【MySQL】分组排序取每组第一条数据
需求:MySQL根据某一个字段分组,然后组内排序,最后每组取排序后的第一条数据。
准备表:
CREATE TABLE `t_student_score` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',`stu_name` varchar(32) NOT NULL COMMENT '学生姓名',`course_name` varchar(32) NOT NULL COMMENT '课程名称',`score` int(11) NOT NULL COMMENT '份数',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='学生-分数';
准备数据:
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (1, '张三', '数学', 90);
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (2, '李四', '语文', 94);
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (3, '张三', '语文', 98);
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (4, '李四', '数学', 97);
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (5, '李四', '英语', 99);
INSERT INTO `t_student_score` (`id`, `stu_name`, `course_name`, `score`) VALUES (6, '张三', '英语', 100);
数据如下:
mysql> select * from t_student_score;
+----+----------+-------------+-------+
| id | stu_name | course_name | score |
+----+----------+-------------+-------+
| 1 | 张三 | 数学 | 90 |
| 2 | 李四 | 语文 | 94 |
| 3 | 张三 | 语文 | 98 |
| 4 | 李四 | 数学 | 97 |
| 5 | 李四 | 英语 | 99 |
| 6 | 张三 | 英语 | 100 |
+----+----------+-------------+-------+
6 rows in set (0.08 sec)
要求:查询出各科分数最高的学生姓名。
group by
查询出各科分数最高的学生姓名一开始可能会这样写:
select stu_name,course_name,max(score) from t_student_score group by course_name;
sql中只是简单的按课程进行分组,这样写就会导致一个问题也就是查询出来的各科最高分数可能不是那个学生的,结果如下:
mysql> select stu_name,course_name,max(score) from t_student_score group by course_name;
+----------+-------------+------------+
| stu_name | course_name | max(score) |
+----------+-------------+------------+
| 张三 | 数学 | 97 |
| 李四 | 英语 | 100 |
| 李四 | 语文 | 98 |
+----------+-------------+------------+
3 rows in set (0.05 sec)
很明显数学得97分的压根就不是张三,这是为什么呢,group by后的显示的列会只会根据所有组的第一行来显示,张三刚好在数学组的第一行,所以出来的是张三。
group by+子查询order by
既然我们知道group by后的显示的列会只会根据所有组的第一行来显示,那么我们先根据分数进行排序,这样分数最高的肯定是所有组的第一行,然后根据课程进行分组这样是不是就对了?
mysql> select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----------+-------------+------------+
| stu_name | course_name | max(score) |
+----------+-------------+------------+
| 张三 | 数学 | 97 |
| 李四 | 英语 | 100 |
| 李四 | 语文 | 98 |
+----------+-------------+------------+
3 rows in set (0.13 sec)
什么情况,以前我怎么记得这么使用是对的呢?然后去查看SQL的执行计划:
mysql> explain select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | SIMPLE | t_student_score | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using temporary; Using filesort |
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
1 row in set (0.06 sec)执行计划显示只有一个步骤,为什么不是分为两个步骤执行呢?第一步先根据表t_student_score的score字段进行倒序排序,第二步根据第一步生成的临时表t的course_name字段进行分组???
而在MySQL5.6中,执行上面的sql会出现不一样的结果:
mysql> select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----------+-------------+------------+
| stu_name | course_name | max(score) |
+----------+-------------+------------+
| 李四 | 数学 | 97 |
| 张三 | 英语 | 100 |
| 张三 | 语文 | 98 |
+----------+-------------+------------+
3 rows in set (0.10 sec)
MySQL5.6中返回的结果正是我们想要的。
再来看下MySQL5.6中这个SQL的执行计划:
mysql> explain select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----+-------------+-----------------+------+---------------+------+---------+------+------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------------+------+---------------+------+---------+------+------+---------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 6 | Using temporary; Using filesort |
| 2 | DERIVED | t_student_score | ALL | NULL | NULL | NULL | NULL | 6 | Using filesort |
+----+-------------+-----------------+------+---------------+------+---------+------+------+---------------------------------+
2 rows in set (0.09 sec)
MySQL5.6中这个SQL的执行计划分为两个步骤执行的。
那么为什么切换了版本后就好了呢?
derived_merge
MySQL5.7针对于5.6版本做了一个优化,针对MySQL本身的优化器增加了一个控制优化器的参数叫derived_merge,什么意思呢,“派生类合并”。
官方文档介绍:https://dev.mysql.com/doc/refman/5.7/en/derived-table-optimization.html
使用合并或实现来优化派生表和视图引用优化器可以使用两种策略(也适用于视图引用)处理派生表引用:
- 将派生表合并到外部查询块中
- 将派生表实现为内部临时表
例如:
SELECT * FROM (SELECT *FROM t1) AS derived_t1
通过合并派生表derived_t1,该查询的执行类似于:
SELECT * FROM t1;
原来是派生类合并在作怪,通过对MySQL官方使用手册的了解,MySQL5.7对derived_merge参数默认设置为on,也就是开启状态,我们在MySQL5.7中把这个特性关闭使用就行了,如下命令:
# 针对当前session关闭
set session optimizer_switch="derived_merge=off";# 全局关闭
set global optimizer_switch="derived_merge=off";
这样如果from中查询出来的的结果就不会与外部查询块合并了,sql执行结果如下:
mysql> set session optimizer_switch="derived_merge=off";
Query OK, 0 rows affected (0.01 sec)mysql> select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----------+-------------+------------+
| stu_name | course_name | max(score) |
+----------+-------------+------------+
| 李四 | 数学 | 97 |
| 张三 | 英语 | 100 |
| 张三 | 语文 | 98 |
+----------+-------------+------------+
3 rows in set (0.07 sec)mysql> explain select stu_name,course_name,max(score) from (select * from t_student_score order by score desc) t group by course_name;
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using temporary; Using filesort |
| 2 | DERIVED | t_student_score | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using filesort |
+----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
2 rows in set (0.10 sec)
其实修改derived_merge参数得谨慎而行之,因为MySQL5.7版本有了这个优化的机制是有它的道理的,之所以去除派生类与外部块合并,是因为减少查询开销,派生类是个临时表,开辟一个临时表的同时还要维护和排序或者分组,都会影响效率,所以尽量不要去修改此参数。
其实也有多种办法不需要修改derived_merge参数而使合并派生类失效,具体做法可参考官方使用手册,可以通过在子查询中使用任何阻止合并的构造来禁用合并,尽管这些构造对实现的影响并不明确。
防止合并的构造对于派生表和视图引用是相同的:
- 聚合函数(SUM(),MIN(),MAX(),COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- LIMIT
- UNION或UNION ALL
- 选择列表中的子查询
- 分配给用户变量
- 仅引用文字值(在这种情况下,没有基础表)
下面通过在子查询中使用distinct关键字来禁用derived_merge:
mysql> explain select stu_name,course_name,max(score) from (select distinct(id) tid,s.* from t_student_score s order by score desc) t group by course_name;
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using temporary; Using filesort |
| 2 | DERIVED | s | NULL | ALL | NULL | NULL | NULL | NULL | 6 | 100.00 | Using filesort |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+---------------------------------+
2 rows in set (0.08 sec)
子查询order by失效的场景
因为临时表(派生表derived table)中使用order by且使其生效,必须满足三个条件:
- 外部查询禁止分组或者聚合
- 外部查询未指定having, order by
- 外部查询将派生表或者视图作为from句中唯一指定源
不满足这三个条件,order by会被忽略。
一旦外部表使用了group by,那么临时表(派生表 derived table)将不会执行filesort操作(即order by 会被忽略)。
相关文章:

【MySQL】分组排序取每组第一条数据
需求:MySQL根据某一个字段分组,然后组内排序,最后每组取排序后的第一条数据。 准备表: CREATE TABLE t_student_score (id int(11) NOT NULL AUTO_INCREMENT COMMENT ID,stu_name varchar(32) NOT NULL COMMENT 学生姓名,course…...

滚珠螺杆在精密机械设备中如何维持精度要求?
滚珠螺杆在精密设备领域中的运用非常之广泛,具有精度高、效率高的特点。为了确保滚珠螺杆在生产设备中能够发挥最佳性能,我们必须从多个维度进行深入考量,并采取针对性的措施,以确保其稳定、精准地服务于现代化生产的每一个环节。…...

现代 c++ 三:右值引用与移动语义
c11 为了提高效率,引入了右值引用及移动语义,这个概念不太好理解,需要仔细研究一下,下文会一并讲讲左值、右值、左值引用、右值引用、const 引用、移动构造、移动赋值运行符 … 这些概念。 左值和右值 左值和右值是表达式的属性。…...
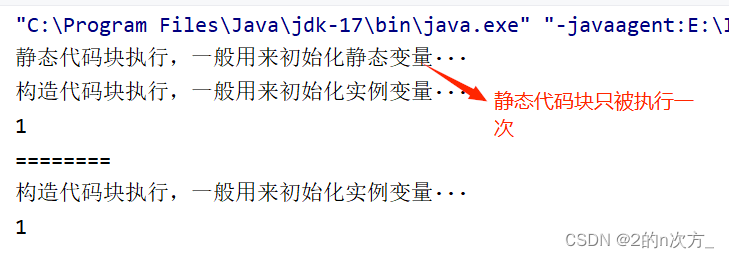
Java学习【类与对象—封装】
Java学习【类与对象—封装】 封装的概念封装的实现包的概念import 导包导包中*的介绍import static 导入包中的静态方法和字段 static关键字的使用static 修饰成员变量static修饰方法静态成员变量的初始化 代码块静态代码块非静态代码块/实例化代码块/构造代码块加载顺序 封装的…...
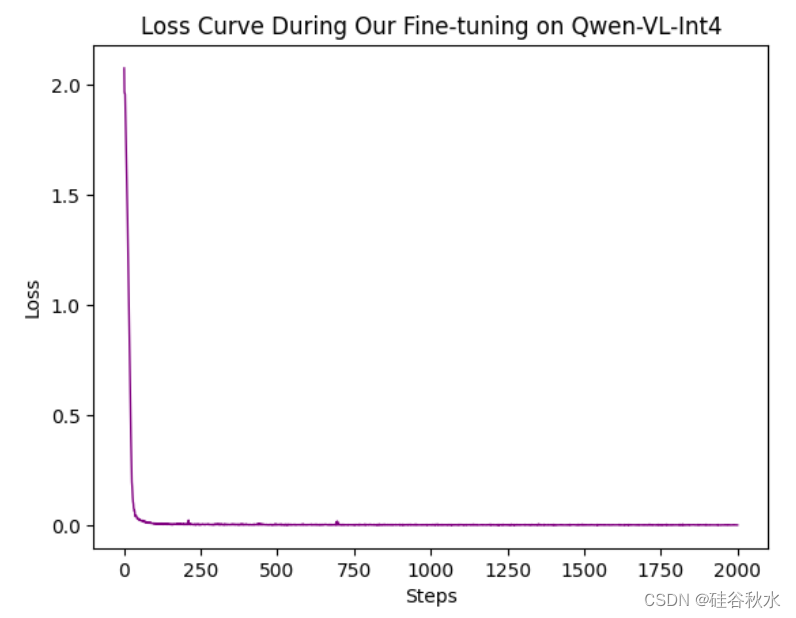
Co-Driver:基于 VLM 的自动驾驶助手,具有类人行为并能理解复杂的道路场景
24年5月来自俄罗斯莫斯科研究机构的论文“Co-driver: VLM-based Autonomous Driving Assistant with Human-like Behavior and Understanding for Complex Road Scenes”。 关于基于大语言模型的自动驾驶解决方案的最新研究,显示了规划和控制领域的前景。 然而&…...

硅胶可以镭射吗?
在科技发展的今天,我们经常会遇到各种各样的材料,其中就有一种叫做硅胶的材料。那么,硅胶可以镭射吗?答案是肯定的,硅胶不仅可以镭射,而且在某些应用中,它的镭射特性还非常突出。 首先ÿ…...

财务风险管理:背后真相及应对策略
市场经济蓬勃发展,机遇与风险并存也是市场经济的一项重要特征。而财务状况的好坏影响着一个企业的发展前景,作为市场经济的必然产物,财务风险贯穿于企业的一切生产经营活动中,无法预知也不以人的意志为转移。 一、企业财务风险的特…...
)
MySQL深入理解事务(详解)
事务概述 事务是数据库区别于文件系统的重要特性之一,当我们有了事务就会让数据库始终保持一致性,同时我们还能通过事务机制恢复到某个时间点,这样可以保证已提交到数据库的修改不会因为系统崩溃而丢失。 1、基本概念 事务:一组…...
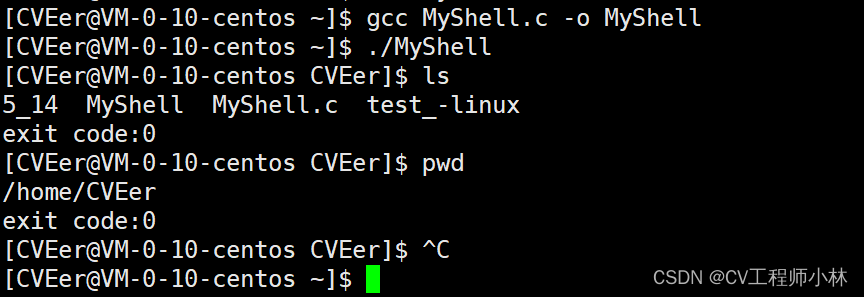
【Linux系统】进程控制
本篇博客整理了进程控制有关的创建、退出、等待、替换操作方面的知识,最终附有模拟实现命令行解释器shell来综合运用进程控制的知识,旨在帮助读者更好地理解进程与进程之间的交互,以及对开发有一个初步了解。 目录 一、进程创建 1.创建子进…...

Go语言数值类型教程
Go语言提供了丰富的数值类型,包括整数类型、浮点类型和复数类型。每种类型都有其特定的用途和存储范围。下面将详细介绍这些类型,并附带示例代码。 原文链接: Go语言数值类型教程 - 红客网-网络安全与渗透技术 1. 整数类型 原文链接…...

Linux进程控制——Linux进程等待
前言:接着前面进程终止,话不多说我们进入Linux进程等待的学习,如果你还不了解进程终止建议先了解: Linux进程终止 本篇主要内容: 什么是进程等待 为什么要进行进程等待 如何进程等待 进程等待 1. 进程等待的概念2. 进…...

GPT-4o:融合文本、音频和图像的全方位人机交互体验
引言: GPT-4o(“o”代表“omni”)的问世标志着人机交互领域的一次重要突破。它不仅接受文本、音频和图像的任意组合作为输入,还能生成文本、音频和图像输出的任意组合。这一全新的模型不仅在响应速度上达到了惊人的水平,在文本、音频和图像理解方面也表现出色,给人带来了…...

灵活的静态存储控制器 (FSMC)的介绍(STM32F4)
目录 概述 1 认识FSMC 1.1 应用介绍 1.2 FSMC的主要功能 1.2.1 FSMC用途 1.2.2 FSMC的功能 2 FSMC的框架结构 2.1 AHB 接口 2.1.1 AHB 接口的Fault 2.1.2 支持的存储器和事务 2.2 外部器件地址映射 3 地址映射 3.1 NOR/PSRAM地址映射 3.2 NAND/PC卡地址映射 概述…...

nginx-rtmp
1.已经安装nginx;configure配置模块;make编译无需安装;把objs/nginx复制到已安装的宁目录下 ./configure --prefix/usr/local/nginx --add-module/usr/local/src/fastdfs-nginx-module/src --add-module/usr/local/src/nginx-rtmp-module-mas…...

nginx 代理java 请求报502
情况:nginx代理java 请求 后端返回正常,但是经过nginx 时报502 经过多次对比其他接口发现可能是返回的请求头过大,导致nginx 报错:如下 2024/05/13 02:57:12 [error] 88#88: *3755 upstream sent too big header while reading r…...
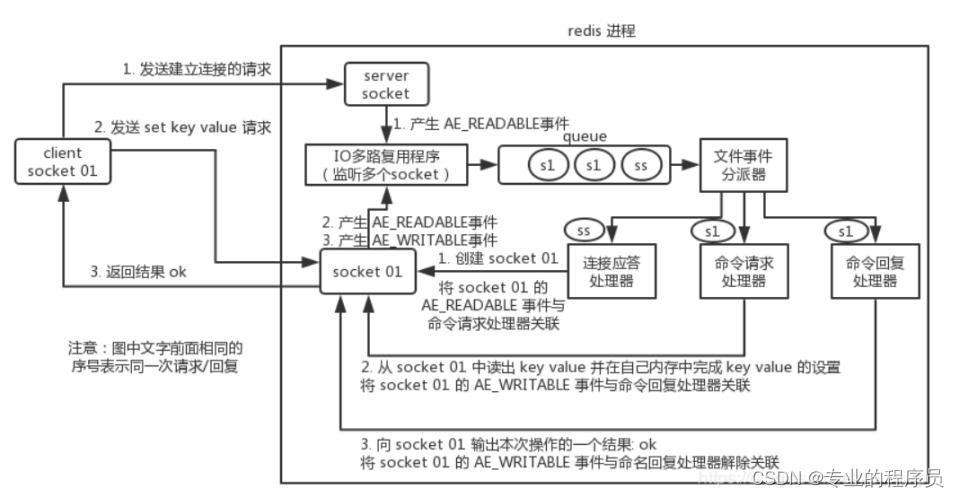
面试集中营—Redis面试题
一、Redis的线程模型 Redis是基于非阻塞的IO复用模型,内部使用文件事件处理器(file event handler),这个文件事件处理器是单线程的,所以Redis才叫做单线程的模型,它采用IO多路复用机制同时监听多个socket&a…...
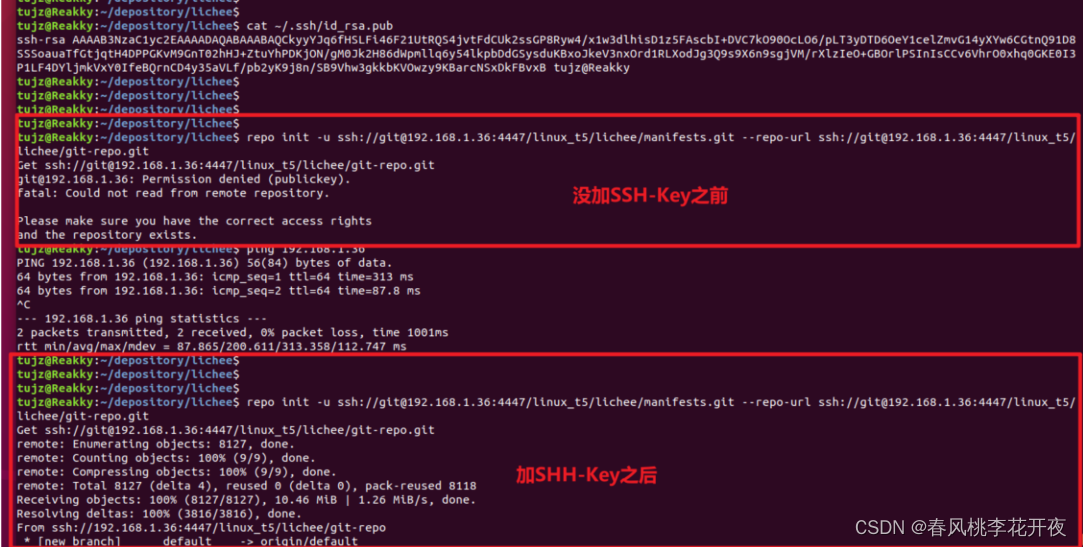
关于使用git拉取gitlab仓库的步骤(解决公钥问题和pytho版本和repo版本不对应的问题)
先获取权限,提交ssh-key 虚拟机连接 GitLab并提交代码_gitlab提交mr-CSDN博客 配置完成上诉步骤之后,执行下列指令进行拉去仓库的内容 sudo apt install repo export PATHpwd/.repo/repo:$PATH python3 "实际路径"/repo init -u ssh://gitxx…...
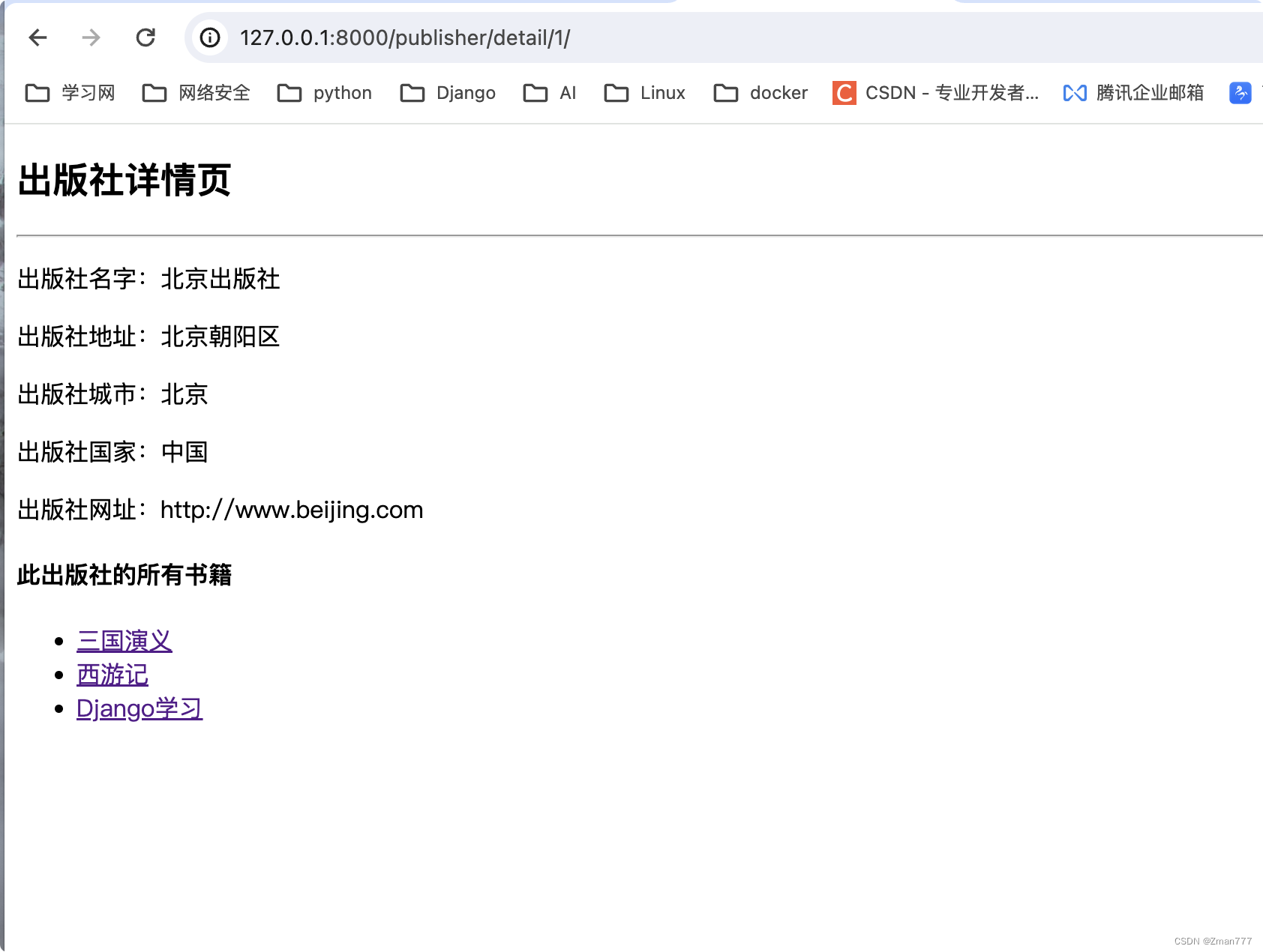
Django图书馆综合项目-学习(2)
接下来我们来实现一下图书管理系统的一些相关功能 1.在书籍的book_index.html中有一个"查看所有书毂"的超链接按钮,点击进入书籍列表book_list.html页面. 这边我们使用之前创建的命名空间去创建超连接 这里的book 是在根路由创建的namespacelist是在bo…...

vue3+ts 获取input 输入框中的值
从前端input 输入框获取值,通过封装axios 将值传给后端服务 数据格式为json html <el-form> <el-form-item label"域名"><el-input v-model"short_url" style"width: 240px"type"text"placeholder&quo…...

Gin框架返回Protobuf类型:提升性能的利器
在构建高效、高性能的微服务架构时,数据序列化和反序列化的性能至关重要。Protocol Buffers(简称Protobuf)作为一种轻量级且高效的结构化数据存储格式,已经在众多领域得到广泛应用。Gin框架作为Go语言中流行的Web框架,…...

RK3588 Android系统签名实战:为APK获取系统权限完整指南
1. 项目概述与核心价值在嵌入式Android开发领域,尤其是基于瑞芯微(Rockchip)平台如RK3588进行产品研发时,我们常常会遇到一个核心需求:如何让一个普通的第三方APK应用,获得系统级(System&#x…...

GitHub史诗级泄露:3800个核心仓库被窃,TeamPCP如何通过VS Code扩展攻破全球最大代码平台
一、引言:全球开发者的至暗时刻 2026年5月20日,一则消息震惊了整个科技界:微软旗下全球最大代码托管平台GitHub确认,约3800个内部私有仓库被威胁组织TeamPCP窃取,涵盖GitHub Copilot、CodeQL、GitHub Actions、Codespa…...

技术人的人际关系:建立良好的职业网络
技术人的人际关系:建立良好的职业网络 引言 作为一名技术人,人际关系同样重要。良好的人际关系可以帮助我们获得更多机会,提升职业发展。 今天就来分享一下如何建立良好的职业网络。 为什么人际关系重要 职业发展 良好的人际关系有助于职业发…...

日薪2700的护网HW面试,以及HW全面熟悉必看流程
前言 参与hvv的事情还是要想办法规避掉很多坑的。网络安全这个行业现阶段还是主要政策驱动,后面应该是客户意识,现在用户教育成本明显比以前低太多。 1.关于HVV的一个简单流程 首先我带大家从甲方和厂商的角度来分解一下整个护网流程的核心逻辑 第一阶段…...

OpenClaw+Hermes +Vibe Coding本地部署|论文自动化|知识工作流
在人工智能快速重塑科研范式的背景下,大语言模型、Agent系统与自动化科研工作流,正在深刻改变文献阅读、代码开发、数据分析、论文写作与科研协作的底层方式。面对模型快速迭代、工具形态持续演进的新局面,科研人员亟需从“会使用AI”进一步升…...

如何在Python中实现轻量级人脸与虹膜检测:基于TensorFlow Lite的解决方案
如何在Python中实现轻量级人脸与虹膜检测:基于TensorFlow Lite的解决方案 【免费下载链接】face-detection-tflite Face and iris detection for Python based on MediaPipe 项目地址: https://gitcode.com/gh_mirrors/fa/face-detection-tflite 在当今的计…...

家庭宽带上网背后的隐形功臣:一文拆解光猫/路由器里的NAT和DHCP是怎么协同工作的
家庭网络中的隐形守护者:NAT与DHCP如何编织你的数字生活 当你躺在沙发上用手机追剧时,是否想过为什么所有家庭设备都能和平共处在同一网络?192.168.1.x这串神秘数字背后,藏着两套精密的协议系统——它们像建筑物的水电管线般隐形却…...

为什么你的蓝晒图总像“褪色老照片”?3个被忽略的--stylize权重陷阱,今晚失效前速查
更多请点击: https://kaifayun.com 第一章:蓝晒法的光学本质与数字转译悖论 蓝晒法(Cyanotype)作为一种1842年诞生的古典摄影工艺,其核心依赖于铁盐在紫外光照射下发生的光还原反应:柠檬酸铁铵与铁氰化钾…...

2026别错过!一键生成论文工具深度测评与推荐
2026年真正好用的一键生成论文工具,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。…...

Servlet 容器与过滤器 超详细讲解
目录 一、Servlet 容器(Servlet Container) 1. 是什么? 2. 核心作用(必须掌握) 3. Servlet 生命周期(容器全权控制) 4. 工作流程(HTTP 请求完整链路) 5. 总结一句话 二、过滤器(Filter) 1. 是什么? 2. 核心特点 3. 过滤器能做什么?(高频场景) 4. 过滤…...