Kafka线上集群部署方案怎么做?no.6
专栏前面几期内容,我分别从Kafka的定位、版本的变迁以及功能的演进等几个方面循序渐进地梳理了Apache Kafka的发展脉络。通过这些内容,我希望你能清晰地了解Kafka是用来做什么的,以及在实际生产环境中该如何选择Kafka版本,更快地帮助你入门Kafka。
现在我们就来看看在生产环境中的Kafka集群方案该怎么做。既然是集群,那必然就要有多个Kafka节点机器,因为只有单台机器构成的Kafka伪集群只能用于日常测试之用,根本无法满足实际的线上生产需求。而真正的线上环境需要仔细地考量各种因素,结合自身的业务需求而制定。下面我就分别从操作系统、磁盘、磁盘容量和带宽等方面来讨论一下。
操作系统
首先我们先看看要把Kafka安装到什么操作系统上。说起操作系统,可能你会问Kafka不是JVM系的大数据框架吗?Java又是跨平台的语言,把Kafka安装到不同的操作系统上会有什么区别吗?其实区别相当大!
的确,如你所知,Kafka由Scala语言和Java语言编写而成,编译之后的源代码就是普通的“.class”文件。本来部署到哪个操作系统应该都是一样的,但是不同操作系统的差异还是给Kafka集群带来了相当大的影响。目前常见的操作系统有3种:Linux、Windows和macOS。应该说部署在Linux上的生产环境是最多的,也有一些Kafka集群部署在Windows服务器上。Mac虽然也有macOS Server,但是我怀疑是否有人(特别是国内用户)真的把生产环境部署在Mac服务器上。
如果考虑操作系统与Kafka的适配性,Linux系统显然要比其他两个特别是Windows系统更加适合部署Kafka。虽然这个结论可能你不感到意外,但其中具体的原因你也一定要了解。主要是在下面这三个方面上,Linux的表现更胜一筹。
- I/O模型的使用
- 数据网络传输效率
- 社区支持度
我分别来解释一下,首先来看I/O模型。什么是I/O模型呢?你可以近似地认为I/O模型就是操作系统执行I/O指令的方法。
主流的I/O模型通常有5种类型:阻塞式I/O、非阻塞式I/O、I/O多路复用、信号驱动I/O和异步I/O。每种I/O模型都有各自典型的使用场景,比如Java中Socket对象的阻塞模式和非阻塞模式就对应于前两种模型;而Linux中的系统调用select函数就属于I/O多路复用模型;大名鼎鼎的epoll系统调用则介于第三种和第四种模型之间;至于第五种模型,其实很少有Linux系统支持,反而是Windows系统提供了一个叫IOCP线程模型属于这一种。
你不必详细了解每一种模型的实现细节,通常情况下我们认为后一种模型会比前一种模型要高级,比如epoll就比select要好,了解到这一程度应该足以应付我们下面的内容了。
说了这么多,I/O模型与Kafka的关系又是什么呢?实际上Kafka客户端底层使用了Java的selector,selector在Linux上的实现机制是epoll,而在Windows平台上的实现机制是select。因此在这一点上将Kafka部署在Linux上是有优势的,因为能够获得更高效的I/O性能。
其次是网络传输效率的差别。你知道的,Kafka生产和消费的消息都是通过网络传输的,而消息保存在哪里呢?肯定是磁盘。故Kafka需要在磁盘和网络间进行大量数据传输。如果你熟悉Linux,你肯定听过零拷贝(Zero Copy)技术,就是当数据在磁盘和网络进行传输时避免昂贵的内核态数据拷贝从而实现快速的数据传输。Linux平台实现了这样的零拷贝机制,但有些令人遗憾的是在Windows平台上必须要等到Java 8的60更新版本才能“享受”到这个福利。一句话总结一下,在Linux部署Kafka能够享受到零拷贝技术所带来的快速数据传输特性。
最后是社区的支持度。这一点虽然不是什么明显的差别,但如果不了解的话可能比前两个因素对你的影响更大。简单来说就是,社区目前对Windows平台上发现的Kafka Bug不做任何承诺。虽然口头上依然保证尽力去解决,但根据我的经验,Windows上的Bug一般是不会修复的。因此,Windows平台上部署Kafka只适合于个人测试或用于功能验证,千万不要应用于生产环境。
磁盘
如果问哪种资源对Kafka性能最重要,磁盘无疑是要排名靠前的。在对Kafka集群进行磁盘规划时经常面对的问题是,我应该选择普通的机械磁盘还是固态硬盘?前者成本低且容量大,但易损坏;后者性能优势大,不过单价高。我给出的建议是使用普通机械硬盘即可。
Kafka大量使用磁盘不假,可它使用的方式多是顺序读写操作,一定程度上规避了机械磁盘最大的劣势,即随机读写操作慢。从这一点上来说,使用SSD似乎并没有太大的性能优势,毕竟从性价比上来说,机械磁盘物美价廉,而它因易损坏而造成的可靠性差等缺陷,又由Kafka在软件层面提供机制来保证,故使用普通机械磁盘是很划算的。
关于磁盘选择另一个经常讨论的话题就是到底是否应该使用磁盘阵列(RAID)。使用RAID的两个主要优势在于:
- 提供冗余的磁盘存储空间
- 提供负载均衡
以上两个优势对于任何一个分布式系统都很有吸引力。不过就Kafka而言,一方面Kafka自己实现了冗余机制来提供高可靠性;另一方面通过分区的概念,Kafka也能在软件层面自行实现负载均衡。如此说来RAID的优势就没有那么明显了。当然,我并不是说RAID不好,实际上依然有很多大厂确实是把Kafka底层的存储交由RAID的,只是目前Kafka在存储这方面提供了越来越便捷的高可靠性方案,因此在线上环境使用RAID似乎变得不是那么重要了。综合以上的考量,我给出的建议是:
- 追求性价比的公司可以不搭建RAID,使用普通磁盘组成存储空间即可。
- 使用机械磁盘完全能够胜任Kafka线上环境。
磁盘容量
Kafka集群到底需要多大的存储空间?这是一个非常经典的规划问题。Kafka需要将消息保存在底层的磁盘上,这些消息默认会被保存一段时间然后自动被删除。虽然这段时间是可以配置的,但你应该如何结合自身业务场景和存储需求来规划Kafka集群的存储容量呢?
我举一个简单的例子来说明该如何思考这个问题。假设你所在公司有个业务每天需要向Kafka集群发送1亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是1KB,那么你能说出你的Kafka集群需要为这个业务预留多少磁盘空间吗?
我们来计算一下:每天1亿条1KB大小的消息,保存两份且留存两周的时间,那么总的空间大小就等于1亿 * 1KB * 2 / 1000 / 1000 = 200GB。一般情况下Kafka集群除了消息数据还有其他类型的数据,比如索引数据等,故我们再为这些数据预留出10%的磁盘空间,因此总的存储容量就是220GB。既然要保存两周,那么整体容量即为220GB * 14,大约3TB左右。Kafka支持数据的压缩,假设压缩比是0.75,那么最后你需要规划的存储空间就是0.75 * 3 = 2.25TB。
总之在规划磁盘容量时你需要考虑下面这几个元素:
- 新增消息数
- 消息留存时间
- 平均消息大小
- 备份数
- 是否启用压缩
带宽
对于Kafka这种通过网络大量进行数据传输的框架而言,带宽特别容易成为瓶颈。事实上,在我接触的真实案例当中,带宽资源不足导致Kafka出现性能问题的比例至少占60%以上。如果你的环境中还涉及跨机房传输,那么情况可能就更糟了。
如果你不是超级土豪的话,我会认为你和我平时使用的都是普通的以太网络,带宽也主要有两种:1Gbps的千兆网络和10Gbps的万兆网络,特别是千兆网络应该是一般公司网络的标准配置了。下面我就以千兆网络举一个实际的例子,来说明一下如何进行带宽资源的规划。
与其说是带宽资源的规划,其实真正要规划的是所需的Kafka服务器的数量。假设你公司的机房环境是千兆网络,即1Gbps,现在你有个业务,其业务目标或SLA是在1小时内处理1TB的业务数据。那么问题来了,你到底需要多少台Kafka服务器来完成这个业务呢?
让我们来计算一下,由于带宽是1Gbps,即每秒处理1Gb的数据,假设每台Kafka服务器都是安装在专属的机器上,也就是说每台Kafka机器上没有混部其他服务,毕竟真实环境中不建议这么做。通常情况下你只能假设Kafka会用到70%的带宽资源,因为总要为其他应用或进程留一些资源。
根据实际使用经验,超过70%的阈值就有网络丢包的可能性了,故70%的设定是一个比较合理的值,也就是说单台Kafka服务器最多也就能使用大约700Mb的带宽资源。
稍等,这只是它能使用的最大带宽资源,你不能让Kafka服务器常规性使用这么多资源,故通常要再额外预留出2/3的资源,即单台服务器使用带宽700Mb / 3 ≈ 240Mbps。需要提示的是,这里的2/3其实是相当保守的,你可以结合你自己机器的使用情况酌情减少此值。
好了,有了240Mbps,我们就可以计算1小时内处理1TB数据所需的服务器数量了。根据这个目标,我们每秒需要处理2336Mb的数据,除以240,约等于10台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以3,即30台。
怎么样,还是很简单的吧。用这种方法评估线上环境的服务器台数是比较合理的,而且这个方法能够随着你业务需求的变化而动态调整。
相关文章:
Kafka线上集群部署方案怎么做?no.6
专栏前面几期内容,我分别从Kafka的定位、版本的变迁以及功能的演进等几个方面循序渐进地梳理了Apache Kafka的发展脉络。通过这些内容,我希望你能清晰地了解Kafka是用来做什么的,以及在实际生产环境中该如何选择Kafka版本,更快地帮…...

vscode 的 AI 协助插件 Tabnine / Codeium
4.1、Tabnine 描述:Tabnine 是一款基于深度学习技术的代码自动补全工具。该插件支持多种编程语言,包括 Python、JavaScript、TypeScript、Java 和 Go 等。它可以根据您输入的代码段和上下文信息,预测并推荐可能的代码补全选项,从而…...

Flutter 中的 OutlineButton 小部件:全面指南
Flutter 中的 OutlineButton 小部件:全面指南 在Flutter的Material Design组件库中,OutlineButton是一个用于创建带边框的扁平按钮的小部件。这种按钮通常用于次要操作或在需要强调其他按钮的情况下使用。本文将为您提供一个全面的指南,帮助…...
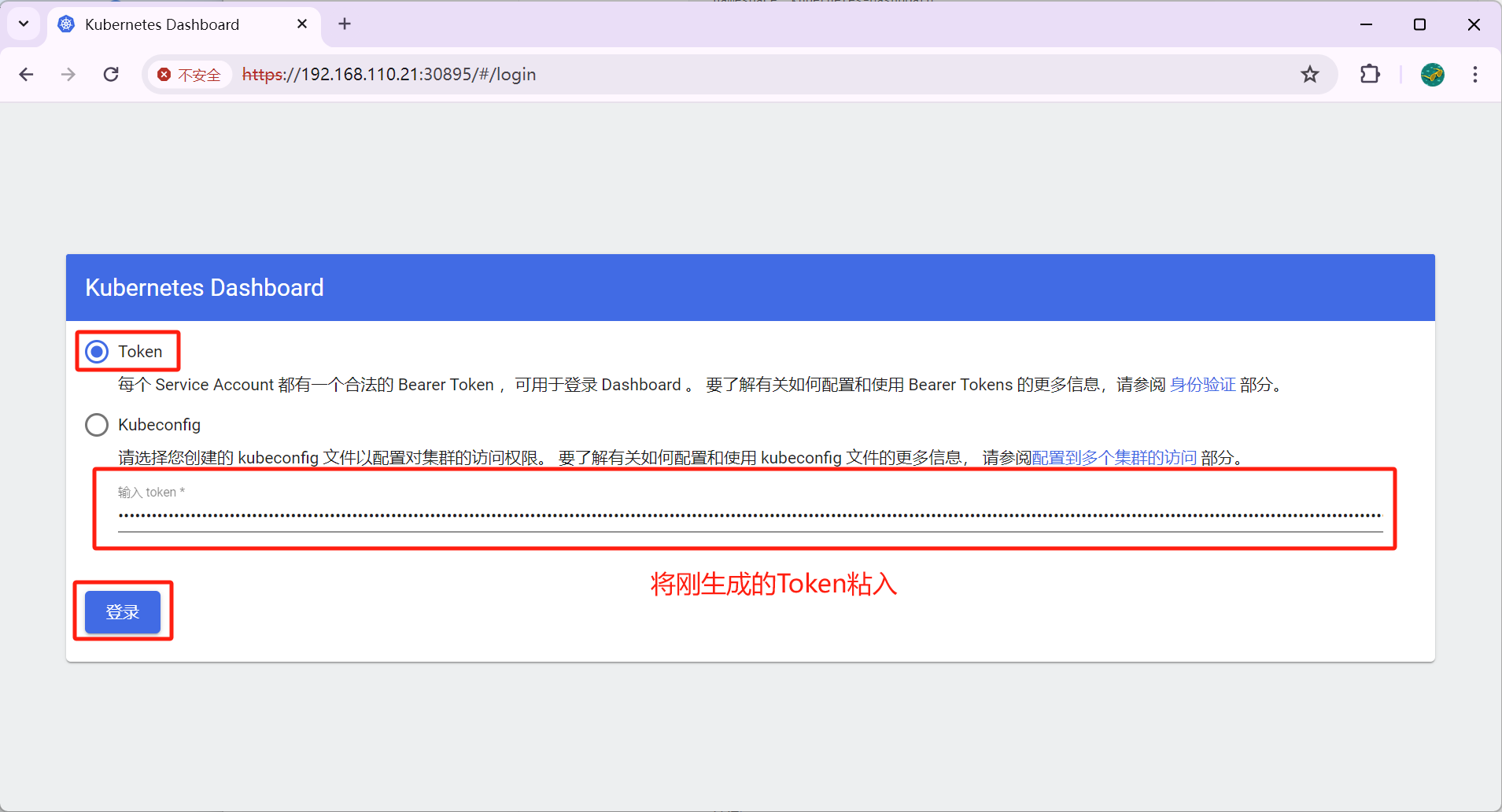
Kubernetes可视化界面之DashBoard
1.1 DashBoard Kubernetes Dashboard 是 Kubernetes 集群的一个开箱即用的 Web UI,提供了一种图形化的方式来管理和监视 Kubernetes 集群中的资源。它允许用户直接在浏览器中执行许多常见的 Kubernetes 管理任务,如部署应用、监控应用状态、执行故障排查…...
Docker学习(4):部署web项目
一、部署vue项目 在home目录下创建项目目录 将打包好的vue项目放入该目录下,dist是打包好的vue项目 在项目目录下,编辑default.conf 内容如下: server {listen 80;server_name localhost; # 修改为docker服务宿主机的iplocation / {r…...

驱动开发中引入私有数据的原因
系列文章目录 驱动开发中引入私有数据的原因 驱动开发中引入私有数据的原因 系列文章目录驱动开发中引入私有数据的原因 驱动开发中引入私有数据的原因 驱动开发中引入私有数据(Private Data)概念主要是为了解决以下几个关键问题: 1.多设备支…...
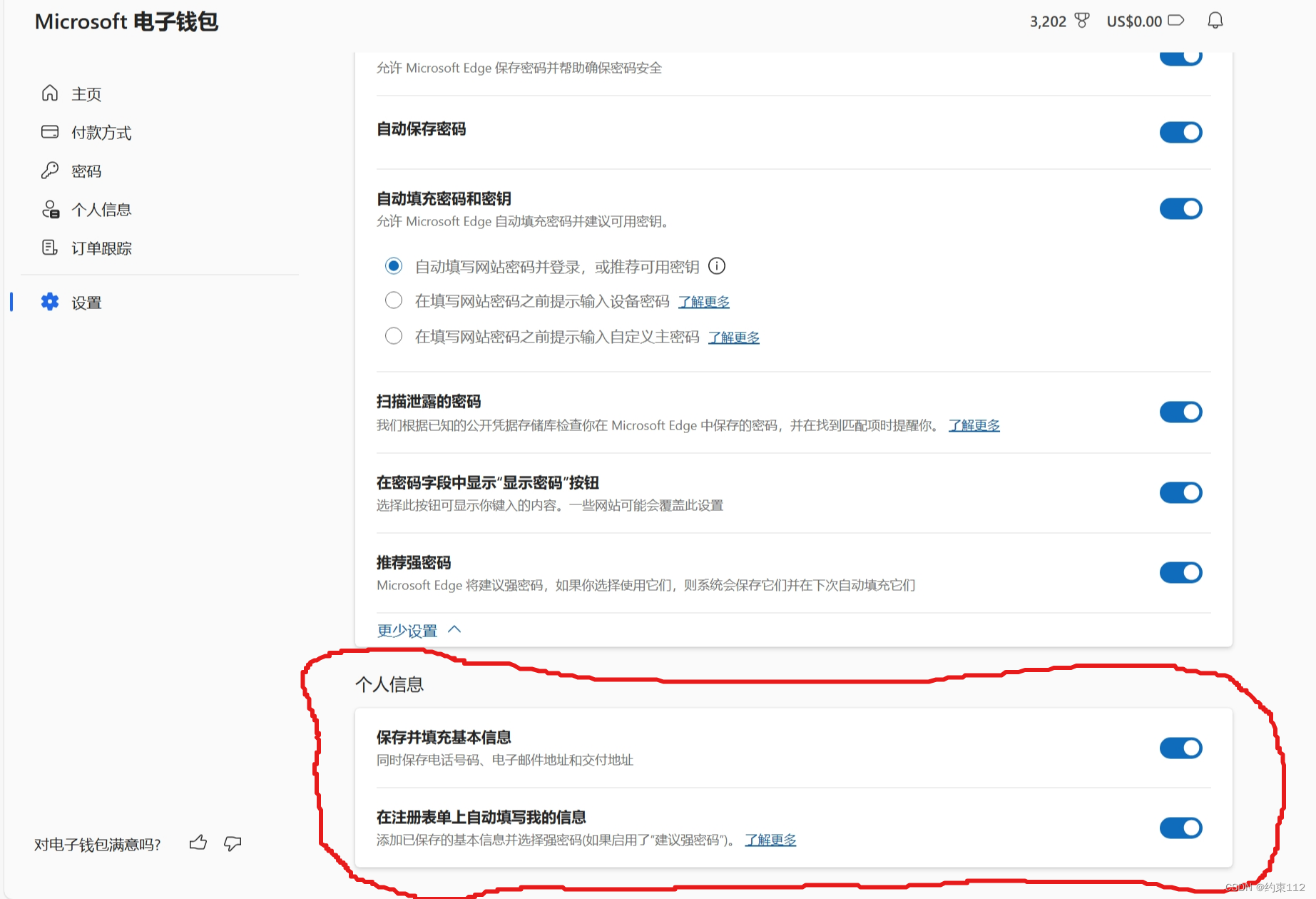
删除edge浏览器文本框储存记录值以及关闭自动填充
当我们点击输入框时总会出现许多以前输入过的信息。 一、删除edge浏览器文本框储存记录值 1、首先按下↓键选中你想删除的信息 二、关闭自动填充。 1、在地址栏输入edge://wallet/settings跳转到以下界面 2、往下滑找到 全部取消即可...
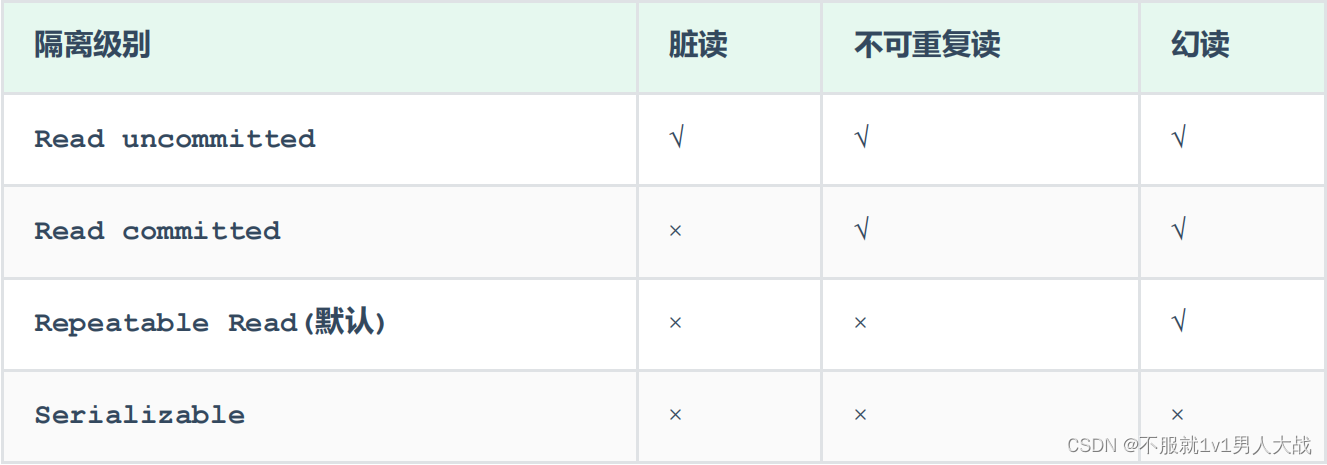
mysql事务 事务并发问题 隔离级别 以及原理
mysql事务 简介:事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 事务四大特性 原子性(Atomici…...

Android 性能为王时代SparseArray和HashMap一争高下
文章目录 一、SparseArray 源码分析1. **类定义和构造函数**2. **基本方法**2.1 put(int key, E value)2.2 get(int key)2.3 delete(int key)2.4 removeAt(int index)2.5 gc()2.6 size()2.7 keyAt(int index) 和 valueAt(int index) 3. **辅助方法**3.1 binarySearch() 二、使用…...
学术图表的基本配色方法
不论是商业图表还是专业图表,图表的配色都极其关键。图表配色主要有彩色和黑白两种配色方案。刘万祥老师曾提出: “在我看来,普通图表与专业图表的差别,很大程度就体现在颜色运用上。” 对于科学图表,大部分国内的期…...
【学习笔记】Webpack5(Ⅱ)
Webpack 3、高级篇 3.1、提升开发体验 —— SourceMap 3.2、提升打包速度 3.2.1 HotModuleReplacement 3.2.2 OneOf 3.2.3 Include / Exclude 3.2.4 Cache 3.2.5 Thread 3.3、减少代码体积 …...

oracle碎片整理
1、move碎片整理 1) DECLARE tmp_val VARCHAR2 (500); BEGIN FOR REC IN (SELECT TABLE_NAME FROM USER_TABLES ) LOOP tmp_val:=ALTER TABLE || REC.TABLE_NAME || MOVE; BEGIN EXECUTE IMMEDIATE tmp_val; DBMS_OUTPUT.ENABLE(buffer_size => null); DBMS_OUTPUT.put_l…...

民国漫画杂志《时代漫画》第15期.PDF
时代漫画15.PDF: https://url03.ctfile.com/f/1779803-1247458444-8befd8?p9586 (访问密码: 9586) 《时代漫画》的杂志在1934年诞生了,截止1937年6月战争来临被迫停刊共发行了39期。 ps:资源来源网络!...
Alamofire常见GET/POST等请求方式的使用,响应直接为json
Alamofire 官方仓库地址:https://github.com/Alamofire/Alamofire xcode中安装和使用:swift网络库Alamofire的安装及简单使用,苹果开发必备-CSDN博客 Alamofire是一个基于Swift语言开发的优秀网络请求库。它封装了底层的网络请求工作&…...

三分钟一条AI小和尚视频 ,日引300+创业粉。单日变现四位数 全套工具
经过六个月的不懈努力和无数次的尝试错误,我终于找到了一个高效引流和积累粉丝的新策略,并愿意与大家无私分享。这一次,我将详尽地介绍这个方法,建议朋友们多次观看以彻底掌握其精髓。 简而言之,该策略主要依托于AI绘…...
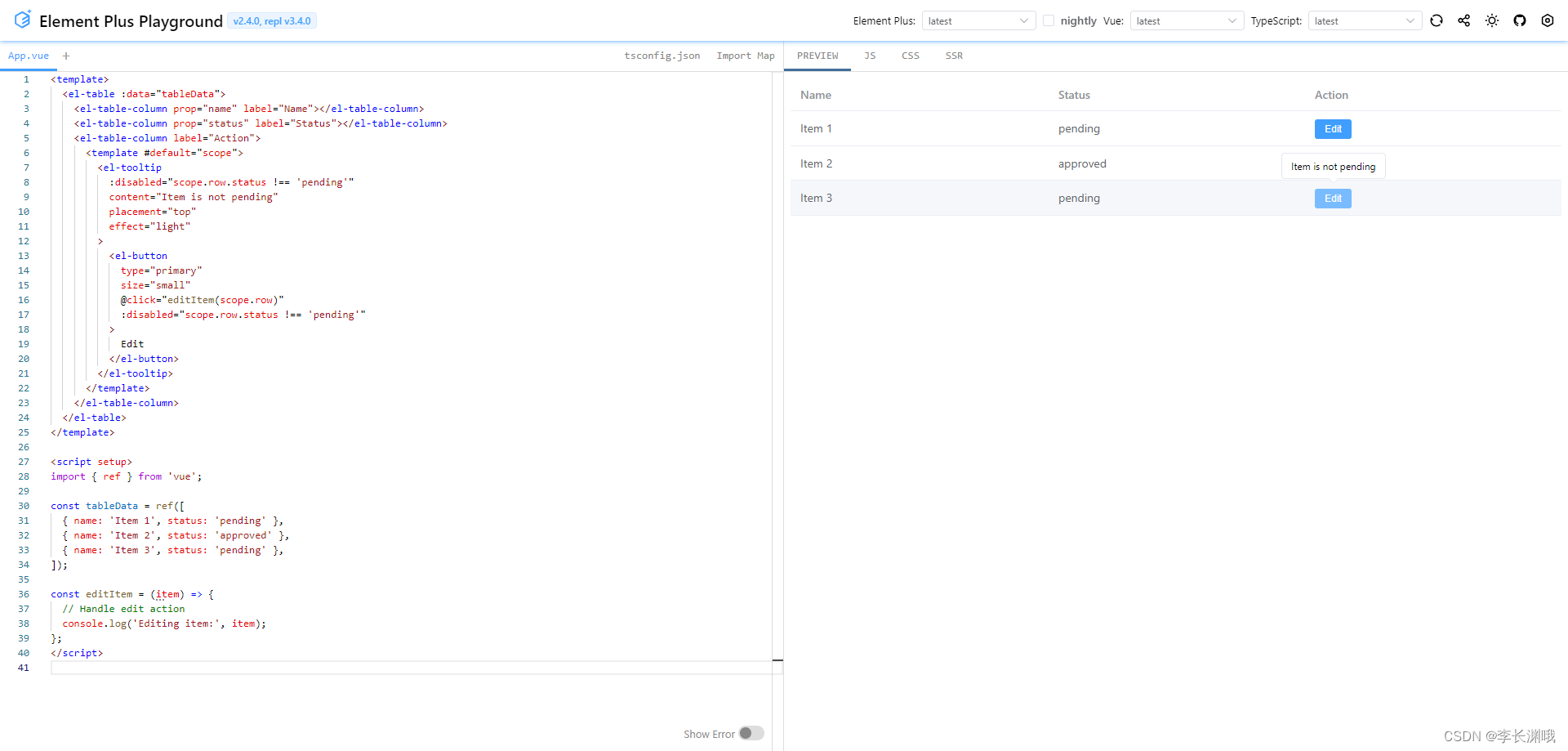
vue3中表格中通过判断某个字段来设置对应按钮和消息提示的disabled展示
vue3中表格中通过判断某个字段来设置对应按钮和消息提示的disabled展示 一、前言1.代码案例2.效果展示 一、前言 当使用 Vue 3 和 Element UI 的 el-table 组件时,你可以通过判断字段的值来设置对应的 el-button 的 disabled 属性和消息提示。下面是一个简单的示例…...

产品经理-交互说明撰写(八)
1. 交互说明 交互说明可以看做是交互设计师或者产品经理输出的最核心的”产品“交互说明面向的”用户“是下游的同事 ⇒ UI设计师、开发工程师、测试工程师 2. 基本交互形式 2.1 页面交互 2.2 元素控件交互 3. 交互说明主要包括以下3个维度 3.1 页面流程(页面之…...

Rust:struct 与字节序列的相互转换
在 Rust 中,将结构体(struct)与字节序列(Vec<u8>)相互转换的常见方法是使用序列化和反序列化库。Rust 有一个流行的序列化库叫做 serde,它支持多种数据格式。为了将结构体转换为字节序列,…...

在https的系统中挂载其他http系统的画面的解决方案
目录 1.问题及说明 2.解决方案及示例 3.总结 1.问题及说明 A系统使用了https,在A系统中挂载B系统的http的画面,会报错如下: Mixed Content: The page at https://beef.zz.com/front/#/biz/cultivationList/cultivationDetails/5dbf836751…...

mysql存储比特位
一、介绍 二、SQL CREATE TABLE bits_table (id INT PRIMARY KEY AUTO_INCREMENT,bit_value BIGINT UNSIGNED );-- 插入一个 8 位的 BIT 值 INSERT INTO bits_table (bit_value) VALUES (B10101010);-- 查询并格式化输出 SELECT id,bit_value,CONCAT(b, LPAD(BIN(bit_value),…...

【Java后端开发】花了2k+多的人民币,烧了几十亿Token,慢慢整理出来适用于Java开发人员的codex配置,还在持续优化中
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...

1000个文件重命名,1秒完成!批量文件重命名软件
前言: 大家好,这里是惠众资料库, 在日常办公、资料归档、素材整理、摄影剪辑等各类场景中,用户会积累大量图片、文档、视频、音频、文件夹等各类文件。为了实现文件分类规整、统一命名规范、方便快速检索调用,文件重命…...

缓存设计:从 LRU 到 Redis 实战
摘要:缓存是提升系统性能的第一道防线,也是面试中系统设计环节的核心话题。本文系统讲解缓存的四大置换策略、LRU 和 LFU 的实现原理,并结合 Python 代码展示完整的缓存系统。AI 开发者还将学到 KV Cache 在 LLM 推理中的关键作用。一、为什么…...

AI正在重构工程师岗位:被替代的不是“人”,而是低维度能力
过去很多人认为,AI更适合写文案、做客服、生成图片,而真正复杂的工程领域——尤其是工业、制造、自动化系统——依然离不开工程师。 但最近一个劳动仲裁案例,让越来越多工程技术人员开始重新思考这个问题: 一位从事测绘工作15年的工程师,因为企业全面导入AI自动化测绘系…...

实际开发中 SQL 与产品的耦合与互动实践
引言 在产品开发初期,数据库 Schema(表结构)的设计是一个绕不开的核心问题。很多开发者,尤其是新手,常常会陷入一个两难境地:“Schema 需要一开始就完全确定好吗?如果后期要改动怎么办?到底要设计多少个表(Schema 数量)才算合适?” 这些问题背后,反映的是对软件工…...
)
HarmonyOS 鸿蒙PC平台三方库移植:使用 vcpkg 移植 libzen(ZenLib)
网罗开发(小红书、快手、视频号同名)大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等方…...

解析美国RTP导热工程塑料在电子散热领域的性能表现与行业应用
美国RTP导热工程塑料通过填充陶瓷、金属等导热介质提升材料热导率,同时保持优异机械性能与绝缘特性,完美适配电子散热场景。行业数据显示其热导率可达1-20 W/(mK),远超普通塑料0.2W/(mK)水平,成为解决电子设备过热问题的优选方案。…...

美国联邦AI资助逻辑:问题驱动型资金如何塑造技术路线
1. 项目概述:这不只是经费数字,而是AI技术路线的投票器“联邦政府对人工智能研究的资金投入现状”——这个标题乍看像一份政策简报的副标题,但在我过去十年跟踪科技政策与AI产业交叉点的过程中,它实际是一把解剖美国创新生态系统的…...
》第4.2条直指Agent记忆泄露风险:3类必查缓存节点+2分钟自检脚本)
紧急!财政部新发《AI增强型审计工作指引(试行)》第4.2条直指Agent记忆泄露风险:3类必查缓存节点+2分钟自检脚本
更多请点击: https://kaifayun.com 第一章:AI Agent审计行业应用 AI Agent在审计行业的深度渗透正重塑传统作业范式。不同于规则驱动的RPA工具,AI Agent具备目标分解、工具调用、多步推理与自主反馈能力,可动态适配审计场景中的非…...

移动储能车远程管理平台解决方案
随着新能源产业快速发展,移动储能车作为灵活、高效的储能载体,在应急保电、抢险救援、野外作业、电网增容等场景中应用日益广泛。然而,传统管理模式下,车辆分布广、工况复杂,存在运行状态不可视、故障响应滞后、运维成…...