搭建大型分布式服务(三十八)SpringBoot 整合多个kafka数据源-支持protobuf
系列文章目录

文章目录
- 系列文章目录
- 前言
- 一、本文要点
- 二、开发环境
- 三、原项目
- 四、修改项目
- 五、测试一下
- 五、小结
前言
本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。
<dependency><groupId>io.github.vipjoey</groupId><artifactId>multi-kafka-consumer-starter</artifactId><version>最新版本号</version>
</dependency>
例如下面这样简单的配置就完成SpringBoot和kafka的整合,我们只需要关心com.mmc.multi.kafka.starter.OneProcessor和com.mmc.multi.kafka.starter.TwoProcessor 这两个Service的代码开发。
## topic1的kafka配置
spring.kafka.one.enabled=true
spring.kafka.one.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.one.topic=mmc-topic-one
spring.kafka.one.group-id=group-consumer-one
spring.kafka.one.processor=com.mmc.multi.kafka.starter.OneProcessor // 业务处理类名称
spring.kafka.one.consumer.auto-offset-reset=latest
spring.kafka.one.consumer.max-poll-records=10
spring.kafka.one.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.one.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer## topic2的kafka配置
spring.kafka.two.enabled=true
spring.kafka.two.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.two.topic=mmc-topic-two
spring.kafka.two.group-id=group-consumer-two
spring.kafka.two.processor=com.mmc.multi.kafka.starter.TwoProcessor // 业务处理类名称
spring.kafka.two.consumer.auto-offset-reset=latest
spring.kafka.two.consumer.max-poll-records=10
spring.kafka.two.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.two.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer## pb 消息消费者
spring.kafka.pb.enabled=true
spring.kafka.pb.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.pb.topic=mmc-topic-pb
spring.kafka.pb.group-id=group-consumer-pb
spring.kafka.pb.processor=pbProcessor
spring.kafka.pb.consumer.auto-offset-reset=latest
spring.kafka.pb.consumer.max-poll-records=10
spring.kafka.pb.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.pb.consumer.value-deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer国籍惯例,先上源码:Github源码
一、本文要点
本文将介绍通过封装一个starter,来实现多kafka数据源的配置,通过通过源码,可以学习以下特性。系列文章完整目录
- SpringBoot 整合多个kafka数据源
- SpringBoot 批量消费kafka消息
- SpringBoot 优雅地启动或停止消费kafka
- SpringBoot kafka本地单元测试(免集群)
- SpringBoot 利用map注入多份配置
- SpringBoot BeanPostProcessor 后置处理器使用方式
- SpringBoot 将自定义类注册到IOC容器
- SpringBoot 注入bean到自定义类成员变量
- Springboot 取消限定符
- Springboot 支持消费protobuf类型的kafka消息
二、开发环境
- jdk 1.8
- maven 3.6.2
- springboot 2.4.3
- kafka-client 2.6.6
- idea 2020
三、原项目
1、接前文,我们开发了一个kafka插件,但在使用过程中发现有些不方便的地方,在公共接口MmcKafkaStringInputer 显示地继承了BatchMessageListener<String, String>,导致我们没办法去指定消费protobuf类型的message。
public interface MmcKafkaStringInputer extends MmcInputer, BatchMessageListener<String, String> {}/*** 消费kafka消息.*/@Overridepublic void onMessage(List<ConsumerRecord<String, String>> records) {if (null == records || CollectionUtils.isEmpty(records)) {log.warn("{} records is null or records.value is empty.", name);return;}Assert.hasText(name, "You must pass the field `name` to the Constructor or invoke the setName() after the class was created.");Assert.notNull(properties, "You must pass the field `properties` to the Constructor or invoke the setProperties() after the class was created.");try {Stream<T> dataStream = records.stream().map(ConsumerRecord::value).flatMap(this::doParse).filter(Objects::nonNull).filter(this::isRightRecord);// 支持配置强制去重或实现了接口能力去重if (properties.isDuplicate() || isSubtypeOfInterface(MmcKafkaMsg.class)) {// 检查是否实现了去重接口if (!isSubtypeOfInterface(MmcKafkaMsg.class)) {throw new RuntimeException("The interface "+ MmcKafkaMsg.class.getName() + " is not implemented if you set the config `spring.kafka.xxx.duplicate=true` .");}dataStream = dataStream.collect(Collectors.groupingBy(this::buildRoutekey)).entrySet().stream().map(this::findLasted).filter(Objects::nonNull);}List<T> datas = dataStream.collect(Collectors.toList());if (CommonUtil.isNotEmpty(datas)) {this.dealMessage(datas);}} catch (Exception e) {log.error(name + "-dealMessage error ", e);}}2、由于实现了BatchMessageListener<String, String>接口,抽象父类必须实现onMessage(List<ConsumerRecord<String, String>> records)方法,这样会导致子类局限性很大,没办法去实现其它kafka的xxxListener接口,例如手工提交offset,单条消息消费等。
因此、所以我们要升级和优化。
四、修改项目
1、新增KafkaAbastrctProcessor抽象父类,直接实现MmcInputer接口,要求所有子类都需要继承本类,子类通过调用{@link #receiveMessage(List)} 模板方法来实现通用功能;
@Slf4j
@Setter
abstract class KafkaAbstractProcessor<T> implements MmcInputer {// 类的内容基本和MmcKafkaKafkaAbastrctProcessor保持一致// 主要修改了doParse方法,目的是让子类可以自定义解析protobuf/*** 将kafka消息解析为实体,支持json对象或者json数组.** @param msg kafka消息* @return 实体类*/protected Stream<T> doParse(ConsumerRecord<String, Object> msg) {// 消息对象Object record = msg.value();// 如果是pb格式if (record instanceof byte[]) {return doParseProtobuf((byte[]) record);} else if (record instanceof String) {// 普通kafka消息String json = record.toString();if (json.startsWith("[")) {// 数组List<T> datas = doParseJsonArray(json);if (CommonUtil.isEmpty(datas)) {log.warn("{} doParse error, json={} is error.", name, json);return Stream.empty();}// 反序列对象后,做一些初始化操作datas = datas.stream().peek(this::doAfterParse).collect(Collectors.toList());return datas.stream();} else {// 对象T data = doParseJsonObject(json);if (null == data) {log.warn("{} doParse error, json={} is error.", name, json);return Stream.empty();}// 反序列对象后,做一些初始化操作doAfterParse(data);return Stream.of(data);}} else if (record instanceof MmcKafkaMsg) {// 如果本身就是PandoKafkaMsg对象,直接返回//noinspection uncheckedreturn Stream.of((T) record);} else {throw new UnsupportedForMessageFormatException("not support message type");}}/*** 将json消息解析为实体.** @param json kafka消息* @return 实体类*/protected T doParseJsonObject(String json) {if (properties.isSnakeCase()) {return JsonUtil.parseSnackJson(json, getEntityClass());} else {return JsonUtil.parseJsonObject(json, getEntityClass());}}/*** 将json消息解析为数组.** @param json kafka消息* @return 数组*/protected List<T> doParseJsonArray(String json) {if (properties.isSnakeCase()) {try {return JsonUtil.parseSnackJsonArray(json, getEntityClass());} catch (Exception e) {throw new RuntimeException(e);}} else {return JsonUtil.parseJsonArray(json, getEntityClass());}}/*** 序列化为pb格式,假设你消费的是pb消息,需要自行实现这个类.** @param record pb字节数组* @return pb实体类流*/protected Stream<T> doParseProtobuf(byte[] record) {throw new NotImplementedException();}
}
2、修改MmcKafkaBeanPostProcessor类,暂存KafkaAbastrctProcessor的子类。
public class MmcKafkaBeanPostProcessor implements BeanPostProcessor {@Getterprivate final Map<String, KafkaAbstractProcessor<?>> suitableClass = new ConcurrentHashMap<>();@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {if (bean instanceof KafkaAbstractProcessor) {KafkaAbstractProcessor<?> target = (KafkaAbstractProcessor<?>) bean;suitableClass.putIfAbsent(beanName, target);suitableClass.putIfAbsent(bean.getClass().getName(), target);}return bean;}
}3、修改MmcKafkaProcessorFactory,更换构造的目标类为KafkaAbstractProcessor。
public class MmcKafkaProcessorFactory {@Resourceprivate DefaultListableBeanFactory defaultListableBeanFactory;public KafkaAbstractProcessor<? > buildInputer(String name, MmcMultiKafkaProperties.MmcKafkaProperties properties,Map<String, KafkaAbstractProcessor<? >> suitableClass) throws Exception {// 如果没有配置process,则直接从注册的Bean里查找if (!StringUtils.hasText(properties.getProcessor())) {return findProcessorByName(name, properties.getProcessor(), suitableClass);}// 如果配置了process,则从指定配置中生成实例// 判断给定的配置是类,还是bean名称if (!isClassName(properties.getProcessor())) {throw new IllegalArgumentException("It's not a class, wrong value of ${spring.kafka." + name + ".processor}.");}// 如果ioc容器已经存在该处理实例,则直接使用,避免既配置了process,又使用了@Service等注解KafkaAbstractProcessor<? > inc = findProcessorByClass(name, properties.getProcessor(), suitableClass);if (null != inc) {return inc;}// 指定的processor处理类必须继承KafkaAbstractProcessorClass<?> clazz = Class.forName(properties.getProcessor());boolean isSubclass = KafkaAbstractProcessor.class.isAssignableFrom(clazz);if (!isSubclass) {throw new IllegalStateException(clazz.getName() + " is not subClass of KafkaAbstractProcessor.");}// 创建实例Constructor<?> constructor = clazz.getConstructor();KafkaAbstractProcessor<? > ins = (KafkaAbstractProcessor<? >) constructor.newInstance();// 注入依赖的变量defaultListableBeanFactory.autowireBean(ins);return ins;}private KafkaAbstractProcessor<? > findProcessorByName(String name, String processor, Map<String,KafkaAbstractProcessor<? >> suitableClass) {return suitableClass.entrySet().stream().filter(e -> e.getKey().startsWith(name) || e.getKey().equalsIgnoreCase(processor)).map(Map.Entry::getValue).findFirst().orElseThrow(() -> new RuntimeException("Can't found any suitable processor class for the consumer which name is " + name+ ", please use the config ${spring.kafka." + name + ".processor} or set name of Bean like @Service(\"" + name + "Processor\") "));}private KafkaAbstractProcessor<? > findProcessorByClass(String name, String processor, Map<String,KafkaAbstractProcessor<? >> suitableClass) {return suitableClass.entrySet().stream().filter(e -> e.getKey().startsWith(name) || e.getKey().equalsIgnoreCase(processor)).map(Map.Entry::getValue).findFirst().orElse(null);}private boolean isClassName(String processor) {// 使用正则表达式验证类名格式String regex = "^[a-zA-Z_$][a-zA-Z\\d_$]*([.][a-zA-Z_$][a-zA-Z\\d_$]*)*$";return Pattern.matches(regex, processor);}}
4、修改MmcMultiConsumerAutoConfiguration,更换构造的目标类的父类为KafkaAbstractProcessor。
@Beanpublic MmcKafkaInputerContainer mmcKafkaInputerContainer(MmcKafkaProcessorFactory factory,MmcKafkaBeanPostProcessor beanPostProcessor) throws Exception {Map<String, MmcInputer> inputers = new HashMap<>();Map<String, MmcMultiKafkaProperties.MmcKafkaProperties> kafkas = mmcMultiKafkaProperties.getKafka();// 逐个遍历,并生成consumerfor (Map.Entry<String, MmcMultiKafkaProperties.MmcKafkaProperties> entry : kafkas.entrySet()) {// 唯一消费者名称String name = entry.getKey();// 消费者配置MmcMultiKafkaProperties.MmcKafkaProperties properties = entry.getValue();// 是否开启if (properties.isEnabled()) {// 生成消费者KafkaAbstractProcessor inputer = factory.buildInputer(name, properties, beanPostProcessor.getSuitableClass());// 输入源容器ConcurrentMessageListenerContainer<Object, Object> container = concurrentMessageListenerContainer(properties);// 设置容器inputer.setContainer(container);inputer.setName(name);inputer.setProperties(properties);// 设置消费者container.setupMessageListener(inputer);// 关闭时候停止消费Runtime.getRuntime().addShutdownHook(new Thread(inputer::stop));// 直接启动container.start();// 加入集合inputers.put(name, inputer);}}return new MmcKafkaInputerContainer(inputers);}
5、修改MmcKafkaKafkaAbastrctProcessor,用于实现kafka的BatchMessageListener 接口,当然你也可以实现其它Listener接口,或者在这基础上扩展。
public abstract class MmcKafkaKafkaAbastrctProcessor<T> extends KafkaAbstractProcessor<T> implements BatchMessageListener<String, Object> {@Overridepublic void onMessage(List<ConsumerRecord<String, Object>> records) {if (null == records || CollectionUtils.isEmpty(records)) {log.warn("{} records is null or records.value is empty.", name);return;}receiveMessage(records);}
}
五、测试一下
1、引入kafka测试需要的jar。参考文章:kafka单元测试
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.18.0</version><scope>test</scope></dependency><dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java-util</artifactId><version>3.18.0</version><scope>test</scope></dependency>
2、定义一个pb类型消息和业务处理类。
(1) 定义pb,然后通过命令生成对应的实体类;
syntax = "proto2";package com.mmc.multi.kafka;option java_package = "com.mmc.multi.kafka.starter.proto";
option java_outer_classname = "DemoPb";message PbMsg {optional string routekey = 1;optional string cosImgUrl = 2;optional string base64str = 3;}
(2)创建PbProcessor消息处理类,用于消费protobuf类型的消息;
@Slf4j
@Service("pbProcessor")
public class PbProcessor extends MmcKafkaKafkaAbastrctProcessor<DemoMsg> {@Overrideprotected Stream<DemoMsg> doParseProtobuf(byte[] record) {try {DemoPb.PbMsg msg = DemoPb.PbMsg.parseFrom(record);DemoMsg demo = new DemoMsg();BeanUtils.copyProperties(msg, demo);return Stream.of(demo);} catch (InvalidProtocolBufferException e) {log.error("parssPbError", e);return Stream.empty();}}@Overrideprotected void dealMessage(List<DemoMsg> datas) {System.out.println("PBdatas: " + datas);}
}
3、配置kafka地址和指定业务处理类。
## pb 消息消费者
spring.kafka.pb.enabled=true
spring.kafka.pb.consumer.bootstrapServers=${spring.embedded.kafka.brokers}
spring.kafka.pb.topic=mmc-topic-pb
spring.kafka.pb.group-id=group-consumer-pb
spring.kafka.pb.processor=pbProcessor
spring.kafka.pb.consumer.auto-offset-reset=latest
spring.kafka.pb.consumer.max-poll-records=10
spring.kafka.pb.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.pb.consumer.value-deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer4、编写测试类。
@Slf4j
@ActiveProfiles("dev")
@ExtendWith(SpringExtension.class)
@SpringBootTest(classes = {MmcMultiConsumerAutoConfiguration.class, DemoService.class, PbProcessor.class})
@TestPropertySource(value = "classpath:application-pb.properties")
@DirtiesContext
@EmbeddedKafka(partitions = 1, brokerProperties = {"listeners=PLAINTEXT://localhost:9092", "port=9092"},topics = {"${spring.kafka.pb.topic}"})
class KafkaPbMessageTest {@Resourceprivate EmbeddedKafkaBroker embeddedKafkaBroker;@Value("${spring.kafka.pb.topic}")private String topicPb;@Testvoid testDealMessage() throws Exception {Thread.sleep(2 * 1000);// 模拟生产数据produceMessage();Thread.sleep(10 * 1000);}void produceMessage() {Map<String, Object> configs = new HashMap<>(KafkaTestUtils.producerProps(embeddedKafkaBroker));Producer<String, byte[]> producer = new DefaultKafkaProducerFactory<>(configs, new StringSerializer(), new ByteArraySerializer()).createProducer();for (int i = 0; i < 10; i++) {DemoPb.PbMsg msg = DemoPb.PbMsg.newBuilder().setCosImgUrl("http://google.com").setRoutekey("routekey-" + i).build();producer.send(new ProducerRecord<>(topicPb, "my-aggregate-id", msg.toByteArray()));producer.flush();}}
}5、运行一下,测试通过。

五、小结
将本项目代码构建成starter,就可以大大提升我们开发效率,我们只需要关心业务代码的开发,github项目源码:轻触这里。如果对你有用可以打个星星哦。下一篇,升级本starter,在kafka单分区下实现十万级消费处理速度。
《搭建大型分布式服务(三十六)SpringBoot 零代码方式整合多个kafka数据源》
《搭建大型分布式服务(三十七)SpringBoot 整合多个kafka数据源-取消限定符》
《搭建大型分布式服务(三十八)SpringBoot 整合多个kafka数据源-支持protobuf》
加我加群一起交流学习!更多干货下载、项目源码和大厂内推等着你
 |  |
相关文章:
搭建大型分布式服务(三十八)SpringBoot 整合多个kafka数据源-支持protobuf
系列文章目录 文章目录 系列文章目录前言一、本文要点二、开发环境三、原项目四、修改项目五、测试一下五、小结 前言 本插件稳定运行上百个kafka项目,每天处理上亿级的数据的精简小插件,快速上手。 <dependency><groupId>io.github.vipjo…...

SpringBoot如何使用日志Logback,及日志等级详解
Spring Boot默认已经集成了SLF4J(Simple Logging Facade for Java)作为日志的接口,以及Logback作为日志的实现。这意味着在大多数情况下,你无需做额外的配置即可开始记录日志。 下面是一个简要的指南,包括如何在Spring…...
若依启动run-modules-system.bat报错问题解决方案
在启动run-modules-system.bat时遇到了一些问题,在网上搜索无果后,排查解决完毕 1.启动nacos时,报错如下 Error creating bean with name grpcClusterServer: Invocation of init method failed; nested exception is java.io.IOException: Failed to bind to address 0.0.0.0…...
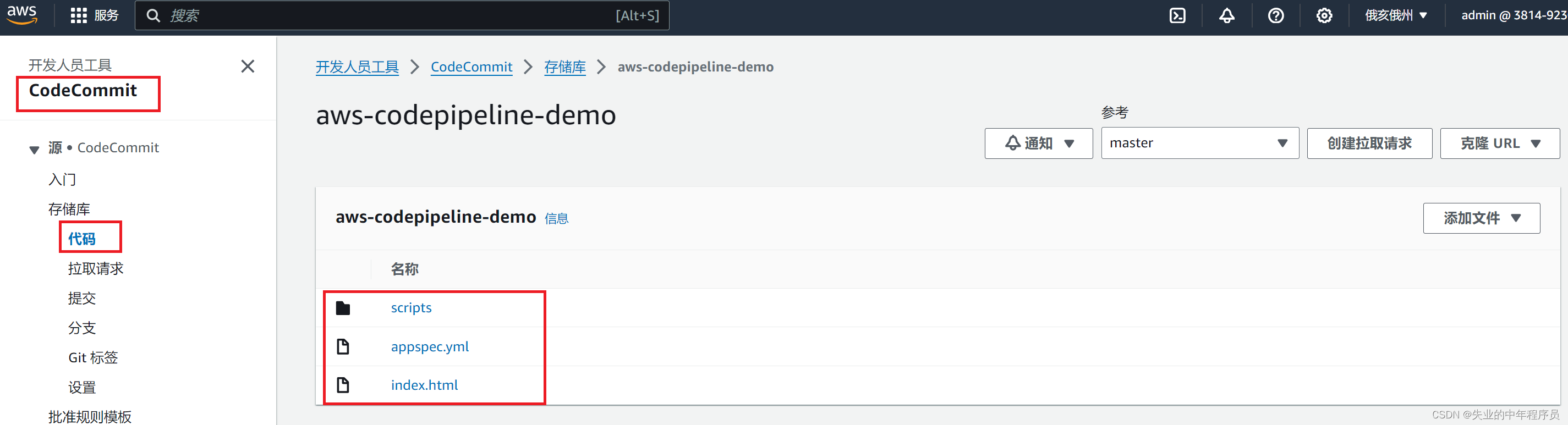
Aws CodeCommit代码仓储库
1 创建IAM用户 IAM创建admin用户,增加AWSCodeCommitFullAccess权限 2 创建存储库 CodePipeline -> CodeCommit -> 存储库 创建存储库 3 SSH 1) window环境 3.1.1 上载SSH公有秘钥 生成SSH秘钥ID 3.1.2 编辑本地 ~/.ssh 目录中名为“config”的 SSH 配置文…...

PostgreSQL的内存参数
PostgreSQL的内存参数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777PostgreSQL 提供了多种内存参数&#x…...

【教程】在CentOS上使用Docker部署前后端分离项目的完整指南
当在CentOS上使用Docker部署前后端分离项目时,需要遵循一系列步骤来实现这一目标。以下是每个步骤的详细内容: 步骤1:安装Docker和Docker Compose 1.1 安装Docker 在CentOS上安装Docker,可以按照以下步骤进行: sudo yum install -y yum-utils device-mapper-persistent…...
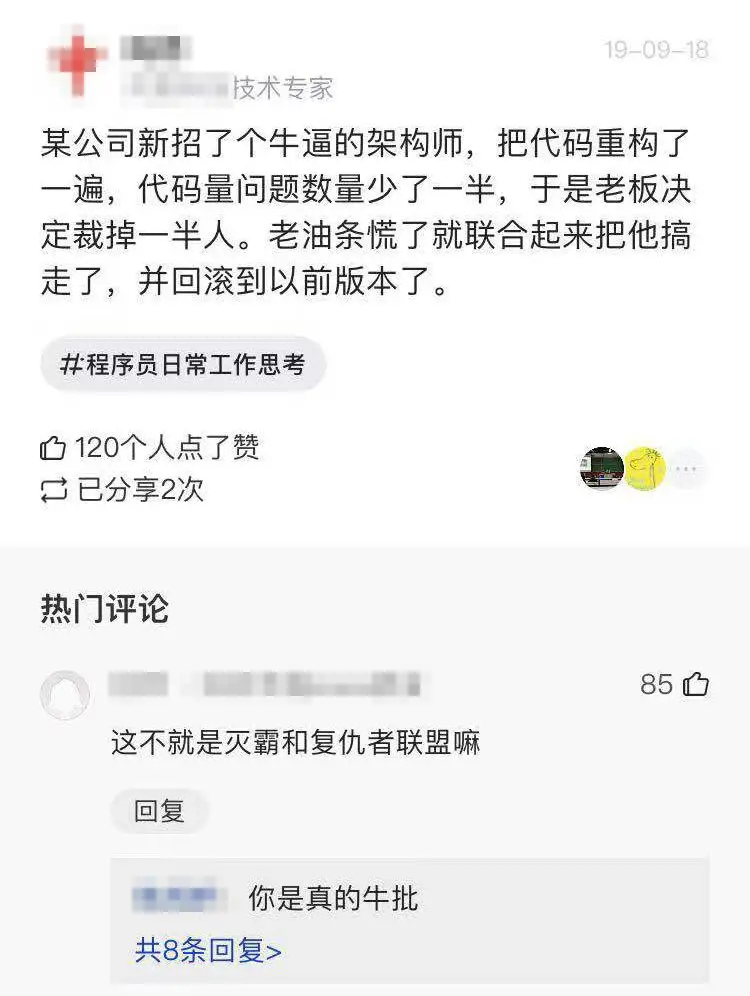
某公司新招了个牛逼的架构师后.....
网友评论: 架构师一个响指之后。第二天,老板不见了走走停停 回头已是数月图片是我的故事没错了,本来我们组有10个人,我把代码重构之后,只要半个人维护,于是老板要裁掉9个>人,于是我被搞走了图…...

云计算和雾计算
雾计算作为传统集中式数据存储系统(云)和边缘设备之间的中间层。雾扩展了云,使计算和数据存储更接近边缘。雾由多个节点(雾节点)组成,并创建一个本地网络,使其成为一个去中心化的生态系统——雾…...

正缘画像 api数据接口
测测正缘画像,相貌特征,高矮胖瘦,黑白美丑,对方何许人也,远嫁近娶,何方定居,家庭观,持家爱家,生活质量,富裕贫穷,健康情况,测算结果仅…...
)
Java 基础面试300题 (171- 200)
Java 基础面试300题 (171- 200) 171.什么是同步? 当多个线程试图同时访问共享资源时,那么他们需要以某种方式让资源一次只能由一个线程访问。实现这一目标的过程被称为同步。Java提供了一个名为synchronized的关键字实现这一目标…...

0基础学习Elasticsearch-使用Java操作ES
文章目录 1 背景2 前言3 Java如何操作ES3.1 引入依赖3.2 依赖介绍3.3 隐藏依赖3.4 初始化客户端(获取ES连接)3.5 发送请求给ES 1 背景 上篇学习了0基础学习Elasticsearch-Quick start,随后本篇研究如何使用Java操作ES 2 前言 建议通篇阅读再回…...

【Linux】GNU编译器基础
文章目录 GCCMakefile、make GCC 常见的GNU编译器是GCC其包含gcc以及g等,适用于C/C中,在Windows系统中通常使用IDE进行程序的编写和编译、链接等操作,但在Linux系统中通常使用GNU编译器来进行,对于C/C等高级语言需要进行预编译、编…...

Linux 软件安装:从源码编译到包管理器安装
Linux 软件安装:从源码编译到包管理器安装 在 Linux 操作系统中,软件安装是一个非常重要的任务。不同的软件安装方式有不同的优缺点,本篇博客将介绍 Linux 软件安装的几种方式,包括从源码编译安装、使用包管理器安装和使用第三方…...
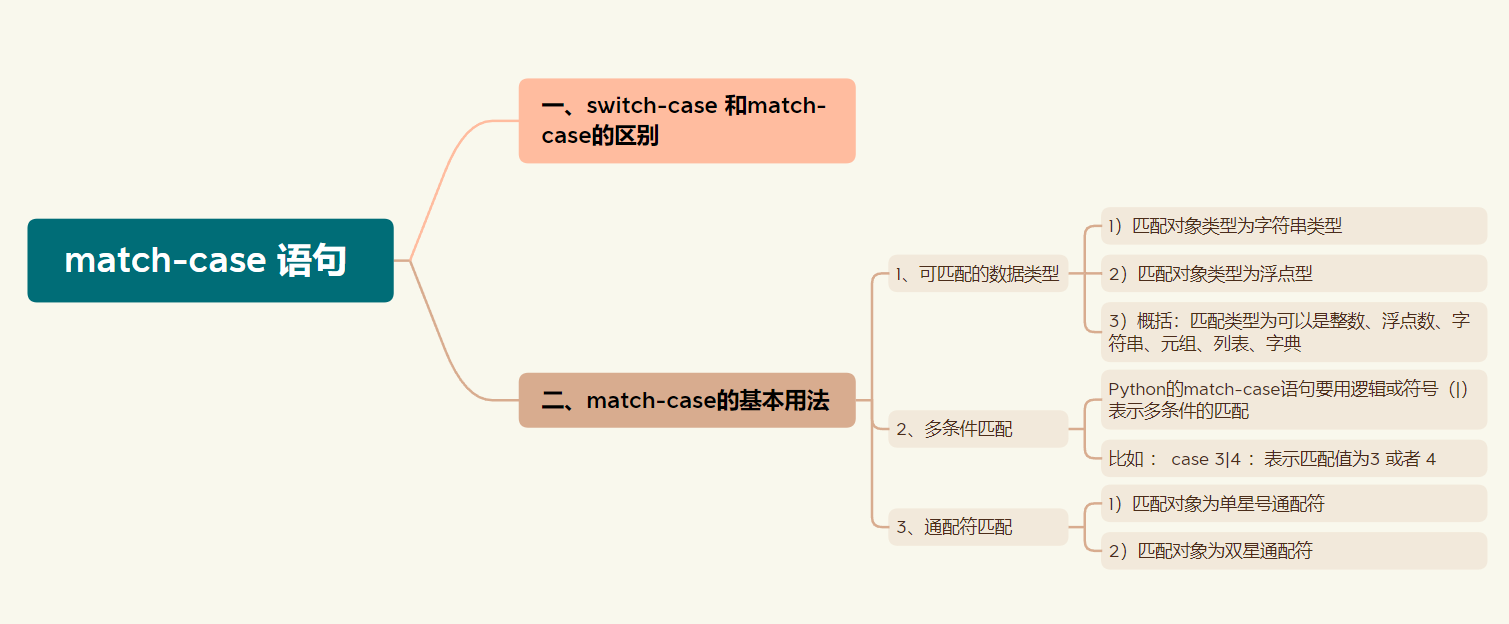
Python3 match-case 语句
前言 本文主要介绍match-case语句与switch-case的区别,及match-case语句的基本用法。 文章目录 前言一、switch-case 和match-case的区别二、match-case的基本用法1、可匹配的数据类型2、多条件匹配3、通配符匹配 一、switch-case 和match-case的区别 C语言里面s…...

图论第三天
似乎要团建了,我再猫会。我必须参与上团建再走。 130.被围绕的区域 先把外围的O变成A,再把飞地的O变成X,再把外围A变回O class Solution { public:int neighbor[4][2] {1,0,0,-1,-1,0,0,1};void solve(vector<vector<char>>&a…...

计算机网络学习2
文章目录 信道复用技术 第三章数据链路层概述数据链路层的三个重要问题封装成帧和透明传输差错检测可靠传输的相关基本概念可靠传输的实现机制停止等待协议回退N帧协议选择重传协议 点对点协议PPP共享式以太网网络适配器和MAC地址CSMA_CD协议的基本原理共享式以太网的争用期共享…...
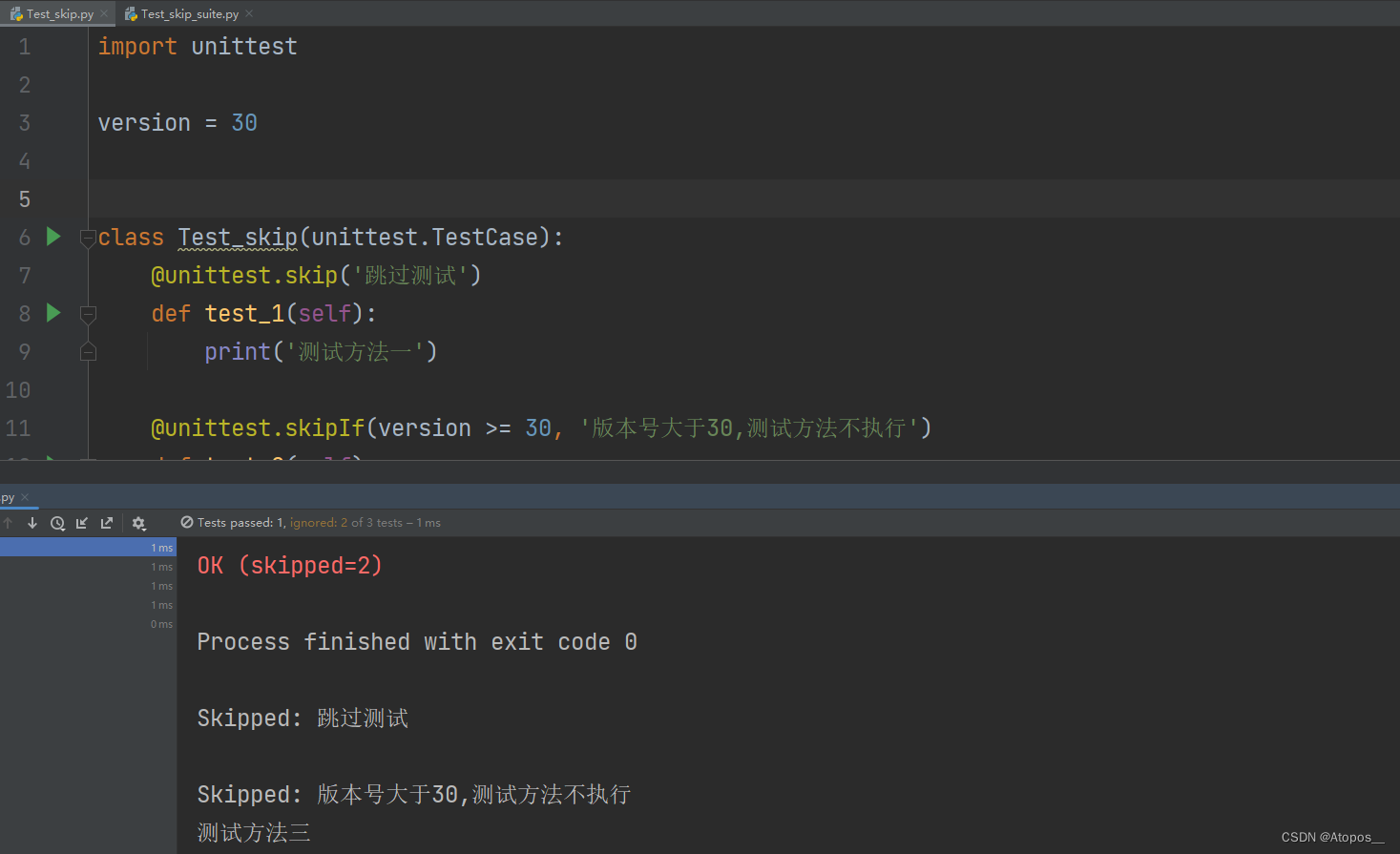
unittest框架
目录 框架: unittest框架: 使用的原因: 核心要素(组成): TestCase测试用例: 可能出现的错误: TestSuite(测试套件): TestRunner(测试执行): 整体步骤: 查看执行结果: TestLoader测试加载: 方法级别Fixture: 类级别Fixture: 模块级别Fixture: 用例脚本…...

Python中的__str__和__repr__:揭示字符串表示的奥秘
标题:Python中的__str__和__repr__:揭示字符串表示的奥秘 摘要 在Python中,对象的字符串表示对于调试和日志记录至关重要。__str__和__repr__是两个特殊的方法,用于定义对象的字符串表示形式。尽管它们在功能上相似,…...

gazebo插入一个图片
在下面的目录下添加文件夹 my_ground_plane 文件夹内容如下 model.sdf <?xml version"1.0" encoding"UTF-8"?> <sdf version"1.4"><model name"my_ground_plane"><static>true</static><link na…...
Bootstrap精美弹出框模态框modal,实现js向modal传递数据)
(已解决)Bootstrap精美弹出框模态框modal,实现js向modal传递数据
Modals是Bootstrap中用户弹框用的组件,使用时不需要额外引入其他插件,在引入了boostrap.js或者boostrap.min.js前提下就可以使用。 官方的示例: <!-- Button trigger modal --> <button type="button" class="btn btn-primary" data-bs-…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

虚实实景双向映射,升级高端楼宇精细化透明治理
虚实实景双向映射,升级高端楼宇精细化透明治理副标题:原生引擎驱动动态三维场景重构,结合无感化坐标解算、遮挡自适应跨镜接续、身体指纹无源身份匹配,构筑难以复刻、适配极强的楼宇透明化技术壁垒一、方案总览当下高端楼宇运营治…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

如何3分钟快速上手企业级后台管理系统:终极配置秘籍
如何3分钟快速上手企业级后台管理系统:终极配置秘籍 【免费下载链接】ant-design-vue3-admin 一个基于 Vite2 Vue3 Typescript tsx Ant Design Vue 的后台管理系统模板,支持响应式布局,在 PC、平板和手机上均可使用 项目地址: https://…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...

Cursor与Figma通过MCP协议实现AI辅助设计与开发同步
1. 项目概述:当代码编辑器与设计工具“开口说话”最近在开发者社区里,一个名为“cursor-talk-to-figma-mcp”的项目引起了我的注意。这个由开发者“hamadoun1760”开源的仓库,名字直译过来就是“Cursor与Figma对话的MCP”。乍一看,…...