【机器学习】机器学习基础概念与初步探索
❀机器学习
- 📒1. 引言
- 📒2. 机器学习概述
- 📒3. 机器学习基础概念
- 🎉2.1 机器学习的分类
- 🎉2.2 数据预处理
- 🌈数据清洗与整合
- 🌈 特征选择和特征工程
- 🌈数据标准化与归一化
- 📒4. 常见机器学习算法
- 📒5. 机器学习模型实践
- 🎉5.1 使用Python和scikit-learn进行模型训练
- 🎉5.2 数据集加载与探索性数据分析
- 🎉5.3 模型的训练与评估
- 📒 6. 总结与展望
- 🎉总结
- 🎉机器学习领域的未来发展趋势
- 🎉学习机器语言的建议
- 🎉展望未来
📒1. 引言
在数字化时代的浪潮中,我们见证了前所未有的信息爆炸和数据处理挑战。随着数据量的不断增长和复杂性的日益提升,如何从中提取有价值的信息、做出智能的决策成为了各行各业共同面临的问题。这正是机器学习(Machine Learning)崭露头角并迅猛发展的背景。本章将简要介绍机器学习的定义和应用领域,提供对机器学习的基本认识。

📒2. 机器学习概述
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。作为人工智能的核心,机器学习是使计算机具有智能的根本途径。未来的机器学习将具有更高的自动化水平,能够处理更加复杂和抽象的问题,为人类带来更多的便利和价值。
📒3. 机器学习基础概念

🎉2.1 机器学习的分类
监督学习:
- 监督学习是利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。在监督学习中,每个实例都是由一个输入对象和一个期望的输出值组成。监督学习算法通过分析训练数据,并产生一个推断的功能,可以用于映射出新的实例。
- 常见的监督学习算法包括线性分类器、支持向量机(SVM)、决策树、k近邻和随机森林等,
- 监督学习通过构建模型来识别模式和规律,从而能够做出预测和决策。
无监督学习:
- 无监督学习与监督学习不同,其数据没有显式的标签或已知的结果变量,无监督学习的核心目的是从输入数据中发现隐藏的模式、结构和规律。
- 常见的无监督学习算法有主成分分析、奇异值分解等。
强化学习:
- 强化学习是机器学习的一种,是通过与环境交互来学习的机器学习方法。强化学习的主要特点是反复实验和获得奖励,并根据获得的奖励来调整行为策略。
- 强化学习中的时间非常重要,因为数据都是有时间关联的。强化学习在游戏、机器人控制、自然语言处理等领域有广泛应用。
综上所述:监督学习、无监督学习与强化学习各有其特点和优势,适用于不同的应用场景。在实际应用中,我们需要根据具体问题和数据特点来选择合适的机器学习类型。
🎉2.2 数据预处理
🌈数据清洗与整合
数据清洗:
- 数据清洗是数据预处理中非常关键的一步,它涉及检查数据的一致性、完整性和准确性,并纠正或删除不准确或不完整的记录,然后对这些数据进行处理
- 常见的数据清洗操作包括删除缺失值、填充缺失值、处理异常值和去重等
数据整合:
数据整合是把在不同数据源的数据收集、整理、清洗、转换后,加载到一个新的数据源,为数据消费者提供统一数据视图的数据集成方式
🌈 特征选择和特征工程
特征选择:
- 特征选择是从原始特征集中选择出子集,使得这个子集在机器学习任务上能够获得更好的性能
- 特征选择目标是减少过拟合,提高模型准确性,减少计算成本
- 特征选择的方法主要有过滤法,包装法,嵌入法
特征工程:
- 特征工程它涉及对原始数据通过数据转换、组合、编码等方式来提高模型的预测能力,简化模型,提高模型的性能和效果
- 特征工程的主要操作包括数值化、独热编码、特征缩放
🌈数据标准化与归一化
数据标准化: 通常是通过将数据指将原始数据按比例缩放,使其落入一个特定的尺度,以便不同特征之间具有可比性,常见的标准化方法有Z-score标准化
数据归一化: 是将数据缩放到一个指定的范围,通常是[0, 1]或[-1, 1]。归一化通常是通过将数据减去最小值,然后除以数据的范围来实现的,常见的归一化方法有Z-score标准化
数据标准化代码示例(Python)
import pandas as pd
from sklearn.preprocessing import StandardScaler # 假设我们有一个名为df的DataFrame
data = { 'feature1': [1, 2, 3, 4, 5], 'feature2': [90, 100, 110, 120, 130], 'feature3': [2.2, 3.4, 5.6, 7.8, 10.0]
}
df = pd.DataFrame(data) # 初始化StandardScaler
scaler = StandardScaler() # 使用fit_transform方法在原始数据上进行标准化,并获取结果
# 注意:这将直接在数据上进行就地变换(inplace),但我们在这里赋值给一个新的变量以显示变化
df_scaled = scaler.fit_transform(df) # 将标准化后的数据转换回DataFrame(如果需要的话)
# 注意:列名可能与原始DataFrame相同,但数据已经是标准化的了
df_scaled = pd.DataFrame(df_scaled, columns=df.columns) # 输出处理后的数据
print("原始数据:")
print(df)
print("\n标准化后的数据:")
print(df_scaled)
📒4. 常见机器学习算法
线性回归算法
- 线性回归:用于预测连续值的方法,它假设特征和目标之间的关系是线性的
- 适用场景:线性回归适用于预测连续数值型目标变量,并且当自变量与目标变量之间存在线性关系时效果最佳
- 优点:简单易懂,计算效率高,对于线性关系的数据有很好的拟合效果
- 缺点:对于非线性关系的数据拟合效果较差,容易受到异常值的影响
逻辑回归
- 逻辑回归:述逻辑回归的概念和应用,可以解释逻辑回归的sigmoid函数和损失函数
- 适用场景:逻辑回归适用于二分类问题,特别是当输出结果为二元(是/否,真/假)时
- 优点:计算效率高,易于实现,对于二分类问题有很好的分类效果
- 缺点:对于多分类问题效果较差,且对于非线性关系的数据拟合效果有限
决策树与随机森林
- 决策树与随机森林:介绍决策树的构建过程和随机森林的集成学习方法。可以通过可视化展示决策树的分裂过程
- 适用场景:决策树适用于处理离散型和连续型数据,可以用于分类和回归问题。
- 优点:直观易懂,可解释性强,能够处理非线性关系的数据。
- 缺点:容易过拟合,对于高维数据效果不佳,且对于连续型数据的处理不够精细。
支持向量机(SVM)
- 支持向量机:算法是一种广泛使用的监督学习算法,主要用于数据分类问题
支持向量机算法特点:高效性,较好的泛化能力,非线性处理能力
SVM算法在多个领域都有广泛的应用,如文本分类、图像识别、生物信息学、金融预测等。由于其出色的性能和广泛的应用前景,SVM已经成为机器学习领域中最受欢迎的算法之一
📒5. 机器学习模型实践
🎉5.1 使用Python和scikit-learn进行模型训练
Scikit-learn是一个用于机器学习和数据挖掘的开源Python库,scikit-learn库是一个常用的选择,因为它提供了许多现成的机器学习算法
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 手动创建模拟数据
np.random.seed(42) # 为了结果的可复现性
X = 2 * np.random.rand(100, 1) # 100个样本,1个特征,值在[0, 2)之间
y = 4 + 3 * X + np.random.randn(100, 1) # 线性关系加上一些噪声 # 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42) # 初始化模型
model = LinearRegression() # 训练模型
model.fit(X_train, y_train.ravel()) # 注意y_train需要是一维数组,所以使用ravel() # 使用模型进行预测
y_pred = model.predict(X_test) # 评估模型性能
mse = mean_squared_error(y_test.ravel(), y_pred)
rmse = np.sqrt(mse)
print(f'Root Mean Squared Error: {rmse}')
🎉5.2 数据集加载与探索性数据分析
数据集加载与探索性数据分析是项目中至关重要的步骤\
数据集加载
数据集来源
- 内置数据集:如scikit-learn库中的鸢尾花数据集(load_iris)、手写数字数据集(load_digits)等
- 外部文件:从CSV、Excel、JSON、数据库等外部文件中加载数据
- API接口:从在线API获取数据
加载方法
- 使用scikit-learn内置函数:如load_iris()加载鸢尾花数据集
- 使用Pandas库:如pd.read_csv(‘data.csv’)从CSV文件加载数据
- 使用NumPy库:如np.load(‘data.npy’)从二进制文件加载数据
- 使用SQLAlchemy库:从关系型数据库中加载数据
探索性数据分析
探索性数据分析的主要目的是了解数据的性质、结构和潜在模式,为后续的数据处理和建模提供指导。
数据收集与清洗
- 数据收集:从各种来源收集数据
- 数据清洗:去除重复值、缺失值、异常值和噪声
数据可视化
- 使用直方图、散点图、折线图等可视化工具展示数据
这有助于快速发现数据中的趋势、模式和异常
描述性统计
- 计算均值、中位数、方差、标准差等描述性统计量
- 了解数据的基本特征,如中心趋势、离散程度等
深入探索
- 相关性分析:探索变量之间的关系
- 回归分析:研究一个或多个自变量与因变量之间的关系
- 聚类分析:将数据划分为不同的组或簇
🎉5.3 模型的训练与评估
模型的训练
模型训练:指
使用已知的数据集来训练机器学习模型,使其能够学习数据中的模式和规律。训练集通常包括一组特征(输入)和对应的标签(输出),模型的目标就是根据输入特征预测输出标签
模型的评估
模型评估:是验证模型性能的过程,旨
在评估模型对新数据的预测能力。评估模型通常使用独立的测试集,该测试集在训练过程中是未知的,以确保评估结果的客观性和公正性
我们举个简单的例子,实际中有更复杂的模型
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # # 为了示例简单,我们只取两个类别
X = X[y < 2]
y = y[y < 2] # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化模型
model = LogisticRegression() # 训练模型
model.fit(X_train, y_train) # 使用模型进行预测
y_pred = model.predict(X_test) # 评估模型:计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}') # 评估模型:打印分类报告
report = classification_report(y_test, y_pred)
print(report)
模型的训练和评估是机器学习和数据科学项目中非常重要的两个步骤。通过训练模型,我们可以使其学习数据中的模式和规律;通过评估模型,我们可以验证其性能并确定是否满足实际需求。在评估模型时,我们需要选择合适的评估指标,并使用独立的测试集或交叉验证等技术来确保评估结果的客观性和公正性
📒 6. 总结与展望
🎉总结
在本文中,深入探讨了机器学习的基础概念、常见算法,模型实践希望能够从中获得对机器学习的全面了解,并对其在未来发展的重要性和应用价值做出了判断
🎉机器学习领域的未来发展趋势
机器学习领域的未来重要性和应用价值是不可忽视的。随着技术的不断发展和数据的不断增长,机器学习正逐渐成为推动社会进步和经济发展的关键力量,机器学习将在金融、医疗、零售等传统领域继续深入应用,同时在新兴领域如物联网、自动驾驶、智能家居等也将发挥更加重要的作用,它不仅将推动科技进步和经济发展,还将为人类社会带来更加美好的未来
🎉学习机器语言的建议
要学好机器学习,首先要夯实数学基础,特别是线性代数、概率论和统计学。其次,选择权威的教程或课程,系统学习机器学习算法和原理。同时,熟练掌握编程语言(如Python),熟悉常用机器学习库。勤做实践项目,将所学知识应用于实际问题。保持对新技术的好奇心,持续学习,紧跟行业前沿。勇于探索,不怕失败,通过不断实践和挑战自我,逐渐掌握机器学习的精髓
🎉展望未来
机器学习将继续引领科技革新的浪潮,其应用将愈发广泛且深入。随着算法的不断优化和计算能力的显著提升,机器学习将能够处理更加复杂、多样化的数据,从而为我们提供更准确、更智能的决策支持。我们期待看到机器学习在医疗、金融、教育、交通等领域发挥更大的作用,解决现实生活中的诸多难题。同时,随着技术的不断进步,让我们共同期待机器学习技术在未来的发展

相关文章:
【机器学习】机器学习基础概念与初步探索
❀机器学习 📒1. 引言📒2. 机器学习概述📒3. 机器学习基础概念🎉2.1 机器学习的分类🎉2.2 数据预处理🌈数据清洗与整合🌈 特征选择和特征工程🌈数据标准化与归一化 📒4. …...

学英语材料:单口喜剧、讲故事、短剧喜剧以及广播剧和播客节目
学习英语节目 有名的单口喜剧、讲故事、短剧喜剧以及广播剧和播客节目: 单口喜剧(Stand-up Comedy) 描述:这是最接近相声的形式,表演者独自一人站在舞台上,用幽默的方式讲述个人经历、观察到的社会现象或…...
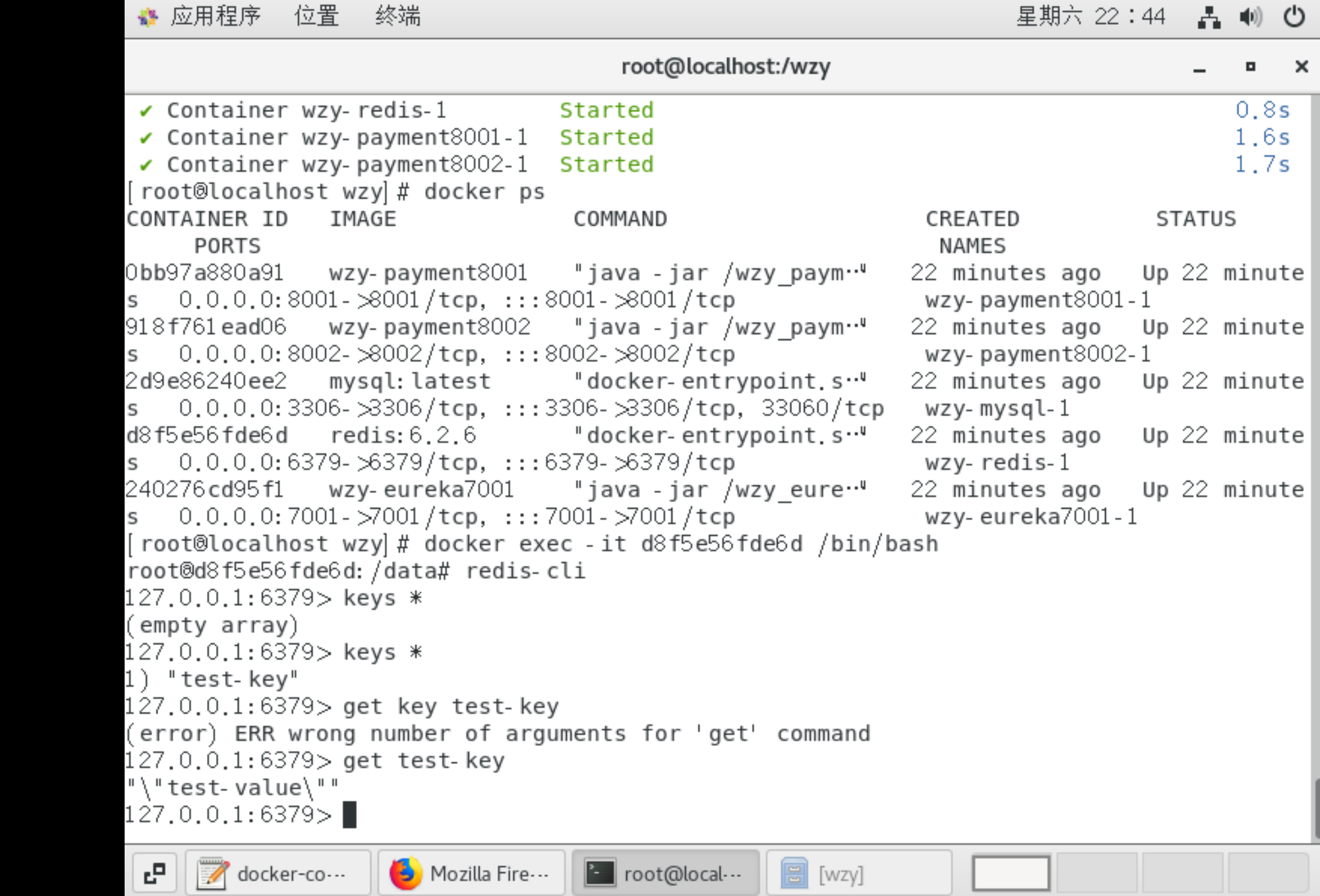
Docker Compose使用
Docker-Compose是什么 docker建议我们每一个容器中只运行一个服务,因为doker容器本身占用资源极少,所以最好是将每个服务单独分割开来,但是这样我们又面临了一个问题: 如果我需要同时部署好多个服务,难道要每个服务单独写Docker…...

如何优雅的卸载linux上的todesk
要优雅地卸载Linux上的ToDesk,您可以按照以下步骤操作: 打开终端。 输入以下命令来停止ToDesk服务(如果它正在运行的话): sudo systemctl stop todesk 然后,使用包管理器卸载ToDesk。如果您使用的是apt&…...

【Vue】el-checkbox多选框实现单选效果,选中一个选项则自动取消其他勾选
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回&#…...

Linux中使用vi编辑器自动缩进4个字符
平常在Linux操作系统下书写shell脚本内容,或是把写好的shell内容直接复制到vi编辑器中,本来缩进好的字符,会自动变乱,这是因为Linux的vi编辑器默认是缩进8个字符造成,可以使用下面2个方法解决该问题的发生。 1、本用户…...

#笔记#笔记#其他
大鱼论文是一款非常靠谱、方便、值得推荐的论文写作工具。无论是在学术研究中还是在日常写作中,大鱼论文都能够帮助用户轻松完成论文的写作工作。 首先,大鱼论文提供了强大的查重降重功能,能够帮助用户快速定位论文中可能存在的抄袭问题&…...

gtask笔记
1、创建Task GTask *g_task_new (gpointer source_object, GCancellable *cancellable, GAsyncReadyCallback callback, gpointer callback_data); source_object:GObject对象,拥有者 cancellable:可否取消 callback:task完成后…...

【Linux学习】深入探索进程等待与进程退出码和退出信号
文章目录 退出码return退出 进程的等待进程等待的方法 退出码 main函数的返回值:进程的退出码。 一般为0表示成功,非0表示失败。 每一个非0退出码都表示一个失败的原因; echo $?命令 作用:查看进程退出码。…...
Linux:线程
文章目录 前言1. 线程概念1.1 什么是线程1.2 线程比进程更加轻量化1.3 虚拟地址到物理地址的转化物理内存的管理页表 1.4 线程的优点1.5 线程的缺点1.6 线程异常1.7 线程用途 2. 进程 vs 线程3. 线程控制3.1 线程创建3.2 线程退出3.3 线程等待3.4 分离线程3.5 线程取消 4. 线程…...
)
卡到BUG了:删除重发白得积分(以前删除会扣减积分)
以前是:删除文章,积分减少,点赞积分减少,从回收站恢复文章,积分恢复,点赞数恢复但点赞积分不恢复。也就是删除重发总积分减少点赞的积分,有损失。 今天是:删除文章,积分不…...

轻松拿捏C语言——【字符函数】字符分类函数、字符转换函数
🥰欢迎关注 轻松拿捏C语言系列,来和 小哇 一起进步!✊ 🌈感谢大家的阅读、点赞、收藏和关注💕 🌹如有问题,欢迎指正 感谢 目录👑 一、字符分类函数🌙 二、字符转换函数…...

【Rust日报】ratatui版本更新
[new ver] ratatui v0.26.3 一个构建终端用户界面的库。新版本包括: 修复Unicode 截断 bug对颜色更好地序列化更快的渲染弃用assert_buffer_eq宏暴露错误类型常量函数和类型 官网: https://ratatui.rs/ 链接: https://ratatui.rs/highlights/v0263/ [new lib] ansi2…...

力扣每日一题 5/28
题目:2951-找出峰值 给你一个下标从 0 开始的数组 mountain 。你的任务是找出数组 mountain 中的所有 峰值。 以数组形式返回给定数组中 峰值 的下标,顺序不限 。 注意: 峰值 是指一个严格大于其相邻元素的元素。数组的第一个和最后一个元…...

async函数和await函数
一、async函数 async是一个加在函数前的修饰符,被async定义的函数会默认返回一个Promise对象resolve的值。 因此对async函数可以直接then,返回值就是then方法传入的函数。 // async基础语法 async function fun0(){console.log(1);return 1; } fun0()…...

Redis面试题深度解析
1、我看你做的项目中,都用到了redis,你在最近的项目中哪些场景使用了redis呢? 2、缓存穿透 布隆过滤器的误判现象 Redisson和Guava都对布隆过滤器进行了实现 3、缓存击穿 互斥锁,就是一个线程来修改,并占据了锁,另外其…...

Ubuntu 22.04 .NET8 程序 环境安装和运行
前言 我们需要将.NET8编写的console控制台程序,部署在Ubuntu服务器上运行。 安装.NET运行时 1.增加微软包安装源 wget https://packages.microsoft.com/config/ubuntu/22.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb sudo dpkg -i packages…...

MetaRTC-ffmpeg arm移植
touch cmake_arm.sh 添加 rm -rf build mkdir build cd build ARCHaarch64.cmake cmake -DCMAKE_BUILD_TYPERelease -DCMAKE_TOOLCHAIN_FILE../$ARCH .. maketouch cmake_arm.sh 添加 SET(CMAKE_SYSTEM_NAME Linux) SET(CMAKE_C_COMPILER /home/yqw/MetaRTC/BC/stbgcc-6.3-1…...

【乐吾乐3D可视化组态编辑器】模型类型与属性
编辑器地址:3D可视化组态 - 乐吾乐Le5le 本章主要为您介绍模型的属性功能。 一个模型至少会包含一个节点(Node),从节点类型上可以分为转换节点(TransformNode)、网格(Mesh)、实例网…...

PyQt下拉框QComboBox点击下拉时即更新下拉数据
在 PyQt 中,QComboBox 控件本身并没有直接的事件或信号来指示下拉列表何时被打开(即用户点击了下拉箭头)。但是,你可以通过其他方式间接地实现这个功能,比如通过重写 QComboBox 的某些方法或者在用户与 QComboBox 交互…...

基于项目代码实测:XCP/CCP 模块“标定差异”全流程深度操作指南
在实际项目的 XCP/CCP 标定业务中,核对与同步底层内存参数是一项极其高频的操作。本指南将完全基于最新版“标定差异(Calibration Difference)”界面的真实功能逻辑,为你提供一份严谨、详细、且立即可用的三倍容量操作手册。无论你…...

抖音获客失效?拆解本地商家流量困局的底层逻辑与破局路径
一、一个反直觉的数据先看两组数据,它们指向同一个方向。第一组:2025年,抖音本地生活服务GMV突破8500亿元。同期,入驻商家达到1519.8万家动销门店,399万新商家在一年内涌入。第二组:2026年Q1,抖…...

Agentic Search能替代GraphRAG吗,结论清晰了
2024 年 GraphRAG 爆火以来,「要不要建图」成了 RAG 系统设计中最常被讨论的决策。建图能显著提升多跳推理性能,但代价高昂——实体抽取、图谱构建、索引维护,每一步都是真金白银。 与此同时,agentic search 系统快速崛起——Sear…...

ElevenLabs支持闽南语吗?福建话语音合成实测:从API调用到音色克隆的7步通关手册
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs福建话语音支持现状与能力边界 ElevenLabs 目前尚未在官方语音模型库中提供对福建话(含闽南语、闽东语等分支)的原生支持。其公开文档与 API 文档均未列出任何以“Fuj…...

RAG 和 NotebookLM 都试过后,我才发现数据库知识库真正缺的不是搜索
很多数据库知识库不好用,不是模型不会答,而是知识没有被整理成可调用、可校验、可维护的资产。 前面几篇一直在聊 DB Agent。 聊 Skill,聊记忆,聊告警风暴,聊编排,也聊到了系统画像、历史案例和当前证据。…...

从零开始:5分钟掌握Mermaid Live Editor,告别复杂图表绘制烦恼
从零开始:5分钟掌握Mermaid Live Editor,告别复杂图表绘制烦恼 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

淘金币自动化脚本:每天节省20分钟,解放双手的终极指南
淘金币自动化脚本:每天节省20分钟,解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinb…...
第3小节:超高纯氟化钙材料难点)
0603光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第3小节:超高纯氟化钙材料难点
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第3小节:超高纯氟化钙材料难点(深紫外配套核心,全维度死磕解析) 前置硬核声明 氟化钙单晶(CaF₂)是DUV深紫外光刻核心光学基…...

Cadence新手村任务:5分钟搞定嘉立创LED封装,让你的OrCAD原理图不再‘裸奔’
Cadence新手村任务:5分钟搞定嘉立创LED封装,让你的OrCAD原理图不再‘裸奔’ 刚安装好Cadence软件的新手设计师,面对空白的OrCAD原理图界面时,往往会感到无从下手。就像游戏角色初入新手村需要第一把武器,你的第一个电子…...

从‘六度空间’到HNSW:图解这个让推荐系统变快的底层算法
从“六度空间”到HNSW:让推荐系统快如闪电的底层逻辑 你是否想过,为什么社交平台上总能精准推荐你可能认识的人?电商网站能在毫秒间为你匹配心仪商品?这一切背后,都藏着一个将“六度分隔理论”数学化的算法——HNSW&am…...