pytorch笔记:自动混合精度(AMP)
1 理论部分
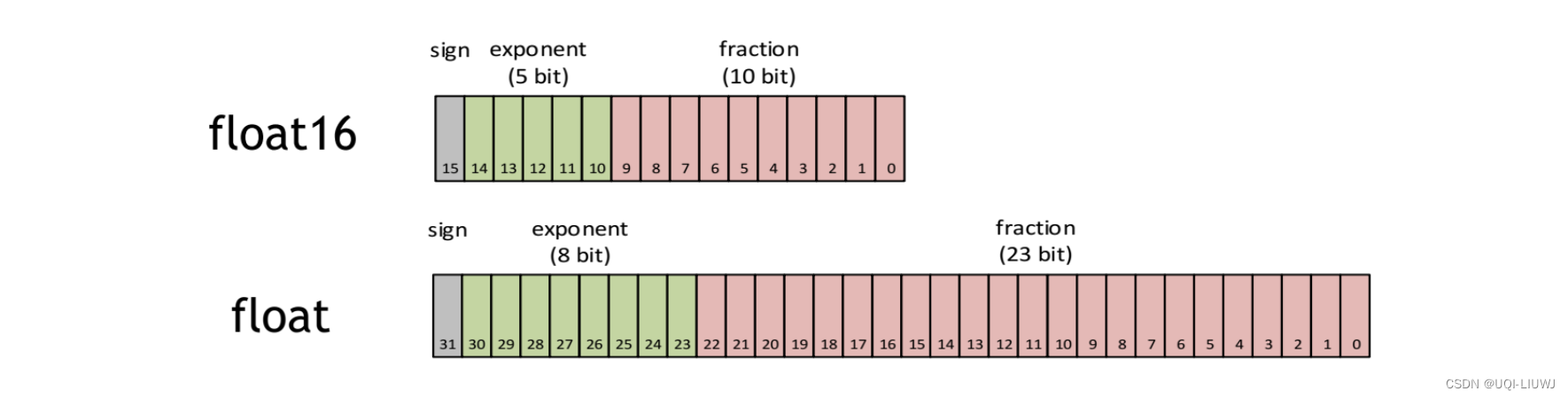
1.1 FP16 VS FP32
- FP32具有八个指数位和23个小数位,而FP16具有五个指数位和十个小数位
- Tensor内核支持混合精度数学,即输入为半精度(FP16),输出为全精度(FP32)
1.1.1 使用FP16的优缺点
- 优点
- FP16需要较少的内存,因此更易于训练和部署大型神经网络,同时还减少了数据移动(同时可以使用更大的batch)
- 数学运算的运行速度大大降低了
- NVIDIA提供的Volta GPU的确切数量是:FP16中为125 TFlops,而FP32中为15.7 TFlops(加速8倍)
- 缺点:
- 从FP32转到FP16时,必然会降低精度
- 但有的时候,这个精度的降低可以忽略不计
- FP16实际上可以很好地表示大多数权重和渐变。
- ——>拥有存储和使用FP32所需的所有这些额外位只是浪费。

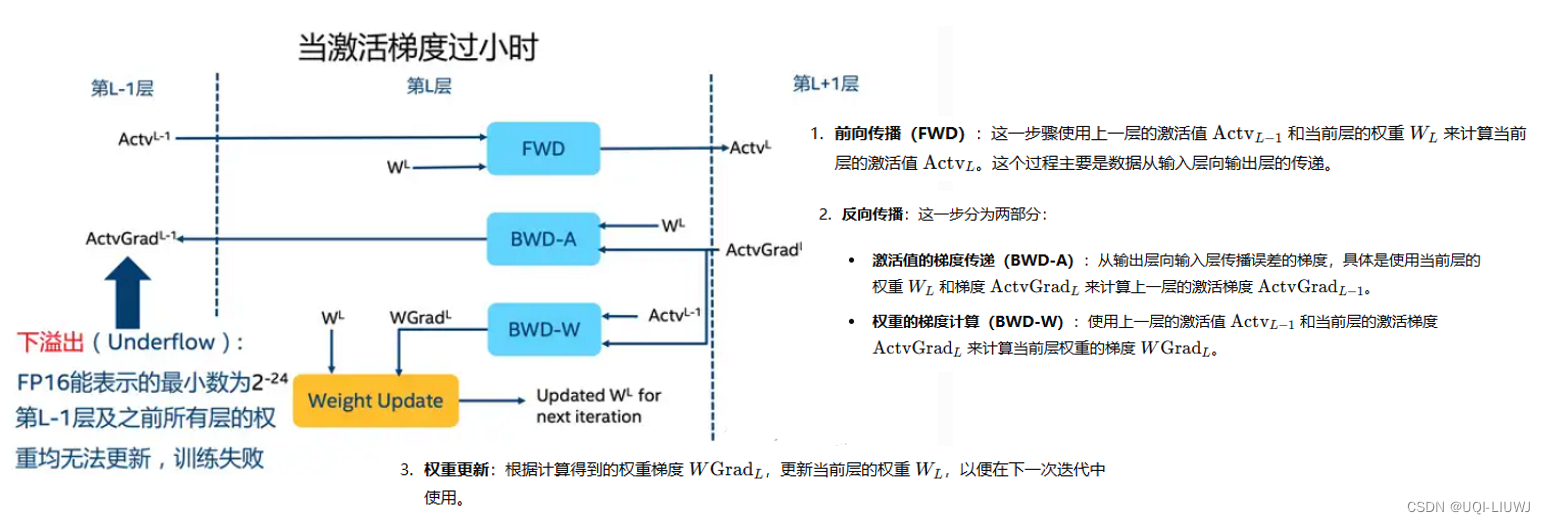
- 溢出错误
- 由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出
- 溢出之后就会出现"NaN"的问题
- 从FP32转到FP16时,必然会降低精度
1.2 解决上述FP16的问题
1.2.1 混合精度训练
- 用FP16做储存和乘法,而用FP32做累加避免舍入误差
- ——>混合精度训练的策略有效地缓解了舍入误差的问题
1.2.2 损失放大(Loss scaling)
- 即使使用了混合精度训练,还是存在无法收敛的情况
- 原因是激活梯度的值太小,造成了溢出。
- ——>通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的下溢出
- 只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去
-
反向传播前,将损失变化手动增大2^k倍
-
因此反向传播时得到的中间变量(激活函数梯度)不会溢出;
-
-
反向传播后,将权重梯度缩小2^k倍,恢复正常值。
-
- 只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去
2 torch.cuda.amp
- AMP(自动混合精度)的关键词有两个:
- 自动
- Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预
- 混合精度
- 采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor
- 自动
2.1 Pytorch中不同类型的tensor
| 类型名称 | 位数 |
| torch.DoubleTensor | 64bit |
| torch.LongTensor | 64bit |
| torch.FloatTensor(默认) | 32bit |
| torch.IntTensor | 32bit |
| torch.HalfTensor | 16bit |
| torch.BFloat16Tensor | 16bit |
| torch.ShortTensor | 16bit |
| torch.ByteTensor(无符号) | 8bit |
| torch.CharTensor | 8bit |
| torch.BoolTensor | Boolean |
2.2 在AMP上下文中,被自动转化为半精度浮点型的参数:
| __matmul__ |
| addbmm |
| addmm |
| addmv |
| addr |
| baddbmm |
| bmm |
| chain_matmul |
| conv1d |
| conv2d |
| conv3d |
| conv_transpose1d |
| conv_transpose2d |
| conv_transpose3d |
| linear |
| matmul |
| mm |
| mv |
| prelu |
2.3 autocast
from torch.cuda.amp import autocast as autocastmodel = Net().cuda()
#首先初始化一个网络模型Net(),并使用.cuda()方法将模型移至GPU上以利用GPU加速
#Net中的参数默认是torch.FloatTensoroptimizer = optim.SGD(model.parameters(), ...)for input, target in data:optimizer.zero_grad()with autocast():output = model(input)loss = loss_fn(output, target)'''自动混合精度环境包含了前向过程(模型的输出)和loss的计算把支持参数对应tensor的dtype转换为半精度浮点型,从而在不损失训练精度的情况下加快运算进入autocast的上下文时,tensor可以是任何类型不需要在model或者input上手工调用.half() ,框架会自动做'''loss.backward()optimizer.step()# 反向传播在autocast上下文之外2.4 GradScaler
在2.3的基础上增加,反向传播时增加梯度,以防止下溢出
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScalermodel = Net().cuda()
#首先初始化一个网络模型Net(),并使用.cuda()方法将模型移至GPU上以利用GPU加速
#Net中的参数默认是torch.FloatTensoroptimizer = optim.SGD(model.parameters(), ...)scaler = GradScaler()
# 在训练最开始之前实例化一个GradScaler对象for epoch in epochs:for input, target in data:optimizer.zero_grad()with autocast():output = model(input)loss = loss_fn(output, target)'''自动混合精度环境包含了前向过程(模型的输出)和loss的计算把支持参数对应tensor的dtype转换为半精度浮点型,从而在不损失训练精度的情况下加快运算进入autocast的上下文时,tensor可以是任何类型不需要在model或者input上手工调用.half() ,框架会自动做'''scaler.scale(loss).backward()# Scales loss. 为了梯度放大,防止下溢出# 代替原来的loss.backward()scaler.step(optimizer)'''scaler.step() 首先把梯度的值unscale回来.如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新(不被破坏)'''scaler.update()'''准备着,看是否要增大scaler'''- scaler的大小在每次迭代中动态的估计
- 为了尽可能的减少梯度underflow,scaler应该更大
- 但是如果太大的话,半精度浮点型的tensor又容易overflow(变成inf或者NaN)。
- ——>动态估计的原理就是在不出现inf或者NaN梯度值的情况下尽可能的增大scaler的值
3 一些tips
- 为了保证计算不溢出,首先保证人工设定的常数不溢出。如epsilon,INF等
- Dimension最好是8的倍数:维度是8的倍数,性能最好
- 涉及sum的操作要小心,容易溢出
- 比如softmax操作,建议用官方API,并定义成layer写在模型初始化里
- 如果遇到以下的报错:
-
RuntimeError: expected scalar type float but found c10::Half - 需要手动在tensor上调用.float()
-
相关文章:
pytorch笔记:自动混合精度(AMP)
1 理论部分 1.1 FP16 VS FP32 FP32具有八个指数位和23个小数位,而FP16具有五个指数位和十个小数位Tensor内核支持混合精度数学,即输入为半精度(FP16),输出为全精度(FP32) 1.1.1 使用FP16的优缺…...

R语言ggplot2包绘制世界地图
数据和代码获取:请查看主页个人信息!!! 1. 数据读取与处理 首先,从CSV文件中读取数据,并计算各国每日收入的平均签证成本。 library(tidyverse) df <- read_csv("df.csv") %>% group_…...
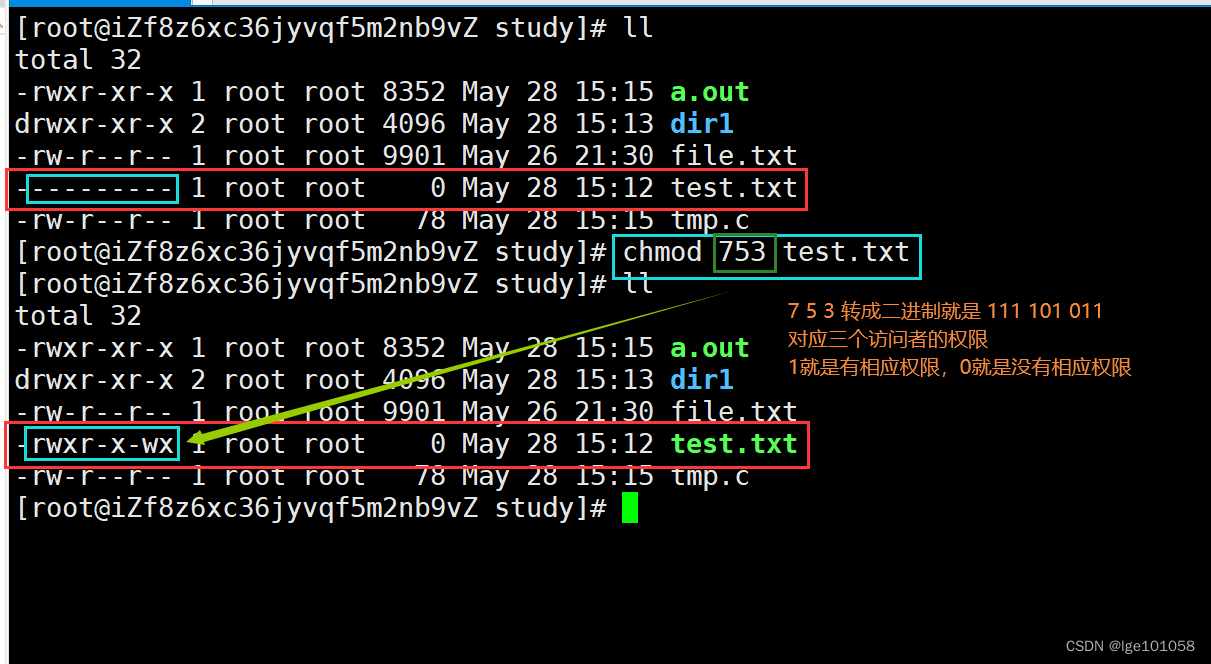
【Linux】Linux的权限_1
文章目录 三、权限1. shell外壳2. Linux的用户3. Linux权限管理文件访问者的分类文件类型和访问权限 未完待续 三、权限 1. shell外壳 为什么要使用shell外壳 由于用户不擅长直接与操作系统直接接触和操作系统的易用程度、安全性考虑,用户不能直接访问操作系统。 什…...

日语_远程办公常用日语单词
基本词汇 リモートワーク(Rimōto Wāku):远程工作テレワーク(Terewāku):远程工作(Telework)在宅勤務(ざいたくきんむ,Zaitaku Kinmu)ÿ…...

MTK 平台项目security boot 开启/关闭 及 系统签名流程
以 https://online.mediatek.com/FAQ#/SW/FAQ26691 为基础做如下记录以做备忘: How to Enable/Disable Secure Boot for Security 3.0: 1、 How to Enable Path Enable Preloader /vendor/mediatek/proprietary/bootable/bootloader/preloader/custom/{…...
JDBC连接MySQL
目录 1.数据库编程的必备条件 2.Java的数据库编程JDBC 3.JDBC的工作原理 4.第三方库connector的下载和导包 5.JDBC的使用 使用步骤 (1)创建数据源对象DataSource (2)给对象设置必要的属性 (3)和数据…...
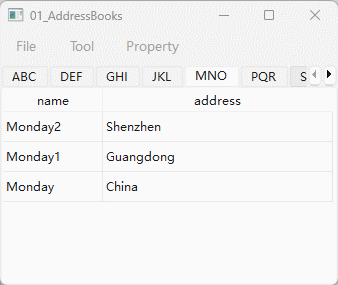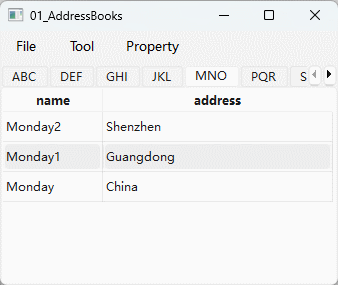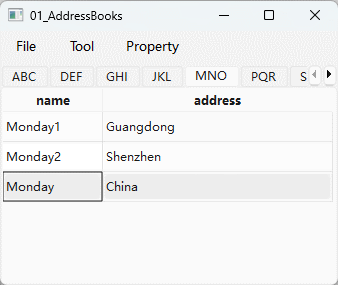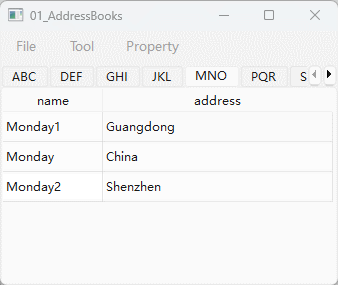
【Qt】【模型视图架构】 在项目视图中启用拖放
文章目录 1. 在便捷类中启用拖放2. 在模型/视图类中启用拖放 模型/视图框架支持Qt的拖放应用。 列表、表格和树中的项目可以在视图中被拖拽,数据作为MIME编码的数据被导入和导出。标准视图可以自动支持内部的拖放。 默认视图的拖放功能并没有被启用,如果…...
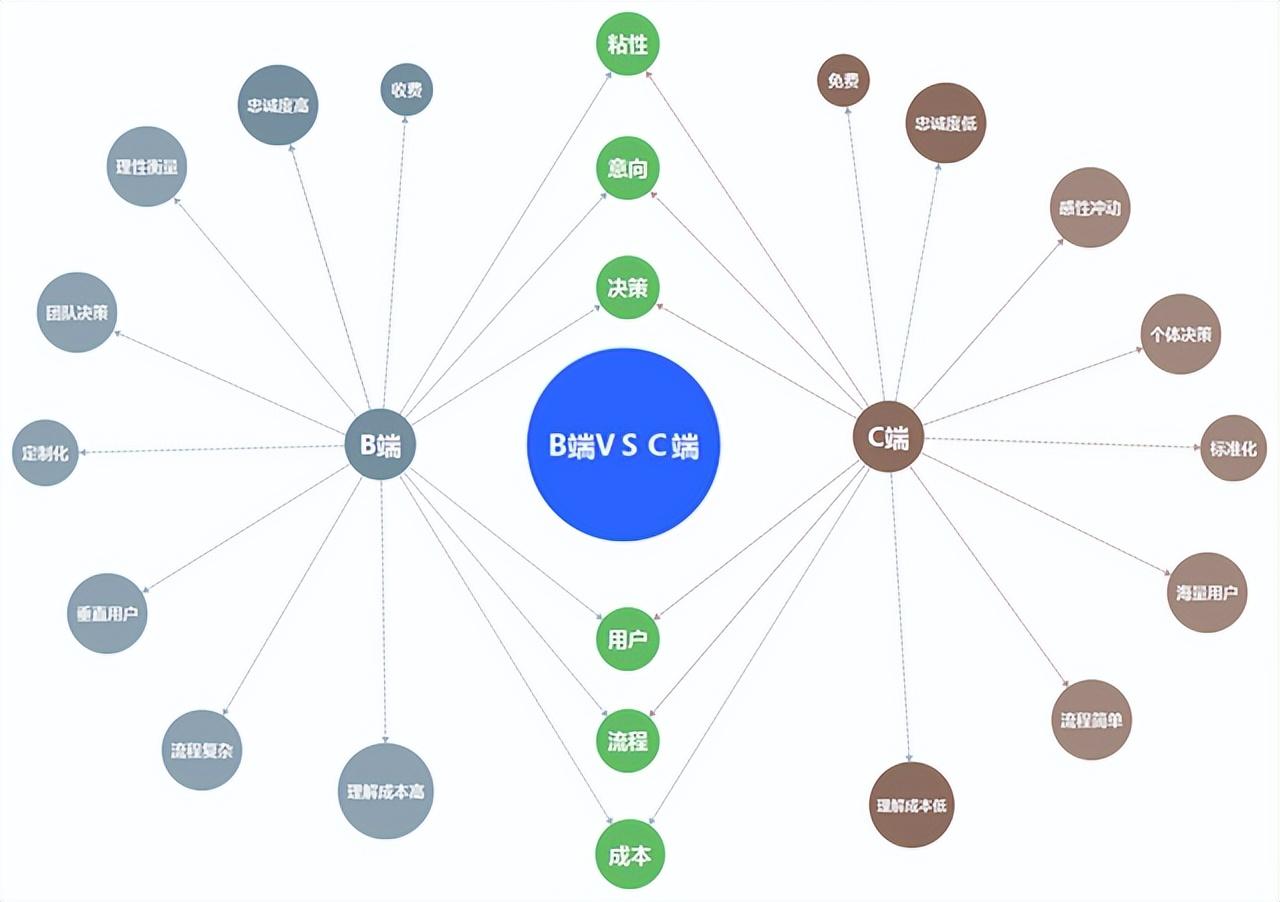
B端产品无爆款,说有的都是忽悠和外行!
前言:网上经常有人讲运营,把C端那一套硬搬到B端,讲的自我陶醉,稍微有点常识的人就知道不能这么玩。 一、什么是B端和C端 B端(Business-to-Business)是指面向企业客户的市场和产品。B端产品或服务主要是为…...

腾讯云的身份证核验,找不到这个类
文件上传功能在许多Web应用程序中是非常常见的需求之一。然而,由于文件上传存在安全风险,保护用户上传的文件的安全性,以及防止黑客利用上传功能进行攻击是非常重要的。在本文中,我们将讨论一些常见的安全漏洞,并提供一…...

vue3 vue-draggable-next 实现拖拽穿梭框效果
一、vue3 vue-draggable-next 实现拖拽穿梭框效果 <template> <div> <h2>列表 1</h2> <draggable v-model"list1" group"items" tag"transition-group" end"onDragEnd"> <div v-for"(item…...
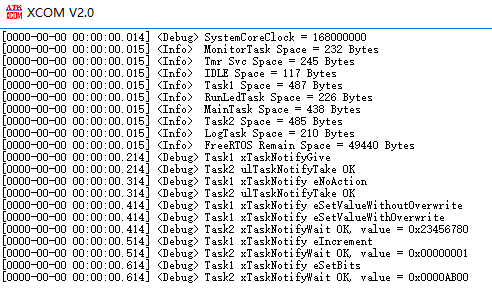
FreeRTOS【16】直达任务通知使用
1.开发背景 直达任务通知,FreeRTOS 的线程任务提供的接口,可以用作线程唤醒,或者是传递数据,因为是基于线程本身的操作,是轻量级,速度响应更快,适合小内存芯片使用。 事实上本人使用得比较少&am…...
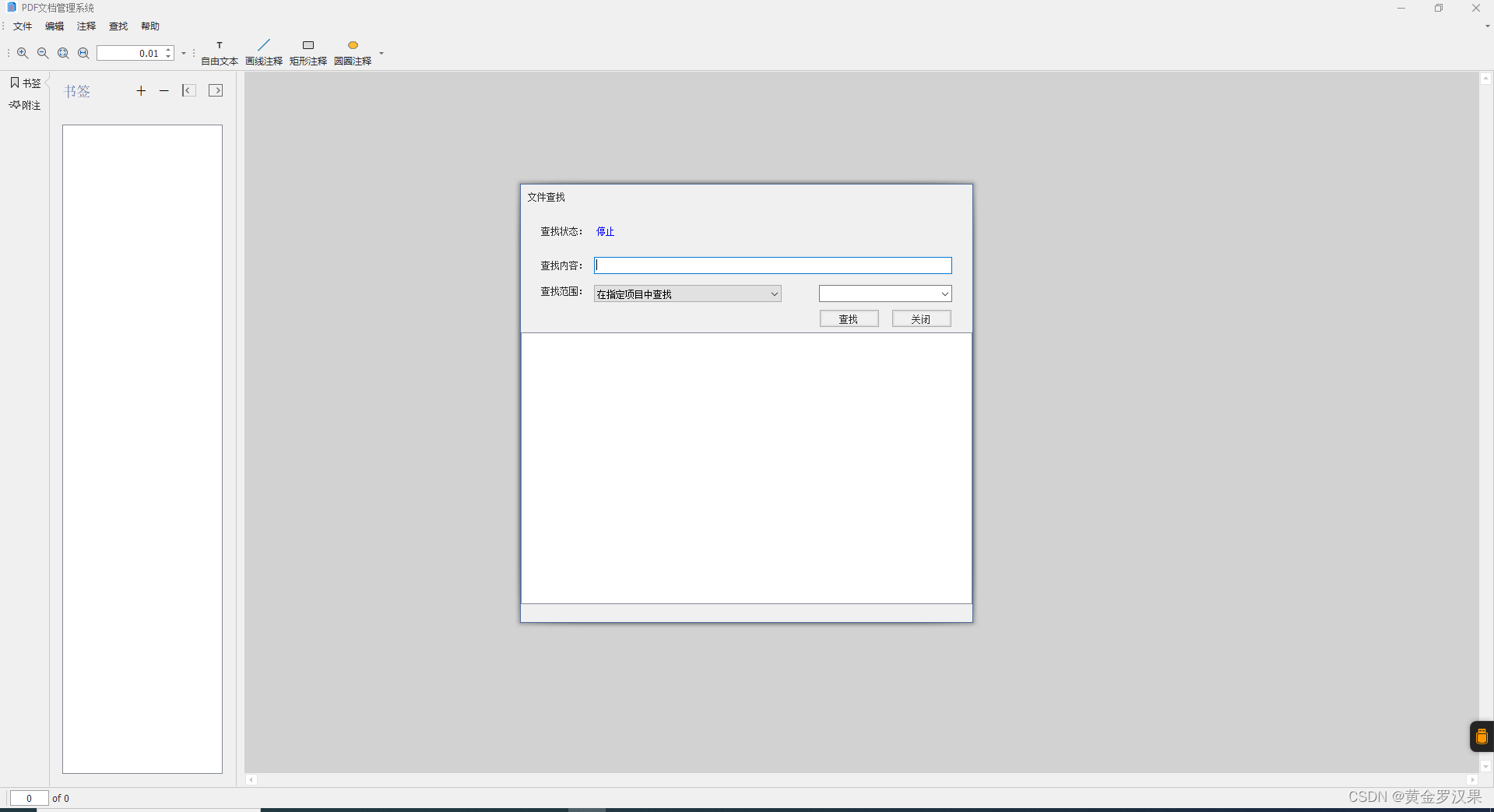
关于软件<PDF文档管理系统V1.0>的介绍
<PDF文档管理系统V1.0>(下载地址在最下面)是我在2023年发布的<知识辅助系统>的改善以及重新开发版本,软件在重新开发提供了<知识辅助系统>的所有功能的基础上,添加了一些新的功能。软件尽量提供简单、实用的功能…...

Java面试题-Tomcat初级面试题
Tomcat是什么?请简述它的主要功能。 Tomcat是一个开源的Web应用服务器,由Apache软件基金会开发。它是一个实现了Java Servlet和JavaServer Pages(JSP)技术的容器,用于处理客户端的请求并返回响应。Tomcat的主要功能如…...

红队内网攻防渗透:内网渗透之windows内网权限提升技术:数据库篇
红队内网攻防渗透 1. 内网权限提升技术1.1 数据库权限提升技术1.1.1 数据库提权流程1.1.1.1 先获取到数据库用户密码1.1.1.2 利用数据库提权工具进行连接1.1.1.3 利用建立代理解决不支持外联1.1.1.4 利用数据库提权的条件及技术1.1.2 Web到Win-数据库提权-MSSQL1.1.3 Web到Win-…...

rust嵌入式开发之总结
我们用rust开发的新版产品刚刚交付,已经在海上安装测试完毕并顺利投产。终于松了口气,同时也有时间和精力来做个全面的总结了。 这个产品,目前差不多有三版: 第一个版本是用crt-thread写的,投产后出了一个内存泄露的…...

【制作100个unity游戏之27】使用unity复刻经典游戏《植物大战僵尸》,制作属于自己的植物大战僵尸随机版和杂交版6(附带项目源码)
最终效果 系列导航 文章目录 最终效果系列导航前言方法一、使用excel配置表excel转txt文本读取txt数据按配置信息生成僵尸 方法二、使用ScriptableObject 配置关卡信息源码结束语 前言 本节主要是推荐两种实现配置关卡信息,并按表生成僵尸和关卡波次 方法一、使用…...

回溯算法指组合总和
题目: 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 思路: 这种问题…...

java-stream转换map key重复报错解决小记
解决key重复问题 在用stream转成map过程中会有key重复的隐患,如果数据没重复还好,如果重复了会提示 java.lang.IllegalStateException: Duplicate key 8753444332651at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)at ja…...

王春城 | 如何解决精益转型过程中的信任问题?
实践证明,精益转型不仅仅是技术和管理方法的更新,更是一场深刻的文化变革。在这个过程中,涉及到多个部门、多个层级的协同合作,需要团队成员之间的深度沟通和高度信任。如果缺乏信任,团队成员之间就会产生隔阂和抵触情…...

Ubuntu Nvidia Docker单机多卡环境配置
ubuntu版本是22.04,现在最新版本是24.xx,截止当前,Nvidia的驱动最高还是22.04版本,不建议更新至最新版本。本部分是从0开始安装Nvidia docker的记录,若已安装Nvdia驱动,请直接跳至3。 1、更新软件软件列表…...

CANN-NPU 显存回收策略:内存碎片整理与显存池化机制实战
一、显存碎片从哪来 1.1 碎片的两种形态 外部碎片——总空闲内存够用,但不连续。比如有 4 块 128MB 空闲,但需要一块 512MB 的连续内存,分配失败。 内部碎片——分配器按固定大小的块分配,实际使用的比分配的小。比如分配 400KB&a…...
)
2026年亲测AI写作辅助软件指南(高效定稿版)
为解决学术写作中效率与合规两大核心痛点,本文精选8款高适配性AI论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度筛选,同时配套分场景精准选型方案与学术合…...

2026 收藏版|程序员转行 AI 大模型应用开发,5 步零基础上岸学习路线
身为程序员,或是打算跨界进军AI应用开发赛道的朋友,真心建议大胆投递岗位,别被招聘简章里严苛的任职要求劝退。诸如精通大模型底层原理、具备多年AI从业经验这类条件,大多只是企业理想招聘标准。 身边不少同行都是秉持先入职深耕、…...

Unity C#方法设计实战:从参数传递到跨脚本调用
1. 这不是语法课,是写代码时每天要面对的“沟通现场”刚带完一批Unity新手做小项目,有个现象特别明显:很多人能背出“方法就是函数”“参数分值传递和引用传递”,但一到实际写代码就卡壳——比如想让角色跳跃时播放音效࿰…...

DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开
更多请点击: https://kaifayun.com 第一章:DeepSeek技术搜索RAG Pipeline重构实录:从模糊匹配到精准意图识别的6次AB测试数据全公开 在DeepSeek内部技术文档搜索系统升级中,我们对原有RAG Pipeline进行了深度重构,核心…...

知名私募急招超高频的人选,tick级别那种,预算八位数+cut,欢迎自荐、推荐[嘿哈]
知名私募急招超高频的人选,tick级别那种,预算八位数cut,欢迎自荐、推荐[嘿哈]...

GQA:多查少算的 Attention 头组合
本文基于昇腾CANN和昇腾NPU,围绕 ops-transformer 仓库的相关技术展开。 MHA(Multi-Head Attention)每个 Head 一套 QKV——8 个 Head 就是 8 组。MQA 省过头了——8 个 Head 共享 K、V。GQA(Grouped Query Attention)…...

大模型概念遗忘:SCUGP梯度投影实现精准神经外科手术
1. 项目概述:这不是“删除记忆”,而是给大模型做一次精准的神经外科手术“Who is Harry Potter?”——这个看似简单的问答,恰恰成了检验大模型“概念遗忘”能力的黄金测试题。微软研究院这篇论文标题里藏着一个反直觉的事实:他们…...

3DS原生GBA硬件实战指南:open_agb_firm深度解析与高效方案
3DS原生GBA硬件实战指南:open_agb_firm深度解析与高效方案 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_agb_firm…...

3DS GBA硬件直通终极指南:用open_agb_firm获得原生游戏体验
3DS GBA硬件直通终极指南:用open_agb_firm获得原生游戏体验 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_agb_fir…...