基于字典树可视化 COCA20000 词汇
COCA20000 是美国当代语料库中最常见的 20000 个词汇,不过实际上有一些重复,去重之后大概是 17600+ 个,这些单词是很有用,如果能掌握这些单词,相信会对英语的能力有一个较大的提升。我很早就下载了这些单词,并且自己编写了一个背单词的简易工具,如果有需要的同学,可以去看我的博客中搜索。今天这篇博客是利用字典树来堆单词的一个可视化。
字典树可视化词汇
下面就是一颗简单的 4 个单词的字典树,这个东西用来检索是很快的,这里我把最后的单词作为树的叶子节点。随着单词的不断增加,整个树也会不断的膨胀,不过这样就难以阅读了,所以我最终选择是把树的排列方向变成从又到右的形式。我之后要实现的字典树和下面这个没有什么本质的区别,只是更大一些而已,利用的数据就是 COCA 20000 的单词。
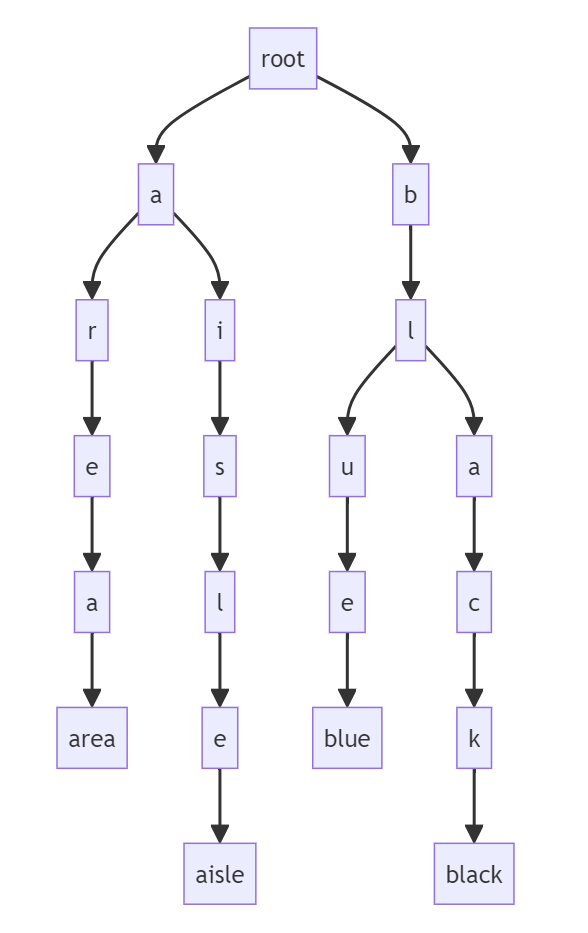
上面这个图形是使用 mermaid 绘制的,不过最终我采用的是 dot 语言(绘图指令就在下面),因为 mermaid 可能会遇到性能问题。实际上,dot 语言也是遇到了性能问题,因为单词实在是太多了,导致最后的图形太大了。我想了一些可能的优化措施,比如根据首字母来区分单词,这样的化加上大小写总共 52 个字母,可以把大的树分成 52 个小一点的树。不过,我也不是真的要去看这个树,所以就没有这样做。
代码处理
下面是全部的处理代码。
"""
字典树
目的是生成 COCA 单词的字典树,但是也可以用于其他单词或者词语(包括英语)。
"""
import jsonclass Node:"""字典树的一个节点,包含这个节点的值,以及它下面的节点,以及是否是一个单词的结尾。"""def __init__(self, val, is_end) -> None:self.val = valself.is_end = is_endself.children = {}def set_is_end(self) -> None:"""有些短的单词要重新设置,否则无法和长的区分开来,例如:are, area"""self.is_end = Trueclass DictTree:"""字典树"""def __init__(self):self.root = Node('/', False)self.stack = [] # 用来保存单词def append(self, word: str):"""向字典树中添加一个单词: 获取当前树的根节点:node = self.root遍历这个词的每一个字符 c,1. 如果该字符在当前树的子树中,则把当前树的子树指向当前树: node = node.children[c]如果当前字符 c 是最后一个字符,那么: node.is_end = True2. 如果该字符不在当前树的子树中,那么新建立一个节点,如果当前字符 c 是最后一个字符:is_end = True把它添加到当前树的子树中, node.children[c] = Node(c, is_end)"""node = self.rootfor i, c in enumerate(word):is_end = not i != len(word)-1if node.children.get(c):node = node.children[c]if is_end:node.set_is_end()else:node.children[c] = Node(c, is_end)node = node.children[c]def dumps(self) -> dict:"""序列化成字典对象"""return {"/": self.__dump(self.root)}def __dump(self, node: Node) -> dict:"""序列化成字典对象的内部方法,一个简单但是并不优雅的递归"""ret = {}self.stack.append(node.val)if not node.children:ret["word"] = "".join(self.stack[1:])for k, c in node.children.items():ret[k] = self.__dump(c)self.stack.pop()return ret# 生成dot描述
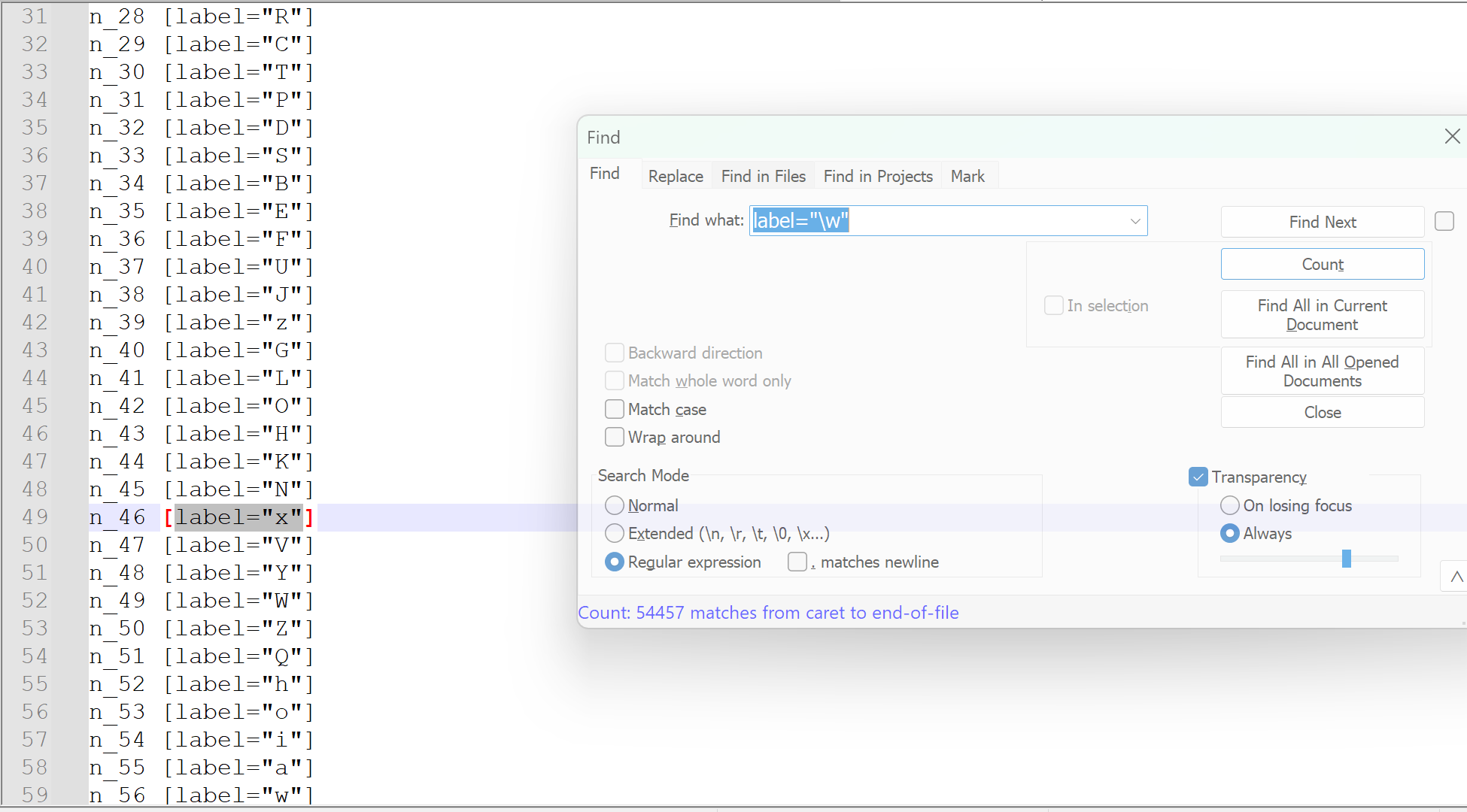
# 层序遍历 tips: 使用队列
def BFS_to_dot(tree) -> str:"""将树结构以层序遍历的方式转换为Dot语言表示的图形。Dot语言用于描述图形结构,本函数特别适用于将树结构可视化。:param tree: 输入的树结构,通常是一个字典或类似字典的对象,其中键值对表示节点及其子节点。:return: 返回一个表示树结构的Dot语言字符串。"""if not tree:returnqueue = [tree["/"]] # 把树的根本身作为第一个节点加入队列count = 0 # 子节点计数parent_count = 0 # 父节点计数parent_map = {0: "/"} # 记录父节点序号和它的值nodes = ['n_0 [label="/"]'] # 点集edges = [] # 边集while queue:node = queue.pop(0)if isinstance(node, dict):for val, child in node.items():queue.append(child)count += 1v = val if val != "word" else childparent_map[count] = vdot_node = f'n_{count} [label="{v}"]'dot_edge = f"n_{parent_count} -> n_{count};"nodes.append(dot_node)edges.append(dot_edge)parent_count += 1node_str = "\n".join(nodes)edge_str = "\n".join(edges)return f"digraph G {{\nrankdir=LR;\n{node_str};\n{edge_str}\n}}"if __name__ == "__main__":in_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_no_order.txt"out_json_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.json"out_dot_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.dot"dt = DictTree()with open(in_file, "r", encoding="utf-8") as file:for word in [line.strip() for line in file.readlines()]:dt.append(word)dt_dumps = dt.dumps()# 序列化json写入with open(out_json_file, "w", encoding="utf-8") as file:json.dump(dt_dumps, file)# dot写入with open(out_dot_file, "w", encoding="utf-8") as file:file.write(BFS_to_dot(dt_dumps))print("EOF")生成的文件
这里生成的 json 文件是压缩形式的,如果格式化的化,就超过 4m 了。

渲染图形
因为我安装了 graphviz 的插件,所以我直接在 VSCode 查看生成的 dot 文件时,它就在渲染了,不过渲染失败了。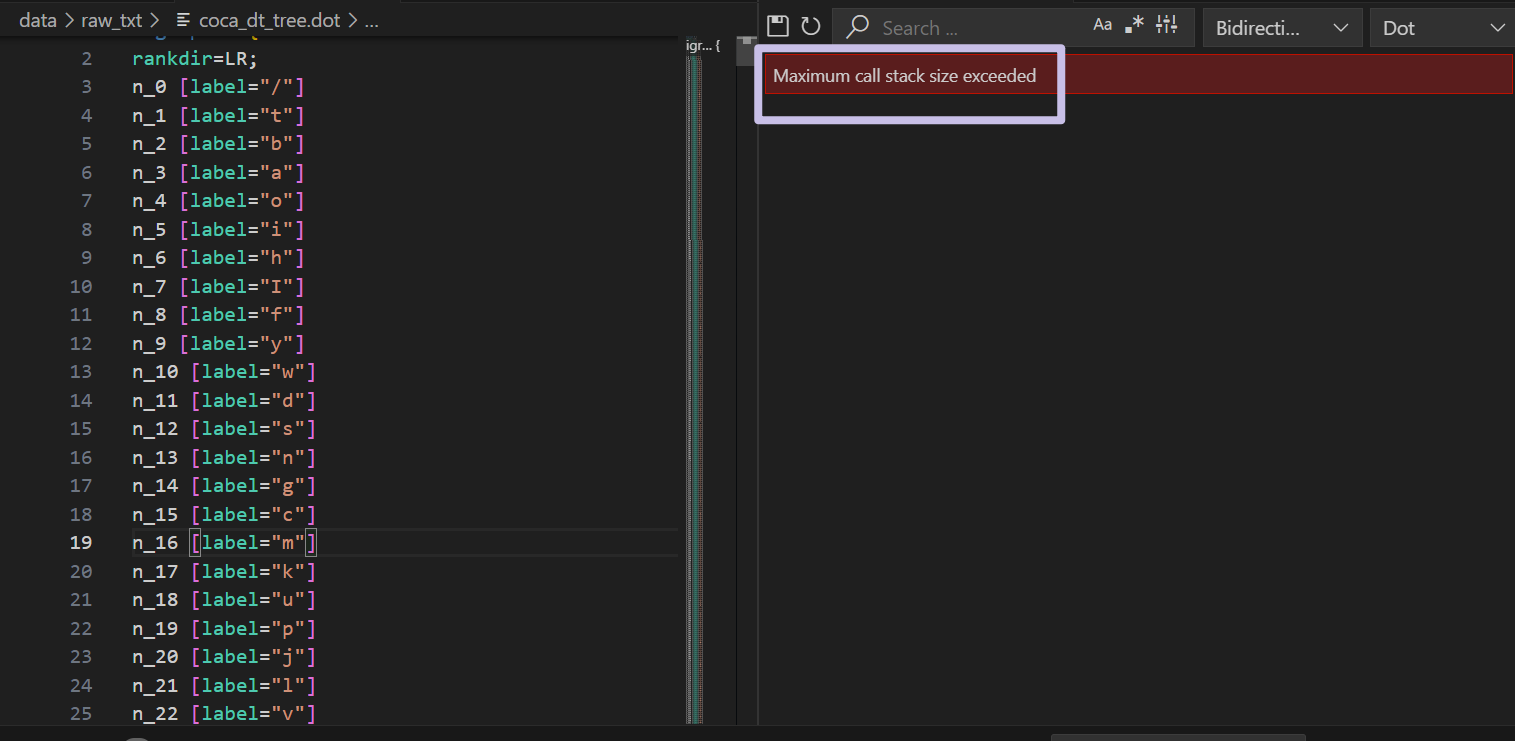
因为这个文件太大了,有十几万行(定义的节点就有几万个了)。

所以还是在本地来生成,我已经配置好了 graphviz 的环境了。一开始是生成的 png 格式,不过它提示分辨率有问题,因为节点太多了,导致生成的图形其实没法观看了。所以最终还是选择了 svg 和 pdf 格式,其中 pdf 格式生成的特别慢,至少是 20 分钟以上了。

生成的 svg 和 pdf

这两个文件的渲染都特别费劲,我的电脑打开有点吃力了。


对它的理解
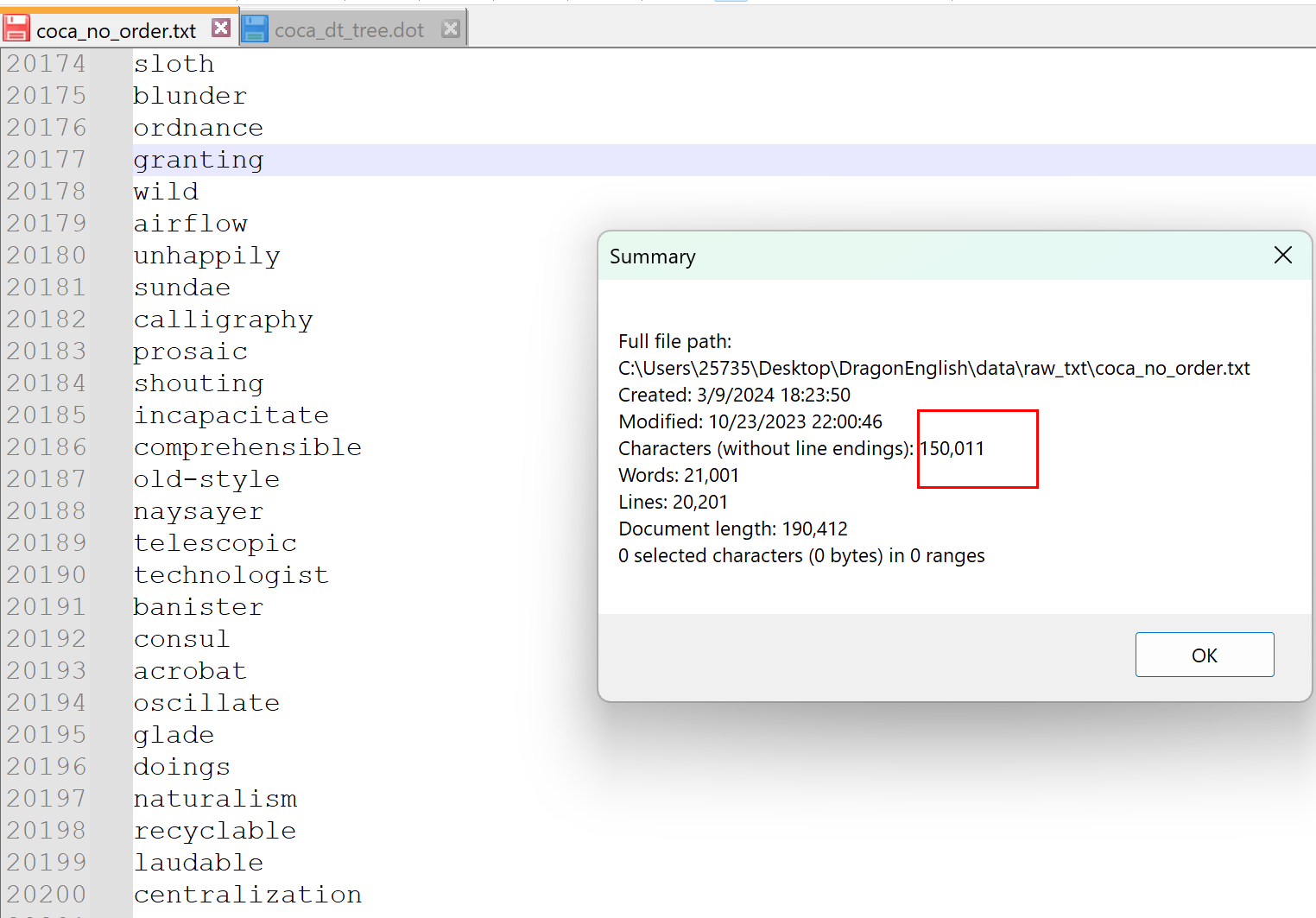
如果是这 20000 个单词,它们的字母数是 150011 个,这是一个十分庞大的数字了。但是观察上面的字典树可以发现,其实有些单词是含有共同部分的,在计算的时候可以省去这部分,对于字典树来说就是计算其中的节点数就行了。因为我把完整的单词也算做节点了,所以要只计算单个字母的节点,这里我使用正则表达式来计算,最终的结果是: 54457 个。我觉得它对于我们记忆单词有一个很好的启示,那就是我们记忆单词并不是孤立的记忆每一个单词,每个单词之间是有联系的,随着记忆的单词越多,对于单词的掌握应该也是越来越熟悉的,但是太少了还是看不出来。而且这里只有前缀的联系,实际上还包括后缀的联系等。我会把这篇博客中产生的文件上传到 CSDN 中,如果有感兴趣的同学也可以自己下载体验。
相关文章:
基于字典树可视化 COCA20000 词汇
COCA20000 是美国当代语料库中最常见的 20000 个词汇,不过实际上有一些重复,去重之后大概是 17600 个,这些单词是很有用,如果能掌握这些单词,相信会对英语的能力有一个较大的提升。我很早就下载了这些单词,…...

TypeScript 中的命名空间
1. 命名空间的概念 命名空间是 TypeScript 提供的一种组织代码的方式,它类似于其他编程语言中的模块化系统,但有一些不同之处。命名空间可以包含变量、函数、类等,并且可以嵌套使用,从而更好地组织和管理代码。 2. 定义命名空间…...
 zty出品)
[C++] 小游戏 斗破苍穹 2.2.1至2.11.5全部版本(上) zty出品
大家好,今天zty整合了斗破苍穹2.2.1到2.11.5的所有版本 我这么辛苦,就要50个赞吧 2.2.1 #include<stdio.h> #include<ctime> #include<time.h> //suiji #include<windows.h> //SLEEP函数 struct Player //玩家结构体,并初始化player { char name[…...
单元测试的心法分享
大家好,我是G探险者! 今天我们简单聊聊单元测试的哪些事儿~ 两天时间我玩明白了单元测试的套路。 这里我分享一下思路。 在我眼里单元测试室什么? 请看这张草图: 单元测试主要关注单个代码单元(通常是类或方法&am…...

【python】多线程(3)queue队列之不同延时时长的参数调用问题
链接1:【python】多线程(笔记)(1) 链接2:【python】多线程(笔记)(2)Queue队列 0.问题描述 两个线程,但是不同延时时长,导致数据输出…...

Java开发常见基础问题
Java开发的多个方面,包括但不限于Java基础知识、多线程并发、JVM、框架使用、数据库、设计模式、网络编程等。 以下是一些常见的问题以及回答的方向: Java 开发技术常见问题(一) Java 基础知识 对象和类的区别是什么࿱…...

大数据组件doc
1.flink Apache Flink Documentation | Apache Flink 2.kafka Apache Kafka 3.hbase Apache HBase ™ Reference Guide 4.zookeeper ZooKeeper: Because Coordinating Distributed Systems is a Zoo 5.spark Overview - Spark 3.5.1 Documentation 6.idea组件(…...
Docker Hub 国内镜像源配置
Docker Hub 国内镜像源配置 Docker Hub 国内镜像源是指在国内境内提供 Docker 镜像服务的镜像源。由于国际网络带宽等问题,国内用户下载 Docker 镜像通常速度较慢。因此,为了解决这个问题,一些国内的公司和组织提供了 Docker 镜像的国内镜像…...
)
持续总结中!2024年面试必问 20 道 Kafka面试题(一)
一、Kafka 的基础概念有哪些? Kafka 是一个分布式流处理平台,由 LinkedIn 开发,并于 2011 年成为 Apache 软件基金会的一部分。以下是 Kafka 的一些基础概念: Broker: Kafka 集群由多个 Broker 组成,每个 Broker 存储…...
Linux共享内存创建和删除
最近项目中使用到了共享内存记录下 创建共享内存: 删除共享内存: 代码: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <fcntl.h> #include <sys/mman.h> #include <sys/stat.h> #include <u…...

微信小程序如何自定义tabbar
微信小程序自定义底部tabbar是一个提升用户体验和增加小程序个性化的重要功能。以下是自定义底部tabbar的步骤,以供参考: 一、自定义tabbar的重要性 微信小程序默认的底部导航栏(tabbar)样式和布局是固定的,开发者无…...
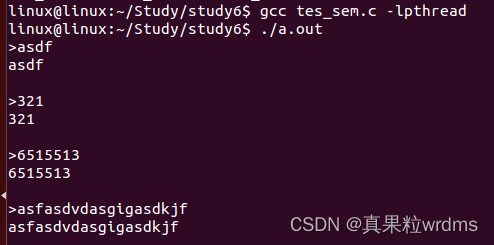
【并发程序设计】15.信号灯(信号量)
15.信号灯(信号量) Linux中的信号灯即信号量是一种用于进程间同步或互斥的机制,它主要用于控制对共享资源的访问。 在Linux系统中,信号灯作为一种进程间通信(IPC)的方式,与其他如管道、FIFO或共享内存等IPC方式不同&…...
【操作与配置】VS2017与MFC环境配置
【操作与配置】VS2017与MFC环境配置 概述 Visual Studio 是一款强大且多功能的集成开发环境(IDE),适用于软件开发人员和团队。使用此应用程序,您可以构建和调试现代Web应用程序,并利用扩展帮助探索几乎任何编程语言。…...
遥感影像信息提取
刘老师(副教授),来自双一流重点高校,长期从事GIS/RS/3S技术及其生态环境领域中的应用等方面的研究和教学工作,并参与GIS的二次开发,发表多篇sci论文,具有资深的技术底蕴和专业背景。 专题一&am…...

LRU算法
文章目录 LRU算法LRU 如何实现LinkedHashMap来实现的LRU算法的缓存HashMap实现LRU算法的缓存 LRU算法 LRU(Least Recently Used)算法可以使用哈希表和双向链表来实现。哈希表用于快速查找数据,双向链表用于记录数据的访问顺序。以下是LRU算法…...
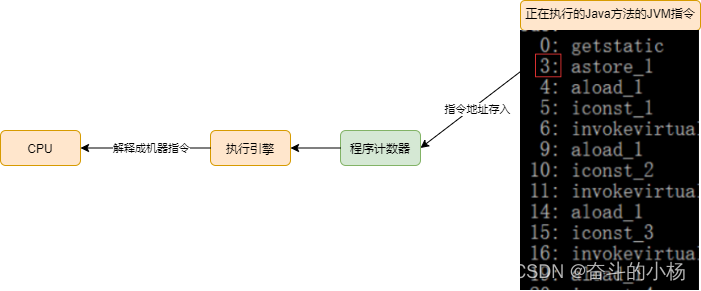
JVM运行时数据区 - 程序计数器
运行时数据区 Java虚拟机在执行Java程序的过程中,会把它管理的内存划分成若干个不同的区域,这些区域有各自的用途、创建及销毁时间,有些区域随着虚拟机的启动一直存在,有些区域则随着用户线程的启动和结束而建立和销毁࿰…...
1.JAVA小项目(零钱通)
一、说明 博客内容:B站韩顺平老师的视频,以及代码的整理。此项目分为两个版本: 面向过程思路实现面向对象思路实现 韩老师视频地址:【【零基础 快速学Java】韩顺平 零基础30天学会Java】 https://www.bilibili.com/video/BV1fh4…...
Redis这一篇就够了
一.概述 Redis是什么? Redis是远程服务字典服务,是一个开源的使用ANSI C语言编写,支持网络,可基于内存亦可持久化的日志型,Key-Value数据库,并提供多种语言的API。 redis会周期性把更新的数据写入磁盘或把…...
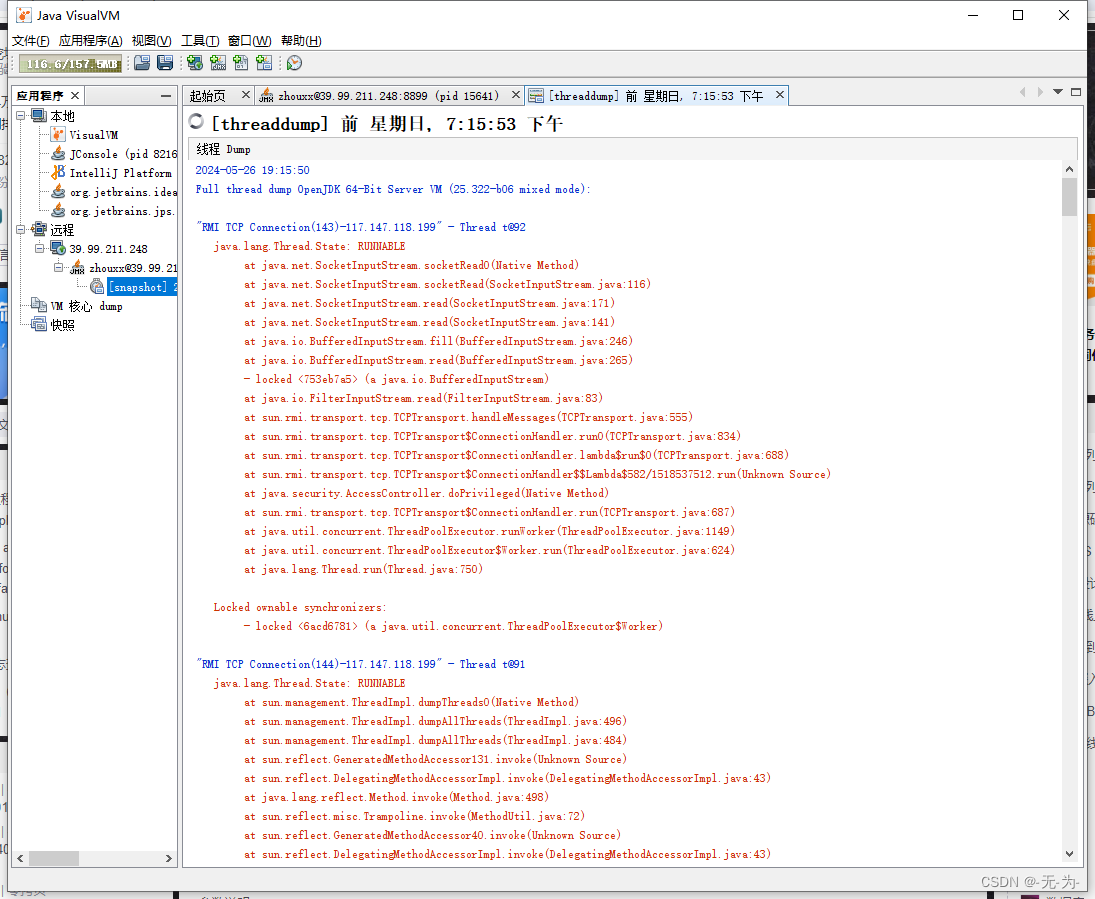
Java web应用性能分析之【jvisualvm远程连接云服务器】
Java web应用性能分析之【java进程问题分析概叙】-CSDN博客 Java web应用性能分析之【java进程问题分析工具】-CSDN博客 前面整理了java进程问题分析和分析工具,现在可以详细看看jvisualvm的使用,一般java进程都是部署云服务器,或者托管IDC机…...
springboot发送短信验证码,结合redis 实现限制,验证码有效期2分钟,有效期内禁止再次发送,一天内发送超3次限制
springboot结合redis发送短信验证码,实现限制发送操作 前言(可忽略)实现思路正题效果图示例手机号不符合规则校验图成功发送验证码示例图redis中缓存随机数字验证码,2分钟后失效删除redis缓存图验证码有效期内 返回禁止重复发送图验证码24小时内发送达到3次…...
OpenAvatarChat终极部署指南:如何构建企业级数字人对话系统
OpenAvatarChat终极部署指南:如何构建企业级数字人对话系统 【免费下载链接】OpenAvatarChat 项目地址: https://gitcode.com/gh_mirrors/op/OpenAvatarChat OpenAvatarChat是一款革命性的模块化交互数字人对话框架,为开发者提供了从本地推理到云…...

图片跨域之谜:img 标签真的“畅通无阻”吗
🖼️ 图片跨域之谜:img 标签真的“畅通无阻”吗? 🤔 核心疑问 在前端开发中,我们常听到“同源策略”限制了跨域请求。但是,当你直接在 HTML 中写 <img src"https://other-domain.com/logo.png&qu…...

AI人工智能行业的现状:为什么说AI从业者的需求越来越大
一、AI产业爆发式增长:需求激增的时代底色2026年,人工智能产业已步入爆发式增长的黄金期,成为驱动全球经济复苏与产业变革的核心引擎。从全球市场来看,2025年AI市场规模达7575.8亿美元,同比增长18.7%,预计2…...
了!手把手教你启用STM32F4的硬件随机数发生器(RNG))
别再只用软件rand()了!手把手教你启用STM32F4的硬件随机数发生器(RNG)
解锁STM32F4硬件随机数发生器:从理论到实战的嵌入式安全升级指南 在嵌入式开发领域,随机数生成常被视为基础功能而草率对待——直到某次安全审计暴露了系统漏洞,或是高并发场景下性能瓶颈显现。许多开发者习惯性地调用标准库中的rand()函数&a…...

如何用Python快速接入Taotoken平台调用多款大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多款大模型 对于希望便捷使用多种大语言模型的开发者而言,逐一对接不同厂商的AP…...

如何3步搭建你的私人游戏云:Sunshine游戏串流服务器终极指南
如何3步搭建你的私人游戏云:Sunshine游戏串流服务器终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,专…...
)
21 鸿蒙LiteOS软件定时器实战:多定时器周期性任务完整示例(源码+解析)
鸿蒙LiteOS软件定时器实战:多定时器周期性任务完整示例(源码解析) 一、前言 在嵌入式鸿蒙(OpenHarmony LiteOS)开发中,软件定时器是实现周期性任务、延时任务、定时触发逻辑的核心内核工具,无…...

10分钟搞定黑苹果:OpCore-Simplify自动化配置工具完全指南
10分钟搞定黑苹果:OpCore-Simplify自动化配置工具完全指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗…...

LiveSplit终极指南:速度跑者的专业计时解决方案
LiveSplit终极指南:速度跑者的专业计时解决方案 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者设计的专业计时软件,通过…...

视频高清直播点播/音视频点播/云点播/云直播EasyDSS交互升级解锁大型活动直播新体验
在数字化时代,大型活动直播已从“可选”变为“必需”,无论是政企发布会、行业峰会,还是跨区域学术论坛,都需要一套兼顾稳定、安全与高效的直播解决方案。EasyDSS私有化视频会议系统凭借高并发、低延迟的核心优势站稳市场ÿ…...