【Python】机器学习中的过采样和欠采样:处理不平衡数据集的关键技术
原谅把你带走的雨天
在渐渐模糊的窗前
每个人最后都要说再见
原谅被你带走的永远
微笑着容易过一天
也许是我已经 老了一点
那些日子你会不会舍不得
思念就像关不紧的门
空气里有幸福的灰尘
否则为何闭上眼睛的时候
又全都想起了
谁都别说
让我一个人躲一躲
你的承诺
我竟然没怀疑过
反反覆覆
要不是当初深深深爱过
我试着恨你
却想起你的笑容
🎵 陈楚生/单依纯《原谅》
在机器学习和数据科学中,数据集的不平衡是一个常见的问题。当一个数据集中的某一类样本数量远远超过其他类时,模型往往会偏向多数类,从而影响分类器的性能。为了解决这一问题,研究人员提出了多种技术,其中过采样和欠采样是两种最常用的方法。本文将详细介绍过采样和欠采样的概念、原理以及在实际应用中的注意事项。
什么是不平衡数据集?
不平衡数据集是指某些类的样本数量显著多于其他类的情况。假设有一个二分类问题,其中类别0有950个样本,而类别1只有50个样本。由于类别0的样本数量远远多于类别1,模型在训练时更容易学习到类别0的特征,忽略类别1,从而导致分类性能下降。
过采样(Oversampling)
过采样是一种通过增加少数类样本数量来平衡数据集的方法。其主要思想是生成新的少数类样本,使少数类的样本数量增加到与多数类相同或相近。
常见的过采样方法
随机过采样(Random Oversampling):
通过随机复制少数类样本来增加其数量。这种方法简单易行,但可能导致过拟合,因为它没有引入新的信息。
from imblearn.over_sampling import RandomOverSamplerros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X_train, y_train)
SMOTE(Synthetic Minority Over-sampling Technique):
通过在少数类样本之间插值生成新的样本。SMOTE不仅复制少数类样本,还生成新的合成样本,从而减少了过拟合的风险。
from imblearn.over_sampling import SMOTEsmote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
ADASYN(Adaptive Synthetic Sampling Approach for Imbalanced Learning):
ADASYN是对SMOTE的改进,它根据样本的分类难度自适应地生成合成样本。分类难度大的样本生成更多的新样本,分类难度小的样本生成较少的新样本。
from imblearn.over_sampling import ADASYNadasyn = ADASYN(random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X_train, y_train)
欠采样(Undersampling)
欠采样是一种通过减少多数类样本数量来平衡数据集的方法。其主要思想是减少多数类样本的数量,使其与少数类的样本数量接近,从而达到平衡数据集的目的。
常见的欠采样方法
随机欠采样(Random Undersampling):
随机删除多数类样本,使其数量减少到与少数类相同或相近。虽然简单,但可能会丢失大量有用信息,导致模型性能下降。
from imblearn.under_sampling import RandomUnderSamplerrus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
集成欠采样(Cluster Centroids):
通过聚类算法将多数类样本聚类为若干个簇,并用簇的中心代替原始样本,从而减少多数类样本的数量。
from imblearn.under_sampling import ClusterCentroidscc = ClusterCentroids(random_state=42)
X_resampled, y_resampled = cc.fit_resample(X_train, y_train)
Tomek Links:
通过删除与少数类样本最接近的多数类样本对(Tomek链接),从而减少多数类样本数量。这种方法不仅减少了多数类样本,还清除了数据集中的噪声样本。
from imblearn.under_sampling import TomekLinkstl = TomekLinks()
X_resampled, y_resampled = tl.fit_resample(X_train, y_train)
过采样与欠采样的选择
选择过采样还是欠采样取决于具体的数据集和问题:
-
过采样适用于:
- 少数类样本特别少,直接删除多数类样本会导致信息丢失过多。
- 数据集足够小,生成合成样本不会显著增加计算开销。
-
欠采样适用于:
- 多数类样本特别多,随机复制少数类样本会导致过拟合。
- 数据集足够大,删除部分多数类样本不会导致信息丢失过多。
在实际应用中,有时可以结合过采样和欠采样的方法,进一步提高模型性能。例如,先通过欠采样减少多数类样本数量,再通过过采样增加少数类样本数量,从而达到更好的平衡效果。
实战案例:结合过采样和欠采样
以下是一个结合过采样和欠采样的方法来平衡数据集的示例:
from imblearn.combine import SMOTETomek
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from collections import Counter# 生成一个不平衡的数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, n_clusters_per_class=1, weights=[0.9, 0.1], flip_y=0, random_state=42)# 查看数据分布
print(f"原始数据集类别分布: {Counter(y)}")# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 使用SMOTETomek进行过采样和欠采样
smote_tomek = SMOTETomek(random_state=42)
X_resampled, y_resampled = smote_tomek.fit_resample(X_train, y_train)# 查看过采样和欠采样后的数据分布
print(f"过采样和欠采样后数据集类别分布: {Counter(y_resampled)}")
结论
过采样和欠采样是处理不平衡数据集的两种重要技术。过采样通过增加少数类样本数量来平衡数据集,而欠采样则通过减少多数类样本数量来达到同样的目的。根据具体问题和数据集的特点,选择合适的方法可以显著提高模型的性能。在实际应用中,结合使用这两种方法往往可以取得更好的效果。希望本文能帮助你理解并掌握过采样和欠采样的基本原理和实现方法,为你的机器学习项目提供支持。如果你有任何问题或建议,欢迎在评论区留言!
相关文章:

【Python】机器学习中的过采样和欠采样:处理不平衡数据集的关键技术
原谅把你带走的雨天 在渐渐模糊的窗前 每个人最后都要说再见 原谅被你带走的永远 微笑着容易过一天 也许是我已经 老了一点 那些日子你会不会舍不得 思念就像关不紧的门 空气里有幸福的灰尘 否则为何闭上眼睛的时候 又全都想起了 谁都别说 让我一个人躲一躲 你的承诺 我竟然没怀…...
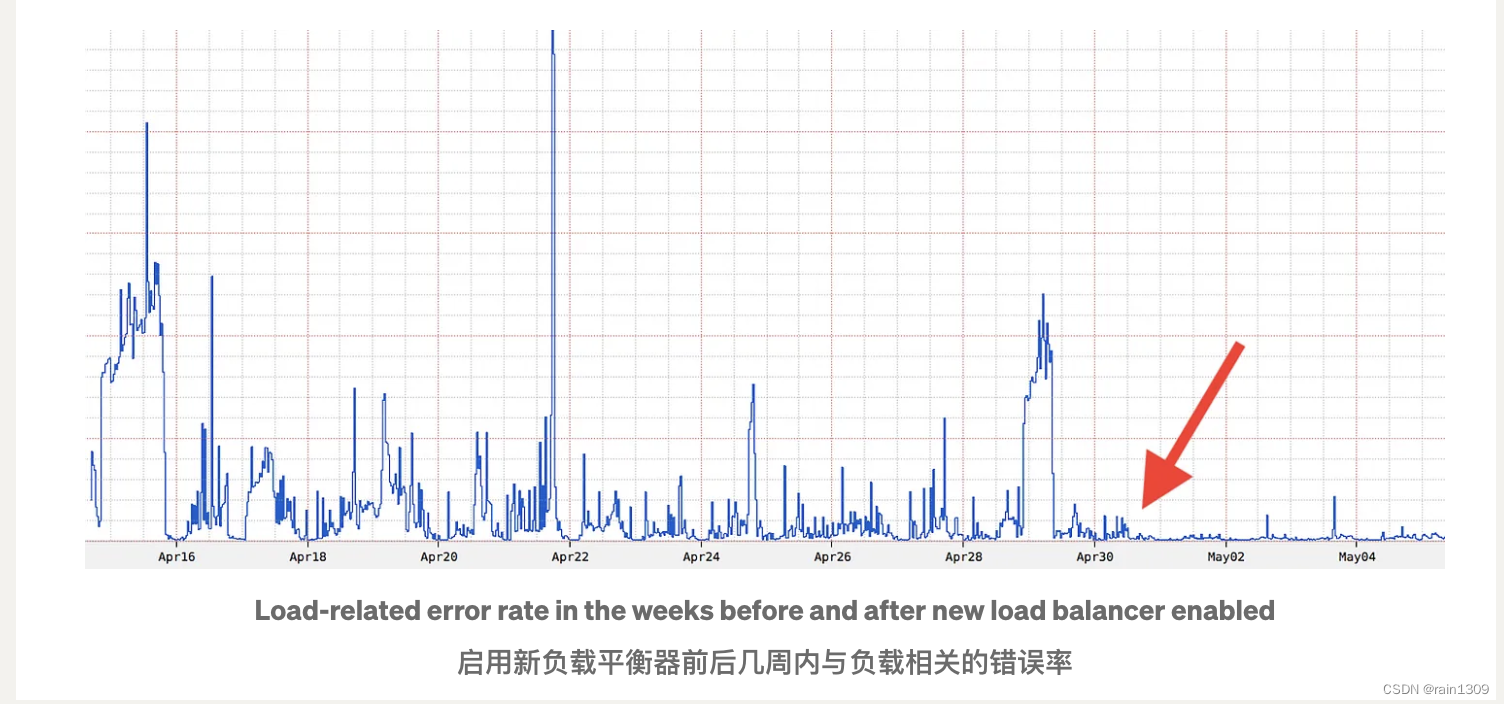
重新思考:Netflix 的边缘负载均衡
声明 本文是对Netflix 博客的翻译 前言 在先前关于Zuul 2开源的文章中,我们简要概述了近期在负载均衡方面的一些工作。在这篇文章中,我们将更详细地介绍这项工作的原因、方法和结果。 因此,我们开始从Zuul和其他团队那里学习&#…...

元组的创建和删除
目录 使用赋值运算符直接创建元组 创建空元组 创建数值元组 删除元组 自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 元组(tuple)是Python中另一个重要的序列结构&#…...

CSS3用户界面
用户界面 appearance appearance 属性用于控制元素是否采用用户代理(浏览器)的默认样式(外观) element {appearance: auto | none;}auto(默认):元素采用浏览器提供的默认样式。none:元素不采用任何默认样式,显示为“裸”元素,通常表现为无特定样式的简单框。input[…...

STL源码刨析:序列式容器之vector
目录 1.序列式容器和关联式容器 2.vector的定义和结构 3.vector的构造函数和析构函数的实现 4.vector的数据结构以及实现源码 5.vector的元素操作 前言 本系列将重点对STL中的容器进行讲解,而在容器的分类中,我们将容器分为序列式容器和关联式容器。本章…...

Flutter 中的 AbsorbPointer 小部件:全面指南
Flutter 中的 AbsorbPointer 小部件:全面指南 在Flutter中,AbsorbPointer是一个特殊的小部件,用于吸收(或“吞噬”)所有传递到其子组件的指针事件(如触摸或鼠标点击)。这在某些情况下非常有用&…...

Web开发学习总结
学习路线 Web 全球广域网,也称为万维网(www World Wide Web),能够通过浏览器访问的网站 初识Web前端 Web标准也称为网页标准,由一系列的标准组成,大部分由W3C(World Wide Web Consortium,万维网联盟)负责制定。三个组…...

springboot相关知识集锦----1
一、springboot是什么? springboot是一个用于构建基于spring框架的独立应用程序的框架。它采用自动配置的原则,以减少开发人员在搭建应用方面的时间和精力。同时提升系统的可维护性和可扩展性。 二、springboot的优点 约定优于配置 版本锁定…...
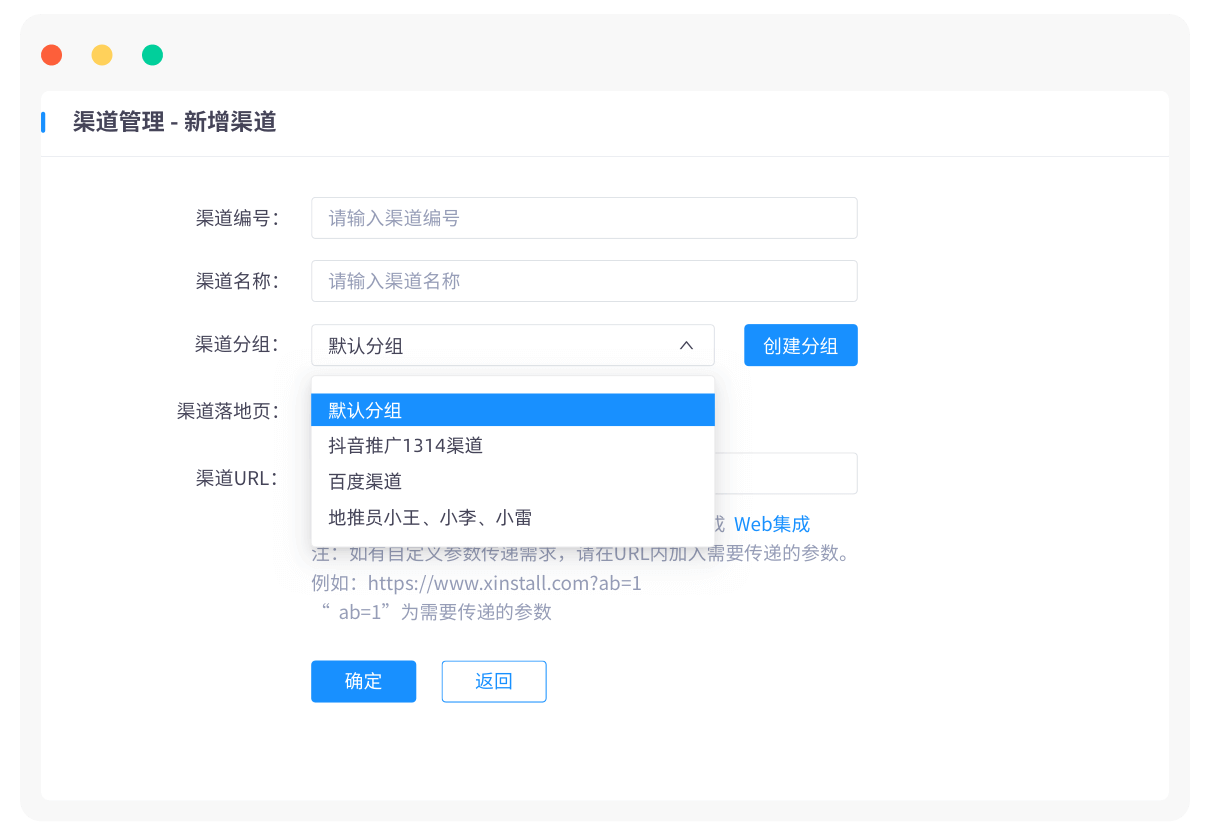
App推广新境界:Xinstall助你轻松突破运营痛点,实现用户快速增长!
在移动互联网时代,App已经成为企业营销不可或缺的一部分。然而,如何有效地推广App,吸引并留住用户,成为了众多企业面临的难题。今天,我们将为您揭秘一款神奇的App推广工具——Xinstall,它将助您轻松突破运营…...
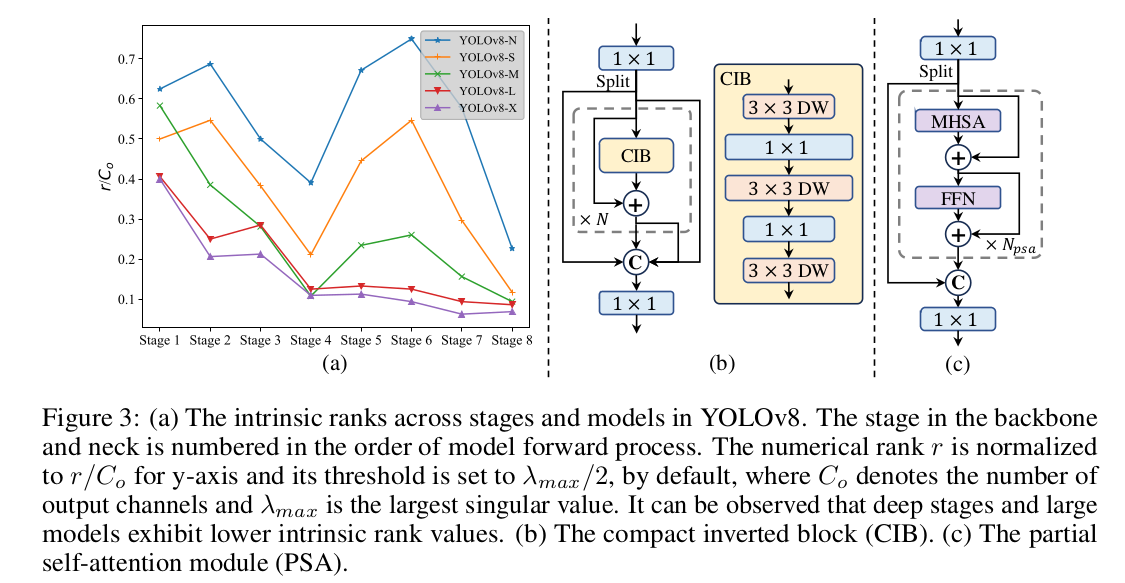
YOLOv10 论文学习
论文链接:https://arxiv.org/pdf/2405.14458 代码链接:https://github.com/THU-MIG/yolov10 解决了什么问题? 实时目标检测是计算机视觉领域的研究焦点,目的是以较低的延迟准确地预测图像中各物体的类别和坐标。它广泛应用于自动…...
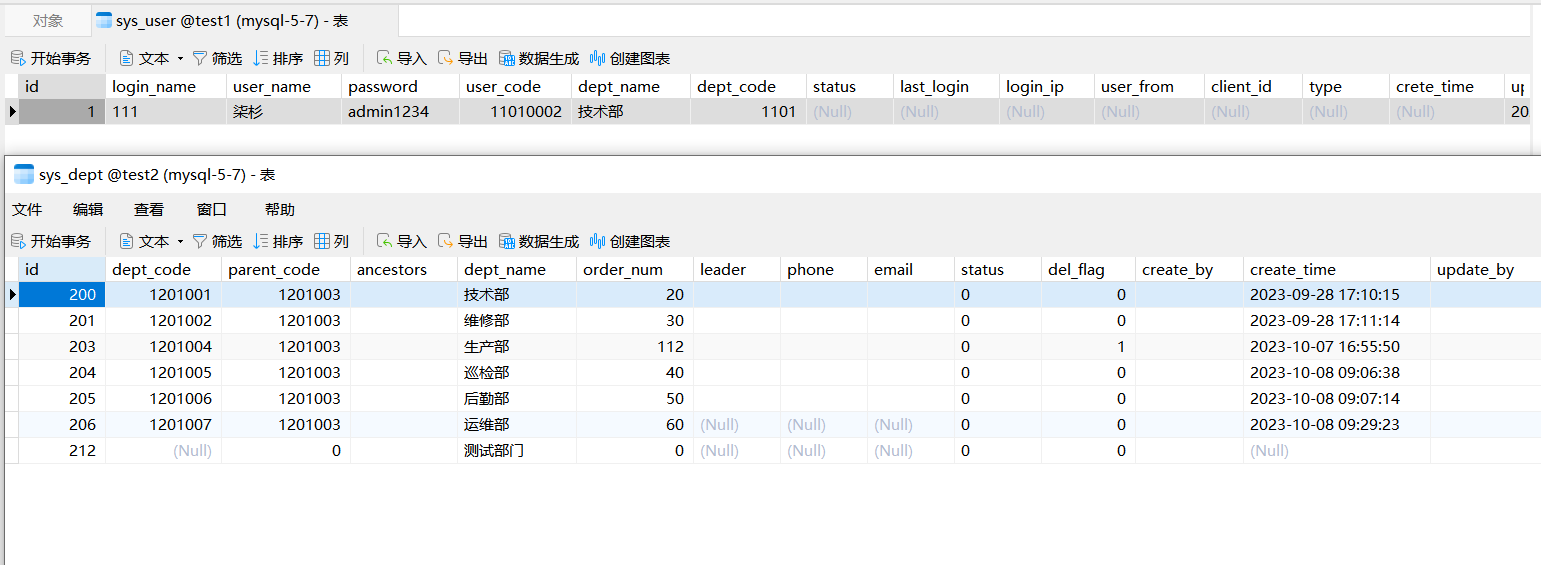
[Spring Boot]baomidou 多数据源
文章目录 简述本文涉及代码已开源 项目配置pom引入baomidouyml增加dynamic配置启动类增加注解配置结束 业务调用注解DS()TransactionalDSTransactional自定义数据源注解MySQL2 测试调用查询接口单数据源事务测试多数据源事务如果依然使用Transactional会怎样?测试正…...

Drone+Gitee自动执行构建、测试和发布工作流
拉取Drone:(至于版本,你可以下载最新的) sudo docker pull drone/drone:2 拉取runner: sudo docker pull drone/drone-runner-docker 在Gitee中添加第三方应用: 进入个人主页,点击设置: 往下翻,找到数…...

Unity3D MMORPG 主城角色动画控制与消息触发详解
Unity3D是一款强大的游戏开发引擎,它提供了丰富的功能和工具,使开发者能够轻松创建出高质量的游戏。其中,角色动画控制和消息触发是游戏开发中非常重要的一部分,它们可以让游戏角色表现出更加生动和多样的动作,同时也能…...

【Text2SQL 经典模型】HydraNet
论文:Hybrid Ranking Network for Text-to-SQL ⭐⭐⭐ arXiv:2008.04759 HydraNet 也是利用 PLM 来生成 question 和 table schema 的 representation 并用于生成 SQL,并在 SQLova 和 X-SQL 做了改进,提升了在 WikiSQL 上的表现。 一、Intro…...
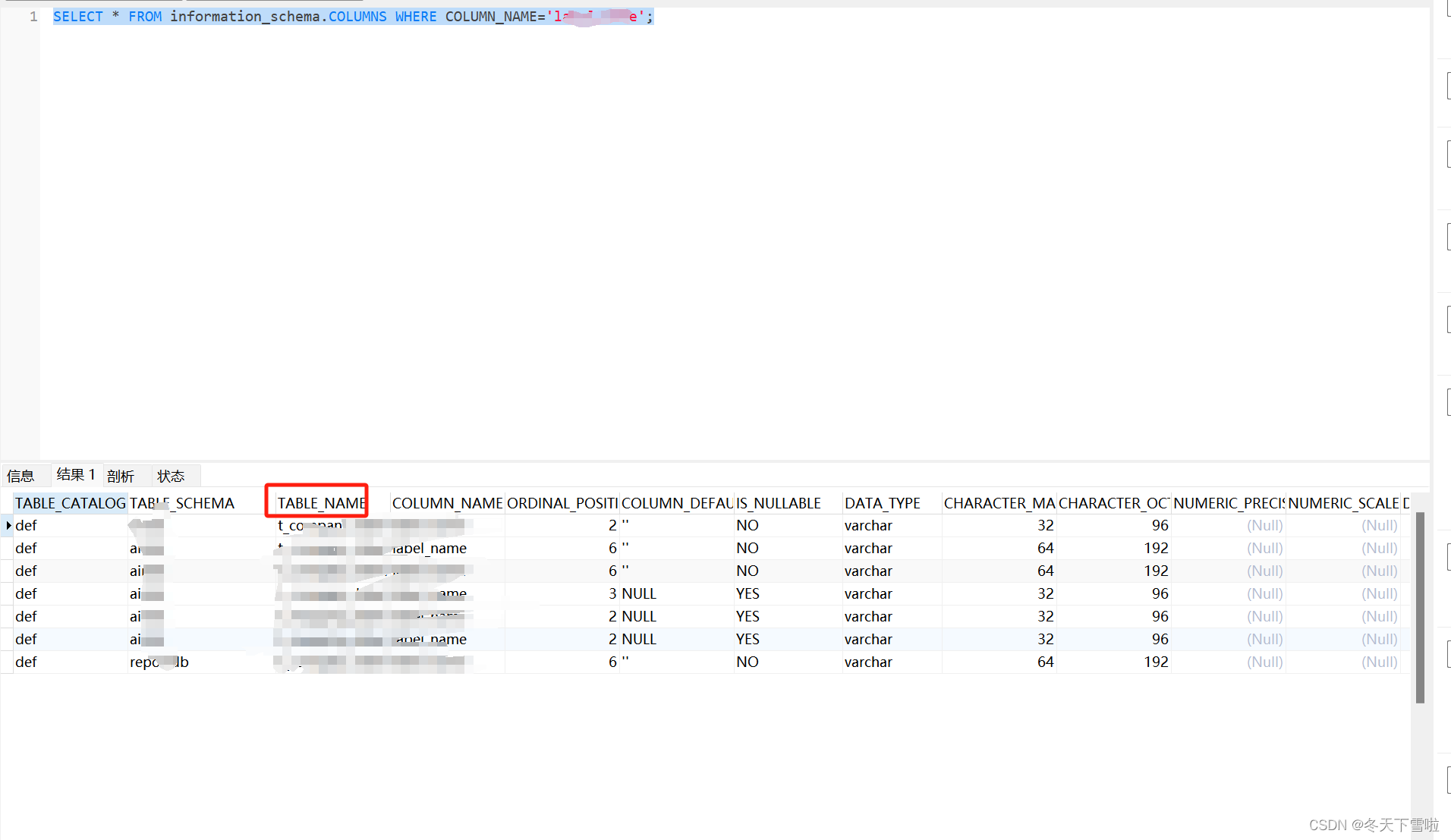
Mysql-根据字段名查询字段在哪些表里
SELECT * FROM information_schema.COLUMNS WHERE COLUMN_NAMElabel_name;...

牛逼!50.3K Star!一个自动将屏幕截图转换为代码的开源工具
1、背景 在当今快节奏的软件开发环境中,设计师与开发者之间的协同工作显得尤为重要。然而,理解并准确实现设计稿的意图常常需要耗费大量的时间和沟通成本。为此,开源社区中出现了一个引人注目的项目——screenshot-to-code,它利用…...

八种单例模式
文章目录 1.单例模式基本介绍1.介绍2.单例模式八种方式 2.饿汉式(静态常量,推荐)1.基本步骤1.构造器私有化(防止new)2.类的内部创建对象3.向外暴露一个静态的公共方法 2.代码实现3.优缺点分析 3.饿汉式(静态…...

禅道密码正确但是登录异常处理
禅道密码正确,但是登录提示密码错误的异常处理 排查内容 # 1、服务器异常,存储空间、数据库异常 # 2、服务异常,文件丢失等异常问题定位 # 1、df -h 排查服务器存储空间 # 2、根据my.php排查数据库连接是否正常 # 3、修改my.pho,debugtrue…...

Go微服务: Nacos的搭建和基础API的使用
Nacos 概述 文档:https://nacos.io/docs/latest/what-is-nacos/搭建:https://nacos.io/docs/latest/quickstart/quick-start-docker/有很多种搭建方式,我们这里使用 docker 来搭建 Nacos 的搭建 这里,我们选择单机模式…...

基于Hadoop的城市公共交通大数据时空分析
基于Hadoop的城市公共交通大数据时空分析 “Spatio-temporal Analysis of Urban Public Transportation Big Data based on Hadoop” 完整下载链接:基于Hadoop的城市公共交通大数据时空分析 文章目录 基于Hadoop的城市公共交通大数据时空分析摘要第一章 引言1.1 研究背景1.2 …...

反向散射通信:无电池物联网的低功耗革命
1. 反向散射通信技术演进概述十年前,当我第一次在实验室接触到RFID技术时,完全没想到这种简单的无线识别技术会演变成今天这样复杂的通信范式。反向散射通信(Backscatter Communication)已经从最初的射频识别工具,发展…...
)
【程序源代码】答题微信小程序(含源码)
关键字:答题,小程序,OCR, 题目识别,题库,练习,错题集,微信小程序,Vue项目名称:答题微信小程序答题小程序是面向学生群体打造的轻量化在线答题学习平台,基于微…...

Unity网络游戏开发避坑指南:手把手教你用C#和MySQL复刻餐厅经营联机对战
Unity网络游戏开发实战:餐厅经营联机对战的技术实现与优化1. 从单机到联机:架构设计的核心转变餐厅经营游戏从单机转向联机对战,首要考虑的是如何重构游戏架构。传统单机游戏的所有逻辑都在本地运行,而联机游戏需要将关键逻辑迁移…...

Unity Addressable本地HTTP服务器5分钟合规搭建指南
1. 为什么Addressable资源托管总卡在“本地跑不通”这一步? Unity Addressable Asset System(可寻址资源系统)上线这么多年,我见过太多团队在最后一步集体卡壳:资源打包没问题,加载逻辑写得滴水不漏&#…...

Flutter国际化与本地化完全指南
Flutter国际化与本地化完全指南 引言 国际化是构建全球化应用的关键环节,Flutter提供了完善的国际化支持。本文将深入探讨Flutter中的国际化和本地化技术。 一、基础配置 1.1 添加依赖 dependencies:flutter_localizations:sdk: flutterintl: ^0.18.11.2 更新main.d…...

DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理
DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 在NVIDIA DLSS技术成为现代PC游戏性能优化的关键要素后,玩家面临一个实际的技术挑战&…...

Solr CVE-2019-0193漏洞深度解析:DataImportHandler远程代码执行原理与实战修复
1. 这个漏洞不是“能远程执行代码”那么简单,而是Solr管理员自己亲手打开的后门 Apache Solr 是企业级搜索领域绕不开的基础设施,我经手过的金融、电商、政务类项目里,有七成以上都用它做全文检索底座。但2019年爆出的 CVE-2019-0193…...
)
企业ESG披露合规危机应对指南(2024欧盟CSRD强制落地倒计时)
更多请点击: https://intelliparadigm.com 第一章:CSRD法规核心要义与企业合规临界点 欧盟《企业可持续发展报告指令》(CSRD)已于2024年1月1日正式生效,取代原有的NFRD,显著扩大了适用范围与披露深度。其核…...

EASY-HWID-SPOOFER:3步掌握硬件标识伪装技术,保护数字隐私安全
EASY-HWID-SPOOFER:3步掌握硬件标识伪装技术,保护数字隐私安全 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字时代,硬件标识&#x…...
昇腾CANN ops-transformer RoPE 旋转位置编码:从复数旋转到 NTK 外推的完整实战
Transformer 的自注意力机制本身对位置不敏感——"猫坐在垫子上"和"垫子坐在猫上"的 attention score 一样,因为点积 QK^T 不区分 token 顺序。位置编码就是给每个 token 打上它在序列中的位置标签。 RoPE(Rotary Position Embeddin…...