Oracle表分区的基本使用
什么是表空间
是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称为表空间
什么是表分区
表分区就是把一张大数据的表,根据分区策略进行分区,分区设置完成之后,由数据库自身的储存引擎来实现分发数据到指定的分区中。
分区不是分表,不会生成新的数据表,只是将表的数据分摊到不同的硬盘,系统或是不同服务器存储介质中,实际上还是一张表。
表分区具体作用
分区功能可以将表、索引或者索引组织表进一步细分为段,这些数据对象的段叫分区,每个分区独有自己的名称,一个分区后的对象(表)具体有多个段,这些段既可以集体管理,也可以单独管理
表分区使用场景
- 表的大小超过2GB
- 表中有大量的临时数据,数据存在明显的时间顺序
- 表的存储必须分散在不同的储存设备
表分区的优缺点
优点
- 改善查询性能:对分区对象的查询可以搜索仅自己关心的分区,提高检索速度
- 增强可用性:如果表的某个分区出现故障,表在其他分区的数据依然可用
- 维护方便:如果某个分区出现故障,需要修复数据,只修复该分区即可
- 均衡i/o:可以把不同的分区映射到磁盘以平衡i/o,改善整个系统的性能
缺点
- 已经存在的表没有方法可以直接转化为分区表
- 需要维护
表分区类型
- 范围分区:range
- 列表分区:list
- 组合分区:范围+列表;范围+散列;列表+散列
范围分区
create table_name(column1 type1,column2 type2,...)
partition by range (需要用作分区的字段名)
(partition 分区名1 values less than (分区字段具体的一个上限值),partition 分区名2 values less than (分区字段具体的一个上限值),partition 分区名3 values less than (maxvalues)
);
创建分区
普通创建
create emp_range(empno number,ename varchar2(10),job varchar2(10),mgr number,hiredate date,sal number,comm number,deptno number)
partition by range(hiredate)
(partition range_1981 values less than (to_date('19810101','YYYYMMDD')),partition range_1982 values less than (to_date('19820101','YYYYMMDD')),partition range_max values less than (maxvalue)--不在上面两个范围内的会划分到此处
);以as的方法创建
create table emp_range3
partition by range(hiredate)
(partition range_1981 values less than (to_date('19810101','YYYYMMDD')),partition range_1982 values less than (to_date('19820101','YYYYMMDD')),partition range_max values less than (maxvalue)
)
as select * from emp;
实例
--创建一张emp_range表数据同emp一样-- 并按照工资范围 划分为三个档 --第一个档 工资不高于2000 第二个档 不高于4000 第三个档 不高于8000drop table emp_range;create table emp_range partition by range (sal)(partition s_2000 values less than (2000),partition s_4000 values less than (4000),partition s_8000 values less than (8000))as select * from emp;select * from emp_range;select * from emp_range partition (s_2000);--step2:数据插入分区表中insert into emp_range(sal) values(2000);--step3:查询分区select * from emp_range partition (s_4000);insert into emp_range(sal) values(10000); --没定义 不能插入当分区字段作为查询条件的时候,如果查询范围没有跨越分区,就会在对应分区查询,否则就会全表扫描partition range single 单个分区扫描
select * from emp_range where sal between 1000 and 1500;
PARTITION RANGE ITERATOR 分区迭代扫描
select * from emp_range where sal between 1000 and 3000;
PARTITION RANGE ALL 是分区全扫描
select * from emp_range where sal between 1000 and 5500; --创建emp_date和emp表数据一致 并按照入职年份进行分区划分 1981年和1982年和其他年份的分区
create table emp_date
partition by range(hiredate)
(partition p_1981 values less than (date'1982-1-1'),partition p_1982 values less than (date'1983-1-1'),partition p_max values less than (maxvalue)
)
as select * from emp;
列表分区
create table table_name(column1 type1,column2 type2,...)
partition by list (需要用作分区的字段名)
(partition 分区名1 values (具体的值),
partition 分区名2 values (具体的值),
partition 分区名3 values (default)
);--创建
create table emp_list2
partition by list(deptno)
(partition list_10 values (10,20),
partition list_o values (default) --没定义的其他值都归为默认值的分区
)
as select * from emp; select * from emp_list2 partition (list_10);
select * from emp_list2 partition (list_o);insert into emp_list2(deptno) values (40); select distinct job from emp
--创建一个emp_job 按照职位类型创建5个分区
create table emp_job
partition by list (job)
(partition p_clerk values ('CLERK'),
partition p_SALESMAN values ('SALESMAN'),
partition p_PRESIDENT values ('PRESIDENT'),partition p_MANAGER values ('MANAGER'),
partition p_ANALYST values ('ANALYST') )
as select * from emp;select * from emp_job partition (p_clerk);
哈希分区
create table emp_hash(deptno number(10),ename varchar2(30)
) partition by hash(empno)(partition p1 tablespace tetstbs1,partition p2 tablespace tetstbs2,partition p3 tablespace tetstbs3,partition p4 tablespace tetstbs4,
);
--简写
create table emp_hash_test2(deptno number(10),ename varchar2(30)
) partition by hash(deptno) partitions 4 store in (tetstbs1, tetstbs2, tetstbs3, tetstbs4);
实例
create table hash_part2(empno number,ename varchar2(34)
)
partition by hash(empno)(partition p1 tablespace users,partition p2 tablespace users,partition p3 tablespace users,partition p4 tablespace users
);create table hash_part(empno number,ename varchar2(34)
)
partition by hash(empno)
partitions 3;--查看具体的分区信息:
SELECT partition_name, high_value,tablespace_name
FROM user_tab_partitions
WHERE table_name = 'HASH_PART'
ORDER BY partition_position;组合分区
组合分区(范围分区+列表分区)语法格式:create table table_name(column1 type1,column2 type2,...)partition by range (主分区字段)subpartition by list (子分区字段)(----partition 主分区名1 values less than (主分区1上限)----(subpartition 子分区名1 values (子分区值1),subpartition 子分区名2 values (子分区值2)) ,-------------------partition 主分区名2 values less than (主分区2上限)---(subpartition 子分区名1 values (子分区值1),subpartition 子分区名2 values (子分区值2)));主分区为range子分区为list:
--对hiredate 进行范围分区 1981 和之后的时间
--再进行 部门编号的列表分区
create table emp_hiredate_deptno
partition by range (hiredate)
subpartition by list(deptno)
(
partition p_1981 values less than (date'1982-1-1')
(
subpartition p_1981_10 values (10),
subpartition p_1981_20 values (20),
subpartition p_1981_30 values (30)
),
partition p_1982 values less than (maxvalue)
(
subpartition p_1982_10 values (10),
subpartition p_1982_20 values (20),
subpartition p_1982_30 values (30)
)
)
as select * from emp;查询主分区与子分区
select * from emp_hiredate_deptno;
select * from emp_hiredate_deptno partition (p_1981);
select * from emp_hiredate_deptno subpartition (p_1981_10); 主分区为list子分区为list:
create table emp_range_list3
partition by list(deptno)
subpartition by list(deptno)
(partition p1 values (10,20)
(subpartition p1a values (10),
subpartition p1b values (20)),
partition p2 values (30)
(subpartition p2c values (30))
)as select * from emp;--创建一张表 emp_job 表数据同emp 并按照部门和职位进行分区 drop table emp_job;
select distinct deptno,job from emp;
create table emp_job
partition by list (deptno)
subpartition by list(job)
(
partition p1 values (10)
(subpartition p1a values ('PRESIDENT'),subpartition p1b values ('CLERK'),subpartition p1c values ('MANAGER')
),
partition p2 values (20)
(subpartition p2a values ('CLERK'),subpartition p2b values ('MANAGER'),subpartition p2c values ('ANALYST')
),
partition p3 values (30)
(subpartition p3a values ('SALESMAN'),subpartition p3b values ('CLERK'),subpartition p3c values ('MANAGER')
)
)
as select * from emp;select * from emp_job subpartition(p1a);分区管理
删除分区(删除分区会删除表数据)
alter table 表名 drop partition 分区名;alter table emp_job drop partition p1;select * from emp_job partition(p1);alter table emp_job drop subpartition p2a;select * from emp_range_list3 subpartition(p1b);
添加分区(只能添加已存分区规则外的规则分区)
范围分区只能在最高值的后边追加,不可以在中间范围增加 maxvalue
alter table 表名 add partition 分区名 values less than(上限值);
--给emp_range 添加 第四个分区 范围是工资不超过10000
select * from emp_range;
alter table emp_range add partition p4 values less than(10000);alter table emp_date add partition range_1984 values less than(to_date('19850101','YYYYMMDD'));
alter table emp_job add partition p1 values (10);
截断分区
alter table 表名 truncate partition 分区名;
alter table 表名 truncate subpartition 子分区名;
alter table emp_job truncate partition p1;
select * from emp_job subpartition (p3a);
alter table emp_job truncate subpartition p3a;
合并分区
不可以跨区合并,要合并必须是相邻且有序的
alter table 表名 merge partitions 分区名1,分区名2 into partition 新分区名;alter table emp_job merge partitions p2,p3 into partition p_new;--合并范围分区
emp_range
alter table emp_range merge partitions s_2000,s_4000 into partition s_4;
拆分分区
alter table 表名 split partition 分区名 at (分割值) into (partition 新分区名1,partition 新分区名2);
alter table emp_range split partition s_4
at (2000) into (partition s_2000,partition s_4000);alter table emp_job split partition p_new at (20) --不可以进行分离列表分区into (partition p2,partition p3);alter table emp_date merge partitions p_1981,p_1982 into partition p_1983;
alter table emp_date split partition p_1983 at (date'1982-1-1') into (partition p_1981,partition p_1982);
重命名分区
alter table 表名 rename partition 原分区名 to 新分区名;
alter table emp_range4 rename partition range_1982 to range_1982_2;
--查看分区信息
select * from user_tab_partitions a where a.table_name = 'EMP_JOB';
实例
select * from emp_range ;
--拆分工资在4000-8000区间的分区为两个分区 以6000为分界线
alter table emp_range split partition s_8000 at (6000) into (partition s_6000,partition s_8000);
--合并 2000-4000 分区和4000到6000范围的分区 分区名命名为 posal
alter table emp_range merge partitions s_2000,s_4000 into partition posal;
--重命名posal为 p4_6
alter table emp_range rename partition posal to p4_6;
--删除 p4分区
alter table emp_range drop partition p4;
--添加8000-15000的范围分区 s_15000
alter table emp_range add partition s_15000 values less than(15000);
--清空p4_6分区的数据
alter table emp_range truncate partition p4_6;
select * from emp_range partition (p4_6);
相关文章:

Oracle表分区的基本使用
什么是表空间 是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称为表空间 什么是表分区 表分区就是把一张大数据的表,根据分区策略进行分区,分区设置完成之后,…...
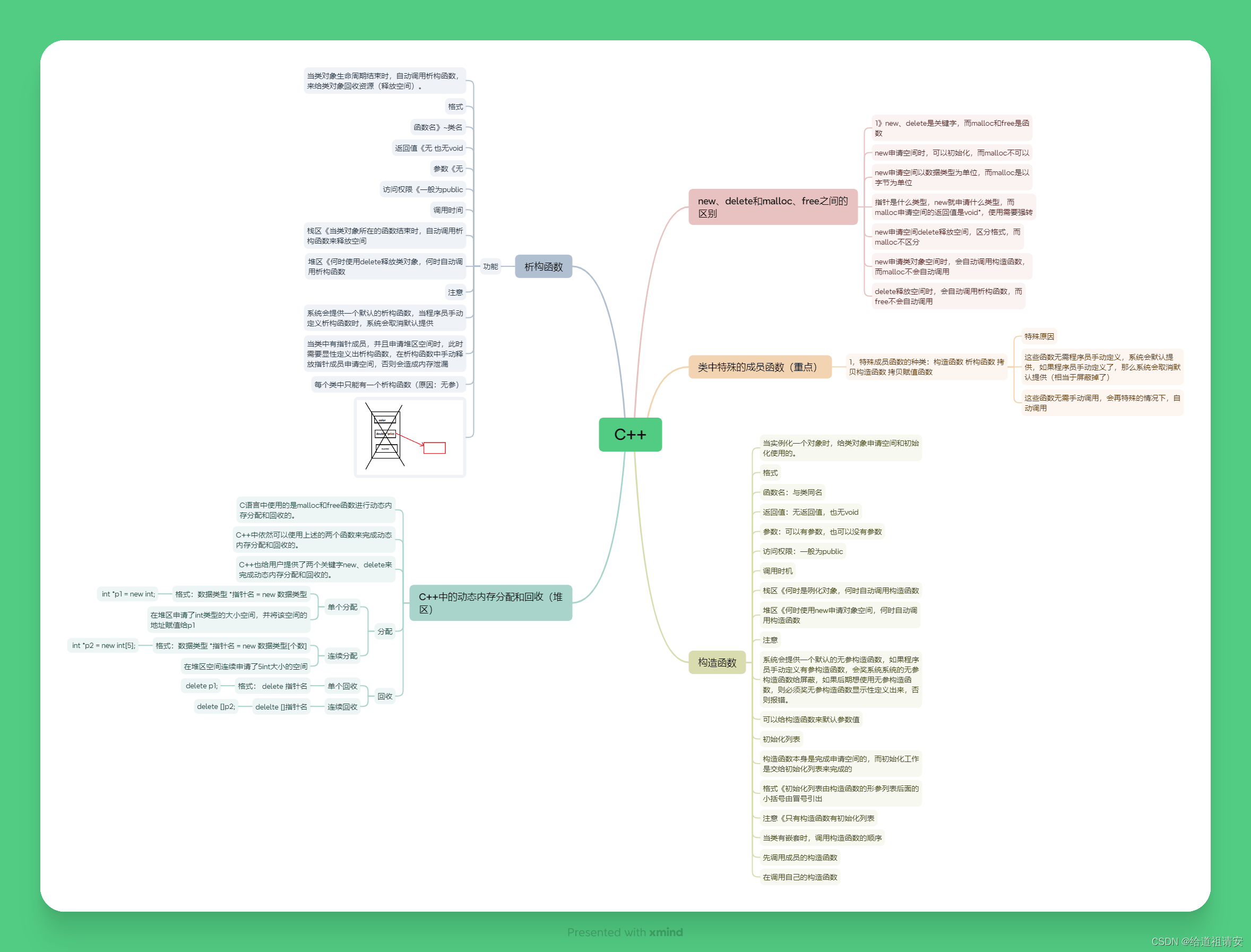
6月5号作业
设计一个Per类,类中包含私有成员:姓名、年龄、指针成员身高、体重,再设计一个Stu类,类中包含私有成员:成绩、Per类对象p1,设计这两个类的构造函数、析构函数 #include <iostream>using namespace std; class Slu { priv…...

中继器、集线器、网桥、交换机、路由器和网关
目录 前言一、中继器、集线器1.1 中继器1.2 集线器 二、网桥、交换机2.1 网桥2.1.1 认识网桥2.1.2 网桥的工作原理2.1.3 生成树网桥 2.2 交换机2.2.1 交换机的特征2.2.2 交换机的交换模式2.2.3 交换机的功能 三、路由器、网关3.1 路由器的介绍3.2 路由器的工作过程3.2.1 前置知…...

揭秘相似矩阵:机器学习算法中的隐形“纽带”
在机器学习领域,数据的处理和分析至关重要。如何有效地从复杂的数据集中提取有价值的信息,是每一个机器学习研究者都在努力探索的问题。相似矩阵,作为衡量数据之间相似性的数学工具,在机器学习算法中扮演着不可或缺的角色。 相似矩…...
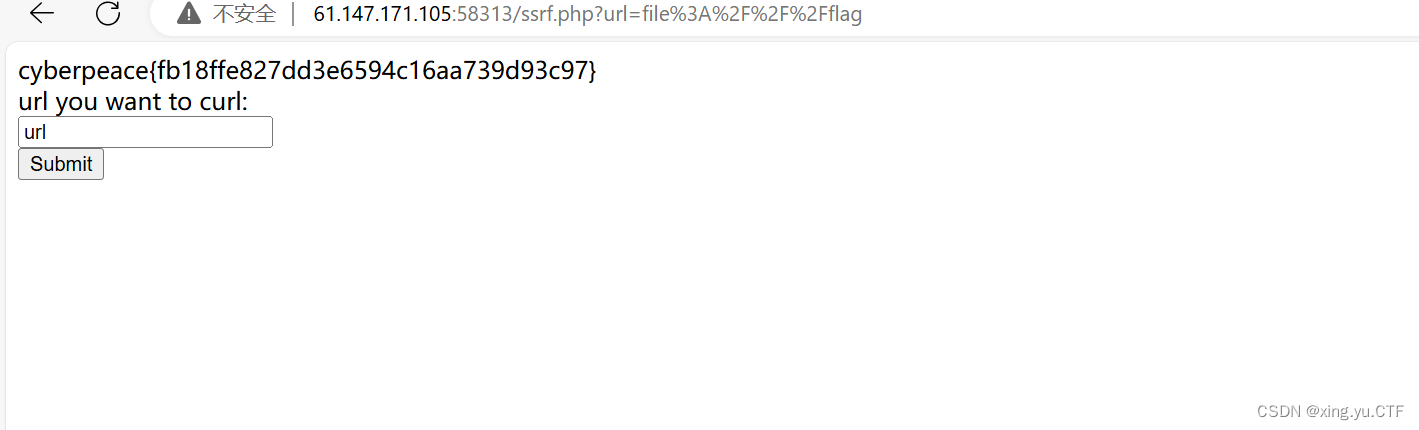
攻防世界—webbaby详解
1.ssrf注入漏洞 ssrf(服务端请求伪造)是一种安全漏洞,攻击者通过该漏洞向受害服务器发出伪造的请求,从而访问并获取服务器上的资源,常见的ssrf攻击场景包括访问内部网络的服务,执行本地文件系统命令&#…...
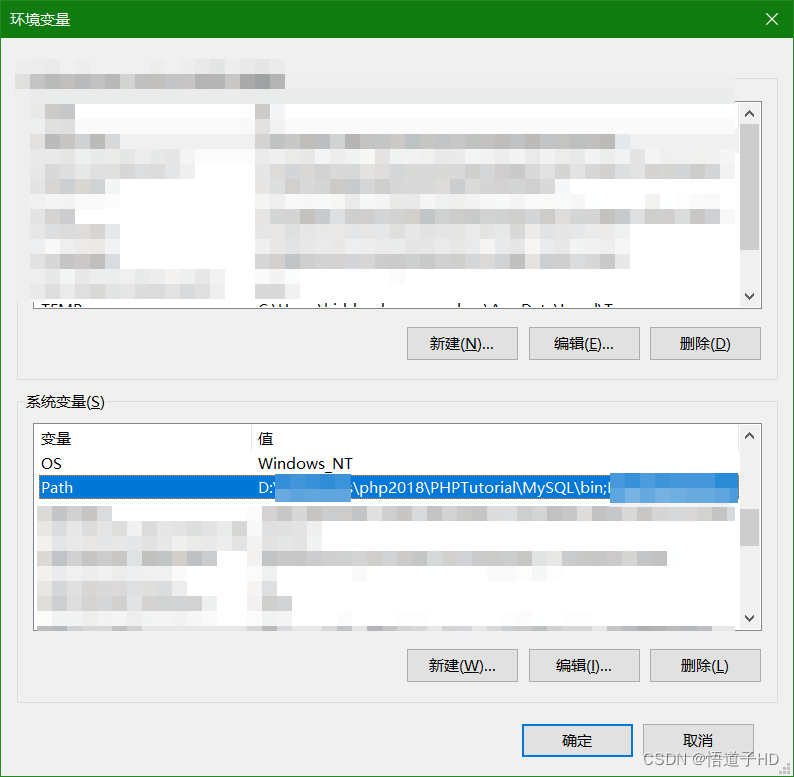
MySQL中:cmd下输入命令mysql -uroot -p 连接数据库错误
目录 问题cmd下输入命令mysql -uroot -p错误 待续、更新中 问题 cmd下输入命令mysql -uroot -p错误 解决 配置环境变量:高级系统设置——环境变量——系统变量——path编辑——新建——MySQL.exe文件路径(如下图所示) phpstudy2018软件下&am…...

【开发利器】使用OpenCV算子工作流高效开发
学习《人工智能应用软件开发》,学会所有OpenCV技能就这么简单! 做真正的OpenCV开发者,从入门到入职,一步到位! OpenCV实验大师Python SDK 基于OpenCV实验大师v1.02版本提供的Python SDK 实现工作流导出与第三方应用集…...
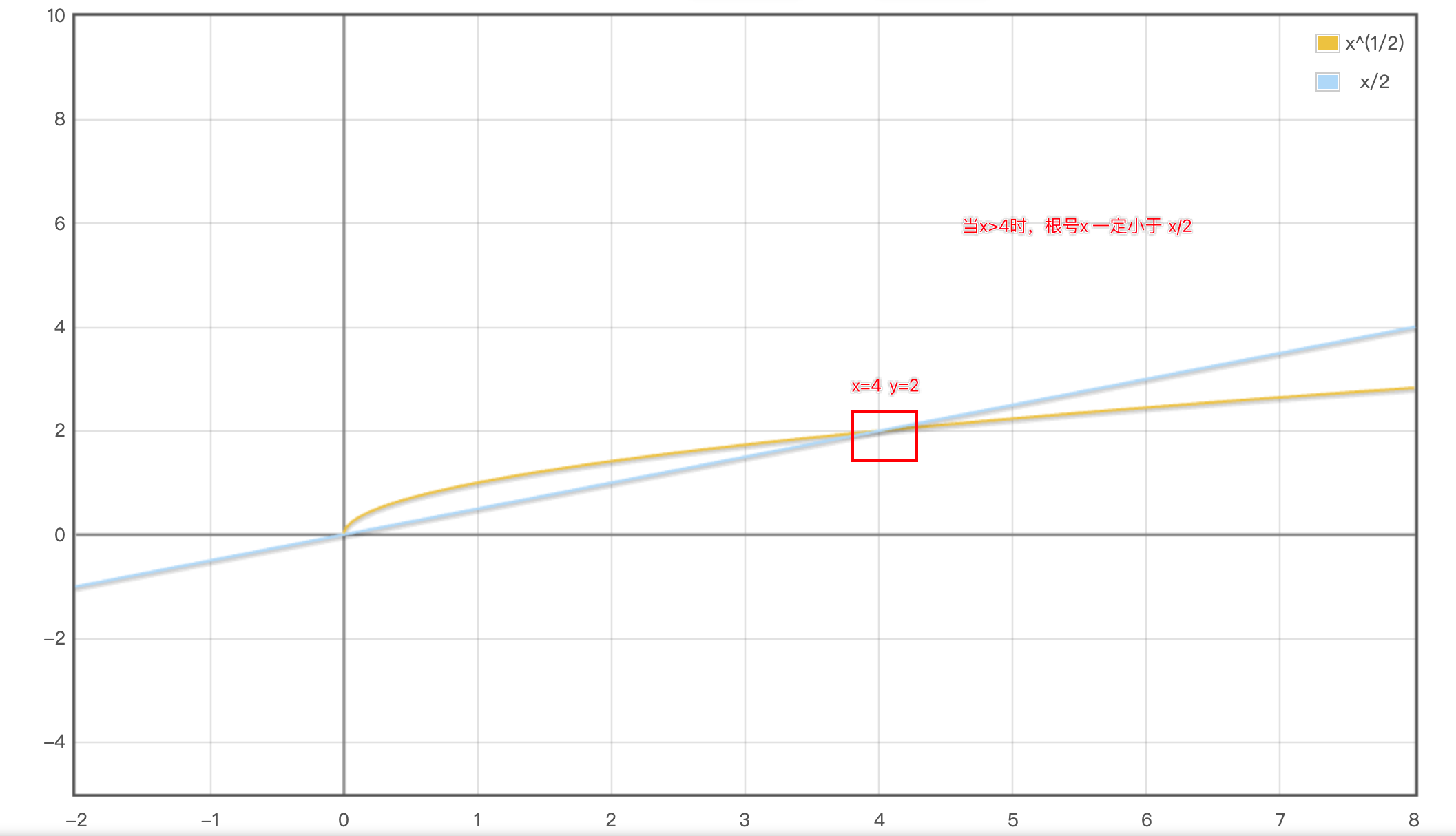
基础数学-求平方根(easy)
一、问题描述 二、实现思路 1.题目不能直接调用Math.sqrt(x) 2.这个题目可以使用二分法来缩小返回值范围 所以我们在left<right时 使 mid (leftright)/21 当mid*mid>x时,说明right范围过大,rightright-1 当mid*mid<x时,说明left范…...

c语言项目-贪吃蛇项目2-游戏的设计与分析
文章目录 前言游戏的设计与分析地图:这里简述一下c语言的国际化特性相关的知识<locale.h> 本地化头文件类项setlocale函数 上面我们讲到需要打印★,●,□三个宽字符找到这三个字符打印的方式有两种: 控制台屏幕的长宽特性&a…...

力扣2831.找出最长等值子数组
力扣2831.找出最长等值子数组 思路:用二维数组存每个数字的出现下标 遍历所有数字求结果当前子数组大小:pos[i] - pos[j] 1;当前相同数个数:i - j 1;需要删去的数的个数:pos[i] - pos[j] - i j; class Solution {public:int…...

17K star,一款开源免费的手机电脑无缝同屏软件
导读:白茶清欢无别事,我在等风也等你。 作为程序员,在我们的工作中经常需要把手机投票到电脑进行调试工作,选择一款功能强大的投屏软件是一件很必要的事情。今天给大家介绍一款开源且免费的投屏软件,极限投屏ÿ…...

正则表达式二
修饰符 i:将匹配设置为不区分大小写,即A和a没有区别 var str"Google Runoob taobao runoob"; var n1str.match(/runoob/g); //runoob var n2str.match(/runoob/gi); //Runoob,runoobg:重找所有匹配项࿰…...
我的创作纪念日--我和CSDN一起走过的1825天
机缘 第一次在CSDN写文章,是自己在记录学习Java8新特性中Lambda表达式的内容过程中收获的学习心得。之前也有记录工作和生活中的心得体会、难点的解决办法、bug的排查处理过程等等。一直都用的有道笔记,没有去和大家区分享的想法,是一起的朋…...

递归书写树形图示例
大叫好,今天书写了一个扁型转换为树型的例子,使用的是递归,请大家食用,无毒 <!DOCTYPE html> <html lang"zh"><head><meta charset"UTF-8"><meta name"viewport" conte…...

【python】IndexError: Replacement index 1 out of range for positional args tuple
成功解决“IndexError: Replacement index 1 out of range for positional args tuple”错误的全面指南 一、引言 在Python编程中,IndexError: Replacement index 1 out of range for positional args tuple这个错误通常发生在使用str.format()方法或者f-string&am…...
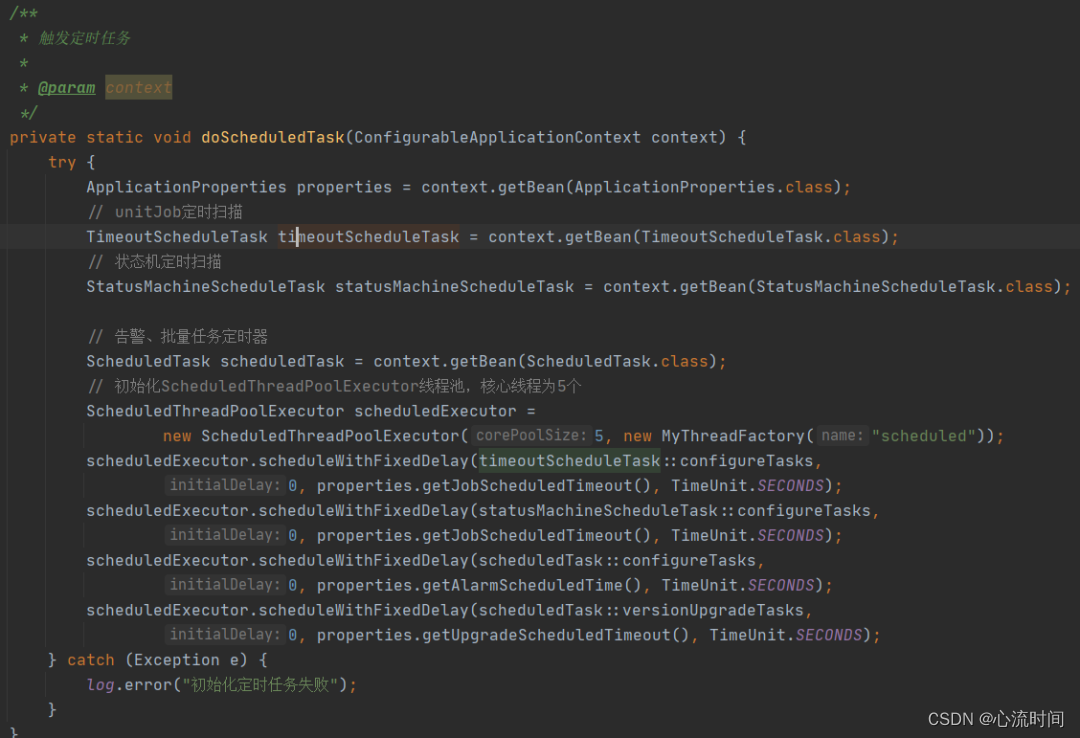
Spring自带定时任务@Scheduled注解
文章目录 1. cron表达式生成器2. 简单定时任务代码示例:每隔两秒打印一次字符3. Scheduled注解的参数3.1 cron3.2 fixedDelay3.3 fixedRate3.4 initialDelay3.5 fixedDelayString、fixedRateString、initialDelayString等是String类型,支持占位符3.6 tim…...

代码随想录算法训练营第二十九天|LeetCode491 非递减子序列、LeetCode46 全排列、LeetCode47 全排列Ⅱ
题1: 指路:491. 非递减子序列 - 力扣(LeetCode) 思路与代码: 对于这个题我们应该想起我们做过的子集问题,就是在原来的问题上加一个去重操作。我们用unordered_set集合去重,集合中使用过的元…...
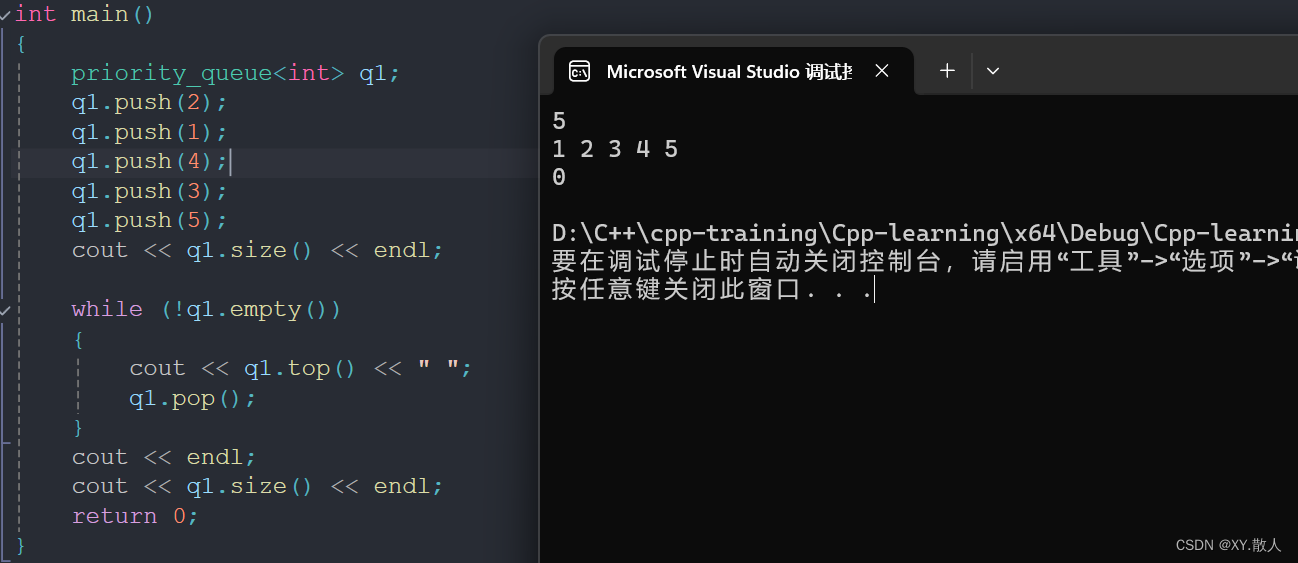
初识C++ · 优先级队列
目录 前言: 1 优先级队列的使用 2 优先级队列的实现 3 仿函数 前言: 栈和队列相对其他容器来说是比较简单的,在stl里面,有一种容器适配器是优先级队列(priority_queue),它也是个队列&#…...
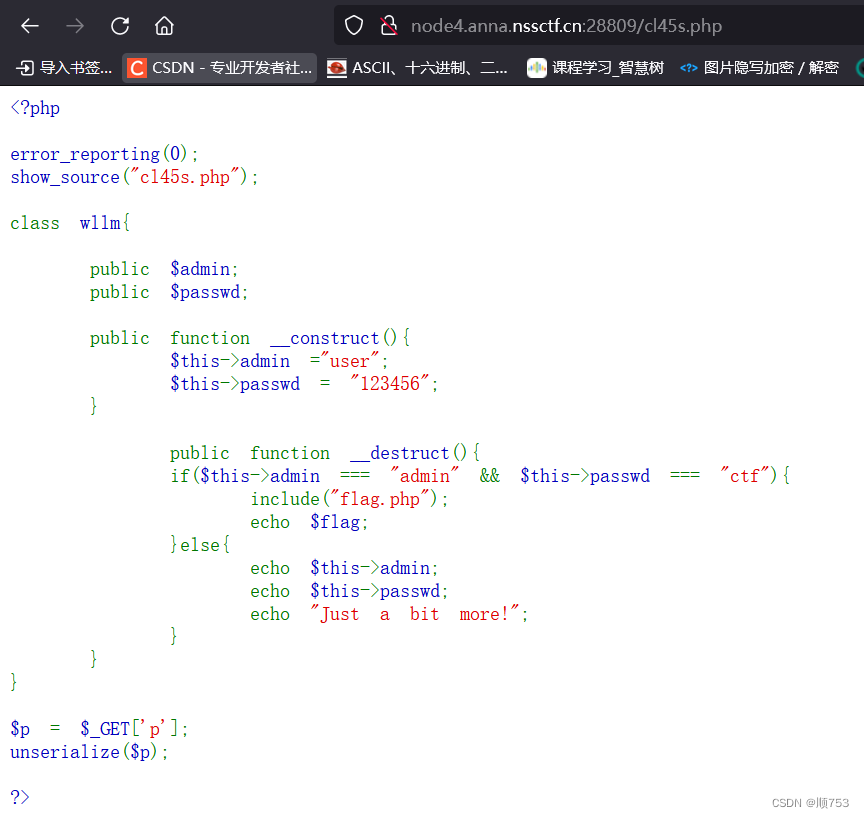
php反序列化入门
一,php面向对象。 1.面向对象: 以“对象”伪中心的编程思想,把要解决的问题分解成对象,简单理解为套用模版,注重结果。 2.面向过程: 以“整体事件”为中心的编程思想,把解决问题的步骤分析出…...
嵌入式 Linux LED 驱动开发实验学习
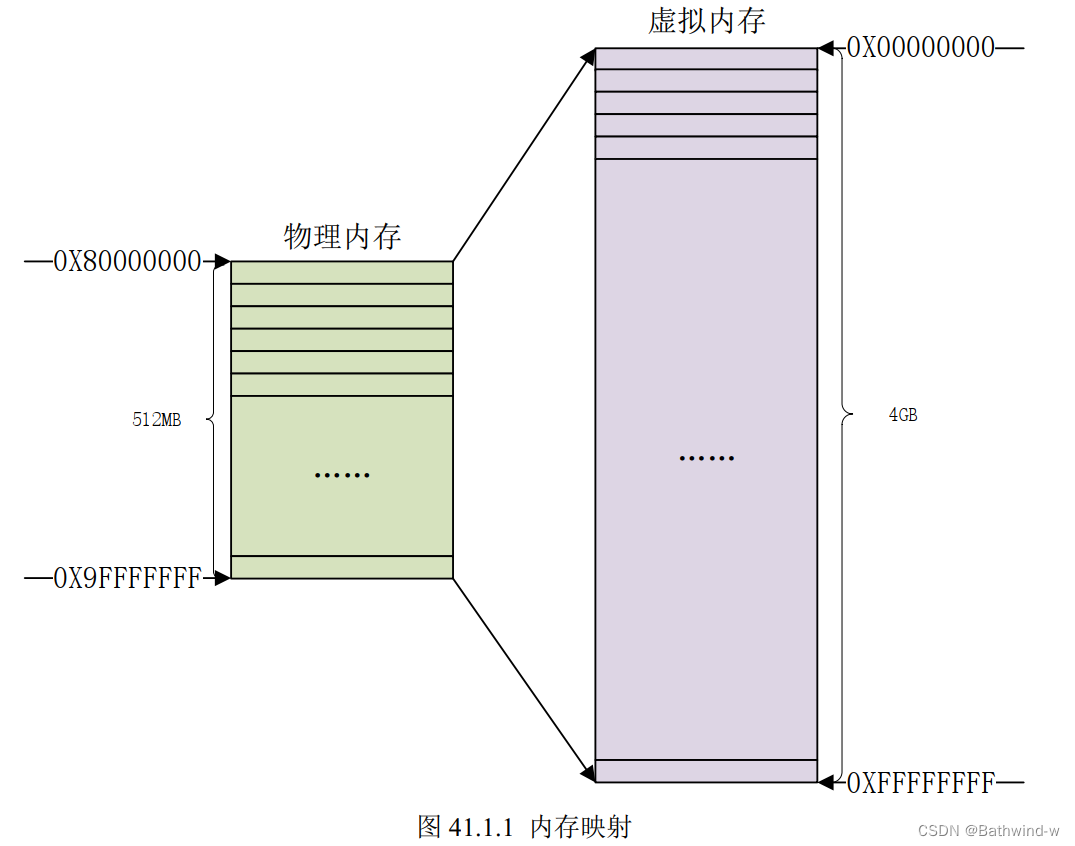
I.MX6U-ALPHA 开发板上的 LED 连接到 I.MX6ULL 的 GPIO1_IO03 这个引脚上,进行这个驱动开发实验之前,需要了解下地址映射。 地址映射 MMU 全称叫做 MemoryManage Unit,也就是内存管理单元。在老版本的 Linux 中要求处理器必须有 MMU&#x…...
)
Verilog实战:手把手教你实现8B/10B编码与解码(附完整代码)
Verilog实战:从零构建8B/10B编解码器的工程化实现 在高速串行通信领域,数据完整性如同精密钟表的齿轮咬合——任何微小的时序偏差都可能导致整个系统崩溃。8B/10B编码技术正是解决这一痛点的关键钥匙,它通过精心设计的编码规则,确…...

实战演练:基于快马平台与zeroclaw理念构建高性能个人博客系统
最近在尝试用zeroclaw理念重构个人博客系统,发现这种极简高效的设计思路确实能大幅提升开发效率和运行性能。今天就来分享下基于InsCode(快马)平台实现的完整实战过程。 项目架构设计 zeroclaw的核心是"零冗余",所以在设计阶段就做了严格的功能…...

Flutter 自定义 Widget:打造独特的用户界面
Flutter 自定义 Widget:打造独特的用户界面突破内置组件的局限,创造属于你自己的 UI 组件。一、自定义 Widget 的意义 作为一名追求像素级还原的 UI 匠人,我深知内置组件的局限。有时候,设计稿上的那个特殊按钮,那个独…...

OpenClaw调试技巧:Phi-3-vision-128k-instruct视觉任务失败原因分析
OpenClaw调试技巧:Phi-3-vision-128k-instruct视觉任务失败原因分析 1. 问题背景与现象描述 上周我在尝试用OpenClaw对接Phi-3-vision-128k-instruct模型处理一组产品截图时,遇到了令人困惑的识别失败问题。明明人眼能清晰辨认的界面元素,模…...

内存屏障与volatile:并发编程的核心机制解析
1. 内存屏障与volatile的核心概念解析在并发编程领域,内存屏障和volatile是两个至关重要的底层技术。它们看似简单,却直接影响着程序的正确性和性能表现。理解这两个概念需要从计算机体系结构的多个层面进行分析。1.1 volatile关键字的本质作用volatile在…...

STM32外设驱动:内存映射与寄存器操作详解
1. STM32外设驱动基础:内存映射与寄存器操作在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源而广受欢迎。要真正掌握STM32的开发,理解其底层外设驱动机制至关重要。让我们从一个工程师的视角,深入剖析STM32外设驱…...

如何让老款Mac重获新生:OpenCore Legacy Patcher完整使用指南
如何让老款Mac重获新生:OpenCore Legacy Patcher完整使用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老款Mac电脑也能运行最新的…...

【数据集】电力巡检场景下的绝缘子、鸟巢及防震锤图像数据集构建与应用
1. 电力巡检图像数据集的价值与应用场景 在电力系统运维中,无人机巡检已经成为主流手段。我参与过多个省级电网的智能化改造项目,发现传统人工巡检最大的痛点在于:巡检员需要盯着屏幕分析数小时的航拍视频,不仅容易疲劳漏检&#…...
实现详解:从原理到前端 AI 对话应用)
前端 SSE(Server-Sent Events)实现详解:从原理到前端 AI 对话应用
为什么前端越来越需要“流式能力”?在传统 Web 应用中,前端与后端的通信方式大多是 “请求—响应” 模式: 前端发起请求,后端计算完成后一次性返回结果。但随着应用形态的演进,这种模式越来越显得“笨重”:…...
✅)
计算机毕业设计:Python智慧出行数据分析系统 Django框架 可视化 数据大屏 数据分析 大数据 机器学习 深度学习(建议收藏)✅
1、项目介绍 技术栈:Python语言、Django框架、ECharts可视化库、数据大屏技术。 功能模块: 首页模块数据大屏模块数据分析模块数据查看模块登录模块后台管理模块订单管理模块用户管理模块 项目介绍:滴滴出行数据分析平台基于Django框架开发&a…...