CLIP 源码分析:simple_tokenizer.py
tokenizer的含义

from .clip import *引入头文件时为什么有个.

正文
import gzip
import html
import os
from functools import lru_cacheimport ftfy
import regex as re# 上面的都是头文件
# 这段代码定义了一个函数 default_bpe(),它使用了装饰器 @lru_cache()。
# @lru_cache() 是 Python 中的一个装饰器,用于缓存函数的返回值,以避免重复计算。
# 这样,如果相同的参数再次传递给函数,它会直接返回之前缓存的结果,而不是重新执行函数。
@lru_cache()
# default_bpe() 函数的作用是返回一个文件路径,这个路径是一个位于当前文件所在目录下的文件路径。
# 具体来说,它构造了一个文件路径,指向一个名为 "bpe_simple_vocab_16e6.txt.gz" 的文件。
# 这个文件路径是相对于当前文件所在目录的,因为它使用了 os.path.dirname(__file__) 获取当前文件所在目录的路径,
# 然后通过 os.path.join() 构建了文件的完整路径。
def default_bpe():return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")Python 中的装饰器概念
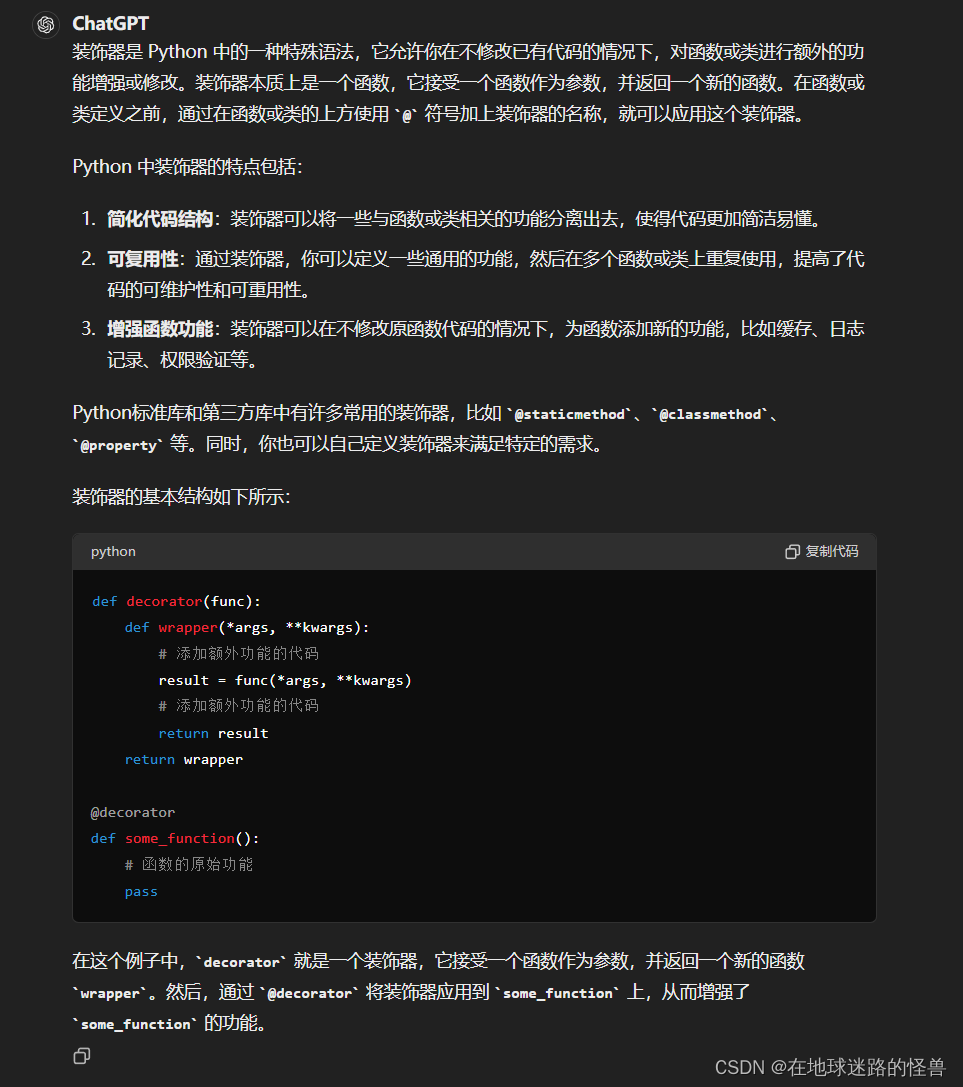
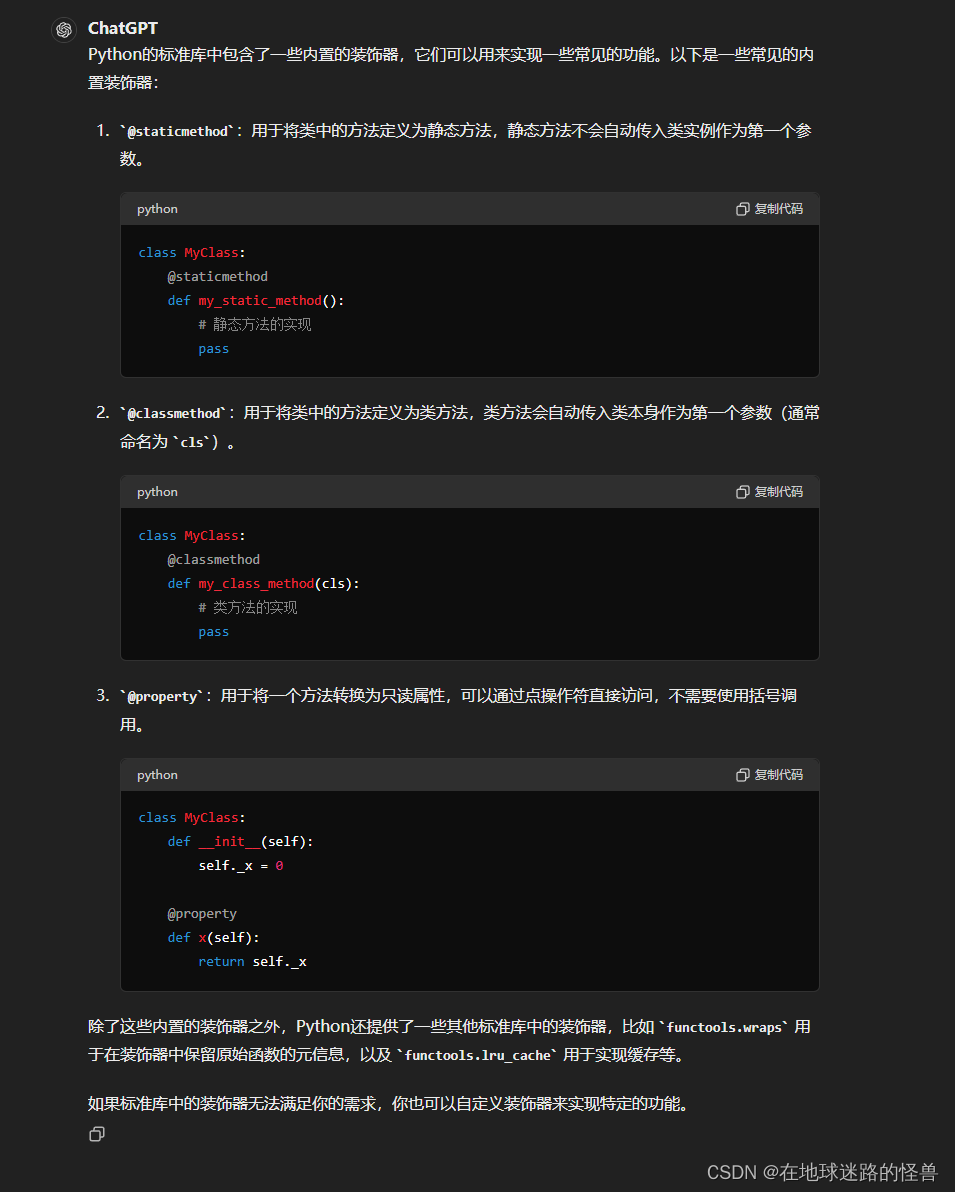
# 这段代码定义了一个函数 bytes_to_unicode(),同样使用了装饰器 @lru_cache() 来缓存函数的返回值
@lru_cache()
# 这个函数的作用是创建一个字典,将 UTF-8 字节映射到对应的 Unicode 字符串。
# 注释中提到,这个字典的目的是为了在 BPE(Byte Pair Encoding)编码中使用。
# BPE 编码需要在词汇表中有大量的 Unicode 字符,以避免未知字符(UNKs)的出现。
def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe codes work on unicode strings.This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.This is a signficant percentage of your normal, say, 32K bpe vocab.To avoid that, we want lookup tables between utf-8 bytes and unicode strings.And avoids mapping to whitespace/control characters the bpe code barfs on."""# 函数内部的操作是创建了两个列表 bs 和 cs,分别存储了一组 UTF-8 字节和对应的 Unicode 字符串。# 然后通过循环将所有可能的 8 位字节加入到这两个列表中,确保覆盖了所有可能的情况。# 最后,使用 zip() 函数将这两个列表合并成一个字典,键为 UTF-8 字节,值为对应的 Unicode 字符串。bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))cs = bs[:]n = 0for b in range(2**8):if b not in bs:bs.append(b)cs.append(2**8+n)n += 1cs = [chr(n) for n in cs]return dict(zip(bs, cs))
bs = list(range(ord(“!”), ord(“~”)+1))+list(range(ord(“¡”), ord(“¬”)+1))+list(range(ord(“®”), ord(“ÿ”)+1))

# 这个函数的作用是提取给定单词中所有相邻字符对的集合,用于后续的处理,比如在文本处理中进行基于字符的分词或编码
def get_pairs(word):"""Return set of symbol pairs in a word.Word is represented as tuple of symbols (symbols being variable-length strings)."""# 创建一个空集合 pairs,用于存储字符对。pairs = set()# 初始化变量 prev_char 为输入单词 word 的第一个字符。prev_char = word[0]# 使用 for 循环遍历输入单词 word 中的每个字符,从第二个字符开始(因为第一个字符已经在 prev_char 中)。for char in word[1:]:# 将相邻的字符对 (prev_char, char) 添加到集合 pairs 中。# 这个操作将当前字符 char 与前一个字符 prev_char 组成一个元组,然后将这个元组添加到集合中。pairs.add((prev_char, char))# 更新 prev_char 的值为当前字符 char,以便在下一次循环中使用。prev_char = char# 返回包含所有相邻字符对的集合 pairs。return pairs
# 这个函数用于对文本进行基本的清洗和修复
def basic_clean(text):# 这一行代码使用了第三方库 ftfy 中的 fix_text() 函数,用于修复文本中的各种编码问题和Unicode字符问题。# 这个函数会尝试修复诸如Unicode编码错误、Unicode编码为HTML实体等问题text = ftfy.fix_text(text)# 这一行代码用于解码 HTML 实体,将 HTML 实体转换回原始字符。# 通常,HTML 实体是用来表示特殊字符的编码形式,比如 < 表示 <,> 表示 >。# 由于可能存在多级嵌套的 HTML 实体,因此使用了两次 html.unescape() 函数来确保解码所有的实体。text = html.unescape(html.unescape(text))# 最后,这一行代码返回经过清洗和修复后的文本,# 并使用 strip() 方法去除文本两端的空白字符,确保文本的整洁性return text.strip()# 这个函数用于去除文本中的多余空白字符
def whitespace_clean(text):
# 这一行代码使用了 Python 内置的 re 模块,调用了 re.sub() 函数来进行正则表达式替换。
# 具体地,它使用了正则表达式 \s+ 来匹配一个或多个连续的空白字符(包括空格、制表符、换行符等),
# 然后将它们替换为单个空格 ' '。这样可以将连续的空白字符合并成一个空格,从而去除多余的空白。text = re.sub(r'\s+', ' ', text)# 这一行代码使用了字符串的 strip() 方法,去除了文本两端的空白字符,确保文本的整洁性text = text.strip()# 返回经过清洗后的文本return text
# 这段代码定义了一个名为 SimpleTokenizer 的类,它实现了一个简单的分词器,用于将文本分割成词语的序列
# 更具体的,这个类实现了一个基于字节对编码的简单分词器,用于将文本转换为词语序列,并提供了编码和解码的方法来处理文本数据
class SimpleTokenizer(object):
# 类的初始化方法。接受一个参数 bpe_path,默认值为 default_bpe() 函数的返回值(也就上面定义的函数),
# 这个函数用于获取默认的 BPE(字节对编码)路径。
# 在初始化过程中,加载了 BPE 模型文件(这个文件也在文件目录中捏),并设置了一些其他的属性和变量。def __init__(self, bpe_path: str = default_bpe()):self.byte_encoder = bytes_to_unicode()self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')merges = merges[1:49152-256-2+1]merges = [tuple(merge.split()) for merge in merges]vocab = list(bytes_to_unicode().values())vocab = vocab + [v+'</w>' for v in vocab]for merge in merges:vocab.append(''.join(merge))vocab.extend(['<|startoftext|>', '<|endoftext|>'])self.encoder = dict(zip(vocab, range(len(vocab))))self.decoder = {v: k for k, v in self.encoder.items()}self.bpe_ranks = dict(zip(merges, range(len(merges))))self.cache = {'<|startoftext|>': '<|startoftext|>', '<|endoftext|>': '<|endoftext|>'}self.pat = re.compile(r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)# 这个方法用于执行 BPE 编码。它接受一个字符串 token 作为输入,返回经过 BPE 编码后的字符串。def bpe(self, token):if token in self.cache:return self.cache[token]word = tuple(token[:-1]) + ( token[-1] + '</w>',)pairs = get_pairs(word)if not pairs:return token+'</w>'while True:bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))if bigram not in self.bpe_ranks:breakfirst, second = bigramnew_word = []i = 0while i < len(word):try:j = word.index(first, i)new_word.extend(word[i:j])i = jexcept:new_word.extend(word[i:])breakif word[i] == first and i < len(word)-1 and word[i+1] == second:new_word.append(first+second)i += 2else:new_word.append(word[i])i += 1new_word = tuple(new_word)word = new_wordif len(word) == 1:breakelse:pairs = get_pairs(word)word = ' '.join(word)self.cache[token] = wordreturn word# 这个方法用于对文本进行编码,将文本转换为 BPE 词汇的索引序列def encode(self, text):bpe_tokens = []text = whitespace_clean(basic_clean(text)).lower()for token in re.findall(self.pat, text):token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))return bpe_tokens# 这个方法用于对索引序列进行解码,将 BPE 编码后的索引序列转换回文本。def decode(self, tokens):text = ''.join([self.decoder[token] for token in tokens])text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('</w>', ' ')# 最后返回经过编解码处理的文本数据return text总结
不难发现,simple_tokenizer.py 这个文件模块就是用来处理我们输入的文本数据的,主要是一些编码上的处理、文本数据的清洗以及文本格式的转换。在最后我们会手动 debug 走一遍流程,看看该项目的各个部分到底是怎么做的都负责了什么。
相关文章:
CLIP 源码分析:simple_tokenizer.py
tokenizer的含义 from .clip import *引入头文件时为什么有个. 正文 import gzip import html import os from functools import lru_cacheimport ftfy import regex as re# 上面的都是头文件# 这段代码定义了一个函数 default_bpe(),它使用了装饰器 lru_cache()。…...

AWS安全性身份和合规性之Shield
shield:盾(牌);(保护机器和操作者的)护罩,防护屏,挡板;屏障;保护物;(警察的)盾形徽章;保护人;掩护物;盾形纹徽;盾形奖牌; AWS Shield是一项AWS托管的DDoS(Distributed Denial of Service,分布式…...

Midjourney入门篇 | 打造最逼真的照片(强烈推荐)
强烈推荐:如何用Midjourney打造最逼真的照片(提示词汇总) 前言1、逼真照片生成公式2、提示词速查表 总结 前言 今天分享一个系统的入门级Midjourney制图教程:涵盖了最基础的绘画概念及提示词,精选了一些重要的提示词&…...
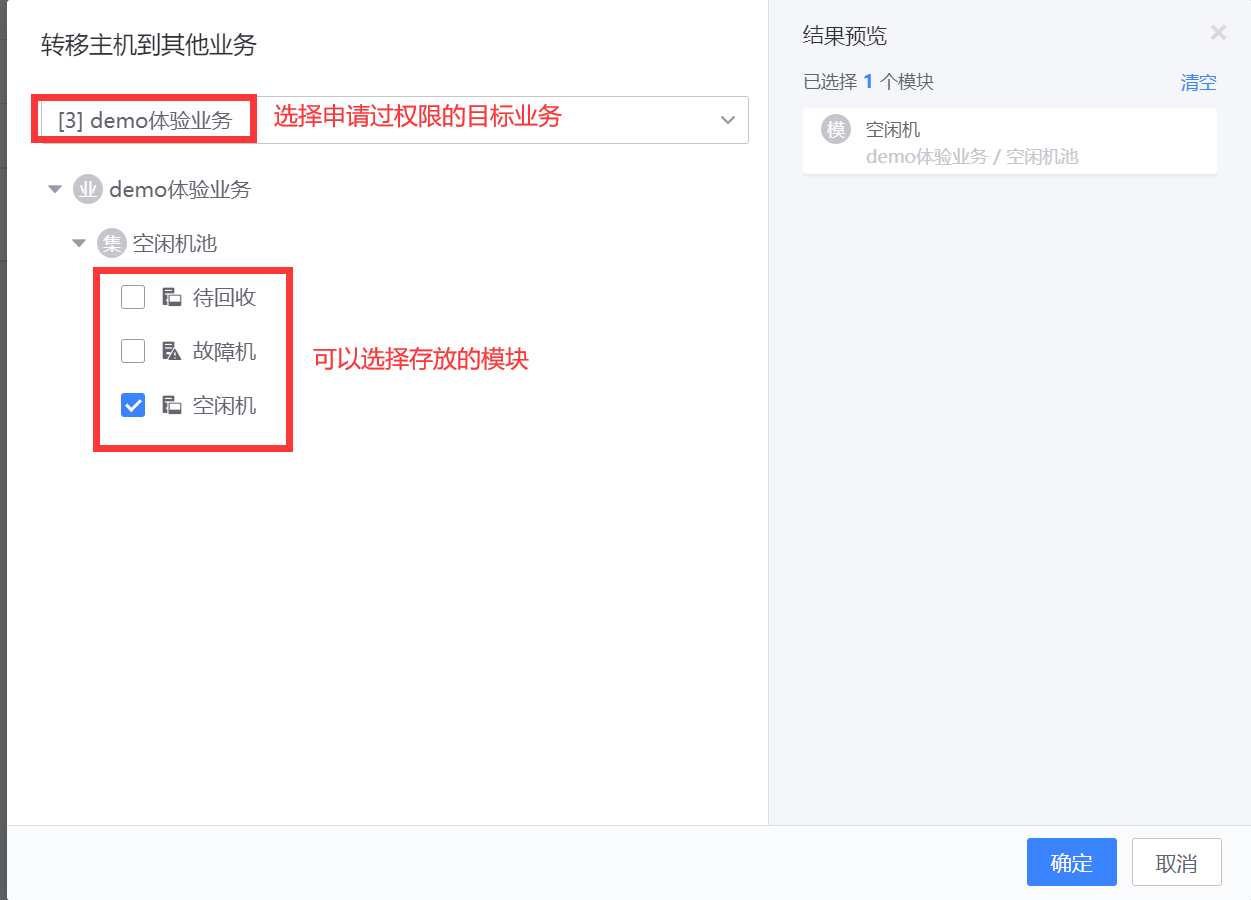
【运维自动化-配置平台】如何跨业务转移主机
在如何创建业务拓扑中,了解到业务是蓝鲸体系重要的资源管理纬度,主机在业务之前需要流转怎么做呢?比如要把A业务一台主机划给B业务使用权限中心 跨业务转移主机一般场景是由源主机所在业务的负责人发起,需要申请目标业务的相关权…...
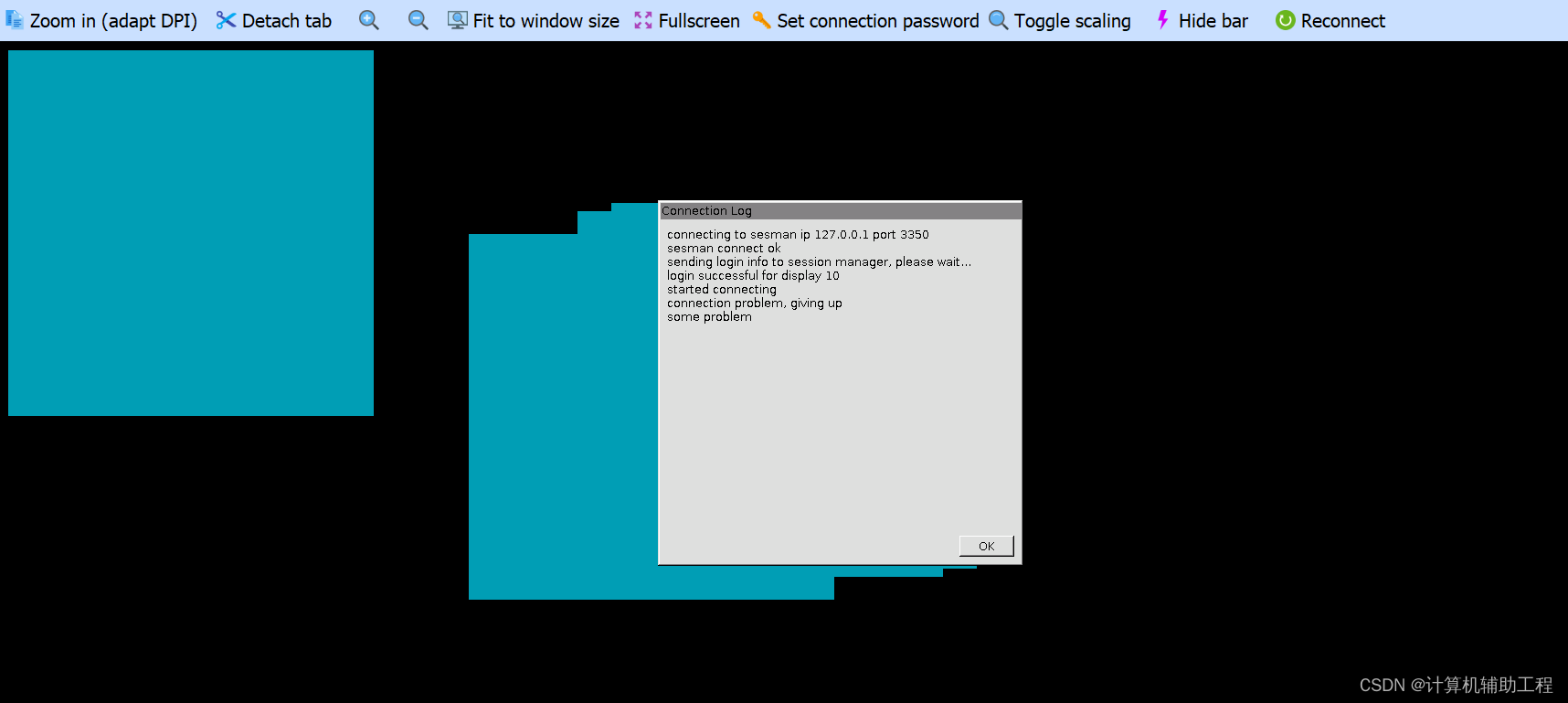
connection problem,giving up
参考: https://zhuanlan.zhihu.com/p/93438433 仅仅安装 sudo apt-get install xrdp 在用RDP远程的时候总是卡在登录界面,connection problem,giving up, some problem… 第一步: sudo apt-get install xserver-xorg-core sudo…...
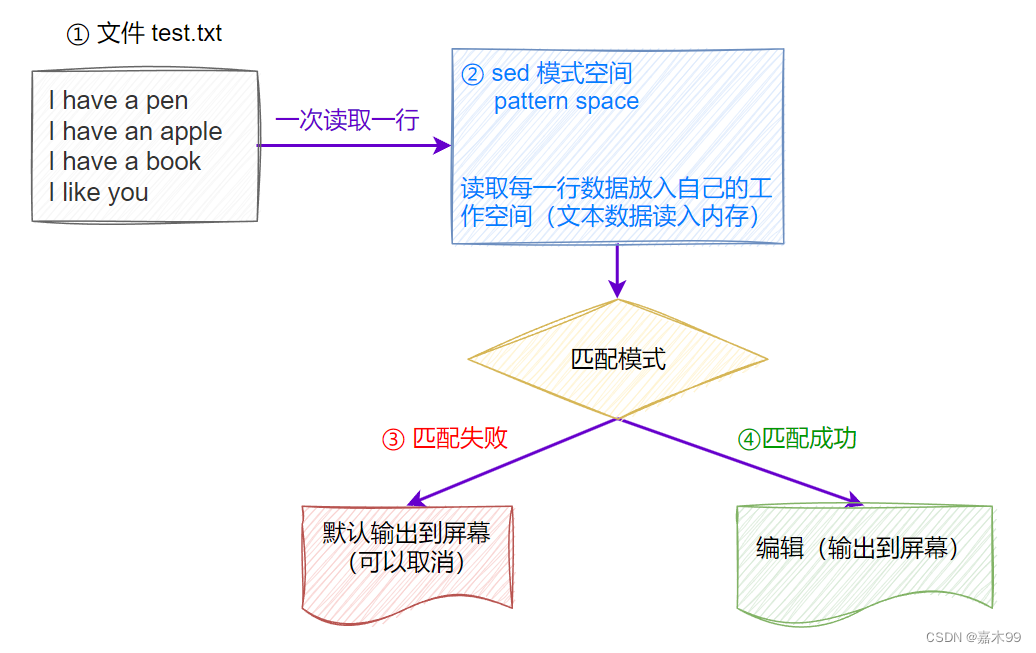
Linux-----sed案例练习
1.数据准备 准备数据如下: [rootopenEuler ~]# cat openlab.txt My name is jock. I teach linux. I like play computer game. My qq is 24523452 My website is http://www.xianoupeng.com My website is http://www.xianoupeng.com My website is http://www.…...
)
【华为OD机试-C卷D卷-200分】运输时间(C++/Java/Python)
【华为OD机试】-(A卷+B卷+C卷+D卷)-2024真题合集目录 【华为OD机试】-(C卷+D卷)-2024最新真题目录 题目描述 M(1 ≤ M ≤ 20)辆车需要在一条不能超车的单行道到达终点,起点到终点的距离为 N(1 ≤ N ≤ 400)。速度快的车追上前车后,只能以前车的速度继续行驶,求最后一…...
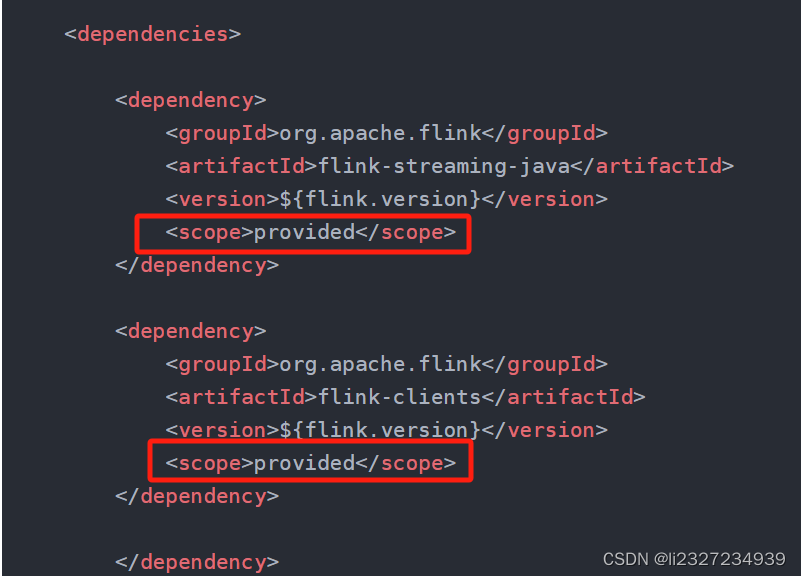
flink程序本地运行报: A JNI error has occurred和java.lang.NoClassDefFoundError
1.问题描述 在idea中运行flink job程序出现如下错误: Error: A JNI error has occurred, please check your installation and try again Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/io/FileInputFormat …...
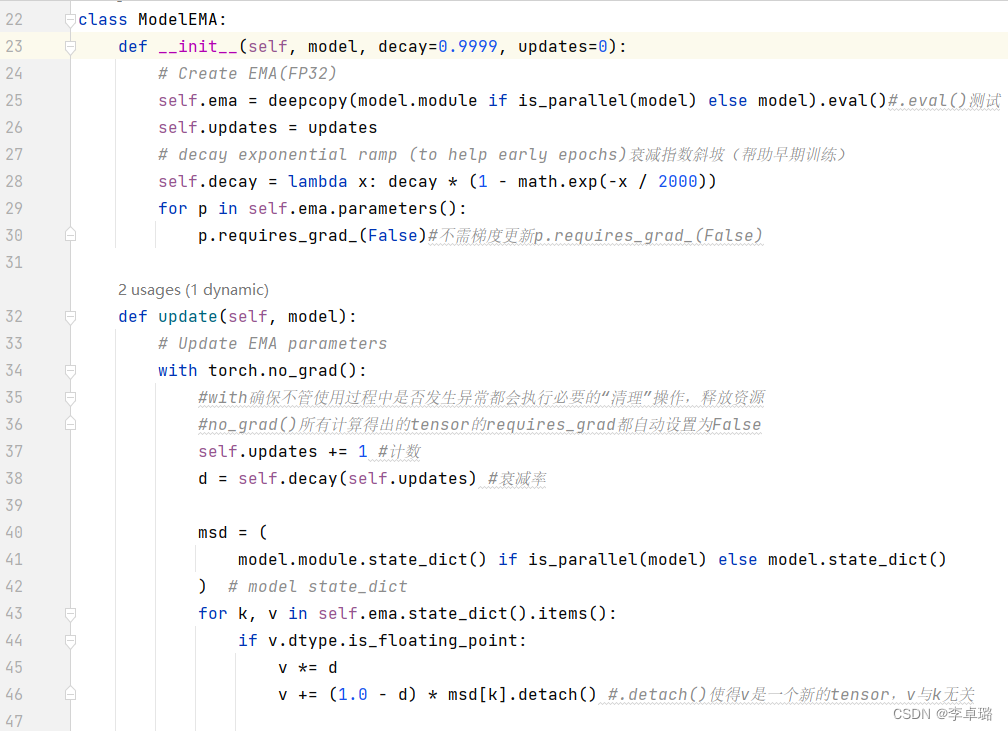
yolox-何为EMA?
何为EMA? 定义: 滑动平均/指数加权平均:用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关,滑动平均可以看作是变量的过去一段时间取值的均值。 优点: 相比于直接赋值,滑动平均…...

Java:String、StringBuffer和StringBuilder的区别
参考: https://blog.csdn.net/kingzone_2008/article/details/9220691 https://blog.csdn.net/itchuxuezhe_yang/article/details/89966303 String 常量字符串,每次修改都是会新创建一个字符串,当要频繁修改字符串的时候不建议使用 String S…...
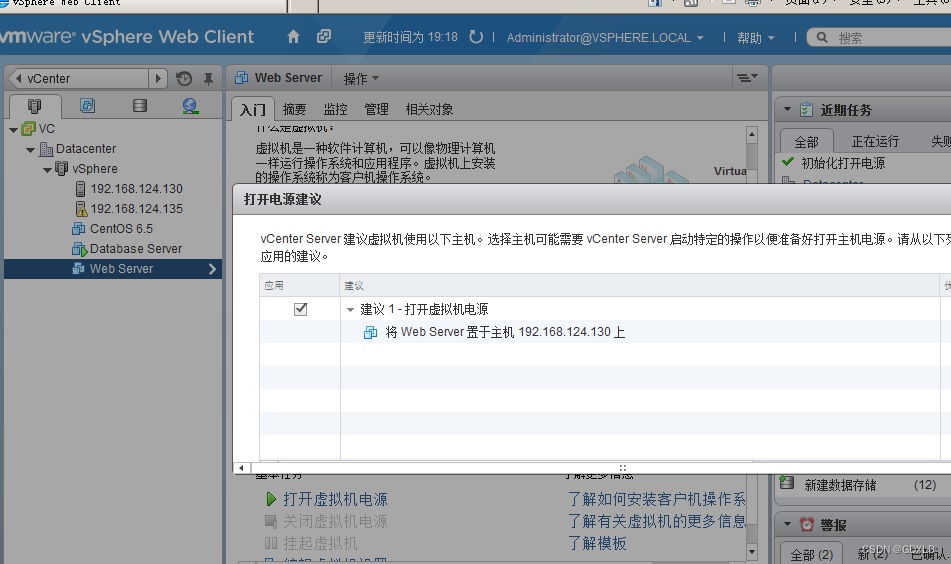
虚拟化技术 分布式资源调度
一、实验内容 实现分布式资源调度 二、实验主要仪器设备及材料 安装有64位Windows操作系统的台式电脑或笔记本电脑,建议4C8G或以上配置已安装VMware Workstation Pro已安装Windows Server 2008 R2 x64已安装vCenter Server 三、实验步骤 将主机esxi1和esxi2加入…...
)
【Element-plus】vue组合式中使用el-upload通过oss接口上传图片流程(可直接复制使用)
Html <el-upload:actionossUrl:on-success"handleImgSuccess":headers"{Authorization:token}"><el-icon><Plus /></el-icon>点击上传图片</el-upload> JS const ossUrl ref("") ossUrl.value 【你的ossUrl】…...

C++ 数据结构算法 学习笔记(33) -查找算法及企业级应用
C 数据结构算法 学习笔记(33) -查找算法及企业级应用 数组和索引 日常生活中,我们经常会在电话号码簿中查阅“某人”的电话号码,按姓查询或者按字母排 序查询;在字典中查阅“某个词”的读音和含义等等。在这里,“电话号码簿”和…...
【Linux】在Ubuntu 16.04上安装Gerrit + PostgreSQL + Apache服务
Gerrit是一个基于Git版本控制系统的运行于Web浏览器上的Code Review工具,本文叙述如何在Ubuntu 16.04上安装Gerrit服务。(当然安装Gerrit的方法有很多,本文只是其中之一) 文章目录 前提安装PostgreSQL数据库并创建用户下载、配置和…...

数据倾斜那些事儿
目录 一、什么是数据倾斜? 二、预判与预防 三、躲闪策略 四、硬刚策略 一、什么是数据倾斜? 之前在大厂当了好几年的sqlboy,数据倾斜这个“小烦人精”确实经常在工作中出没。用简单的话来说,数据倾斜就像是“贫富差距”在数据…...

python考试成绩管理与分析:从列表到方差
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、考试成绩的输入与列表管理 二、成绩的总分与平均成绩计算 三、成绩方差的计算 四、成…...

Excel某列中有不连续的数据,怎么提取数据到新的列?
这里演示使用高级筛选的例子: 1.设置筛选条件 在D2单元格输入公式:COUNTA(A4)>0 这里有两个注意事项: *. 公式是设置在D2单元格,D1单元格保持为空, **. 为什么公式中选A4单元格,A列的第一个数据在A3…...
翻译《The Old New Thing》- What does it mean when a display change is temporary?
What does it mean when a display change is temporary? - The Old New Thing (microsoft.com)https://devblogs.microsoft.com/oldnewthing/20080104-00/?p23923 Raymond Chen 2008年01月04日 什么叫临时性的显示设置变更? 当您调用ChangeDisplaySettings函数时…...

【C语言】char,short char,long char分别是多少字节,多少位,多少bit
一,char,short char,long char分别是多少字节 在 C 语言中,char、short、int、long 这些数据类型的大小是平台相关的,它们的大小取决于编译器和操作系统的实现。然而,它们的大小通常遵循以下规则ÿ…...

新V 系首批订单交付!苏州金龙助新疆游骏文旅集团打造旅运新标杆
热播剧集《我的阿勒泰》收官不久,6月新疆旅游旺季将至。 2024年5月下旬,苏州金龙海格客车新V系首批30辆正式交付新疆客户! 作为苏州金龙海格客车新V系首批用户,新疆游骏文旅集团董事长王红强表示:“海格新V系从外观、…...

BotW Save Manager:技术解析与实战指南,实现Switch与WiiU存档的无缝迁移
BotW Save Manager:技术解析与实战指南,实现Switch与WiiU存档的无缝迁移 【免费下载链接】BotW-Save-Manager BOTW Save Manager for Switch and Wii U 项目地址: https://gitcode.com/gh_mirrors/bo/BotW-Save-Manager BotW Save Manager是一款专…...

显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理?
显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理? 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirr…...

视频字幕提取难题?这个本地OCR工具让你轻松搞定SRT字幕
视频字幕提取难题?这个本地OCR工具让你轻松搞定SRT字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字幕内…...

Bilibili-Evolved界面美化终极指南:打造个性化B站浏览体验
Bilibili-Evolved界面美化终极指南:打造个性化B站浏览体验 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 你是否厌倦了B站千篇一律的默认界面?想要让Bilibili变得更加…...

书匠策AI:你的毕业论文“外挂“已上线,这功能也太懂大学生了吧!
哈喽各位同学们,我是你们的论文写作科普博主。今天不讲什么"论文写作十大技巧"那种老掉牙的东西,今天要给大家安利一个我最近发现的宝藏工具——书匠策AI, 官网直达:www.shujiangce.com,微信公众号搜"书…...

Three.js实战:3D数据可视化入门与实践
Three.js实战:3D数据可视化入门与实践 前言 大家好,我是前端老炮儿。今天咱们来聊聊Three.js! 在数据可视化领域,3D可视化正变得越来越重要。Three.js作为一个强大的3D库,可以帮助我们轻松创建各种3D效果。 今天我就带…...

DLSS Swapper完整指南:3分钟掌握游戏性能优化终极技巧
DLSS Swapper完整指南:3分钟掌握游戏性能优化终极技巧 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的开源工具,专门为PC游戏玩家设计,让你能够轻松管理、…...
FlashAttention 在昇腾NPU上到底快在哪?一次拆透 ops-transformer 的核心算子
这是一篇关于昇腾NPU上FlashAttention技术深度解析的CSDN博客文章。文章结合了您提供的网页信息(特别是ops-transformer仓库的上下文)以及深度学习算子优化的专业知识,旨在帮助开发者理解其原理、优势及在昇腾生态中的应用。 FlashAttention …...

索尼IMX811如何重塑工业视觉与专业影像的边界
突破像素极限,定义成像新高度在影像技术飞速发展的今天,高分辨率始终是专业领域不懈追求的目标。索尼半导体解决方案公司重磅推出的IMX811中画幅CMOS图像传感器,以2.47亿有效像素的惊人规格,为行业带来了颠覆性的突破。这款传感器…...

数据结构——带懒标记的线段树
一、什么是线段树?线段树是一种二叉树数据结构,用于高效地处理区间查询和区间更新操作。核心思想:将数组分成若干个区间(线段),每个节点代表一个区间,通过合并子节点的信息来得到父节点的信息。…...