授权调用: 介绍 Transformers 智能体 2.0
简要概述
我们推出了 Transformers 智能体 2.0!
⇒ 🎁 在现有智能体类型的基础上,我们新增了两种能够 根据历史观察解决复杂任务的智能体。
⇒ 💡 我们致力于让代码 清晰、模块化,并确保最终提示和工具等通用属性透明化。
⇒ 🤝 我们加入了 分享功能,以促进社区智能体的发展。
⇒ 💪 全新的智能体框架性能卓越,使得 Llama-3-70B-Instruct 智能体在 GAIA 排行榜上超越了基于 GPT-4 的智能体!
🚀 快去体验,力争在 GAIA 排行榜上名列前茅!
什么是智能体?
大型语言模型 (LLMs) 能够处理广泛的任务,但它们通常在逻辑、计算和搜索等特定任务上表现不佳。当在这些它们表现不好的领域被提示时,它们经常无法生成正确的答案。
克服这种弱点的一种方法就是创建一个 智能体,它只是一个由 LLM 驱动的程序。智能体通过 工具 获得能力,帮助它执行动作。当智能体需要特定技能来解决特定问题时,它会依赖于工具箱中的适当工具。
因此,在解决问题时,如果智能体需要特定技能,它可以直接依赖于工具箱中的适当工具。
实验上,智能体框架通常表现非常好,在多个基准测试上达到了 SOTA。例如,看看 HumanEval 的最上面的提交: 它们就是智能体系统。
HumanEval 的最上面的提交https://paperswithcode.com/sota/code-generation-on-humaneval
Transformers 智能体方法
构建智能体的过程很复杂,需要高水平的清晰度和模块化设计。一年前,我们发布了 Transformers 智能体,现在我们正加倍努力实现我们的核心设计目标。
我们的框架力求实现:
简化以提升清晰度: 我们将抽象减少到最低限度。简单的错误日志和可访问的属性让你轻松检查系统发生的情况,从而获得更多的清晰度。
模块化设计: 我们更愿意提供构建模块,而不是一个完整、复杂的特性集。这样你可以自由选择最适合你的项目的构建模块。
例如,由于任何智能体系统只是由 LLM 引擎驱动的载体,我们决定在概念上分离这两者,使你可以用任何底层 LLM 创建任何类型的智能体。
此外,我们还提供 分享功能,让你能在前人的基础上继续构建!
主要元素
Tool(工具): 这是一个类,允许你使用工具或实现一个新的工具。它主要由一个可调用的前向method组成,执行工具动作,以及一些必要的属性:name(名称) 、descriptions(描述) 、inputs(输入) 和output_type(输出类型)。这些属性用于动态生成工具的使用手册,并将其插入到 LLM 的提示中。Toolbox(工具箱): 这是一组工具,作为资源提供给智能体,用于解决特定任务。出于性能考虑,工具箱中的工具已经实例化并准备好使用。这是因为某些工具需要时间来初始化,所以通常更好的是重用现有的工具箱,只更换一个工具,而不是在每次智能体初始化时从头开始构建一组工具。CodeAgent(代码智能体): 一个非常简单的智能体,其动作作为单个 Python 代码块生成。它将无法对先前的观察进行迭代。ReactAgent(反应智能体): ReAct 智能体遵循一个循环: 思考 ⇒ 行动 ⇒ 观察直到解决任务。我们提出了两种 ReActAgent 类:ReactCodeAgent(反应代码智能体) 将其动作作为 Python 代码块生成。ReactJsonAgent(反应 JSON 智能体) 将其动作作为 JSON 代码块生成。
查看 文档 了解如何使用每个组件!
文档链接https://hf.co/docs/transformers/en/main_classes/agent
智能体在底层是如何工作的?
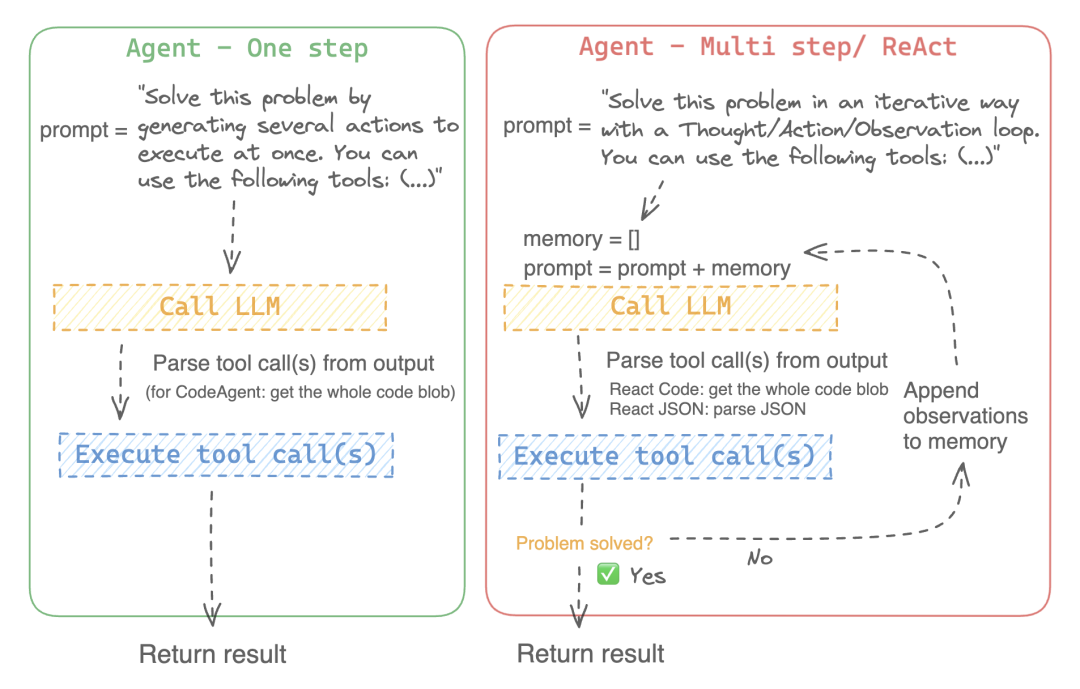
本质上,智能体的作用是“允许 LLM 使用工具”。智能体有一个关键的 agent.run() 方法,该方法:
在一个 特定提示 中向你的 LLM 提供关于工具使用的信息。这样,LLM 可以选择运行工具来解决任务。
解析 来自 LLM 输出的工具调用 (可以通过代码、JSON 格式或任何其他格式)。
执行 调用。
如果智能体被设计为对先前的输出进行迭代,它会 保留 先前的工具调用和观察的记忆。这个记忆可以根据你希望它持续的时间长短而变得更加或更少细致。
关于智能体的更多一般背景信息,你可以阅读 Lilian Weng 的 这篇优秀博客,或者阅读我们之前的博客,关于使用 LangChain 构建 智能体。
博客地址https://lilianweng.github.io/posts/2023-06-23-agent/
智能体https://hf.co/blog/open-source-llms-as-agents
要深入了解我们的包,请查看 智能体文档。
智能体文档https://hf.co/docs/transformers/en/transformers_agents
示例用例
为了获得此功能的早期访问权限,请首先从其 main 分支安装 transformers :
pip install "git+https://github.com/huggingface/transformers.git#egg=transformers[agents]"智能体 2.0 将在 v4.41.0 版本中发布,预计将于五月中旬上线。
自我修正的检索增强生成
快速定义: 检索增强生成 (RAG) 是“使用 LLM 回答用户查询,但基于从知识库检索到的信息来回答”。与使用普通或微调的 LLM 相比,它有许多优点: 举几个例子,它允许基于真实事实来回答问题,减少虚构,它允许向 LLM 提供特定领域的知识,并且可以细粒度地控制对知识库信息的访问。
假设我们想要执行 RAG,并且某些参数必须动态生成。例如,根据用户查询,我们可能想要将搜索限制在知识库的特定子集,或者我们可能想要调整检索到的文档数量。难题是: 如何根据用户查询动态调整这些参数?嗯,我们可以通过让我们的智能体访问这些参数来实现!
让我们设置这个系统。
安装以下依赖项:
pip install langchain sentence-transformers faiss-cpu我们首先加载一个想要在其上执行 RAG 的知识库: 这个数据集是许多 huggingface 包的文档页面汇编,以 markdown 格式存储。
import datasets
knowledge_base = datasets.load_dataset("m-ric/huggingface_doc", split="train")现在我们通过处理数据集并将其存储到向量数据库中来准备知识库,以便检索器使用。我们将使用 LangChain,因为它具有用于向量数据库的优秀工具:
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddingssource_docs = [Document(page_content=doc["text"], metadata={"source": doc["source"].split("/")[1]}) for doc in knowledge_base
]docs_processed = RecursiveCharacterTextSplitter(chunk_size=500).split_documents(source_docs)[:1000]embedding_model = HuggingFaceEmbeddings("thenlper/gte-small")
vectordb = FAISS.from_documents(documents=docs_processed,embedding=embedding_model
)现在我们已经准备好了数据库,让我们构建一个基于它回答用户查询的 RAG 系统!
我们希望我们的系统根据查询仅从最相关的信息来源中选择。
我们的文档页面来自以下来源:
>>> all_sources = list(set([doc.metadata["source"] for doc in docs_processed]))
>>> print(all_sources)['blog', 'optimum', 'datasets-server', 'datasets', 'transformers', 'course',
'gradio', 'diffusers', 'evaluate', 'deep-rl-class', 'peft',
'hf-endpoints-documentation', 'pytorch-image-models', 'hub-docs']我们如何根据用户查询选择相关的来源?
👉 让我们构建一个 RAG 系统作为智能体,它将自由选择其信息来源!
我们创建一个检索工具,智能体可以使用它选择的参数来调用:
import json
from transformers.agents import Tool
from langchain_core.vectorstores import VectorStoreclass RetrieverTool(Tool):name = "retriever"description = "Retrieves some documents from the knowledge base that have the closest embeddings to the input query."inputs = {"query": {"type": "text","description": "The query to perform. This should be semantically close to your target documents. Use the affirmative form rather than a question.",},"source": {"type": "text","description": ""},}output_type = "text"def __init__(self, vectordb: VectorStore, all_sources: str, **kwargs):super().__init__(**kwargs)self.vectordb = vectordbself.inputs["source"]["description"] = (f"The source of the documents to search, as a str representation of a list. Possible values in the list are: {all_sources}. If this argument is not provided, all sources will be searched.")def forward(self, query: str, source: str = None) -> str:assert isinstance(query, str), "Your search query must be a string"if source:if isinstance(source, str) and "[" not in str(source): # if the source is not representing a listsource = [source]source = json.loads(str(source).replace("'", '"'))docs = self.vectordb.similarity_search(query, filter=({"source": source} if source else None), k=3)if len(docs) == 0:return "No documents found with this filtering. Try removing the source filter."return "Retrieved documents:\n\n" + "\n===Document===\n".join([doc.page_content for doc in docs])现在创建一个利用这个工具的智能体就很简单了!
智能体在初始化时需要以下参数:
tools: 智能体将能够调用的工具列表。llm_engine: 驱动智能体的 LLM。
我们的 llm_engine 必须是一个可调用的对象,它接受一个 messages 列表作为输入并返回文本。它还需要接受一个 stop_sequences 参数,指示何时停止生成。为了方便起见,我们直接使用包中提供的 HfEngine 类来获取一个调用我们的 Inference API 的 LLM 引擎。
messageshttps://hf.co/docs/transformers/main/chat_templating
Inference APIhttps://hf.co/docs/api-inference/en/index
from transformers.agents import HfEngine, ReactJsonAgentllm_engine = HfEngine("meta-llama/Meta-Llama-3-70B-Instruct")agent = ReactJsonAgent(tools=[RetrieverTool(vectordb, all_sources)],llm_engine=llm_engine
)agent_output = agent.run("Please show me a LORA finetuning script")print("Final output:")
print(agent_output)由于我们将智能体初始化为 ReactJsonAgent ,它已经自动获得了一个默认的系统提示,告诉 LLM 引擎逐步处理并生成工具调用作为 JSON 代码块 (根据需要,你可以替换此提示模板)。
然后,当它的 .run() 方法被启动时,智能体会负责调用 LLM 引擎,解析工具调用的 JSON 代码块并执行这些工具调用,所有这些都在一个循环中进行,只有在提供最终答案时才会结束。
我们得到以下输出:
Calling tool: retriever with arguments: {'query': 'LORA finetuning script', 'source': "['transformers', 'datasets-server', 'datasets']"}
Calling tool: retriever with arguments: {'query': 'LORA finetuning script'}
Calling tool: retriever with arguments: {'query': 'LORA finetuning script example', 'source': "['transformers', 'datasets-server', 'datasets']"}
Calling tool: retriever with arguments: {'query': 'LORA finetuning script example'}
Calling tool: final_answer with arguments: {'answer': 'Here is an example of a LORA finetuning script: https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L371'}Final output:
Here is an example of a LORA finetuning script: https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L371我们可以看到自我修正的实际效果: 智能体最初尝试限制来源,但由于缺乏相应的文档,它最终没有限制任何来源。
我们可以通过检查第二步的日志中的 llm 输出来验证这一点: print(agent.logs[2]['llm_output']) 。
Thought: I'll try to retrieve some documents related to LORA finetuning scripts from the entire knowledge base, without any source filtering.Action:
{"action": "retriever","action_input": {"query": "LORA finetuning script"}
}使用简单的多智能体设置 🤝 进行高效的网页浏览
在这个例子中,我们想要构建一个智能体并在 GAIA 基准测试上对其进行测试 (Mialon et al. 2023)。GAIA 是一个非常困难的基准测试,大多数问题需要使用不同的工具进行多个步骤的推理。一个特别困难的要求是拥有一个强大的网络浏览器,能够导航到具有特定约束条件的页面: 使用网站的内部导航发现页面,按时间选择特定的文章 …
Mialon et al. 2023https://hf.co/papers/2311.12983
网页浏览需要深入到子页面并滚动大量不必要的文本标记,这对于解决更高级别的任务是不必要的。我们将网页浏览的子任务分配给一个专业的网页浏览智能体。我们为其提供了一些浏览网页的工具和一个特定的提示 (查看仓库以找到特定的实现)。
定义这些工具超出了本文的范围: 但是你可以在 仓库 中找到特定的实现。
仓库地址https://github.com/aymeric-roucher/agent_reasoning_benchmark
from transformers.agents import ReactJsonAgent, HfEngineWEB_TOOLS = [SearchInformationTool(),NavigationalSearchTool(),VisitTool(),DownloadTool(),PageUpTool(),PageDownTool(),FinderTool(),FindNextTool(),
]websurfer_llm_engine = HfEngine(model="CohereForAI/c4ai-command-r-plus"
) # 我们选择 Command-R+ 因为它具有很高的上下文长度websurfer_agent = ReactJsonAgent(tools=WEB_TOOLS,llm_engine=websurfer_llm_engine,
)为了允许更高层次的任务解决智能体调用这个智能体,我们可以简单地将其封装在另一个工具中:
class SearchTool(Tool):name = "ask_search_agent"description = "A search agent that will browse the internet to answer a question. Use it to gather informations, not for problem-solving."inputs = {"question": {"description": "Your question, as a natural language sentence. You are talking to an agent, so provide them with as much context as possible.","type": "text",}}output_type = "text"def forward(self, question: str) -> str:return websurfer_agent.run(question)然后我们使用这个搜索工具初始化任务解决智能体:
from transformers.agents import ReactCodeAgentllm_engine = HfEngine(model="meta-llama/Meta-Llama-3-70B-Instruct")
react_agent_hf = ReactCodeAgent(tools=[SearchTool()],llm_engine=llm_engine,
)让我们做这个任务:
使用 Marisa Alviar-Agnew 和 Henry Agnew 根据 CK-12 许可在 LibreText 的《初级化学》材料中提供的密度数据,编译日期为 2023 年 8 月 21 日。我有一加仑的蜂蜜和一加仑的蛋黄酱,温度为 25 摄氏度。我每次从一加仑蜂蜜中取出一杯蜂蜜。我要取出多少次一杯蜂蜜,才能使蜂蜜的重量低于蛋黄酱?假设容器本身的重量相同。
Thought: I will use the 'ask_search_agent' tool to find the density of honey and mayonnaise at 25C.
==== Agent is executing the code below:
density_honey = ask_search_agent(question="What is the density of honey at 25C?")
print("Density of honey:", density_honey)
density_mayo = ask_search_agent(question="What is the density of mayonnaise at 25C?")
print("Density of mayo:", density_mayo)
===
Observation:
Density of honey: The density of honey is around 1.38-1.45kg/L at 20C. Although I couldn't find information specific to 25C, minor temperature differences are unlikely to affect the density that much, so it's likely to remain within this range.
Density of mayo: The density of mayonnaise at 25°C is 0.910 g/cm³.===== New step =====
Thought: I will convert the density of mayonnaise from g/cm³ to kg/L and then calculate the initial weights of the honey and mayonnaise in a gallon. After that, I will calculate the weight of honey after removing one cup at a time until it weighs less than the mayonnaise.
==== Agent is executing the code below:
density_honey = 1.42 # taking the average of the range
density_mayo = 0.910 # converting g/cm³ to kg/L
density_mayo = density_mayo * 1000 / 1000 # conversiongallon_to_liters = 3.785 # conversion factor
initial_honey_weight = density_honey * gallon_to_liters
initial_mayo_weight = density_mayo * gallon_to_literscup_to_liters = 0.236 # conversion factor
removed_honey_weight = cup_to_liters * density_honey
===
Observation:===== New step =====
Thought: Now that I have the initial weights of honey and mayonnaise, I'll try to calculate the number of cups to remove from the honey to make it weigh less than the mayonnaise using a simple arithmetic operation.
==== Agent is executing the code below:
cups_removed = int((initial_honey_weight - initial_mayo_weight) / removed_honey_weight) + 1
print("Cups removed:", cups_removed)
final_answer(cups_removed)
===
>>> Final answer: 6✅ 答案是 正确的!
测试我们的智能体
让我们使用智能体框架进行一些基准测试,看看不同模型的表现!
以下实验的所有代码都可以在 这里 找到。
实验代码仓库https://github.com/aymeric-roucher/agent_reasoning_benchmark
基准测试大型语言模型引擎
agents_reasoning_benchmark 是一个小型但强大的推理测试,用于评估智能体性能。这个基准测试已经在 我们之前的博客 中使用并进行了更详细的解释。
我们之前的博客https://hf.co/blog/open-source-llms-as-agents
这个想法是,你为智能体使用的工具选择可以极大地改变某些任务的性能。因此,这个基准测试限制了使用的工具集为一个计算器和一个非常基础的搜索工具。我们从几个数据集中挑选了问题,这些问题只能使用这两个工具来解决:
来自 HotpotQA 的 30 个问题 (Yang et al., 2018),用于测试搜索工具的使用。
来自 GSM8K 的 40 个问题 (Cobbe et al., 2021),用于测试计算器工具的使用。
来自 GAIA 的 20 个问题 (Mialon et al., 2023),用于测试使用这两个工具解决困难问题的能力。
HotpotQAhttps://hf.co/datasets/hotpot_qa
Yang et al., 2018https://hf.co/papers/1809.09600
GSM8Khttps://hf.co/datasets/gsm8k
Cobbe et al., 2021https://hf.co/papers/2110.14168
GAIAhttps://hf.co/datasets/gaia-benchmark/GAIA
Mialon et al., 2023https://hf.co/papers/2311.12983
在这里,我们尝试了三种不同的引擎: Mixtral-8x7B, Llama-3-70B-Instruct,和 GPT-4 Turbo。
Mixtral-8x7Bhttps://hf.co/mistralai/Mixtral-8x7B-Instruct-v0.1
Llama-3-70B-Instructhttps://hf.co/meta-llama/Meta-Llama-3-70B-Instruct
GPT-4 Turbohttps://platform.openai.com/docs/models
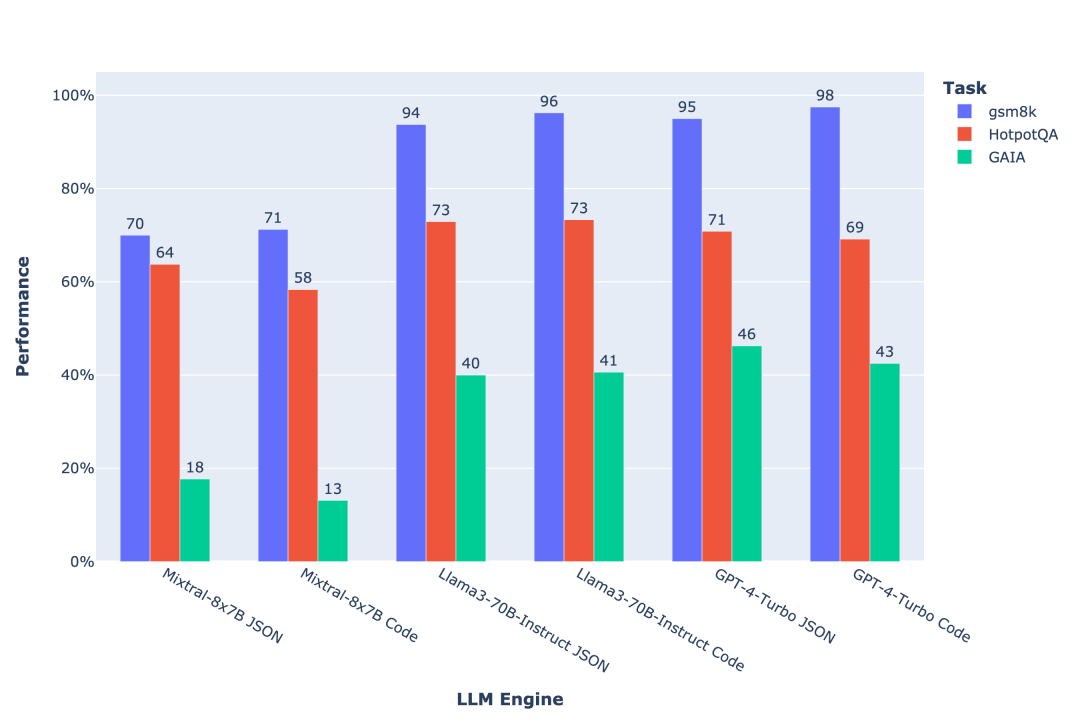
结果在上方显示 - 为了提高精度,我们显示了两轮完整运行的平均值。我们还测试了 Command-R+ 和 Mixtral-8x22B,但由于清晰度原因,这里没有显示。
Command-R+https://hf.co/CohereForAI/c4ai-command-r-plus
Mixtral-8x22Bhttps://hf.co/mistralai/Mixtral-8x22B-Instruct-v0.1
⇒ Llama-3-70B-Instruct 在开源模型中领先: 它与 GPT-4 相当,尤其在与 ReactCodeAgent 的结合中表现出色,得益于 Llama 3 强大的编码性能!
💡 比较基于 JSON 和基于代码的 React 智能体很有趣: 对于像 Mixtral-8x7B 这样较弱的 LLM 引擎,基于代码的智能体不如基于 JSON 的智能体表现好,因为 LLM 引擎经常无法生成好的代码。但随着更强大的模型作为引擎,基于代码的版本表现尤为出色: 在我们的经验中,基于代码的版本甚至在使用 Llama-3-70B-Instruct 时超越了基于 JSON 的版本。因此,我们使用基于代码的版本进行下一个挑战: 在完整的 GAIA 基准测试上进行测试。
使用多模态智能体刷 GAIA 排行榜
GAIA (Mialon et al., 2023) 是一个非常困难的基准测试: 在上面的 agent_reasoning_benchmark 中可以看到,即使我们挑选了可以使用两种基本工具解决的任务,模型也几乎没有达到 50% 的表现。
GAIAhttps://hf.co/datasets/gaia-benchmark/GAIA
Mialon et al., 2023https://hf.co/papers/2311.12983
现在我们想要在完整的测试集上获得分数,不再挑选问题。因此,我们需要覆盖所有模态,这导致我们使用这些特定的工具:
SearchTool: 如上所述的网页浏览器。TextInspectorTool: 将文档作为文本文件打开并返回其内容。SpeechToTextTool: 将音频文件转录为文本。我们使用基于 distil-whisper 的默认工具。VisualQATool: 分析图像的视觉内容。对于这些,我们使用全新的 Idefics2-8b-chatty!distil-whisperhttps://hf.co/distil-whisper/distil-large-v3
Idefics2-8b-chattyhttps://hf.co/HuggingFaceM4/idefics2-8b-chatty
我们首先初始化这些工具 (更多细节,请检查 仓库 中的代码)。
仓库https://github.com/aymeric-roucher/agent_reasoning_benchmark
然后我们初始化我们的智能体:
from transformers.agents import ReactCodeAgent, HfEngineTASK_SOLVING_TOOLBOX = [SearchTool(),VisualQATool(),SpeechToTextTool(),TextInspectorTool(),
]react_agent_hf = ReactCodeAgent(tools=TASK_SOLVING_TOOLBOX,llm_engine=HfEngine(model="meta-llama/Meta-Llama-3-70B-Instruct"),memory_verbose=True,
)在完成 165 个问题所需的一段时间后,我们提交了我们的结果到 GAIA 排行榜,然后…… 🥁🥁🥁
GAIA 排行榜https://hf.co/spaces/gaia-benchmark/leaderboard
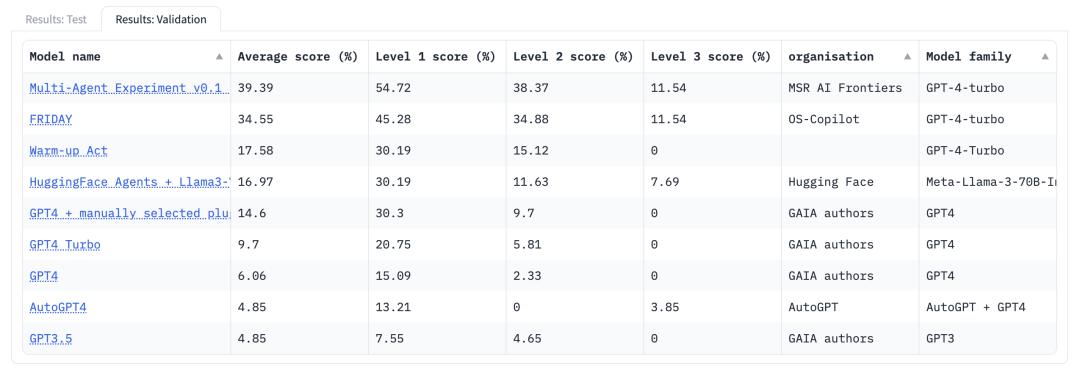
⇒ 我们的智能体排名第四: 它超过了许多基于 GPT-4 的智能体,现在已成为开源类别中的领先竞争者!
总结
在接下来的几个月里,我们将继续改进这个包。我们已经在我们开发路线图中确定了几个令人兴奋的路径:
更多的智能体共享选项: 目前你可以从 Hub 推送或加载工具,我们将实现推送/加载智能体。
更好的工具,特别是用于图像处理。
长期记忆管理。
多智能体协作。
👉 去尝试一下 Transformers 智能体! 我们期待着收到你的反馈和你的想法。
让我们一起用更多的开源模型刷排行榜登顶!🚀
英文原文: https://hf.co/blog/agents
原文作者: Aymeric Roucher, Lysandre, Pedro Cuenca
译者: innovation64
相关文章:
授权调用: 介绍 Transformers 智能体 2.0
简要概述 我们推出了 Transformers 智能体 2.0! ⇒ 🎁 在现有智能体类型的基础上,我们新增了两种能够 根据历史观察解决复杂任务的智能体。 ⇒ 💡 我们致力于让代码 清晰、模块化,并确保最终提示和工具等通用属性透明化…...

流媒体内网穿透/组网/视频协议转换EasyNTS上云网关如何更改密码?
EasyNTS上云网关的主要作用是解决异地视频共享/组网/上云的需求,网页对域名进行添加映射时,添加成功后会生成一个外网访问地址,在浏览器中输入外网访问地址,即可查看内网应用。无需开放端口,EasyNTS上云网关平台会向Ea…...
HTML5的标签(文本链接、图片路径详解)
目录 前言 一、文本链接 超链接表述 二、图片路径详解 绝对路径 相对路径 网络路径 前言 一、文本链接 超链接表述 HTML 使用标签<a>来设置超文本链接 超链接可以是一个字,一个词,或者一组词,也可以是一幅图像,…...
(十五))
React Native 之 Linking(链接)(十五)
URL Scheme是什么 URL Scheme是一种机制,主要用于在移动应用程序中打开另一个应用程序或执行特定操作。 定义与原理: URL Scheme允许应用程序通过特定的URL格式与其他应用程序进行交互。 它通过在应用程序中注册一个自定义的URL Scheme,并在…...

Java实现图书系统
首先实现一个图书管理系统,我们要知道有哪些元素? 1.用户分成为管理员和普通用户 2.书:书架 书 3.操作的是: 书架 目录 第一步:建包 第二步:搭建框架 首先:完成book中的方法 其次:完成BookList 然后:完成管理员界面和普通用户界面 最后:Main 第三步:细分方法 1.退…...

Git提交和配置命令
一、提交代码到仓库 在软件开发中,版本控制是一个至关重要的环节。而Git作为目前最流行的版本控制系统之一,为我们提供了便捷高效的代码管理和协作工具。在日常开发中,我们经常需要将本地代码提交到远程仓库,以便于团队协作和版本…...

已解决java.lang.ExceptionInInitializerError: 初始化程序中的异常错误的正确解决方法,亲测有效!!!
已解决java.lang.ExceptionInInitializerError: 初始化程序中的异常错误的正确解决方法,亲测有效!!! 目录 问题分析 报错原因 解决思路 解决方法 分析错误栈信息 检查静态初始化块和静态变量 验证资源和配置 使用日志记录…...

报表显示中,是否具备条件格式功能设计?
**报表显示中确实具备条件格式功能设计**。条件格式是一种根据特定条件对单元格或单元格区域进行格式设置的功能,它可以帮助用户更直观地理解和分析数据。 通过条件格式,用户可以设置多种条件,如单元格值的大小、是否包含特定文本等…...

完全二叉树查找
描述 有一棵树,输出某一深度的所有节点,有则输出这些节点,无则输出EMPTY。该树是完全二叉树。 输入描述 输入有多组数据,遇到0时终止输入。 每组输入一个n(1<n<1000),然后将树中的这n个节点依次输入ÿ…...

Web安全:SQL注入之时间盲注原理+步骤+实战操作
「作者简介」:2022年北京冬奥会网络安全中国代表队,CSDN Top100,就职奇安信多年,以实战工作为基础对安全知识体系进行总结与归纳,著作适用于快速入门的 《网络安全自学教程》,内容涵盖系统安全、信息收集等…...
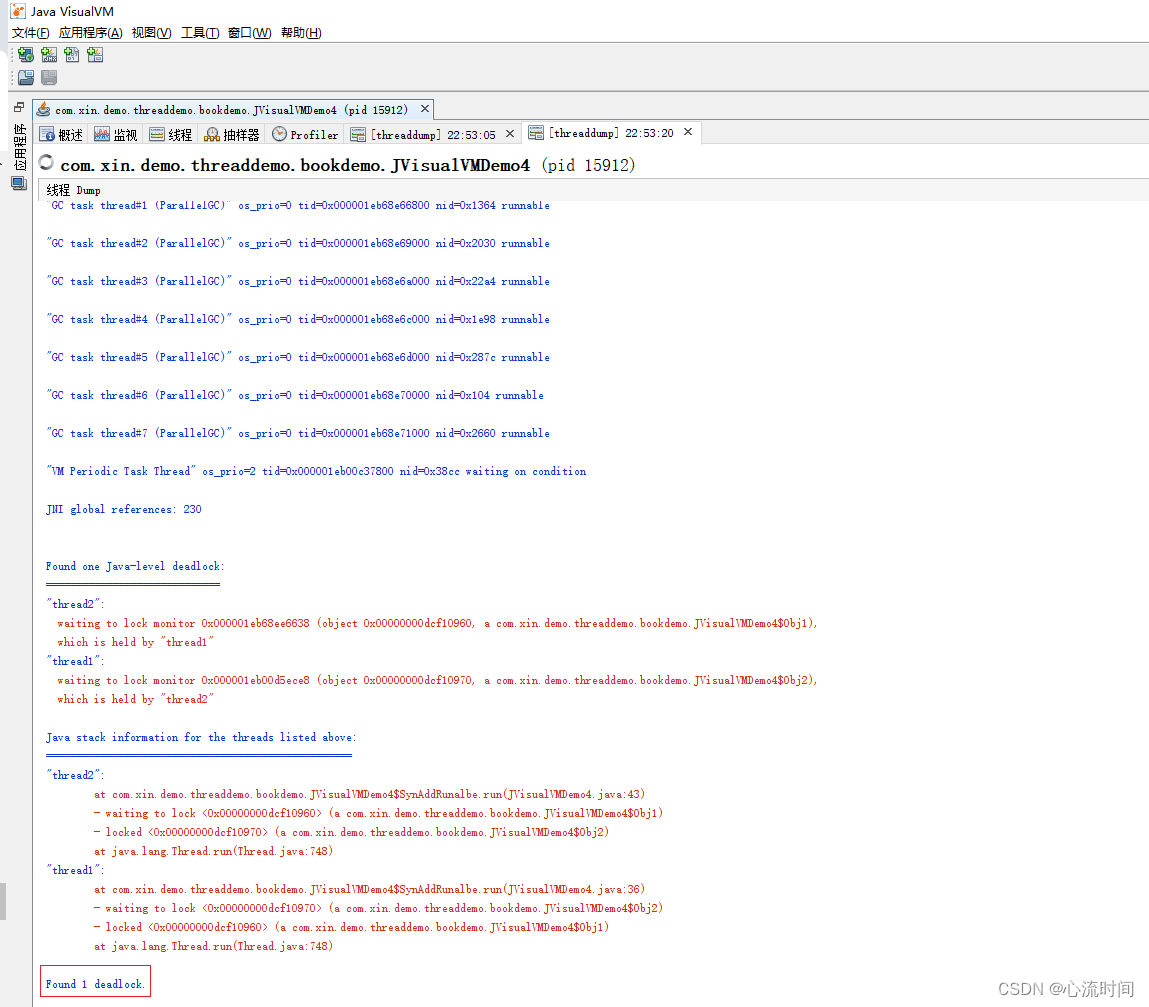
[JDK工具-10] jvisualvm 多合一故障处理工具
文章目录 1. 介绍2. 查看堆的变化3. 查看堆快照4. 导出堆快照文件5. 查看class对象加载信息6. CPU分析:发现cpu使用率最高的方法7. 查看线程快照:发现死锁问题 1. 介绍 VisualVM 是一款免费的,集成了多个 JDK 命令行工具的可视化工具…...
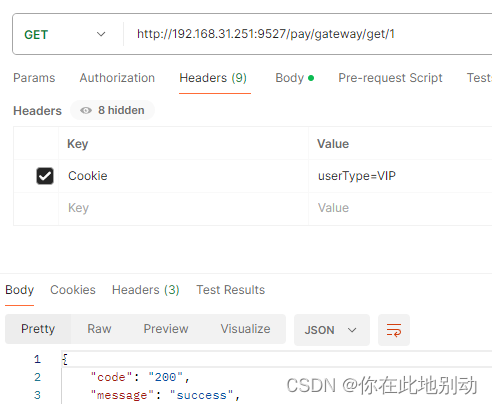
【GateWay】自定义RoutePredicateFactory
需求:对于本次请求的cookie中,如果userType不是vip的身份,不予访问 思路:因为要按照cookie参数进行判断,所以根据官方自带的CookieRoutePredicateFactory进行改造 创建自己的断言类,命名必须符合 xxxRout…...

今日总结2024/5/27
今日学习了状态压缩DP,状态压缩DP分为棋盘型(基于连通性)和集合型 Acwing.1064 小国王 在 nn的棋盘上放 k个国王,国王可攻击相邻的 8个格子,求使它们无法互相攻击的方案总数。 输入格式 共一行,包含两个整数 n和 k。 输出格式 共一行&…...

使用 Snort 进行入侵检测
使用 Snort 进行入侵检测 Snort 是一种流行的开源入侵检测系统。您可以在http://www.snort.org/上获取它。Snort 分析流量并尝试检测和记录可疑活动。Snort 还能够根据其所做的分析发送警报。 Snort 安装 在本课中,我们将从源代码安装。此外,我们不会安…...

C++ | Leetcode C++题解之第116题填充每个节点的下一个右侧节点指针
题目: 题解: class Solution { public:Node* connect(Node* root) {if (root nullptr) {return root;}// 从根节点开始Node* leftmost root;while (leftmost->left ! nullptr) {// 遍历这一层节点组织成的链表,为下一层的节点更新 next…...
计算机网络学习
文章目录 第一章信息时代的计算机网络因特网概述电路交换,分组交换,报文交换计算机网络的定义和分类计算机网络的性能指标常见的三种计算机网络体系计算机网络体系结构分层的必要性计算机网络体系结构分层思想举例计算机网络体系结构中的专用术语 第二章…...

代码随想录算法训练营第四天| 24.两两交换链表中的节点、19.删除链表的倒数第N个节点、面试题 02.07. 链表相交、142.环形链表II
24.两两交换链表中的节点 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 解题思路 很麻烦的一道题目,不是很理解。还是看视频文章才AC的。 解法1 …...
职业探索--运维体系-SRE岗位/CRE岗位/运维岗位-服务心态-运维职业发展方向-运维对象和运维场景
参考来源: 极客时间专栏:赵成的运维体系管理课 极客时间专栏:全栈工程师修炼指南 赵成大佬在鹏讯云社区的文章(77篇) 有了CMDB,为什么还要应用配置管理 故障没有根因,别再找了 如何理解CMDB的套…...
)
深入理解C++智能指针系列(五)
引言 前面两篇介绍了std::unique_ptr的自定义删除器以及如何优化删除器的使用。本文将介绍std::unique_ptr在使用过程中的一些“奇技淫巧”。 正文 删除器和std::move std::move是将对象的所有权转移给另一个对象,那如果通过std::move来转移带自定义删除器的std::…...

1.Nginx上配置 HTTPS
1.安装 Nginx: 如果还没有安装 Nginx,可以使用包管理工具安装。例如,在 Ubuntu 上: sudo apt update sudo apt install nginx2.上传证书和私钥文件: 将你的证书文件和私钥文件上传到服务器上的某个目录,…...

Pandas 数据处理进阶:缺失值、合并、分组聚合与透视表
Pandas 数据处理进阶:缺失值、合并、分组聚合与透视表 在完成 pandas 的基础操作(索引、筛选、赋值、函数应用)之后,下一步便是处理真实数据中常见的问题:缺失值、多表合并、分组统计以及数据透视。本文带你系统掌握这…...

【204期】异地组网一键联机工具
想和朋友异地联机打单机游戏,结果发现没有公网IP连不上?或者居家办公想访问公司局域网里的文件,搞了半天搞不定?今天聊的这类异地组网、内网穿透工具,就是专门解决这些问题的。它能把一个个单独的局域网连接起来&#…...

Ender-3固件配置终极指南:5步简单快速性能优化
Ender-3固件配置终极指南:5步简单快速性能优化 【免费下载链接】Ender-3 The Creality3D Ender-3, a fully Open Source 3D printer perfect for new users on a budget. 项目地址: https://gitcode.com/gh_mirrors/en/Ender-3 Ender-3固件配置是解锁3D打印机…...

CANN 显存优化深度解析:梯度累积、混合精度与显存回收实战
CANN 显存优化深度解析:梯度累积、混合精度与显存回收实战显存不够跑不了大模型?这篇讲清楚昇腾上的显存优化技术,从原理到实践。显存问题诊断流程 OOM 报错 → 检查模型大小 → 分析梯度占用 → 定位瓶颈 → 选择优化方案显存问题是大模型训…...

大模型MoE架构揭秘:为何每次只用2%参数
1. 这不是“参数越多越强”的简单故事:拆解大模型里被悄悄激活的那2% 你可能已经看过不少标题党文章,说“GPT-4有1.8万亿参数”“DeepSeek-R1有6710亿参数”,然后配上一张闪闪发光的数字图,再加一句“人类大脑才860亿神经元&#…...

邮件安全联防预警平台“网哨M01”:全面联防对抗社工钓鱼攻击
数字化时代,电子邮件是办公协同、政企协作的重要通信手段,但也是网络攻击的常见突破口。结合社会工程学(简称“社工”)的钓鱼邮件,以隐蔽、迷惑性强的特点,严重威胁个人财产与企业信息安全,防御…...

【DeepSeek架构演进倒计时】:K8s 1.30+废弃Dockershim后,容器运行时迁移至containerd+Podman的6小时无感切换方案
更多请点击: https://intelliparadigm.com 第一章:DeepSeek微服务架构演进的背景与战略意义 随着DeepSeek大模型训练规模持续扩大、推理服务调用量激增,单体架构在弹性伸缩、故障隔离、团队协作和灰度发布等方面日益暴露出瓶颈。传统单体服务…...

RTB点击率预估中的长尾失衡与价值重标定
1. 项目概述:当广告竞价遇上“长尾陷阱”——为什么实时竞价系统里99%的流量不说话,却决定着100%的效果你有没有遇到过这样的情况:训练了一个看起来AUC高达0.92的点击率预估模型,上线后CTR却比老模型还低0.3个百分点?或…...

生产级机器学习模型服务:从Notebook到Kubernetes的工程实践
1. 项目概述:这不是“跑通模型”,而是让模型在真实世界里活下来“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句行话暗号,老手一眼就懂:前面三篇已经蹚过了数据清洗、特征工程、…...

Java应用CPU飙升到900%?这套排查套路让你10分钟定位根因
在这篇文章中,我将结合最近一次真实的生产事故,分享一套经过实战检验的CPU排查方法论。这不是教科书上那些”用jstack查看线程栈”的泛泛之谈,而是我们在72小时连续作战中总结出来的血泪经验。 一、告警响应该做什么?别急着重启&…...