opencv进阶 ——(九)图像处理之人脸修复祛马赛克算法CodeFormer
算法简介
CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.com/sczhou/CodeFormer
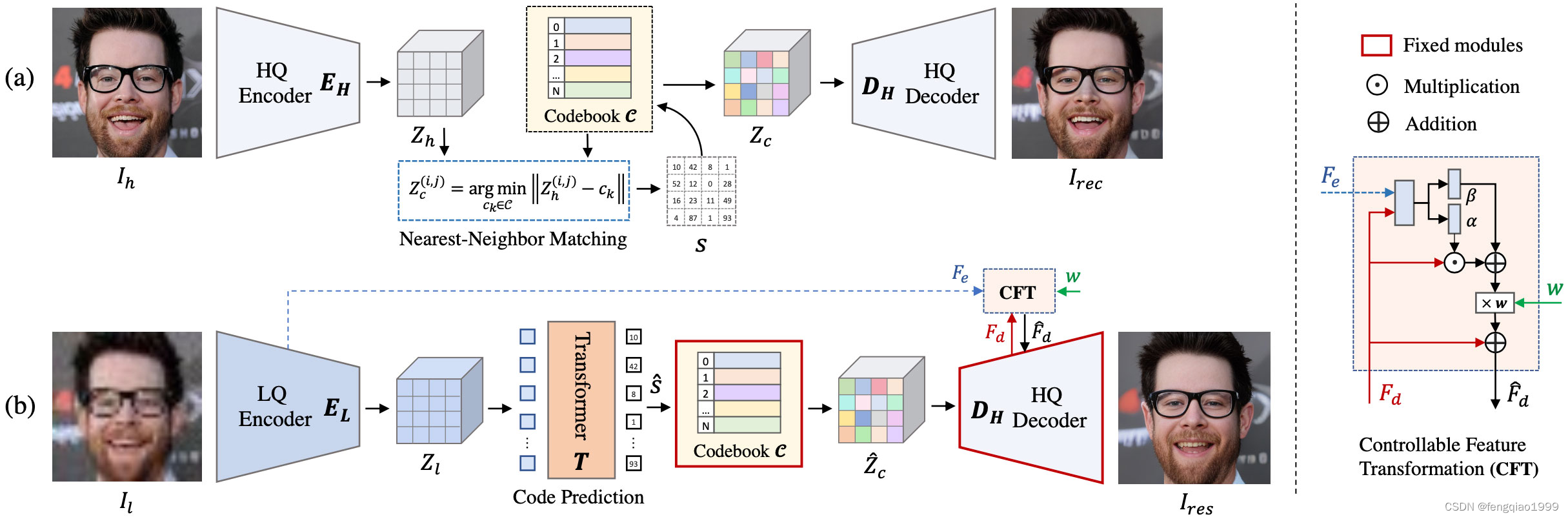
Face Restoration

Face Color Enhancement and Restoration

Face Inpainting

模型部署
如果想用C++进行模型推理部署,首先要把模型转换成onnx,转成onnx就可以使用onnxruntime c++库进行部署,或者使用OpenCV的DNN也可以。
1、可在以下地址下载模型:https://github.com/sczhou/CodeFormer/releases/tag/v0.1.0
2、下载CodeFormer源码,在工程目录下添加onnx转换python代码
import torch
from basicsr.utils.registry import ARCH_REGISTRYif __name__ == '__main__':device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')net = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9, connect_list=['32', '64', '128', '256']).to(device)# ckpt_path = 'weights/CodeFormer/codeformer.pth'ckpt_path = './codeformer.pth'checkpoint = torch.load(ckpt_path)['params_ema']net.load_state_dict(checkpoint)net.eval()input_tensor = torch.zeros((1, 3, 512, 512)).to(device)torch.onnx.export(net, # 模型实例input_tensor, # 输入张量"./codeformer.onnx", # 输出的ONNX模型路径export_params=True, # 是否包含模型参数opset_version=11, # ONNX操作集版本do_constant_folding=True, # 是否进行常量折叠优化input_names=['input'], # 输入名称output_names=['output'], # 输出名称dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}} # 声明动态轴)
3、采用onnxruntime加载模型,示例代码如下
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <fstream>
#include <numeric>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
//#include <cuda_provider_factory.h> ///nvidia-cuda加速
#include <onnxruntime_cxx_api.h>using namespace cv;
using namespace std;
using namespace Ort;class CodeFormer
{
public:CodeFormer(string modelpath);Mat detect(Mat cv_image);
private:void preprocess(Mat srcimg);vector<float> input_image_;vector<double> input2_tensor;int inpWidth;int inpHeight;int outWidth;int outHeight;float min_max[2] = { -1,1 };//存储初始化获得的可执行网络Env env = Env(ORT_LOGGING_LEVEL_ERROR, "CodeFormer");Ort::Session *ort_session = nullptr;SessionOptions sessionOptions = SessionOptions();vector<char*> input_names;vector<char*> output_names;vector<vector<int64_t>> input_node_dims; // >=1 outputsvector<vector<int64_t>> output_node_dims; // >=1 outputs
};CodeFormer::CodeFormer(string model_path)
{//OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); ///nvidia-cuda加速sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);std::wstring widestr = std::wstring(model_path.begin(), model_path.end()); ///如果在windows系统就这么写ort_session = new Session(env, widestr.c_str(), sessionOptions); ///如果在windows系统就这么写///ort_session = new Session(env, model_path.c_str(), sessionOptions); ///如果在linux系统,就这么写size_t numInputNodes = ort_session->GetInputCount();size_t numOutputNodes = ort_session->GetOutputCount();AllocatorWithDefaultOptions allocator;for (int i = 0; i < numInputNodes; i++){input_names.push_back(ort_session->GetInputName(i, allocator));Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();auto input_dims = input_tensor_info.GetShape();input_node_dims.push_back(input_dims);}for (int i = 0; i < numOutputNodes; i++){output_names.push_back(ort_session->GetOutputName(i, allocator));Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();auto output_dims = output_tensor_info.GetShape();output_node_dims.push_back(output_dims);}this->inpHeight = input_node_dims[0][2];this->inpWidth = input_node_dims[0][3];this->outHeight = output_node_dims[0][2];this->outWidth = output_node_dims[0][3];input2_tensor.push_back(0.5);
}void CodeFormer::preprocess(Mat srcimg)
{Mat dstimg;cvtColor(srcimg, dstimg, COLOR_BGR2RGB);resize(dstimg, dstimg, Size(this->inpWidth, this->inpHeight), INTER_LINEAR);this->input_image_.resize(this->inpWidth * this->inpHeight * dstimg.channels());int k = 0;for (int c = 0; c < 3; c++){for (int i = 0; i < this->inpHeight; i++){for (int j = 0; j < this->inpWidth; j++){float pix = dstimg.ptr<uchar>(i)[j * 3 + c];this->input_image_[k] = (pix / 255.0 - 0.5) / 0.5;k++;}}}
}Mat CodeFormer::detect(Mat srcimg)
{int im_h = srcimg.rows;int im_w = srcimg.cols;this->preprocess(srcimg);array<int64_t, 4> input_shape_{ 1, 3, this->inpHeight, this->inpWidth };vector<int64_t> input2_shape_ = { 1 };auto allocator_info = MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);vector<Value> ort_inputs;ort_inputs.push_back(Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape_.data(), input_shape_.size()));ort_inputs.push_back(Value::CreateTensor<double>(allocator_info, input2_tensor.data(), input2_tensor.size(), input2_shape_.data(), input2_shape_.size()));vector<Value> ort_outputs = ort_session->Run(RunOptions{ nullptr }, input_names.data(), ort_inputs.data(), ort_inputs.size(), output_names.data(), output_names.size());post_processfloat* pred = ort_outputs[0].GetTensorMutableData<float>();//Mat mask(outHeight, outWidth, CV_32FC3, pred); /经过试验,直接这样赋值,是不行的const unsigned int channel_step = outHeight * outWidth;vector<Mat> channel_mats;Mat rmat(outHeight, outWidth, CV_32FC1, pred); // RMat gmat(outHeight, outWidth, CV_32FC1, pred + channel_step); // GMat bmat(outHeight, outWidth, CV_32FC1, pred + 2 * channel_step); // Bchannel_mats.push_back(rmat);channel_mats.push_back(gmat);channel_mats.push_back(bmat);Mat mask;merge(channel_mats, mask); // CV_32FC3 allocated///不用for循环遍历Mat里的每个像素值,实现numpy.clip函数mask.setTo(this->min_max[0], mask < this->min_max[0]);mask.setTo(this->min_max[1], mask > this->min_max[1]); 也可以用threshold函数,阈值类型THRESH_TOZERO_INVmask = (mask - this->min_max[0]) / (this->min_max[1] - this->min_max[0]);mask *= 255.0;mask.convertTo(mask, CV_8UC3);cvtColor(mask, mask, COLOR_BGR2RGB);return mask;
}int main()
{CodeFormer mynet("codeformer.onnx");string imgpath = "input.png";Mat srcimg = imread(imgpath);Mat dstimg = mynet.detect(srcimg);resize(dstimg, dstimg, Size(srcimg.cols, srcimg.rows), INTER_LINEAR);//imwrite("result.jpg", dstimg)namedWindow("srcimg", WINDOW_NORMAL);imshow("srcimg", srcimg);namedWindow("dstimg", WINDOW_NORMAL);imshow("dstimg", dstimg);waitKey(0);destroyAllWindows();
}效果展示
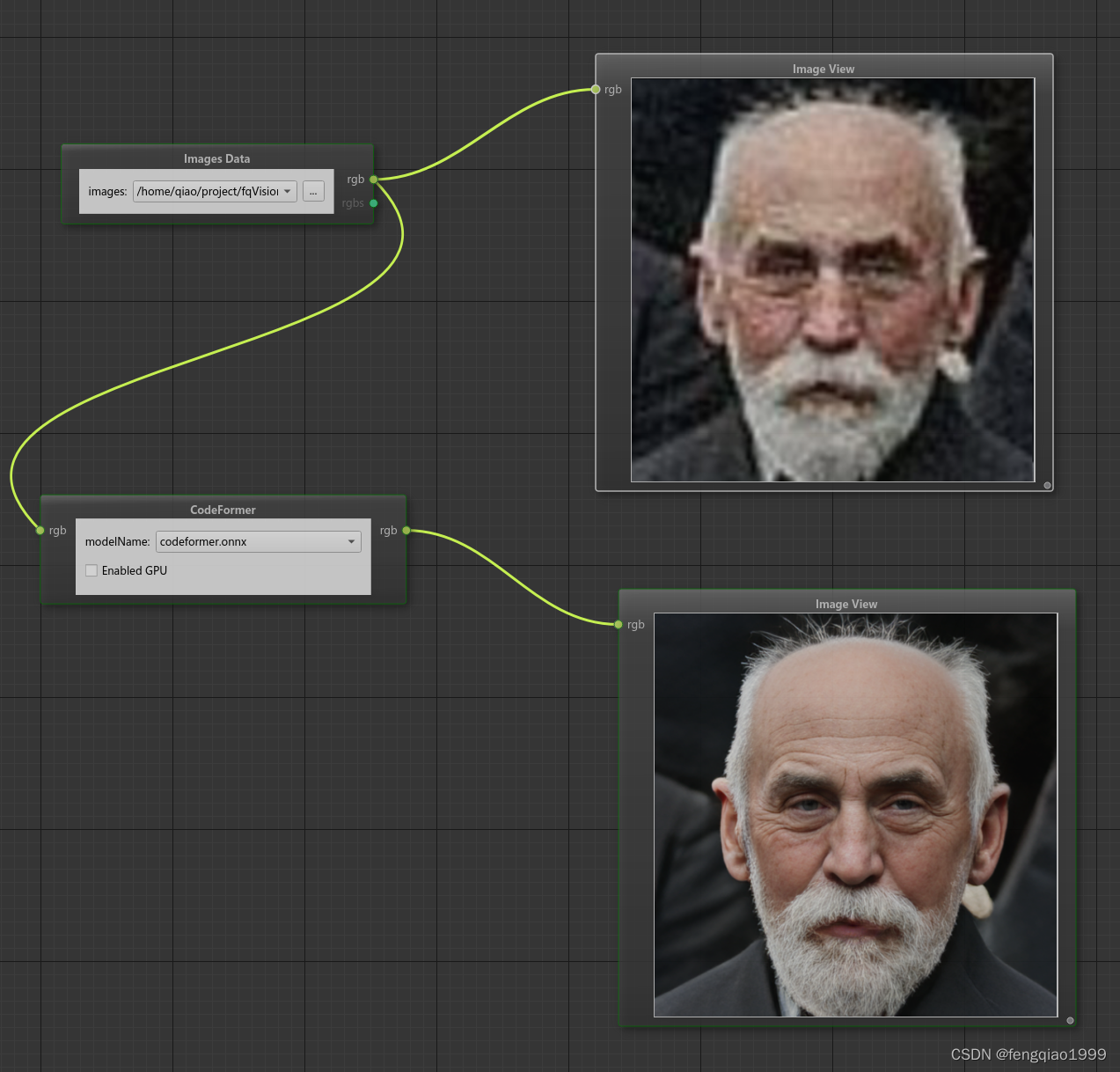
面部恢复
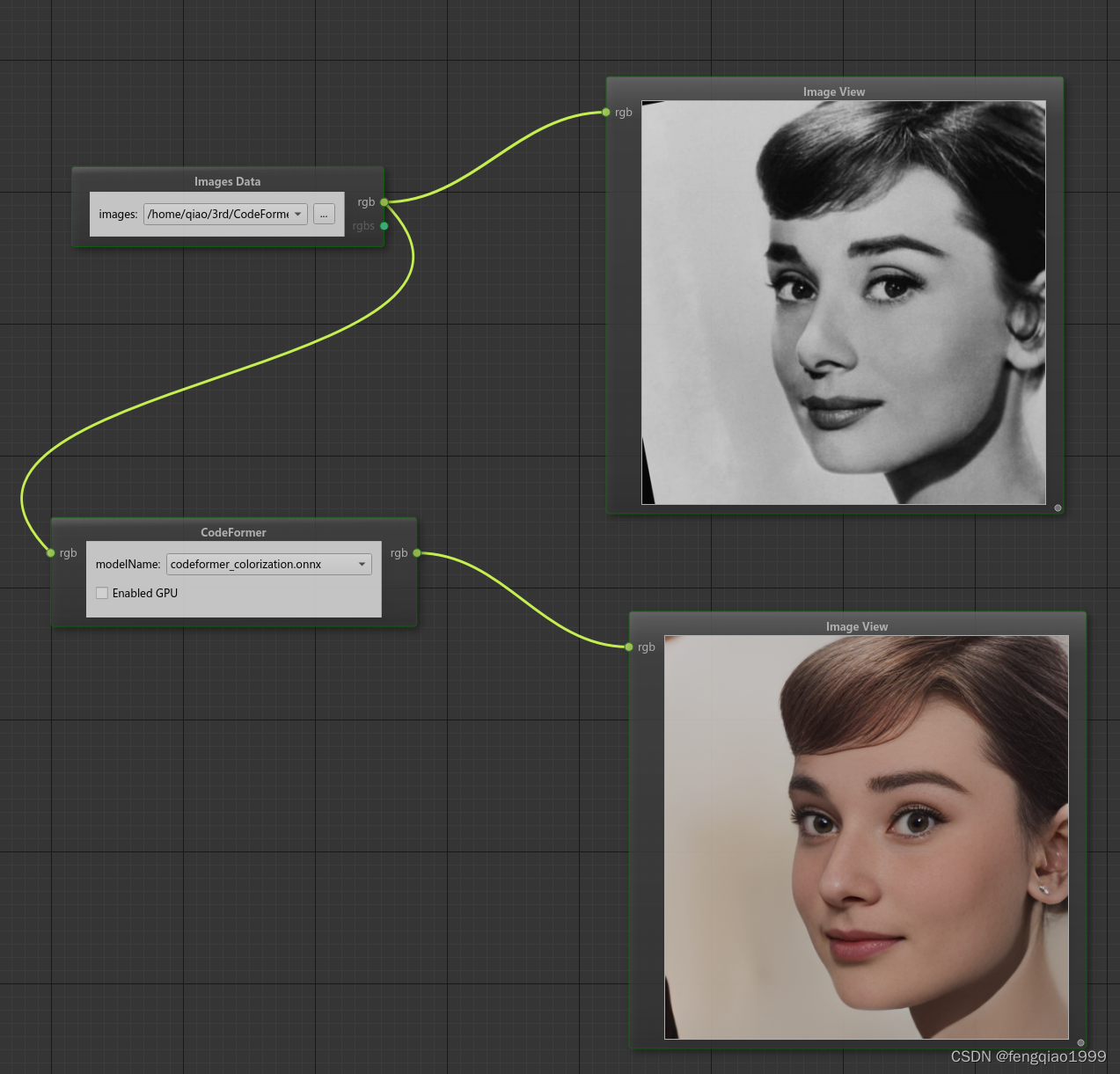
面部色彩增强与恢复
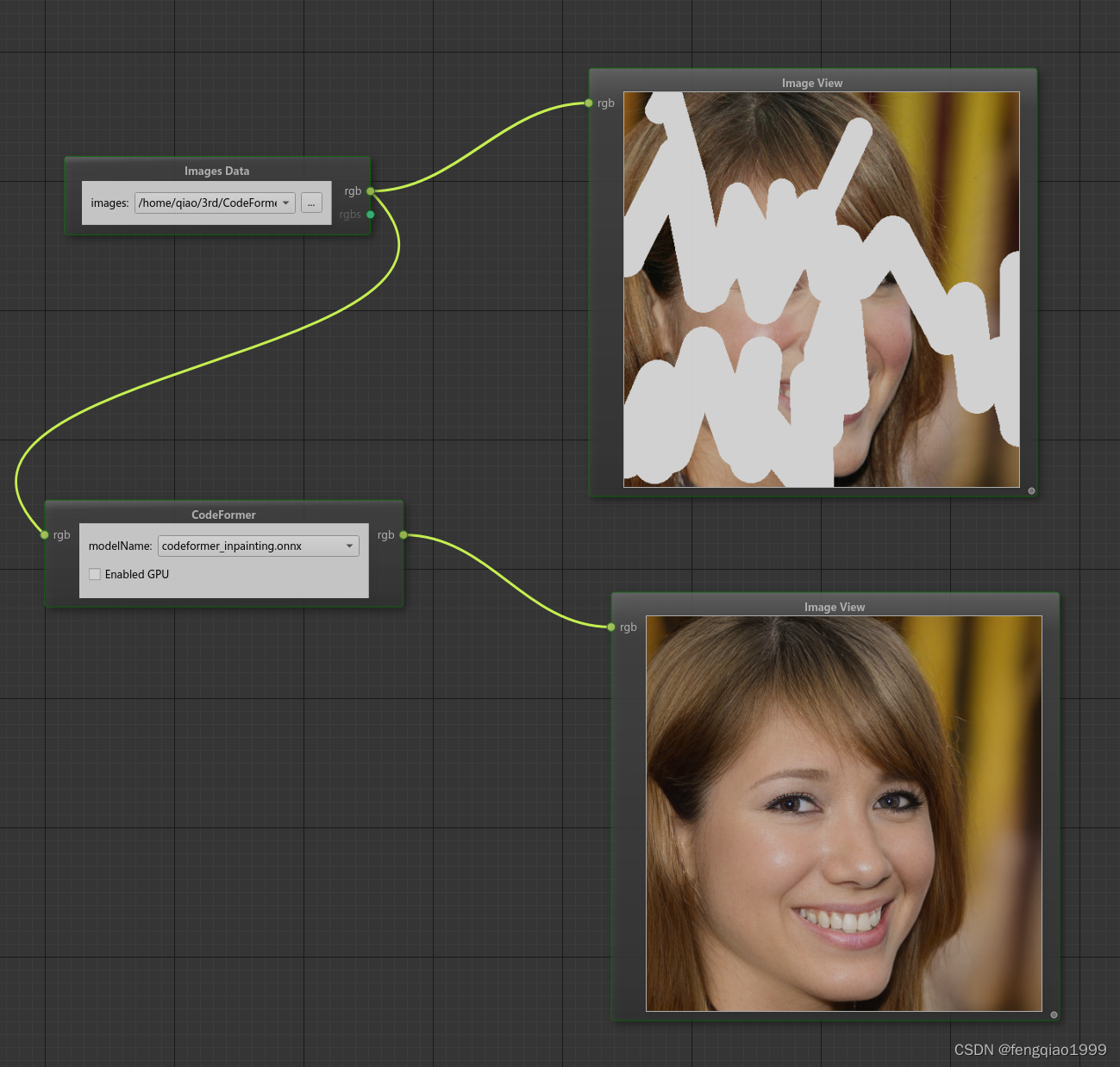
面部修复
破旧照片修复效果
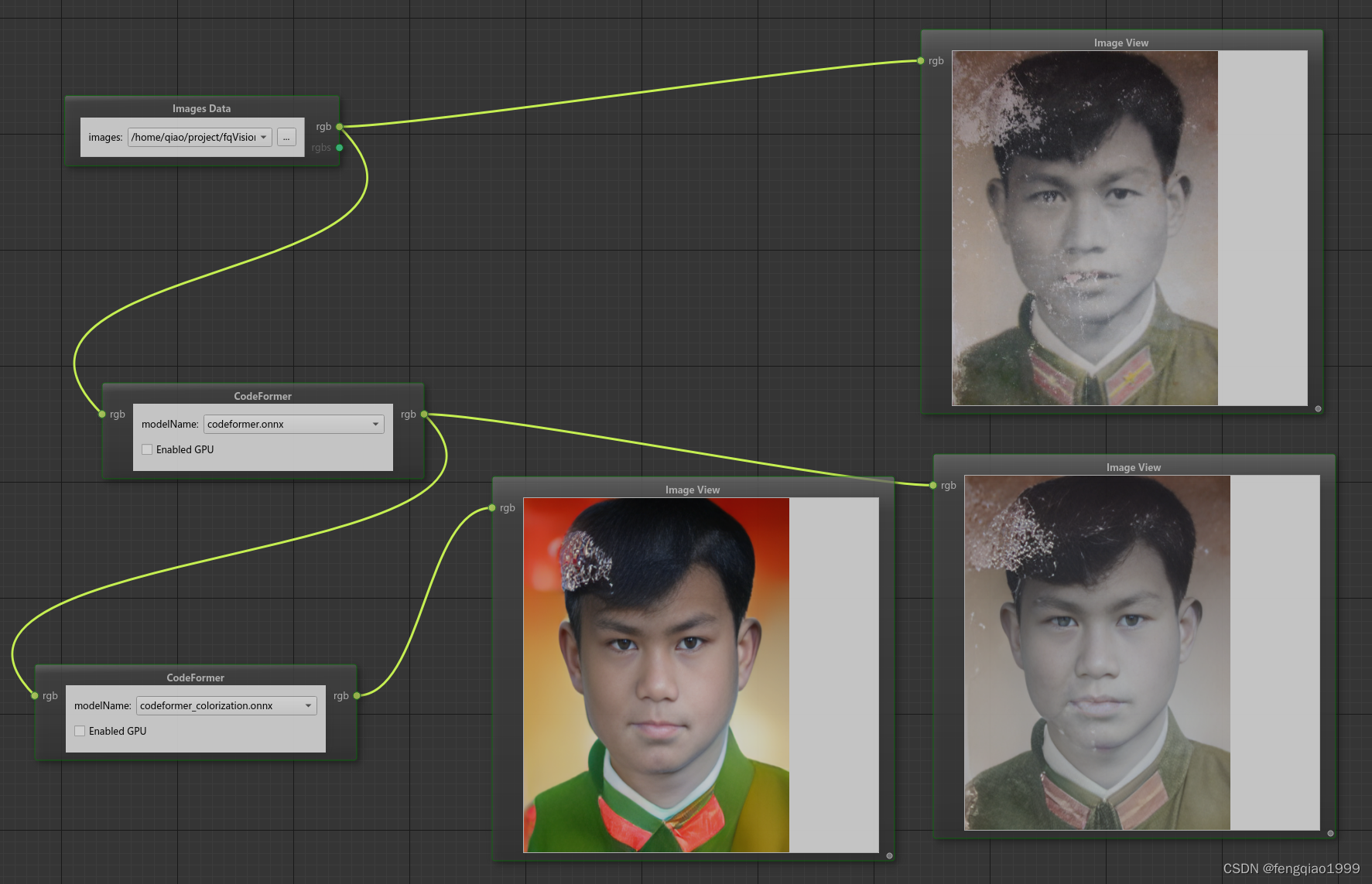
相关文章:
opencv进阶 ——(九)图像处理之人脸修复祛马赛克算法CodeFormer
算法简介 CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.com/sczhou/CodeFormer…...
虚拟机改IP地址
使用场景:当你从另一台电脑复制一个VMware虚拟机过来,就是遇到一个问题,虚拟的IP地址不一样(比如,一个是192.168.1.3,另一个是192.168.2.4,由于‘1’和‘2’不同,不是同一网段&#…...
MySQL(二)-基础操作
一、约束 有时候,数据库中数据是有约束的,比如 性别列,你不能填一些奇奇怪怪的数据~ 如果靠人为的来对数据进行检索约束的话,肯定是不行的,人肯定会犯错~因此就需要让计算机对插入的数据进行约束要求! 约…...

vue3学习使用笔记
1.学习参考资料 vue3菜鸟教程:https://www.runoob.com/vue3/vue3-tutorial.html 官方网站:https://cn.vuejs.org/ 中文文档: https://cn.vuejs.org/guide/introduction.html Webpack 入门教程:https://www.runoob.com/w3cnote/webpack-tutor…...

微信小程序怎么进行页面传参
微信小程序页面传参的方式有多种,每种方式都有其特定的使用场景和优势。以下是几种常见的页面传参方式,以及它们的具体使用方法和示例: URL参数传值 原理:通过在跳转链接中附加参数,在目标页面的onLoad函数中获取参数…...

隆道出席河南ClO社区十周年庆典,助推采购和供应链数字化发展
5月26日,“河南ClO社区十周年庆典”活动在郑州举办,北京隆道网络科技有限公司总裁助理姚锐出席本次活动,并发表主题演讲《数字化采购与供应链:隆道的探索与实践》,分享隆道公司在采购和供应链数字化转型方面的研究成果…...
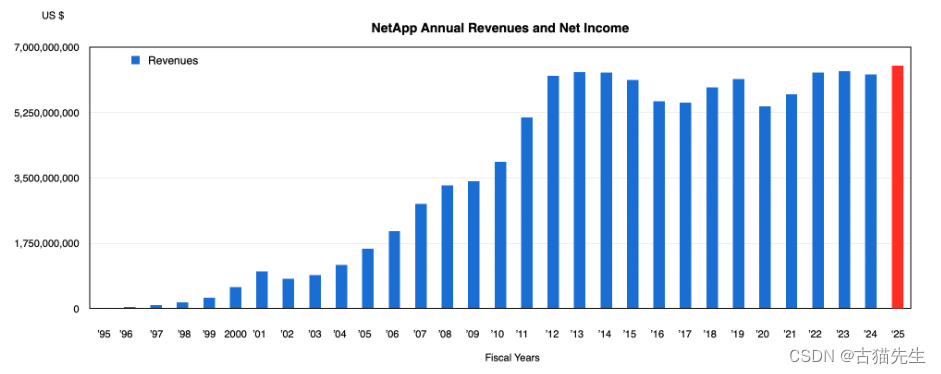
NetApp财季报告亮点:全闪存阵列需求强劲,云计算收入增长放缓但AI领域前景乐观
在最新的财季报告中,NetApp的收入因全闪存阵列的强劲需求而显著增长。截至2024年4月26日的2024财年第四季度,NetApp的收入连续第三个季度上升,达到了16.7亿美元,较前一年同期增长6%,超出公司指导中值。净利润为2.91亿美…...

javascript读取本地目录
在JavaScript中,直接读取本地目录的能力受到浏览器安全限制,因为出于隐私和安全考虑,浏览器的JavaScript环境通常不允许直接访问用户的文件系统。然而,随着Web技术的发展,一些现代浏览器引入了File System API或Web Fi…...

Java基础八股
Java基础八股 Java语言Java语言有什么特点Java与C区别Java如何实现跨平台JVMvsJDKvsJRE标识符和关键字的区别是什么自增自减运算符移位运算符continue,break,return的区别是什么final,finally,finalize的区别final关键字的作用时什么 变量 Java语言 Java语言有什么特点 Java是…...
【机器学习300问】102、什么是混淆矩阵?
一、混淆矩阵的定义 混淆矩阵是一种用于评估分类模型性能的评估指标。当模型对数据进行预测并将数据分配到预定义的类别时,混淆矩阵提供了一种直观的方式来总结这些预测与数据实际类别之间的对应关系。具体来说,它是一个表格。 二、分类模型性能评估一级…...

基于SpringBoot3和JDK17,集成H2数据库和jpa
基于SpringBoot3和JDK17,集成H2数据库和jpa 学会用H2数据库,为了快速写出需要处理数据关系的demo。 文章目录 基于SpringBoot3和JDK17,集成H2数据库和jpa工程配置pom.xml文件application.properties文件 练习H2数据库的操作h2数据库的建表自…...

《逆水寒》手游周年庆,热度不减反增引发热议
易采游戏网5月31日最新消息:随着数字娱乐时代的飞速发展,手游市场的竞争愈发激烈。在这样的大背景下,《逆水寒》手游以其独特的古风武侠世界和深度的社交体验,自上线以来便吸引了无数玩家的目光。如今,这款游戏迎来了它…...
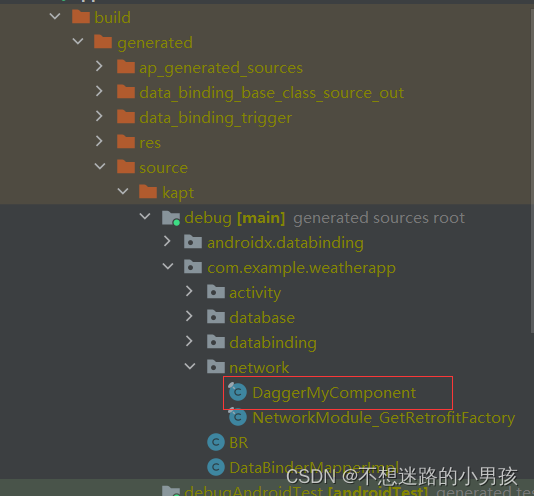
Kotlin使用Dagger2但无法生成对应类 Unresolved reference: DaggerMyComponent
最近在使用Dagger2时,遇到这个错误,app/build/generated/source/没有生成对应类,没有生成如下类,网上看了许多博客替换版本,添加dagger2的其他依赖均未成功,最终看到一篇大佬的文章才终于得以解决 解决&am…...

Vue组件通讯⽗组件中通过 provide 来提供变量,然后在⼦组件中通过 inject 来注⼊变量例子
在Vue中,provide 和 inject 主要用于依赖注入,允许祖先组件向其所有子孙组件提供一个依赖,而不论组件层次有多深。这在开发高阶插件/组件库时特别有用。 以下是一个简单的例子,演示了如何在父组件中使用 provide 提供变量&#x…...
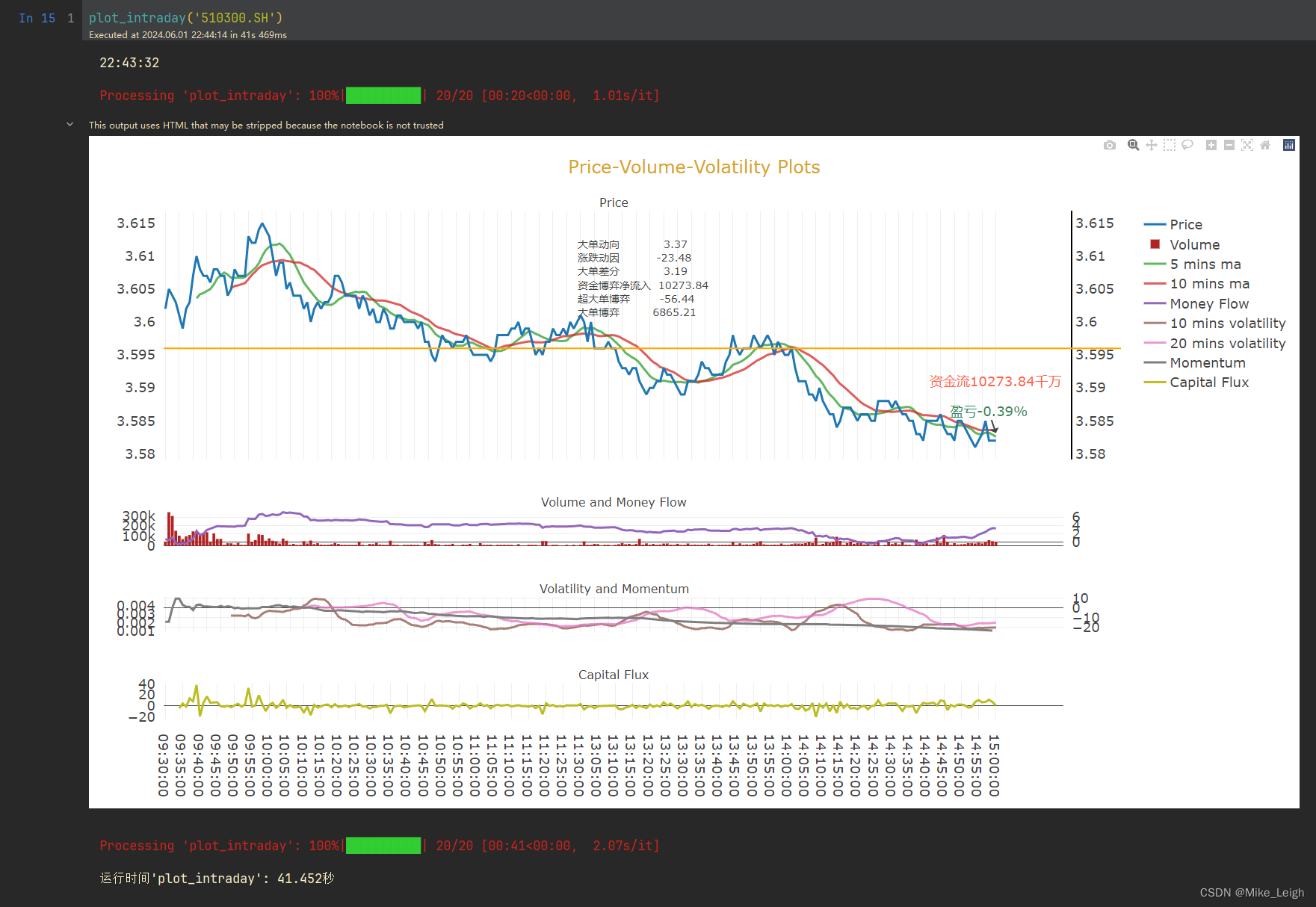
教你搞一个比较简单的计时和进度条装饰器
教你搞一个比较简单的计时和进度条装饰器 什么是装饰器为啥要用装饰器呢?上代码!如何使用装饰器效果 什么是装饰器 装饰器的英文是:Decorator。装修的英文是:Decoration。顾名思义就是我们要用装饰器在函数func()上搞点儿事儿&am…...

跑马灯的两种实现方式
方式一:利用元素尺寸变化监听api,计算宽度,得出时间,进行无限次数动画。 优点:能自定义速度(0 - 1)。 <template><div class"box"><i class"iconfont icon-gon…...

OpenAI 的 GPT-4o 是目前最先进的人工智能模型!如何在工作或日常生活中高效利用它?
OpenAI 的 GPT-4o 是目前最先进的人工智能模型!如何在工作或日常生活中高效利用它? 博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大…...
安卓ANR检测、分析、优化面面谈
前言 一个引发讨论的楔子,以下三种现象有什么区别: App停止运行App暂无响应App闪退 答案: 产生原因不同:停止运行是UNCheckExceptionError暂无响应是ANRDialog闪退是CheckExceptionError 本文讨论的主题是ANR的定义、分类、复现…...
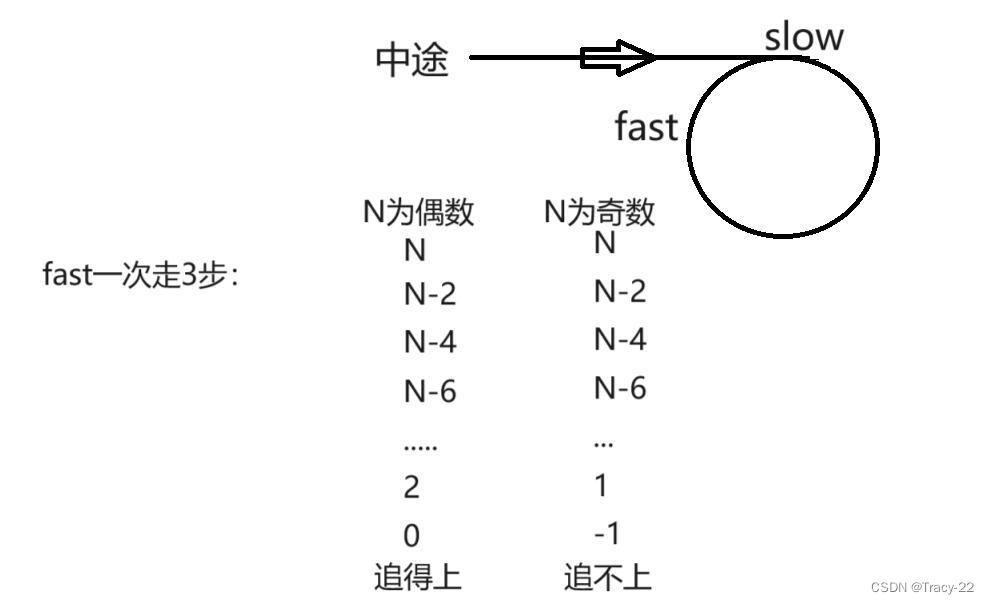
“手撕”链表的九道OJ习题
目录 1. 第一题 2. 第二题 3. 第三题 4. 第四题 5. 第五题 6. 第六题 7. 第七题 8. 第八题 9. 第九题 1. 第一题 删除链表中等于给定值 val 的所有节点。OJ链接 思路如下: 相当于链表的removeAll();制定prev和cur,prev记录前一个节点ÿ…...

解决 Git commit 或 Git merge 跑到 VIM 里面去了
像 git commit 分支名字 或 git merge 分支名字这个命令后面最好加上 -m "消息",如果你不加上 -m "消息"的话,它会打开一个程序让你去加上消息,这个程序还是在控制台里面,只不过是 Linux 里面一个叫做 VIM 的…...

AI健身教练开源项目:用代码实现个性化训练与健康追踪
1. 项目概述:当AI健身教练遇上开源代码库最近在GitHub上闲逛,发现了一个挺有意思的项目,叫ClaireAICodes/gym-workout-health-longevity。光看名字,你可能会觉得这又是一个普通的健身计划分享,但点进去之后,…...

修音翻车现场实录:用Melodyne选择工具时,这3个坑我劝你别踩
Melodyne修音避坑指南:选择工具三大致命操作误区解析 第一次用Melodyne修人声时,我对着屏幕上的波形信心满满地拖动音符,结果导出的音频听起来像电子合成器故障——音高扭曲、节奏支离破碎。后来才发现,问题都出在那个看似简单的…...

Linux高手必备:从安全操作到高效运维的12个核心习惯
1. 为什么说“习惯”是Linux高手的护城河刚接触Linux那会儿,我总觉得高手和菜鸟的区别在于记住了多少命令、会不会写复杂的脚本。后来踩了无数坑、熬了无数夜、甚至搞崩过几次生产环境后,我才恍然大悟:真正的分水岭,其实藏在那些日…...

自托管信息聚合器FeedMe:全栈部署与高效信息管理实践
1. 项目概述:一个“喂饱”你的信息聚合器最近在折腾一个挺有意思的小项目,叫 FeedMe。这名字起得挺直白,翻译过来就是“喂我”。它的核心目标,就是帮你把散落在互联网各个角落的信息源——比如你关注的博客、技术论坛、新闻网站、…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

城通网盘解析工具终极指南:免费获取高速直连下载地址
城通网盘解析工具终极指南:免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的下载速度?每次下载文件都要面对漫长的等待…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...