【机器学习】:基于决策树与随机森林对数据分类
机器学习实验报告:决策树与随机森林数据分类
实验背景与目的
在机器学习领域,决策树和随机森林是两种常用的分类算法。决策树以其直观的树形结构和易于理解的特点被广泛应用于分类问题。随机森林则是一种集成学习算法,通过构建多个决策树并进行投票,以提高分类的准确性和鲁棒性。本实验的目的在于让学生通过实践,深入理解这两种算法的工作原理,掌握使用Python的sklearn库对数据进行分类的方法,并熟悉数据预处理的相关技术。
数据集
关注公众号:码银学编程,回复:income_classification。
income_classification
实验环境配置
实验在配置较高的个人计算机上进行,具体配置如下:
- 开发工具:PyCharm 2021.3.1
- 操作系统:Windows 11
- 处理器:Intel® Core™ i5-10210U CPU @ 1.60GHz 2.11 GHz
- 内存:16.0 GB (15.8 GB 可用)
- 系统类型:64 位操作系统,基于 x64 的处理器
实验内容与过程
实验内容主要围绕使用决策树和随机森林算法对收入水平数据集income_classification.csv进行分类。具体步骤如下:
实验步骤1:数据载入与展示
首先,实验从载入数据集开始。使用pandas库的read_csv函数读取数据集,并使用shape属性获取数据集的维度,即行数和列数,以及使用head()函数展示前5行数据。
实验步骤2:数据离散化处理
对于连续变量age,实验采用分位数的方法进行离散化处理。pd.qcut函数根据数据的分布将age分为5个区间,每个区间的数据被赋予一个从0开始的整数标签。
实验步骤3:特征编码
对于分类特征,实验使用LabelEncoder进行编码,将每个类别的字符串标签转换为整数。这一步骤是必要的,因为机器学习模型只能处理数值型数据。
实验步骤4:数据预处理及构造标签
接下来,实验对数据进行预处理,构造模型的输入数据和标签。数据集中的income字段被用作标签,根据其值将标签分为0和1两类。
实验步骤5:转换字符串数据类型为数值型
由于决策树和随机森林算法只能处理数值型数据,实验使用DictVectorizer将数据转换为数值型。
实验步骤6:训练集与测试集拆分
实验将数据集按照7:3的比例随机划分为训练集和测试集,以便于后续的训练和测试。
实验步骤7:CART决策树分类
使用CART算法训练决策树分类器,并计算其在测试集上的分类准确率。
实验步骤8:随机森林分类
使用随机森林算法训练分类器,并同样计算其在测试集上的分类准确率。
实验步骤9:结果可视化
最后,实验通过柱状图可视化了两种模型的分类准确率,直观展示了随机森林相对于决策树在本次实验中的优势。

实验结果
实验结果显示,CART决策树的分类准确率为82.61%,而随机森林的分类准确率达到了84.83%,后者在本次实验中表现更优。
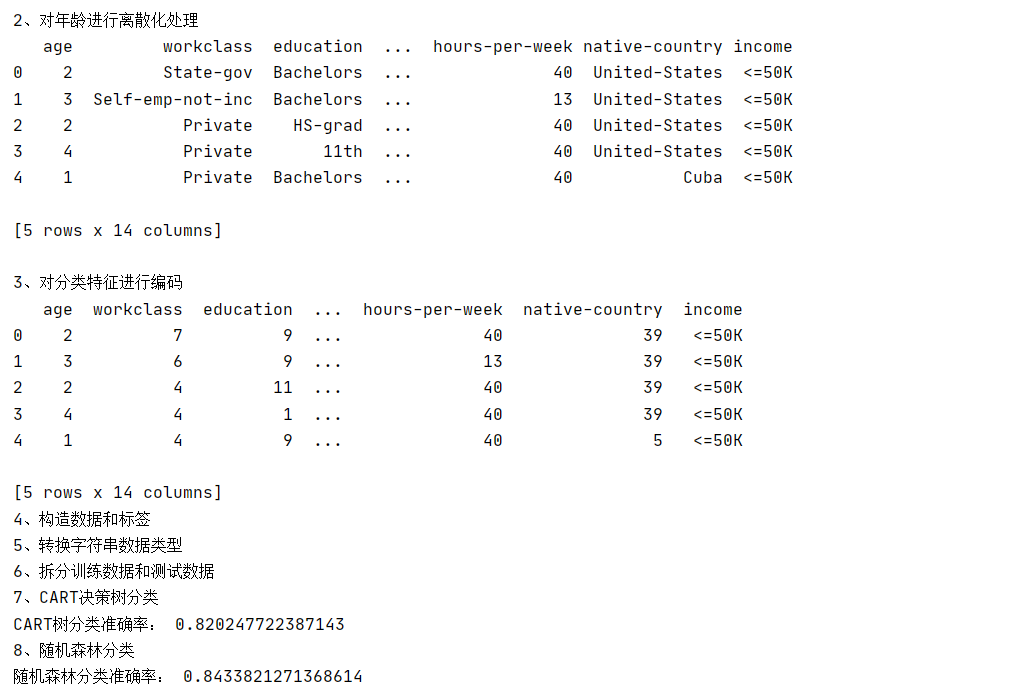
结果分析
决策树的生成是基于递归分裂过程,每一次分裂都旨在最大化类别的同质性。然而,决策树容易过拟合,特别是当数据集未经过适当的离散化处理时。随机森林通过构建多个决策树并进行投票,有效地提高了分类的准确性和鲁棒性。在本次实验中,随机森林的准确率超过了决策树,这可能是因为随机森林在处理复杂的分类问题时,能够更好地泛化。
整体代码分析
以下是实验中使用的关键代码的详细分析:
# 导入所需库
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt# 1. 载入数据
print('1、载入数据')
data = pd.read_csv("income_classification.csv", header=0)
print('数据维度:', data.shape)
print(data.head())# 2. 对连续变量 'age' 进行离散化处理
print('\n2、对年龄进行离散化处理')
data['age'] = pd.qcut(data['age'], q=5, labels=False) # 使用分位数进行离散化
print(data.head())# 3. 将分类特征进行编码
print('\n3、对分类特征进行编码')
class_le = LabelEncoder()
categorical_features = ['workclass','marital-status','occupation','education','native-country','relationship','race','sex']
for feature in categorical_features:data[feature] = class_le.fit_transform(data[feature])
print(data.head())# 4. 数据预处理及构造标签
print('4、构造数据和标签')
data1 = data.drop('income', axis=1).to_dict(orient='records')
labels = np.where(data['income'] == '<=50K', 0, 1)# 5. 转换字符串数据类型为数值型
print('5、转换字符串数据类型')
vec = DictVectorizer()
x = vec.fit_transform(data1).toarray()# 6. 拆分训练集与测试集
print('6、拆分训练数据和测试数据')
ratio = 0.7
indices = np.random.permutation(len(x))
split_index = int(ratio * len(indices))
x_train, x_test = x[indices[:split_index]], x[indices[split_index:]]
y_train, y_test = labels[indices[:split_index]], labels[indices[split_index:]]# 7. CART决策树分类
print('7、CART决策树分类')
clf_cart = tree.DecisionTreeClassifier(criterion='entropy')
clf_cart.fit(x_train, y_train)
accuracy_cart = clf_cart.score(x_test, y_test)
print('CART树分类准确率:', accuracy_cart)# 8. 随机森林分类
print('8、随机森林分类')
clf_random = RandomForestClassifier()
clf_random.fit(x_train, y_train)
accuracy_random = clf_random.score(x_test, y_test)
print('随机森林分类准确率:', accuracy_random)# 可视化分类准确率
models = ['CART', 'Random Forest']
accuracies = [accuracy_cart, accuracy_random]plt.figure(figsize=(5, 5))
plt.bar(models, accuracies, color=['blue', 'green'])
plt.yticks(np.arange(0, 1, 0.05))
for i, v in enumerate(accuracies):plt.text(i, v + max(accuracies) * 0.05, str(v), ha='center', va='bottom')
plt.title('Model Accuracies')
plt.xlabel('Model')
plt.ylabel('Accuracy Score')
plt.show()
在上述代码中,首先导入了实验所需的库,然后按步骤执行了数据载入、离散化处理、特征编码、数据预处理、模型训练和分类准确率计算。最后,使用matplotlib库对分类准确率进行了可视化展示。
相关文章:
【机器学习】:基于决策树与随机森林对数据分类
机器学习实验报告:决策树与随机森林数据分类 实验背景与目的 在机器学习领域,决策树和随机森林是两种常用的分类算法。决策树以其直观的树形结构和易于理解的特点被广泛应用于分类问题。随机森林则是一种集成学习算法,通过构建多个决策树并…...

.NET 4.8和.NET 8.0的区别和联系、以及查看本地计算机的.NET版本
文章目录 .NET 4.8和.NET 8.0的区别查看本地计算机的.NET版本 .NET 4.8和.NET 8.0的区别 .NET 8.0 和 .NET 4.8 之间的区别主要体现在它们的发展背景、目标平台、架构设计和功能特性上。下面是它们之间的一些主要区别: 发展背景: .NET 4.8 是.NET Fram…...
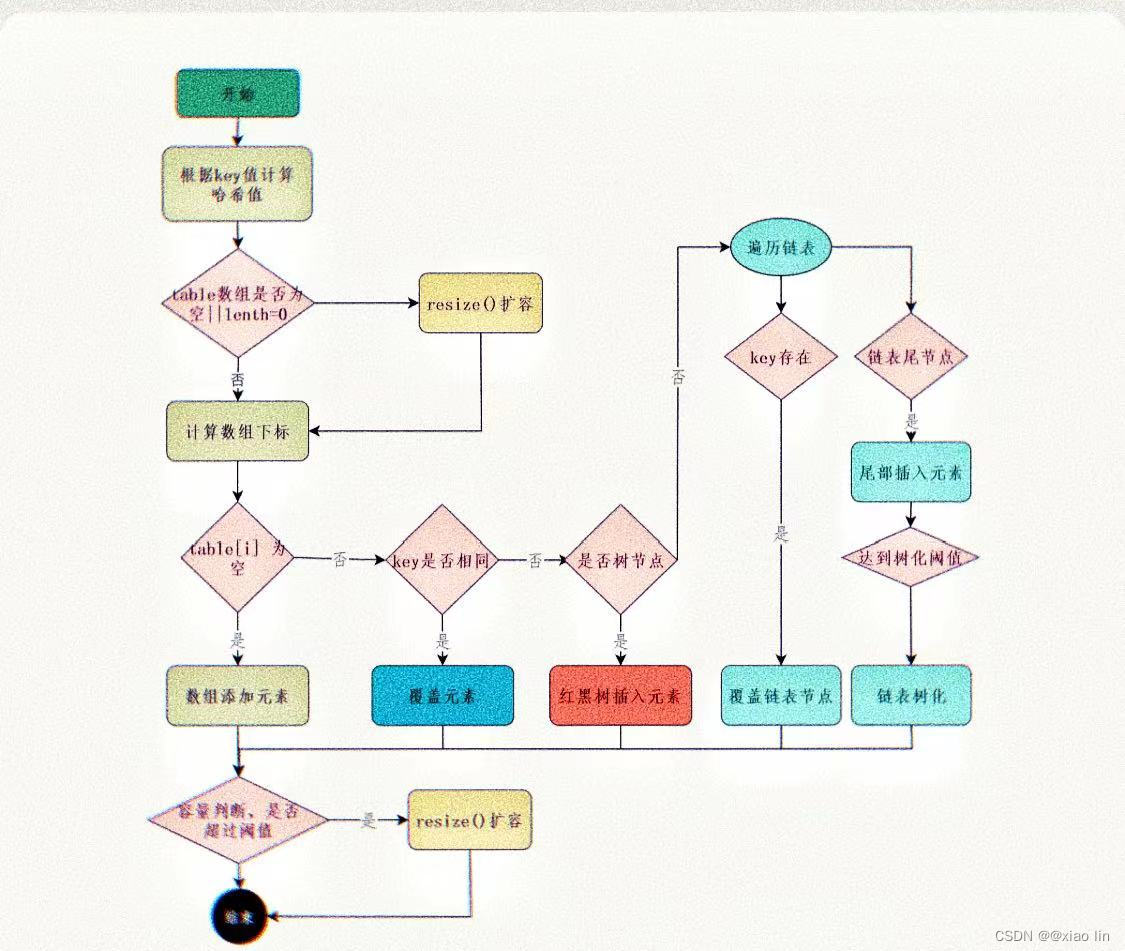
23.HashMap的put方法流程
一、put方法的流程图 二、put方法的执行步骤 首先,根据key值计算哈希值。然后判断table数组是否为空或者数组长度是否为0,是的话则要扩容,resize()。接着,根据哈希值计算数组下标。如果这个下标位置为空&a…...

元类结合__new__
__new__:用来生成骨架 __init__:骨架添加血肉 【一】类中的__new__ class MyClass(object):def __init__(self,name,age):print(f"给当前MyClass类的对象初始化属性的时候会触发__init__")self.name nameself.age age def __call__(self,*args,**kwargs):pri…...

(C语言)队列实现与用队列实现栈
目录 1.队列 1.1队列的概念及结构 1.2 队列的实际应用联想 1.3队列的实现 2. 队列应用——队列实现栈 主要思路 1.队列 1.1队列的概念及结构 队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进…...

字符画生成网站 ascii字符画
_____ / ___/__ ___ / /__/ _ \/ _ \ \___/ .__/ .__//_/ /_/ font推荐:1.Slant 2.Small 3.Small slant https://patorjk.com/software/taag/#pdisplay&fSmall%20Slant&tCpp https://www.kammerl.de/ascii/AsciiSignature.php https://asciia…...

【C -> Cpp】由C迈向Cpp (6):静态、友元和内部类
标题:【C -> Cpp】由C迈向Cpp (6):静态、友元和内部类 水墨不写bug (图片来源于网络) 目录 (一)静态成员 (二)友元 (三)…...

探索Playwright:Python下的Web自动化测试革命
在如今这个互联网技术迅速发展的时代,web应用的质量直接关系着企业的声誉和用户的体验。因此,自动化测试成为了保障软件质量的重要手段之一。今天,我将带大家详细了解一款在测试领域大放异彩的神器——Playwright,并通过Python语言…...

先有JVM还是先有垃圾回收器?很多人弄混淆了
是先有垃圾回收器再有JVM呢,还是先有JVM再有垃圾回收器呢?或者是先有垃圾回收再有JVM呢?历史上还真是垃圾回收更早面世,垃圾回收最早起源于1960年诞生的LISP语言,Java只是支持垃圾回收的其中一种。下面我们就来刨析刨析…...
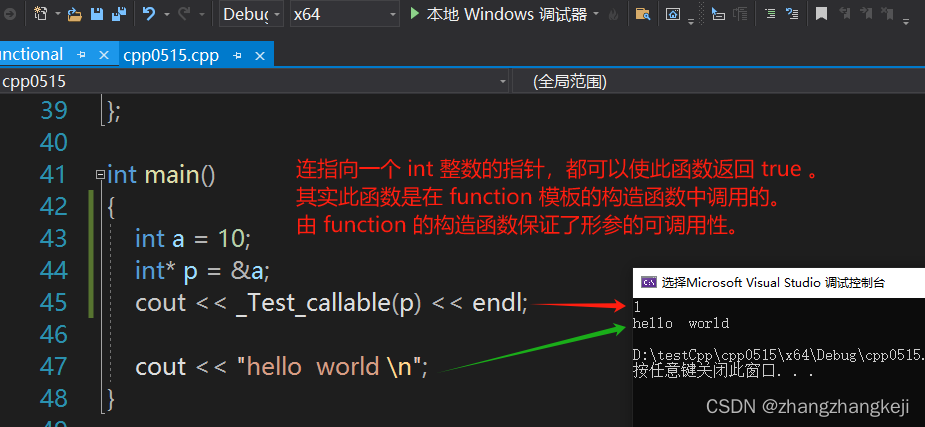
关于 vs2019 c++20 规范里的一个全局函数 _Test_callable
(1)看名思议,觉得这个函数可以测试其形参是否是可以被调用的函数,或可调用对象? 不,这个名字不科学。有误导,故特别列出。看下其源码(该函数位于 头文件): 辅…...

07-Fortran基础--Fortran指针(Pointer)的使用
07-Fortran基础--Fortran指针Pointer的使用 0 引言1 指针(Poionter)的有关内容1.1 一般类型指针1.2 数组指针1.3 派生类(type)指针1.4 函数指针 2 可运行code 0 引言 Fortran是一种广泛使用的编程语言,特别适合科学计算和数值分析。Fortran 9…...

日期差值,
日期差值 ac代码 #include<iostream> using namespace std; int ans0; int get(int n){int mon[14]{0,31,28,31,30,31,30,31,31,30,31,30,31};ans0;int m_dayn%100;int m_month(n/100)%100;int m_year(n/10000);ansm_day;while(m_month--){//加上月数if((m_year%40&…...

GMV ES6直流变频多联空调机组室外机工作原理
GMV ES6直流变频多联空调机组室外机工作原理如下: 内机为制冷模式运行时,室外机根据室内机的运行负荷需求启动运行,室外换热器作为系统的冷凝器,各制冷室内机的换热器并联作为系统的蒸发器,通过室内机的送回风循环实现…...
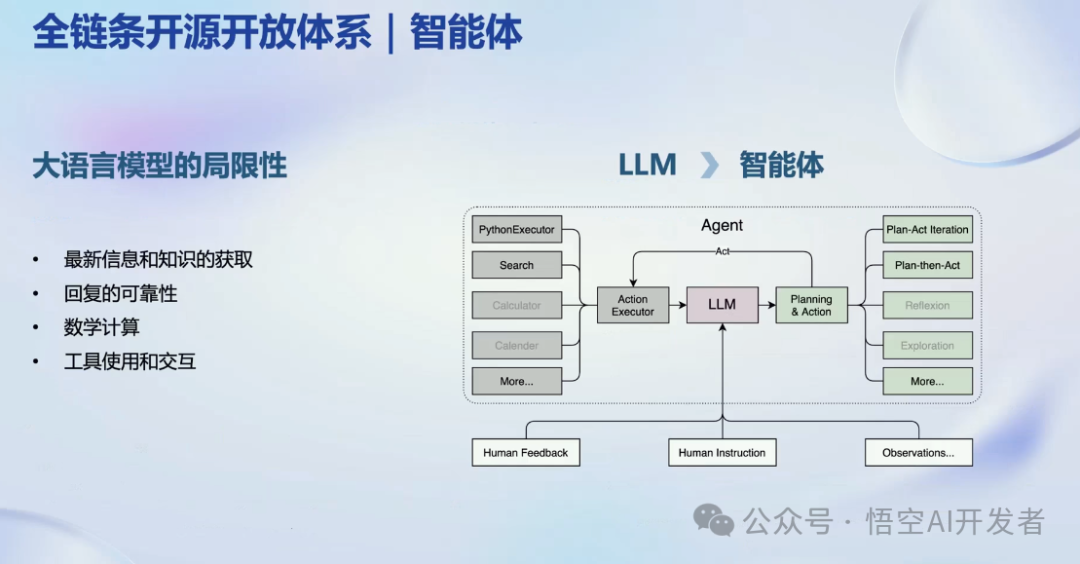
中国开源 AI 大模型之光-InternLM2
今天给大家带来 AI 大模型领域的国产之光 - InternLM2,在10B量级开源大模型领域取得了全球 Top 3 的成绩,仅次于 Meta 发布的 Llama-3,在国内则是第一名的存在! 简介 InternLM2是由上海人工智能实验室和商汤科技联合研发的一款大型…...

【嵌入式开发】Arduino人机界面及接口技术:独立按键接口,矩阵按键接口,模拟量按键接口(基础知识介绍)
“生活总是让我们遍体鳞伤,但到后来,那些受伤的地方一定会变成我们最强壮的地方。” 🎯作者主页: 追光者♂🔥 🌸个人简介: 📝[1] CSDN 博客专家📝 🏆[2] 人工智能领域优质创作者🏆 🌟[3] 2022年度博客之星人工智能领域TOP4🌟 🌿[4] …...

element ui Tree树形控件
lazy 是否懒加载子节点,需与 load 方法结合使用 boolean 默认为falseload 加载子树数据的方法,仅当 lazy 属性为true 时生效 function(node, resolve)使用懒加载load不需要再使用data,利用resolve返回值即可注意:第一层的数据要写…...

AI 绘画神器 Fooocus 图生图:图像放大或变化、图像提示、图像重绘或扩充、反推提示词、生成参数提取、所需模型下载
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 大家好,我是水滴~~ 本文讲述 Fooocus 的图生图功能,主要内容包括:图像放大或变化、图像提示、图像重绘或扩充、反推…...

yolov8 模型架构轻量化 | 极致降参数量
模型轻量化加速是深度学习领域的重要研究方向,旨在减小模型的体积和计算复杂度,从而提高在资源受限设备上的运行效率,模型参数量在轻量化加速中扮演着至关重要的角色。 首先,模型参数量直接决定了模型的复杂度和存储空间需求。随…...

uniapp 小程序低功耗蓝牙配网 ble配网 物联网
1.获取蓝牙列表 bleList.vue <template><view><button touchstart"startSearch">获取蓝牙列表</button><scroll-view :scroll-top"scrollTop" scroll-y class"content-pop"><viewclass"bluetoothItem&q…...

服务器防火墙有什么用防护策略
随着互联网的飞速发展,服务器的安全问题日益凸显。为了保护服务器免受网络攻击和恶意入侵的威胁,人们引入了防火墙的概念。服务器防火墙作为保护服务器的第一道防线,具有重要的作用。那么服务器防火墙有什么用? 首先,服…...
的3D视觉原理与应用)
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头(如Intel Realsense)的3D视觉原理与应用
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头的3D视觉原理与应用 当你第一次看到RGB-D摄像头生成的彩色点云在屏幕上旋转时,那种将现实世界数字化的震撼感令人难忘。但真正让这种设备发挥价值的,是理解它如何将光信号转化为三维坐标的完整技术…...

告别Selenium!用DrissionPage的ChromiumPage和SessionPage,5分钟搞定登录与爬虫
告别Selenium!用DrissionPage的ChromiumPage和SessionPage,5分钟搞定登录与爬虫 在Python自动化测试和爬虫开发领域,Selenium曾经是无可争议的王者。但随着时间的推移,开发者们逐渐意识到Selenium的局限性——复杂的配置、缓慢的执…...

告别手写UI!用VSCode+QtDesigner+PyQt5,5分钟搞定你的第一个Python图形界面
5分钟极速构建Python GUI:VSCodeQtDesignerPyQt5全流程实战 每次看到同事用代码逐行构建UI界面时,总忍不住想起自己初学时的痛苦经历——调整一个按钮位置要反复运行程序,修改边距像素值就像在玩"猜数字"游戏。直到发现QtDesigner这…...

如何永久保存微信聊天记录?3分钟学会数据导出与智能分析终极指南
如何永久保存微信聊天记录?3分钟学会数据导出与智能分析终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...

告别黑盒预测:用TFT模型的可解释性,看清电力负荷预测的‘为什么’
电力负荷预测的透明革命:如何用TFT模型打开时间序列黑箱 当电网调度员面对突如其来的负荷波动时,传统深度学习模型往往只能给出一个冷冰冰的预测数字,却无法解释"为什么会有这样的变化"。这种黑箱特性让关键决策充满不确定性——温…...

如何快速掌握unnpk:网易游戏资源解包的完整入门指南
如何快速掌握unnpk:网易游戏资源解包的完整入门指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇过网易游戏《阴阳师》中那些精美的角色立绘…...

Pydantic序列化避坑大全:从‘按声明类型序列化’到灵活exclude/include的5个常见误区
Pydantic序列化深度避坑指南:从类型陷阱到安全控制的实战解析 深夜调试代码时,你是否遇到过这样的场景:明明在内存中完整的对象,通过API返回给前端时却莫名丢失了关键字段?或者当你在日志中打印包含敏感信息的模型时&a…...

告别轮询!STM32CubeMX配置DMA串口收发485数据,并详解HAL库回调函数使用避坑
STM32CubeMX实战:DMA驱动RS485通信与HAL库回调机制深度解析 当我们需要在工业环境中实现稳定可靠的串行通信时,RS485总线因其抗干扰能力强、传输距离远等优势成为首选。而STM32系列MCU配合HAL库的开发模式,能够显著提升开发效率。本文将彻底改…...

高效AI专著生成:20万字专著一键搞定,AI写专著工具实测推荐!
学术专著写作挑战与AI工具助力 对于初次尝试编写学术专著的研究者来说,写作过程就像是在“摸索着走过一条未知的小路”,处处都有挑战等待着他们。在选题上常常感到迷惘,难以在“有意义”与“可操作性”之间找到合适的平衡:有的研…...

思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析
思源宋体TTF字体包:为什么专业设计师都选择它?7大应用场景深度解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版烦恼吗?字体选择困…...