机器学习:在Python中sklearn库的使用,纯干货!12个小时的整理!
无监督学习是在没有标签的数据上训练的。其主要目的可能包括聚类、降维、生成模型等。
以下是 6 个重要的无监督学习算法,这些算法都可以通过使用sklearn(Scikit-learn)库在Python中很好地处理:
目录
K-Means 聚类
层次聚类
DBSCAN
主成分分析
独立成分分析
高斯混合模型
K-Means 聚类
数据准备
首先,我们导入必要的库和数据,并进行基本的数据探查。
这里,准备了名称为「customer_data.csv」的数据集,维度分别为``Age, Annual_Income 和Spending_Score`作为 3 个特征。
获取数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from time import time# 假定你已将上文的数据存储为'customer_data.csv'
data = pd.read_csv("customer_data.csv")
数据标准化
因为K-Means聚类是距离基础的算法,我们通常在进行聚类分析之前会标准化我们的数据。
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
确定K值
这里我们使用轮廓系数(Silhouette Score)来帮助我们确定适当的K值。
轮廓系数是在-1到1之间的,一个高的轮廓系数表明样本点离其他类的距离较远。
k_values = range(2, 11)
silhouette_scores = []for k in k_values:kmeans = KMeans(n_clusters=k, random_state=42)kmeans.fit(scaled_data)silhouette_scores.append(silhouette_score(scaled_data, kmeans.labels_))plt.plot(k_values, silhouette_scores, marker='o')
plt.title('Silhouette Score for Different k')
plt.xlabel('k')
plt.ylabel('Silhouette Score')
plt.show()
模型训练
从轮廓系数图中选择一个合适的 K 值进行模型训练,并可视化结果。
# 假设我们选择k=3
k = 3
kmeans = KMeans(n_clusters=k, random_state=42)
clusters = kmeans.fit_predict(scaled_data)# 可视化结果
plt.scatter(scaled_data[clusters == 0, 0], scaled_data[clusters == 0, 1], label='Cluster 1')
plt.scatter(scaled_data[clusters == 1, 0], scaled_data[clusters == 1, 1], label='Cluster 2')
plt.scatter(scaled_data[clusters == 2, 0], scaled_data[clusters == 2, 1], label='Cluster 3')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', label='Centroids')
plt.title('Clusters of Customers')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.legend()
plt.show()
这三个群集可能分别代表以下客户类型:
-
Cluster 1: 年轻且花费适中的客户群体
-
Cluster 2: 年轻且花费较高的客户群体
-
Cluster 3: 年纪较大且花费较低的客户群体
商业决策将基于这些群体的特点来制定。例如,针对花费较高的年轻客户群体,可以提供最新的产品推广或者特殊折扣,以便进一步激励他们的购买行为。
以上代码及分析基于假定的数据。在现实项目中,要充分理解业务背景、数据的含义并根据业务目标来决定聚类的数量及如何解读各个群体的特征。
层次聚类
为了便于展示,我们使用上文中的customer_data.csv数据。我们将使用层次聚类(Hierarchical Clustering)探索数据内在的群集结构。
咱们关注的特征依然是Age, Annual_Income, 和Spending_Score。
数据准备
如之前例子一样,首先进行数据导入和标准化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering# 读取数据
data = pd.read_csv("customer_data.csv")# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
层次聚类模型
构建并可视化树状图 (Dendrogram)
我们用scipy中的linkage和dendrogram函数来构建层次聚类的树状图。
linked = linkage(scaled_data, 'ward') # 使用Ward连接方法plt.figure(figsize=(10, 7))
dendrogram(linked,orientation='top',labels=data.index,distance_sort='descending',show_leaf_counts=True)
plt.show()
训练模型并可视化结果
选择一个合适的距离阈值或群集数量进行模型训练,并可视化结果。
# 定义模型并指定我们想要的群集数量
cluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward') # 训练模型并预测标签
cluster_labels = cluster.fit_predict(scaled_data)# 可视化结果
plt.figure(figsize=(10, 7))
plt.scatter(scaled_data[:,0], scaled_data[:,1], c=cluster_labels, cmap='rainbow')
plt.title('Clusters of Customers')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.show()
与K-Means聚类类似,我们可以根据生成的群集进行进一步分析。例如,每个群集的中心的特征可以被认为是该群集的“代表”特征。由于我们使用了相同的特征(Age和Spending_Score),群集的解释将与前文类似。
注意点
1、距离计算:affinity参数表示用于计算距离的方法。在本例中,我们使用了欧几里得距离。
2、链接方法:linkage参数表示用于链接群集的方法。在本例中,我们使用了Ward方法,该方法试图最小化群集内的方差。
3、选择群集数量:在生成的树状图中,通常选择一个“高度”来切割树形结构,并形成各个群集。在这个示例中,我们预先选择了群集的数量。在实际分析中,你也可以选择在树状图中一个合适的高度来切割群集。
DBSCAN
咱们继续使用customer_data.csv数据集来演示DBSCAN。
数据准备
DBSCAN模型构建与训练
首先选定DBSCAN的两个主要参数:邻域大小(eps)和最小点数(min_samples)。
# 实例化DBSCAN模型
dbscan = DBSCAN(eps=0.5, min_samples=5)# 训练模型
clusters = dbscan.fit_predict(scaled_data)# 计算轮廓系数
print(f'Silhouette Score: {silhouette_score(scaled_data, clusters):.2f}')
结果可视化
我们用散点图展示聚类的结果。
# 可视化
plt.scatter(scaled_data[:,0], scaled_data[:,1], c=clusters, cmap='plasma')
plt.title('DBSCAN Clustering')
plt.xlabel('Age (scaled)')
plt.ylabel('Spending Score (scaled)')
plt.show()
-
轮廓系数:展示了群集的密度和分离度。范围从-1到1,值越高表明聚类效果越好。由于DBSCAN能够识别噪声,轮廓系数可能会受到噪声点的影响。
-
图形分析:可视化结果允许我们直观地看到不同的群集及其形状。DBSCAN能够找到非球形的群集,这是其独有的优点。
注意点
-
参数选择:
eps和min_samples的选择对模型影响很大。一个常见的方法是使用k-距离图来估计eps。通常需要多次尝试来找到合适的参数。 -
标准化的重要性:由于DBSCAN依赖于距离的计算,所以标准化通常是必需的。
-
处理不均衡数据:DBSCAN可能在不同密度的群集之间表现不佳。在数据的分布非常不均匀时,可能需要调整参数或选择其他算法。
-
噪声点:DBSCAN将不属于任何群集的点归类为噪声(即,将其标签为-1)。在结果解释和进一步分析时需要注意这一点。
DBSCAN提供了一种不需要预先指定群集数量的聚类方法,并且可以找到复杂形状的群集。然而,它对参数的选择非常敏感,需要仔细进行调整和验证。
主成分分析
主成分分析(PCA)是一种在降维和可视化高维数据方面非常流行的技术。通过找到数据的主轴并将数据投影到这些轴上来减少数据的维度,从而尽可能保留数据的方差。
数据准备
假设我们有一个包含3个特征的 150x3 的数据集。我们的目标是将这些数据从3D空间降维到2D空间以便进行可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler# 使用iris数据集
iris = load_iris()
X = iris.data # 特征矩阵, shape: (150, 4)
y = iris.target # 目标变量, shape: (150,)# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
模型训练
# 实施PCA
pca = PCA(n_components=2) # 我们将数据投影到前两个主成分
X_pca = pca.fit_transform(X_scaled)
数据可视化
# 创建一个新的figure
plt.figure(figsize=(8,6))# 遍历标签,为不同的标签创建不同的散点图
for target, color in zip(iris.target_names, ['r', 'g', 'b']):indicesToKeep = iris.target == np.where(iris.target_names == target)[0][0]plt.scatter(X_pca[indicesToKeep, 0], X_pca[indicesToKeep, 1], c = color, s = 50)# 增加图例和坐标轴的标签
plt.legend(iris.target_names, loc='upper right', fontsize='x-large')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('2D PCA of Iris Dataset')
plt.grid(True)# 显示图形
plt.show()
解释方差
explained_variance = pca.explained_variance_ratio_
print(f"Explained variance: {explained_variance}")
从上面的2D散点图中,你可以看到3种不同的鸢尾花在投影到前两个主成分上时是如何分开的。另外,解释的方差告诉我们前两个主成分保存了多少原始数据的方差。在许多情况下,希望这些主成分包含了足够多的信息,以便在丢失最小量的信息的情况下利用它们。
这个简单的示例展示了PCA的工作方式和它如何在实践中实施。
独立成分分析
独立成分分析是一种用于从混合信号中恢复原始信号的技术,通常用于盲源分离和信号处理。
数据准备
首先,我们需要准备一个包含混合信号的虚拟数据集。
以下示例中,创建两个独立的信号并将它们线性混合。
import numpy as np# 创建两个独立的信号
signal_1 = np.random.rand(1000)
signal_2 = np.sin(np.linspace(0, 100, 1000))# 创建混合信号
mixing_matrix = np.array([[2, 1], [1, 2]]) # 混合矩阵
mixed_signals = np.dot(np.vstack((signal_1, signal_2)).T, mixing_matrix.T)
ICA模型训练
使用Scikit-Learn中的FastICA来拟合ICA模型,以恢复原始信号。
from sklearn.decomposition import FastICAica = FastICA(n_components=2)
recovered_signals = ica.fit_transform(mixed_signals)
绘制混合信号和恢复信号的图形
我绘制混合信号和恢复信号的图形,以可视化ICA的效果。
import matplotlib.pyplot as plt# 绘制混合信号
plt.figure(figsize=(12, 6))
plt.subplot(2, 2, 1)
plt.plot(signal_1, label='Signal 1')
plt.title('Original Signal 1')
plt.subplot(2, 2, 2)
plt.plot(signal_2, label='Signal 2')
plt.title('Original Signal 2')# 绘制混合信号
plt.subplot(2, 2, 3)
plt.plot(mixed_signals[:, 0], label='Mixed Signal 1')
plt.title('Mixed Signal 1')
plt.subplot(2, 2, 4)
plt.plot(mixed_signals[:, 1], label='Mixed Signal 2')
plt.title('Mixed Signal 2')plt.tight_layout()# 绘制恢复信号
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(recovered_signals[:, 0], label='Recovered Signal 1')
plt.title('Recovered Signal 1')
plt.subplot(2, 1, 2)
plt.plot(recovered_signals[:, 1], label='Recovered Signal 2')
plt.title('Recovered Signal 2')plt.tight_layout()
plt.show()
在图形中,可以看到原始信号、混合信号以及通过ICA恢复的信号。恢复信号应该与原始信号尽可能接近,这就是ICA的目标。通过独立成分分析,我们可以从混合信号中分离出原始信号,实现了信号的盲源分离。
示例演示了独立成分分析的用途,如何准备数据,训练模型以及通过图形可视化来理解分离效果。在实际应用中,你可以使用不同数量的混合信号和独立成分来执行ICA,以满足具体的应用需求。
高斯混合模型
高斯混合模型是一种用于建模多个高斯分布混合在一起的概率模型。
下面是一个关于高斯混合模型的完整示例,包括数据准备、模型训练、Python代码和图形展示等等。
数据准备
首先,我们需要准备一个包含多个高斯分布的虚拟数据集。
例子中,创建一个包含两个高斯分布的数据集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture# 创建两个高斯分布的虚拟数据集
np.random.seed(0)
data1 = np.random.normal(0, 1, 200)
data2 = np.random.normal(5, 1, 200)
data = np.concatenate((data1, data2), axis=0)# 绘制数据分布
plt.hist(data, bins=30, density=True, alpha=0.5)
plt.title('Data Distribution')
plt.xlabel('Value')
plt.ylabel('Density')
plt.show()
GMM模型训练
接下来,我们将使用Scikit-Learn中的GaussianMixture来拟合GMM模型,以对数据进行建模。
# 使用GMM拟合数据
gmm = GaussianMixture(n_components=2, random_state=0)
gmm.fit(data.reshape(-1, 1))
绘制GMM模型的图形
我们可以绘制GMM模型对数据的拟合情况,以及估计的高斯分布参数。
# 绘制数据分布
plt.hist(data, bins=30, density=True, alpha=0.5, label='Data')# 绘制GMM模型的拟合曲线
x = np.linspace(-3, 8, 1000)
pdf = np.exp(gmm.score_samples(x.reshape(-1, 1)))
plt.plot(x, pdf, '-r', label='GMM')# 绘制每个高斯分布的拟合曲线
for i in range(2):mean = gmm.means_[i][0]variance = np.sqrt(gmm.covariances_[i][0][0])weight = gmm.weights_[i]plt.plot(x, weight * np.exp(-(x - mean)**2 / (2 * variance**2)) / (np.sqrt(2 * np.pi) * variance),label=f'Component {i+1}')plt.title('Gaussian Mixture Model Fit')
plt.xlabel('Value')
plt.ylabel('Density')
plt.legend()
plt.show()
在图中,你可以看到原始数据的分布(直方图),以及GMM模型的拟合曲线。GMM模型通过多个高斯分布的线性组合来拟合数据分布,图中还显示了每个高斯分布的拟合曲线,包括均值、方差和权重。
这个示例演示了如何使用高斯混合模型来对数据进行建模和拟合,以及如何通过图形可视化来理解模型的效果。在实际应用中,你可以根据数据的特性和需求选择不同数量的高斯分布成分来建立更复杂的模型。
最后
今天演示了关于scikit-learn在无监督学习方面的使用。后续会出scikit-learn在其他方面的使用,大家可以关注起来!
相关文章:

机器学习:在Python中sklearn库的使用,纯干货!12个小时的整理!
无监督学习是在没有标签的数据上训练的。其主要目的可能包括聚类、降维、生成模型等。 以下是 6 个重要的无监督学习算法,这些算法都可以通过使用sklearn(Scikit-learn)库在Python中很好地处理: 目录 K-Means 聚类 层次聚类 …...

XSS 攻击
XSS 攻击简介 定义: XSS(跨站脚本攻击)是一种网络安全漏洞,攻击者通过在 Web 页面中注入恶意代码,利用用户的浏览器执行这些恶意脚本,从而实施攻击。 解决方案: 过滤用户输入: 对…...

.Net Core 中间件与过滤器
过滤器这个是.Net MVC旧有的功能,中间件这个概念是新出的, ASP.NET Core只是完成了HTTP请求调度、报文解析等必要的工作,像检查用户身份、设置缓存报文头等操作都是在中间件中完成,中间件就是ASP.NET Core的一个组件,…...
)
【ARMv7-A】——WFI(wait for interrupt)
文章目录 WFI基本原理使用场景多任务模型注意事项代码实例linux 内核中的 WFI 指令不使用 WFI 指令测试使用 WFI 指令测试WFI WFI 即 Wait for interrupt,常用于低功耗。 WFI (Wait for interrupt) 和 WFE (Wait for event) 是两个让 ARM 核进入 low-power standby 模式的指…...

92. 反转链表 II
题目描述 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出&#…...

Modbus工业网关
随着工业自动化程度的不断提高,设备之间的数据通信与交互变得至关重要。在这一背景下,Modbus协议凭借其简单、可靠、开放的特点,成为了工业自动化领域中最常用的通信协议之一。而HiWoo Box网关作为一款支持Modbus协议的工业网关设备ÿ…...

c++——模板初始识
1.函数模板 我们经常用到Swap函数交换两个值。由于需要交换的数据的类型不同,我们就需要写不同参数类型的同名函数,也就是函数重载: 然而这三个函数的逻辑是一样的,写这么多有些多此一举,通过函数模版可以写一个通用…...
帆软生成csv文件
帆软官网提供了导出csv文件的插件,需要下载指定版本的插件 请选择具体的详情点击官网介绍:文档介绍 插件地址:插件地址...

12.Redis之补充类型渐进式遍历
1.stream 官方文档的意思, 就是 stream 类型就可以用来模拟实现这种事件传播的机制~~stream 就是一个队列(阻塞队列)redis 作为一个消息队列的重要支撑属于是 List blpop/brpop 升级版本.用于做消息队列 2.geospatial 用来存储坐标 (经纬度)存储一些点之后,就可以让用户给定…...

品牌做电商控价的原因
品牌控价确实是一项至关重要的任务,它关乎着品牌形象、市场定位以及长期发展的稳定性。在电商平台上,价格的公开性和透明度使得消费者、经销商和其他渠道参与方都能够轻易地进行价格比较。因此,品牌方必须对电商渠道的价格进行严格的管控&…...

安全面试中的一个基础问题:你如何在数据库中存储密码?
3分钟讲解。 上周的面试故事 职位:初级安全工程师,刚毕业。 开始面试。 我:“这里你提到对数据安全有很好的理解。你能举例说明哪些方面的数据安全吗?” A:“当然。例如,当我们构建一个系统时,会…...
)
【python深度学习】——torch.min()
【python深度学习】——torch.min 1. torch.min()1.1 计算整个张量的最小值1.2 沿特定维度计算最小值1.3 比较两个张量 1. torch.min() torch.min()接受的参数如下: input: 输入的张量。dim: 沿指定维度寻找最小值。如果指定了该参数,返回一个元组,其中…...
)
华为校招机试 - 最久最少使用缓存(20240508)
题目描述 无线通信移动性需要在基站上配置邻区(本端基站的小区 LocalCell 与周边邻基站的小区 NeighborCelI 映射)关系, 为了能够加速无线算法的计算效率,设计一个邻区关系缓存表,用于快速的通过本小区 LocalCell 查询到邻小区 NeighborCell。 但是缓存表有一定的规格限…...

第三部分:领域驱动设计之分析模式和设计模式应用于模型
分析模式 分析模式是一种概念集合,用来表示业务建模中的常见结构。它可能只与一个领域有关,也可能跨越多个领域。“分析模式”这个名字本身就强调了其概念本质。分析模式并不是技术解决方案,他们只是些参考,用来指导人们设计特定领…...

PID传感器在光电显示行业VOC气体检测的应用
随着光电显示技术的飞速发展,液晶显示器等显示器件产品已经成为我们日常生活和工作中不可或缺的一部分。然而,在生产过程中,液晶显示器会释放大量的挥发性有机物(VOC)气体,对生产环境及工作人员的健康构成威…...
iOS推送证书过期处理
苹果推送证书的有效期都是一年,将要过期的时候,苹果官方会发邮件提醒。 一、过期 在电脑上找到并打开其它->钥匙串访问; 我的证书可以看到各个App的推送证书,如果过期了,显示红色X 二、重新创建 1、登陆apple开…...
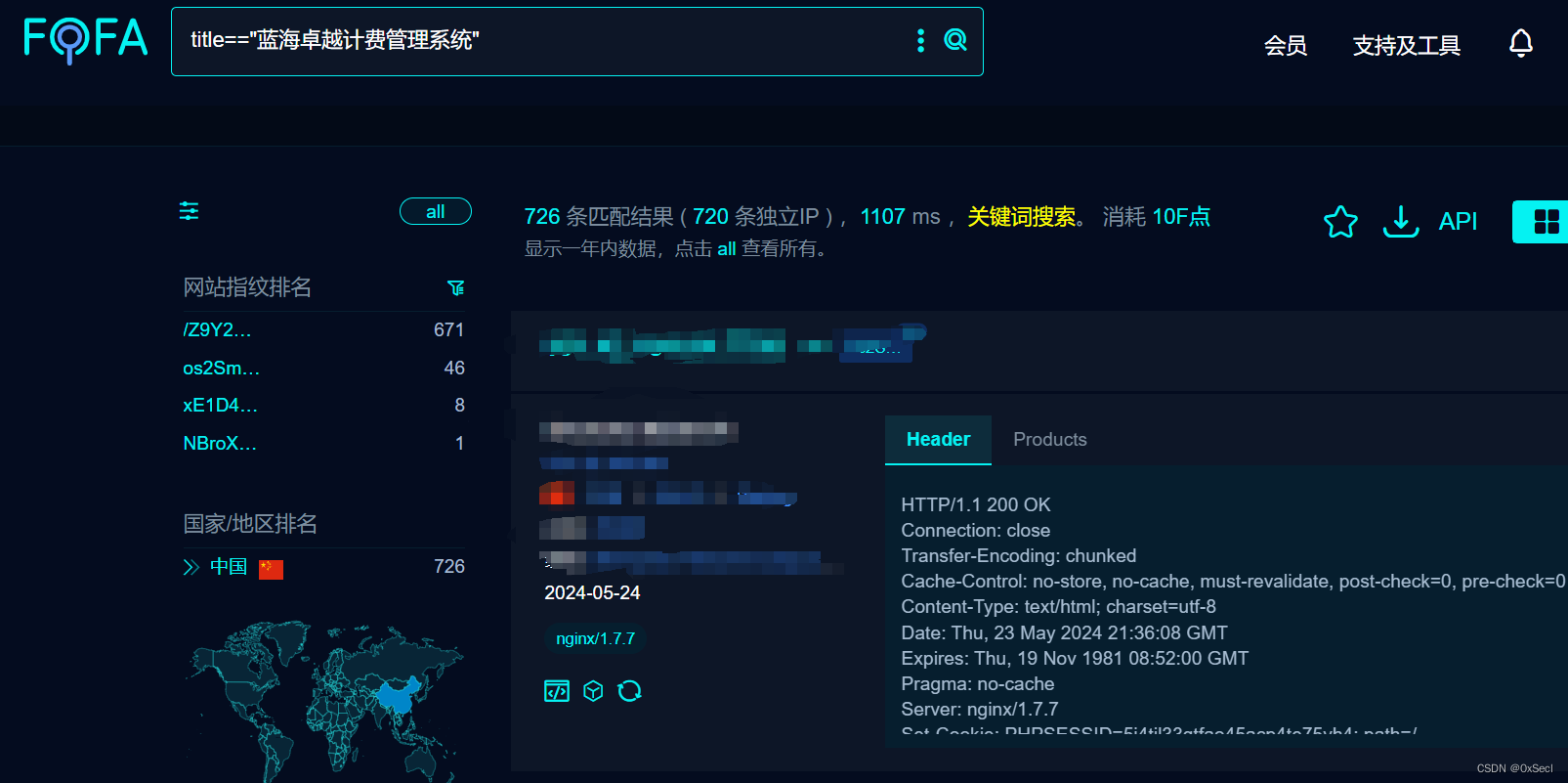
蓝海卓越计费管理系统 agent_setstate.php SQL注入漏洞复现
0x01 产品简介 蓝海卓越计费管理系统是一套以实现网络运营为基础,增强全局安全为中心,提高管理效率为目的的网络安全运营管理系统,提供“高安全、可运营、易管理”的运营管理体验,基于标准的RADIUS协议开发,它不仅支持PPPOE和WEB认证计费,还支持802.1X接入控制技术,与其…...
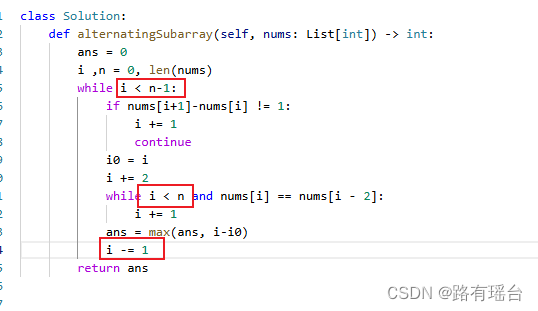
【leetcode2765--最长交替子数组】
要求:给定一个数组,找出符合【x, x1,x,x-1】这样循环的最大交替数组长度。 思路:用两层while循环,第一个while用来找到符合这个循环的开头位置,第二个用来找到该循环的结束位置,并比较一下max进行记录。 …...

java文档管理系统的设计与实现源码(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的文档管理系统的设计与实现。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 文档管理系统的…...

西安航空学院电子工程学院领导莅临泰迪智能科技参观交流
5月26日,西安航空学院电子工程学院院长杨亚萍、专业教师刘坤莅临广东泰迪智能科技股份有限公司产教融合实训基地参观交流。泰迪智能科技董事长张良均、副总经理施兴、产品中心负责周东平、校企合作经理吴桂锋与泰迪智能科技韩伟进行热情了接待。双方就专业建设、协同…...

5.12linux自学
1,安装vMware2,部署Kali Linux虚拟机3,了解Linux的优点:多人多任务环境安全性高4,格式化的概念:每种操作系统所配置的文件属性/权限并不相同,为了存放这些文件所需的数据,因此就需要进行格式化,以成为操作系…...

如何快速从图表图片中提取数据?WebPlotDigitizer终极使用指南
如何快速从图表图片中提取数据?WebPlotDigitizer终极使用指南 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 你是否曾面对…...

java springboot-vue加油站管理系统的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术架构核心功能模块系统特色部署方式应用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目背景 加…...

25款经典老芯片回顾:从运放、逻辑门到MCU,重温电子工程基石
1. 引言:一场跨越时代的芯片“认亲大会”最近在整理工作室的旧物料箱,翻出了一堆尘封已久的芯片,从布满灰尘的DIP封装到早已停产的早期逻辑门,每一片都像一张泛黄的老照片,记录着电子工业发展的一个脚印。我随手拍了几…...

obsidian博客联动方案
平台文章具有滞后性,最新文章请访问https://blog.nuoyis.net 原先博客需要使用typorapicgotypecho,其中typora编写完毕后需要复制到typecho后台去,极其不方便,然后经过高人指点,我对该软件交互使用开发了新高度 obsidi…...

计算机二级 WPS 文字题:样式调整考点 详细解析
计算机二级 WPS 文字题:样式调整考点 详细解析 这道题是WPS 文字 / Word 样式设置的高频必考题型,核心考点是「样式批量修改」和「分页控制」,我会把每一步的操作、考点和易错点都拆解清楚。 一、题目整体拆解 题目分为 3 个核心任务&#…...

桌面图标变白纸别慌!手把手教你用右键属性+路径复制,5分钟找回所有软件图标
桌面图标异常修复指南:从白纸图标到完整恢复的实战解析 电脑桌面上那些熟悉的图标突然变成白纸,这种看似小问题却让人倍感困扰。不必惊慌,这通常是系统图标缓存更新不及时或软件关联异常导致的常见现象。本文将带你深入理解图标显示机制&…...

广州市认定广东专利奖的条件有哪些?如何准备广东专利奖申报?
一、奖项设置与省级奖励标准广东专利奖设四类奖项,省级直接奖励标准如下:广东专利金奖:不超过20项,每项30万元广东专利银奖:不超过40项,每项20万元广东专利优秀奖:不超过60项,每项10…...

mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析
mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析 【免费下载链接】mpdf PHP library generating PDF files from UTF-8 encoded HTML 项目地址: https://gitcode.com/gh_mirrors/mp/mpdf 在当今数字化办公环境中,PDF文档生成已成为企业…...
:Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.24):Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...