【软考】下篇 第19章 大数据架构设计理论与实践
目录
- 大数据处理系统架构特征
- Lambda架构
- Lambda架构介绍
- Lambda架构实现
- Lambda架构优缺点
- Lambda架构与其他架构模式对比
- Kappa架构
- Kappa架构介绍
- Kappa架构实现
- Kappa架构优缺点
- 常见Kappa架构变形(Kappa+、混合分析系统)
- Kappa+架构
- 混合分析系统的Kappa架构
- Lambda与Kappa架构对比
- Lambda与Kappa架构选型
- 案例分析
- 术语
大数据处理系统架构特征
鲁棒性和容错性
低延迟读取和更新能力
横向扩容
通用性
延展性
即席查询能力
最少维护能力
可调试性
Lambda架构
Lambda架构由 Storm 的作者 Nathan Marz提出,
其设计目的在于提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等。
其整合 离线计算 与 实时计算,融合不可变性、读写分离和复杂性隔离等原则,
可集成 Hadoop、Kafka、Spark、Storm等各类大数据组件。
Lambda 是用于同时处理 离线 和 实时数据的,可容错的,可扩展的分布式系统。
它具备强鲁棒性,提供低延迟和持续更新。
Lambda架构介绍
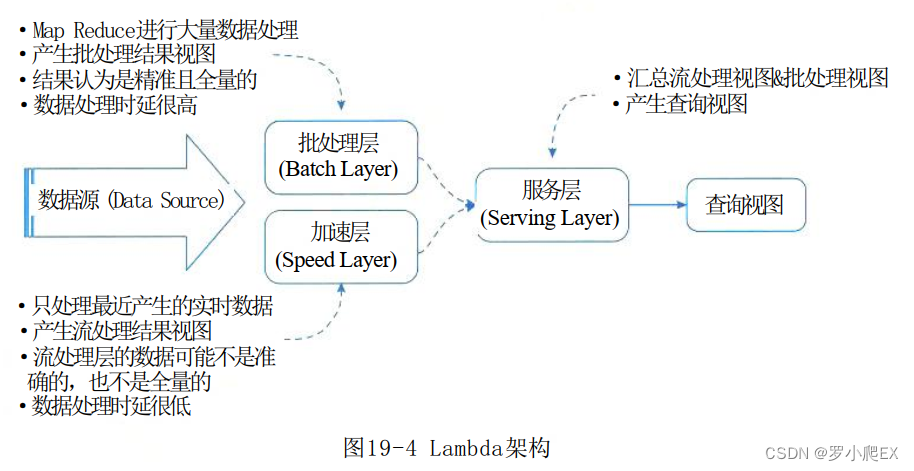
- (1) 批处理层 (Batch Layer): 存储数据集, Batch Layer在数据集上预先计算查询函数,并构建查询所对应的 View。Batch Layer可以很好地处理离线数据,但有很多场景数据是不断实时生成且需要实时查询处理,对于这种情况, Speed Layer更为适合。
- (2) 加速层 (Speed Layer): Batch Layer处理的是全体数据集,而 Speed Layer处理的是最近的增量数据流。 Speed Layer 为了效率,在接收到新的数据后会不断更新 Real-time View, 而Batch Layer 是根据全体离线数据集直接得到 Batch View。
- (3) 服务层 (Serving Layer): Serving Layer 用于合并Batch View 和 Real-time View中的结果数据集到最终数据集。
Lambda架构实现
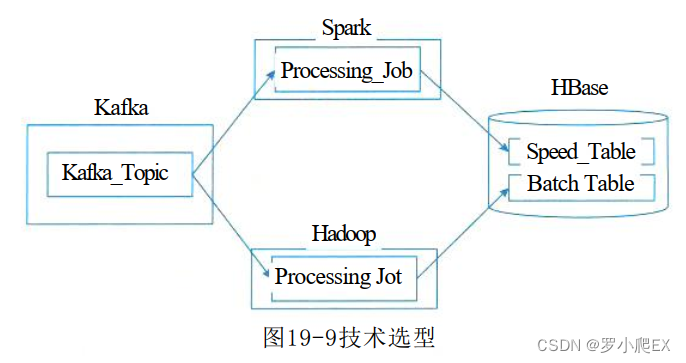
在这种Lambda架构实现中,
Hadoop (HDFS) 用于存储主数据集,
Spark(或Storm) 可构成速度层 (Speed Layer),
HBase ( 或 Cassandra) 作为服务层,由Hive创建可查询的视图。
Lambda架构优缺点
优点
- (1) 容错性好。 Lambda 架构为大数据系统提供了更友好的容错能力,一旦发生错误,我们可以修复算法或从头开始重新计算视图。
- (2) 查询灵活度高。批处理层允许针对任何数据进行临时查询。
- (3) 易伸缩。所有的批处理层、加速层和服务层都很容易扩展。因为它们都是完全分布式的系统,我们可以通过增加新机器来轻松地扩大规模。
- (4) 易扩展。添加视图是容易的,只是给主数据集添加几个新的函数。
缺点
- (1) 全场景覆盖带来的编码开销。
- (2) 针对具体场景重新离线训练一遍益处不大。
- (3) 重新部署和迁移成本很高。
Lambda架构与其他架构模式对比
- 事件溯源 - 数据集的存储:存储所有数据,支持根据历史数据 重新计算 恢复正确状态(容错性)
- CQRS - 读写分离,通过流、批处理进行写,通过view进行读
Kappa架构
数据系统=数据+查询
数据的特性:When(时间点)、What(不可变、CRUD变成CR添加和读取)
数据的存储:数据不可变、存储所有数据
Kappa架构介绍
Kappa架构由 Jay Kreps提出,不同于Lambda 同时计算流计算和批计算并合并视图,
Kappa只会通过 流计算 一条的数据链路计算并产生视图。
Kappa 同样采用了重新处理事件的原则,对于历史数据分析类的需求, Kappa要求数据的长期存储能够以有序日志流的方式重新流入流计算引擎,重新产生历史数据的视图。
本质上是通过改进 Lambda架构中的 Speed Layer, 使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据。
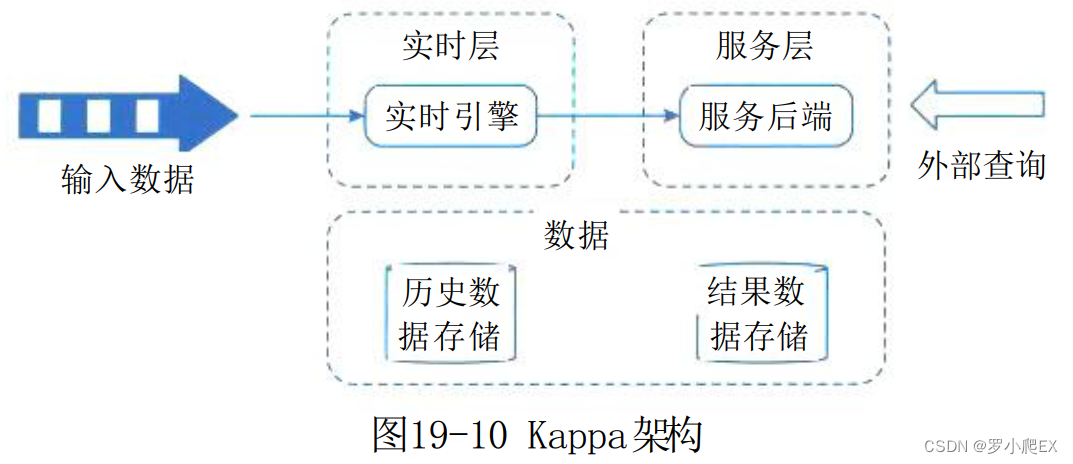
Kappa架构实现
Kappa架构优缺点
优点
- 在于将实时和离线代码 统一 起来,方便维护而且统一了数据口径的问题,
- 避免了 Lambda架构中与离线 数据合并 的问题,查询历史数据的时候只需要重放存储的历史数据即可。
缺点
- (1) 消息中间件缓存的数据量和回溯数据有性能瓶颈。通常算法需要过去180天的数据,如果都存在消息中间件,无疑有非常大的压力。同时,一次性回溯订正180天级别的数据,对实时计算的资源消耗也非常大。
- (2) 在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
- (3) Kappa 在抛弃了离线数据处理模块的时候,同时抛弃了离线计算更加稳定可靠的特点。Lambda 虽然保证了离线计算的稳定性,但双系统的维护成本高且两套代码带来后期运维困难。
对于以上Kappa框架存在的几个问题,目前也存在一些解决方案,
- 对于消息队列缓存数据性能的问题, Kappa+框架 提出使用HDFS来存储中间数据。
- 针对 Kappa 框架展示层能力不足的问题,也有人提出了 混合分析系统 的解决方案。
常见Kappa架构变形(Kappa+、混合分析系统)
Kappa+架构
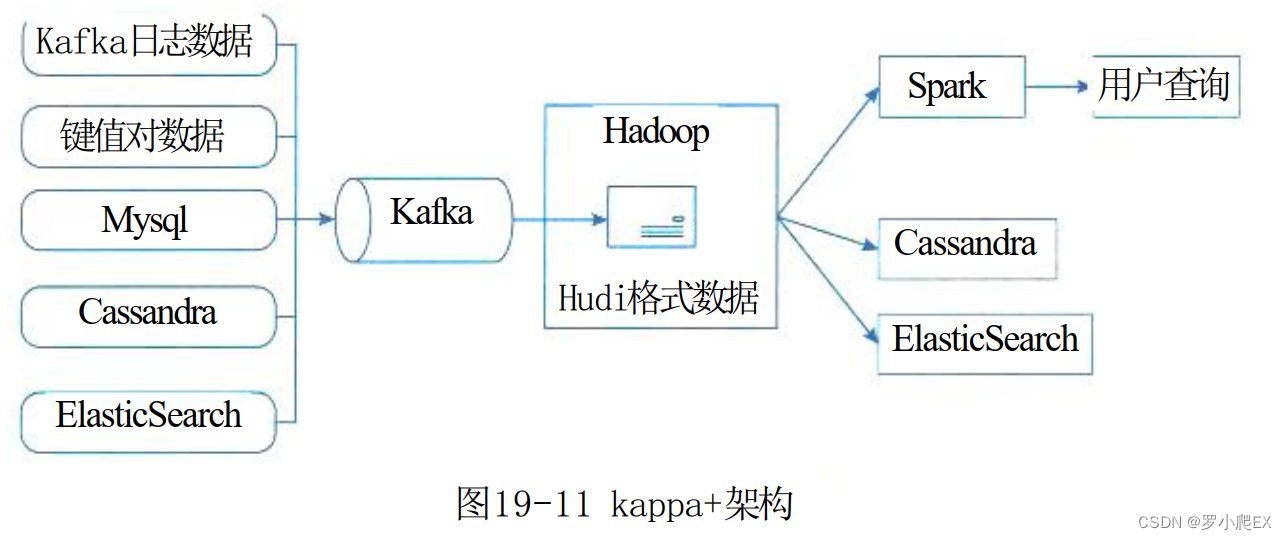
Kappa+是 Uber提出流式数据处理架构,
它的核心思想是让流计算框架 直接读 HDFS里的数据仓库数据,
一并实现实时计算和历史数据 backfll 计算,不需要为 backfll 作业长期保存日志或者把数据拷贝回消息队列。
Kappa+ 将数据任务分为 无状态任务和 时间窗口任务。
Uber开发了 Apache hudi 框架 来存储数据仓库数据,
hudi 支持更新、删除已有parquet数据,
也支持增量消费数据更新部分,
从而系统性解决了问题2存储的问题。
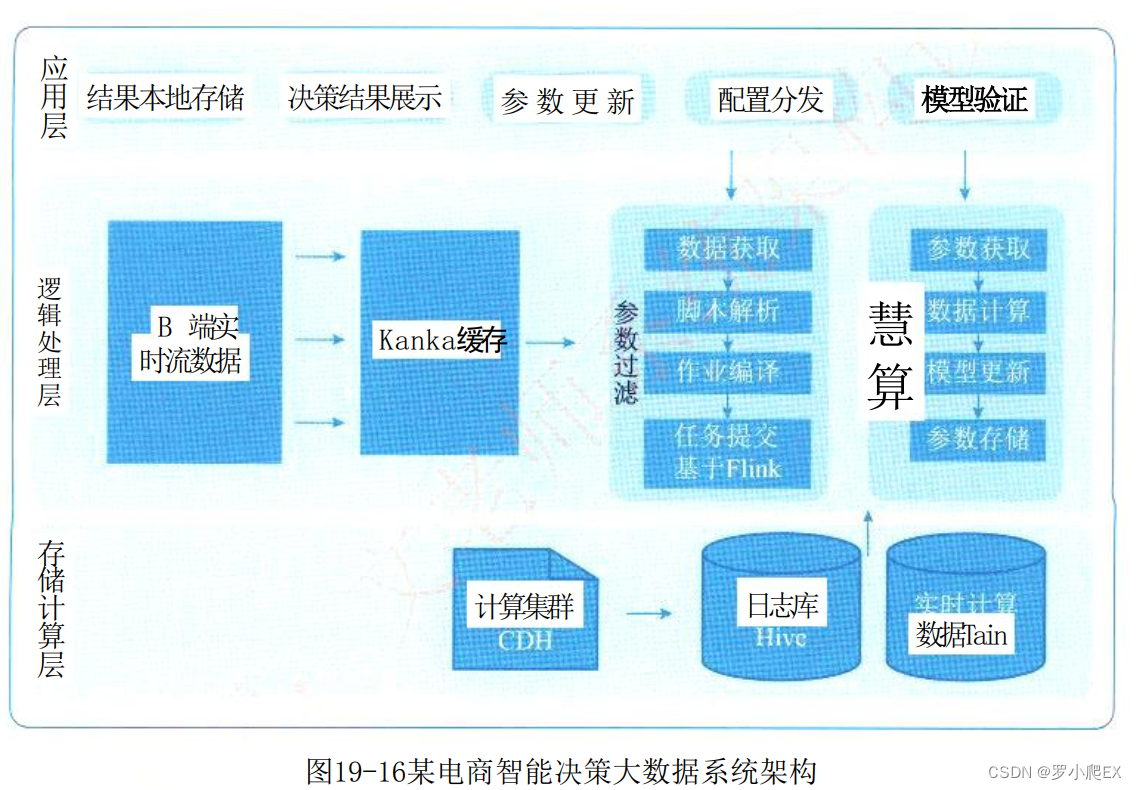
图19-11是完整的Uber大数据处理平台,其中Hadoop→ Spark →用户查询 的流程涵盖了Kappa+数据处理架构。
将不同来源的数据通过 Kafka 导入到Hadoop 中,
通过HDFS来存储中间数据,
再通过 spark对数据进行分析处理,
最后交由上层业务进行查询。
混合分析系统的Kappa架构
Lambda和 Kappa架构都还有展示层的困难点,结果视图如何支持热点数据查询分析,
一个解决方案是在 Kappa基础上衍生数据分析流程。
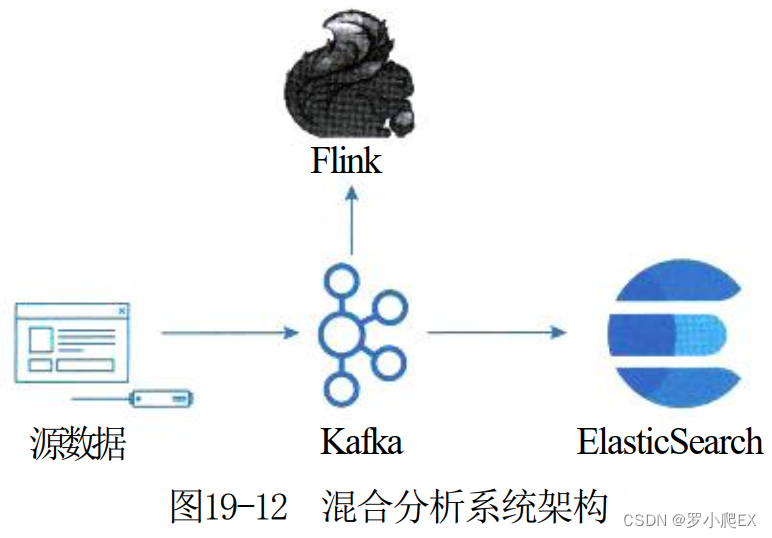
如图19-12所示,在基于使用 Kafka +Flink 构 建 Kappa 流计算数据架构, 针对Kappa架构分析能力不足的问题,
再利用 Kafka对接组合 Elastic-Search 实时分析引擎,部分弥补其数据分析能力。
但是 ElasticSearch 也只适合对合理数源数量级的热点数据进行索引,无法覆盖所有批处理相关的分析需求,
这种混合架构某种意义上属于 Kappa和 Lambda间的折中方案。
Lambda与Kappa架构对比

Lambda架构
- 批处理:Hadoop -> Hbase
- 流处理:Spark、Storm -> Redis
Kappa架构
- Kafka作为消息中间件,将数据保持在消息队列中
- 流式计算:Flink,其作为新兴的流处理框架,以数据并行和流水线方式执行任意流数据程序,且同时支持批处理和流处理。
| Spark | Flink |
|---|---|
| 微批处理 | 流处理(无界流) |
| 批处理 | 有界流 |
Lambda与Kappa架构选型
| 考虑因素 | 详细说明 |
|---|---|
| 业务需求 与 技术需求 | - 用户需要根据自己的业务需求来选择架构, - 如果业务对于 Hadoop、Spark、Strom 等关键技术有强制性依赖,选择 Lambda 架构可能较为合适; - 如果处理数据偏好于流式计算,又依赖Flink 计算引擎,那么选择 Kappa架构可能更为合适。 |
| 复杂度 | - 频繁修改, Lambda 架构需要反复修改两套代码,则显然不如 Kappa架构简单方便。 - 同时支持批处理和流式计算,或者希望用一份代码进行数据处理,那么可以选择Kappa 架构。 - 实时处理和离线处理的结果不能统一,比如某些机器学习的预测模型,需要先通过离线批处理得到训练模型,再交由实时流式处理进行验证测试,那么这种情况下,批处理层和流处理层不能进行合并,因此应该选择Lambda架构。 |
| 开发维护成本 | - Lambda架构需要有一定程度的开发维护成本,包括两套系统的开发、部署、测试、维护,适合有足够经济、技术和人力资源的开发者。 - 而Kappa 架构只需要维护一套系统,适合不希望在开发维护上投入过多成本的开发者。 |
| 历史数据处理能力 | - 频繁接触海量数据集进行分析,比如过往十年内的地区降水数据等,这种数据适合批处理系统进行分析,应该选择Lambda架构。 - 如果始终使用小规模数据集,流处理系统完全可以使用,则应该选择 Kappa架构。 |
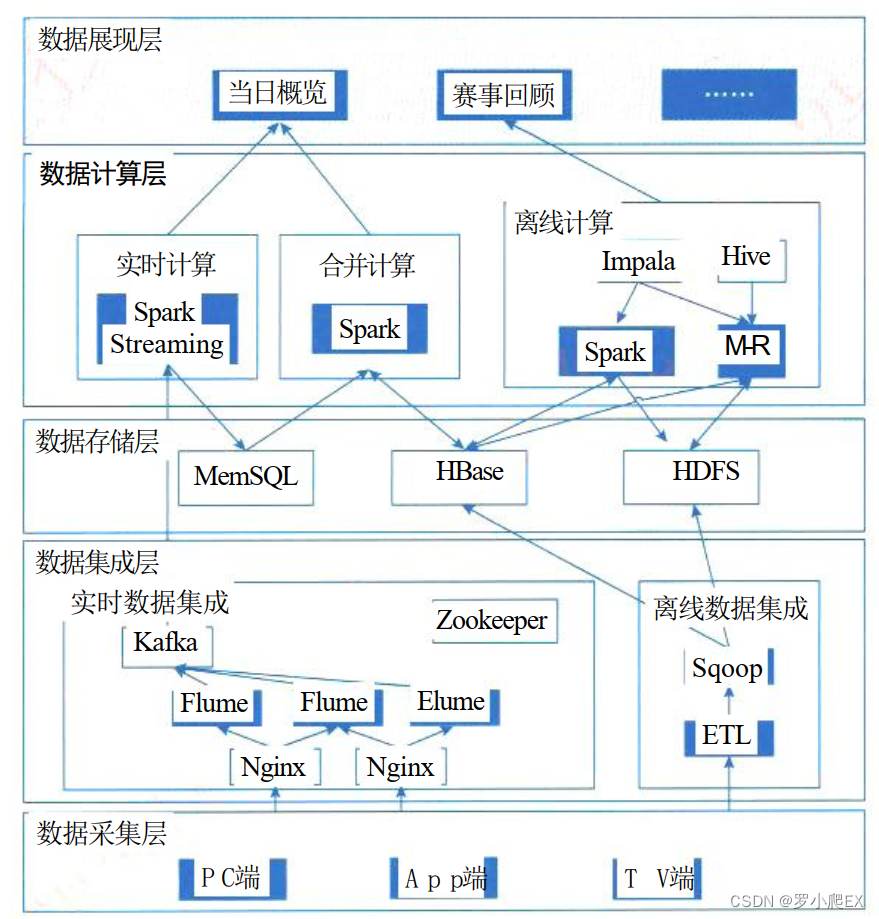
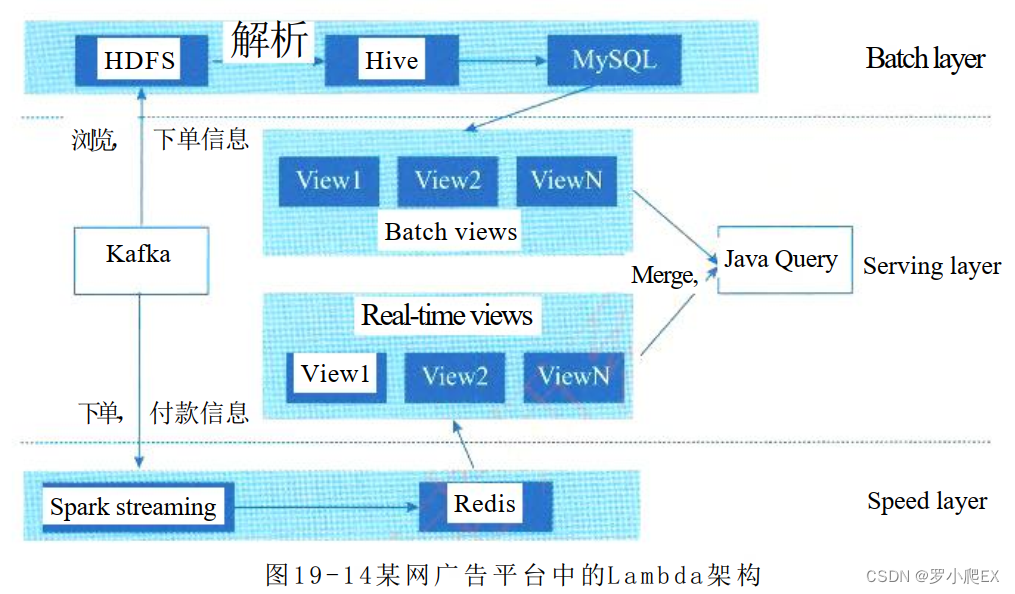
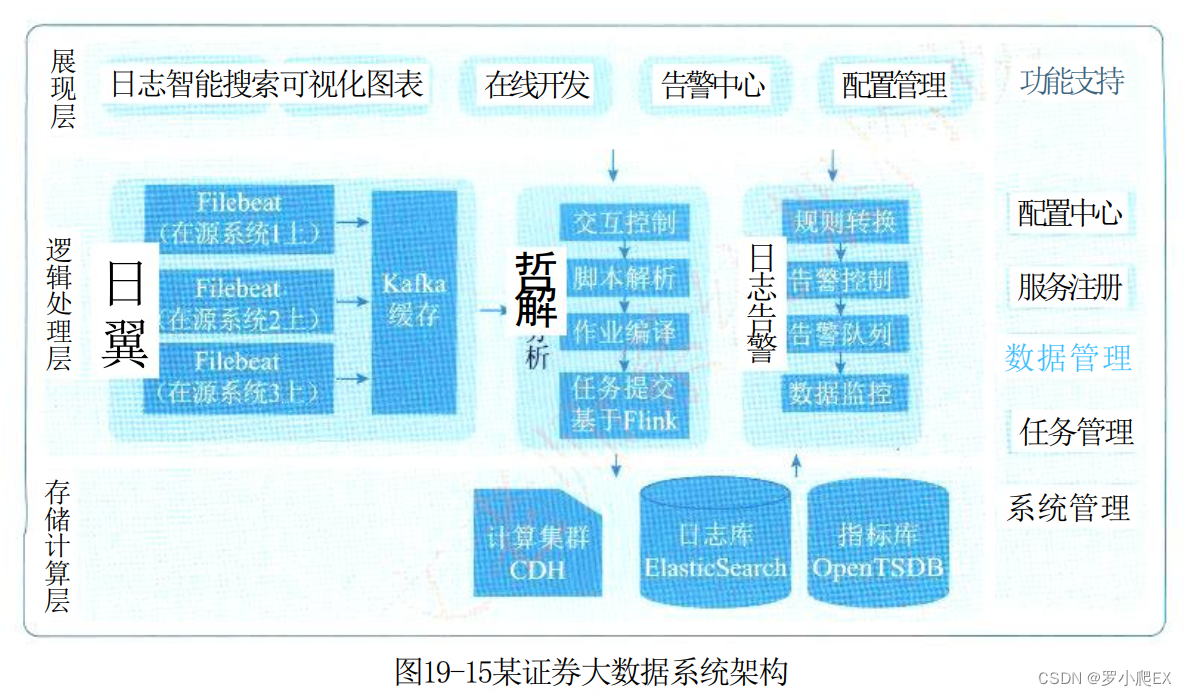
案例分析
术语
即席查询(Ad Hoc)
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
AD-HOC :以单独的SQL语句的形式执行的查询就是即席查询,比如说:在C#程序里嵌入的SQL语句,或者在SSMS里的新建查询窗口自己键入的SQL代码就是即席查询。
而将SQL代码放入存储过程里面,以存储过程或者函数或者触发器来执行的查询就不是即席查询,即席:当场,就是当场去查询。
即席查询是指那些用户在使用系统时,根据自己当时的需求定义的查询。即席查询生成的方式很多,最常见的就是使用即席查询工具。一般的数据展现工具都会提供即席查询的功能。通常的方式是,将数据仓库中的维度表和事实表映射到语义层,用户可以通过语义层选择表,建立表间的关联,最终生成SQL语句。即席查询与通常查询从SQL语句上来说,并没有本质的差别。它们之间的差别在于,通常的查询在系统设计和实施时是已知的,所有我们可以在系统实施时通过建立索引、分区等技术来优化这些查询,使这些查询的效率很高。而即席查询是用户在使用时临时生产的,是一种松散类型的命令/查询,其值取决于某个变量,每次执行命令时,结果都不同,这取决于变量的值。它不能预先确定,通常属于动态编程SQL查询。临时查询是短期的,并且是在运行时创建的。系统无法预先优化这些查询,所以即席查询也是评估数据仓库的一个重要指标。
即席查询的位置通常是在关系型的数据仓库中,即在EDW或者ROLAP中。多维数据库有自己的存储方式,对即席查询和通常查询没有区别。在一个数据仓库系统中,即席查询使用的越多,对数据仓库的要求就越高,对数据模型的对称性的要求也越高。对称性的数据模型对所有的查询都是相同的,这也是维度建模的一个优点。
资料来源:
Ad Hoc Query https://www.techopedia.com/definition/30581/ad-hoc-query-sql-programming
What is an Ad Hoc Query? https://www.wisegeek.com/what-is-an-ad-hoc-query.htm
相关文章:
【软考】下篇 第19章 大数据架构设计理论与实践
目录 大数据处理系统架构特征Lambda架构Lambda架构介绍Lambda架构实现Lambda架构优缺点Lambda架构与其他架构模式对比 Kappa架构Kappa架构介绍Kappa架构实现Kappa架构优缺点 常见Kappa架构变形(Kappa、混合分析系统)Kappa架构混合分析系统的Kappa架构 La…...
创新指南|降低 TikTok CPA 的 9 项专家策略
企业在 TikTok 上投放广告,往往最想确保获得最佳的投资回报。然而,这往往说起来容易做起来难。您需要了解如何利用不同的营销工具、定位策略和创意执行来实现您的业务目标并提高成本效率。本文将分享 9 个行之有效的策略,助您有效降低 TikTok…...
jmeter服务器性能监控分析工具ServerAgent教程
ServerAgent介绍:支持监控CPU,memory,磁盘,网络等,和JMeter集成,在JMeter的图形界面中,可以实时看到监控的数据,但是,它只能监控硬件资源使用情况。 不能监控应用服务 S…...
工作纪实50-Idea下载项目乱码
下载了公司的一份项目代码,发现是gbk格式的,但是我的日常习惯又是utf-8,下载项目以后全是乱码,一脸懵 借用网友的一张图,如果是一个一个文件这么搞,真的是费劲,好几百个文件! 步骤…...

37. 解数独 - 力扣(LeetCode)
基础知识要求: Java: 方法、for循环、if else语句、数组 Python: 方法、for循环、if else语句、列表 题目: 编写一个程序,通过填充空格来解决数独问题。 数独的解法需 遵循如下规则: 数字 1-9 在每一行…...

使用uniapp编写的微信小程序进行分包
简介: 由于小程序发布的时候每个包最多只能放置2MB的东西,所以把所有的代码资源都放置在一个主包当中不显示,所以就需要进行合理分包,,但是分包后整个小程序最终不能超过20MB。 一般情况下,我习惯将tabba…...

设计模式19——观察者模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 观察者模式(Observ…...

C++算术运算和自增自减运算
一 引言 表示运算的符号称为运算符。 算术运算; 比较运算; 逻辑运算; 位运算; 1 算术运算 算术运算包括加、减、乘、除、乘方、指数、对数、三角函数、求余函数,这些都是算术运算。 C中用、-、*、/、%分别表示加、减…...
Python深度学习:【模型系列】一文搞懂Transformer架构的三种注意力机制
文章目录 1. 什么是注意力机制?2. Transformer 的注意力层2.1 注意力机制基础2.2 理解Q,K,V2.3 交叉注意力层2.4 全局自注意力层2.5 因果注意力层3. 位置编码4. 多头注意力机制5. 总结1. 什么是注意力机制? 注意力机制最初受到人类视觉注意力的启发,目的是让模型在处理大…...

微服务架构中Java的应用
在微服务架构中,Java是一种非常常用的编程语言。Java生态系统非常庞大,有许多框架和工具可以用来构建和管理微服务。 以下是一些在微服务架构中使用Java编写的应用程序的示例: Spring Boot和Spring Cloud:Spring Boot是一种用于快…...

【强训笔记】day25
NO.1 思路:哈希质数判断。 代码实现: #include <iostream> #include<string> #include<cmath> using namespace std;bool isprime(int n) {if(n<2) return false;for(int i2;i<sqrt(n);i){if(n%i0) return false;}return true…...

知识产权与标准化
知识产权与标准化 导航 文章目录 知识产权与标准化导航一、知识产权概述二、保护范围与对象三、保护期限四、知识产权归属五、侵权判定六、标准的分类 一、知识产权概述 知识产权:知识产权是指人们就其智力劳动成果所依法享有的专有权利,通常是国家赋予创造者对其…...

【LeetCode:2769. 找出最大的可达成数字 + 模拟】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
编程5年的老哥说:我代码里从来不用锁,谁爱...
技多不压身! 大家好,我是 javapub。 今天一个朋友找我吐槽,说自己平时在工作中几乎用不到需要上锁的场景,就算有也只是并发很小、或者直接从有业务设计上就规避掉了。但一到面试,都是各种锁题,很头疼。 面…...
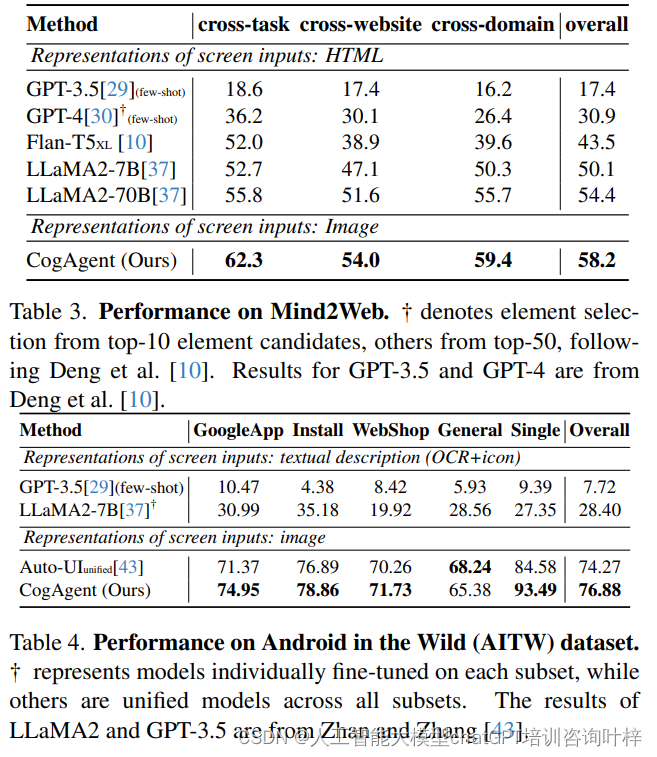
CogAgent:开创性的VLM在GUI理解和自动化任务中的突破
尽管LLMs如ChatGPT在撰写电子邮件等任务上能够提供帮助,它们在理解和与GUIs交互方面存在挑战,这限制了它们在提高自动化水平方面的潜力。数字世界中的自主代理是许多现代人梦寐以求的理想助手。这些代理能够根据用户输入的任务描述自动完成如在线预订票务…...

C++容器之位集(std::bitset)
目录 1 概述2 使用实例3 接口使用3.1 constructor3.2 count_and_size3.3 test3.4 any3.5 none3.6 all3.7 set3.8 reset3.9 filp3.10 to_string3.11 to_ulong3.12 to_ullong3.13 operators1 概述 位集存储位(只有两个可能值的元素:0或1,true或false,…)。 该类模拟bool…...

《Ai学习笔记》自然语言处理 (Natural Language Processing):常见机器阅读理解模型(上)02
Glove 词向量: 在机器理解中的词的表示: 词袋(bow,bag of words) one-hot 词向量 word2vec glove 目的:将一个词转换成一个向量 Word2vec 是一种用于生成词向量的工具包,由Google在2013年开源推出…...

老师如何在线发布期末考试成绩查询?
在这个数字化时代,教育领域也迎来了翻天覆地的变化。传统的纸质成绩查询方式已经逐渐被在线成绩查询所替代。如何高效、便捷地进行在线期末考试成绩查询? 成绩的录入与上传。教师需要将学生的考试成绩准确无误地录入系统。这一步骤需要细心和耐心&#x…...

TensorBoard相关学习
TensorBoard是Google为TensorFlow框架开发的一个强大的可视化工具,它可以帮助用户更直观地理解、分析和调试机器学习模型的训练过程。通过TensorBoard,你可以可视化模型的结构、监控训练过程中的指标变化(如损失函数、准确率)、查…...

敏感数据处理的艺术:安全高效的数据提取实践与挑战
在数字化时代,数据已成为驱动经济社会发展的核心要素之一。然而,伴随数据量的爆炸性增长,敏感数据的管理和保护成为了信息安全领域的重大挑战。敏感数据,包括个人身份信息、财务记录、健康档案、商业秘密等,一旦泄露&a…...

收藏!AI时代,软件工程基本功才是你的核心竞争力
在AI coding时代,软件工程的基本功不仅没有过时,反而比以往任何时候都更加重要。AI是放大器,好的代码库能提升效率,而模糊混乱的代码库则会放大混乱。接口、边界、领域语言和测试等“老派”的基本功,是开发者手中杠杆率…...

【码上爬】 题十一:wasm小试牛刀 wasm文件处理,堆栈分析
暗号:aHR0cHM6Ly9tYXNoYW5ncGEuY29tL3Byb2JsZW0tZGV0YWlsLzExLw题目:先分析数据接口,可以看到m和ts是加密的,但是这里的ts的值应该是一个时间戳,所以主要要逆向的值是m:然后在发起程序的最上面的堆栈下一个…...

搭建企业AI知识库:6步从0到1,避免百万投入打水漂!揭秘大模型落地成败关键!
企业AI Agent的成功关键在于高质量的私有知识库。文章强调了知识库需满足真实权威、时效动态、可控安全、语义完整、持续进化五点。搭建过程分为爬虫采集、数据清洗、文档切分、Embedding生成、向量存储和RAG检索优化六个阶段,其中前两阶段尤为重要。文章还详细阐述…...

OBS智能镜头:5分钟实现直播自动对焦,让镜头始终跟随你
OBS智能镜头:5分钟实现直播自动对焦,让镜头始终跟随你 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 你是否在直播时经常需要手动调整摄像头角度&#…...

别再硬扛了!书匠策AI用大白话告诉你:毕业论文其实可以“拼“出来
各位还在跟毕业论文死磕的朋友们,今天这篇文章,可能会颠覆你对写论文的认知。 先问你一个问题:你写论文最痛苦的是什么?不是写不出来,而是——坐在电脑前三个小时,一个字都没憋出来。 别慌,今…...

Scandit Barcode Scanner:这家瑞士公司的SDK,如何让淘宝、京东的扫码快人一步?
Scandit Barcode Scanner:解码瑞士技术如何重塑全球扫码体验 在移动互联网时代,扫码已成为连接物理世界与数字世界的无形桥梁。从超市收银台到物流仓库,从零售门店到电商平台,条码扫描技术默默支撑着现代商业的高效运转。而在这背…...

Newbie-Guideline数据库实战:SQL查询与ER模型设计的完整教程
Newbie-Guideline数据库实战:SQL查询与ER模型设计的完整教程 【免费下载链接】Newbie-Guideline 컴퓨터과학/공학 신입생 및 비전공자 신입을 위한 지침서 项目地址: https://gitcode.com/gh_mirrors/ne/Newbie-Guideline Newbie-Guideline是面向计算机科学/…...

2026年最新推荐 很多一线老师都在用的英语作文批改工具
行业共性痛点拆解我们团队做英语教育技术落地5年,接触过全国上千位初高中英语老师,发现作文批改是大家公认的效率洼地。人工批改模式下,一个45人班的作文,每篇要改语法、逻辑、表达、扣题四个维度,最少花3分钟…...

RimSort终极指南:开源跨平台RimWorld模组管理器完全解析
RimSort终极指南:开源跨平台RimWorld模组管理器完全解析 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, community-ma…...

2026 论文双检突围:9 款查重降重降 AIGC 工具硬核横评,Paperxie 领跑全场景通关
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/weight?type1https://www.paperxie.cn/weight?type1 毕业季论文查重飘红、AIGC 率爆表,已成为无数本科生与研究生的 “双重噩梦”。2026 年知网、维普全面升级…...