解决MyBatis的N+1问题
解决MyBatis的N+1问题
N+1问题通常出现在一对多关联查询中。当我们查询主表数据(如订单)并希望获取关联的从表数据(如订单的商品)时,如果每获取一条主表记录都要执行一次从表查询,就会产生N+1次查询的问题。假设有10个订单,主查询执行1次,从查询执行10次,总共执行了11次查询。这种情况显然会导致性能低下。
这个问题比较傻,可能只有刚接触编程的人才会犯这么初级的错误,最近在面试的过程中被问到了这个问题,给我搞的一愣一愣的。所以记录一下。
示例
假设我们有两个表:orders(订单表)和items(商品表),一个订单可以有多个商品。传统的MyBatis配置可能会这样写:
<select id="getOrders" resultMap="orderResultMap">SELECT * FROM orders
</select><select id="getItemsByOrderId" resultMap="itemResultMap" parameterType="int">SELECT * FROM items WHERE order_id = #{orderId}
</select>
在Java代码中调用:
List<Order> orders = orderMapper.getOrders();
for (Order order : orders) {List<Item> items = orderMapper.getItemsByOrderId(order.getId());order.setItems(items);
}
这种方式会导致N+1问题。
解决方法
1. 使用嵌套查询(Subqueries)
嵌套查询通过在一个查询中嵌套其他查询,可以减少查询次数。这个方法通常在SQL语句中使用IN子句。例如:
<select id="getOrdersWithItems" resultMap="orderWithItemsResultMap">SELECT * FROM orders WHERE id IN(SELECT DISTINCT order_id FROM items WHERE order_id IS NOT NULL)
</select><resultMap id="orderWithItemsResultMap" type="Order"><id property="id" column="id"/><result property="orderName" column="order_name"/><collection property="items" ofType="Item"><id property="id" column="item_id"/><result property="itemName" column="item_name"/><result property="orderId" column="order_id"/></collection>
</resultMap>
2. 使用JOIN查询
JOIN查询通过一次性获取所有需要的数据,避免了多次查询的问题。这个方法通常在SQL语句中使用LEFT JOIN或INNER JOIN等连接操作。例如:
<select id="getOrdersWithItems" resultMap="orderWithItemsResultMap">SELECT o.*, i.* FROM orders oLEFT JOIN items i ON o.id = i.order_id
</select><resultMap id="orderWithItemsResultMap" type="Order"><id property="id" column="id"/><result property="orderName" column="order_name"/><collection property="items" ofType="Item"><id property="id" column="item_id"/><result property="itemName" column="item_name"/><result property="orderId" column="order_id"/></collection>
</resultMap>
3. 使用批量查询(Batch Query)
批量查询可以将多个查询合并为一个查询,减少查询次数。例如:
<select id="getOrders" resultMap="orderResultMap">SELECT * FROM orders
</select><select id="getItemsByOrderIds" resultMap="itemResultMap" parameterType="list">SELECT * FROM items WHERE order_id IN<foreach item="orderId" collection="list" open="(" separator="," close=")">#{orderId}</foreach>
</select>
在Java代码中批量查询:
List<Order> orders = orderMapper.getOrders();
List<Integer> orderIds = orders.stream().map(Order::getId).collect(Collectors.toList());
List<Item> items = orderMapper.getItemsByOrderIds(orderIds);// 处理查询结果,将items分配给对应的order
Map<Integer, List<Item>> itemsMap = items.stream().collect(Collectors.groupingBy(Item::getOrderId));
for (Order order : orders) {order.setItems(itemsMap.get(order.getId()));
}
4. 使用缓存(Caching)
缓存可以减少数据库的查询次数,特别是在数据变化不频繁的情况下。MyBatis提供了一级缓存和二级缓存机制。例如:
<settings><setting name="cacheEnabled" value="true"/>
</settings><cache/>
在Mapper文件中使用缓存:
<cache/>
<select id="getOrders" resultMap="orderResultMap" useCache="true">SELECT * FROM orders
</select><select id="getItemsByOrderId" resultMap="itemResultMap" parameterType="int" useCache="true">SELECT * FROM items WHERE order_id = #{orderId}
</select>
5. 使用懒加载(Lazy Loading)
MyBatis支持懒加载,当访问到关联对象时才执行查询。可以通过以下方式开启懒加载:
<settings><setting name="lazyLoadingEnabled" value="true"/><setting name="aggressiveLazyLoading" value="false"/>
</settings>
在Mapper文件中设置:
<resultMap id="orderResultMap" type="Order"><id property="id" column="id"/><result property="orderName" column="order_name"/><association property="items" javaType="List" select="getItemsByOrderId" fetchType="lazy"/>
</resultMap>
参考链接
- MyBatis官方文档

相关文章:
解决MyBatis的N+1问题
解决MyBatis的N1问题 N1问题通常出现在一对多关联查询中。当我们查询主表数据(如订单)并希望获取关联的从表数据(如订单的商品)时,如果每获取一条主表记录都要执行一次从表查询,就会产生N1次查询的问题。假…...
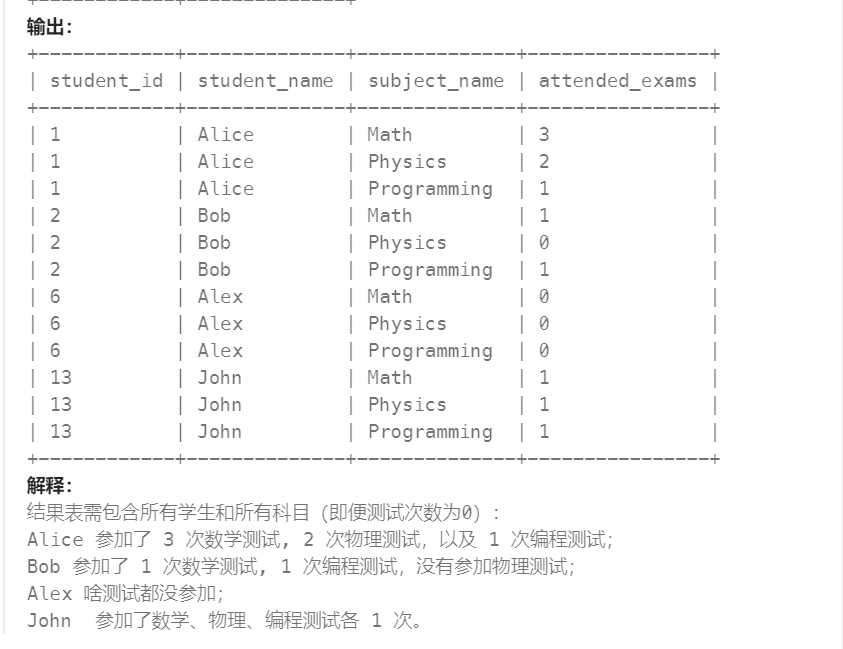
12-学生们参加各科测试的次数(高频 SQL 50 题基础版)
12-学生们参加各科测试的次数 -- 学生表中,id是唯一的,将他作为主表 -- CROSS JOIN产生了一个结果集,该结果集是两个关联表的行的乘积 -- 2行表,与3行表使用cross join,得到2*36行数据 select st.student_id, st.student_name,su.subject_na…...

2024网络与信息安全管理员职工职业技能竞赛re0220164094
main部分,就是要逆这部分shellcode,程序把data段里面的东西复制到bss段去执行,期间包含解码操作。 v19 0;puts("Please input your flag: ");__isoc99_scanf("%s", s);if ( strlen(s) ! 38 ){puts("Wrong length!&…...

Elasticsearch--easy-ES框架使用,轻松操作查询Elasticsearch,简化开发
Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的ORM开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过Mybatis-Plus(简称MP),那么您基本可…...

【教程】如何实现WordPress网站降级(用于解决插件和主题问题)
在最新可用版本上运行WordPress安装、插件和主题是使用该平台的关键最佳实践。还建议使用最新版本的PHP。但是,在某些情况下,这是不谨慎或不可能的。 如果您发现自己处于这种情况,您可能需要撤消更新并降级您的WordPress网站(或其中的一部分)。幸运的是,有一些方法可用于…...
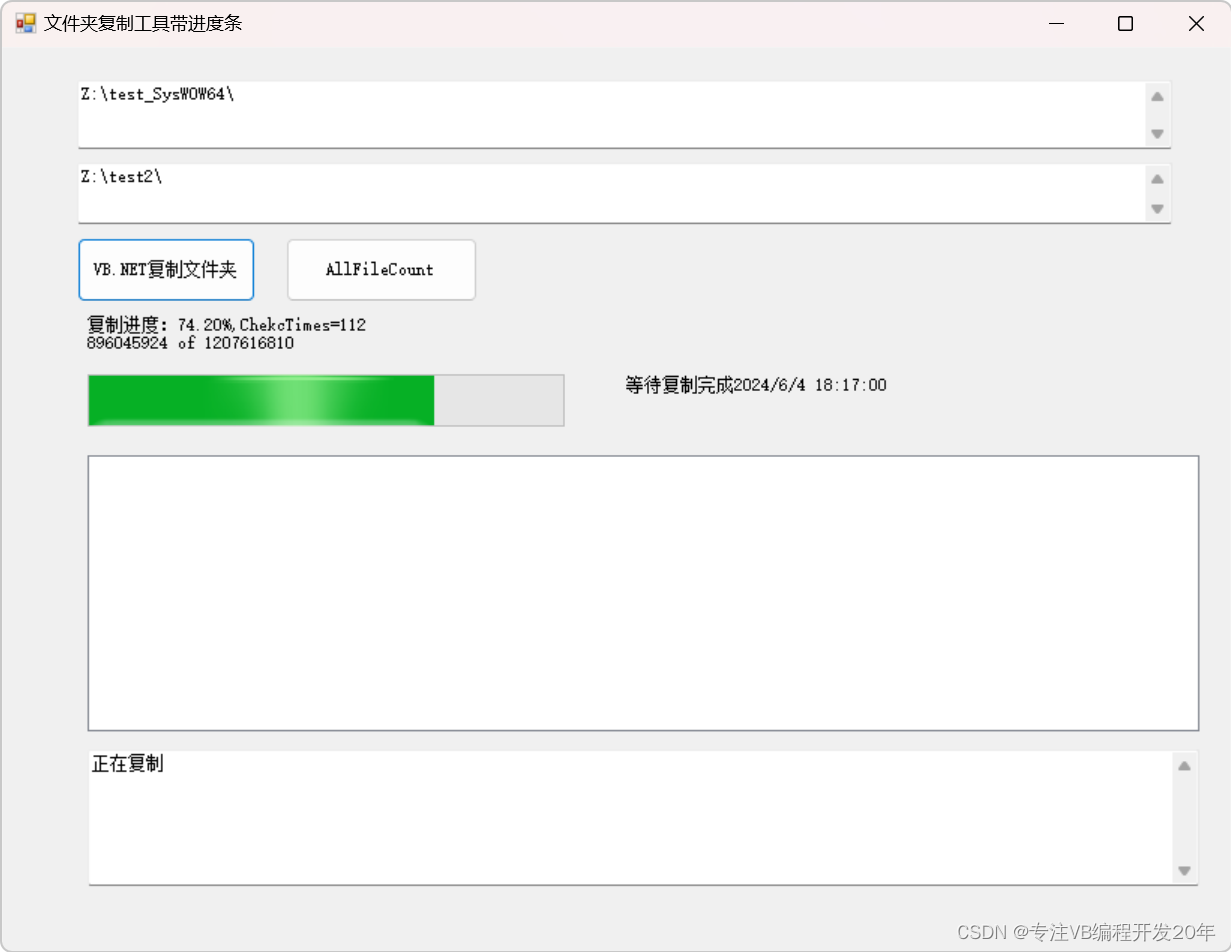
思维导图-vb.net开发带进度条的复制文件夹功能c#复制文件夹
你们谁写代码会用流程图来做计划,或者写项目总结报告? .net带进度条复制文件夹 方案 列出所有子文件夹,再创建,复制文件 大文件可以单独做进度条 缺点:设计会更复杂 直接…...
Linux文本处理三剑客之awk命令
官方文档:https://www.gnu.org/software/gawk/manual/gawk.html 什么是awk? Awk是一种文本处理工具,它的名字是由其三位创始人(Aho、Weinberger和Kernighan)的姓氏首字母组成的。Awk的设计初衷是用于处理结构化文本数…...

公差和配合
配合的选择: 配合特性以及基本偏差的应用: 常用优先配合特性及选用举例 为什么一般情况下选用基孔制而不用基轴制: 优先采用基孔制的原因主要包括工艺性、经济性和标准化: 工艺性。加工孔比加工轴更难,因为孔…...
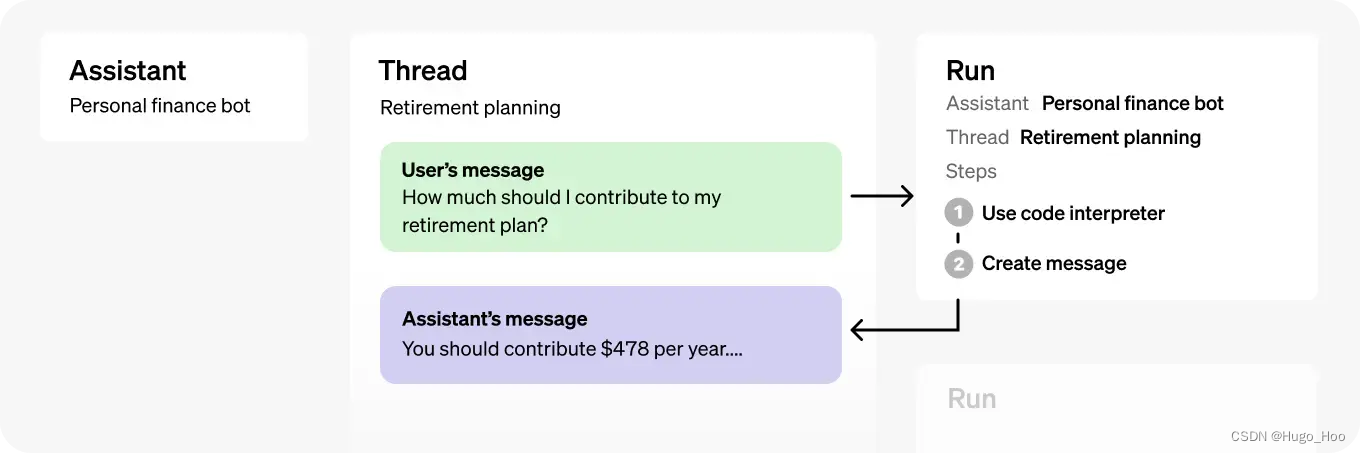
AI大模型应用开发实践:5.快速入门 Assistants API
快速入门 Assistants API Assistants API 允许您在自己的应用程序中构建人工智能助手。一个助手有其指令,并可以利用模型、工具和知识来回应用户查询。 Assistants API 目前支持三种类型的工具: 代码解释器 Code Interpreter检索 Retrieval函数调用 Function calling使用 P…...

stack和queue的模拟实现
文章目录 如何实现?实现stack实现queue总结 如何实现? 首先我们看看官网上的stack,官网上的stack是用deque作为模版的缺省值去实现的,deque是什么? deque其实就是双端队列,双端队列,顾名思义&am…...
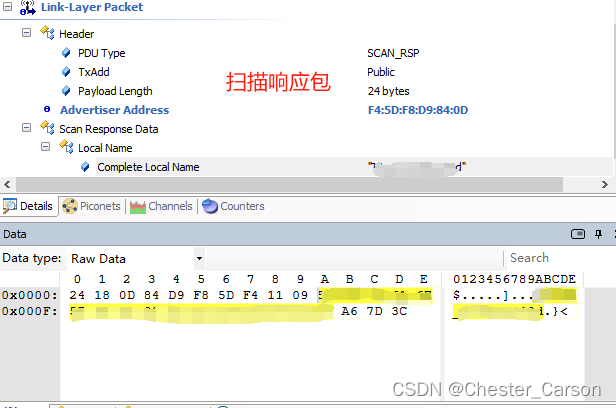
你的手机是如何控制你的手表之广播篇
前言 要让手机能够控制手表,第一步当然要让手机能够“看见”手表,人类作为上帝视角,我们是能够通过眼睛直接看见手机和手表的,但要让手机“看见”手表,就需要一端把自己的信息通过电磁波的形式发往空中,另…...
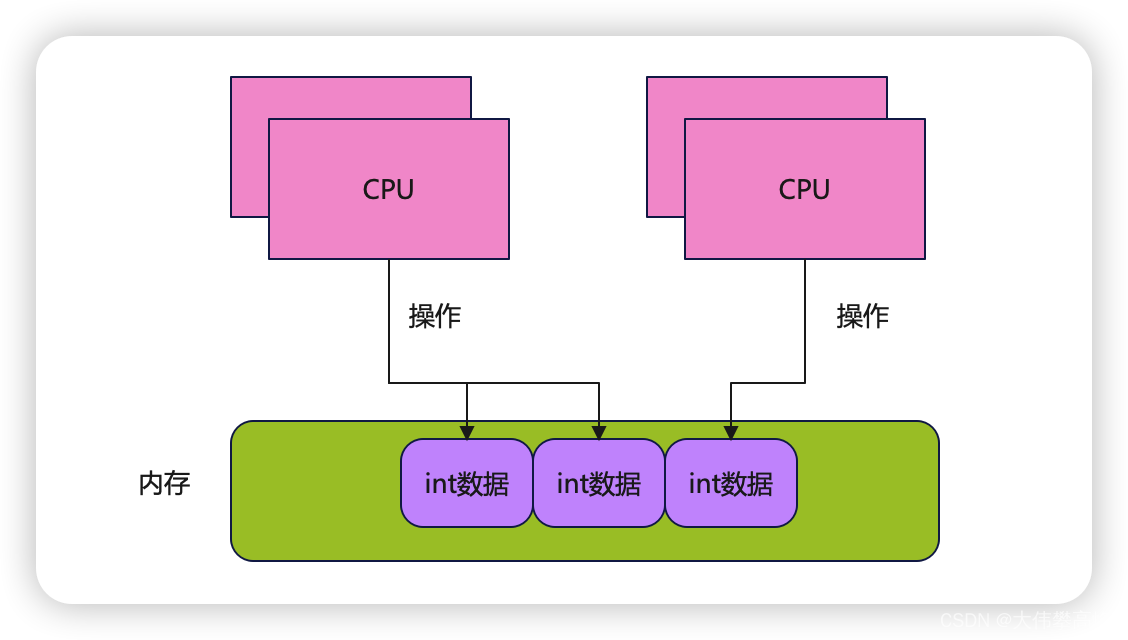
深入理解并发之LongAdder、DoubleAdder的实现原理
深入理解LongAdder、DoubleAdder的实现原理 本文主要通过LongAdder和DoubleAdder的源码,讲述一下其实现原理。通过LongAdder和DoubleAdder的源码可知。两者都是继承了Striped64的类。下面我们将通过源码的形式讲述一下这三个类都做了哪些事情。 1: Striped64 …...

virtuoso原理图无法编辑
(SCH-1217): Could not open "XX schematic" for edit. (because it is locked by user XX on XX) Would you like to open it for read? 解决方法: 到工程目录的schematic文件夹下找到sch.oa.cdslck.RHEL30.XXX-eda.21423和sch.oa.cdslck全部删掉即可正…...

Kotlin协程中的作用域 `GlobalScope`、`lifecycleScope` 和 `viewModelScope`
Kotlin协程中的作用域 Kotlin协程提供了多种作用域来管理协程的生命周期,其中最常见的是 GlobalScope、lifecycleScope 和 viewModelScope。 1. GlobalScope GlobalScope 是一个全局作用域,不受任何其他生命周期的限制。这意味着在 GlobalScope 中启动…...

leetcode739 每日温度
题目 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 输入: tempe…...

【软件测试】自动化测试如何管理测试数据
前言 在之前的自动化测试框架相关文章中,无论是接口自动化还是UI自动化,都谈及data模块和config模块,也就是测试数据和配置文件。 随着自动化用例的不断增加,需要维护的测试数据也会越来越多,维护成本越来越高&#…...

Llama 3-V: 比GPT4-V小100倍的SOTA
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模…...

Anaconda安装配置
Anaconda下载: 网盘下载:https://pan.quark.cn/s/c5663477ccef 配置环境变量: 以管理员身份运行命令提示符 setx /M PATH "%PATH%;C:\ProgramData\anaconda3;C:\ProgramData\anaconda3\Scripts;C:\ProgramData\anaconda3\Library\bi…...

全面理解渗透测试
揭秘网络安全的秘密武器:全面理解渗透测试 在数字化时代,网络安全已成为人们关注的焦点。网络攻击和数据泄露事件频发,给个人、企业和国家带来了巨大的损失。为了应对这一挑战,渗透测试作为一种重要的网络安全评估手段࿰…...
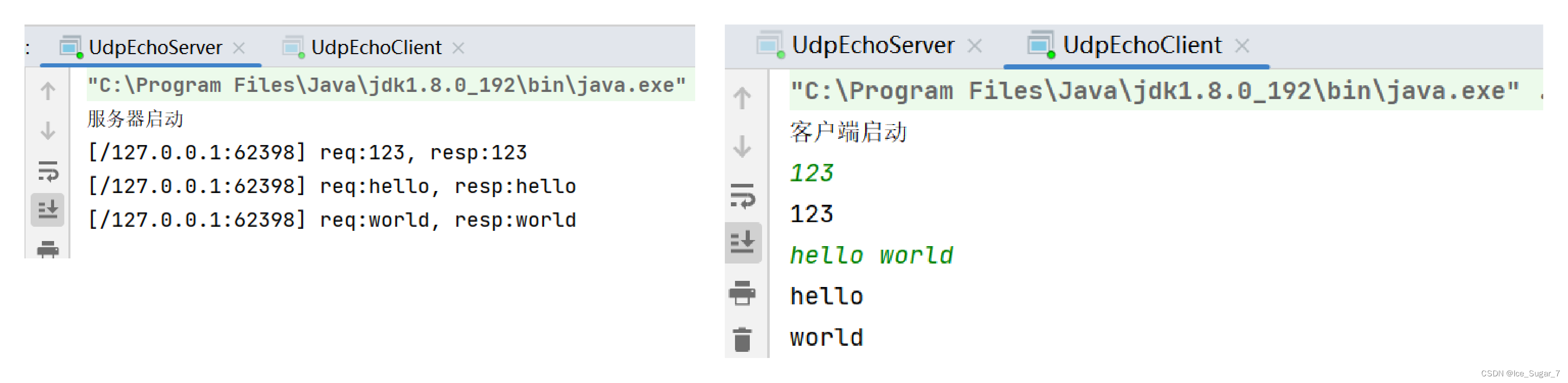
「网络编程」基于 UDP 协议实现回显服务器
🎇个人主页:Ice_Sugar_7 🎇所属专栏:计网 🎇欢迎点赞收藏加关注哦! 实现回显服务器 🍉socket api🍉回显服务器🍌实现🥝服务器🥝客户端 dz…...

Oracle 12c安装实战:解决PRVG-0449堆栈软限制配置难题
1. 初识PRVG-0449错误:堆栈软限制的"拦路虎" 第一次在Oracle 12c安装过程中遇到PRVG-0449错误时,我盯着屏幕上的红色警告愣了好几秒。错误信息明确告诉我:"Proper soft limit for maximum stack size was not found"&…...

汇川PLC与IS620N伺服驱动实战:手把手教你完成EtherCAT网络配置与电机命名
汇川PLC与IS620N伺服驱动深度配置指南:从EtherCAT组态到电机精准控制 在工业自动化领域,伺服系统的稳定性和响应速度直接决定了设备性能的上限。汇川AM600系列PLC搭配IS620N伺服驱动组成的EtherCAT网络,正成为越来越多自动化工程师的首选方案…...

如何快速实现手机号码定位查询:3步掌握号码地理位置追踪技术
如何快速实现手机号码定位查询:3步掌握号码地理位置追踪技术 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/g…...

从图像处理到推荐系统:特征值不等式在工程中的5个妙用
从图像处理到推荐系统:特征值不等式在工程中的5个妙用 在工程实践中,数学工具往往能带来意想不到的优化效果。特征值不等式作为线性代数中的重要结论,其应用范围远超理论推导,能解决图像处理、推荐系统等多个领域的实际问题。本文…...

Docker测试学习思路
Docker 核心概念学习与实战指南本文系统梳理 Docker 学习的核心思路与方法,用通俗类比帮助理解 Docker 的本质,涵盖镜像构建、容器运行、网络通信、数据持久化、资源限制五大核心能力,适合初学者建立清晰的 Docker 知识框架。一、Docker 到底…...

opencode令牌分析插件使用:API调用监控部署教程
opencode令牌分析插件使用:API调用监控部署教程 1. 引言:为什么需要API调用监控? 当你使用AI编程助手时,是否曾经遇到过这些问题:不知道模型调用了多少次API、不清楚每次调用消耗了多少token、无法监控API调用的性能…...
)
告别GitHub下载卡顿:手把手教你配置Electron国内镜像(npmrc文件详解)
告别Electron下载困境:深度解析.npmrc配置与国内镜像实战指南 每次执行npm install electron时,看着进度条卡在node install.js阶段一动不动,或是突然蹦出RequestError: connect ETIMEDOUT的红色报错——这种体验对于国内开发者来说再熟悉不过…...

Qwen3.5-2B部署案例:基于Docker+Supervisor的生产级多用户服务搭建
Qwen3.5-2B部署案例:基于DockerSupervisor的生产级多用户服务搭建 1. 项目背景与模型介绍 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型专为低功耗、低门槛部署场景设计&…...

Open Event Server数据导入导出完全指南:支持JSON、XML、iCal格式的终极教程
Open Event Server数据导入导出完全指南:支持JSON、XML、iCal格式的终极教程 【免费下载链接】open-event-server The Open Event Organizer Server to Manage Events https://test-api.eventyay.com 项目地址: https://gitcode.com/gh_mirrors/op/open-event-ser…...

Dash.js终极指南:5分钟掌握专业级流媒体播放技术
Dash.js终极指南:5分钟掌握专业级流媒体播放技术 【免费下载链接】dash.js A reference client implementation for the playback of MPEG DASH via Javascript and compliant browsers. 项目地址: https://gitcode.com/gh_mirrors/da/dash.js Dash.js是一个…...