番外篇-用户购物偏好标签BP-推荐算法ALS
引言
推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。
推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。
数据仓库(Data Warehouse) -> 用户画像(User Profile) -> 推荐系统(Recommend System)
用户购物偏好模型:依据用户浏览行为日志数据,给用户推荐可能感兴趣的商品。
- 数据集:tbl_logs 表数据
- 推荐商品:Top5商品
- 解决方案:协同过滤推荐算法ALS
推荐系统概述
推荐系统是信息过载所采用的措施,面对海量的数据信息,从中快速的推荐出符合用户特点的物品。
推荐系统是自动化的通过分析用户的历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的信息的软件系统。

推荐引擎需要依赖用户的行为日志,因此一般都作为一个后台应用程序存在于网站中。通过截取网站提供了大量用户行为日志,给用户提供不同的个性化页面或者信息,提高整个网站的点击率和转化率。

推荐系统一般都由三个部分组成,前端的交互界面、日志系统以及推荐算法系统。
个性化推荐的成功需要两个条件:
- 存在信息过载,用户不能很容易从所有物品中找到喜欢的物品
- 用户大部分时候没有明确的需求
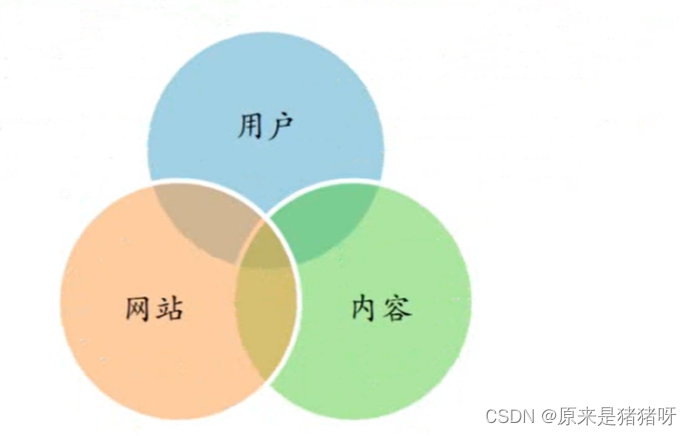
一个完整的推荐系统一般存在3个参与方:用户、内容提供者和提供推荐系统的网站。
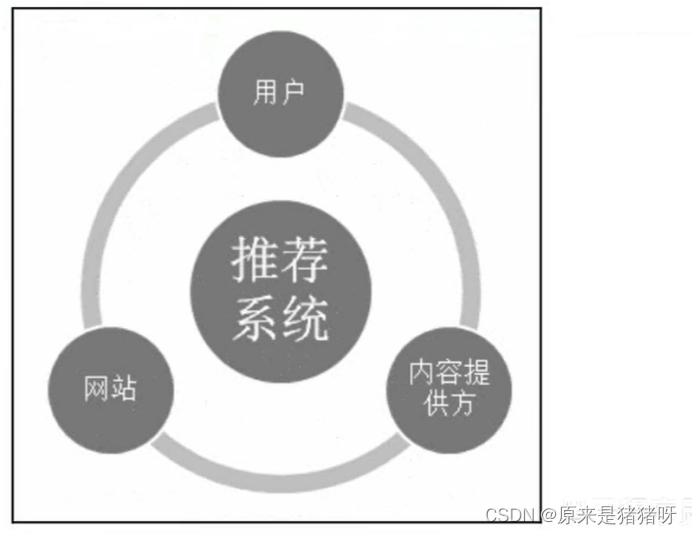
比如一个图书推荐系统:
- 推荐系统需要满足用户的需求,能给用户推荐那些令他们感兴趣的图书。
- 推荐系统要让各出版社的书都能够推荐给对其感兴趣的用户,恶如是只推荐几个大型出版社的书。
- 推荐系统应该能够收集到高质量的用户反馈,不断完善推荐的质量,增加用户和网站的交互,提高网站的收入。
好的推荐系统是一个能够让三分共赢的系统。
好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户去“发现”更多自己可能感兴趣的事务。
·让用户更快更好的获取到自己需要的内容
·让内容更快更好的推送到喜欢他的用户手中
·让网站(平台)更有效的保留用户资源
推荐系统的基本思想
利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征的物品。
利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
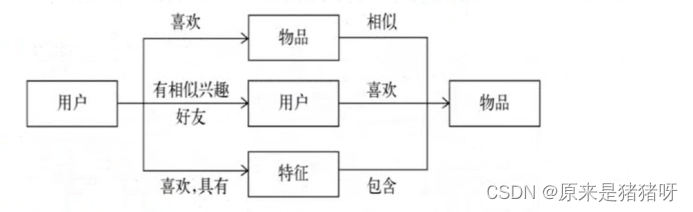
即:
知你所想,精准推送
利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征和物品。
物以类聚
利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
人以群分
利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
推荐系统数据分析
推荐系统主要根据用户数据、物品数据以及用户对物品行为数据(评分数据、点击数据、购物数据等)
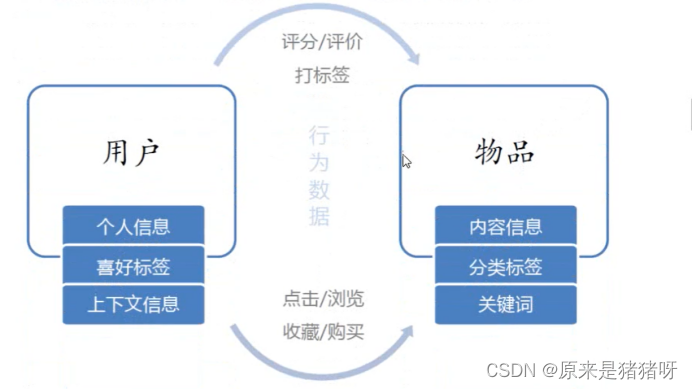
不同数据说明如下:
其一:要推荐物品或者内容的元数据
例如关键字、分类标签、基因描述等
其二:系统用户的基本信息
例如性别、年龄、兴趣标签等
其三:用户的行为数据,可以转换为对物品或信息的偏好
根据应用本身的不同,可以包括用户对物品的评分,用户查看物品的基类,用户购买的记录等
用户的偏好信息可以分为两类:
显示的用户反馈:这类是用户在网站上自然浏览或者使用网站意外,显示的提供反馈信息,例如用户对物品的评分,或者对物品的评论。
隐式的用户反馈:这类型用户在使用网站时产生的数据,隐式的反映了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。
推荐系统分类
针对推荐系统来说,最重要的就是数据:用户数据、物品数据以及用户对物品行为数据(评分数据、点击数据、购物数据等),按照不同类型业务或实现,划分推荐系统为如下几个类型
协同过滤
如果推荐系统仅仅利用用户的行为数据,根据用户对历史兴趣来给用户做推荐
——如果用户能够找到和自己历史兴趣相似的一群用户,看看他们最近在看什么电影,那么结果可能比宽泛的热门排行榜更能符合自己的兴趣
·数据:用户对物品的评价,评价时最为关键
·使用此算法时,如何获取用户对物品的评价(显示评价与隐式评价)
基于内容推荐
如果推荐系统利用了物品的内容数据,计算用户的兴趣和物品描述之间的相似度,来给用户做推荐
——通过分析用户曾经看过的电影找到用户喜欢的演员或导演,然后给用户推荐这些演员或导演的其他电影
·某个用户浏览、点击、购买某个物品,再次浏览的时候,将会把相似的物品进行推荐
·物品相似度比较高
·啤酒与尿布的故事,购买某个物品时,通常也会购买什么别的商品
·依据用户购物数据(订单数据)
社会化推荐
如果推荐系统利用了用户之间的社会网络信息,利用用户在社会网络中的好友的兴趣来给用户做推荐。
——让好友给自己推荐物品
ALS算法
推荐算法中的ALS是指Alternating Least Squares(交替最小二乘法)算法。这是一种协同过滤推荐算法,主要用于解决推荐系统中的矩阵降维。
ALS算法的核心思想:将用户-物品评分矩阵分解为两个低维矩阵的乘积,即将用户-物品的关联关系表示为用户和物品的特征向量表示。具体而言,首先初始化一个因子矩阵,使用评分矩阵获取另外的因子矩阵,交替计算,直到满足终止条件(最大迭代次数 or 收敛条件),此时就可以得到两个因子矩阵,即模型Model。ALS算法构建模型最本质就是两个因子矩阵。
Spark MLlib的推荐模型库只包含基于矩阵分解模型:
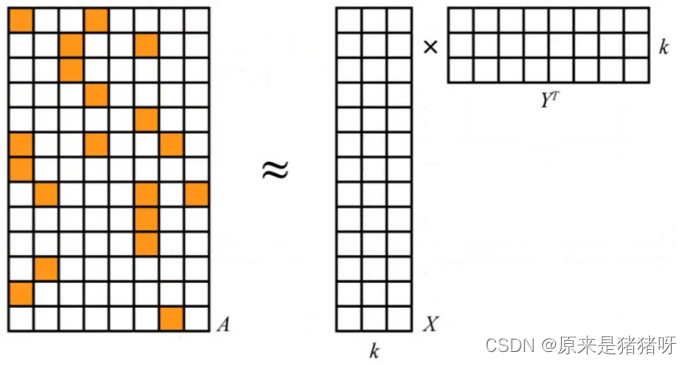
- 数学上,算法把User和Item数据当作一个大矩阵A,矩阵第i行和第j列上的元素有值,代表User-i对应Item-j的值
- 矩阵a是系数的:A中大多数元素都是0,因为相对于所有可能的用户-物品组合,只有很少一部分组合会出现在数据中
- 算法将A分解为两个小矩阵X和Y的乘积
矩阵X和矩阵Y非常小,因为A有很多行与列,但X和Y的行有很多而列很少(列数用k来标识)。这k个列就是潜在元素,用来解释数据中的交互关系。
K:矩阵因子,秩
矩阵分解
大致分为以下几个步骤:
Step1:初始化因子矩阵(随机)
Step2:依据大评价矩阵和初始化因子矩阵,计算出另外一个因子矩阵
Step3:再依据大评价矩阵和刚刚计算出来的因子矩阵,计算出另外一个因子矩阵。
Step4:重复2和3,直到满足收敛条件或达到次数为止
……
这里在之前进行知识点补充的时候已经详细的讲过了,想了解原理的xdm可以去看看之前我写的这篇文章->对ALS算法自己的理解,谢谢大家的支持!
样例代码实现(基于RDD实现)
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.mllib.recommendation._
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}/*** 使用MovieLens 电影评分数据集,调用Spark MLlib 中协同过滤推荐算法ALS建立推荐模型:* -a. 预测 用户User 对 某个电影Product 评价* -b. 为某个用户推荐10个电影Products* -c. 为某个电影推荐10个用户Users*/
object SparkAlsRmdMovie {def main(args: Array[String]): Unit = {// TODO: 1. 构建SparkContext实例对象val sc: SparkContext = {// a. 创建SparkConf对象,设置应用相关配置val sparkConf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName.stripSuffix("$"))// b. 创建SparkContextval context = SparkContext.getOrCreate(sparkConf)// 设置检查点目录context.setCheckpointDir(s"datas/ckpt/als-ml-${System.nanoTime()}")// c. 返回context}// TODO: 2. 读取 电影评分数据val rawRatingsRDD: RDD[String] = sc.textFile("datas/als/ml-100k/u.data")println(s"Count = ${rawRatingsRDD.count()}")println(s"First: ${rawRatingsRDD.first()}")// TODO: 3. 数据转换,构建RDD[Rating]val ratingsRDD: RDD[Rating] = rawRatingsRDD// 过滤不合格的数据.filter(line => null != line && line.split("\\t").length == 4).map{line =>// 字符串分割val Array(userId, movieId, rating, _) = line.split("\\t")// 返回Rating实例对象Rating(userId.toInt, movieId.toInt, rating.toDouble)}// 划分数据集为训练数据集和测试数据集val Array(trainRatings, testRatings) = ratingsRDD.randomSplit(Array(0.9, 0.1))// TODO: 4. 调用ALS算法中显示训练函数训练模型// 迭代次数为20,特征数为10val alsModel: MatrixFactorizationModel = ALS.train(ratings = trainRatings, // 训练数据集rank = 10, // 特征数rankiterations = 20 // 迭代次数)// TODO: 5. 获取模型中两个因子矩阵/*** 获取模型MatrixFactorizationModel就是里面包含两个矩阵:* -a. 用户因子矩阵* alsModel.userFeatures* -b. 产品因子矩阵* alsModel.productFeatures*/// userId -> Featuresval userFeatures: RDD[(Int, Array[Double])] = alsModel.userFeaturesuserFeatures.take(10).foreach{tuple =>println(tuple._1 + " -> " + tuple._2.mkString(","))}println("=======================================================")// productId -> Featuresval productFeatures: RDD[(Int, Array[Double])] = alsModel.productFeaturesproductFeatures.take(10).foreach{tuple => println(tuple._1 + " -> " + tuple._2.mkString(","))}// TODO: 6. 模型评估,使用RMSE评估模型,值越小,误差越小,模型越好// 6.1 转换测试数据集格式RDD[((userId, ProductId), rating)]val actualRatingsRDD: RDD[((Int, Int), Double)] = testRatings.map{tuple =>((tuple.user, tuple.product), tuple.rating)}// 6.2 使用模型对测试数据集预测电影评分val predictRatingsRDD: RDD[((Int, Int), Double)] = alsModel// 依据UserId和ProductId预测评分.predict(actualRatingsRDD.map(_._1))// 转换数据格式RDD[((userId, ProductId), rating)].map(tuple => ((tuple.user, tuple.product), tuple.rating))// 6.3 合并预测值与真实值val predictAndActualRatingsRDD: RDD[((Int, Int), (Double, Double))] = predictRatingsRDD.join(actualRatingsRDD)// 6.4 模型评估,计算RMSE值val metrics = new RegressionMetrics(predictAndActualRatingsRDD.map(_._2))println(s"RMSE = ${metrics.rootMeanSquaredError}")// TODO 7. 推荐与预测评分// 7.1 预测某个用户对某个产品的评分 def predict(user: Int, product: Int): Doubleval predictRating: Double = alsModel.predict(196, 242)println(s"预测用户196对电影242的评分:$predictRating")println("----------------------------------------")// 7.2 为某个用户推荐十部电影 def recommendProducts(user: Int, num: Int): Array[Rating]val rmdMovies: Array[Rating] = alsModel.recommendProducts(196, 10)rmdMovies.foreach(println)println("----------------------------------------")// 7.3 为某个电影推荐10个用户 def recommendUsers(product: Int, num: Int): Array[Rating]val rmdUsers = alsModel.recommendUsers(242, 10)rmdUsers.foreach(println)// TODO: 8. 将训练得到的模型进行保存,以便后期加载使用进行推荐val modelPath = s"datas/als/ml-als-model-" + System.nanoTime()alsModel.save(sc, modelPath)// TODO: 9. 从文件系统中记载保存的模型,用于推荐预测val loadAlsModel: MatrixFactorizationModel = MatrixFactorizationModel.load(sc, modelPath)// 使用加载预测val loaPredictRating: Double = loadAlsModel.predict(196, 242)println(s"加载模型 -> 预测用户196对电影242的评分:$loaPredictRating")// 为了WEB UI监控,线程休眠Thread.sleep(10000000)// 关闭资源sc.stop()}}样例代码实现(基于DF实现)
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType, StructField, StructType}/*** 基于DataFrame实现ALS算法库使用,构建训练电影推荐模型*/
object SparkRmdAls {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[4]").config("spark.sql.shuffle.partitions", "4").getOrCreate()import org.apache.spark.sql.functions._import spark.implicits._// 自定义Schame信息val mlSchema = StructType(Array(StructField("userId", IntegerType, nullable = true),StructField("movieId", IntegerType, nullable = true),StructField("rating", DoubleType, nullable = true),StructField("timestamp", LongType, nullable = true)))// TODO: 读取电影评分数据,数据格式为TSV格式val rawRatingsDF: DataFrame = spark.read.option("sep", "\t").schema(mlSchema).csv("datas/als/ml-100k/u.data")//rawRatingsDF.printSchema()/*** root* |-- userId: integer (nullable = true)* |-- movieId: integer (nullable = true)* |-- rating: double (nullable = true)* |-- timestamp: long (nullable = true)*///rawRatingsDF.show(10, truncate = false)// TODO: ALS 算法实例对象val als = new ALS() // def this() = this(Identifiable.randomUID("als"))// 设置迭代的最大次数.setMaxIter(10)// 设置特征数.setRank(10)// 显式评分.setImplicitPrefs(false)// 设置Block的数目, be partitioned into in order to parallelize computation (默认值: 10)..setNumItemBlocks(4).setNumUserBlocks(4)// 设置 用户ID:列名、产品ID:列名及评分:列名.setUserCol("userId").setItemCol("movieId").setRatingCol("rating")// TODO: 使用数据训练模型val mlAlsModel: ALSModel = als.fit(rawRatingsDF)// TODO: 用户-特征 因子矩阵val userFeaturesDF: DataFrame = mlAlsModel.userFactorsuserFeaturesDF.show(5, truncate = false)// TODO: 产品-特征 因子矩阵val itemFeaturesDF: DataFrame = mlAlsModel.itemFactorsitemFeaturesDF.show(5, truncate = false)/*** 推荐模型:* 1、预测用户对物品评价,喜好* 2、为用户推荐物品(推荐电影)* 3、为物品推荐用户(推荐用户)*/// TODO: 预测 用户对产品(电影)评分val predictRatingsDF: DataFrame = mlAlsModel// 设置 用户ID:列名、产品ID:列名.setUserCol("userId").setItemCol("movieId").setPredictionCol("predictRating") // 默认列名为 prediction.transform(rawRatingsDF)predictRatingsDF.show(5, truncate = false)/*TODO:实际项目中,构建出推荐模型以后,获取给用户推荐商品或者给物品推荐用户,往往存储至NoSQL数据库1、数据量表较大2、查询数据比较快可以是Redis内存数据,MongoDB文档数据,HBase面向列数据,存储Elasticsearch索引中*/// TODO: 为用户推荐10个产品(电影)// max number of recommendations for each userval userRecs: DataFrame = mlAlsModel.recommendForAllUsers(10)userRecs.show(5, truncate = false)// 查找 某个用户推荐的10个电影,比如用户:196 将结果保存Redis内存数据库,可以快速查询检索// TODO: 为产品(电影)推荐10个用户// max number of recommendations for each itemval movieRecs: DataFrame = mlAlsModel.recommendForAllItems(10)movieRecs.show(5, truncate = false)// 查找 某个电影推荐的10个用户,比如电影:242// TODO: 模型的评估val evaluator = new RegressionEvaluator().setLabelCol("rating").setPredictionCol("predictRating").setMetricName("rmse")val rmse = evaluator.evaluate(predictRatingsDF)println(s"Root-mean-square error = $rmse")// TODO: 模型的保存mlAlsModel.save("datas/als/mlalsModel")// TODO: 加载模型val loadMlAlsModel: ALSModel = ALSModel.load( "datas/als/mlalsModel")loadMlAlsModel.recommendForAllItems(10).show(5, truncate = false)// 应用结束,关闭资源Thread.sleep(1000000)spark.stop()}}
(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)
相关文章:
番外篇-用户购物偏好标签BP-推荐算法ALS
引言 推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。 推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。 数…...

气膜体育馆的防火性能分析—轻空间
随着现代体育事业的蓬勃发展,气膜体育馆因其建设快捷、成本低廉、使用灵活等优势,逐渐在全球范围内受到广泛关注。然而,对于这种新型建筑形式,防火性能一直是人们关注的焦点之一。轻空间将详细探讨气膜体育馆的防火性能࿰…...

什么台灯对眼睛好?一文给你分享具体什么台灯对眼睛好!
什么台灯对眼睛好?随着学生们最近陆续返校,家长们和孩子们都忙于开学初的准备工作,而眼睛的健康自然也是他们考虑的一部分。这也是护眼台灯在近年来变得非常普及的原因之一。我自己一直是一个近视的人,而且日常用眼时间也相当长。…...

python-bert模型基础笔记0.1.00
python-bert模型基础笔记0.1.00 bert的适合的场景bert多语言和中文模型bert模型两大类官方建议模型模型中名字的含义标题bert系列模型包含的文件bert系列模型参数参考链接bert的适合的场景 裸跑都非常优秀,句子级别(例如,SST-2)、句子对级别(例如MultiNLI)、单词级别(例…...
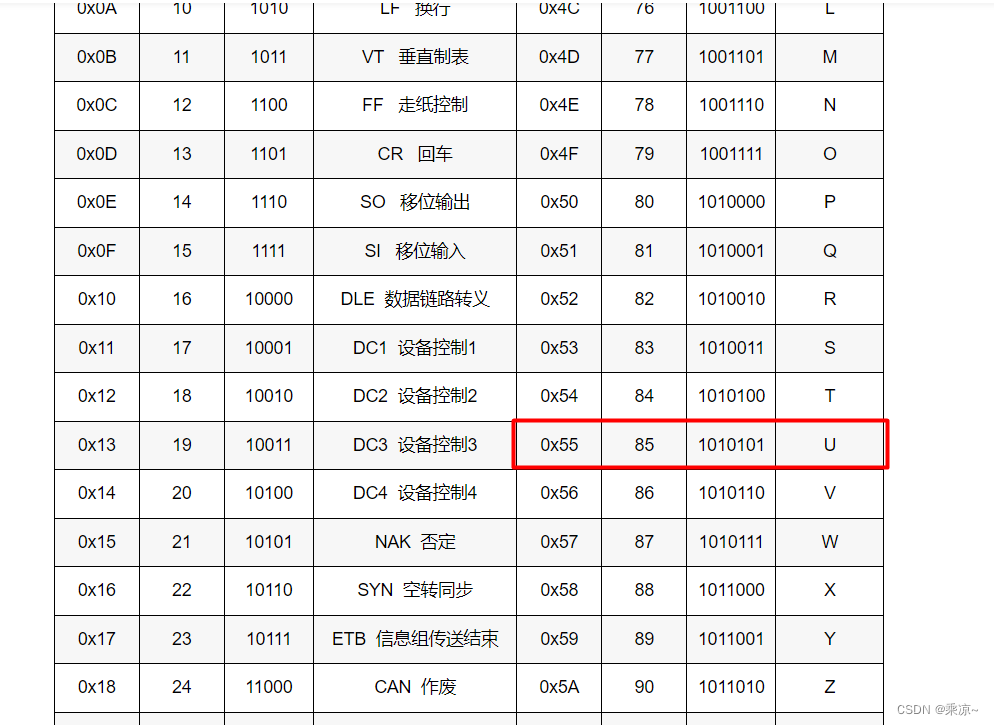
STM32G030C8T6:EEPROM读写实验(I2C通信)--M24C64
本专栏记录STM32开发各个功能的详细过程,方便自己后续查看,当然也供正在入门STM32单片机的兄弟们参考; 本小节的目标是,系统主频64 MHZ,采用高速外部晶振,实现PB11,PB10 引脚模拟I2C 时序,对M24C08 的EEPRO…...

opencascade 布尔运算笔记
BRepAlgoAPI_Common 对两个topods求解 没有公共部分也返回结果了 我想要的结果是没有公共部分返回false 在 Open CASCADE 中使用 BRepAlgoAPI_Common 进行布尔操作时,即使两个 TopoDS_Shape 没有公共部分,操作仍会返回一个结果。为了判断两个形状是否确…...

GPT-4o:人工智能新纪元的突破与展望
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

标准化、信息化、数字化、智能化、智慧化与数智化
近年来,标准化、信息化、数字化、智能化、智慧化以及数智化等词汇频繁出现,并逐渐成为业界热议的焦点。在国内,以华为、BAT等为代表的领军企业,不断强调“数字化转型”的重要性,并致力于推动其深入实施。与此同时&…...

14-JavaScript中的点操作符与方括号操作符
JavaScript中的点操作符与方括号操作符:简单理解与应用 笔记分享 在JavaScript中,访问对象的属性有两种常见方式:点操作符(.)和方括号操作符([])。尽管它们在很多情况下可以互换使用࿰…...

智慧大屏是如何实现数据可视化的?
智慧大屏,作为数据可视化的重要载体,已在城市管理、交通监控、商业运营等领域广泛应用。本文旨在阐述智慧大屏实现数据可视化的关键技术和方法,包括数据源管理、数据处理、视觉编码、用户界面与交互设计等。 大屏通过接入企业内部的数据库系…...
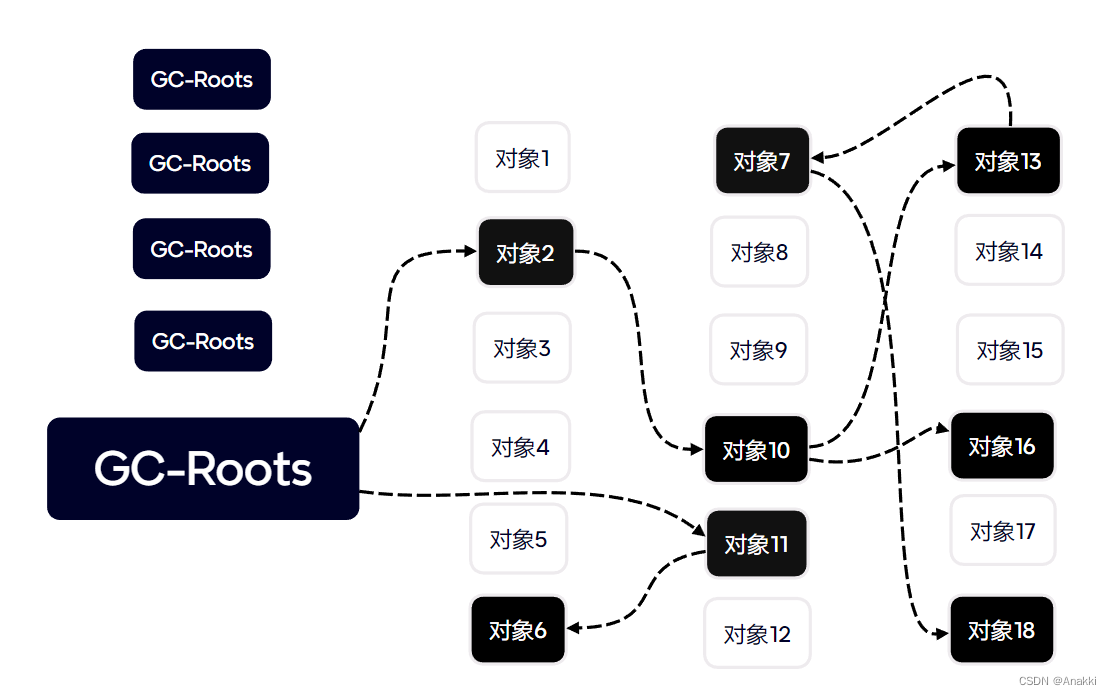
【JVM精通之路】垃圾回收-三色标记算法
首先预期你已经基本了解垃圾回收的相关知识,包括新生代垃圾回收器,老年代垃圾回收器,以及他们的算法,可达性分析等等。 先想象一个场景 最开始黑色节点是GC-Roots的根节点,这些对象有这样的特点因此被选为垃圾回收的根…...

Redis缓存(笔记一:缓存介绍和数据库启动)
目录 1、NoSQL数据库简介 2、Redis介绍 3、Redis(win系统、linux系统中操作) 3.1 win版本Redis启动 3.2 linux版本Redis启动 1、NoSQL数据库简介 技术的分类:(发展史) 1、解决功能性的问题:Java、Jsp、RDBMS、Tomcat、HTML、…...
OrangePi Kunpeng Pro套装测评:开箱与基本功能测试
前言 大家好,我是起个网名真难。非常荣幸受到香橙派的邀请,同时也是第一次做这个事情,很荣幸对香橙派与华为鲲鹏在2024年5月12日联合发布的新品——香橙派Kunpeng Pro开发板进行深入的评测。这款开发板是香橙派与华为鲲鹏合作推出的高性能平…...
:RocketMQ以及控制台的安装)
RocketMQ教程(二):RocketMQ以及控制台的安装
RocketMQ-Console RocketMQ-Console 是一个针对 Apache RocketMQ 的开源 Web 监控和管理平台。它提供了一个用户友好的界面,通过 Web 浏览器允许用户对 RocketMQ 集群进行管理和监控。这个控制台使得管理和监测 RocketMQ 集群变得更加直观和方便,特别是对于不熟悉命令行操作的…...
电脑记事本怎么恢复之前的内容记录
每个人都曾有过这样的时刻——在记事本上精心记录下的重要内容,一不小心就被删除了。那种心情,仿佛一瞬间从山顶跌落到谷底,无尽的懊悔涌上心头。我也曾遭遇过这样的困境,那些消失的文字对我来说意义非凡,它们的丢失仿…...
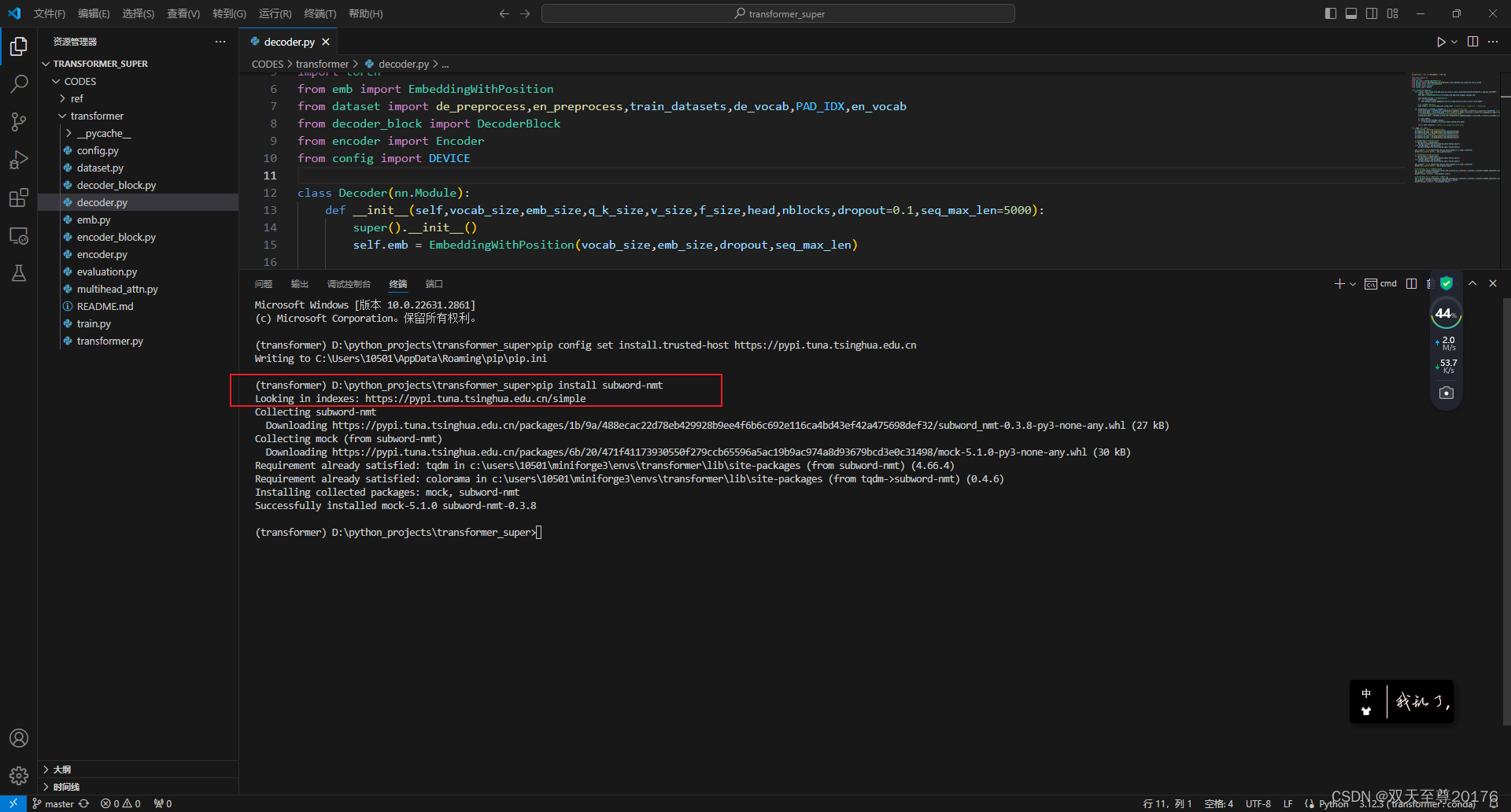
Windows下设置pip代理(proxy)
使用场景 正常网络情况下我们安装如果比较多的python包时,会选择使用这种 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-hostpypi.tuna.tsinghua.edu.cn 国内的镜像来加快下载速度。 但是,当这台被限制上…...
【调试笔记-20240530-Linux-在 OpenWRT-23.05 上为 nginx 配置 HTTPS 网站】
调试笔记-系列文章目录 调试笔记-20240530-Linux-在 OpenWRT-23.05 上为 nginx 配置 HTTPS 网站 文章目录 调试笔记-系列文章目录调试笔记-20240530-Linux-在 OpenWRT-23.05 上为 nginx 配置 HTTPS 网站 前言一、调试环境操作系统:OpenWrt 23.05.3调试环境调试目标…...
)
安装 hbase(伪分布式)
目录 1、安装 jdk8 (1)选择 jdk 版本 (2)下载 jdk 并解压 (3)配置环境变量 2、安装hadoop (1)添加 hadoop 用户,配置免密登录 (2)下载 hado…...

Angular-数组循环
简单数组 .ts-定义一个数组 // 第一种定义方式 public arr1:string[] [aa,bb,cc]; // 完整版 arr2:string[] [aa,bb,cc]; // 省略版 public objects:any[] [{username:Echoo,age:18},{username:Amily,age:39},{username:Mike,age:34}]; // 元素是对象 //第二种定…...
初级网络工程师之入门到入狱(一)
本文是我在学习过程中记录学习的点点滴滴,目的是为了学完之后巩固一下顺便也和大家分享一下,日后忘记了也可以方便快速的复习。 网络工程师从入门到入狱 前言一、交换机二、路由器三、DHCP(动态主机配置协议)四、路由器配置 DHCP自…...
)
MySQL 生产环境故障排查与性能优化全攻略(8.0 版本实战)
前言MySQL 作为目前企业级应用最广泛的开源关系型数据库,在生产环境中承担着核心数据存储与处理任务。默认配置往往无法满足高并发、大数据量的业务场景,同时运维过程中也会频繁遇到各类故障。本文基于 MySQL 8.0 版本,从单实例故障、主从复制…...

VR摩托车|沉浸式交通安全教育的新方向
在交通安全教育不断创新的今天,如何让参与者真正理解风险、形成安全意识,成为教育场景中的关键问题。传统的宣讲与视频观看虽然信息完整,却常因缺乏代入感而难以真正触动体验者。而“VR摩托车”作为一款结合虚拟现实技术、实景交互系统和交通…...

飞书推送文件给指定用户
首先要先把文件上传到飞书服务器,获取文件key。然后调用消息发送API进行文件推送// 上传文件String fileKey uploadFileToFeishu();// 将文件推送给用户列表sendFileToFeishuUserId(fileKey,userList);/*** 上传文件到飞书云端* return* throws Exception*/privat…...

基于Matlab的轴承-空心转轴-飞轮不同耦合类型动力学分析
基于Matlab的轴承-空心转轴-飞轮不同耦合类型动力学分析 保持轴承类型不变,变换飞轮和转轴耦合方式,分固有频率的变化趋势 可自行定义轴承、飞轮、转轴参数 程序高度模块化,修改十分方便 程序已调通,可直接运行最近做了一个关于轴…...

Qwen3-TTS声音设计模型5分钟快速部署:10种语言语音合成一键搞定
Qwen3-TTS声音设计模型5分钟快速部署:10种语言语音合成一键搞定 1. 为什么选择Qwen3-TTS声音设计模型? 1.1 用自然语言"设计"声音,不是选择音色 传统语音合成工具通常提供固定音色库,而Qwen3-TTS的VoiceDesign功能允…...

Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流
Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

如何快速提升Python开发效率:VS Code扩展终极指南
如何快速提升Python开发效率:VS Code扩展终极指南 【免费下载链接】pylance-release Documentation and issues for Pylance 项目地址: https://gitcode.com/gh_mirrors/py/pylance-release Python开发工具在当今编程世界中扮演着至关重要的角色,…...

5个核心功能让你效率提升:MongoDB Compass实战指南
5个核心功能让你效率提升:MongoDB Compass实战指南 【免费下载链接】compass The GUI for MongoDB. 项目地址: https://gitcode.com/gh_mirrors/com/compass MongoDB Compass作为官方可视化管理工具,正在彻底改变开发者与MongoDB交互的方式。通过…...

《数字孪生为什么90%都是假的》——没有空间数据的“孪生”,只是一个会动的PPT
一、摘要(Executive Summary)近年来,“数字孪生(Digital Twin)”成为智慧城市、工业互联网与数字基础设施建设中的核心关键词。然而,在大量实际项目中,所谓“数字孪生系统”仅停留在三维建模与数…...

用快马AI十分钟搭建你的第一篇论文展示官网原型
最近在准备学术成果展示时,发现很多同行都开始搭建个人论文官网。这种展示方式确实比单纯发PDF专业很多,但自己从头开发又太费时间。尝试用InsCode(快马)平台快速搭建原型,没想到十分钟就搞定了基础框架,分享下具体实现思路。 明确…...