【RAG 论文】UPR:使用 LLM 来做检索后的 re-rank
论文:Improving Passage Retrieval with Zero-Shot Question Generation
⭐⭐⭐⭐
EMNLP 2022, arXiv:2204.07496
Code: github.com/DevSinghSachan/unsupervised-passage-reranking
论文:Open-source Large Language Models are Strong Zero-shot Query Likelihood Models for Document Ranking
⭐⭐⭐⭐
EMNLP 2023, arXiv:2310.13243
Code: github.com/ielab/llm-qlm
一、UPR 论文速读
关于 Improving Passage Retrieval with Zero-Shot Question Generation 这篇论文
论文提出了一个基于 LLM 的 re-ranker:UPR(Unsupervised Passage Re-ranker),它不需要任何标注数据用于训练,只需要一个通用的 PLM(pretrained LM),并且可以用在多种类型的检索思路上。
给定一个 corpus 包含所有的 evidence documents,给定一个 question,由 Retriever 来从 corpus 中检索出 top-K passages,re-ranker 的任务就是把这 K 个 passages 做重新排序,期待重排后再交给 LLM 做 RAG 能提升效果。
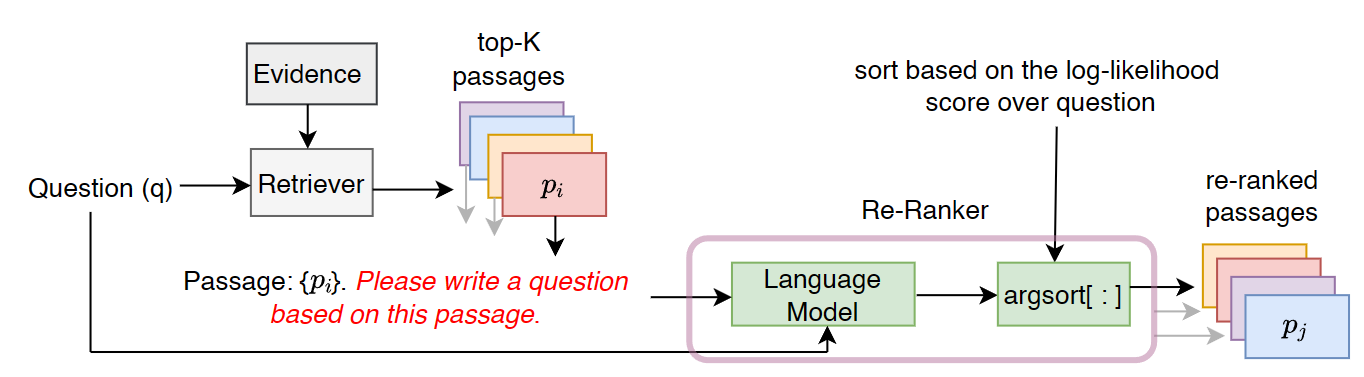
本论文的工作中,使用 LLM 来为每一个 passage 计算一个 relevance score,然后按照 relevance scores 来对这些 passages 做排序。passages z i z_i zi 的 relevance score 的计算方式是:以 passage z i z_i zi 为条件,计算 LLM 生成 question q q q 的 log-likelihood log p ( q ∣ z i ) \log p(q|z_i) logp(q∣zi):
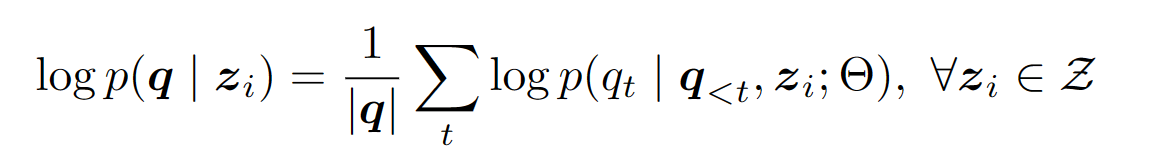
关于为什么使用 p ( q ∣ z ) p(q|z) p(q∣z) 来计算 relevance score 而非用 p ( z ∣ q ) p(z|q) p(z∣q),原因在于在假设 log p ( z i ) \log p(z_i) logp(zi) 是都一样的话,按照 Bayes 公式来算的话, p ( q ∣ z ) p(q|z) p(q∣z) 与 p ( z ∣ q ) p(z|q) p(z∣q) 呈正相关的关系。此外,使用 p(q|z) 允许模型利用交叉注意力机制(cross-attention)在问题和段落之间建立联系。而且实验发现使用 p ( q ∣ z ) p(q|z) p(q∣z) 效果更好。
其实从感性上想一想,也是通过 prompt 让 LLM 去计算 p ( q ∣ z ) p(q|z) p(q∣z) 来建模 question 和 passage 更合理。
二、开源 LLM 本身就是强 zero-shot 的 QLM re-ranker
QLM(Query Likelihood Model) 是指,通过计算特定 question 下 document 的概率来理解 docs 和 queries 的语义关系。QLM re-ranker 就是借助这个概率得出相关性分数从而做出排名,进而实现 re-rank。前面介绍的 UPR 就是一种 QLM re-ranker。
在前面介绍的 UPR 中,使用了 T0 LLM 模型作为 QLM 从而实现了有效的 re-rank,但是由于 T0 在许多 QG(Question Generation) 数据集上做了微调,所以该工作不能完全反映通用的 zero-shot 的 QLM ranking 场景。
本工作研究了使用 LLaMA 和 Falcon 这两个 decoder-only 的模型作为 QLM 来做 re-rank 任务的表现,这两个 LLM 都没有在 QG 数据集上做训练。
2.1 多种 QLM re-ranker
本文工作设计了多种 QLM re-ranker,下面分别做一个介绍。
1)Zero-shot QLM re-ranker
类似于前面 UPR 的做法,借助于 QLM 计算出一个 relevance score,计算方法也一样(以 retrieved doc 为条件的 question 的概率):
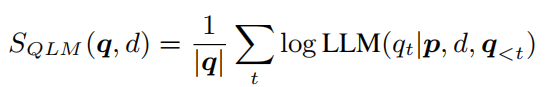
2)BM25 插值的 re-ranker
除了使用 QLM 计算出来的分数 S Q L M S_{QLM} SQLM,还融入第一阶段的检索器 BM25 给出的相关性分数,两者通过权重共同计算最终的 relevance score:
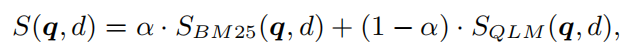
3)Few-shot QLM re-ranker
在前面 zero-shot 的基础上,使用 LLM 时,设计一个 prompt template 并加入一些 few-shot exemplars。
2.2 实验
论文详细介绍了多个实验,感兴趣可以参考原论文,这里列出几个结论:
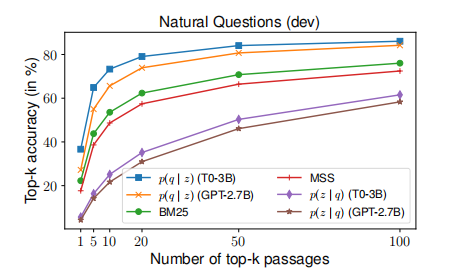
- 在 QG 数据集(NS NARCO 数据集)上微调的 retriever 和 re-ranker 在所有数据集上表现都由于 zero-shot 的 retriever 和 QLM re-ranker,这是意料之中的,因为这些方法会受益于大量人工判断的 QA 训练数据,其知识可以有效地迁移到测试数据集中。
- zero-shot 的 QLM 和经过 QG 指令微调的 QLM 表现出相似的竞争力,这一发现时令人惊讶的,这说明 pretrained-only 的 LLM 就具有强大的 zero-shot QLM 排名的能力。
- 如果 QG 任务没有出现在指令微调的数据中,那么指令微调反而会阻碍 LLM 的 QLM re-rank 能力。猜测原因在于,指令微调的模型往往更关注任务指令,而较少关注输入内容本身,但是评估 Query Likelihood 的最重要信息都在文档内容中,所以指令调优不利用 LLM 的 Query Likelihood 的估计。
- BM25 插值策略的改进究竟有没有用,取决于具体的 LLM 模型。
2.3 一个有效的 ranking pipeline
这篇论文工作(原文 4.3 节)还提出了一个有效的 ranking pipeline。
在第一阶段的 retriever 中,将 BM25 和 HyDE 结合作为 zero-shot first-stage hybird retriever,然后再使用 QLM 做 re-rank。
经过实验发现,这种方法可以与当前 SOTA 模型表现相当,重要的这种方法不需要任何训练。
总结
这两篇论文给了我们使用 LLM 来做 QLM re-rank 的思路,展现了通用的 LLM 本身具备强大的 QLM re-rank 的能力。
相关文章:
【RAG 论文】UPR:使用 LLM 来做检索后的 re-rank
论文:Improving Passage Retrieval with Zero-Shot Question Generation ⭐⭐⭐⭐ EMNLP 2022, arXiv:2204.07496 Code: github.com/DevSinghSachan/unsupervised-passage-reranking 论文:Open-source Large Language Models are Strong Zero-shot Query…...
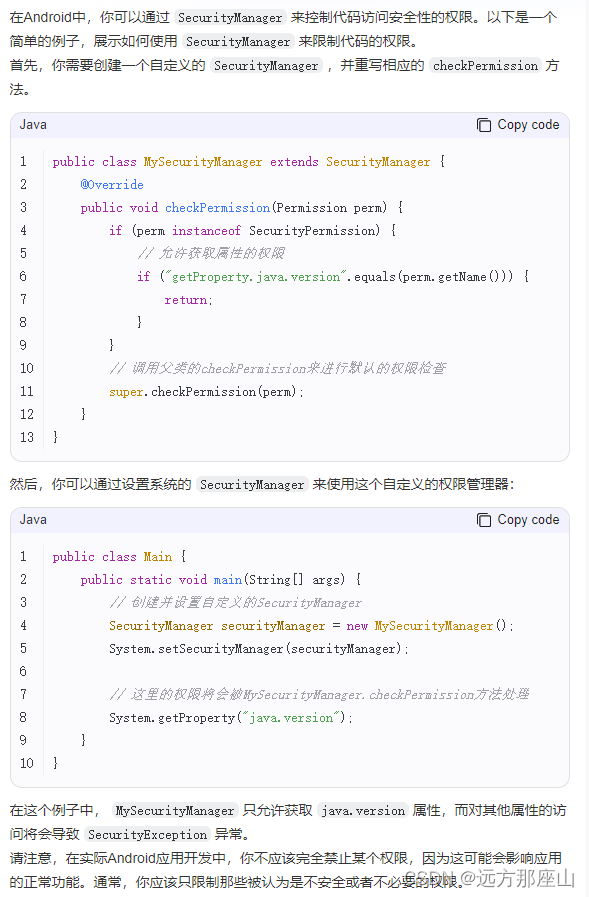
安全风险 - 如何解决 setAccessible(true) 带来的安全风险?
可能每款成熟的金融app上架前都会经过层层安全检测才能执行上架,所以我隔三差五就能看到安全检测报告中提到的问题,根据问题的不同级别,处理的优先级也有所不同,此次讲的主要是一个 “轻度问题” ,个人认为属于那种可改…...

创建继承自QObject的线程:一个详细指南
目录标题 步骤 1:创建一个新的QObject子类步骤 2:在新的QObject子类中实现工作代码步骤 3:创建一个新的QThread对象步骤 4:管理线程的生命周期步骤 5:处理线程间通信结论 在Qt中,线程可以通过继承QThread类…...

java项目之智慧图书管理系统设计与实现(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的智慧图书管理系统设计与实现。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 智慧图书管理…...

分享一些人生道理,希望能对大家有所帮助!
1. 别总想出风头,炫耀就是深渊,贪心就是毁灭,人性的恶一旦被激发,后果不堪设想。 2. 戒取怨之言:不要说招人怨恨的话,播下使人怨恨的种子。 3. 学会感恩,因为感恩能够让你更加幸福。 4. 玉碎不能…...

【设计模式】JAVA Design Patterns——Abstract-document(抽象文档模式)
🔍 目的 使用动态属性,并在保持类型安全的同时实现非类型化语言的灵活性。 🔍 解释 抽象文档模式使您能够处理其他非静态属性。 此模式使用特征的概念来实现类型安全,并将不同类的属性分离为一组接口 真实世界例子 考虑由多个部…...
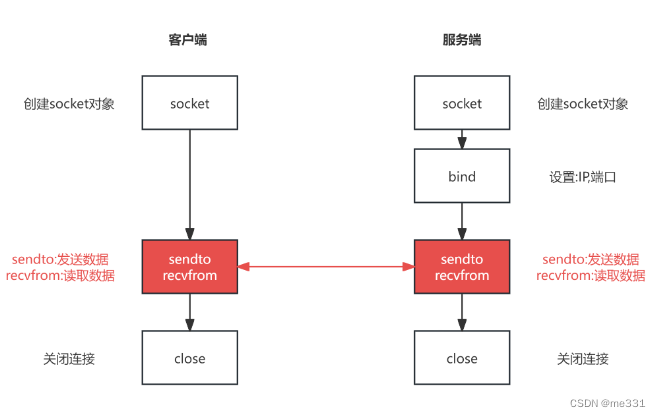
5.13网络编程
只要在一个电脑中的两个进程之间可以通过网络进行通信那么拥有公网ip的两个计算机的通信是一样的。但是一个局域网中的两台电脑上的虚拟机是不能进行通信的,因为这两个虚拟机在电脑中又有各自的局域网所以通信很难实现。 socket套接字是一种用于网络间进行通信的方…...

那些年使用过的UA头
一些WAF会根据扫描器UA头进行屏蔽 UA头 在sqlmap 中可以使用 –random-agnet /xx.txt 来更换UA头 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 Opera/8.0 (Windows NT 5.1; U; en) Mozi…...

IT技术产品:开发者极为重要的思维习惯
1、特色内容预告 1、我用敏捷开发思维,提高工作效率。 2、我用代码批判思维,逐渐让自己的作品变得无可挑剔。 3、我是一个顶级程序员,是哪些重要的专业习惯,让我如此优秀? 2、可以免费获取到的IT资源 1、《软件工程&a…...

软件产品质量模型及其子特性
一、功能性 子特性: 功能的完备性 功能正确性 功能适合性 功能性的依从性 二、性能效率 子特性: 时间特性 资源利用性 容量 性能效率的依从性 三、兼容性 子特性: 共存性 互操作性 兼容性的依从性 四、易用性 子特性: 可辨识性…...
方法理解)
神经网络中的误差反向传播(Backpropagation)方法理解
想象一下,神经网络就像是一个复杂的迷宫,里面有许多交叉路口(神经元),每个路口都有指示牌告诉你往哪个方向走(权重),而你的目标是找到从入口到出口的最佳路径,使得从起点…...

Day 32 shell变量及运算
一:变量概述 1.什么是变量 变量来源于数学,是计算机语言中能储存计算结果或能表示值的抽象概念 变量可以通过变量名访问,在指令式语言中,变量通常是可变的;在某些条件下也是不可变的 2.变量的规则 命名只…...

八、VUE内置指令
一、初识VUE 二、再识VUE-MVVM 三、VUE数据代理 四、VUE事件处理 五、VUE计算属性 六、Vue监视属性 七、VUE过滤器 七、VUE内置指令 九、VUE组件 v-text 向其所在的节点中渲染文本内容。 (纯文本渲染)与插值语法的区别:v-text会替换掉节点中的内容,{{x…...

学习笔记:IEEE 1003.13-2003【POSIX PSE53接口列表】
一、POSIX PSE53接口列表 根据IEEE 1003.13-2003,整理了POSIX PSE53接口API(一共126个),每个API支持链接查看。 IEEE POSIX接口online搜索链接: The Open Group Base Specifications Issue 7, 2018 edition 详细内…...

springboot logback 日志注入安全问题 统一处理
背景 日志注入一般指的是恶意用户输出换行等内容,混淆正常的日志,导致排查问题是无法正确定位问题,因此,我们需要对要打印的日志内容进行过滤。 但是,如果是每个接口单独处理的话,成本较高,因此…...
-Squid代理服务器)
linux进阶高级配置,你需要知道的有哪些(13)-Squid代理服务器
1、squid代理的作用:缓存网页对象,减少重复请求 2、代理的基本类型 传统代理:适用于Internet互联网,需明确指定服务端(浏览器需要配置) 透明代理:适用于共享上网网关,不需要指定服务…...

SpringBoot自动装配(二)
近日,余溺于先贤古哲之文无法自拔。虽未明其中真意,但总觉有理。遂抄录一篇以供诸君品鉴——公孙鞅曰:“臣闻之:‘疑行无名,疑事无功。’君亟定变法之虑,殆无顾天下之议之也。且夫有高人之行者,…...
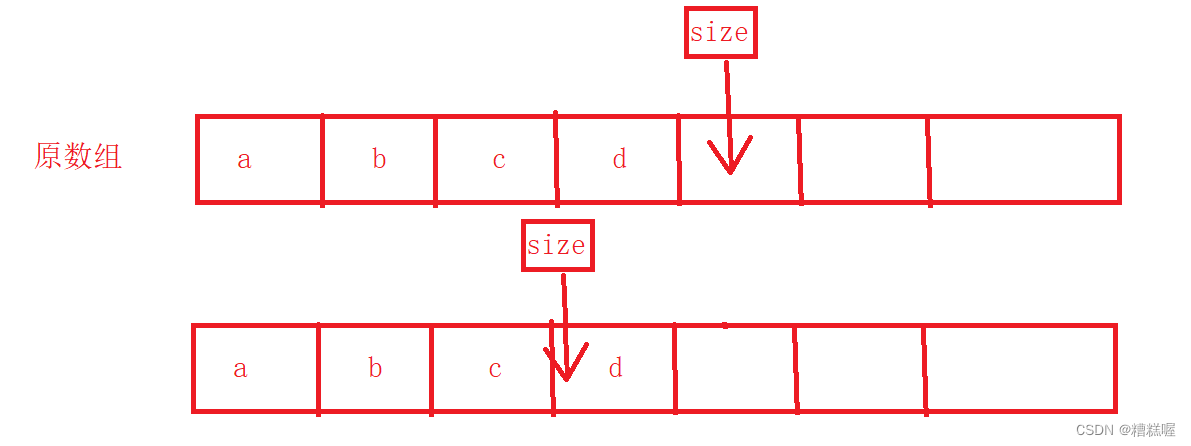
数据结构 顺序表1
1. 何为顺序表: 顺序表是一种线性数据结构,是由一组地址连续的存储单元依次存储数据元素的结构,通常采用数组来实现。顺序表的特点是可以随机存取其中的任何一个元素,并且支持在任意位置上进行插入和删除操作。在顺序表中…...

C++基础-编程练习题1
文章目录 一、哥德巴赫猜想二、哥德巴赫猜想2三、打印成绩单四、成绩输入输出五、数组输出奇数位偶数位 一、哥德巴赫猜想 【试题描述】 哥德巴赫提出了以下的猜想:任何一个大于 2 的偶数都可以表示成 2 个质数之和。 质数是指除了 1 和本身之外没有其他约数的数&a…...

四十九坊股权设计,白酒新零售分红制度,新零售策划机构
肆拾玖坊商业模式 | 白酒新零售体系 | 新零售系统开发 坐标:厦门,我是易创客肖琳 深耕社交新零售行业10年,主要提供新零售系统工具及顶层商业模式设计、全案策划运营陪跑等。 不花钱开3000多家门店,只靠49个男人用一套方法卖白酒…...

JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现
JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现 【免费下载链接】jmeter-grpc-request JMeter gRPC Request load test plugin for gRPC 项目地址: https://gitcode.com/gh_mirrors/jm/jmeter-grpc-request 随着微服务架构的普及,gRPC已…...

大学英语四级试卷历年真题及答案PDF电子版百度网盘
大学英语四级备考必备历年真题合集(2015年6月-2025年12月),高清 PDF 电子版含完整试卷与详细答案解析,以及配套听力音频,题型齐全答案详实,可下载打印刷题,吃透真题考点,高效冲刺顺利…...

AI时代Geo优化:深度解析阶段、工作与实战SOP
引言在生成式人工智能(Generative AI)浪潮的推动下,数字内容生态正经历一场深刻的变革。传统的搜索引擎优化(SEO)已然演进为生成式引擎优化(Generative Engine Optimization, 简称GEO)ÿ…...
:含ISO 200/400/800三档真实胶片响应曲线)
【限时解密】Midjourney范戴克印相私藏LUT包+预设Prompt库(仅开放48小时):含ISO 200/400/800三档真实胶片响应曲线
更多请点击: https://kaifayun.com 第一章:Midjourney范戴克印相的美学溯源与数字复刻逻辑 范戴克印相(Van Dyke Brown process)诞生于19世纪末,是一种以硝酸银、柠檬酸铁铵与酒石酸钾钠配制感光液,经紫外…...

AI原生组织:从「加AI功能」到「长AI基因」,大企业实践与中小团队轻量思路揭秘
AI原生组织:从「加AI功能」到「长AI基因」的本质跃迁与落地路径AI原生组织并非给传统企业贴AI膏药,而是围绕人机协同重新设计业务逻辑、组织架构和激励机制。下面从认知误区切入,结合阿里、华为、传神等企业案例,拆解AI原生组织的…...

Java Map集合详解与实战
集合进阶(Map集合)一、Map集合1.1 Map概述体系各位同学,前面我们已经把单列集合学习完了,接下来我们要学习的是双列集合。首先我们还是先认识一下什么是双列集合。所谓双列集合,就是说集合中的元素是一对一对的。格式:…...

SPSS虚拟变量避坑指南:创建后如何正确用于回归分析?别让编码错误毁了你的模型
SPSS虚拟变量实战避坑:从编码到回归分析的完整解决方案 在数据分析领域,虚拟变量(Dummy Variable)是将分类变量转换为可用于回归分析形式的桥梁。许多研究者虽然掌握了SPSS生成虚拟变量的基础操作,却在后续分析中频频…...

光电效应实验避坑指南:从汞灯预热到遏止电压判读,新手常犯的5个错误
光电效应实验避坑指南:从汞灯预热到遏止电压判读的5个关键误区 在大学的物理实验室里,光电效应实验就像一位性格古怪的教授——看似简单明了,实则暗藏玄机。许多同学满怀信心地走进实验室,却在数据采集阶段屡屡碰壁,最…...

告别手动写Testbench!用Quartus II + ModelSim自动生成仿真模板的保姆级教程
Quartus II ModelSim自动化测试框架实战:从零构建高效数字电路验证流程 在数字电路设计领域,验证工作往往消耗工程师60%以上的开发时间。传统手动编写Testbench的方式不仅效率低下,还容易引入人为错误。Altera Quartus II内置的Test Bench T…...

5分钟搞定专业网络拓扑图:easy-topo终极使用指南
5分钟搞定专业网络拓扑图:easy-topo终极使用指南 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 还在为绘制复杂的网络架构图而头疼吗?网络拓扑图是网络工程师、系统管…...