【第5章】SpringBoot整合Druid
文章目录
- 前言
- 一、启动器
- 二、配置
- 1.JDBC 配置
- 2.连接池配置
- 3. 监控配置
- 三、配置多数据源
- 1. 添加配置
- 2. 创建数据源
- 四、配置 Filter
- 1. 配置Filter
- 2. 可配置的Filter
- 五、获取 Druid 的监控数据
- 六、案例
- 1. 问题
- 2. 引入库
- 3. 配置
- 4. 配置类
- 5. 测试类
- 6. 测试结果
- 七、案例 ( 推荐 ) \color{#00FF00}{(推荐)} (推荐)
- 1. 引入库
- 2. 配置
- 3. 测试类
- 4. 测试结果
- 总结
前言
Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。
一、启动器
Druid Spring Boot Starter 用于帮助你在Spring Boot项目中轻松集成Druid数据库连接池和监控。
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter -->
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.22</version>
</dependency>
二、配置
1.JDBC 配置
spring.datasource.druid.url= # 或spring.datasource.url=
spring.datasource.druid.username= # 或spring.datasource.username=
spring.datasource.druid.password= # 或spring.datasource.password=
spring.datasource.druid.driver-class-name= #或 spring.datasource.driver-class-name=
2.连接池配置
spring.datasource.druid.initial-size=
spring.datasource.druid.max-active=
spring.datasource.druid.min-idle=
spring.datasource.druid.max-wait=
spring.datasource.druid.pool-prepared-statements=
spring.datasource.druid.max-pool-prepared-statement-per-connection-size=
spring.datasource.druid.max-open-prepared-statements= #和上面的等价
spring.datasource.druid.validation-query=
spring.datasource.druid.validation-query-timeout=
spring.datasource.druid.test-on-borrow=
spring.datasource.druid.test-on-return=
spring.datasource.druid.test-while-idle=
spring.datasource.druid.time-between-eviction-runs-millis=
spring.datasource.druid.min-evictable-idle-time-millis=
spring.datasource.druid.max-evictable-idle-time-millis=
spring.datasource.druid.filters= #配置多个英文逗号分隔
....//more
3. 监控配置
# WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter
spring.datasource.druid.web-stat-filter.enabled= #是否启用StatFilter默认值false
spring.datasource.druid.web-stat-filter.url-pattern=
spring.datasource.druid.web-stat-filter.exclusions=
spring.datasource.druid.web-stat-filter.session-stat-enable=
spring.datasource.druid.web-stat-filter.session-stat-max-count=
spring.datasource.druid.web-stat-filter.principal-session-name=
spring.datasource.druid.web-stat-filter.principal-cookie-name=
spring.datasource.druid.web-stat-filter.profile-enable=# StatViewServlet配置,说明请参考Druid Wiki,配置_StatViewServlet配置
spring.datasource.druid.stat-view-servlet.enabled= #是否启用StatViewServlet(监控页面)默认值为false(考虑到安全问题默认并未启动,如需启用建议设置密码或白名单以保障安全)
spring.datasource.druid.stat-view-servlet.url-pattern=
spring.datasource.druid.stat-view-servlet.reset-enable=
spring.datasource.druid.stat-view-servlet.login-username=
spring.datasource.druid.stat-view-servlet.login-password=
spring.datasource.druid.stat-view-servlet.allow=
spring.datasource.druid.stat-view-servlet.deny=# Spring监控配置,说明请参考Druid Github Wiki,配置_Druid和Spring关联监控配置
spring.datasource.druid.aop-patterns= # Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔
三、配置多数据源
1. 添加配置
spring.datasource.url=
spring.datasource.username=
spring.datasource.password=# Druid 数据源配置,继承spring.datasource.* 配置,相同则覆盖
...
spring.datasource.druid.initial-size=5
spring.datasource.druid.max-active=5
...# Druid 数据源 1 配置,继承spring.datasource.druid.* 配置,相同则覆盖
...
spring.datasource.druid.one.max-active=10
spring.datasource.druid.one.max-wait=10000
...# Druid 数据源 2 配置,继承spring.datasource.druid.* 配置,相同则覆盖
...
spring.datasource.druid.two.max-active=20
spring.datasource.druid.two.max-wait=20000
...
2. 创建数据源
@Primary
@Bean
@ConfigurationProperties("spring.datasource.druid.one")
public DataSource dataSourceOne(){return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.two")
public DataSource dataSourceTwo(){return DruidDataSourceBuilder.create().build();
}
四、配置 Filter
1. 配置Filter
你可以通过 spring.datasource.druid.filters=stat,wall,log4j … 的方式来启用相应的内置Filter,不过这些Filter都是默认配置。如果默认配置不能满足你的需求,你可以放弃这种方式,通过配置文件来配置Filter,下面是例子。
# 配置StatFilter
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.db-type=h2
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=2000# 配置WallFilter
spring.datasource.druid.filter.wall.enabled=true
spring.datasource.druid.filter.wall.db-type=h2
spring.datasource.druid.filter.wall.config.delete-allow=false
spring.datasource.druid.filter.wall.config.drop-table-allow=false# 其他 Filter 配置不再演示
2. 可配置的Filter
目前为以下 Filter 提供了配置支持,请参考文档或者根据IDE提示(spring.datasource.druid.filter.*)进行配置。
- StatFilter
- WallFilter
- ConfigFilter
- EncodingConvertFilter
- Slf4jLogFilter
- Log4jFilter
- Log4j2Filter
- CommonsLogFilter
要想使自定义 Filter 配置生效需要将对应 Filter 的 enabled 设置为 true ,Druid Spring Boot Starter 默认禁用 StatFilter,你也可以将其 enabled 设置为 true 来启用它。
五、获取 Druid 的监控数据
Druid 的监控数据可以在开启 StatFilter 后通过 DruidStatManagerFacade 进行获取,获取到监控数据之后你可以将其暴露给你的监控系统进行使用。Druid 默认的监控系统数据也来源于此。下面给做一个简单的演示,在 Spring Boot 中如何通过 HTTP 接口将 Druid 监控数据以 JSON 的形式暴露出去,实际使用中你可以根据你的需要自由地对监控数据、暴露方式进行扩展。
@RestController
public class DruidStatController {@GetMapping("/druid/stat")public Object druidStat(){// DruidStatManagerFacade#getDataSourceStatDataList 该方法可以获取所有数据源的监控数据,除此之外 DruidStatManagerFacade 还提供了一些其他方法,你可以按需选择使用。return DruidStatManagerFacade.getInstance().getDataSourceStatDataList();}
}
[{"Identity": 1583082378,"Name": "DataSource-1583082378","DbType": "h2","DriverClassName": "org.h2.Driver","URL": "jdbc:h2:file:./demo-db","UserName": "sa","FilterClassNames": ["com.alibaba.druid.filter.stat.StatFilter"],"WaitThreadCount": 0,"NotEmptyWaitCount": 0,"NotEmptyWaitMillis": 0,"PoolingCount": 2,"PoolingPeak": 2,"PoolingPeakTime": 1533782955104,"ActiveCount": 0,"ActivePeak": 1,"ActivePeakTime": 1533782955178,"InitialSize": 2,"MinIdle": 2,"MaxActive": 30,"QueryTimeout": 0,"TransactionQueryTimeout": 0,"LoginTimeout": 0,"ValidConnectionCheckerClassName": null,"ExceptionSorterClassName": null,"TestOnBorrow": true,"TestOnReturn": true,"TestWhileIdle": true,"DefaultAutoCommit": true,"DefaultReadOnly": null,"DefaultTransactionIsolation": null,"LogicConnectCount": 103,"LogicCloseCount": 103,"LogicConnectErrorCount": 0,"PhysicalConnectCount": 2,"PhysicalCloseCount": 0,"PhysicalConnectErrorCount": 0,"ExecuteCount": 102,"ErrorCount": 0,"CommitCount": 100,"RollbackCount": 0,"PSCacheAccessCount": 100,"PSCacheHitCount": 99,"PSCacheMissCount": 1,"StartTransactionCount": 100,"TransactionHistogram": [55,44,1,0,0,0,0],"ConnectionHoldTimeHistogram": [53,47,3,0,0,0,0,0],"RemoveAbandoned": false,"ClobOpenCount": 0,"BlobOpenCount": 0,"KeepAliveCheckCount": 0,"KeepAlive": false,"FailFast": false,"MaxWait": 1234,"MaxWaitThreadCount": -1,"PoolPreparedStatements": true,"MaxPoolPreparedStatementPerConnectionSize": 5,"MinEvictableIdleTimeMillis": 30001,"MaxEvictableIdleTimeMillis": 25200000,"LogDifferentThread": true,"RecycleErrorCount": 0,"PreparedStatementOpenCount": 1,"PreparedStatementClosedCount": 0,"UseUnfairLock": true,"InitGlobalVariants": false,"InitVariants": false}
]
六、案例
1. 问题

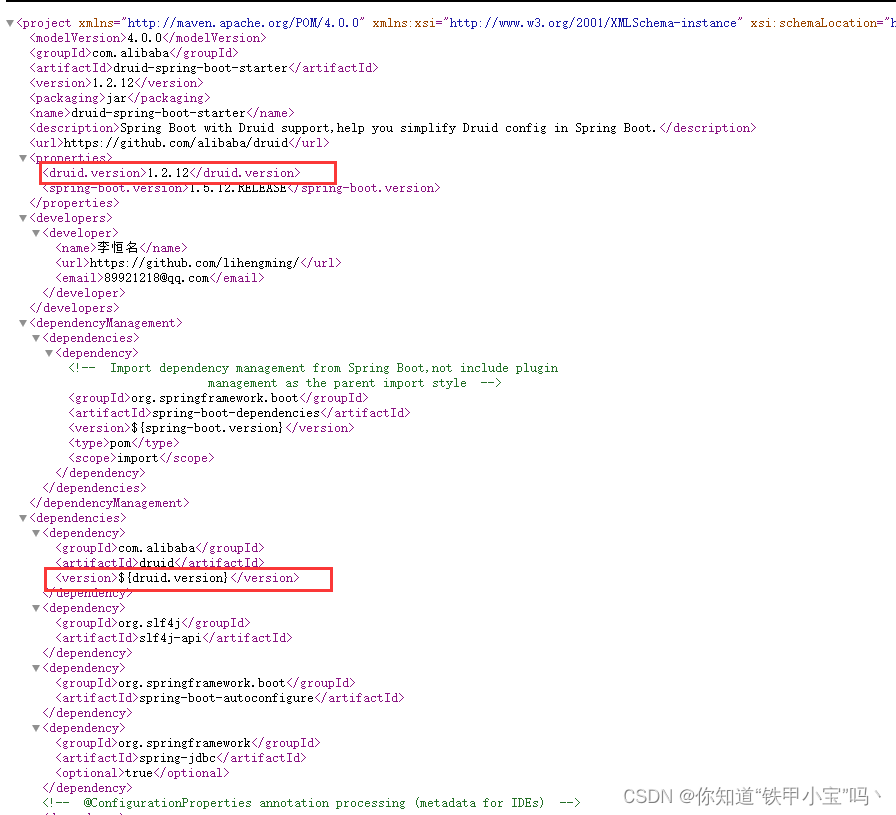
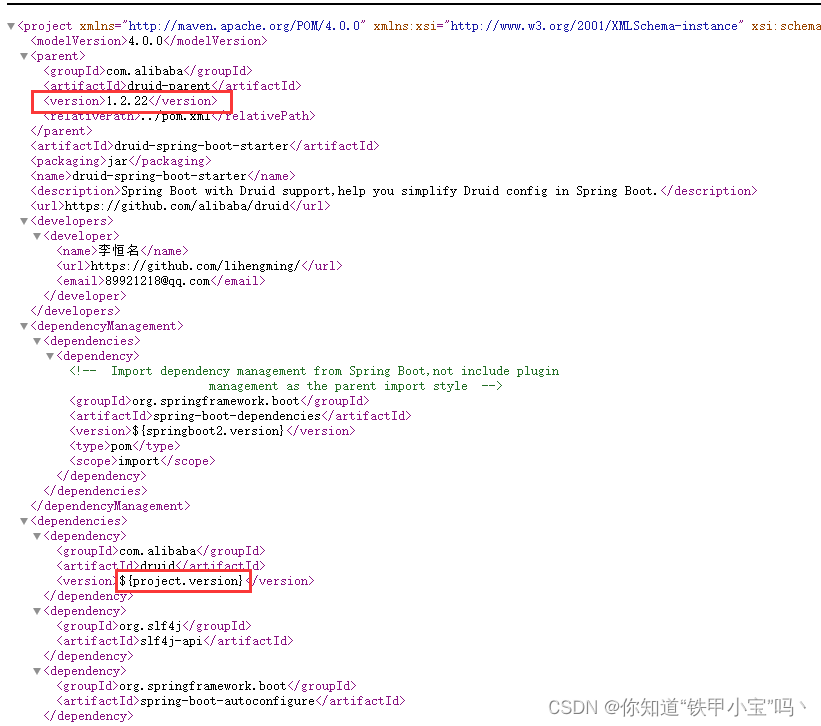
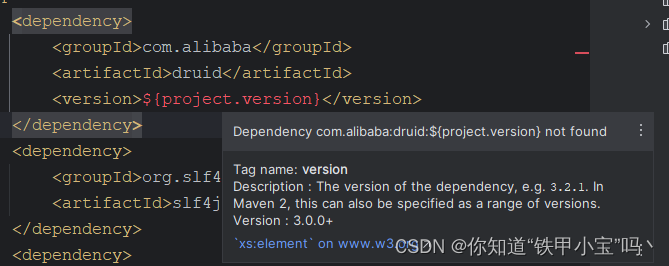
在
1.2.13快照版及之后的版本,都会去查找一个${project.version}的属性导致我druid的包一直没有下载下来,
就算切换到之前的版本自动注入也无法生效,SpringBoot3是已经确定的大版本,所以我们只能放弃对start的使用。
<parent><groupId>com.alibaba</groupId><artifactId>druid-parent</artifactId><version>1.2.23-SNAPSHOT</version><relativePath>../pom.xml</relativePath>
</parent>
<artifactId>druid-spring-boot-3-starter</artifactId>
也可能是版本问题,官方的下一个版本
1.2.23-SNAPSHOT,才能匹配springboot3版本。
2. 引入库
由于上面的问题,我们只能使用spring常规的使用方式,但是和mvc中可能会略有区别。
<properties><java.version>17</java.version><spring.version>6.1.6</spring.version><springboo.version>3.2.5</springboo.version>
</properties><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>${spring.version}</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.19</version>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.22</version>
</dependency>
3. 配置
spring:application:name: spring-boot3#druiddatasource:#type: com.alibaba.druid.pool.DruidDataSourcedruid:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=trueusername: rootpassword: 123456a?initial-size: 5max-active: 20max-wait: 60000min-idle: 3
4. 配置类
package org.example.springboot3.druid.config;import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;/*** Create by zjg on 2024/5/19*/
@Configuration
public class DruidConfig {@Bean@ConfigurationProperties("spring.datasource.druid")public DataSource dataSource(){return new DruidDataSource();}
}5. 测试类
package org.example.springboot3.druid.controller;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;/*** Create by zjg on 2024/5/19*/
@RestController
@RequestMapping("/druid/")
public class DruidController {@AutowiredDataSource dataSource;@RequestMapping("001")public String druid001() throws SQLException {Connection connection = dataSource.getConnection();Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery("select 1 from dual");String result = null;if(resultSet.next()){result=resultSet.getString(1);}statement.close();connection.close();return result;}
}6. 测试结果
1
单独使用最新的
1.2.22版本是没有问题的。
七、案例 ( 推荐 ) \color{#00FF00}{(推荐)} (推荐)
昨天写了这篇文章之后,感觉没有把最好的带给家人们,经过一晚上的不断阅读诸佬的经典,总算找到了druid对springboot支持的starter,可能是阿里的哥哥们太忙了,官方文档是一点介绍没有啊!
1. 引入库
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.19</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-3-starter -->
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-3-starter</artifactId><version>1.2.22</version>
</dependency>
2. 配置
spring:application:name: spring-boot3#druiddatasource:#type: com.alibaba.druid.pool.DruidDataSourcedruid:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=trueusername: rootpassword: 123456a?initial-size: 5max-active: 20max-wait: 60000min-idle: 3
3. 测试类
package org.example.springboot3.druid.controller;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;/*** Create by zjg on 2024/5/19*/
@RestController
@RequestMapping("/druid/")
public class DruidController {@AutowiredDataSource dataSource;@RequestMapping("001")public String druid001() throws SQLException {Connection connection = dataSource.getConnection();Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery("select 1 from dual");String result = null;if(resultSet.next()){result=resultSet.getString(1);}statement.close();connection.close();return result;}
}4. 测试结果
1
总结
回到顶部
源码仓库
中文文档
Druid Spring Boot Starter
更多内容请参考:
【第5章】spring命名空间和数据源的引入
【第21章】spring-mvc之整合druid
推荐大家使用starter的案例。
相关文章:
【第5章】SpringBoot整合Druid
文章目录 前言一、启动器二、配置1.JDBC 配置2.连接池配置3. 监控配置 三、配置多数据源1. 添加配置2. 创建数据源 四、配置 Filter1. 配置Filter2. 可配置的Filter 五、获取 Druid 的监控数据六、案例1. 问题2. 引入库3. 配置4. 配置类5. 测试类6. 测试结果 七、案例 ( 推荐 )…...
力扣654. 最大二叉树
Problem: 654. 最大二叉树 文章目录 题目描述思路复杂度Code 题目描述 思路 对于构造二叉树这类问题一般都是利用先、中、后序遍历,再将原始问题分解得出结果 1.定义递归函数build,每次将一个数组中的最大值作为当前子树的根节点构造二叉树;…...

基于Netty实现WebSocket客户端
本文是基于Netty快速上手WebSocket客户端,不涉及WebSocket的TLS/SSL加密传输。 WebSocket原理参考【WebSocket简介-CSDN博客】,测试用的WebSocket服务端也是用Netty实现的,参考【基于Netty实现WebSocket服务端-CSDN博客】 一、基于Netty快速…...

homebrew安装mysql的一些问题
本文目录 一、Homebrew镜像安装二、mac安装mysql2.1、修改mysql密码 本文基于mac环境下进行的安装 一、Homebrew镜像安装 Homebrew国内如何自动安装,运行命令/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 会…...

产线问题排查
CPU过高 使用top命令查看占用CPU过高的进程。 导出CPU占用高进程的线程栈。 jstack pid >> java.txt Java 内存过高的问题排查 1.分析OOM异常的原因,堆溢出?栈溢出?本地内存溢出? 2.如果是堆溢出,导出堆dump&…...
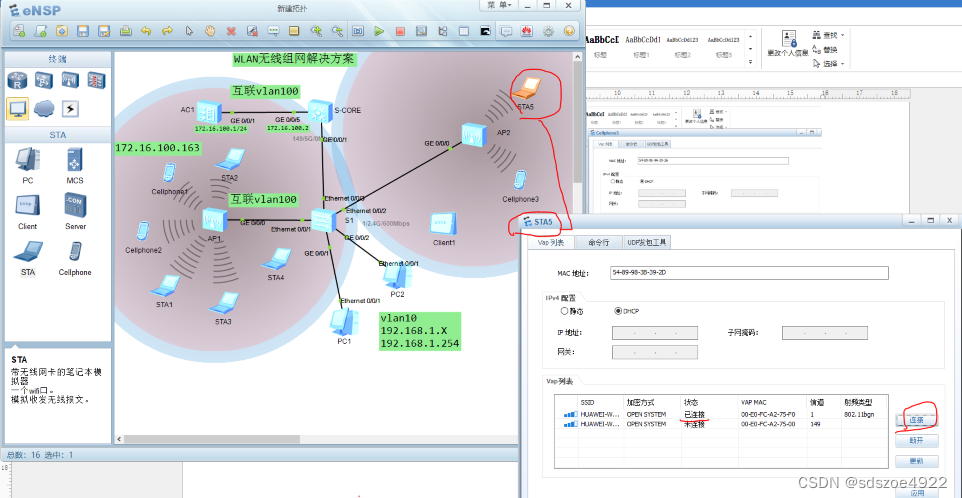
华为WLAN实验继续-2,多个AP如何部署
----------------------------------------如果添加新的AP,如何实现多AP的服务----------- 新增加一个AP2启动之后发现无法获得IP地址 在AP2上查看其MAC地址,并与将其加入到AC中去 打开AC,将AP2的MAC加入到AC中 sys Enter system view, re…...
——流程)
手把手教你写Java项目(1)——流程
个人练手项目的一般流程: 个人练手项目的流程通常相对简单和灵活,但仍然遵循一定的步骤来确保项目的顺利进行。流程相对较为详细,不是所有流程都要实现,一些仅供参考。主要是让大家对项目有初步的了解,不至于无法入手…...

微信小程序post请求
一、普通请求 wx.request({url: http://43.143.124.247:8282/sendEmail,method: POST,data: {user: that.data.currarr[0][that.data.mulu[0]] that.data.currarr[1][that.data.mulu[1]] that.data.sushe,pwd: 3101435196qq.com},header: {Content-Type: application/x-www-…...
)
frm一级4个1大神复习经验分享系列(二)
先说一下自己的情况,8月份中旬开始备考,中间一直是跟着网课走,notes和官方书都没看,然后10月份下旬开始刷题一直到考试。下面分享一些自己备考的经验和走过的弯路。 一级 一级整体学习下来的感受是偏重于基础的理论知识。FRM一级侧…...

理解磁盘分区与管理:U启、PE、DiskGenius、MBR与GUID
目录 U启和PE的区别: U启(U盘启动): PE(预安装环境): 在DiskGenius中分区完成之后是否还需要格式化: 1.建立文件系统: 2.清除数据: 3.检查并修复分区: 分区表格式中,MBR和GUID的区别: 1…...
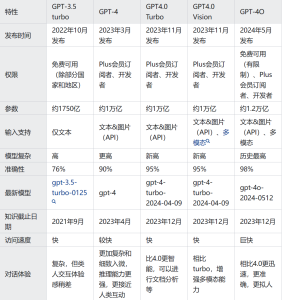
GPT-4o和GPT-4有什么区别?我们还需要付费开通GPT-4?
GPT-4o 是 OpenAI 最新推出的大模型,有它的独特之处。那么GPT-4o 与 GPT-4 之间的主要区别具体有哪些呢?今天我们就来聊聊这个问题。 目前来看,主要是下面几个差异。 响应速度 GPT-4o 的一个显著优势是其处理速度。它能够更快地回应用户的查…...
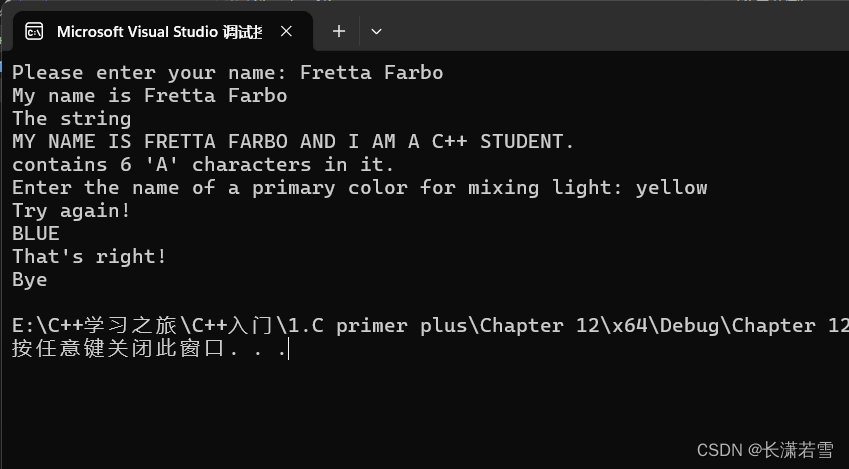
《C++ Primer Plus》第十二章复习题和编程练习
目录 一、复习题二、编程练习 一、复习题 1. 假设String类有如下私有成员: // String 类声明 class String { private: char* str;int len;// ... };a. 下述默认构造函数有什么问题? String::String() { } // 默认构造函数b. 下述构造函数有什么问题…...

2024 年科技裁员综合清单
推荐阅读: 独立国家的共同财富 美国千禧一代的收入低于父辈 创造大量就业机会却毁掉了财富 这四件事是创造国家财富的关键 全球财富报告证实联盟自始至终无能 美国人已陷入无休止债务循环中,这正在耗尽他们的财务生命 2024 年,科技行业…...
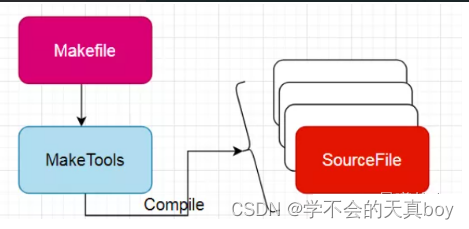
Linux系统编程学习笔记
1 前言 1.1 环境 平台:uabntu20.04 工具:vim,gcc,make 1.2 GCC Linux系统下的GCC(GNU Compiler Collection)是GNU推出的功能强大、性能优越的多平台编译器,是GNU的代表作品之一。gcc是可以在多种硬体平台上编译出可执…...

vue3 excel 文件导出
//文件导出 在index.ts 中 export function downloadHandle(url: string,params?:object, filename?: string, method: string GET){ try { downloadLoadingInstance ElLoading.service({ text: "正在生成下载数据,请稍候", background: "rgba…...

优雅的代码规范
在软件开发中,优雅的代码规范可以帮助我们写出既美观又实用的代码。 以下是提升代码质量的建议性规范: 命名清晰: 使用描述性强的命名,让代码自我解释。 简洁性: 力求简洁,避免冗余,用最少的代…...

JVM、JRE 和 JDK 的区别,及如何解决学习中可能会遇到的问题
在学习Java编程的过程中,理解JVM、JRE和JDK之间的区别是非常重要的。它们是Java开发和运行环境的核心组件,各自扮演不同的角色。 一、JVM(Java Virtual Machine) 定义 JVM(Java虚拟机)是一个虚拟化的计算…...
【开源】加油站管理系统 JAVA+Vue.js+SpringBoot+MySQL
目录 一、项目介绍 论坛模块 加油站模块 汽油模块 二、项目截图 三、核心代码 一、项目介绍 Vue.jsSpringBoot前后端分离新手入门项目《加油站管理系统》,包括论坛模块、加油站模块、汽油模块、加油模块和部门角色菜单模块,项目编号T003。 【开源…...

详解 Scala 的泛型
一、协变与逆变 1. 说明 协变:Son 是 Father 的子类,则 MyList[Son] 也作为 MyList[Father] 的 “子类”逆变:Son 是 Father 的子类,则 MyList[Son] 作为 MyList[Father] 的 “父类”不变:Son 是 Father 的子类&…...

【本周面试问题总结】
01.如何判断链表中是否有环 ①穷举遍历:从头节点开始,依次遍历单链表中的每一个节点。每遍历到一个新节点,将新节点和此前节点进行比较,若已经存在则说明已被遍历过,链表有环。 ②快慢指针:创建两个指针&am…...
)
市面上有哪些是真正高效的降AI率软件(规避AIGC机器检测)
最崩溃的不是查重难题,而是查重达标却AI率超标亮红灯;很多工具只会简单同义词替换、浅层改字,根本洗不掉AI专属句式、行文逻辑和高频模板话术,学校AIGC检测一查一个准,论文直接被标记为AI生成,想答辩都难。…...

硬件选型干货|钡特电源DQ1-15D1709S与金升阳QA01-17属工业标准模块电源,避坑指南
在工业电子硬件研发中,工业DC-DC模块是板级隔离供电的核心器件,其标准化封装、性能稳定性及国产化水平,直接影响研发效率、系统可靠性与供应链安全。钡特电源DQ1-15D1709S与金升阳QA01-17作为国产直流电源模块领域的代表性型号,均…...

ReTerraForged终极指南:5步掌握Minecraft高级地形生成技术
ReTerraForged终极指南:5步掌握Minecraft高级地形生成技术 【免费下载链接】ReTerraForged TerraForged for modern MC versions 项目地址: https://gitcode.com/gh_mirrors/re/ReTerraForged ReTerraForged是一款专为现代Minecraft版本设计的革命性地形生成…...

大模型转型AI工程师:小白必看学习路线,收藏这份成功秘籍!
本文作者分享了自己从零基础成功转型AI工程师的经历,强调学AI无需死磕算法和公式,关键在于掌握Python搭建AI智能体和Java项目迭代能力。文章提供三个月的学习路线,包括Python基础、Prompt技巧、RAG技术、知识库搭建、Agent搭建等,…...

写论文用什么软件?精选7款AI论文生成工具深度测评,AI率精准控制无压力!
论文写作的痛点,AI工具来化解! 面对开题报告、文献综述到正文撰写的全流程压力,选对AI论文写作工具能让效率提升数倍。本文将基于真实体验,为你深度测评7款主流工具,帮你找到最适合的学术助手。 测评围绕四大核心维度…...
)
不止于配置:用Qt给周立功CAN卡写个简易数据收发测试工具(附源码)
从零构建Qt版CAN数据收发测试工具:周立功硬件实战指南 在嵌入式开发领域,CAN总线调试是工程师日常工作中的高频需求。当我们需要验证硬件连接是否正常、测试通信质量或快速检查数据流时,一个轻量级的图形化测试工具能极大提升工作效率。本文将…...

KMS_VL_ALL_AIO:Windows和Office永久激活终极指南
KMS_VL_ALL_AIO:Windows和Office永久激活终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office软件授权问题烦恼吗?KMS_VL_ALL_AIO是一…...

Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节
Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节 当工业自动化遇上Python,pylogix库成为了连接AB PLC与Python世界的桥梁。但在处理数组、字符串和用户自定义数据类型(UDT)时,即便是经验丰富的开发…...
上搞定WireGuard编译:一个内核版本不匹配的实战修复记录)
在国产飞腾ARM平台(银河麒麟V10)上搞定WireGuard编译:一个内核版本不匹配的实战修复记录
在国产飞腾ARM平台(银河麒麟V10)上搞定WireGuard编译:内核兼容性深度解析与实战 国产化替代浪潮下,越来越多的企业和机构开始将关键业务迁移到国产操作系统和硬件平台。银河麒麟V10作为国产操作系统的代表之一,搭配飞…...

STM32G474的HRTIM驱动DAC:你的锯齿波‘毛刺’和失真,可能是这两个寄存器配置反了
STM32G474的HRTIM驱动DAC:锯齿波失真问题深度解析与优化方案 在精密模拟电路设计中,STM32G474系列微控制器凭借其高性能HRTIM(高分辨率定时器)和DAC(数模转换器)的组合,成为生成高精度波形的重要…...