神经网络的工程基础(二)——随机梯度下降法|文末送书
相关说明
这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。
本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/stochastic_gradient_descent.ipynb
本文将讨论利用PyTorch实现随机梯度下降法的细节。
关于大语言模型的内容,推荐参考这个专栏。
内容大纲
- 相关说明
- 一、随机梯度下降法:更优化的算法
- 二、算法细节
- 三、代码实现
- 四、粉丝福利
一、随机梯度下降法:更优化的算法
梯度下降法虽然在理论上很美好,但在实际应用中常常会碰到瓶颈。为了说明这个问题,令 L i L_i Li表示模型在 i i i点的损失,即 L i = ( y i − a x i − b ) 2 L_i = (y_i - ax_i - b)^2 Li=(yi−axi−b)2,对所有数据点的损失求和后,可以得到整体损失函数: L = 1 ⁄ n ∑ i L i L = 1⁄n ∑_iL_i L=1⁄n∑iLi 。即模型的损失函数实际上是各个数据点损失的平均值,这一观点适用于大多数模型 1。
计算整体损失函数 L L L的梯度可得, ∇ L = 1 ⁄ n ∑ i L i ∇L = 1⁄n \sum_i L_i ∇L=1⁄n∑iLi。也就是说,损失函数的梯度等于所有数据点处梯度的平均值。但是在实际应用中,通常会使用大型数据集计算所有数据点的梯度和,这需要相当长的时间。为了加速这个计算过程,可以考虑使用随机梯度下降法(Stochastic Gradient Descent,SGD)。
二、算法细节
随机梯度下降法的核心思想是:每次迭代时只随机选择小批量的数据点来计算梯度,然后用这个小批量数据点的梯度平均值来代替整体损失函数的梯度2。
为了使算法的细节更加准确,引入一个超参数,称为批量大小(Batch Size),记作m。每次随机选取m个数据,记为 I 1 , I 2 , ⋯ , I m I_1,I_2,⋯,I_m I1,I2,⋯,Im。使用这些数据点的梯度平均值来近似代替整体损失函数的梯度: ∇ L = 1 ⁄ n ∑ i ∇ L i ≈ 1 ⁄ m ∑ j = 1 m ∇ L I j ∇L = 1⁄n ∑_i∇L_i ≈ 1⁄m ∑_{j = 1}^m∇L_{I_j } ∇L=1⁄n∑i∇Li≈1⁄m∑j=1m∇LIj 。由此得到新的参数迭代公式:
a k + 1 = a k − η / m ∑ j = 1 m ∂ L I j / ∂ a b k + 1 = b k − η / m ∑ j = 1 m ∂ L I j / ∂ b (1) a_{k + 1} = a_k - η/m ∑_{j = 1}^m∂L_{I_j }/∂a \\ b_{k + 1} = b_k -η/m ∑_{j = 1}^m∂L_{I_j }/∂b \tag{1} ak+1=ak−η/mj=1∑m∂LIj/∂abk+1=bk−η/mj=1∑m∂LIj/∂b(1)
在随机梯度下降法中,所有数据点都使用了一遍,称为模型训练了一轮。由此在实际应用中常使用另一个超参数——训练轮次(Epoch),表示所有数据将被用几遍,用于控制随机梯度下降法的循环次数。换句话说,就是公式(1)被迭代运算多少次。
在一些机器学习书籍和学术文献中,还对随机梯度下降法(当m=1时)和小批量梯度下降法(当m>1时)进行了进一步的区分。然而,这两种方法之间的区别并不大,其核心思想都是基于随机采样来近似计算梯度,从而高效地更新参数、优化模型。在实际应用中,会根据问题的性质和数据规模选择合适的批次大小,以获得最佳的训练效果。因此,本书将统一使用随机梯度下降法来代表这一类方法,以保持概念清晰和简洁。
与梯度下降法相比,随机梯度下降法更高效,这是因为小批量梯度计算比整体梯度计算快得多。尽管在随机梯度下降法中,采用小批量数据估计梯度可能会引入一些噪声,但实践证明这些噪声对整个优化过程有好处,有助于模型克服局部最优的“陷阱”,逐步逼近全局最优参数。
三、代码实现
随机梯度下降法的实现与梯度下降法类似,不同之处在于,每次计算梯度时需要“随机”选取一部分数据,具体的实现步骤可以参考程序清单1(完整代码)。
- 在程序清单1的第2行,引入一个名为batch_size的超参数,用于控制每个批次中的数据量大小。选择合适的batch_size对算法的运行效率和稳定性至关重要。如果参数设置过大,可能会导致算法运行效率下降;而过小的参数可能使算法变得过于随机,影响收敛的稳定性。选择合适的参数需要结合具体的模型和应用场景,结合相关领域的经验进行决策。
- 在程序清单1的第11—13行,展示了一种随机选取批次数据的实现方式。这也是随机梯度下降法与普通梯度下降法的主要区别之一。实现随机性的方式有很多种,比如引入随机数等。这里仅呈现一种经典方法:将数据按顺序划分成批次。
1 | # 定义每批次用到的数据量2 | batch_size = 203 | # 定义模型4 | model = Linear()5 | # 确定最优化算法6 | learning_rate = 0.17 | optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)8 | 9 | for t in range(20):
10 | # 选取当前批次的数据,用于训练模型
11 | ix = (t * batch_size) % len(x)
12 | xx = x[ix: ix + batch_size]
13 | yy = y[ix: ix + batch_size]
14 | yy_pred = model(xx)
15 | # 计算当前批次数据的损失
16 | loss = (yy - yy_pred).pow(2).mean()
17 | # 将上一次的梯度清零
18 | optimizer.zero_grad()
19 | # 计算损失函数的梯度
20 | loss.backward()
21 | # 迭代更新模型参数的估计值
22 | optimizer.step()
23 | # 注意!loss记录的是模型在当前批次数据上的损失,该数值的波动较大
24 | print(f'Step {t + 1}, Loss: {loss: .2f}; Result: {model.string()}')
在随机梯度下降法的执行过程中,通常使用模型的整体损失作为指标来监测算法的运行情况。但要注意的是,程序清单1中第16行定义的loss表示模型在小批量数据上的损失,这个值仅依赖于少量数据,迭代过程中会表现出极大的不稳定性,因此并不适合作为评估算法运行情况的主要标志。
如果希望更准确地监测算法的运行情况,需要在更大的数据集上估计模型的整体损失,例如在全部训练数据上计算损失,如图1所示。这种评估方式更稳定,能够更全面地反映模型的训练进展。

四、粉丝福利
参与方式:关注博主、点赞、收藏、评论区评论“解构大语言模型”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
本次送书数量不少于3本,【阅读量越多,送得越多】
活动结束后,会私信中奖粉丝,请各位注意查看私信哦~
活动截止时间:2024-05-24 24:00:00
对于解决回归问题的模型,这个结论显然成立。对于解决分类问题的模型(比如逻辑回归模型),只需对模型的似然函数做简单的数学变换(先求对数,再求相反数),就可以得到同样的结论。 ↩︎
这在数学上是完全合理的。从统计的角度来看,用所有数据点求平均值,并不比随机抽样的方法高明很多。与线性回归参数估计值类似,两个结果都是随机变量:它们都以真实梯度为期望,只是前者的置信区间更小。 ↩︎
相关文章:
神经网络的工程基础(二)——随机梯度下降法|文末送书
相关说明 这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。 本文涉及到的代码链接如下:regression2chatgpt/ch06_optimizer/stochastic_gradient_descent.ipynb 本文将讨论利用…...

常见的几种编码方式
常见的编码方式及其特点: 编码方式的设计是为了适应不同的字符集和应用需求,因此它们在表示字符时使用的位数和字节数各不相同 常见编码方式及其位数和字节数 ASCII(American Standard Code for Information Interchange)&#x…...
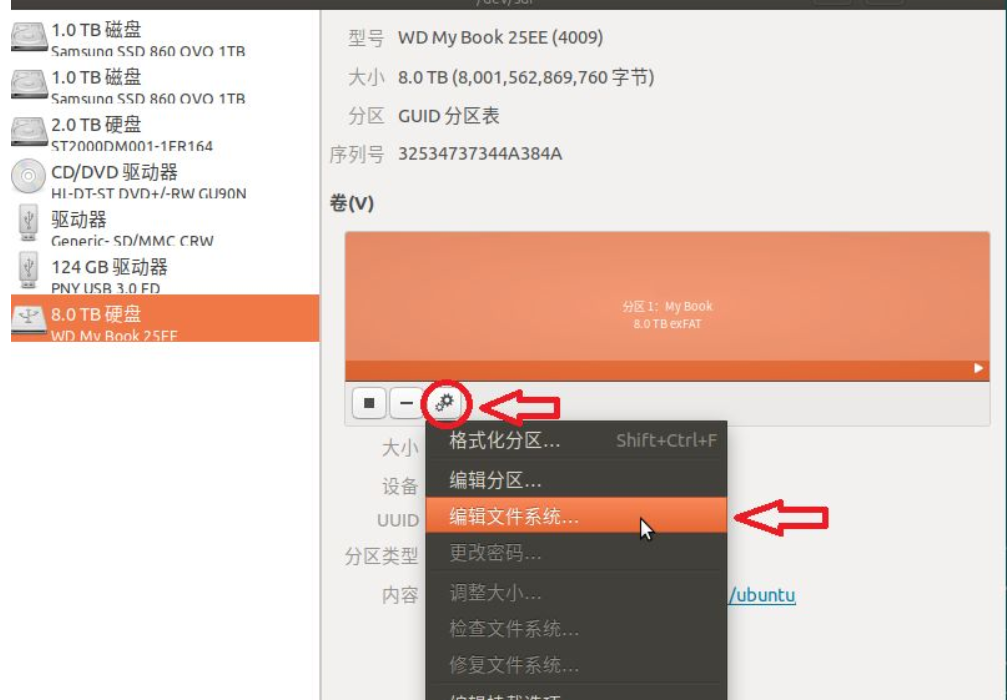
ubuntu移动硬盘重命名
因为在ubuntu上移动硬盘的名字是中文的,所以想要改成英文的。 我的方法: 将移动硬盘插到windows上,直接右键重命名。再插到ubuntu上名字就改变了。 别人的方法: ubuntu下如何修改U盘名字-腾讯云开发者社区-腾讯云 在自带的软件…...

VUE框架前置知识总结
一、前言 在学习vue框架中,总是有些知识不是很熟悉,又不想系统的学习JS,因为学习成本太大了,所以用到什么知识就学习什么知识。此文档就用于记录零散的知识点。主要是还是针对与ES6规范的JS知识点。 以下实验环境都是在windows环…...

张宇1000题80%不会?别急,这个方法肯定有用!
这太正常了,1000题的难度本来就高,不要慌 我考研的时候跟的也是张宇老师,但是1000题我根本就没做几道题就给换成880题660题了,而且只是强化阶段用880题,基础阶段我用的都是汤家凤的1800题。 不要担心做的不是张宇老师…...

【python】爬虫记录每小时金价
数据来源: https://www.cngold.org/img_date/ 因为这个网站是数据随时变动的,用requests、BeautifulSoup的方式解析html的话,数据的位置显示的是“--”,并不能取到数据。 所以采用webdriver访问网站,然后从界面上获取…...
一行命令将已克隆的本地Git仓库推送到内网服务器
一、需求背景 我们公司用gitea搭建了一个git服务器,其中支持win7的最高版本是v1.20.6。 我们公司的电脑在任何时候都不能连接外网,但是希望将一些开源的仓库移植到内网的服务器来。一是有相关代码使用的需求,二是可以建设一个内网能够查阅的…...

Linux文本处理三剑客(详解)
一、文本三剑客是什么? 1. 对于接触过Linux操作系统的人来说,应该都听过说Linux中的文本三剑客吧,即awk、grep、sed,也是必须要掌握的Linux命令之一,三者都是用来处理文本的,但侧重点各不相同,a…...
AI在线UI代码生成,不需要敲一行代码,聊聊天,上传图片,就能生成前端页面的开发神器
ioDraw的在线UI代码生成器是一款开发神器,它可以让您在无需编写一行代码的情况下创建前端页面。 主要优势: 1、极简操作:只需聊天或上传图片,即可生成响应式的Tailwind CSS代码。 2、节省时间:自动生成代码可以节省大…...

go-zero整合单机版ClickHouse并实现增删改查
go-zero整合单机版ClickHouse并实现增删改查 本教程基于go-zero微服务入门教程,项目工程结构同上一个教程。 本教程主要实现go-zero框架整合单机版ClickHouse,并暴露接口实现对ClickHouse数据的增删改查。 go-zero微服务入门教程:https://b…...
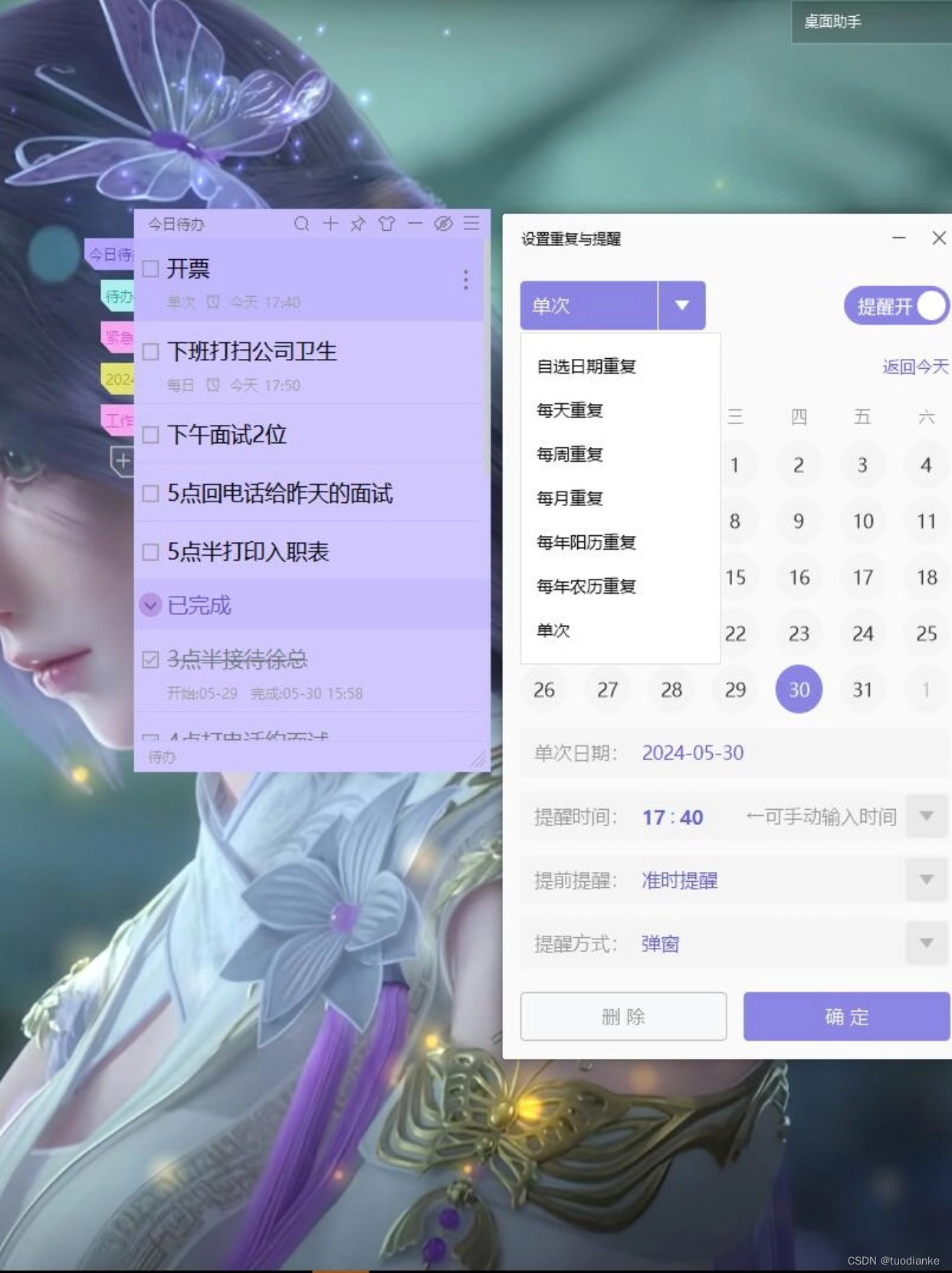
行政工作如何提高效率?桌面备忘录便签软件哪个好
在行政管理工作中,效率的提高无疑是每个行政人员都追求的目标。而随着科技的发展,各种便捷的工具也应运而生,其中桌面备忘录便签软件便是其中的佼佼者。那么,这类软件又如何帮助我们提高工作效率呢? 首先,…...

利用向日葵和微信/腾讯会议实现LabVIEW远程开发
利用向日葵远程控制软件结合微信或腾讯会议的视频通话功能,可以实现LabVIEW的远程开发和调试。通过向日葵进行远程桌面访问,配合视频通话工具进行实时沟通与问题解决,不仅提高了开发效率,还减少了地域限制带来的不便。介绍这种远程…...
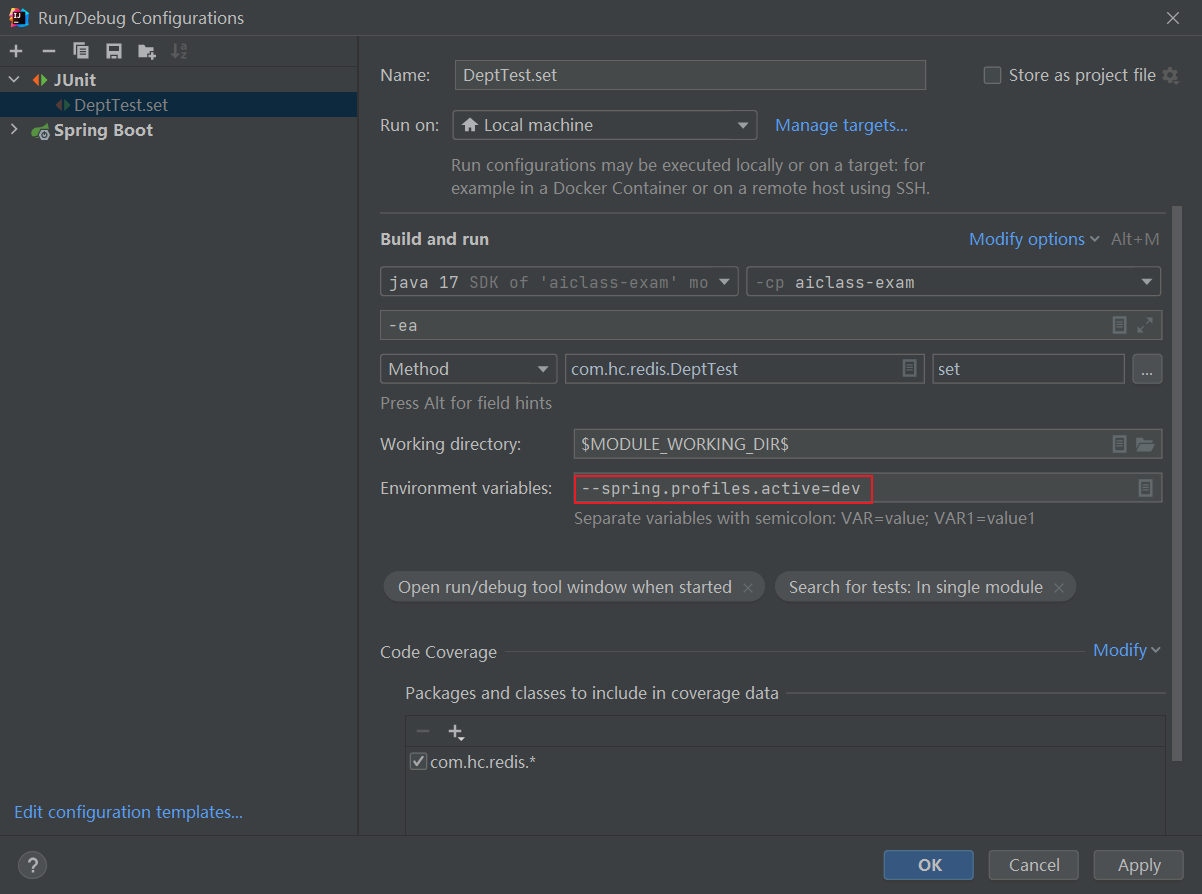
SpringBoot 单元测试 指定 环境
如上图所示,在配置窗口中添加--spring.profiles.activedev,就可以了。...

Flutter 中的 SliverOpacity 小部件:全面指南
Flutter 中的 SliverOpacity 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,由 Google 开发,允许开发者使用 Dart 语言来构建高性能、美观的跨平台应用。在 Flutter 的滚动组件体系中,SliverOpacity 是一个用来为其子 Slive…...

源码分析の前言
源码分析路线图: 初级部分:ArrayList->LinkedList->Vector->HashMap(红黑树数据结构,如何翻转,变色,手写红黑树)->ConcurrentHashMap 中级部分:Spring->Spring MVC->Spring Boot->M…...
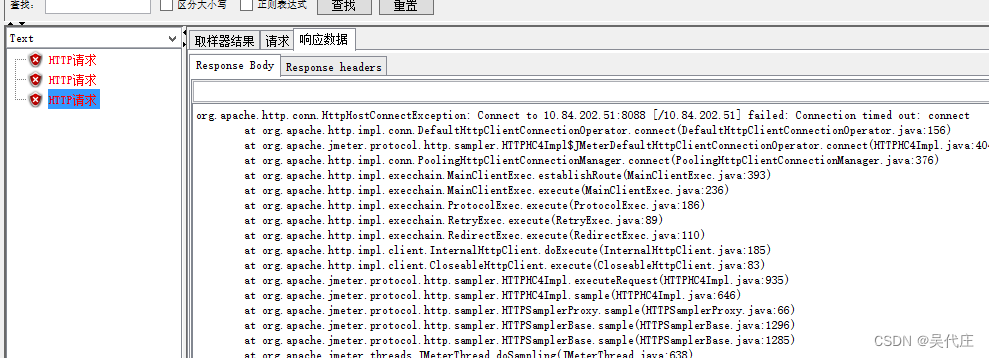
接口性能测试复盘:解决JMeter超时问题的实践
在优化接口并重新投入市场后,我们面临着一项关键任务:确保其在高压环境下稳定运行。于是,我们启动了一轮针对该接口的性能压力测试,利用JMeter工具模拟高负载场景。然而,在测试进行约一分钟之后,频繁出现了…...

[数据集][目标检测]猕猴桃检测数据集VOC+YOLO格式1838张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1838 标注数量(xml文件个数):1838 标注数量(txt文件个数):1838 标注…...
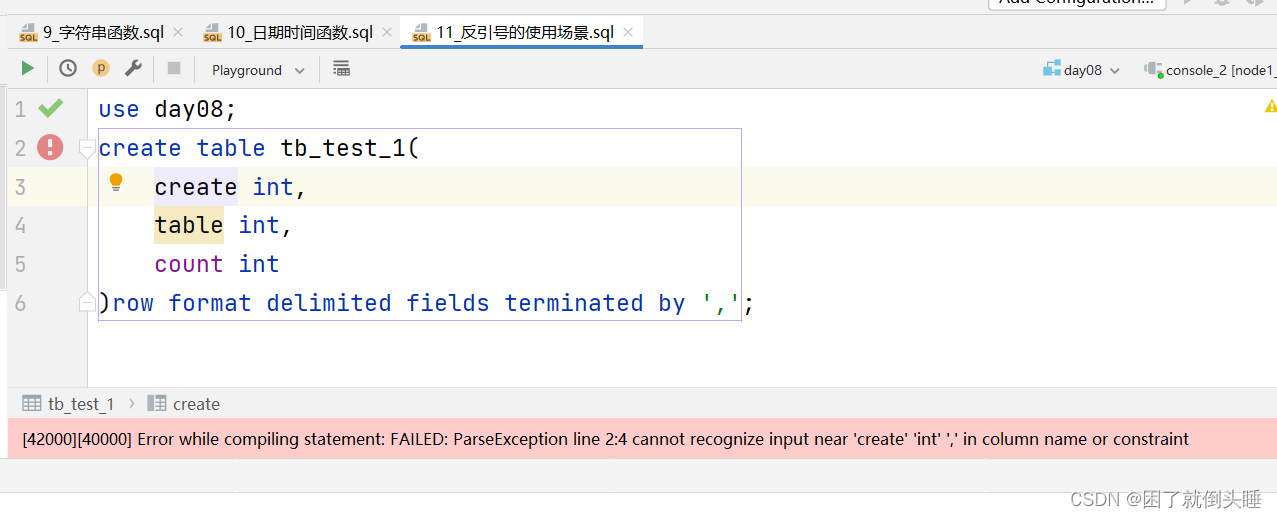
摸鱼大数据——Hive函数7-9
7、日期时间函数 Hive函数链接:LanguageManual UDF - Apache Hive - Apache Software Foundation SimpleDateFormat (Java Platform SE 8 ) current_timestamp: 获取时间原点到现在的秒/毫秒,底层自动转换方便查看的日期格式 常用 to_date: 字符串格式时间…...

python连接数据库
python连接MYSQL、postgres、oracle等的基本操作 python连接mysql MySQLdb MySQLdb又叫MySQL-python ,是 Python 连接 MySQL 的一个驱动,很多框架都也是基于此库进行开发,只支持 Python2.x,而且安装的时候有很多前置条件&#…...

能不能接受这些坑?买电车前一定要看
图片来源:汽车之家 文 | Auto芯球 作者 | 雷慢 刚有个朋友告诉我,买了电车后感觉被骗了, 很多“坑”都是他买车后才知道的。 不提前研究,不做功课,放着我这个老司机不请教, 这个大冤种他不当谁当&…...

Cursor Pro功能完全解锁指南:三步实现免费无限使用体验
Cursor Pro功能完全解锁指南:三步实现免费无限使用体验 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

Mulch:轻量级声明式Docker编排工具,简化单机应用部署与管理
1. 项目概述与核心价值最近在折腾一个自托管的小型服务器,主要用来跑一些个人项目、家庭媒体服务和自动化脚本。随着服务越装越多,一个老问题又浮出水面:如何高效、安全地管理这些应用?传统的做法要么是手动安装配置,过…...

Lightweight Charts:高性能金融图表库的架构哲学与技术实现
Lightweight Charts:高性能金融图表库的架构哲学与技术实现 【免费下载链接】lightweight-charts Performant financial charts built with HTML5 canvas 项目地址: https://gitcode.com/gh_mirrors/li/lightweight-charts 在金融数据可视化领域,…...

从零到一:手把手部署openGauss极简版并完成基础运维
1. 环境准备:从零搭建openGauss的基石 第一次接触openGauss时,我被它"极简版"的宣传吸引,但真正动手部署才发现,前期环境准备才是决定成败的关键。就像盖房子需要打地基,数据库安装前的系统配置直接影响后续…...

PearProject梨子项目:如何快速搭建轻量级远程协作系统的完整指南
PearProject梨子项目:如何快速搭建轻量级远程协作系统的完整指南 【免费下载链接】pearProject pear,梨子,轻量级的在线项目/任务协作系统,远程办公协作 项目地址: https://gitcode.com/gh_mirrors/pe/pearProject PearPro…...

Angular 响应式原理深度解析:核心机制与源码解读
一、前言Angular 响应式原理深度解析:核心机制与源码解读。本文深入源码层面,剖析核心设计原理,帮你从"会用"升级到"精通"。二、核心原理深度剖析2.1 数据结构设计// Angular 核心数据结构与算法 // 理解 Angular 的底层…...

Code-Captain:一体化开发工作流自动化工具的设计与实践
1. 项目概述:一个为开发者打造的“全能副驾”最近在 GitHub 上看到一个挺有意思的项目,叫devobsessed/code-captain。光看这个名字,你可能会联想到“代码船长”或者“开发指挥官”之类的形象。没错,这个项目的核心定位,…...
CircuitPython硬件交互实战:从数字I/O到NeoPixel灯带控制
1. 项目概述如果你刚开始接触嵌入式硬件开发,面对一堆引脚、传感器和电机,可能会觉得有点无从下手。我刚开始玩Arduino和树莓派Pico的时候,也是这种感觉,总觉得底层寄存器、数据手册太复杂。直到后来用上了CircuitPythonÿ…...

3步免费解锁WeMod完整功能:WandEnhancer终极使用指南
3步免费解锁WeMod完整功能:WandEnhancer终极使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod的高级功能付费而烦恼吗&am…...

VRLog透明选民数据库的密码学实现与应用
1. VRLog系统概述:透明选民数据库的密码学实现VRLog是一种基于可验证注册表(Verifiable Registry)架构设计的透明选民数据库系统,其核心目标是通过密码学方法解决传统选民登记系统中的数据完整性和可验证性问题。在现实选举场景中…...