万字长文带你走进MySql优化(系统层面优化、软件层面优化、SQL层面优化)
文章目录
- 系统层面优化
- 采用分布式架构
- 使用缓存
- 使用搜索引擎
- 软件层面优化
- 调整 MySQL 参数配置
- 定期清理无用数据
- 创建索引
- 创建索引
- 普通索引
- 唯一索引
- 全文索引
- 组合索引
- 空间索引
- 主键索引
- 外键索引
- 索引前缀
- 适合创建索引的场景
- 不适合创建索引的场景
- 优化表结构
- 分库分表
- SQL优化
- explain执行计划
- **样本sql**
- **执行结果**
- 字段含义
- Select 优化
- 避免 SELECT * 查询,只查需要的字段
- 尽量避免or查询
- 使用 UNION ALL 替代 UNION
- 避免使用子查询,可以改成 JOIN
- 有必要时在应用层 ORDER BY 和 GROUP BY
- 避免使用 LIKE '%value%' 或 LIKE '%value'
- 避免在索引字段上使用函数
- 避免隐式类型转换
- 表连接时候用小数据集驱动大数据集
- 避免在索引字段使用不等值操作(!=、<>)
- inner join 、left join、right join选择
- 先过滤,再GROUP BY、ORDER BY
- 查询时对null数据处理
- 限制返回条数
- 明知结果返回一条记录,可以加limit1
- 分页查询优化
- 使用书签
- 延迟关联
- 倒序查询
- Update优化
- 使用或者涉及索引字段进行update
- 使用批量更新
- 限制更新
- 避免使用子查询
- 减少触发器和外键
- Insert 优化
- 批量插入数据
- 使用 LOAD DATA INFILE
- 大量更新数据时禁用索引
- 使用 REPLACE INTO
- 大数据量减少自增主键的使用
- Delete 优化
- 推荐使用 TRUNCATE TABLE
- 推荐使用删除标记
MySQL是一个关系型数据库管理系统,可以从不同的层面进行优化以提高系统的性能和效率。下面就是从系统设计层面、软件层面、SQL层面的一些优化建议。优化MySql可以从减轻数据库压力、提高配置、提高查询效率等方面入手。
系统层面优化
采用分布式架构
如果单台服务器无法满足需求,可以采用分布式架构来提高 MySQL 的性能。常用的分布式架构包括主从复制、读写分离等。
扩展
- 主从复制:主从复制是指将一个 MySQL 实例(主库)中的数据复制到其他 MySQL 实例(从库)中,从库中的数据与主库中的数据保持一致。主从复制的主要优点是:
- 提高系统的可用性,当主库故障时,可以快速切换到从库继续提供服务;
- 分担主库的负载,可以将读请求分发到从库中处理,减轻主库的负担。
- 读写分离:读写分离是指将读请求和写请求分别分发到不同的 MySQL 实例中处理。写请求只发送到主库中,而读请求则发送到从库中。读写分离的主要优点是:
- 分担主库的负载,将读请求和写请求分别分发到不同的 MySQL 实例中处理,减轻主库的负
- 提高系统的读性能,将读请求分发到从库中处理,减轻主库的负担;
使用缓存
使用缓存优化 MySQL 可以大幅提升系统性能,减少数据库的压力。
常用的缓存方案有以下几种:
- 前端缓存
前端缓存是指将数据缓存在客户端(如浏览器)中,减少服务器端的请求。前端缓存可以通过 HTTP 缓存头来实现,例如,可以设置 Cache-Control、Expires、Last-Modified 等缓存头。
- 应用程序缓存
应用程序缓存是指将数据缓存在应用程序的内存中,减少对数据库的访问。应用程序缓存可以使用一些缓存框架来实现,例如,Redis、Memcached 等。在使用应用程序缓存时需要注意缓存数据的有效期,避免缓存数据过期或失效。
- 数据库缓存
数据库缓存是指将数据缓存在数据库的内存中,减少磁盘 I/O 的访问。数据库缓存可以使用 MySQL 内置的缓存机制来实现,例如,使用 Query Cache、InnoDB Buffer Pool 等。
扩展:使用缓存优化 MySQL 需要注意以下几点:
- 缓存数据的有效期,避免缓存数据过期或失效。
- 缓存数据的一致性,需要确保缓存数据与数据库中的数据保持一致。
- 缓存数据的大小,需要根据系统的需求和硬件资源来确定缓存的大小。
- 缓存数据的并发访问,需要考虑多线程并发访问时的锁竞争问题。
- 缓存的选择,需要根据系统的需求和硬件资源来选择合适的缓存方案,例如,前端缓存、应用程序缓存、数据库缓存等。
使用搜索引擎
使用 Elasticsearch 进行查询可以加速查询操作,并且可以提供强大的搜索和分析功能。
注意⚠️
- 在使用 Elasticsearch 进行查询时,需要注意 Elasticsearch 和 MySQL 之间的数据一致性问题。由于 Elasticsearch 中的数据可能会有延迟,因此需要考虑如何处理数据同步和数据一致性问题。
- 需要注意 Elasticsearch 和 MySQL 之间的数据一致性问题。由于 Elasticsearch 中的数据可能会有延迟,因此需要考虑如何处理数据同步和数据一致性问题。
软件层面优化
调整 MySQL 参数配置
通过修改 MySQL 的配置参数来优化 MySQL 的性能,例如,修改缓冲池的大小、修改连接数的数量、缓存池大小等等。
扩展
- innodb_buffer_pool_size:这个参数配置了 InnoDB 存储引擎使用的内存池的大小,可以用来控制 InnoDB 存储引擎的缓存区大小。一般来说,innodb_buffer_pool_size 的大小应该是系统内存的 50%~70%。
- innodb_log_file_size:这个参数配置了 InnoDB 存储引擎的日志文件大小,可以影响到事务的提交速度和数据恢复速度。一般来说,innodb_log_file_size 的大小应该是 1GB~2GB 左右。
- query_cache_size:这个参数配置了查询缓存的大小,可以提高查询的速度。但需要注意,使用查询缓存会增加 MySQL 服务器的 CPU 负载,并且会占用额外的内存,因此需要根据实际情况来决定是否启用查询缓存。
- max_connections:这个参数配置了 MySQL 服务器的最大连接数,可以控制 MySQL 服务器的并发连接数。需要根据实际情况来决定 max_connections 的大小,一般来说,max_connections 的值应该大于服务器上同时在线的最大连接数。
- key_buffer_size:这个参数配置了 MyISAM 存储引擎的索引缓存的大小,可以提高查询的速度。但需要注意,MyISAM 存储引擎的索引缓存只能缓存索引,无法缓存表数据,因此只有在使用 MyISAM 存储引擎时才需要配置 key_buffer_size。
定期清理无用数据
定期清理无用数据可以帮助我们减少数据存储空间,提高数据库的性能,以及减少备份和恢复数据的时间和成本
扩展
- 清理日志文件:MySQL 中的错误日志、二进制日志和慢查询日志等日志文件可能会占用大量的存储空间,需要定期清理。
- 清理过期数据:在 MySQL 中,经常会产生一些过期的数据,例如历史数据、日志数据等,这些数据可以定期清理。可以通过设置自动删除或手动删除的方式来清理过期数据。
- 清理未使用的表和索引:MySQL 中有些表和索引可能已经不再使用,但仍然占用着存储空间。可以通过查询系统表来找出这些未使用的表和索引,然后进行清理。
- 清理无效的备份文件:MySQL 中的备份文件可能会占用大量的存储空间,需要定期清理无效的备份文件,保留最新的有效备份文件。
- 优化数据存储方式:MySQL 中有很多数据存储方式,例如 MyISAM、InnoDB、MEMORY 等,不同的存储方式对空间的使用效率也不同。可以根据实际情况选择合适的存储方式,优化数据的存储方式。
创建索引
索引类似于字典的目录,可以提高查询的效率。
索引从物理上可以分为:聚集索引,非聚集索引
从逻辑上可以分为:普通索引,唯一索引,主键索引,联合索引,全文索引
创建索引可以提高数据库查询性能,但是不是所有场景都适合创建索引。
创建索引
普通索引
适用场景:对于一些较小的表或者经常需要进行查询的表,可以使用普通索引来提高查询效率。
CREATE INDEX idx_name ON table_name(column_name);
唯一索引
适用场景:当需要保证某个字段的唯一性时,可以使用唯一索引。
CREATE UNIQUE INDEX idx_name ON table_name(column_name);
全文索引
适用场景:当需要进行全文搜索时,可以使用全文索引。
CREATE FULLTEXT INDEX idx_name ON table_name(column_name);
组合索引
适用场景:当查询条件中涉及多个字段时,可以使用组合索引来提高查询效率。
CREATE INDEX idx_name ON table_name(column1, column2, ...);
空间索引
适用场景:当需要对地理位置进行查询时,可以使用空间索引。
CREATE SPATIAL INDEX idx_name ON table_name(column_name);
主键索引
适用场景:当需要对某个字段进行唯一标识时,可以使用主键索引。
ALTER TABLE table_name ADD PRIMARY KEY(column_name);
外键索引
适用场景:当需要对表之间的关联进行查询时,可以使用外键索引。
ALTER TABLE table_name ADD FOREIGN KEY(column_name) REFERENCES ref_table(ref_column);
索引前缀
适用场景:当某个字段值的长度较长,可以使用索引前缀来提高查询效率。
注意⚠️:使用索引前缀时,可能会导致索引失效或者查询结果不准确,需要根据实际情况进行选择。
CREATE INDEX idx_name ON table_name(column_name(prefix_length));
适合创建索引的场景
- 经常用作查询条件的列:如果一个列经常用作查询条件,那么为这个列创建索引可以提高查询性能。例如,用户表中的用户名、邮箱、手机号等列。
- 经常被用于连接的列:如果一个列经常被用于连接多个表,那么为这个列创建索引可以提高连接查询的性能。例如,在一个订单表和商品表中,订单表中的商品编号和商品表中的商品编号经常被用于连接查询。
- 经常被用于排序的列:如果一个列经常被用于排序,那么为这个列创建索引可以提高排序查询的性能。例如,新闻网站中的文章发布时间、评论数等列。
- 经常被用于分组的列:如果一个列经常被用于分组,那么为这个列创建索引可以提高分组查询的性能。例如,在一个销售数据表中,按照产品类别分组的查询。
- 大表中的常用列:在大表中,查询性能通常较差。为了提高查询性能,可以为常用的列创建索引,例如,大表中的订单号、产品编号等。
不适合创建索引的场景
- 列的数据分布不均匀:如果一个列的数据分布不均匀,那么为这个列创建索引可能会降低查询性能,因为数据库查询优化器会认为使用索引查询的代价比全表扫描高。例如,在一个性别列中,如果大部分数据是男性,那么为这个列创建索引可能会降低查询性能。
- 小表:如果一个表很小,那么为这个表创建索引的代价可能比使用全表扫描更高,因为查询优化器需要额外的代价来使用索引。通常情况下,小于1000行的表不适合创建索引。
- 经常更新的列:如果一个列经常被更新,那么为这个列创建索引可能会降低数据库写入性能,因为每次更新操作都需要更新索引。例如,一个日志表中的时间戳列。
- 数据类型是 TEXT、BLOB 等:一般对于数据类型是 TEXT、BLOB 等的列,创建索引的代价非常高,因为这些列的数据比较大,索引也会很大,导致查询性能下降。
优化表结构
- 避免使用过大的字段类型,可以使用合适的数据类型来减少存储空间的浪费;
- 避免使用 NULL,因为 NULL 会增加存储空间和查询复杂度;
- 避免使用 BLOB 和 TEXT 类型的字段,因为这些字段会影响查询性能;
- 对于大型的表,可以使用分区表来提高查询性能。
分库分表
MySQL 分库分表是一种常用的数据库水平扩展方式,可以有效地解决单个 MySQL 实例无法满足高并发、海量数据存储等需求的问题。可以将一个大型的数据库拆分成多个小型的数据库,每个小型数据库中包含一部分数据。同时,可以将一个大型的表拆分成多个小型的表,每个小型表中包含一部分数据。这种方式可以解决单一数据库或表过大导致的性能瓶颈问题,提高系统的可扩展性和可用性。
扩展
分库分表的具体实现方法有以下几种:
- 垂直分库
垂直分库是将一个大型的数据库拆分成多个小型的数据库,每个小型数据库中包含一部分相关的表。例如,可以将一个电商系统中的用户表、订单表、商品表等拆分成多个小型数据库,每个小型数据库中只包含一部分相关的表。垂直分库的优点是易于管理,每个小型数据库中包含的表都具有相似的特点。缺点是可能会导致数据不一致,例如,当一个表的数据需要更新时,可能需要在多个小型数据库中进行更新操作。
- 水平分库
水平分库是将一个大型的数据库中的表按照某种规则分散到多个小型数据库中,每个小型数据库中包含一部分表。例如,可以将一个电商系统中的订单表按照订单号的范围分散到多个小型数据库中,每个小型数据库中包含一部分订单数据。水平分库的优点是易于扩展,可以将新的小型数据库添加到系统中。缺点是可能会导致数据不一致,例如,当一个表的数据需要更新时,可能需要在多个小型数据库中进行更新操作。
- 水平分表
水平分表是将一个大型的表按照某种规则分散到多个小型表中,每个小型表中包含一部分数据。例如,可以将一个电商系统中的订单表按照订单号的范围分散到多个小型表中,每个小型表中包含一部分订单数据。水平分表的优点是易于扩展,可以将新的小型表添加到系统中。缺点是可能会导致查询性能下降,因为查询可能需要在多个小型表中进行。
SQL优化
explain执行计划
在看具体SQL优化之前,可以先了解一下explain执行计划,使用 EXPLAIN 命令来获取一个 SQL 查询语句的执行计划。执行计划描述了 MySQL 数据库系统如何执行查询,并且可以用来分析和优化查询语句。
样本sql
CREATE TABLE students (id INT NOT NULL AUTO_INCREMENT,name VARCHAR(50) NOT NULL,email VARCHAR(50) NOT NULL,PRIMARY KEY (id)
);
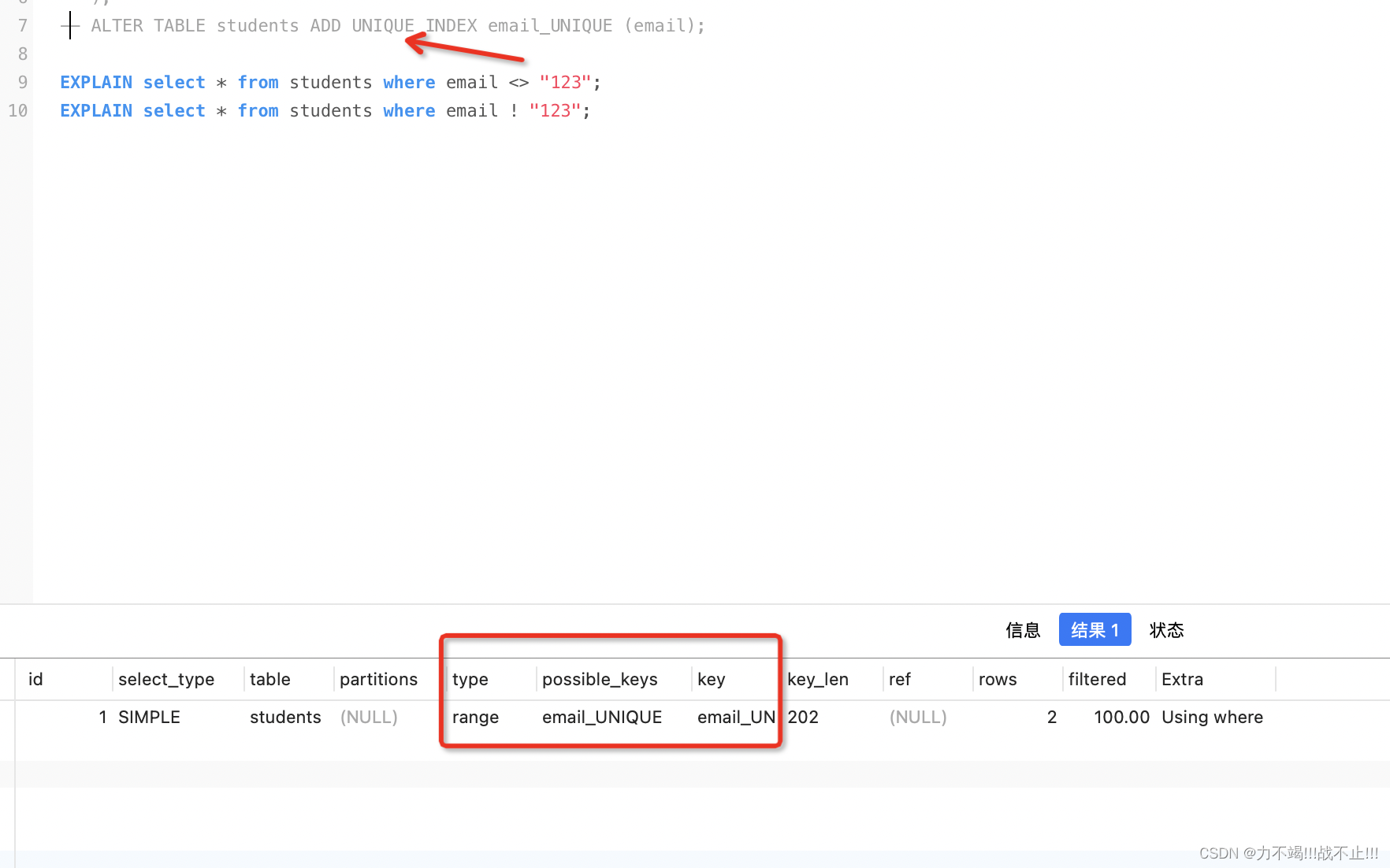
ALTER TABLE students ADD UNIQUE INDEX email_UNIQUE (email);
#explain执行计划
EXPLAIN select * from students where email ! "123";
执行结果

字段含义
-
id:查询的唯一标识符。如果查询包含子查询,则每个子查询都有一个唯一标识符。
-
select_type:查询的类型,例如 SIMPLE(简单查询)、PRIMARY(主查询)或 UNION(联合查询)等。
-
table:查询的表名。
-
partitions:查询的分区。
-
type:连接类型【SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是
consts 最好。】(执行性能排名:system > const > eq_ref > ref > range > index > all。)
-
system:表仅有一行,基本用不到;
-
const:表最多一行数据配合,主键查询时触发较多;
-
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型;
-
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
-
range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range;
-
index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小;
-
all:全表扫描;
-
-
possible_keys:查询可能使用的索引列表。
-
key:查询实际使用的索引。
-
key_len:索引的长度。
-
ref:使用索引的列或常数。
-
rows:MySQL 估计将会扫描的行数。
-
filtered:使用条件过滤后,剩余的行数百分比。
-
Extra:额外的信息,例如使用了哪些索引或排序方式等。
-
Using index:只从索引树中获取信息,而不需要回表查询;
-
Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
-
Using temporary:mysql常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时;
-
Select 优化
避免 SELECT * 查询,只查需要的字段
- 性能问题:使用"SELECT字段"可以提高查询性能。当使用"SELECT *"时,MySQL需要检索表中的所有字段,包括不需要的字段,这会占用更多的系统资源和时间。而使用"SELECT字段"可以减少检索的数据量,从而提高查询性能。
- 可读性和维护性问题:使用"SELECT字段"可以提高查询的可读性和维护性。当使用"SELECT *"时,查询结果中的字段顺序可能会发生变化,这会给程序员带来一定的困扰。而使用"SELECT字段"可以明确指定查询的字段,使得查询结果的字段顺序和查询语句中的字段顺序一致,更易于程序员理解和维护。
- 安全问题:使用"SELECT字段"可以提高查询的安全性。当使用"SELECT *"时,如果表结构发生变化,可能会将不需要的字段暴露给外部,这会给系统带来潜在的安全风险。而使用"SELECT字段"可以避免暴露不需要的字段,从而提高查询的安全性。
尽量避免or查询
or没有索引的字段会走全表查询,有必要时可以让拆成多条sql,让没有索引的字段and有索引的字段
如a,c字段有单值索引
#这条语句走全表扫描
select * from test where a = "xxx" or b = "xxx";
可以优化成下面语句
#分开查询后续合并结果
select * from test where a = "xxx";
select * from test where c = "xxx" and b = "xxx";#或者单次查询
select * from test where a = "xxx" or a in (select a from test where c = "xxx" and b = "xxx";);
使用 UNION ALL 替代 UNION
因为 UNION ALL 不会去重,速度更快,UNION 会去重,即将两个结果集中相同的记录合并成一条记录。如果我们确定合并的结果集中不会出现重复记录,那么我们可以使用 UNION ALL 来代替 UNION 操作。
注意⚠️:使用 UNION ALL 可能会增加网络传输的数据量,因为结果集中可能会有重复的记录。因此,我们需要在实际应用中根据具体情况来选择使用 UNION 还是 UNION ALL。
避免使用子查询,可以改成 JOIN
- 执行子查询时, MYSQL需要为内层查询语句的查询结果建立一个临时表。然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。连接(JOIN)之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑
- 更容易优化查询:使用 JOIN 操作可以更好地利用索引,提高查询的效率。
- 可读性更好:使用 JOIN 操作可以使 SQL 语句更加清晰易懂,降低出错的概率。
- 子查询嵌套层数过多会影响可维护性:使用 JOIN 操作可以将查询拆分成多个表,易于维护和优化。
有必要时在应用层 ORDER BY 和 GROUP BY
避免使用不必要的 ORDER BY 和 GROUP BY 操作,可以在应用层进行排序和分组。
- 减少数据库负担:ORDER BY 和 GROUP BY 操作需要对结果集进行排序或分组,会增加数据库的负担,特别是当结果集非常大时,效率会更低。而在应用层进行排序或分组可以减轻数据库的压力。
- 灵活性更高:在应用层进行排序或分组可以更加灵活地控制结果集的处理方式,可以根据具体需求进行自定义排序或分组操作。
避免使用 LIKE ‘%value%’ 或 LIKE ‘%value’
索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。以通配符(%)开头的搜索字符串会强制数据库系统进行全表扫描。
尽可能使用前缀搜索:如果可以使用前缀搜索而不是在字符串的任意位置进行匹配,那么查询将更加高效。例如,LIKE ‘value%’ 比 LIKE ‘%value%’ 更加高效
如果非要使用 LIKE ‘%value%’ 或 LIKE ‘%value’,可以采取放在语句末、搜索引擎、离线数据仓库
- 放在带索引查询的语句末:将 LIKE 语句放在 WHERE 子句的末尾可以避免在查询的前面进行全表扫描。(如果查询条件前面的字段是索引查询,在执行like的时候会缩减范围使得查询避免走全表查询)【注意⚠️:如果索引查询后的数据量依旧很大,不建议使用!】
- 搜索引擎:可以使用 Elasticsearch来进行模糊查询,效率更高
- 离线数据仓库:如Hive,有些场景可以使用,查询时长可能会有点久且不能保证实时性
- 使用 REVERSE() 函数:可以先将需要查询的值
value进行反转,然后将查询条件改写为LIKE reverse('value')%',这样可以利用索引加速查询,避免全表扫描。
-- 原查询:
SELECT * FROM my_table WHERE my_column LIKE '%abc';-- 优化后的查询:
SELECT * FROM my_table WHERE REVERSE(my_column) LIKE REVERSE('cba')%;避免在索引字段上使用函数
在索引字段上运用了函数,导致索引失效。B+ 树提供索引的快速定位能力,来源于同一层兄弟节点的有序性。也就是说,对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。可以在查询后对结果数据字段进行函数操作。
避免隐式类型转换
隐式类型转换会导致索引失效
#如order_id是varchar类型索引字段,查询时用的整数,底层查询时会做类型转换
select * from test where order_id = 110717;
表连接时候用小数据集驱动大数据集
小表驱动大表可以减少不必要的表连接,从而达到优化效果
扩展:
嵌套循环联接(NLJ)算法:循环从第一个表中依次读取行,取到每行再到联接的下一个表中循环匹配。这个过程会重复多次直到剩余的表都被联接了。通过外循环的行去匹配内循环的行,所以内循环的表会被扫描多次。(可以理解为外层循环一次就是一次表连接,以小表1万条,大表1000万条来对比,小表驱动大表来算只需要1万次表连接)
for each row in t1 matching range {for each row in t2 matching reference key {for each row in t3 {if row satisfies join conditions,send to client}}
}
避免在索引字段使用不等值操作(!=、<>)
当不等值操作在主键索引上时,索引生效(range查询)

当不等值操作在唯一索引上时,索引生效(唯一索引)
注意⚠️:当不等值操作作用在普通索引上时,索引失效
inner join 、left join、right join选择
- Inner join 只返回两个表中匹配的记录,不包含左表或右表中没有匹配到的记录。当需要查询两个表中的公共数据时,应该优先使用inner join。
- Left join 返回左表中所有的记录,以及左表和右表中匹配的记录。如果右表中没有匹配到左表中的记录,则返回null值。当需要查询左表的所有记录,并且只需要匹配右表中的一部分记录时,可以使用left join。
- Right join 返回右表中所有的记录,以及左表和右表中匹配的记录。如果左表中没有匹配到右表中的记录,则返回null值。当需要查询右表的所有记录,并且只需要匹配左表中的一部分记录时,可以使用right join。
先过滤,再GROUP BY、ORDER BY
在SQL查询语句中,过滤(Filtering)、分组(Grouping)和排序(Sorting)是常见的操作。正确的顺序应该是先过滤、再分组、最后排序。
- 减少操作的数据量,如果不先过滤数据,查询引擎可能需要对整个数据集进行聚合操作,这会消耗大量的时间和计算资源。
- 提高查询效率,如果不先过滤数据,查询引擎需要对大量无用的数据进行排序或分组操作,这会降低查询效率。
- 优化查询计划,查询引擎可以通过优化查询计划,选择更高效的执行计划来执行查询。如果不先过滤数据,查询引擎可能无法有效地优化查询计划,导致查询效率低下。
查询时对null数据处理
使用 IS NULL 或 IS NOT NULL 进行判断:在 WHERE 子句中使用 IS NULL 或 IS NOT NULL 来判断某个列是否为 NULL 值,可以避免使用等于号(=)进行判断时可能出现的索引失效情况。
使用 COALESCE 函数替换 NULL 值:在 SELECT 子句中使用 COALESCE 函数可以将 NULL 值替换为其他指定的值,例如:
#如果 column_name 列的值为 NULL,则查询结果中将显示 'default_value'。
SELECT COALESCE(column_name, 'default_value') AS column_alias FROM table_name;
使用 IFNULL 或 NVL 函数替换 NULL 值:在一些数据库中,也可以使用 IFNULL 或 NVL 函数来替换 NULL 值,例如:
#如果 column_name 列的值为 NULL,则查询结果中将显示 'default_value'。
SELECT IFNULL(column_name, 'default_value') AS column_alias FROM table_name;
- 在索引中使用 IS NULL 进行查询:对于包含大量 NULL 值的列,可以使用包含 IS NULL 的查询条件来进行索引查询。这样可以避免对 NULL 值进行排序或聚合操作,提高查询效率。
限制返回条数
有必要时限制返回结果的数量:在查询中使用 LIMIT 语句可以限制返回结果的数量,只拿取所需要的数据,减少数据传输和处理的时间。
好处
- 减少网络传输开销:查询结果集非常大,MySQL需要将全部结果传输给客户端,这会导致网络传输开销增加。通过限制返回条数,可以减少网络传输开销。
- 避免客户端内存溢出:查询结果集非常大,客户端需要占用大量的内存来存储结果集,这可能导致内存溢出。通过限制返回条数,可以避免客户端内存溢出。
- 提高用户体验:查询结果集非常大,用户需要等待很长时间才能看到结果。通过限制返回条数,可以提高用户体验,让用户更快地看到部分结果,从而决定是否需要进一步查询。
- 提高查询效率:查询结果集非常大,MySQL需要耗费大量的时间和资源来返回全部结果。通过限制返回条数,可以减少MySQL的负担,提高查询效率。
明知结果返回一条记录,可以加limit1
当我们明确知道某个查询的结果只会返回一条记录时,可以添加 LIMIT 1 语句,让MySQL停止游标移动,来提高查询效率和减少资源消耗。这是因为 LIMIT 1 会让 MySQL 在找到第一条匹配记录之后就停止搜索,而不会继续扫描整个表,从而可以更快地返回结果。
分页查询优化
当进行分页时,MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后放弃前 offset 行,返回 N 行。例如 limit 10000, 20。mysql排序取出10020条数据后,仅返回20条数据,查询和排序的代价都很高。那当 offset 特别大的时候,效率就非常的低下,所以我们要对sql进行改写
使用书签
用书签记录上次取数据的位置,过滤掉部分数据.
如下面语句
#改进前
SELECT id, name, description FROM film ORDER BY name LIMIT 1000, 10;#改进后
#name为上次查询后的最大值,注意这种场景只适用于不存在重复值的场景。
SELECT id, name, description FROM film WHERE name > 'begin' ORDER BY name LIMIT 10;延迟关联
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据.MySQL 延迟关联(Delayed Join)是一种优化技术,可以提高查询性能。当查询需要关联多个表时,延迟关联可以将一些关联操作推迟到后面的查询中,从而减少关联操作的数量,提高查询性能。
#id是主键值,name上面有索引。这样每次查询的时候,会先从name索引列上找到id值,然后回表,查询到所有的数据。可以看到有很多回表其实是没有必要的。完全可以先从name索引上找到id(注意只查询id是不会回表的,因为非聚集索引上包含的值为索引列值和主键值,相当于从索引上能拿到所有的列值,就没必要再回表了),然后再关联一次表,获取所有的数据
#改进前
SELECT id, name, description FROM film ORDER BY name LIMIT 100,5;#改进后
SELECT film.id, name, description FROM film
JOIN (SELECT id from film ORDER BY name LIMIT 100,5) temp
ON film.id = temp.id
倒序查询
假如查询倒数最后一页,offset可能会非常大
#改进前
SELECT id, name, description FROM film ORDER BY name LIMIT 100000, 10;
#改进后
SELECT id, name, description FROM film ORDER BY name DESC LIMIT 10;
Update优化
使用或者涉及索引字段进行update
确保涉及到UPDATE语句的列上有索引,这样可以大大减少查询时间。特别是对于更新大表的操作。
使用批量更新
批量更新可以将多个单独的UPDATE操作合并为一个,从而减少服务器和客户端之间的通信次数。可以使用INSERT … ON DUPLICATE KEY UPDATE语句或使用UPDATE … WHERE语句,同时更新多行数据。
限制更新
- LIMIT限制:在UPDATE语句中使用LIMIT关键字来限制更新的行数,以避免对整个表进行更新。特别是当更新大表时,限制更新行数是非常必要的。【可以在应用层面进行开关控制,在更新出错误数据后及时停掉应用,进行回滚】
- WHERE限制:限制更新行数可以避免意外或不正确的更新操作,例如当使用错误的 WHERE 子句时,可以防止更新整个表的数据。
避免使用子查询
使用子查询更新数据可能会导致以下问题:
- 不可预测性问题:当使用子查询更新时,可能会发生数据不一致的情况。这是因为子查询返回的结果可能会受到其他会话更新的影响,从而导致数据不一致的情况。
- 可读性问题:使用子查询的更新语句通常比较复杂,难以理解和维护,特别是在涉及多个子查询的情况下。
- 性能问题:子查询可能会导致 MySQL 执行缓慢,特别是当数据量很大时。因为子查询会逐行扫描数据表,并且每个子查询都会消耗额外的资源。
可以使用 JOIN 或 EXISTS 进行相关的过滤和更新操作,这通常比子查询更高效和可读。
减少触发器和外键
在 MySQL 中进行 UPDATE 操作时,可能会触发与表相关的触发器和外键,这可能会导致以下问题:
- 性能问题:触发器和外键需要额外的时间和资源来处理,这可能会导致 UPDATE 操作变得缓慢,并增加数据库的负载。
- 扩展1:当进行 UPDATE 操作时,MySQL 会检查更新的数据是否涉及到任何触发器或外键。如果存在相关的触发器或外键,MySQL 需要执行额外的逻辑来确保数据的完整性和一致性。这可能会导致额外的时间和资源开销,从而导致 UPDATE 操作变得缓慢。
- 扩展2:如果表中存在多个触发器和外键,那么在进行 UPDATE 操作时,需要处理多个复杂的操作,从而增加代码的复杂度和难度。这可能会导致数据库负载的增加,影响数据库性能。
- 可维护性问题:如果表中存在多个触发器和外键,那么在进行 UPDATE 操作时,可能需要处理多个复杂的操作,从而增加代码的复杂度和难度。
- 数据完整性问题:如果 UPDATE 操作中涉及到多个表或外键关系,那么触发器和外键可能会对数据完整性产生影响。如果不正确地处理这些关系,可能会导致数据不一致或损坏。
Insert 优化
批量插入数据
使用 INSERT INTO … VALUES (…) 语句单条插入数据的效率较低,可以使用 INSERT INTO … VALUES (…), (…), (…) 的语法批量插入多条数据,可以显著提高插入数据的速度。
使用 LOAD DATA INFILE
如果需要插入大量数据,可以使用 LOAD DATA INFILE 语句从本地文件中快速地加载数据到 MySQL 数据库中。这种方式比使用 INSERT INTO … VALUES (…) 的方式要快得多。
扩展:
以下是使用 LOAD DATA INFILE 的步骤:
- 创建表:首先需要创建一个表,用于存储要导入的数据。
- 创建文件:创建一个包含要导入数据的文件。文件格式必须与 MySQL 表中列的顺序一致,并使用特定的分隔符将列分开。
- 使用 LOAD DATA INFILE:使用 LOAD DATA INFILE 语句将文件中的数据加载到 MySQL 表中。
例如,如果要将数据从名为 data.txt 的文件中加载到名为 mytable 的表中,可以使用以下 SQL 语句:
#指定文件路径
LOAD DATA INFILE 'data.txt'
#指定要插入的表
INTO TABLE mytable
#指定列之间的分隔符
FIELDS TERMINATED BY ','
#指定每个列值的引号字符
ENCLOSED BY '"'
#指定行分隔符
LINES TERMINATED BY '\n'
使用 LOAD DATA INFILE 时,需要确保 MySQL 用户拥有从指定文件读取数据的权限。如果需要从网络中的文件中读取数据,可以使用 MySQL 客户端的 --local-infile 选项启用从本地加载数据的功能。
大量更新数据时禁用索引
在进行大量数据插入时,MySQL 可能会花费很多时间来更新索引。如果可以接受数据插入完成后再创建索引,可以使用 ALTER TABLE … DISABLE KEYS 语句禁用索引,等数据插入完成后再重新启用索引。【注意⚠️:当前可以在极少量查询的情况下使用!否则在大数据量下会导致大量慢sql】
使用 REPLACE INTO
REPLACE INTO 语句与 INSERT INTO 语句的区别在于,如果要插入的数据已经存在,INSERT INTO 语句会产生重复记录错误。而 REPLACE INTO 语句会自动更新原有的数据行,而不是产生错误。
REPLACE INTO 语句在以下情况下非常有用:
- 当需要插入新数据时,如果表中已经存在相同的数据,则用新的数据替换原有数据。
- 当需要更新一行数据时,如果该行数据不存在,则插入新数据;如果该行数据已经存在,则用新的数据替换原有数据。
大数据量减少自增主键的使用
如果表中存在自增主键,并且插入的数据量很大,那么每次插入数据时,MySQL 都需要重新计算自增主键的值,这可能会导致插入数据变慢。可以考虑使用其他方式来生成主键,例如使用 UUID 或使用应用程序生成主键。
Delete 优化
推荐使用 TRUNCATE TABLE
如果您需要删除整个表格中的所有行,则可以使用 TRUNCATE TABLE 命令。这比 DELETE 命令更快,并且可以在不影响系统性能的情况下删除大量数据。
推荐使用 TRUNCATE TABLE 的原因有以下几点:
- TRUNCATE TABLE 比 DELETE 语句更快。这是因为 TRUNCATE TABLE 在删除数据时不会记录每一行的删除操作,而是将整个表格直接清空,从而避免了一些额外的开销和日志记录。对于大型表格,TRUNCATE TABLE 可以显著提高清空数据的速度。
- TRUNCATE TABLE 比 DELETE 语句更安全。TRUNCATE TABLE 操作是原子性的,也就是说,在 TRUNCATE TABLE 运行过程中,如果出现故障或错误,整个操作会被回滚到原始状态,从而保证了数据的一致性。相比之下,DELETE 语句需要一行一行地删除数据,如果出现故障或错误,数据可能会被删除一部分,但不会被完全清空。
推荐使用删除标记
有些场景下需要让某些数据不展示出去,可以使用一个标记来表示这个数据被删除。例如可以使用date_delete字段,里面可以存储删除的时间戳或者0、1等,在查询的时候进行过滤。
相关文章:
万字长文带你走进MySql优化(系统层面优化、软件层面优化、SQL层面优化)
文章目录系统层面优化采用分布式架构使用缓存使用搜索引擎软件层面优化调整 MySQL 参数配置定期清理无用数据创建索引创建索引普通索引唯一索引全文索引组合索引空间索引主键索引外键索引索引前缀适合创建索引的场景不适合创建索引的场景优化表结构分库分表SQL优化explain执行计…...
云原生安全2.X 进化论系列|云原生安全2.X未来展望(4)
随着云计算技术的蓬勃发展,传统上云实践中的应用升级缓慢、架构臃肿、无法快速迭代等“痛点”日益明显。能够有效解决这些“痛点”的云原生技术正蓬勃发展,成为赋能业务创新的重要推动力,并已经应用到企业核心业务。然而,云原生技…...
认识进程 -了解进程调度
前言 本篇通过介绍操作系统OS的重要功能,了解并发并行, 了解操作系统的一项重要功能 “进程管理” , 通过了解进程管理认识进程是操作系统资源分配的基本单位 ,如有错误,请在评论区指正,让我们一起交流,共同进步! 文章…...
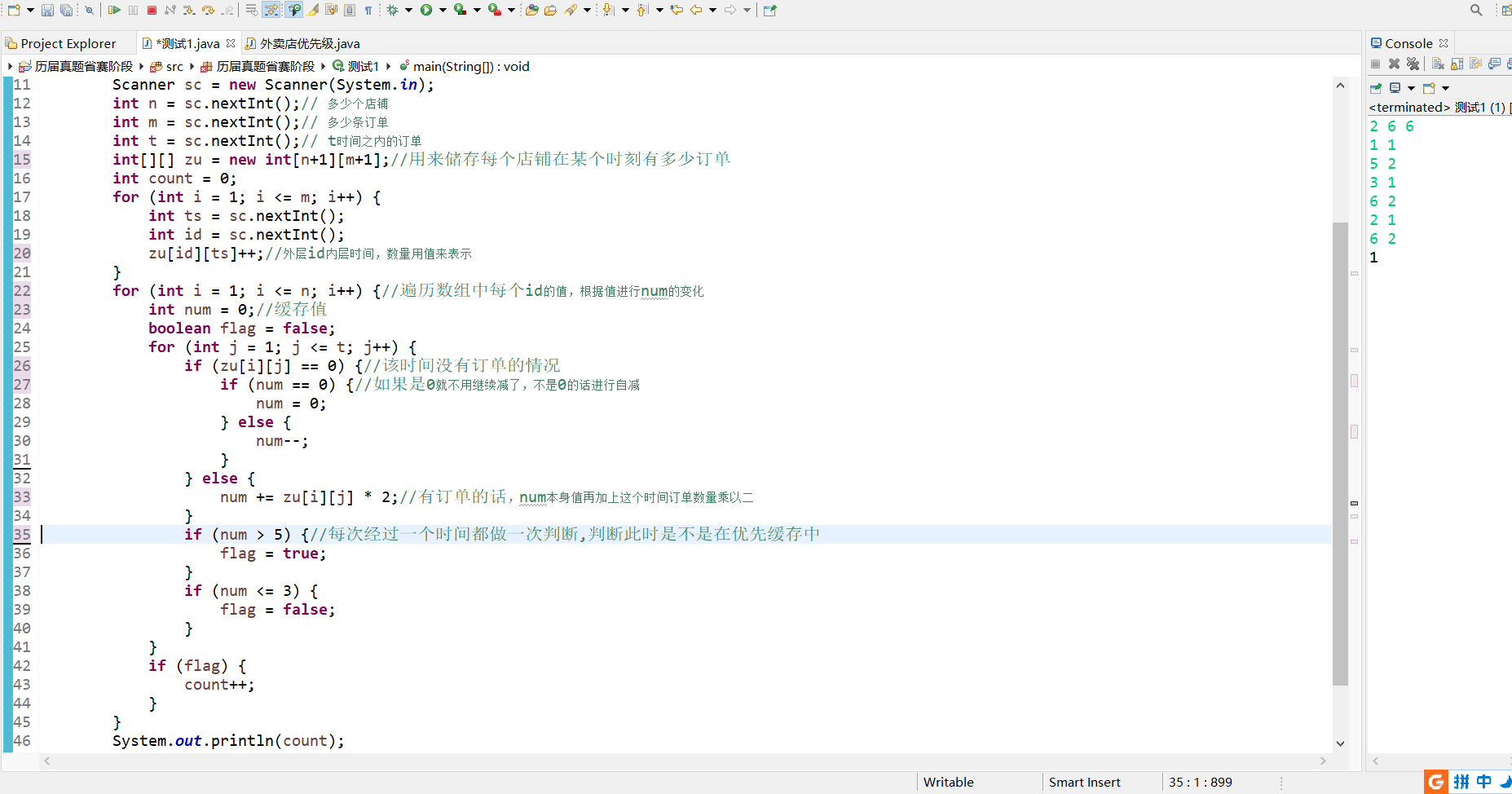
第十届省赛——7外卖店优先级
题目:“饱了么”外卖系统中维护着N 家外卖店,编号1~N。每家外卖店都有一个优先级,初始时(0 时刻) 优先级都为0。每经过1 个时间单位,如果外卖店没有订单,则优先级会减少1,最低减到0;而如果外卖店…...

做自动化测试选择Python还是Java?
今天,我们来聊一聊测试人员想要进阶,想要做自动化测试,甚至测试开发,如何选择编程语言 前言 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发展的趋势。特别是…...
C#基础之基础语法(一)
总目录 文章目录总目录前言一、C#简述1 C#是什么?2 .Net平台3. C# 和.Net的关系4. 集成开发环境(IDE)二、控制台应用程序1. 常用代码2.注意事项三、基础语法1.编写C#代码注意事项2.C#注释2. 变量&标识符&关键字4. 变量,字…...
【JVM篇1】认识JVM,内存区域划分,类加载机制
目录 一、JVM内存区域划分 ①程序计数器(每个线程都有一个) ②栈:保存了局部变量和方法调用的信息(每一个线程都有一个栈) 如果不停地调用方法却没有返回值,会产生什么结果 ③堆(每一个进程都有一个堆,线程共享一个堆) 如何区分一个变量是…...
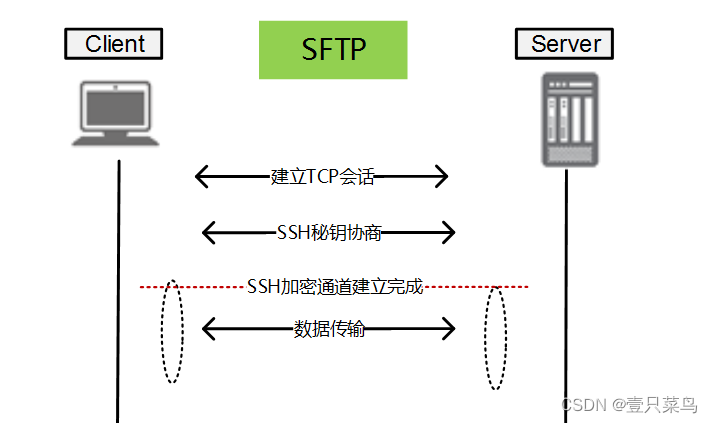
CHAPTER 5 文件共享 - FTP
文件共享 - FTP1 FTP1.1 传输方式1. ASCII传输方式2. 二进制传输模式3. 两种传输方式的区别1.2 支持的模式1. 主动模式(PORT)2. 被动模式(PASV)3. 如何选择4. 为什么绝大部分互联网应用都是被动模式?1.3 搭建FTP服务器(使用vsftpd)1. 安装软件…...
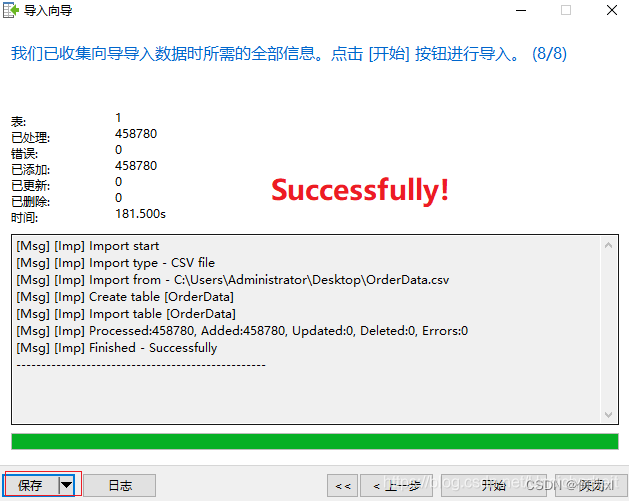
【MySQL】将 CSV文件快速导入 MySQL 中
【MySQL】将 CSV文件快速导入 MySQL 中方法一:使用navicat等软件的导入向导如果出现中文乱码方法二:命令行导入(LOAD DATA INFILE SQL)一般来说,将csv文件导入mysql数据库有两种办法: 使用 navicat、workbe…...

Ngnix安装教程(2023.3.8)
Nginx安装教程(2023.3.8)引言1、Nginx简介2、Nginx安装2.1 下载Nginx安装包2.2 免安装启动Nginx(切记解压后将nginx-1.23.3文件夹需要放在英文路径下,实测中文路径不识别且启动不成功)2.3 熟悉Nginx文件夹目录结构2.4 …...

【C语言】每日刷题 —— 牛客(2)
前言 大家好,继续更新专栏c_牛客,不出意外的话每天更新十道题,难度也是从易到难,自己复习的同时也希望能帮助到大家,题目答案会根据我所学到的知识提供最优解。 🏡个人主页:悲伤的猪大肠9的博客…...
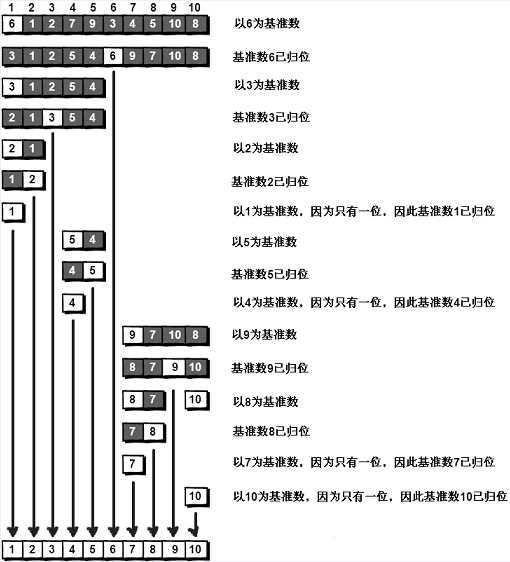
关于算法的一些简单了解
文章目录ALGORITHMBASIC INFORMATIONBasic algorithm design technology穷举法分治法减治法动态规划法贪心法Algorithm design technology based on search回溯法分支限界法PRACTICECONCEPTCALATION*CODEprim&dijkstra&kruskal分治法Q&AT(n)T(n)T(n) 是渐进时间复杂…...
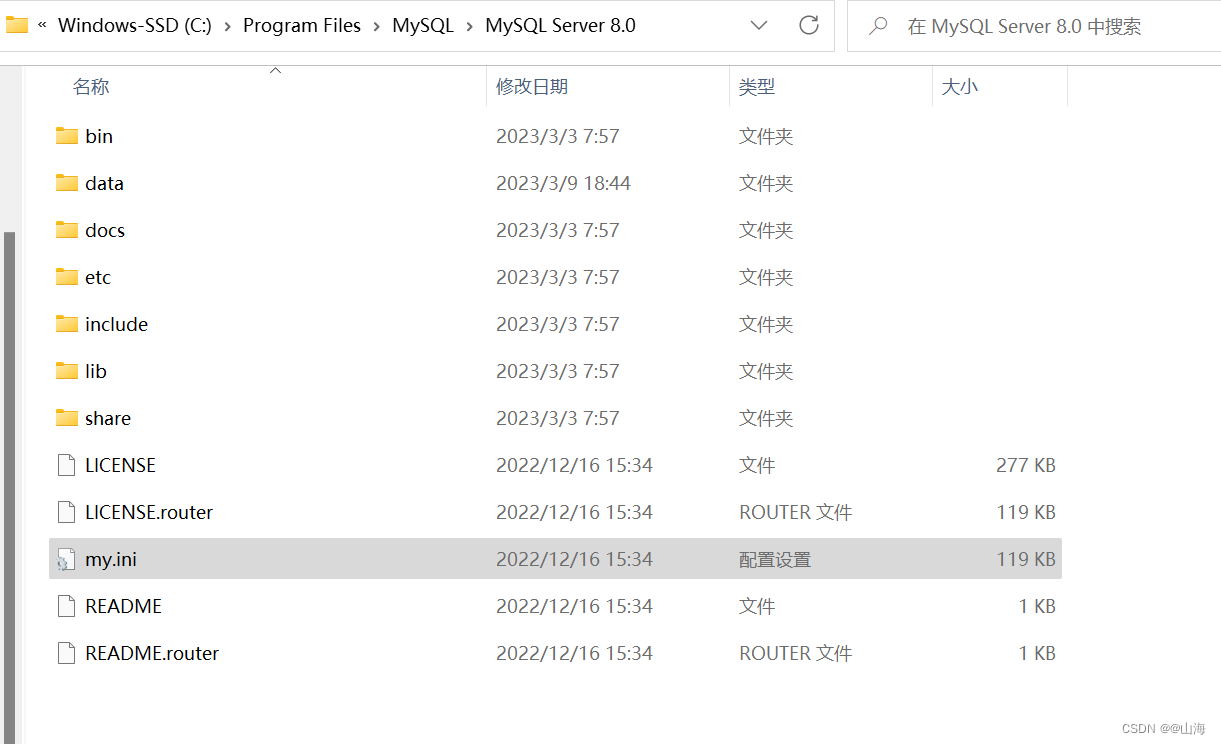
mysql无法启动服务及其他问题总结
文章目录1.安装后关于配置的问题显示【发生系统错误,拒绝访问】命令行Command Line Client闪退2.显示【MySQL服务无法启动】问题检查端口被占用删除data文件并初始化配置my.ini/.conf文件重新安装MySQL1.安装后关于配置的问题 显示【发生系统错误,拒绝访…...

数据库表字段命名规范
因为近期笔者在数据库命名规范上产生了一些疑问,故特此记录下来了一些开发规范,望做参考。 摘要: 当前研发工作中经常出现因数据库表、数据库表字段格式不规则而影响开发进度的问题,在后续开发使用原来数据库表时,也会…...
)
23种设计模式-命令模式(android应用场景介绍)
命令模式是一种行为设计模式,它允许将请求封装成一个独立的对象,并将请求的不同参数化。通过这种方式,命令模式可以在不同的请求间切换,或者将请求放入队列中等待执行。 在Java中,命令模式通常由一个抽象命令类和具体…...

vector你得知道的知识
vector的基本使用和模拟实现 一、std::vector基本介绍 1.1 常用接口说明 std::vector是STL中的一个动态数组容器,它可以自动调整大小,支持在数组末尾快速添加和删除元素,还支持随机访问元素。 以下是std::vector常用的接口及其说明…...
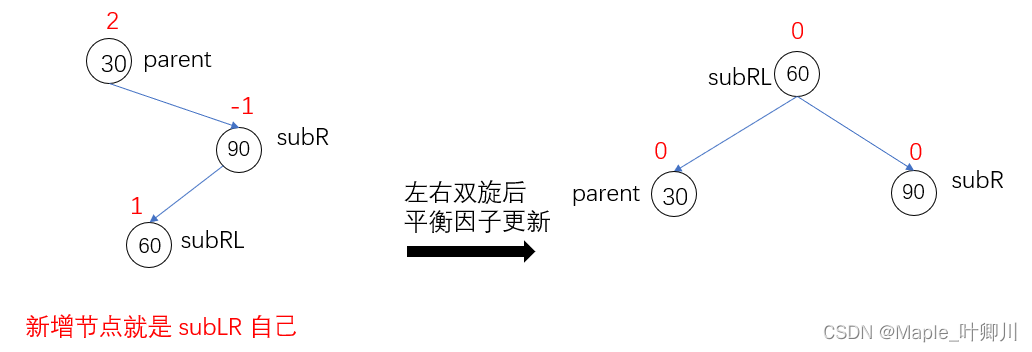
【C++进阶】四、AVL树(二)
目录 前言 一、AVL树的概念 二、AVL树节点的定义 三、AVL树的插入 四、AVL树的旋转 4.1 左单旋 4.2 右单旋 4.3 左右双旋 4.4 右左双旋 五、AVL树的验证 六、AVL树的性能 七、完整代码 前言 前面对 map/multimap/set/multiset 进行了简单的介绍,在其文…...
React 服务端渲染
React 服务器端渲染概念回顾什么是客户端渲染CSR(Client Side Rendering)服务器端只返回json数据,Data和Html的拼接在客户端进行(渲染)。什么是服务器端渲染SSR(Server Side Rendering)服务器端返回数据拼接过后的HTML,Data和Html…...
)
【算法设计-搜索】回溯法应用举例(1)
文章目录0. 回溯模板1. 走楼梯2. 机器走格子,但限定方向3. 中国象棋,马走日字4. 走迷宫5. 积木覆盖0. 回溯模板 搜索算法中的回溯策略,也是深度优先搜索的一种策略,比较接近早期的人工智能。毕竟,搜索是人工智能技术中…...

C++基础了解-23-C++ 多态
C 多态 一、C 多态 多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。 C 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。 下面的实例中,基类 Shape 被…...

手把手教你微调MONAI Bundle预训练模型:用TotalSegmentator数据提升CT器官分割精度
深度定制化医学影像分割:基于MONAI Bundle的TotalSegmentator数据微调实战 医学影像分析领域正经历着从通用模型到专用模型的范式转变。当我在去年参与一个肝脏肿瘤分割项目时,深刻体会到预训练模型在特定数据集上表现不佳的困境——不同医院的CT扫描协议…...

G-Helper:华硕笔记本轻量级硬件控制开源工具全解析
G-Helper:华硕笔记本轻量级硬件控制开源工具全解析 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: …...

Mermaid图表绘制终极指南:用Markdown代码快速创建专业图表
Mermaid图表绘制终极指南:用Markdown代码快速创建专业图表 【免费下载链接】mermaid mermaid-js/mermaid: 是一个用于生成图表和流程图的 Markdown 渲染器,支持多种图表类型和丰富的样式。适合对 Markdown、图表和流程图以及想要使用 Markdown 绘制图表和…...

最强AI剪辑工具盘点:免费直接用,小白秒变剪辑大师!
一、AI视频剪辑新时代:为什么选择这些工具? 2025年的AI视频工具已经不再是简单的滤镜和特效叠加,而是真正能够理解内容、自动完成剪辑全流程的智能助手。根据权威评测,真正优秀的AI剪辑工具应该具备以下特点: 真正免费…...

KART-RERANK大模型实战:Python爬虫数据智能排序与相关性分析
KART-RERANK大模型实战:Python爬虫数据智能排序与相关性分析 你是不是也遇到过这种情况?用Python爬虫吭哧吭哧抓了一大堆数据,结果发现里面什么都有:有用的、没用的、相关的、跑题的、高质量的、纯广告的……看着满屏的文本&…...

如何利用Outline构建现代化团队知识管理体系
如何利用Outline构建现代化团队知识管理体系 【免费下载链接】outline Outline 是一个基于 React 和 Node.js 打造的快速、协作式团队知识库。它可以让团队方便地存储和管理知识信息。你可以直接使用其托管版本,也可以自己运行或参与开发。源项目地址:ht…...

SKILL语言在数字IC设计中的高级应用:如何优化你的工作流程
SKILL语言在数字IC设计中的高级应用:如何优化你的工作流程 在数字IC设计的复杂世界里,效率就是竞争力。当大多数工程师还在手动点击EDA工具菜单时,掌握SKILL语言的高手已经用几行代码完成了批量操作。这不是魔法,而是SKILL语言赋…...
)
Python基础实战——批量处理文件(适合入门)
一、学习目标掌握 Python 文件操作(读取、写入、遍历),学会批量处理指定目录下的文件,比如批量修改文件名、提取文件内容,适合刚入门 Python 的程序员巩固基础语法。二、核心知识点os 模块:遍历目录、修改文…...
——WPS帧格式与交互流程详解)
hostapd wpa_supplicant madwifi深度解析(十)——WPS帧格式与交互流程详解
1. WPS协议基础与交互流程全景 第一次接触WPS(Wi-Fi Protected Setup)时,很多人会被它"一键连接"的便捷性吸引。但作为开发者,我们需要拨开这层简单的外衣,看看内部精妙的协议设计。WPS本质上是通过标准化的…...

FrankenPHP服务器性能监控终极指南:10个关键指标深度解析
FrankenPHP服务器性能监控终极指南:10个关键指标深度解析 【免费下载链接】frankenphp The modern PHP app server 项目地址: https://gitcode.com/GitHub_Trending/fr/frankenphp FrankenPHP作为现代化的PHP应用服务器,提供了强大的性能监控能力…...