Re系列专栏:我们思考 (Rethink) 我们重建 (Rebuild) 我们记录 (Record…...

奇门对接顺丰电子面单:从200行“祖传代码”到优雅重构的经验分享
一、背景:那年写下的“能跑就行” 在我们的电商WMS系统中,发货环节需要通过菜鸟奇门电子面单接口向顺丰等快递公司申请运单号。这段核心代码写于多年前,当时的业务需求比较简单:只支持淘宝/天猫订单,快递也只有顺丰。…...

为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端 在构建基于OpenClaw的复杂自动化工作流时,一个稳定且模型…...