基于transformers框架实践Bert系列6-完形填空
本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、选择题、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert等)
本篇主要讲解完形填空应用场景。本系列代码和数据集都上传到GitHub上:https://github.com/forever1986/bert_task
1 环境说明
1)本次实践的框架采用torch-2.1+transformer-4.37
2)另外还采用或依赖其它一些库,如:evaluate、pandas、datasets、accelerate等
2 前期准备
Bert模型是一个只包含transformer的encoder部分,并采用双向上下文和预测下一句训练而成的预训练模型。可以基于该模型做很多下游任务。
2.1 了解Bert的输入输出
Bert的输入:input_ids(使用tokenizer将句子向量化),attention_mask,token_type_ids(句子序号)、labels(结果)
Bert的输出:
last_hidden_state:最后一层encoder的输出;大小是(batch_size, sequence_length, hidden_size)(注意:这是关键输出,本次任务就需要获取该值,可以取出那个被mask掉的token,获取其前几个,取score最高的(当然也可以使用top_k或者top_p方式获取一定随机性))
pooler_output:这是序列的第一个token(classification token)的最后一层的隐藏状态,输出的大小是(batch_size, hidden_size),它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)。
hidden_states: 这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
attentions:这是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
2.2 数据集与模型
1)数据集来自:ChnSentiCorp(该数据集本身是做情感分类,但是我们只需要取其text部分即可)
2)模型权重使用:bert-base-chinese
2.3 任务说明
完形填空其实就是在一段文字中mask掉几个字,让模型能够自动填充字。这里本身就是bert模型做预训练是所做的事情之一,因此就是让数据给模型做训练的过程。
2.4 实现关键
1)数据集结构是一个带有text和label两列的数据,我们只需要获取到text部分即可。
2)随机mask掉部分数据,这个本身也是bert的训练过程,因此在transforms框架中DataCollatorForLanguageModeling已经实现了,你也可以自己实现随机mask掉你的数据进行训练
3 关键代码
3.1 数据集处理
数据集不需要做过多处理,只需要将text部分进行tokenizer,并制定max_length和truncation即可
def process_function(datas):tokenized_datas = tokenizer(datas["text"], max_length=256, truncation=True)return tokenized_datas
new_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
3.2 模型加载
model = BertForMaskedLM.from_pretrained(model_path)
注意:这里使用的是transformers中的BertForMaskedLM,该类对bert模型进行封装。如果我们不使用该类,需要自己定义一个model,继承bert,增加分类线性层。另外使用AutoModelForMaskedLM也可以,其实AutoModel最终返回的也是BertForMaskedLM,它是根据你config中的model_type去匹配的。
这里列一下BertForMaskedLM的关键源代码说明一下transformers帮我们做了哪些关键事情
# 在__init__方法中增加增加了BertOnlyMLMHead,BertOnlyMLMHead其实就是一个二层神经网络,一层是BertPredictionHeadTransform(包括linear+geluAct+ln),一层是decoder(hidden_size*vocab_size大小的linear)。
self.bert = BertModel(config, add_pooling_layer=False)
self.cls = BertOnlyMLMHead(config)
# 将输出结果outputs取第一个返回值,也就是last_hidden_state
sequence_output = outputs[0]
# 将last_hidden_state输入到cls层中,获得最终结果(预测的score和词)
prediction_scores = self.cls(sequence_output)
3.3 自动并随机mask数据
关键代码在于DataCollatorForLanguageModeling,该类会实现自动mask。参考torch_mask_tokens方法。
trainer = Trainer(model=model,args=train_args,train_dataset=new_datasets["train"],data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15),)
4 整体代码
"""
基于BERT做完形填空
1)数据集来自:ChnSentiCorp
2)模型权重使用:bert-base-chinese
"""
# step 1 引入数据库
from datasets import DatasetDict
from transformers import TrainingArguments, Trainer, BertTokenizerFast, BertForMaskedLM, DataCollatorForLanguageModeling, pipelinemodel_path = "./model/tiansz/bert-base-chinese"
data_path = "./data/ChnSentiCorp"# step 2 数据集处理
datasets = DatasetDict.load_from_disk(data_path)
tokenizer = BertTokenizerFast.from_pretrained(model_path)def process_function(datas):tokenized_datas = tokenizer(datas["text"], max_length=256, truncation=True)return tokenized_datasnew_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)# step 3 加载模型
model = BertForMaskedLM.from_pretrained(model_path)# step 4 创建TrainingArguments
# 原先train是9600条数据,batch_size=32,因此每个epoch的step=300
train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹per_device_train_batch_size=32, # 训练时的batch_sizenum_train_epochs=1, # 训练轮数logging_steps=30, # log 打印的频率)# step 5 创建Trainer
trainer = Trainer(model=model,args=train_args,train_dataset=new_datasets["train"],# 自动MASK关键所在,通过DataCollatorForLanguageModeling实现自动MASK数据data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15),)# Step 6 模型训练
trainer.train()# step 7 模型评估
pipe = pipeline("fill-mask", model=model, tokenizer=tokenizer, device=0)
str = datasets["test"][3]["text"]
str = str.replace("方便","[MASK][MASK]")
results = pipe(str)
# results[0][0]["token_str"]
print(results[0][0]["token_str"]+results[1][0]["token_str"])
5 运行效果

注:本文参考来自大神:https://github.com/zyds/transformers-code
相关文章:
基于transformers框架实践Bert系列6-完形填空
本系列用于Bert模型实践实际场景,分别包括分类器、命名实体识别、选择题、文本摘要等等。(关于Bert的结构和详细这里就不做讲解,但了解Bert的基本结构是做实践的基础,因此看本系列之前,最好了解一下transformers和Bert…...
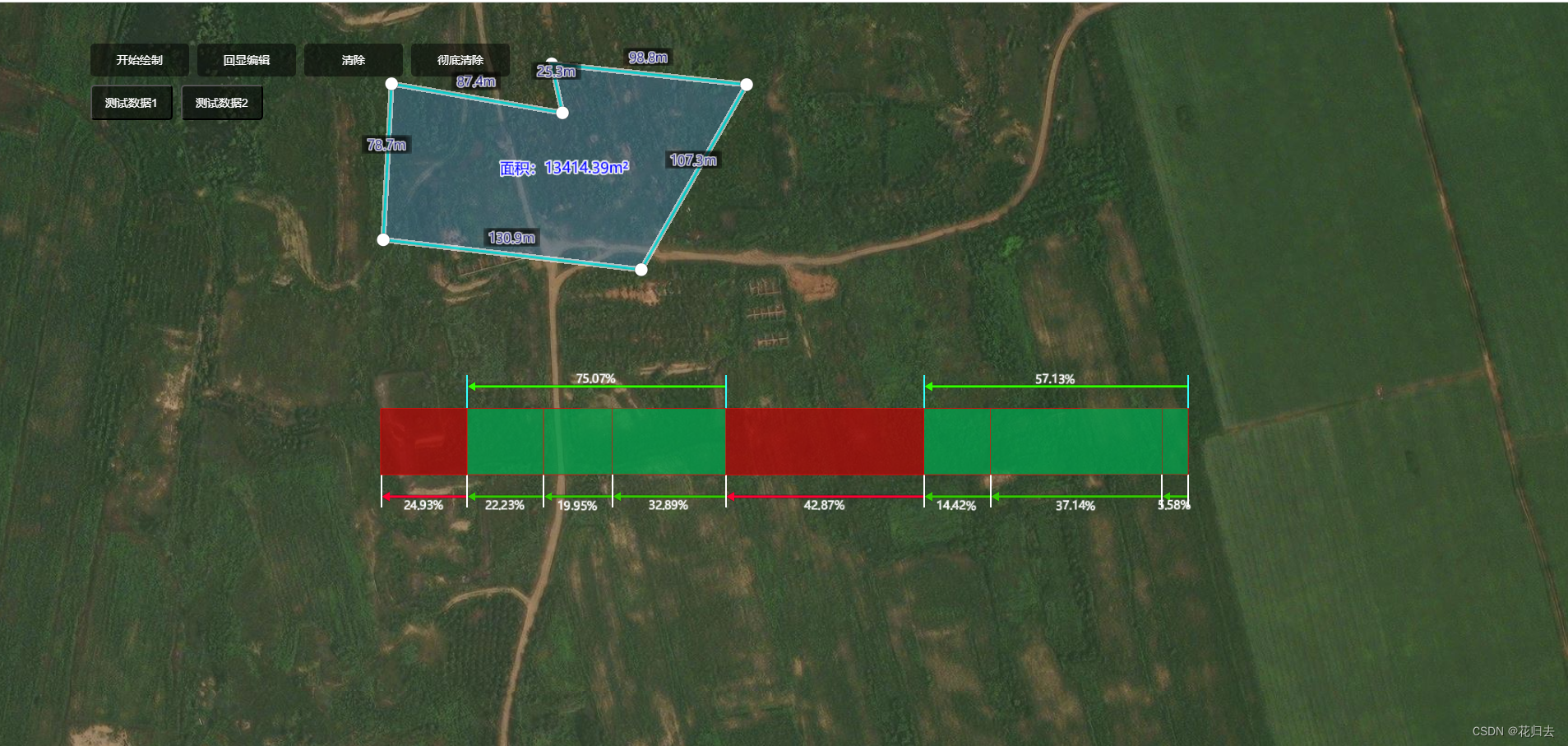
cesium绘制编辑区域
npm 安装也是可以的 #默认安装最新的 yarn add cesium#卸载插件 yarn remove cesium#安装指定版本的 yarn add cesium1.96.0#安装指定版本到测试环境 yarn add cesium1.96.0 -D yarn install turf/turf token记得换成您自己的!!! <t…...

数据库攻防之MySQL
MySQL 是最流行的关系型数据库,与此同时也是 web 应用中最好的关系型数据库管理应用软件。我们在渗透过程中碰到的 PHP 站点大部分都会搭配 MySQL 数据库,因此它是红队攻防中最常遇到的数据库。 0x01 MySQL简介 MySQL 是典型的关系型数据库,…...
八国多语言微盘微交易所系统源码 单控点控 K线完好
安装环境linux NGMySQL5.6PHP7.2(函数全删)pm2管理器(node版本选择v12.20.0) config/ database.php 修改数据库链接 设置运行目录 public 伪静态thinkphp...

爪哇,我初学乍道
>>上一篇(学校上课,是耽误我学习了。。) 2016年9月,我大二了。 自从我发现上课会耽误我学习,只要我认为不影响我期末学分的,我就逃课了。 绝大多数课都是要签到的,有的是老师突击喊名字…...
-限制)
【MySQL精通之路】全文搜索(5)-限制
主博客:【MySQL精通之路】全文搜索功能-CSDN博客 全文搜索仅支持InnoDB和MyISAM表。 分区表不支持全文搜索。参见“分区的限制和限制”。 全文搜索可用于大多数多字节字符集。 例外的是,对于Unicode,可以使用utf8mb3或utf8mb4字符集ÿ…...

动态规划part03 Day43
LC343整数拆分(未掌握) 未掌握分析:dp数组的含义没有想清楚,dp[i]表示分解i能够达到的最大乘积,i能够如何分解呢,从1开始遍历,直到i-1;每次要不是j和i-j两个数,要不是j和…...

Activity->Activity生命周期和启动模式
<四大组件 android:name"xxx"android:exported"true" // 该组边能够被其他组件启动android:enabled"true" // 该组件能工与用户交互 </四大组件>Activity常用生命周期 启动Activity 2024-05-29 03:53:57.401 21372-21372 yang …...
浅谈网络安全态势感知
前言 网络空间环境日趋复杂,随着网络攻击种类和频次的增加,自建强有力的网络安全防御系统成为一个国家发展战略的一部分,而网络态势感知是实现网络安全主动防御的重要基础和前提。 什么是网络安全态势感知? 态势感知一词来源于对…...

cesium本地文档-天空盒-arcgis切片404-服务查询
1.vite-plugin-cesium // vite-plugin-cesium 是一个 Vite 插件,用于在 Vite 项目中轻松集成和使用 Cesium 地图引擎。它简化了在 Vite 项目中使用 Cesium 的配置和引入过程。 // 具体来说,vite-plugin-cesium 主要提供了以下功能: // 自动…...

OpenMv图片预处理
本博客讲述的是获取一张图片首先对图像进行处理,比如畸形矫正,图像滤波等操作。 1.histeq()自适应直方图均衡 # 自适应直方图均衡例子 # # 此示例展示了如何使用自适应直方图均衡来改善图像中的对比度。 #自适应直方图均衡将图像分割成区域,然后均衡这些区域中的直方图,…...
Springboot 实战运用
一,基本配置 1,pom文件配置介绍 1.1继承 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.2</version><relativePath/> <…...

kafka的安装与简单使用
下载地址:Apache Kafka 1. 上传并解压安装包 tar -zxvf kafka_2.13-3.6.2.tgz 修改文件名:mv kafka_2.13-3.6.2 kafka 2. 配置环境变量 sudo vim /etc/profile #配置kafka环境变量 export KAFKA_HOME/export/server/kafka export PATH$PATH:$KAFKA…...

【服务器部署篇】Linux下Node.js的安装和配置
作者介绍:本人笔名姑苏老陈,从事JAVA开发工作十多年了,带过刚毕业的实习生,也带过技术团队。最近有个朋友的表弟,马上要大学毕业了,想从事JAVA开发工作,但不知道从何处入手。于是,产…...
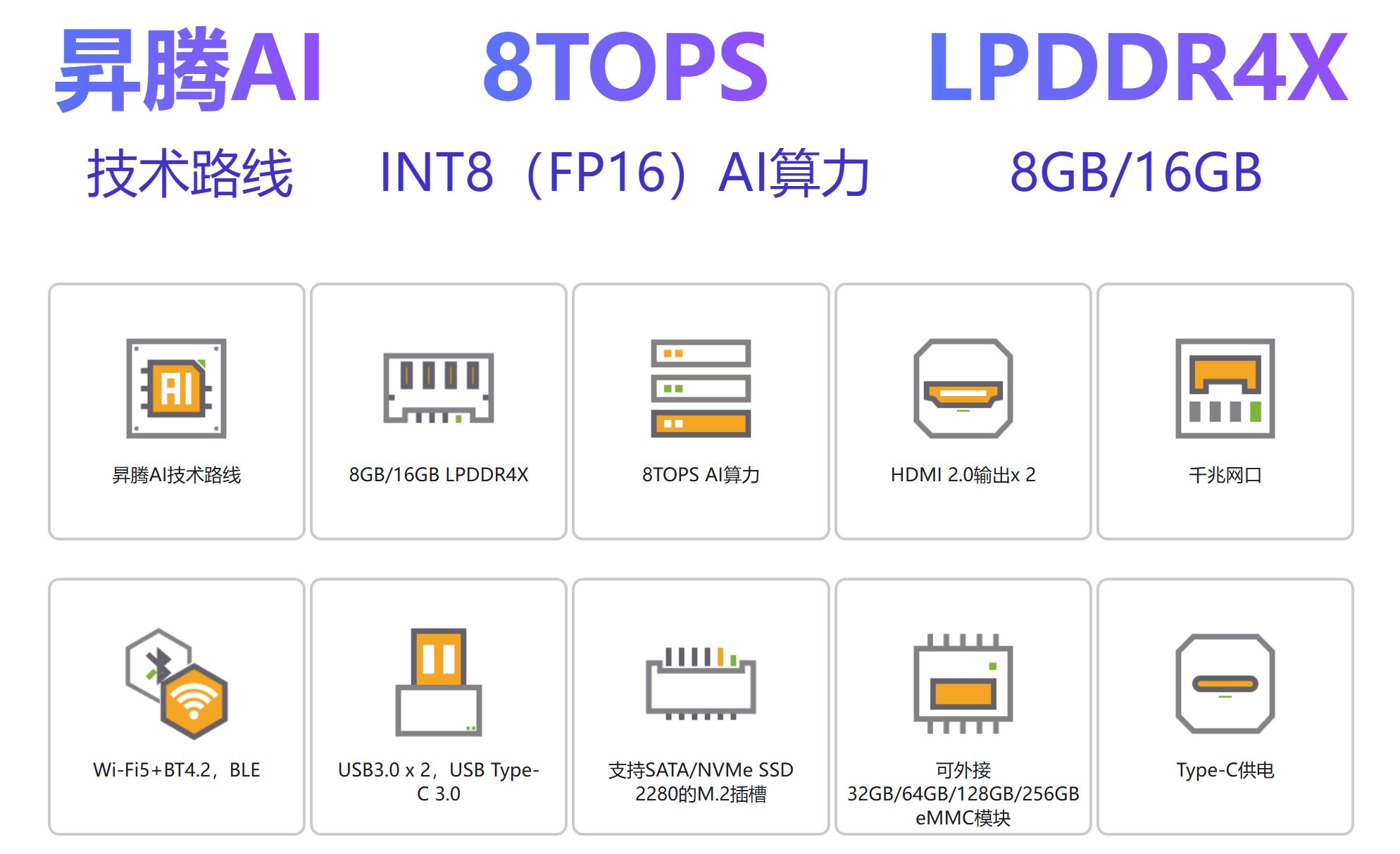
【OrangePi AIpro】香橙派 AIpro 为AI而生
产品简介 OrangePi AIpro(8T):定义边缘智能新纪元的全能开发板 在当今人工智能与物联网技术融合发展的浪潮中,OrangePi AIpro(8T)凭借其强大的硬件配置与全面的接口设计,正逐步成为开发者手中的创新利器。这款开发板不仅代表了香橙派与华为…...

AES算法
收集了几个博主 1、https://blog.csdn.net/shaosunrise/article/details/80219950 2、AESECB加密算法 C 语言代码实现_c语言aes-256-cbc-CSDN博客 3、https://www.cnblogs.com/hello-/articles/8718186.html 4、AES加密过程详解-CSDN博客 5、AES加密算法原理的详细介绍与实…...

自主创新助力科技强军,麒麟信安闪耀第九届军博会
由中国指挥与控制学会主办的中国指挥控制大会暨第九届北京军博会于5月17日-19日在北京国家会议中心盛大开展,政府、军队、武警、公安、交通、人防、航天、航空、兵器、船舶、电科集团等从事国防军工技术与产业领域的30000多名代表到场参加。 麒麟信安作为国产化方案…...

Android Retrofit 封装模版
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、加上网络访问的权限二、引入依赖三、由API生成JavaBean四、封装Retrofit五、调用 一、加上网络访问的权限 <uses-permission android:name"android.p…...

【介绍下运维开发】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

mybatis-plus中多条件查询使用and合or嵌套使用
背景 在实际项目中,数据库条件查询经常需有一些复杂的查询条件的SQL语句,将这些SQL语句用mybatis-plus 组件的实现的时候经常会费一些时间,下面对几种常见的SQL语句实现做个介绍以方便以后遇到时少走弯路提高开发效率。 案例 Data public class User{ …...

冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南
冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南 【免费下载链接】WzComparerR2 Maplestory online Extractor 项目地址: https://gitcode.com/gh_mirrors/wz/WzComparerR2 你是否曾经好奇冒险岛游戏中那些精美的角色装备、华丽的地图场景和丰富的UI界面是…...
:make与makefile)
第9课:Linux开发工具(四):make与makefile
第9课:Linux开发工具(四):make与makefile 一、为什么我们需要 Makefile? 1.1 IDE 背后的秘密 在使用 Visual Studio 等 IDE 时,我们只需按下 F5 或点击"编译"按钮,程序就会自动完成编…...

魔百盒M301H-ZN代工_HI3798MV300H芯片_8822CS无线模块-深度定制与刷机实战指南
1. 魔百盒M301H-ZN硬件拆解与芯片解析 第一次拿到魔百盒M301H-ZN时,我差点被它朴实无华的外表骗了。拆开底部四颗螺丝后,内部布局清晰地展现在眼前:HI3798MV300H主控芯片位于主板中央,右上角是8822CS无线模块,存储芯片…...

AbMole丨Apigenin:天然黄酮化合物在氧化应激中的应用
Apigenin(芹菜素)是一种广泛存在于芹菜、洋甘菊、欧芹等植物中的天然黄酮类化合物[1]。Apigenin(CAS No.:520-36-5)具有多种生物活性,其分子机制涉及对多条细胞信号通路的调控,包括PI3K/AKT/mTO…...

项目烂尾的魔咒:为什么你的物联网系统总是“上线即落后”?
在物联网行业有一个令人沮丧的“3-6-12”现象:3个月调研,6个月开发,12个月后项目烂尾或重构。 为什么投入巨资打造的智慧园区或工业互联系统,往往在验收通过的那一刻,就已经开始走向僵化?问题往往不出在硬…...

基于MCP协议构建AI智能体记忆系统:mnemo-mcp实战指南
1. 项目概述:一个为AI记忆而生的开源工具最近在折腾AI应用开发,特别是围绕大语言模型(LLM)构建智能体(Agent)时,一个绕不开的痛点就是“记忆”。模型本身没有持久化记忆,每次对话都是…...

NLP知识图谱构建实战:从文本到结构化知识的完整流程
1. 项目概述:当NLP遇上知识图谱如果你在NLP(自然语言处理)领域摸爬滚打了一段时间,或者对知识图谱(Knowledge Graph)这个听起来就很有“智慧感”的东西感兴趣,那么你大概率在GitHub上见过或搜索…...

GitHub星标6.6k+的WindTerm,除了快还有这些隐藏技巧:自动补全、锁屏密码重置、主题切换
GitHub星标6.6k的WindTerm高阶技巧:解锁专业级终端体验 当大多数用户还在用默认配置与终端工具"和平共处"时,真正的效率追求者早已开始挖掘那些藏在菜单深处的生产力加速器。作为GitHub上获得6.6k星标的现象级终端工具,WindTerm的…...
)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码) 在5G NR系统中,随机接入过程是终端设备与基站建立连接的关键第一步。而其中ZC序列作为preamble的核心组成部分,其特性直接决定了随机接入的性能…...

Syncia:轻量级本地文件同步引擎的设计原理与实战部署指南
1. 项目概述:一个轻量级、高可用的本地文件同步引擎 最近在折腾个人工作流和跨设备数据同步时,我一直在寻找一个既轻量又可靠、能完全由自己掌控的解决方案。市面上的云盘服务虽然方便,但涉及到隐私、速度限制和订阅费用,总感觉不…...