Redis之内存管理过期、淘汰机制
1.Redis内存管理
我们的redis是一个内存型数据库,我们的数据也都是放在内存中的,内存是有限的空间,当数据满了之后,我们要怎么样继续保证redis的可用性呢?我们就需要采取点管理措施和机制来保证我们redis的可用性。
在redis.conf中通过maxmemory来配置
maxmemory 100mb // 如果配置是0 那么默认是电脑的内存, 如果是32bit 隐式大小为3G
在Redis中有两个核心的机制来保证我们的可用性: Redis过期策略、Redis淘汰机制
2. Redis过期策略
那么什么是过期策略。首先,我们知道Redis有一个特性,就是Redis中的数据我都是可以设置过期时间的,如果时间到了,这个数据就会从我们的Redis中删除。
那么过期策略,就是讲的是我怎么把Redis中过期的数据从我们Redis服务中移除的。
我们可以类比一个例子,假如我们把Redis容器比作一个冰箱。冰箱里面也会放菜,菜就是我们的数据,数据跟菜都会过期。那么我们冰箱里面假如有菜过期了,我们一般是怎么发现的呢?
2.1 惰性过期
我们在准备拿冰箱里的食物吃的时候,我们就会先去看下,这个东西有没有过期,如果过期了就仍掉。
那么在Redis里面,就是每次在访问操作key的时候,判断这个key是不是过期了,如果过期了就删除。
源码验证 expireIfNeeded方法(db.c文件)
int expireIfNeeded(redisDb *db, robj *key) {if (!keyIsExpired(db,key)) return 0;/* If we are running in the context of a slave,instead of* evicting the expired key from the database, wereturn ASAP:* the slave key expiration is controlled by themaster that will* send us synthesized DEL operations for expiredkeys.** Still we try to return the right information to thecaller,* that is, 0 if we think the key should be stillvalid, 1 if* we think the key is expired at this time. *///如果配置有masterhost,说明是从节点,那么不操作删除if (server.masterhost != NULL) return 1;/* Delete the key */server.stat_expiredkeys++;propagateExpire(db,key,server.lazyfree_lazy_expire);notifyKeyspaceEvent(NOTIFY_EXPIRED,"expired",key,db->id);//是否是异步删除 防止单个Key的数据量很大 阻塞主线程 是4.0之后添加的新功能,默认关闭int retval = server.lazyfree_lazy_expire ?dbAsyncDelete(db,key) :dbSyncDelete(db,key);if (retval) signalModifiedKey(NULL,db,key);return retval;
}
每次调用到相关指令时,才会执行expireIfNeeded判断是否过期。平时不会判断是否过期。
优点: 该策略就可以最大化地节省CPU资源,因为它平时都懒得都判断,所以也没有啥cpu损耗,只有访问的时候我才会去判断一下
缺点: 对内存非常不友好。因为如果没有再次访问,该过期删除的就可能一直堆积在内存里面!从而不会被清除,占用大量内存。
所以我们需要另外一种策略来配合使用,解决内存占用问题。就是我们的定期过期
2.2 定期过期
所谓定期过期,就是我们会每个星期或者每个月去清理一次冰箱,把冰箱里面过期的菜全部扔掉。
在Redis中,就是我也会定期去把过期的数据删除。
那么究竟多久去清除一次呢,我们在讲rehash的时候Redis数据结构扩容源码分析_redis数据结构扩容机制-CSDN博客 有个方法是serverCron,执行频率根据redis.conf中的hz配置
这方法除了做Rehash以外,还会做很多其它的事情,比如
- 清理数据库中的过期键值对
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等
- 关闭和清理连接失效的客户端
- 尝试进行持久化操作
我们知道了多久会去扫描一下,那么接下来我们需要知道具体是怎么扫的
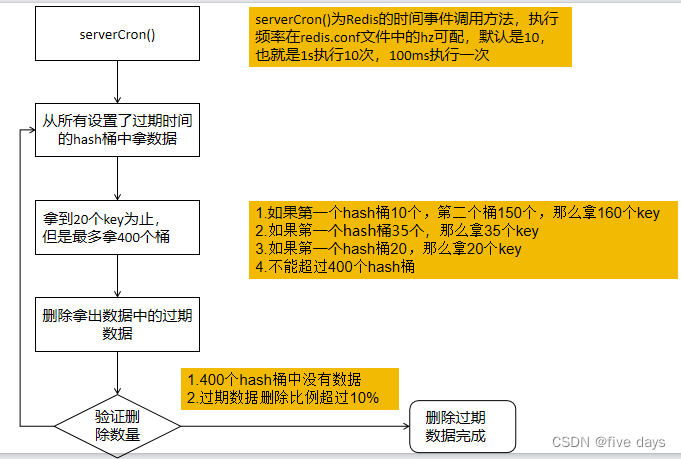
具体实现流程如下:
1. 定时serverCron方法去执行清理,执行频率根据redis.conf中的hz配置 的值
2. 执行清理的时候,不是去扫描所有的key,而是去扫描所有设置了过期 时间的key(redisDb.expires)
3. 如果每次去把所有过期的key都拿过来,那么假如过期的key很多,就会 很慢,所以也不是一次性拿取所有的key
4. 根据hash桶的维度去扫描key,扫到20(可配)个key为止。假如第一个桶 是15个key ,没有满足20,继续扫描第二个桶,第二个桶20个key,由 于是以hash桶的维度扫描的,所以第二个扫到了就会全扫,总共扫描 35个key
5. 找到扫描的key里面过期的key,并进行删除
6. 如果取了400个空桶,或者扫描的删除比例跟扫描的总数超过10%,继续 执行4、5步。
7. 也不能无限的循环,循环16次后回去检测时间,超过指定时间会跳出。
实现流程图如下:
3.Redis淘汰机制
由于Redis内存是有大小的,并且我可能里面的数据都没有过期,当快满的时候,我又没有过期的数据进行淘汰,那么这个时候内存也会满。内存满了之后,redis也会放不了新的数据了。
所以,我们不得已需要一些策略来解决这个问题来保证可用性。
类比冰箱扔菜
如果我们发现冰箱的菜满了,但是冰箱里的菜都是好的,那你会咋办?
a. 不放入新的,但是可以拿出来吃 -- noeviction
b. 扔掉很久没有吃的 ---LRU
c. 扔掉很少吃的 -----lfu
d. 扔掉即将快过期的 --- ttl
那么在Redis中究竟是怎么处理的呢?
noeviction: New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database 默认,不淘汰 能读不能写
allkeys-lru: Keeps most recently used keys; removes least recently used (LRU) keys 基于伪LRU算法 在所有的key中去淘汰
allkeys-lfu: Keeps frequently used keys; removes least frequently used (LFU) keys 基于伪LFU算法 在所有的key中去淘汰
volatile-lru: Removes least recently used keys with the expire field set to true . 基于伪LRU算法 在设置了过期时间的key中去淘汰
volatile-lfu: Removes least frequently used keys with the expire field set to true . 基于伪LFU算法 在设置了过期时间的key中去淘汰
allkeys-random: Randomly removes keys to make space for the new data added. 基于随机算法 在所有的key中去淘汰
volatile-random: Randomly removes keys with expire field set to true . 基于随机算法 在设置了过期时间的key中去淘汰
volatile-ttl: Removes least frequently used keys with expire field set to true and the shortest remaining time-to-live (TTL) value. 根 据过期时间来,淘汰即将过期的
上述是官网给我们提供了8种不同的策略,只要在config配置中配置maxmemory-policy即可指定相关的淘汰策略
# maxmemory-policy noeviction //默认不淘汰数据,能读不能写
那么现在我们已经知道了有不同的方式去淘汰,那么整个的淘汰流程又是什么呢?LRU跟LFU算法又是什么呢?
3.1 淘汰流程

如上图所示
1.首先,我们会有个淘汰池,默认大小是16,并且里面的数据是末尾淘汰制。
2.每次指令操作的时候,自旋会判断当前内存是否满足指令所需要的内存
3.如果当前内存不能满足,会从淘汰池中的尾部拿取一个最适合淘汰的数据
3.1 会取样(配置 maxmemory-samples)从Redis中获取随机获 取到取样的数据 解决一次性读取所有的数据慢的问题
3.2 在取样的数据中,根据淘汰算法 找到最适合淘汰的数据
3.3 将最合适的那个数据跟淘汰池中的数据比较,是否比淘汰池 中的更适合淘汰,如果更适合,放入淘汰池
3.4 按照适合的程度进行排序,最适合淘汰的放入尾部
4.将需要淘汰的数据从Redis删除,并且从淘汰池移除。
3.2 LRU算法
LRU, least Recently Used 翻译过来是最久未使用,根据时间轴来走,仍很久没用的数据。只要最近有用过,我就默认是有效的。
那么它的一个衡量标准是什么呢?事件对不对!根据使用事件,从近到远,越远的越容易淘汰
实现原理
- 首先,LRU是根据这个对象的访问操作时间来进行淘汰的,那我们需要知道这个对象最后的操作访问时间。
- 知道了对象的最后操作访问时间后,我们只需要跟当前的系统时间来进行对比,就能计算出对象已经多久没有访问了
源码验证
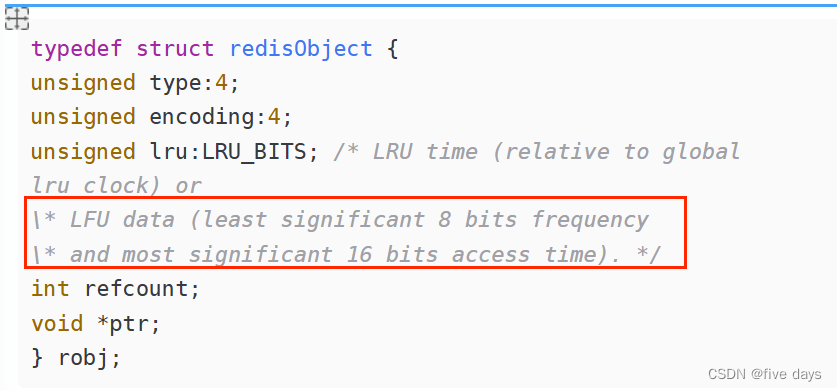
在Redis中,对象都会被一个redisObject对象包装,这个对象就是我们redis的所有数据结构的对外对象!那么它里面有个字段叫做lru
redisObject对象(server.h文件)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global
lru_clock) or
\* LFU data (least significant 8 bits frequency
\* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;lru这个字段的大小为24bit,那么这个字段记录的是对象操作访问时候的秒单位时间的后24bit
long timeMillis=System.currentTimeMillis();
System.out.println(timeMillis/1000); //获取当前秒
System.out.println(timeMillis/1000 & ((1<<24)-1)); //获取秒的后24位我们知道了这个对象的最后操作访问的时间。如果我们要得到这个对象多久没访问了,我们是不是就很简单,用我当前的时间-这个对象的访问时间就可以了!!!但是这个访问时间是秒单位时间的后24bit!所以,也是用当前时间的秒单位的后24bit去减!
假如我们lrulock=当前时间的秒单位的最后24bit
那么我们如果要得到这个对象多久没访问 只需要: lrulock - redisObject.lru
但是我们就会发现一个问题: 24bit是有大小限制的,最大是24个1,那么假如时间一直往前走,这个系统时间的最后24bit肯定会变成24个0
举个例子
11111111111111111000000000011111110 假如这个是我当前秒单位的时 间,
获取后8位 是 11111110
11111111111111111000000000011111111
获取后8位 是 11111111
11111111111111111000000000100000000
获取后8位 是 00000000 但是比上面的那个二进制肯定要大
所以,它有个轮询的概念,它如果超过24位,又会从0开始!所以我们不能直接用系统时间秒单位的24bit去减对象的lru,而是要判断一下,怎么判断
举个生活中的例子
我们的月份,跟我们的24bit的值是一样的,都有最大值,只不过月份的最 大值是12。
场景一:数据在5月份被操作访问,现在是8月份 我们可通过:8-5=3 得 到这个对象3个月没访问
场景二:数据在5月份被操作访问,现在是3月份 我们可通过: 12-5+3 得 到这个对象10个月没访问
同理
如果redisObject.lru<lrulock,直接通过lrulock-redisObject.lru得到这个对象多久没访问
如果redisObject.lru>lrulock,通过lrulock + (24bit的最大值-redisObject.lru)
源码验证
estimateObjectIdleTime方法(evict.c)
unsigned long long estimateObjectIdleTime(robj *o) {//获取秒单位时间的最后24位unsigned long long lruclock = LRU_CLOCK();//因为只有24位,所有最大的值为2的24次方-1//超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小if (lruclock >= o->lru) {//如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;} else {//否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到对象的值越小,返回的值越大,越大越容易被淘汰return (lruclock + (LRU_CLOCK_MAX - o->lru)) *LRU_CLOCK_RESOLUTION;}
}整体流程图:Redis LRU算法实现| ProcessOn免费在线作图,在线流程图,在线思维导图
总结
用lrulock与redisObject.lru进行比较,因为Lrulock只获取了当前秒单位时间的后24位,所以肯定有个轮询
所以,我们会用lrulock跟redisObject.lru进行比较,如果lrulock>redisObject.lru,那么我们用lrulock-redisObject.lru,否则lrulock+(24bit的最大值-redisObject.lru),得到的lru越小,那么返回的数据越大,相差越大的越优先会被淘汰!
3.3 LFU算法
LFU,Least Frequently Used,翻译成中文就是最不常用的优先淘汰。
不常用,它的衡量标准就是次数,次数越少的越容易被淘汰
这个实现起来应该也很简单,对象被操作访问的时候,去记录次数,每次操作访问一次,就+1;淘汰的时候,直接去比较这个次数,次数越少的越容易淘汰
LFU的时效性问题
但是LFU有个致命的问题,那就是时效性问题。何为时效性?就是只考虑数量,不考虑时间
举个生活中的例子:
假如去年有个新闻很火,比如之前的吴亦凡事件,假如点击量是3000W
那么今年又有个新闻,刚出来,点击量是100次
本来,我们应该是要让今年的这个新闻显示出来的,吴亦凡虽然去年很火,但是由于时间久了,我肯定是不希望上热搜的。
但是根据LFU来做的话,我们发现淘汰的却是今年的新闻,这个明显是不合理的。
导致的问题就是: 新的数据进不去,旧的数据出不来
Redis肯定也是知道这个问题的,那么Redis是怎么解决的呢?
上面的RedisObject中的lru字段有注释:
它前面16bit代表的是时间,后8位代表的是一个数值,frequency是频率,代表的是这个对象的访问次数。
前16bit时间有什么用呢?大胆猜测应该是跟时效性有关的,那么究竟是怎么解决的呢?
我们再来看个生活中的例子
大家应该充过一些会员,比如我这个年纪的,小时候喜欢充腾讯的黄钻、 绿钻、蓝钻等等。
但是有一个点,假如哪天我没充钱了的话,或者没有续VIP的时候,我这个 钻石等级会随着时间的流失而降低。比如我本来是黄钻V6,但是一年不充 钱的话,可能就变成了V4。
那么有了这个例子,在redis中,我们是不是也可以猜测: 这个时间是记录的这个对象有多久没访问了,如果超过了多久没访问,就去减少对应的次数。
源码验证:
LFUDecrAndReturn方法(evict.c)
unsigned long LFUDecrAndReturn(robj *o) {
//lru字段右移8位,得到前面16位的时间
unsigned long ldt = o->lru >> 8;
//lru字段与255进行&运算(255代表8位的最大值),
//得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值
//LFUTimeElapsed(ldt)源码见下
//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
unsigned long num_periods = server.lfu_decay_time ?
LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能减少为负数,非负数用couter值减去衰减值
counter = (num_periods > counter) ? 0 : counter -
num_periods;
return counter;
}衰减因子的配置
lfu-decay-time 1 //多少分钟没操作访问就去衰减一次
后8bits的次数,最大值是255,肯定不够,但是我们可以让数据达到255很难,就是每个数值都是访问了多少次才+1,那么redis究竟是怎么做的呢?
LFULoglncr方法(evict.c文件)
uint8_t LFULogIncr(uint8_t counter) {//如果已经到最大值255,返回255 ,8位的最大值if (counter == 255) return 255;//得到随机数(0-1)double r = (double)rand()/RAND_MAX;//LFU_INIT_VAL表示基数值(在server.h配置) 默认为5double baseval = counter - LFU_INIT_VAL;//如果达不到基数值,表示快不行了,baseval =0if (baseval < 0) baseval = 0;//如果快不行了,肯定给他加counter//不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关//都是在分子,所以2个值越大,加counter几率越小double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;return counter;
}所以,LFU加的逻辑我们可以总结下:
- 最大只能到255, 如果到了255,不往上加
- 如果当前次数5<count<255,那么越往上,加的概率越低 lfu-log-factor配置 的值越大,添加的几率越小!
- 如果小于等于5,每次访问必加1,因为p=1,r是0到1之间的随机数,必然小于p
来看一波官方给的压测数据
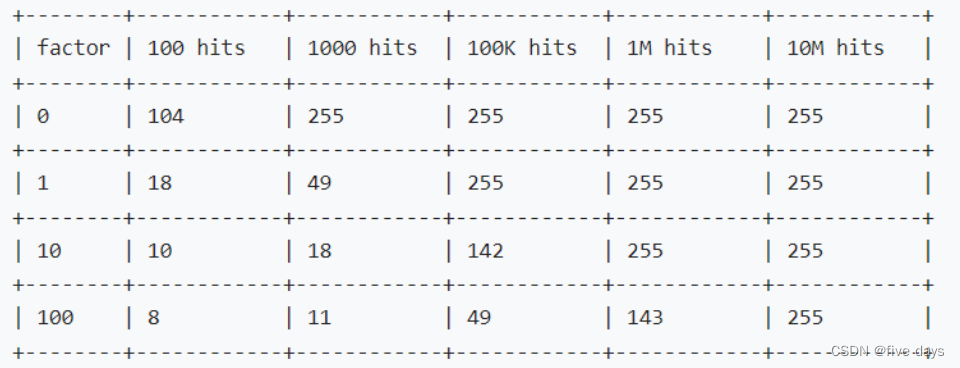
factor因子与点击量的关系。
相关文章:
Redis之内存管理过期、淘汰机制
1.Redis内存管理 我们的redis是一个内存型数据库,我们的数据也都是放在内存中的,内存是有限的空间,当数据满了之后,我们要怎么样继续保证redis的可用性呢?我们就需要采取点管理措施和机制来保证我们redis的可用性。 在redis.co…...

金融科技赋能跨境支付:便捷与安全并驾齐驱
一、引言 在全球经济一体化的背景下,跨境支付作为国际贸易和金融活动的重要组成部分,正迎来金融科技浪潮的洗礼。金融科技以其独特的创新性和颠覆性,正在重塑跨境支付市场的格局,使其更加便捷、高效且安全。本文旨在探讨金融科技如何助力跨境支付,实现便捷与安全并存,并…...
【康耐视国产案例】智能AI相机:深度解析DataMan 380大视野高速AI读码硬实力
随着读码器技术的不断更新迭代,大视野高速应用成为当前工业读码领域的关键发展方向。客户对大视野高速读码器的需求源于其能显著减少生产成本并提升工作效率。然而,大视野应用场景往往伴随着对多个条码的读取需求,这无疑增加了算法的处理负担…...
SQL实验 带函数查询和综合查询
一、实验目的 1.掌握Management Studio的使用。 2.掌握带函数查询和综合查询的使用。 二、实验内容及要求 1.统计年龄大于30岁的学生的人数。 --统计年龄大于30岁的学生的人数。SELECT COUNT(*) AS 人数FROM StudentWHERE (datepart(yea…...

【前端每日基础】day34——HTTP和HTTPS
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)是互联网通信协议,用于在Web浏览器和Web服务器之间传输数据。以下是对HTTP和HTTPS的详细介绍: HTTP(Hypertext…...

go mongo 唯一索引创建
1. 登录mongo,创建数据库 mongosh -u $username -p $password use test 2. 查看集合索引 db.$collection_name.getIndexes() 为不存在的集合创建字段唯一索引 package mainimport ("context""fmt""log""time""go…...

微信小程序如何进行页面跳转
微信小程序中的页面跳转可以通过多种方式实现,以下是几种主要的跳转方式及其详细解释: wx.navigateTo 功能:保留当前页面,跳转到应用内的某个页面。特点: 可以在新页面使用wx.navigateBack返回原页面。每跳转一个新页…...

信息标记形式 (XML, JSON, YAML)
文章目录 🖥️介绍🖥️三种形式🏷️XML (Extensible Markup Language)🔖规范🔖注释🔖举例🔖其他 🏷️JSON (JavaScript Object Notation)🔖规范🔖注释&#x…...

C语言:学生成绩管理系统(含源代码)
一.功能 二.源代码 #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAX_NUM 100 typedef struct {char no[30];char name[10];char sex[10];char phone[20];float cyuyan;float computer;float datastruct; } *student, student1;typ…...

MySQL 导出导入的101个坑
最近接到一个业务自行运维的MySQL库迁移至标准化环境的需求,库不大,迁移方式也很简单,由开发用myqldump导出数据、DBA导入,但迁移过程坎坷十足,记录一下遇到的各项报错及后续迁移注意事项。 一、 概要 空间问题源与目…...

OpenCv之简单的人脸识别项目(人脸提取页面)
人脸识别 准备五、人脸提取页面1.导入所需的包2.设置窗口2.1定义窗口外观和大小2.2设置窗口背景2.2.1设置背景图片2.2.2创建label控件 3.定义单人脸提取脚本4.定义多人脸提取脚本5.创建一个退出对话框6.按钮设计6.1单人脸提取按钮6.2多人脸提取按钮6.3返回按钮 7.定义关键函数8…...
linux 内核映像差异介绍:vmlinux、zImage、zbImage、image、uImage等
一、背景 Linux内核是整个Linux操作系统的核心部分,它是一个负责与硬件直接交互的软件层,并且提供多种服务和接口,让用户程序能够方便地使用硬件资源。 当我们编译自定义内核时,可以将其生成为以下内核映像之一:vmli…...
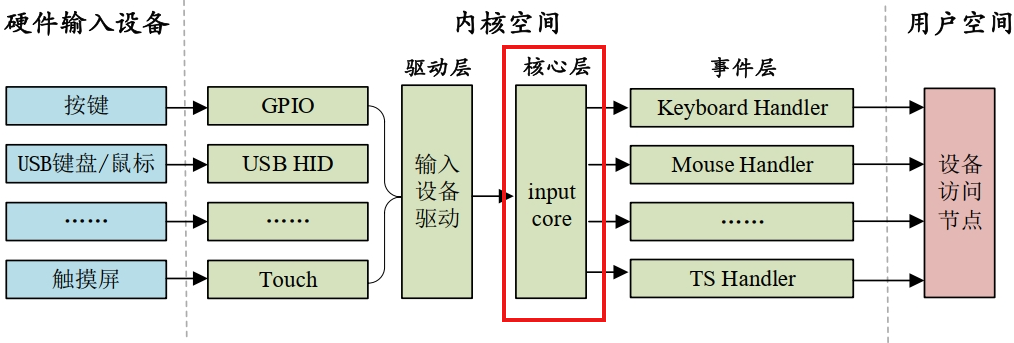
【Linux-INPUT输入的子系统】
Linux-INPUT输入的子系统 ■ input 子系统简介■ input 驱动编写流程■ 事件类型 ■ ■ input 子系统简介 input 子系统就是管理输入的子系统, input 子系统分为 input 驱动层、 input 核心层、 input 事件处理层,最终给用户空间提供可访问的设备节点 …...

密码加密及验证
目录 为什么需要加密? 密码算法分类 对称密码算法 非对称密码算法 摘要算法 DigestUtils MD5在线解密工具原理 实现用户密码加密 代码实现 为什么需要加密? 在MySQL数据库中,我们常常需要对用户密码、身份证号、手机号码等敏感信息进…...
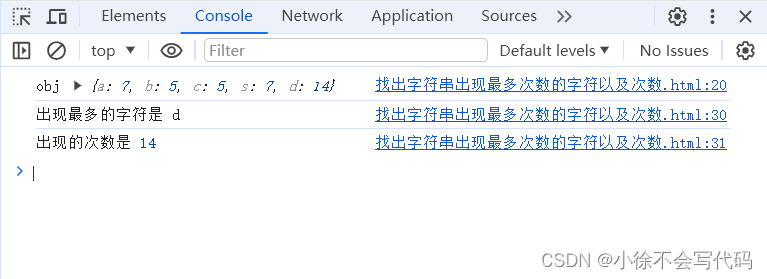
找出字符串中出现最多次数的字符以及出现的次数
str.charAt(i) 是JavaScript中获取字符串中特定位置字符的方法,表示获取当前的字符。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-wi…...
如何看待央行买卖长期国债?
央行远比大家想象中的要渴求货币宽松。 引子 今年以来,有不少关于“央行买卖长期国债”的讨论,前些时候关注点在“买”,最近关注点在“卖”。 然而,市场上的讨论采用了十分粗糙和松散的“自然语言”,所以࿰…...
)
MATLAB算法实战应用案例精讲-【数模应用】Turf组合模型(附MATLAB、python和R语言代码实现)
目录 几个高频面试题目 如何以最小的成本覆盖到最大的消费群体? 应用场景 TURF举例...

android源码下载编译模拟器运行
安卓aosp源码下载,编译,模拟器运行 virtualbox7 安装ubuntu20.04,ubuntu22.04 编译android aosp 源码可以,但是模拟器跑不了,哪个版本都是要么黑屏,要么整个vbox虚拟机闪退。解决方案使用vmware17 ##拯救…...

Golang:Sirupsen/logrus是一个日志库
Sirupsen/logrus是一个日志库 文档 https://github.com/Sirupsen/logrus 安装 go get github.com/sirupsen/logrus代码示例 package mainimport ("github.com/sirupsen/logrus" )func main() {var log logrus.New()log.Trace("Something very low level.&…...
Android Studio插件开发 - Dora SDK的IDE插件
IDE插件开发简介 Android Studio是一种常用的集成开发环境(IDE),用于开发Android应用程序。它提供了许多功能和工具,可以帮助开发人员更轻松地构建和调试Android应用程序。 如果你想开发Android Studio插件,以下是一…...
)
北邮数电实验:用Verilog在FPGA上实现4位加法器,从全加器到数码管显示(附完整代码与管脚绑定)
北邮数电实验:从全加器到4位加法器的FPGA实现全流程解析 第一次接触FPGA上的数字电路实验时,看着开发板上密密麻麻的管脚和闪烁的LED,我完全不知道从何入手。直到亲手实现了一个4位加法器,才真正理解了数字系统设计的精髓——用硬…...

Circuit事件处理深度解析:如何优雅处理用户交互
Circuit事件处理深度解析:如何优雅处理用户交互 【免费下载链接】circuit ⚡️ A Compose-driven architecture for Kotlin and Android applications. 项目地址: https://gitcode.com/gh_mirrors/cir/circuit 在构建现代化的Android和Kotlin应用时ÿ…...

bezier-easing性能优化秘籍:牛顿迭代与二分搜索算法详解
bezier-easing性能优化秘籍:牛顿迭代与二分搜索算法详解 【免费下载链接】bezier-easing cubic-bezier implementation for your JavaScript animation easings – MIT License 项目地址: https://gitcode.com/gh_mirrors/be/bezier-easing 在现代Web动画开发…...

避坑指南:合宙ESP32-C3连接MPU6050时常见的I2C通信失败与数据跳变问题
ESP32-C3与MPU6050实战避坑手册:从I2C通信失败到数据稳定的全链路解决方案 当你在深夜调试ESP32-C3与MPU6050的组合时,突然发现串口监视器不断弹出"not find MPU6050"的红色警告,或者读取到的加速度数据像过山车一样疯狂跳动——这…...

Tenstorrent:基于RISC-V的异构计算架构如何挑战AI芯片市场
1. 项目概述:Tenstorrent的野心与Jim Keller的蓝图在芯片设计的江湖里,Jim Keller这个名字本身就代表着一种传奇。从AMD的K7、K8架构,到苹果A系列、M1芯片的奠基,再到特斯拉的自动驾驶芯片,他参与的每一个项目都深刻影…...

深入Linux内存管理:从虚拟内存到OOM Killer的完整解析
1. 从物理到虚拟:内存管理的演进与核心挑战干了这么多年系统开发和性能调优,内存问题始终是那个最让人头疼,但又不得不面对的“老朋友”。无论是半夜被报警叫醒处理线上服务的OOM(Out of Memory)崩溃,还是为…...

线下技术沙龙:AI Coding深度实践LLM应用分享
活动简介 我们正在经历一场软件开发 范式的变革。从Copilot的智能补全,到Cursor的对话式编程,再到Agent自主完成复杂任务——代码的编写方式,正在被重新定义。 但这场变革的核心,不是工具本身,而是使用工具的人。 本…...

Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图
Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图 在ROS开发中,地图可视化工具Mapviz因其强大的插件系统和高度可定制性备受青睐。然而,Ubuntu20.04环境下安装Mapviz时,Qt版本冲突和OpenCV链接错误…...

WebShell-Bypass-Guide字符串处理函数免杀技巧详解
WebShell-Bypass-Guide字符串处理函数免杀技巧详解 【免费下载链接】WebShell-Bypass-Guide 从零学习Webshell免杀手册 项目地址: https://gitcode.com/gh_mirrors/we/WebShell-Bypass-Guide WebShell免杀技术是网络安全领域的重要技能,而字符串处理函数是构…...

你的RAR5密码有多安全?我用hashcat掩码攻击实测了一下
RAR5密码安全实测:从暴力破解到防御策略 当你在深夜赶工,把重要文件打包成加密压缩包发送给同事时,是否想过这个密码能撑多久?上周我给自己设置了一个看似安全的8位数字密码,结果在咖啡还没凉透前就被破解了。这不是危…...