Elasticsearch 8.1官网文档梳理 - 十三、Search your data(数据搜索)
Search your data
这里有两个比较有用的参数需要注意一下
Search timeout:设置每个分片的搜索超时时间。从集群级别可以通过search.default_search_timeout来设置超时时间。如果在search.default_search_timeout设置的时间段内未完成搜索请求,就会取消该任务。search.default_search_timeout的默认值为-1,表示无超时时间限制。
GET /my-index-000001/_search
{"timeout": "2s","query": {"match": {"user.id": "kimchy"}}
}
track_total_hits:设置搜索过程中匹配文档的数量。如果需要匹配所有文档,track_total_hits设置为true,如果需要匹配的文档为 1000 条,则track_total_hits设置为1000。数据量大时track_total_hits设置为true会拖慢查询速度。
GET my-index-000001/_search
{"track_total_hits": true,"query": {"match" : {"user.id" : "elkbee"}}
}
注意:
这强调一下 Response 中的 took。took 代表处理该请求所耗费的毫秒数。从节点收到查询后开始,到返回客户端之前,包括在线程池中等待、在集群中执行分布式搜索和收集、排序所有结果所花费的时间。
一、Collapse search results
没看懂有啥用呢。。。考完试再研究
二、Filter search results
post_filter:filter过滤会将符合条件的文档留下,之后进行 聚合,而post_filter是在聚合后过滤结果,不影响聚合结果。
# 创建索引,添加数据
PUT /shirts
{"mappings": {"properties": {"brand": { "type": "keyword"},"color": { "type": "keyword"},"model": { "type": "keyword"}}}
}POST /shirts/_bulk
{"index":{}}
{"brand": "gucci", "color": "red", "model": "slim"}
{"index":{}}
{"brand": "gucci", "color": "back", "model": "slim"}
{"index":{}}
{"brand": "gucci", "color": "back", "model": "large"}
直接使用 filter
GET /shirts/_search
{"query": {"bool": {"filter": [{ "term": { "color": "red" }},{ "term": { "brand": "gucci" }}]}},"aggs": {"models": {"terms": { "field": "model" } }}
}

使用 post_filter
GET /shirts/_search
{"post_filter": {"bool": {"filter": [{ "term": { "color": "red" }},{ "term": { "brand": "gucci" }}]}}, "aggs": {"models": {"terms": { "field": "model" } }}
}
rescore:对每个分片的查询结果的前window_size个文档重新评分。
POST /_search
{"query" : {"match" : {"message" : {"operator" : "or","query" : "the quick brown"}}},"rescore" : {"window_size" : 50,"query" : {"rescore_query" : {"match_phrase" : {"message" : {"query" : "the quick brown","slop" : 2}}},"query_weight" : 0.7,"rescore_query_weight" : 1.2}}
}
三、Highlighting
从搜索结果中的一个或多个字段中获取高亮片段,并高亮显示,便于显示查询匹配的位置。
简单一点
GET my_index/_search
{"query": {"match": { "my_text": "GET" }},"highlight": {"fields": {"my_text": {"pre_tags" : ["<em>"], "post_tags" : ["</em>"]}}}
}
高亮显示可让您从搜索结果中的一个或多个字段中获取高亮片段,以便向用户显示查询匹配的位置。
四、Long-running searches
五、Near real-time search
六、Paginate search results
主要描述分页查询和深度查询,其中分页查询通过 from 和 size 来控制,这里将不再赘述。深度查询这里主要通过 Point in time(时间点) 和 Scroll search(滚动查询)这两种方法来实现。文档中更推荐使用 Point in time 配合 search_after 来实现。
- Point in time 配合
search_after实现深度分页查询
# 创建时间点
POST /my-index-000001/_pit?keep_alive=1m# Response
{"id" : "8_LoAwEXa2liYW5hX3NhbXBsZV9kYXRhX2xvZ3MWTThSb1hDMUpSZS1EWnBuSjNtWG1sZwAWUmotTmxzRENUbXVCdGw0YVQyUGJPZwAAAAAAAAAEmBZBYjhlejFTQ1MxaWZLS1VST05NZnhBAAEWTThSb1hDMUpSZS1EWnBuSjNtWG1sZwAA"
}# 利用
GET /_search
{"size": 10,"query": {"term": {"tags.keyword": {"value": "success"}}},"pit": {"id": "8_LoAwEXa2liYW5hX3NhbXBsZV9kYXRhX2xvZ3MWTThSb1hDMUpSZS1EWnBuSjNtWG1sZwAWeGZPTXRkbS1UX3lkd1ZsVzloVnlnZwAAAAAAAAAAfRZGSWlyWklWMlRsT05URnFocm9fakVBAAEWTThSb1hDMUpSZS1EWnBuSjNtWG1sZwAA", "keep_alive": "1m"},"sort": [ {"timestamp": {"order": "asc", "format": "strict_date_optional_time_nanos", "numeric_type" : "date_nanos" }}]
}
- Scroll search(滚动查询)实现深度分页查询
# 创建一个滚动查询
POST /kibana_sample_data_logs/_search?scroll=1m
{"size": 100,"slice": {"id": 0,"max": 2},"query": {"match": {"agent": "Mozilla"}}
}# Response
{"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFkFiOGV6MVNDUzFpZktLVVJPTk1meEEAAAAAAAAE6hZSai1ObHNEQ1RtdUJ0bDRhVDJQYk9n","took" : 5,"timed_out" : false...
}# 通过滚动查询实现深度分页查询
POST /_search/scroll
{"scroll" : "1m", "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFkFiOGV6MVNDUzFpZktLVVJPTk1meEEAAAAAAAAE6hZSai1ObHNEQ1RtdUJ0bDRhVDJQYk9n"
}
七、Retrieve inner hits
八、Retrieve selected fields
九、Search across clusters
十、Search multiple data streams and indices
十一、Search shard routing
十二、Search templates
十三、Sort search results
对返回的结果排序。这里需要注意的是,_score 和 _doc 和 sort 中的被排序的字段的优先级一样,按照在 sort 中的排列顺序来排序。_score 表示文档的相似度得分,_doc 表示 _doc 的写入顺序。
GET /my_index/_search
{"sort" : [{ "@timestamp" : {"order" : "asc", "format": "strict_date_optional_time_nanos"}},{ "my_other_field" : "desc" },{ "my_field": "desc" },"_score","_doc"]
}
也支持对 数组类型的字段进行排序,通过 mode 来选择数组中的值。
十四、kNN search
相关文章:
Elasticsearch 8.1官网文档梳理 - 十三、Search your data(数据搜索)
Search your data 这里有两个比较有用的参数需要注意一下 Search timeout:设置每个分片的搜索超时时间。从集群级别可以通过 search.default_search_timeout 来设置超时时间。如果在 search.default_search_timeout 设置的时间段内未完成搜索请求,就会…...

笔墨挥毫如游龙 最是经典铁线篆——记著名书法家王子彬
真正的书法大家,必是经历了日积月累的求索磨炼,毕竟书法从来都不是一蹴而就的艺术,因此但凡是急功近利者,其人也是远远无法达到书入臻境的创作高度。而纵观当代书坛界内,其中王子彬先生的艺术声誉可谓是广为人知,作为一名深具传统功底的实力派书法大家,王子彬先生的取法历途无疑…...
智慧校园有哪些特征
随着科技的飞速进步,教育领域正经历着一场深刻的变革。智慧校园,作为这场变革的前沿代表,正在逐步重塑我们的教育理念和实践方式。它不仅仅是一个概念,而是一个集成了物联网、大数据、人工智能等先进技术的综合生态系统࿰…...

day25回溯算法part02| 216.组合总和III 17.电话号码的字母组合
216.组合总和III 题目链接/文章讲解 | 视频讲解 class Solution { public:vector<vector<int>> result;vector<int> path;int sum;void backtracking(int n, int k, int startindex) {// int sum accumulate(path.begin(), path.end(), 0);if (sum n &am…...

AWS联网和内容分发服务
概况 VPC Amazon Virtual Private Cloud (Amazon VPC) 让您能够全面地控制自己的虚拟网络环境,包括资源放置、连接性和安全性。首先在 AWS 服务控制台中设置 VPC。然后,向其中添加资源,例如 Amazon Elastic Compute Cloud (EC2) 和 Amazon …...
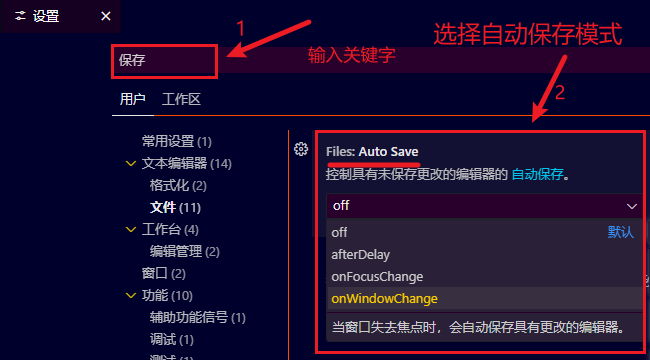
vscode设置编辑器文件自动保存
步骤 1.打开vscode的设置 2.在搜索栏输入关键字“保存”; 在 Files: Auto Save 设置项,选择自动保存的模式...

SJ705C安全帽高温预处理箱
一、仪器用途 安全帽高温预处理箱是我公司根据安全帽新国家标准检测试验要求而自主设计研发制造。是安全帽检测前做高温预处理的专用设备。 二、仪器特征 1、有PID自整定温度控制仪,控制准确。 2、数显计时、计温器。 3、石英灯管加热系统;。 …...
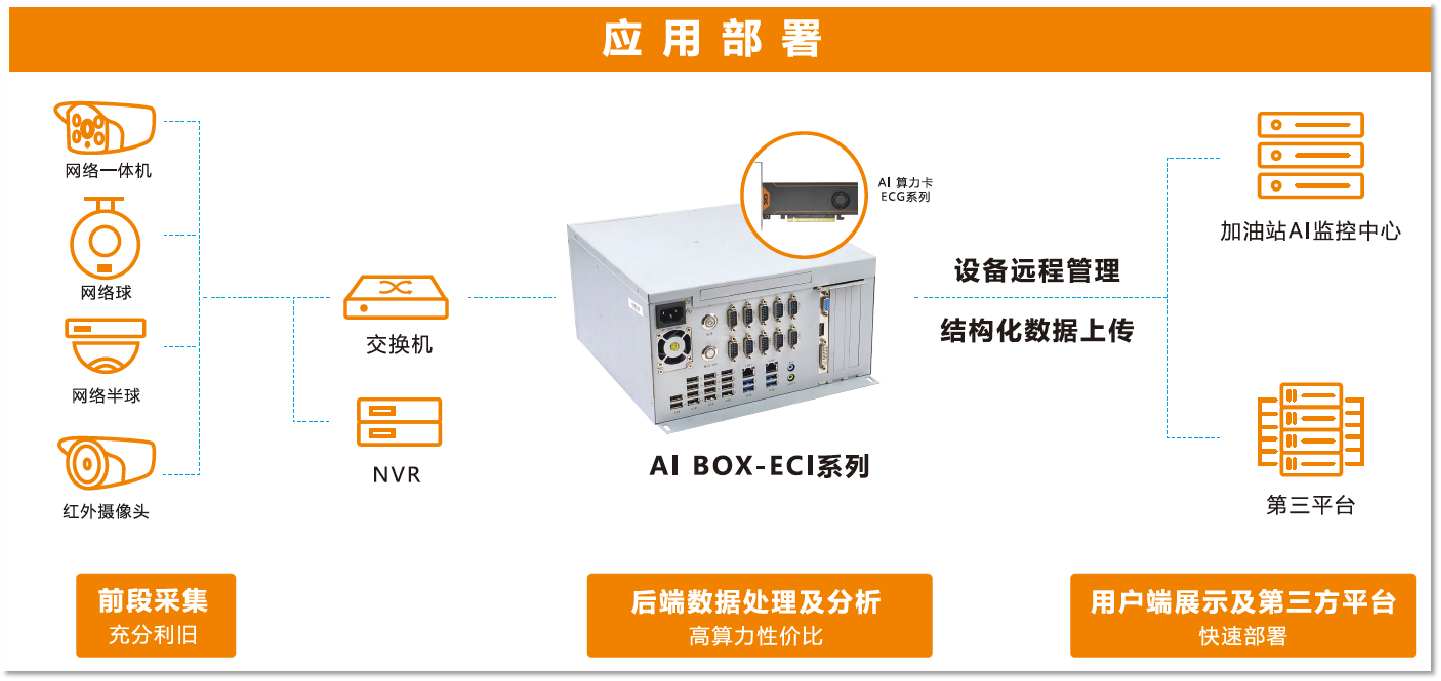
AI盒子在智慧加油站的应用
方案背景 为规范加油站作业,保障人民生命财产安全,《加油站作业安全规范》(AQ 3010-2007)中第五条规定:卸油作业基本要求,明确防静电、防雷电、防火、人员值守、禁止其他车辆及非工作人员进入卸油区。 痛点…...
IC开发——VCS基本用法
1. 简介 VCS是编译型verilog仿真器,处理verilog的源码过程如下: VCS先将verilog/systemverilog文件转化为C文件,在linux下编译链接生成可执行文件,在linux下运行simv即可得到仿真结果。 VCS使用步骤,先编译verilog源…...
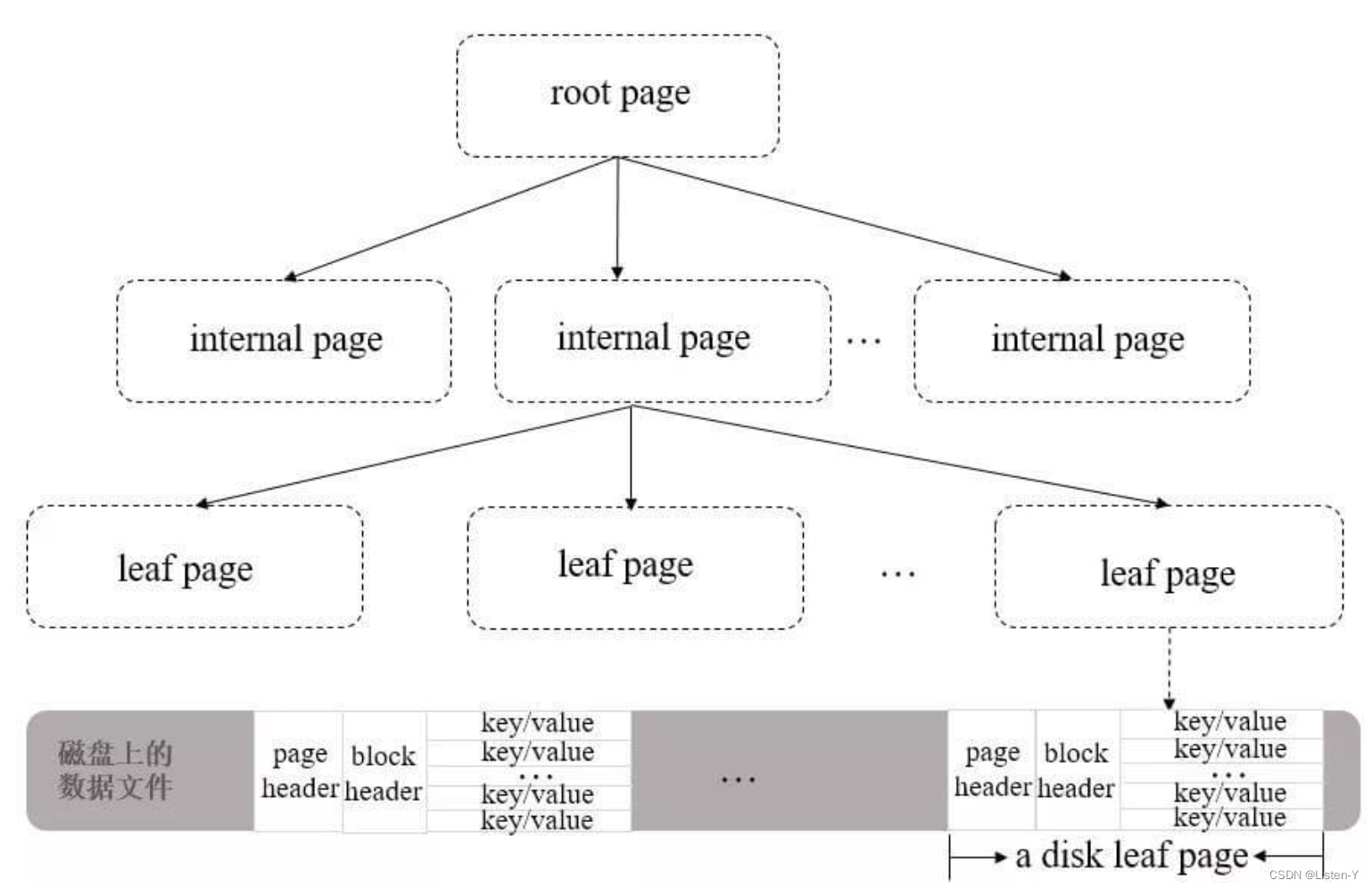
MongoDB~存储引擎了解
存储引擎 存储引擎是一个数据库的核心,主要负责内存、磁盘里数据的管理和维护。 MongoBD的优势,在于其数据模型定义的灵活性、以及可拓展性。但不要忽略,其存储引擎也是插件式的存在,支持不同类型的存储引擎,使用不同…...

JavaScript实现粒子数字倒计时效果附完整注释
<!DOCTYPE html> <html lang="en"><head><meta charset...
机制深度解析)
Dubbo SPI(Service Provider Interface)机制深度解析
Dubbo SPI(Service Provider Interface)机制是Apache Dubbo框架中一项核心的技术组件,它超越了传统Java SPI的范畴,为Dubbo带来了高度的可扩展性和灵活性。在分布式服务架构日益复杂多变的今天,Dubbo SPI机制通过巧妙的…...
常用中间件各版本下载
常用中间件下载地址 前言分布式中间件负载均衡中间件缓存中间件数据库中间件其他中间件1、Maven下载地址2、Git下载地址2、JDK下载地址3、MySQL下载地址4、Redis下载地址5、Nacos下载地址6、Tomcat下载地址7、Nginx下载地址8、RocketMQ下载地址8、RabbitMQ下载地址8、Erlang下载…...

VsCode SSH远程设置不用重复输入密码
winR输入cmd,回车,输入 C:\Users\Administrator> ssh-keygen -t rsa -b 4096 Generating public/private rsa key pair. Enter file in which to save the key (C:\Users\Administrator/.ssh/id_rsa): Enter passphrase (empty for no passphrase): …...

【Linux】:进程切换
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux进程切换的知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精…...

MongoDB CRUD操作:删除文档
MongoDB CRUD操作:删除文档 文章目录 MongoDB CRUD操作:删除文档删除集合的所有文档删除符合条件的所有文件删除第一个符合条件的文档## 在MongoDB Atlas中删除文档删除行为索引 原子性写确认 可以使用下面的方式删除MongoDB集合的文档: 使用…...

SpringBoot集成腾讯COS流程
1.pom.xml中添加cos配置 <!--腾讯cos --> <dependency><groupId>com.qcloud</groupId><artifactId>cos_api</artifactId><version>5.6.28</version> </dependency> 2.application.yaml中添加cos配置 # 腾讯云存储cos…...

中高级前端开发岗
定位: 日常迭代任务的核心研发,具备高质、高效完成迭代任务的能力。 素质要求: 业务专家或擅长某一方向技术;有较丰富的开发经验;需要具备良好的沟通和协作能力,能够与其他部门和团队进行有效的沟通和协…...
idea常用配置
文章目录 I 常见问题1.1 取消maven忽略文件清单1.2 源根之外的java文件1.3 idea取消所有断点1.4 idea使用非模式提交界面1.5 用Service窗口展示所有服务及端口1.6 idea编码问题(加载配置文件失败)II idea 换行后自动缩进4个空格,怎么取消?I 常见问题 1.1 取消maven忽略文件…...

Spring AOP 切面按照一定规则切片并行查询Mapper并返回
需求: 有时候我们在查询mapper层时,有时候可能由于入参数据过大或者查询的范围较大,导致查询性能较慢,此时 我们需要将原本的查询按照一定规则将查询范围进行切面,然后分片查询,最后将查询结果进行组装合并…...

基于APScheduler的定时提醒服务设计与Python实现
1. 项目概述与核心价值最近在折腾一个名为rogerwus/Noonwake_test的项目,这名字乍一看有点神秘,像是某个内部测试或者个人实验性质的仓库。作为一名常年泡在代码仓库里的开发者,我对这类项目标题背后的故事和技术探索总是充满好奇。经过一番深…...

ClawPowers-Skills:开发者实战技能库与个人工具箱构建指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ClawPowers-Skills”,作者是up2itnow0822。乍一看这个标题,你可能会有点摸不着头脑——“ClawPowers”是什么?“Skills”又具体指什么?这其实是一个典…...

AI养老服务兴起:代写回忆录爆火,技术短板与市场乱象待解?
AI正在替人尽孝五六年前,采访北京一家智慧养老院,其为每个房间配智能音箱,用AI陪老人聊天等。今年回访,智能陪伴设备已停用。2023年新技术催生新AI养老服务,如2024年下半年AI代写回忆录风潮,从业者能月入过…...
)
千问 LeetCode 2402.会议室 III public int mostBooked(int n, int[][] meetings)
这道题是经典的会议室 III,核心是双堆模拟,一个堆管空闲会议室(按编号排序),一个堆管正在使用的会议室(按结束时间排序)。解题思路1. 排序:按会议开始时间升序排列。 2. 双堆初始化&…...

程序员35岁转型记:我如何成为AI产品经理?
当“质量守卫者”遇见职业天花板如果你是一名软件测试工程师,你一定熟悉这样的场景:凌晨三点还在盯着自动化脚本的运行日志,白天反复和开发争论一个缺陷的定级,周报里写满了用例覆盖率和漏测率,但晋升答辩时评委却问你…...

告别金融数据壁垒:如何用AKTools一键打通多语言财经数据接口
告别金融数据壁垒:如何用AKTools一键打通多语言财经数据接口 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools 还在为不同编程语言获取…...
从3D打印到智能光效:制作可编程NeoPixel守护者之剑全流程
1. 项目概述:当数字建模遇见智能光效作为一名在创客领域摸爬滚打了十多年的老玩家,我经手过无数个将虚拟想法变为现实的项目。但每次看到那些融合了数字制造与智能交互的作品,比如一把能自己发光的游戏道具,依然会感到兴奋。这不仅…...

对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知 1. 从按需付费到套餐规划的成本视角转变 在直接使用各…...

基于自然语言处理的macOS日历智能助手:原理、实现与定制
1. 项目概述:一个让Mac日历“开口说话”的智能助手最近在折腾个人效率工具,发现一个挺有意思的开源项目,叫macos-calendar-assistant-skill。这名字听起来有点绕,但说白了,它就是一个能让你的Mac日历变得更“聪明”的插…...

AI Coding如何落地APP开发——从个人玩具到公司级降本增效
一、AI 编程能力如何应用到APP开发团队 每天打开新闻都是各种: AI可以取代程序猿、AI可以独立写页面、AI可以独立完成APP,程序员马上要失业了,一个产品经理半天时间就能生成一个带完整页面的活动模块原型;一个运营人员一个小时就…...