类别型特征
#机器学习 #深度学习 #基础知识 #特征工程 #数据编码
背景
在现实生活中,我们面对的数据类型有很多,其中有的数据天然为数值类型具备数值意义,那么可以很自然地和算法结合,但是大部分数据他没有天然的数值意义,那么将他们送入到算法前,就需要对数据进行编码处理,将其转换为数值类型,才可以送入算法进行运算.
问题
处理一个这样算法问题时,首先我们需要确认所处理的数据是什么类型的,是否可以直接输入模型,如果不能,那么我们需要根据数据本身的特点,然后结合算法的适配的格式,去对数据进行编码处理.因此,我们需要依次思考以下的几个问题:
- 常见的类别数据有哪些形式?其中有哪些是需要进行编码的?
- 哪些算法能接收未经编码的类别型特征?哪些算法不能?
- 常见的编码类型及其优缺点?如何选择适合的编码方式?
解决方案
常见的类别特征有哪些?其中有哪些是需要进行编码的?
类别型特征是指在数据集中表示某种类别或属性的特征。它包含有限个离散的取值,通常用于描述无序的分类或标签信息。类别型特征没有固定的数值间隔和数值运算意义,只表示不同类别之间的区别和关系。
例如,性别、颜色、地区、职业、喜好程度、股票种类、专业等都可以是类别型特征。性别可以有两个取值:男和女;颜色可以有多个取值:红、蓝、绿等;地区可以有多个取值:东、南、西、北等;职业可以有多个取值:医生、教师、工程师等;问卷调查中,对一件事的喜好程度分为厌恶、无感、较喜欢、喜欢、特别喜欢等;股票可以分为煤炭,光伏,消费,白酒,医疗等等不同的板块;高考报志愿时,专业可以分为计算机科学,基础物理学,临床医学,兽医学,法律,文学等等.
总结来看,这些类别特征按照是否有序可以分为: 有序类别特征(Ordinal Categorical Features)是指类别之间存在自然顺序或等级关系的特征。这类特征的值可以进行排序,但不能直接进行数值运算;无序类别特征(Nominal Categorical Features)是指类别之间没有自然顺序或等级关系的特征。这类特征的值只是表示不同的类别,不存在排序关系。要是按照类别的数量来来分:高基类类别特征,具有大量唯一值的类别,特征类别总数很大;低基类类别特征,具有少量唯一值的类别,特征类别总数较少.
关于哪些类别特征需要编码,这个问题其实需要结合所采用的算法统筹考虑才有实际意义.但是,单从类别特征的分类上来考虑,可以划分为四种类型,它们的编码难点可以总结为下:
| 有序 | 无序 | |
| 低基类 | 保留类别顺序关系,保证类别均衡 | 保证类别间独立,保证类别均衡 |
| 高基类 | 保留类别关系,防止过拟合,解决稀疏性 | 保证类别间独立,解决稀疏性 |
哪些算法能接收未经编码的类别特征?哪些算法不能?
首先,没有经过编码的数据大多数为字符串类型.不同的算法所接受的数据格式是不同的,所以根据具体算法接收的数据格式来看.一般来说,只有能够直接依据类别划分就能进行运行的算法可以不用进行编码,决策树类算法(决策树,随机森林),规则基础算法(C5.0)以及基于统计概率的部分贝叶斯分类算法,其余的算法都需要对类别型特征进行编码处理后才能让算法正常运行.
常见的编码类型及其优缺点?如何选择适合的编码方式?
标签编码
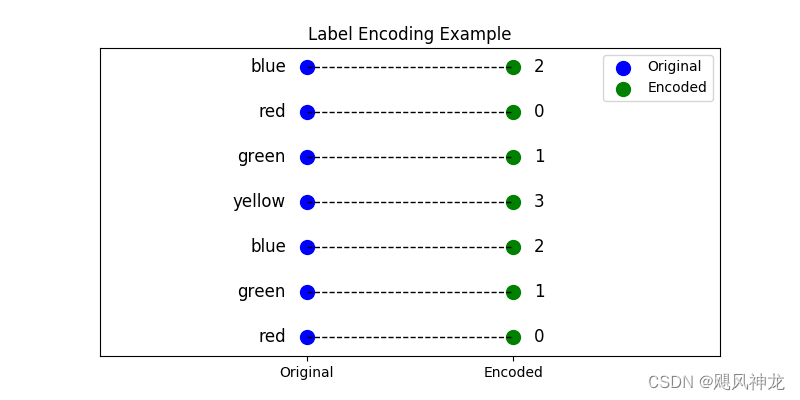
不适用于高基类类别特征,并且编码后的自然数对于回归任务来说是线性不可分的,即自然数之间的关系不能代表编码前的类别关系.
哈稀编码
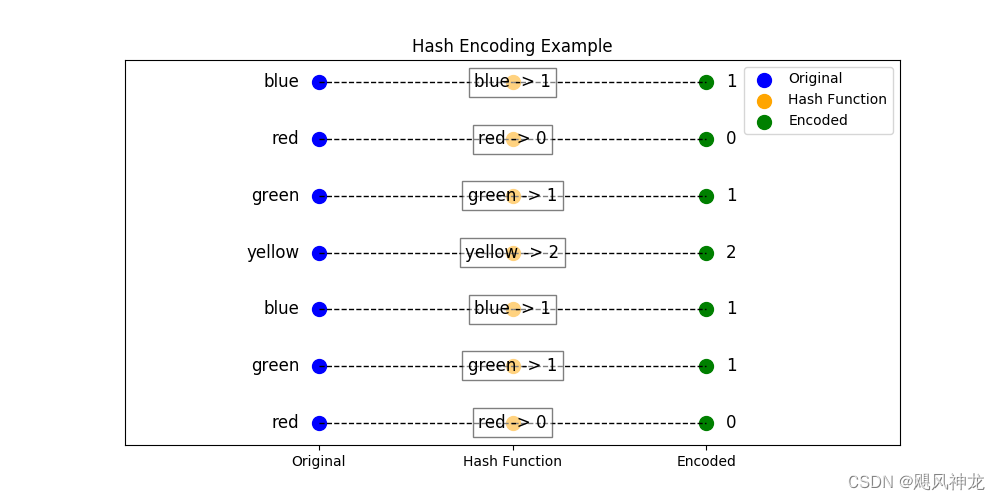
将类别特征通过哈希函数映射到固定数量的哈希桶中。这种方法在类别数量非常多时可以减小维度,但可能引入哈希冲突。
独热编码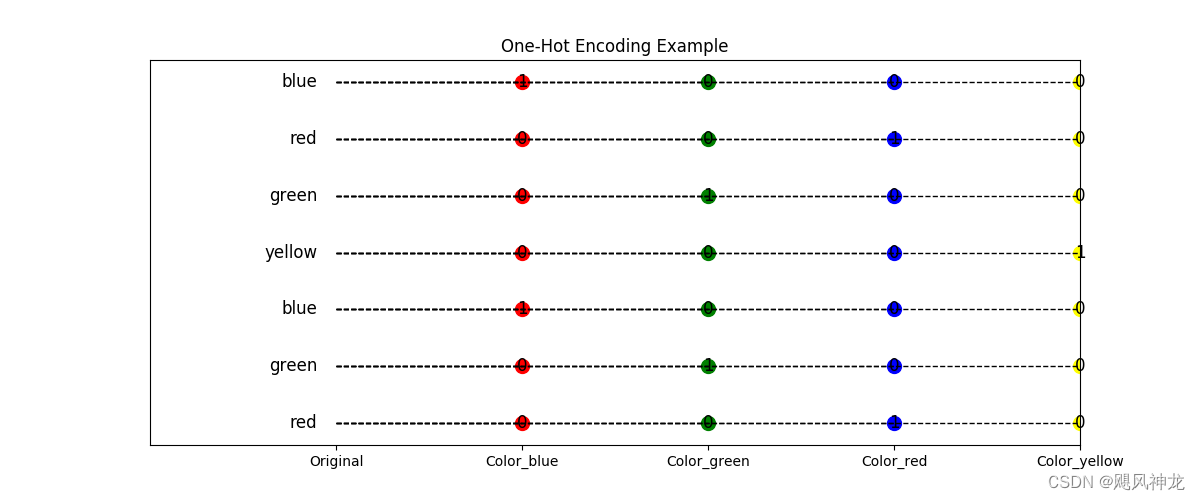
独热编码(One-Hot Encoding),又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。这个方法能很好的保证编码后,各个类别特征的独立性,但是面对高基类类型特征时,会比较稀疏从而浪费资源.
计数编码
计数编码(Count Encoding,也称频率编码)的过程,可以按照以下步骤进行:
- 原始类别数据:列出原始的类别数据。
- 计算类别频数:计算每个类别在数据集中出现的频数。
- 替换类别值:用类别的频数替换原始的类别值。
假设我们有一个类别特征 "Color",它有以下类别值:红色、绿色、蓝色、黄色、绿色、红色、蓝色。我们将计算这些颜色频数得:红色:2,绿色:2,蓝色:2,黄色:1。这种编码方式的问题显而易见,编码只关注了类别在数据集中出现的频次,但是忽略了类别本身的意义.所以,这种方式可能只适用于模型不关心类别意义,而关注类别统计属性的模型中.
直方图编码

实际上直方图编码,也是基于统计的编码,只不过它统计的不是单纯类别样本出现的次数,而是某一种特征在不同类别中的出现频次.这样我们通过先验的统计这些每个类别中这些特征的频次,然后观察样本中表现出的特征,来预测这个样本的类别.直方图编码能清晰看出特征下不同类别对不同预测标签的贡献度,缺点在于:使用了标签数据,若训练集和测试集的类别特征分布不一致,那么编码结果容易引发过拟合。此外,直方图编码出的特征数量是分类标签的类别数量,若标签类别很多,可能会给训练带来空间和时间上的负担。
WOE编码
权重证据编码(Weight of Evidence Encoding, WOE)的过程,我们可以按照以下步骤进行:
- 原始类别数据:列出原始的类别数据和目标变量。
- 计算类别的WOE值:计算每个类别的WOE值。
- 替换类别值:用类别的WOE值替换原始的类别值。
假设我们有一个类别特征 "Color",它有以下类别值:红色、绿色、蓝色、黄色,并且有一个二进制目标变量 "Target"。
权重证据(WOE)的计算公式为:
其中,"Good" 和 "Bad" 通常是正类和负类的计数。
我们需要计算每个类别的Good和Bad的分布:
- 红色:Good = 1,Bad = 1
- 绿色:Good = 1,Bad = 1
- 蓝色:Good = 1,Bad = 1
- 黄色:Good = 0,Bad = 1
总的Good和Bad数量:
- Total Good = 3
- Total Bad = 4
计算WOE值:
- 红色:
- 绿色:
- 蓝色:
- 黄色:
(注意:在实际应用中我们会处理这种情况)
透过公式,我们可以把WOE理解成:每个分组内坏客户分布相对于优质客户分布之间的差异性。
WOE存在几个问题:
- 分母可能为0.
- 没有考虑不同类别数量的大小带来的影响,可能某类数量多,但最后计算出的WOE跟某样本数量少的类别的WOE一样。
- 只针对二分类问题。
- 训练集和测试集可能存在WOE编码差异(通病)。
对于问题1,可加入regularization(默认值为1)。

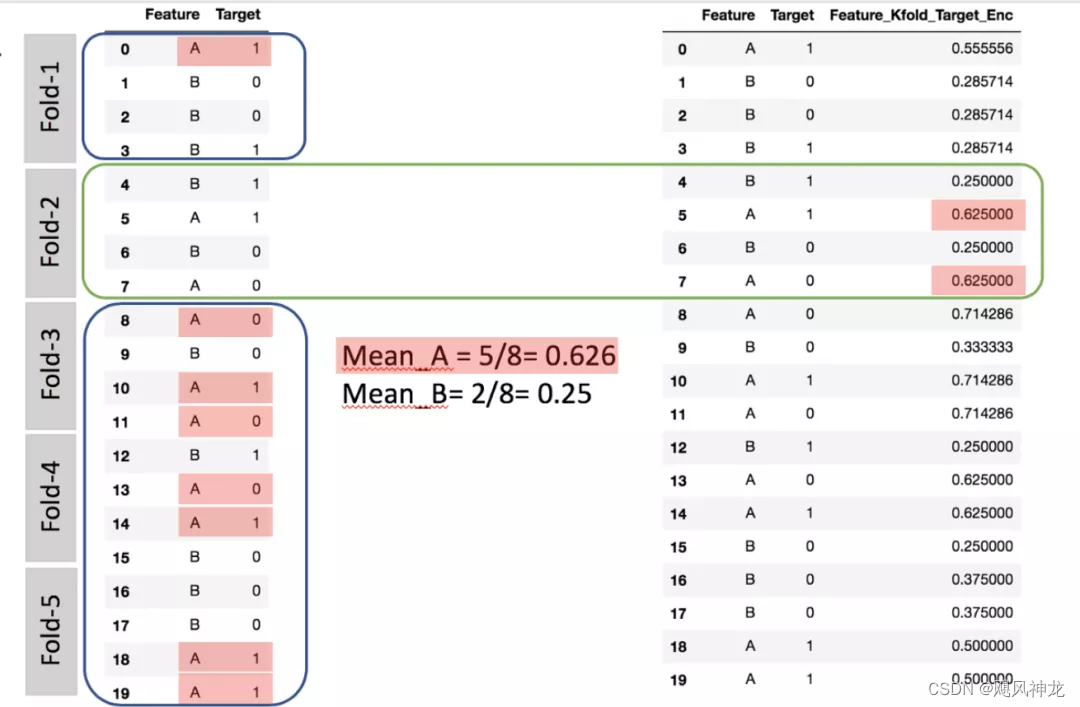
目标编码
亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。 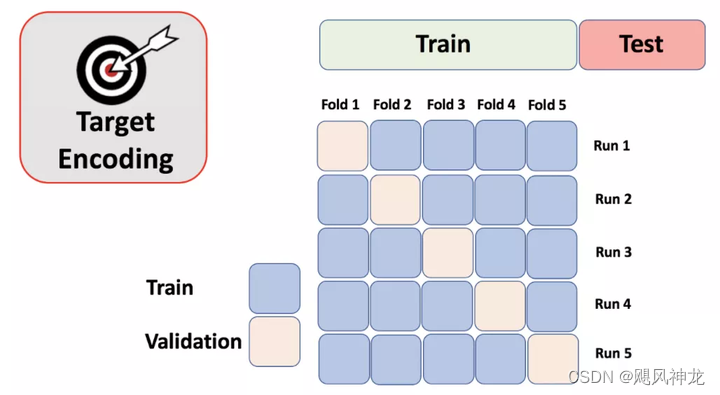
模型编码
其实模型编码思想很简单,即用神经网络来将输入的数据映射到一个易于算法进行的空间中.这也是很多预训练模型能够有利于实际任务的原因.但是,其中的优点与缺点也十分明显,优点是利用深度学将远特征映射到更有剖利于算法施行的空间中,缺点是需要大量数据做预训练,以及使用深度学习模型会可能有较大的资源消耗.

代码实践
标签编码
Scikit-learn中的LabelEncoder是用来对分类型特征值进行编码,即对不连续的数值或文本进行编码。其中包含以下常用方法:
- fit(y) :fit可看做一本空字典,y可看作要塞到字典中的词。
- fit_transform(y):相当于先进行fit再进行transform,即把y塞到字典中去以后再进行transform得到索引值。
- inverse_transform(y):根据索引值y获得原始数据。
- transform(y) :将y转变成索引值。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
city_list = ["red", "green", "blue", "red"]
le.fit(city_list)
print(le.classes_) # 输出为:['blue' 'green' 'red']
city_list_le = le.transform(city_list) # 进行Encode
print(city_list_le) # 输出为:[2 1 0 2]
city_list_new = le.inverse_transform(city_list_le) # 进行decode
print(city_list_new) # 输出为:['red' 'green' 'blue' 'red']哈稀编码
可以自由的定义hash函数,原则上不要产生过多碰撞就行,其中依据什么来hash可以结合具体情况选择,以便编码后的特征有利于算法的进行
import pandas as pd
import numpy as np# 原始数据
data = {'类别特征': ['Apple', 'Banana', 'Orange', 'Banana', 'Apple', 'Orange', 'Grape', 'Apple']
}
df = pd.DataFrame(data)# 选择哈希桶数量
num_buckets = 4# 定义哈希编码函数
def hash_encode(value, num_buckets):return hash(value) % num_buckets# 应用哈希编码函数
df['哈希值'] = df['类别特征'].apply(lambda x: hash_encode(x, num_buckets))# 独热编码哈希值
hash_encoded = pd.get_dummies(df['哈希值'], prefix='哈希桶')# 将哈希编码结果合并到原始数据中
result_df = pd.concat([df, hash_encoded], axis=1)# 打印结果
print(result_df)独热编码
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
- 可以处理数值型和类别型数据
- 输入必须为1D数组
- 可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizerlb = LabelBinarizer()city_list = ["red", "blue", "green", "blue"]lb.fit(city_list)
print(lb.classes_) # 输出为:['blue' 'green' 'red']city_list_le = lb.transform(city_list) # 进行Encode
print(city_list_le)
# 输出为:
# [[0 0 1]
# [1 0 0]
# [0 1 0]
# [1 0 0]]计数编码
import pandas as pd# 原始数据
data = {'类别特征': ['Apple', 'Banana', 'Orange', 'Banana', 'Apple', 'Orange', 'Grape', 'Apple']
}
df = pd.DataFrame(data)# 计算每个类别的频数
frequency_encoding = df['类别特征'].value_counts()# 应用频数编码
df['频数编码'] = df['类别特征'].map(frequency_encoding)# 打印结果
print(df)
直方图编码
计数编码是统计单纯特征数量,直方图编码是统计特征在不同类别中的分布.
import pandas as pd# 原始数据
data = {'类别特征': ['A', 'A', 'B', 'B', 'A', 'A', 'B'],'目标变量': [0, 1, 0, 1, 2, 2, 2]
}
df = pd.DataFrame(data)# 计算每个类别特征在目标变量各个取值上的分布
histogram_encoding = df.groupby('类别特征')['目标变量'].value_counts(normalize=True).unstack(fill_value=0)# 为了便于合并,将列名转换为字符串
histogram_encoding.columns = [f'目标变量_{col}' for col in histogram_encoding.columns]# 合并编码结果到原始数据
df = df.join(histogram_encoding, on='类别特征')# 打印结果
print(df)WOE编码
WOE值的计算公式为:
WOE=ln(正样本比例负样本比例)WOE=ln(负样本比例正样本比例)
其中:
- 正样本比例(Positive Rate):该类别在正样本中的占比。
- 负样本比例(Negative Rate):该类别在负样本中的占比。
import pandas as pd
import numpy as np# 原始数据
data = {'类别特征': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'A'],'目标变量': [0, 1, 0, 1, 1, 0, 1, 0]
}
df = pd.DataFrame(data)# 计算每个类别的正负样本数量
total_positive = df['目标变量'].sum()
total_negative = len(df) - total_positive# 计算每个类别的正负样本数量
positive_count = df[df['目标变量'] == 1].groupby('类别特征').size()
negative_count = df[df['目标变量'] == 0].groupby('类别特征').size()# 计算每个类别的正负样本比例
positive_ratio = positive_count / total_positive
negative_ratio = negative_count / total_negative# 填充缺失值为0
positive_ratio = positive_ratio.fillna(0)
negative_ratio = negative_ratio.fillna(0)# 计算WOE值
woe = np.log(positive_ratio / negative_ratio)# 打印每个类别的WOE值
print(woe)# 应用WOE编码
df['WOE编码'] = df['类别特征'].map(woe)# 打印结果
print(df)
目标编码
根据属性与类别的分布统计,用似然函数进行编码
import pandas as pd# 原始数据
data = {'类别特征': ['A', 'B', 'A', 'B', 'A', 'C', 'B', 'C', 'A', 'B'],'目标变量': [1, 0, 1, 1, 0, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)# 计算每个类别的目标变量均值
target_mean = df.groupby('类别特征')['目标变量'].mean()# 打印每个类别的目标变量均值
print("目标变量均值:\n", target_mean)# 应用目标编码
df['目标编码'] = df['类别特征'].map(target_mean)# 打印结果
print("\n目标编码结果:\n", df)
模型编码
在各个领域中的backbone预训练模型,以及当下在大模型领域广泛运用的CLIP.
总结
处理类别型编码时,需要综合考虑数据本身的特性:数据量,类别量,样本的分布特性,样本属性重要程度;算法的适应性:输入的数据的型式,算法效率,算法进度;实际处理问题的需要和目标.总之,针对这一类类别型特征的编码,其目的是将这类结构化的数据映射到一个易于算法处理的空间中.
参考链接
https://zhuanlan.zhihu.com/p/349592092
https://zhuanlan.zhihu.com/p/480609142
相关文章:
类别型特征
#机器学习 #深度学习 #基础知识 #特征工程 #数据编码 背景 在现实生活中,我们面对的数据类型有很多,其中有的数据天然为数值类型具备数值意义,那么可以很自然地和算法结合,但是大部分数据他没有天然的数值意义,那么将他们送入到算法前,就需要对数据进行编码处理,将其转换为数…...

java医院管理系统源码(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的医院管理系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 医院管理系统的主要使用者分…...

vue2 面试题
一、.vue的性能优化怎么做? 1.编码优化: 不要把所有的数据都放在data中;v-for时给每个元素绑定事件用事件代理;keep-alive缓存组件;尽可能拆分组件,提高复用性、维护性;key值要保证唯一&#…...

【JavaEE精炼宝库】多线程(3)线程安全 | synchronized
目录 一、线程安全 1.1 经典线程不安全案例: 1.2 线程安全的概念: 1.3 线程不安全的原因: 1.3.1 案例刨析: 1.3.2 线程不安全的名词解释: 1.3.3 Java 内存模型 (JMM): 1.3.4 解决线程不安全问题: 二…...
el-table-column两种方法处理特殊字段,插槽和函数
问题:后端返回的字段为数字 解决办法: {{ row[item.prop] 1 ? "启用" : "禁用" }} {{ row[item.prop] }} 最终果: 另外:如果多种状态时可用函数 {{ getStatus(row[item.prop]) }} {{ row[item.prop…...
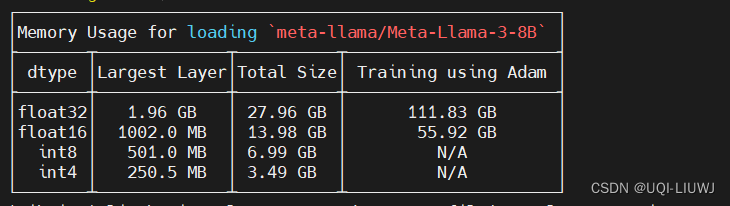
huggingface笔记: accelerate estimate-memory 命令
探索可用于某一机器的潜在模型时,了解模型的大小以及它是否适合当前显卡的内存是一个非常复杂的问题。为了缓解这个问题,Accelerate 提供了一个 命令行命令 accelerate estimate-memory。 accelerate estimate-memory {MODEL_NAME} --library_name {LIBR…...

李飞飞亲自撰文:大模型不存在主观感觉能力,多少亿参数都不行
近日,李飞飞连同斯坦福大学以人为本人工智能研究所 HAI 联合主任 John Etchemendy 教授联合撰写了一篇文章,文章对 AI 到底有没有感觉能力(sentient)进行了深入探讨。 「空间智能是人工智能拼图中的关键一环。」知名「AI 教母」李…...

超级好用的C++实用库之套接字
💡 需要该C实用库源码的大佬们,可搜索微信公众号“希望睿智”。添加关注后,输入消息“超级好用的C实用库”,即可获得源码的下载链接。 概述 C中的Socket编程是实现网络通信的基础,允许程序通过网络与其他程序交换数据。…...
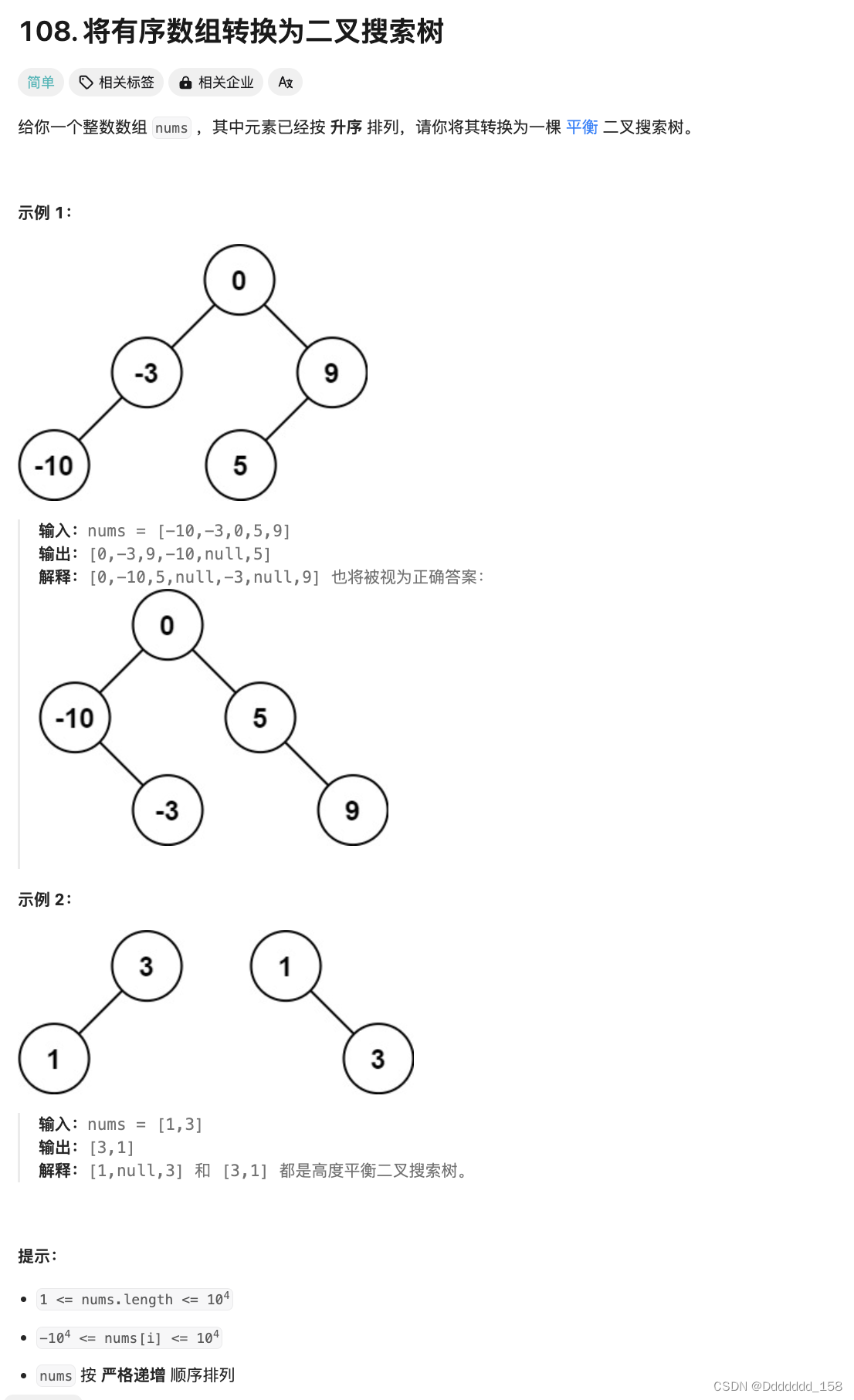
C++ | Leetcode C++题解之第108题将有序数组转换为二叉搜索树
题目: 题解: class Solution { public:TreeNode* sortedArrayToBST(vector<int>& nums) {return helper(nums, 0, nums.size() - 1);}TreeNode* helper(vector<int>& nums, int left, int right) {if (left > right) {return nu…...

5月27日,每日信息差
第一、韩国宇宙航空厅于 5 月 27 日正式成立,旨在推动以民间为主的太空产业生态圈发展,助力韩国成为航天强国。首任厅长尹宁彬表示,该机构将在庆尚南道泗川市的临时大楼开展相关工作。 第二、京东集团宣布,自2024年7月1日起&…...

echart扩展插件词云echarts-wordcloud
echart扩展插件词云echarts-wordcloud 一、效果图二、主要代码 一、效果图 二、主要代码 // 安装插件 npm i echarts-wordcloud -Simport * as echarts from echarts; import echarts-wordcloud; //下载插件echarts-wordcloud import wordcloudBg from /components/wordcloudB…...

解决无法直接抓取链接地址
当我们在爬取一些文章列表的时候,可能无法从接口或者html界面上获取到文章的详细列表 这个时候我们可以通过模拟点击且重写window.open方法,将跳转的地址捕获,并且放到html中去。 这样我们就可以获取到某个文章的详细地址了 // 保存原始的 …...

java面对对象编程-多态
介绍 方法的多态 多态是在继承,重载,重写的基础上实现的 我们可以看看这个代码 package b;public class main_ {public static void main(String[] args) { // graduate granew graduate(); // gra.cry();//这个时候,子类的cry方法就重写…...
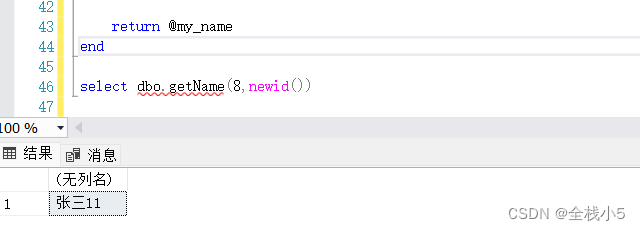
【Sql Server】随机查询一条表记录,并重重温回顾下自定义函数的封装和使用
大家好,我是全栈小5,欢迎来到《小5讲堂》。 这是《Sql Server》系列文章,每篇文章将以博主理解的角度展开讲解。 温馨提示:博主能力有限,理解水平有限,若有不对之处望指正! 目录 前言随机查询语…...

基于C#开发web网页管理系统模板流程-主界面管理员录入和编辑功能完善
前言 紧接上篇->基于C#开发web网页管理系统模板流程-登录界面和主界面_c#的网页编程-CSDN博客 已经完成了登录界面和主界面,本篇将完善主界面的管理员录入和编辑功能,事实上管理员录入和编辑的设计套路适用于所有静态表的录入和编辑 首先还是介绍一下…...

K8s证书过期处理
问题描述 本地有一个1master2worker的k8s集群,今天启动VMware虚拟机之后发现api-server没有起来,docker一直退出,这个集群是使用kubeadm安装的。 于是kubectl logs查看了日志,发现证书过期了 解决方案: 查看证书 #…...
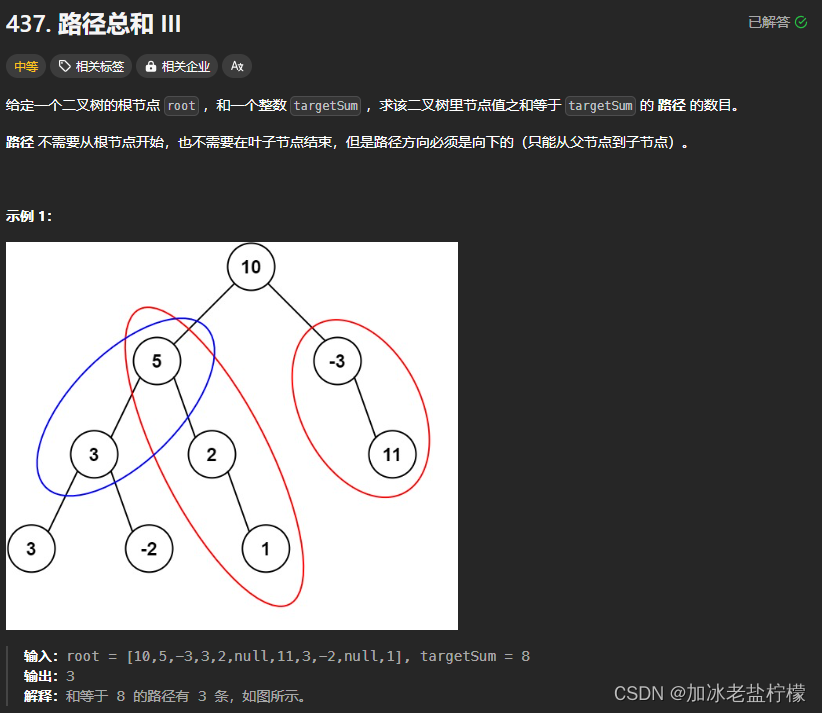
刷题之路径总和Ⅲ(leetcode)
路径总和Ⅲ 这题和和《为K的数组》思路一致,也是用前缀表。 代码调试过,所以还加一部分用前序遍历数组和中序遍历数组构造二叉树的代码。 #include<vector> #include<unordered_map> #include<iostream> using namespace std; //Def…...

MongoDB 原子操作:确保数据一致性和完整性的关键
在 MongoDB 中,原子操作是指可以一次性、不可分割地执行的数据库操作。这些操作能够保证在多个并发操作中不会出现数据不一致或者丢失的情况,确保数据库的数据完整性和一致性。 基本语法 MongoDB 的原子操作通常与更新操作相关,其基本语法如…...

2024上半年软考高级系统架构设计师回顾
本博客地址:https://security.blog.csdn.net/article/details/139238685 2024年上半年软考在5月25-26日举行,趁着时间刚过去记忆还在,简单写一点总结。 关于考试形式:上机考试(以后也都是机考)࿰…...

SQL注入绕过技术深度解析与防御策略
引言 在Web安全领域,SQL注入攻击一直是一个棘手的问题。攻击者通过SQL注入手段获取敏感数据、执行恶意操作,甚至完全控制系统。尽管许多防御措施已被广泛采用,但攻击者仍不断开发新的绕过技术。本文将深度解析SQL注入的绕过技术,…...

E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南
E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 还在为手动保存上百张漫画图片而烦恼吗&am…...

第一学期结果
关注 1.从安涛老师前三期视频中了解了方向2.从b站了解了555的内部结构3.仿真。4.低通滤波器的基本原理:一、核心定义只允许低频信号顺利通过,阻挡、衰减高频信号的电路。 你电路里作用:滤掉方波里的高频谐波,留下低频基波…...

链游3.0时代:GameFi+NFT+SocialFi如何引爆万亿级“数字乌托邦“?
——区块链游戏开发的全栈解密与商业落地指南引言:当游戏世界开始"造富" 当Axie Infinity的玩家在菲律宾靠打怪月入过万,当Decentraland的虚拟土地拍出243万美元天价,当StepN的运动鞋NFT创造45天回本神话——链游已不再是加密圈的小…...

iTorrent完整指南:如何在iPhone上实现专业级种子下载管理
iTorrent完整指南:如何在iPhone上实现专业级种子下载管理 【免费下载链接】iTorrent Torrent client for iOS 16 项目地址: https://gitcode.com/gh_mirrors/it/iTorrent iTorrent是一款专为iOS 16设备设计的专业种子客户端应用,让你能够在iPhone…...

FICO创凭证标准错误:在折旧范围 01 中的业务与帐面净值规则冲突
凭证过账总金额等于资产剩余总价值创凭证出现如下错误:一、首先确认是否是业务配置问题排查业务问题操作如下:T-CODE:SPRO --->财务会计--->资产会计核算--->组织结构--->复制参考折旧表选折对应折旧表如果不一致设置为一致即可解决问题&…...

Pure Live:3大平台聚合,打造你的专属纯净直播空间
Pure Live:3大平台聚合,打造你的专属纯净直播空间 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否厌倦了在多个直播应用间来回切换?…...
的介绍说明)
关于国内SDR(成都振芯)的介绍说明
概述 软件无线电(SDR)是一种无线电通信技术,其关键功能(如调制解调、滤波、变频等)通过软件在可编程硬件(如FPGA、DSP)上实现,而非依赖固定的硬件电路。这使得无线电设备具有高度的灵…...

谷歌 I/O 开发者大会亮点多:Gemini Spark、YouTube 搜索等新功能来袭!
谷歌 I/O 开发者大会拉开帷幕 谷歌年度 I/O 开发者大会于周二在加利福尼亚州山景城拉开帷幕,会上发布了众多新的 AI 功能、硬件和工具。记者在现场通过 CNET 的实时博客报道了每一项更新。以下是一些亮点回顾。 Gemini Spark 任务自动化 AI 是今年谷歌 I/O 大会的核…...

Unity游戏资源提取实战指南:AssetStudio高阶用法与避坑手册
1. 这不是“又一个AssetStudio教程”,而是我拆了27款Unity手游后总结的资源提取生存手册AssetStudio、Unity游戏资源提取、Unity AssetBundle、Unity3D反编译——这几个词,过去三年里我每天至少在技术群、论坛、工单系统里看到50次。但绝大多数人点开Ass…...

Kimi LeetCode 2547. 拆分数组的最小代价 C++实现
这道题的核心思路是动态规划 记忆化搜索。我们定义 dfs(i) 为从下标 i 开始拆分数组的最小代价,答案即为 dfs(0)。关键观察子数组的重要性 k trimmed(subarray).length。其中 trimmed 操作会移除子数组中只出现一次的数字。如果我们用 cnt[x] 记录数字 x 在当前子…...