语言模型解构——Tokenizer
1. 认识Tokenizer
1.1 为什么要有tokenizer?
计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。
- 举个例子:单=1,双=2,计算机面临“单”和“双”的时候,它所理解的就是2倍关系。
- 再举一个例子:赞美=1,诋毁=0, 当计算机遇到0.5的时候,它知道这是“毁誉参半”。
- 再再举一个例子:女王={1,1},女人={1,0},国王={0,1},它能明白“女人”+“国王”=“女王”。
可以看出,计算机面临文字的时候,都是要通过数字去理解的。
所以,如何把文本转成数字,是语言模型中最基础的一步,而Tokenizer的作用就是完成文本到数字的转换,是大语言模型最基础的组件。
1.2 什么是tokenizer?
Tokenizer是一个词元生成器,它首先通过分词算法将文本切分成独立的token列表,再通过词表映射将每个token转换成语言模型可以处理的数字。
这里有一个网站,可以在线演示tokenizer的切分,见:tokenizer在线演示
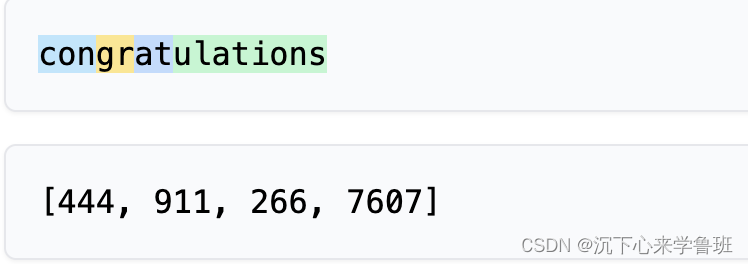
大多数常见的英语单词都分配一个token:

而有的单词却分配不止一个token:
像congratulations就被切分成4个token.
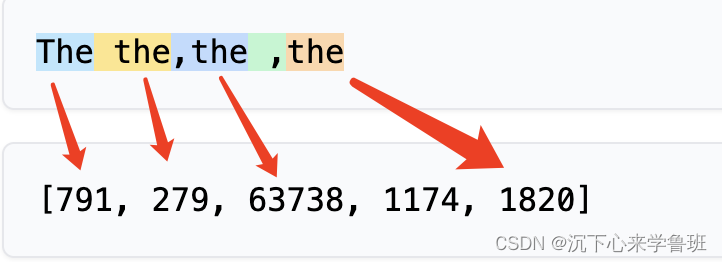
不仅如此,而字母大小写,空格和标点符号对分词结果也有影响,如下面示例:
以上这些分词效果,均与token的切分方式有关。
2. token切分方式
根据切分粒度的不同可以把tokenizer分为:
- 基于词的切分
- 基于字的切分
- 基于subword的切分
2.1 基于词的切分
将文本按照词语进行分割,通过空格或者标点符号来把文本分成一个个单词,这样分词之后的 token 数量就不会太多,比如 It is a nice day -> It, is, a, nice, day。缺点是:
- 词表规模可能会过大;
- 一定会存在UNK,造成信息丢失;
- 不能学习到词根、词缀之间的关系,例如:dog与dogs,happy与unhappy;
UNK是"unknown"(未知)的缩写,表示模型无法识别的单词或标记,对于一些新词、生僻词、专有名词或拼写错误的词可能未被词典收录。
词表规模过大原因:自然语言中存在大量的词汇,而词汇与词汇之间的排列组合又能造出大量的复合词,这会导致词表规模很大,并且持续增长。
2.2 基于字的切分
将文本按照字符进行切分,把文本拆分成一个个字符单独表示,比如 highest -> h, i, g, h, e, s, t。
- 优点:
- 词表Vocab 不会太大,Vocab 的大小为字符集的大小,英文只有26个字母;
- 也不会遇到UNK问题;
- 缺点:
- 字符本身并没有传达太多的语义,丧失了词的语义信息;
- 分词之后的 token序列过长,例如
highest一个单词就可以得到 7 个 token,如果是很长的文本分出来的token数量将难以想象,这会造成语言模型的解码效率很低;
2.3 基于subword的切分
从上可以看出,基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而subword就是一种相对平衡的折中方案,基本切分原则是:
- 高频词依旧切分成完整的整词,例如
It=>[ It ] - 低频词被切分成有意义的子词,例如
dogs=>[dog, s]
它的特点是:
- 词表规模适中,解码效率较高
- 不存在UNK,信息不丢失
- 能学习到词缀之间的关系
因此基于subword的切分是目前的主流切分方式。
3. subword分词流程
分词的基本需求:给定一个句子,基于分词模型切分成一连串token。效果如下:
input: Hello, how are u tday?
output: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
整个tokenize的过程可以用下面这个图来理解,分为预分词、基于模型分词、编码三步。

3.1 预分词
预分词阶段会把句子切分成词单元,可以基于空格或者标点进行切分。
以gpt2为例,预切分结果如下,每个单词变成了[word, (start_index, end_index)]
input: Hello, how are you?pre-tokenize:
[GPT2]: [('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)), ('?', (19, 20))]
在GPT2中,空格会保留成特殊的字符“Ġ”。
不同的模型在切分时对于空格和标点的处理方式不同,作为对比:
- BERT的tokenizer也是基于空格和标点进行切分,但不会保留空格。
[BERT]: [('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
- LLama 的T5则只基于空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",并且句子开头也会添加特殊字符"▁"。
[t5]: [('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
3.2 基于模型分词
上面预分词的结果基本就是一个单词一个token,但这样的切分粒度是很粗的,正如上面切分方式中介绍的问题,容易造成词表规模过大。
而基于模型分词本质上就是对预分词后的每个单词再尝试进行切分,也就是上面提到的subword方式,目前主流大语言模型使用的是BPE算法。
BPE分词的过程可以简单理解为从短到长逐步查找词元的过程,概括为以下三步。
- 对于输入序列中的每个单词拆分成一个个字符,以
Ġtday为例,拆分结果如下。
('Ġ', 't', 'd', 'a', 'y')
在BPE算法中,每个字母都是最基本的词元,这样能避免UNK问题。
- 从输入的字符序列逐步查找是否有更长的词元可以代替,如果找到,就将较短的几个词元替换成这个更长的词元,还是以
Ġtday为例替换过程如下所示。
# 第一次替换:'Ġ'和't'->'Ġt'
('Ġt', 'd', 'a', 'y')
# 第二次替换:'a'和'y'->'ay'
('Ġt', 'd', 'ay')
# 第三次替换:'d'和'ay'->'day'
('Ġt', 'day')
# 结束
- 这样
Ġtday这个预分的词元就被拆分成了Ġt和day两个最终的词元,这两个词元会替换掉先前的Ġtday。
为什么
Ġt和day不能进一步合并替换呢?
原因:tday其实是today这个单词的网络用语,这个网络简称在词汇表中并不存在,所以无法合并,最终tday这个单词就在分词阶段拆分成了t和day两个token。
那么,具体哪些字符或子词能合并成更长的词元呢?
这里依据的是分词模型中子词合并记录merges.txt,这个文件是模型训练过程中生成的,其中一段示例如下。
[["]", ",\\u010a"],["\\u0120H", "e"],["_", "st"],["f", "ul"],["o", "le"],[")", "{\\u010a"],["\\u0120sh", "ould"],["op", "y"],["el", "p"],["i", "er"],["_", "name"],["ers", "on"],["I", "ON"],["ot", "e"],["\\u0120t", "est"],["\\u0120b", "et"],["rr", "or"],["ul", "ar"],["\\u00e3", "\\u0122"],["\\u0120", "\\u00d0"],["b", "s"],["t", "ing"],["\\u0120m", "ake"],["T", "r"],["\\u0120a", "fter"],["ar", "get"],["R", "O"],["olum", "n"],["r", "c"],["_", "re"],["def", "ine"],["\\u0120r", "ight"],["r", "ight"],["d", "ay"],["\\u0120l", "ong"],["[", "]"],["(", "p"],["t", "d"],["con", "d"],["\\u0120P", "ro"],["\\u0120re", "m"],["ption", "s"],["v", "id"],[".", "g"],["\\u0120", "ext"],["\\u0120", "__"],["\'", ")\\u010a"],["p", "ace"],["m", "p"],["\\u0120m", "in"],["st", "ance"],["a", "ir"],["a", "ction"],["w", "h"],["t", "ype"],["ut", "il"],["a", "it"],["<", "?"],["I", "C"],["t", "ext"],["\\u0120p", "h"],["\\u0120f", "l"],[".", "M"],["cc", "ess"],["b", "r"],["f", "ore"],["ers", "ion"],[")", ",\\u010a"],[".", "re"],["ate", "g"],["\\u0120l", "oc"],["in", "s"],["-", "s"],["tr", "ib"],
这个合并记录表与我们人类能理解的单词、词根、词缀有一定差别,既有我们常见单词的合并记录: ["def","ine"], ["r", "ight"], ["d", "ay"],也有我们看不明白的: ["\\u0120f", "l"],、 ["cc", "ess"],这些合并记录不是人工编辑的,而是模型训练阶段根据实际语料来生成的。
这种方式是有效的,它既能保留常见的独立词汇(例如:how), 又能保证未知或罕见的词汇能被拆分为较小的词根或词缀(例如:tday->t和day),即使没有词根或词缀,最后还能以单个字符(例如:?, u) 作为词元保证不会出现UNK。
这样,通过词汇表就可以将预分词后的单词序列切分成最终的词元。
input: Hello, how are u tday?
Model: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
3.3 编码
编码本质上就是给每个token分配一个唯一的数字ID,这个数字ID是分词模型训练好后就维护在词汇表中的。
每个分词模型内部都有一个vocab词汇表,以chatgpt为例,目前使用的词表为c100k_base, 它是一个index ——> token的map映射(index表示token对应的数字ID)里面有大概10万个词元,示例如下:
{"0": "!","1": "\"","2": "#","3": "$","4": "%","5": "&","6": "'","7": "(","8": ")","9": "*","10": "+",……"1268": " how","1269": "rite","1270": "'\n","1271": "To","1272": "40","1273": "ww","1274": " people","1275": "index",……"100250": ".allowed","100251": "(newUser","100252": " merciless","100253": ".WaitFor","100254": " daycare","100255": " Conveyor"
}
切分好token后,就可以根据上面示例的词汇表,将token序列转换为数字序列,如下所示:
input: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
output: [9906, 11, 1268, 527, 577, 259, 1316, 5380]
关于这个词表vocab以及合并记录merges.txt的由来,与BPE算法的实现和训练过程有关,后续再介绍。
4. 中文分词
4.1 长度疑问
我们在估算token的消耗时,经常听到有同事说汉字要占两个token,是这样吗?我们来验证下:

为何有的汉字一个token,有的汉字两个token? 这和tiktoken对中文分词的实现方式有关。
4.2 实现剖析
举例:‘山东淄博吃烧烤’
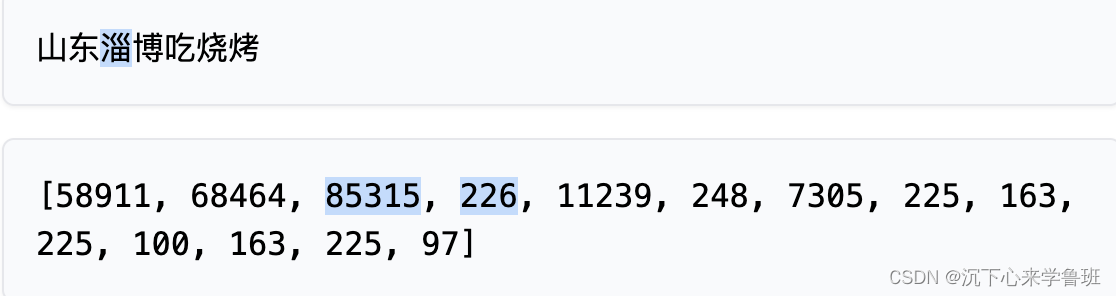
对应词汇表中的词元:
["山", "东", "b'\\xe6\\xb7'", "b'\\x84'", "b'\\xe5\\x8d'", "b'\\x9a'", "b'\\xe5\\x90'", "b'\\x83'", "b'\\xe7'", "b'\\x83'", "b'\\xa7'", "b'\\xe7'", "b'\\x83'", "b'\\xa4'"]
除了“山“、”东”这两个相对比较简单的汉字词表里面直接就有,其他的都是一些非常奇怪的Unicode编码表示。
仔细观察可以发现:tokens[85315, 226] 对应的"b’\xe6\xb7’", “b’\x84’” 拼接起来,然后按照utf-8解码回去 b’\xe6\xb7\x84’.decode(‘utf-8’) 得到的就是“淄”。
原来,OpenAI为了支持多种语言的Tokenizer,采用了文本的一种通用表示:UTF-8的编码方式,这是一种针对Unicode的可变长度字符编码方式,它将一个Unicode字符编码为1到4个字节的序列。
山和东因为比较常见,所以被编码为了独立的词元- 而
淄、博等字词频较低,所以按照Unicode编码预处理成了独立的3个字节,然后子词的迭代 合并最终分成了两个词元。
\x 表示16进制编码,可以发现
淄博分别被编码为6个16进制数字,分别占3个字节。随后,GPT-4将每2个16进制数字,也就是1字节的数据作为最小颗粒度的token,然后进行BPE的迭代、合并词表。
5. tiktoken
tiktoken是OpenAI开源一种分词工具,
采用BPE算法实现,被GPT系列大模型广泛使用。
基于某个模型来初始化tiktoken(不同模型的tiktoken词表不同):
import tiktoken
enc = tiktoken.encoding_for_model("gpt-3.5-turbo-16k")
字节对编码
encoding_res = enc.encode("Hello, how are u tday?")
print(encoding_res)> [9906, 11, 1268, 527, 577, 259, 1316, 30]
字节对解码
raw_text = enc.decode(encoding_res)
print(raw_text) > Hello, how are u tday?
如果想要控制token数量,则可以通过len函数来判断
length = len(enc.encode("Hello, how are u tday?"))
print(length)> 8
参考资料
- gpt在线分词演示
- 探索GPT Tokenizer的工作原理
相关文章:
语言模型解构——Tokenizer
1. 认识Tokenizer 1.1 为什么要有tokenizer? 计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。 举个例子:单1,双2&#x…...

前端经验:导出表格为excel并设置样式
应用场景 将网页上的table标签内容导出为excel,并且导出的excel携带样式,比如字色、背景色、对齐等等 实施步骤 必备引入包 npm install xlsx-js-style步骤1:准备好table table可以是已经存在与页面中的,也可以动态创建。 行…...
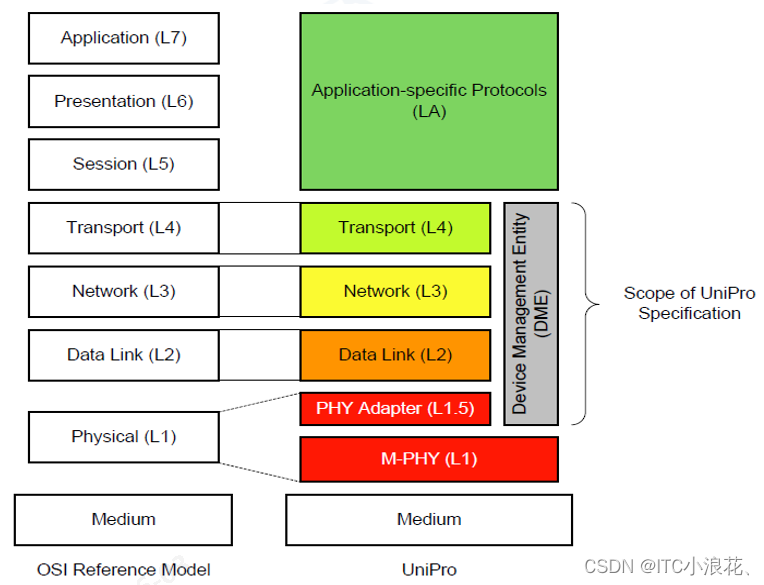
UFS协议—新手快速入门(二)【5-6】
目录 五、UFS协议栈 六、UFS技术演进与详解 1、UFS应用层 设备管理器 任务管理器 2、UFS传输层 3、UFS互联层 UFS协议—新手快速入门(一)【1-4】 五、UFS协议栈 UFS(Universal Flash Storage)协议是针对固态存储设备&…...

手机建站介绍
随着科技的不断进步和移动互联网的普及,手机应用已经成为人们生活中最不可或缺的一部分。而手机建站作为一种新兴技术,在这一领域也有着广泛的应用。本文将为大家介绍手机建站的概念、优势和应用。 什么是手机建站? 手机建站是指将传统的网络…...

windows11 安装cnpm 报错 Error: EPERM: operation not permitted 没权限
全部试过: 您遇到的错误是EPERM: operation not permitted,这意味着npm在尝试重命名文件或目录时缺少必要的权限。这通常与操作系统的权限设置有关。为了解决这个问题,您可以尝试以下几个步骤: 以管理员身份运行命令行࿱…...

SQL 如何获取A列相同但是B列不同的数据项
用户表里有两个字段:部门和职位。一个部门可能对应多个职位,多个部门也可能都有同一职位。比如: 部门 职位 财务 部长 财务 副部长 财务 会计 财务 职员 编辑 部长 编辑 副部长 编辑 主编 编辑 副主编 现在想通过筛选,获取职位名称…...

如何在QGIS中加载高清卫星影像?
我们在《如何在GlobalMapper中加载高清卫星影像》一文中,分享了在GlobalMapper中加载卫星影像的方法。 这里再为你分享如何在QGIS中加载高清卫星影像的方法,并可以在文末查看领取软件安装包和图源的方法。 如何加载高清图源? 要在QGIS中在…...

后端返回图片格式乱码
try {const response await request.get(checkCodeUrl.value,{responseType:"arraybuffer"});console.log("验证码请求成功:", response);checkCodeUrl.value data: image/jpeg;base64,${btoa(new Uint8Array(response).reduce((data, byte) > data …...

C++基础编程100题-025 OpenJudge-1.4-05 整数大小比较
更多资源请关注纽扣编程微信公众号 http://noi.openjudge.cn/ch0104/05/ 描述 输入两个整数,比较它们的大小。 输入 一行,包含两个整数x和y,中间用单个空格隔开。 0 < x < 2^32, -2^31 < y < 2^31。 输出 一个字符。 若x &…...

[office] 16种常见的COUNTIF函数公式设置 #笔记#职场发展
16种常见的COUNTIF函数公式设置 1、返回包含值12的单元格数量 COUNTIF(A:A,12) 2、返回包含负值的单元格数量 COUNTIF(A:A,"<0") 3、返回不等于0的单元格数量 COUNTIF(A:A,"<>0") 4、返回大于5的单元格数量 COUNTIF(A:A,">5"…...
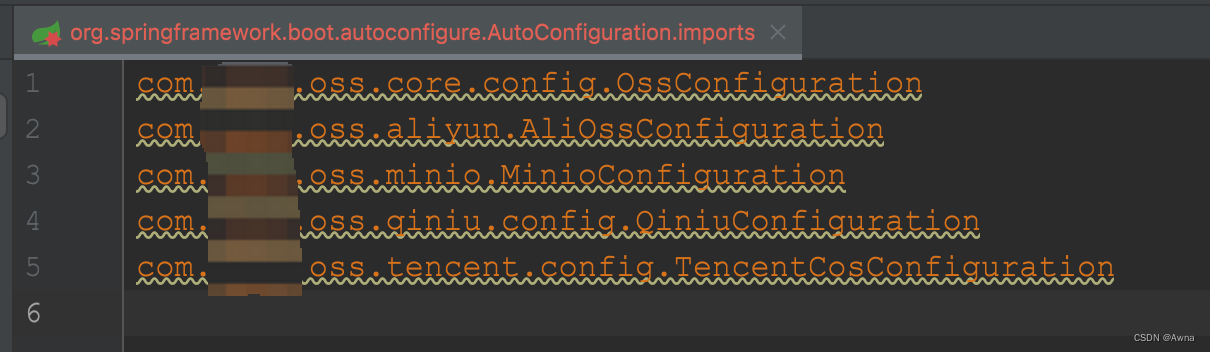
spring boot2.7.x遇到问题
validation报错 高版本已移除了validation以来,需手动添加 <dependency><groupId>jakarta.validation</groupId><artifactId>jakarta.validation-api</artifactId> </dependency>mybatis报错 升级版本 <dependency>&…...

Webpack 开发快速入门
WebPack详细入门教程(一)之简介 Webpack详细入门教程(二)之安装配置 WebPack详细入门教程(三)之loader加载器 Webpack详细入门教程(四)之Source Maps调试 Webpack详细入门教程&#…...

AI时代的多维探索
随着人工智能(AI)技术的迅猛发展,我们的生活正在经历一场深刻的变革。从智能家居到自动驾驶,从医疗诊断到金融投资,AI技术正逐渐渗透到社会的各个角落。为了更全面地了解AI时代的发展趋势,我们将通过十个具…...
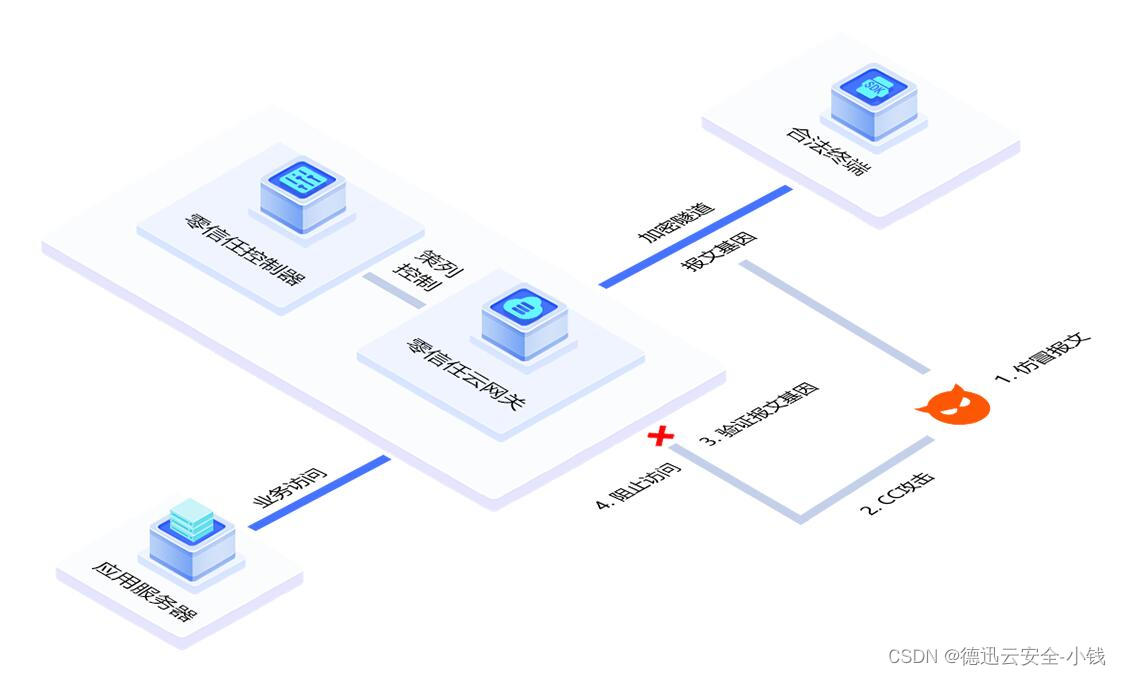
您的游戏端被攻击了怎么办,德迅云安全的应用加速来帮您
游戏行业DDoS攻击的主要原因是因为游戏产品生命周期偏短,而DDoS供给成本又不高,只要发起攻击,企业为确保游戏稳定运营而不得不快速做出让步,致使敲诈勒索的成功率相对更高。在遭受DDoS攻击后,游戏公司的日损失甚至多达…...

关于利用hashcat破解WiFi数据包的操作记录
准备数据包相关转换工具 ┌──(kali㉿kali)-[~/cap/3204] └─$ sudo apt-cache search hc | grep ^hc hcloud-cli - command-line interface for Hetzner Cloud hcxdumptool - Small tool to capture packets from wlan devices hcxkeys - Tools to generate plainmasterkey…...

伯克希尔·哈撒韦:“股神”的“登神长阶”
股价跳水大家见过不少,但一秒跌掉62万美元的你见过吗? 今天我们来聊聊“股市”巴菲特的公司——伯克希尔哈撒韦 最近,由于纽交所技术故障,伯克希尔哈撒韦A类股股价上演一秒归“零”,从超过62万美元跌成185.1美元&…...
f1c100s 荔枝派 系统移植
一。交叉编译环境配置 1.1下载交叉工具链:https://releases.linaro.org/components/toolchain/binaries/7.2-2017.11/arm-linux-gnueabi/ 1.2解压安装 在home目录下新建 工程目录:mkdir f1c100s_project 将windows下的gcc-linaro-7.2.1-2017.11-x86…...

EtherCAT 和 UDP 通讯的实时性 区别
EtherCAT 和 UDP 是两种不同的通信协议,它们在实时性方面有着本质的区别,主要体现在以下几个方面: 实时性设计目的: EtherCAT 是专为工业自动化设计的实时以太网协议,它通过独特的数据通信机制实现了极高的实时性能。E…...
山东大学软件学院项目实训-创新实训-基于大模型的旅游平台(二十八)- 微服务(8)
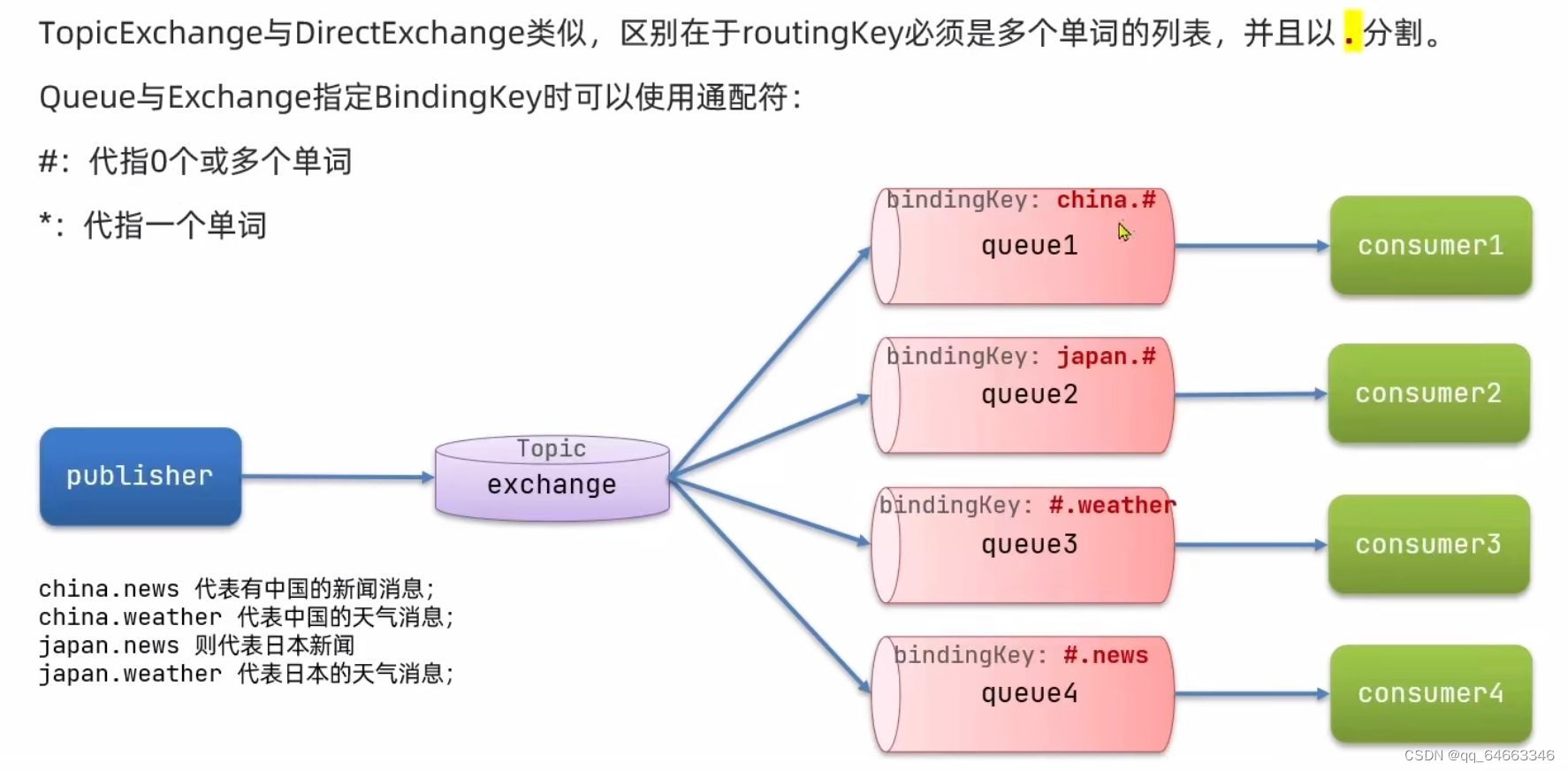
目录 11.4 SpringAMQP 11.4.2 Work Queue工作队列 11.4.3 发布订阅模型 11.4.4 FanoutExchange(广播交换机) 11.4.5 DirectExchange(路由模式交换机) 11.4.6 TopicExchange 11.5 消息转换器 11.4 SpringAMQP 父工程引入AMQP依赖 <!--AMQP依赖,包含RabbitMQ…...

如何将 MySQL 数据库共享给他人?
文章目录 共享所有数据库给他人1. 连接到 MySQL 数据库2. 选择要使用的数据库3. 修改连接所需的 host4. 刷新权限 共享部分数据库给他人1. 创建用户2. 授权3. 刷新权限 结语 🎉欢迎来到Java学习路线专栏~探索Java中的静态变量与实例变量 ☆* o(≧▽≦)o *☆嗨~我是I…...

Ostrakon-VL-8B多模态能力解析:图文联合理解在零售场景的体现
Ostrakon-VL-8B多模态能力解析:图文联合理解在零售场景的体现 1. 零售场景中的多模态挑战 现代零售行业面临着复杂的视觉理解需求。传统计算机视觉系统通常只能完成单一任务,比如商品识别或文字提取,而无法同时理解图像中的多种元素及其相互…...

华为eNSP实战:手把手教你用单臂路由打通不同VLAN,附排错命令清单
华为eNSP单臂路由实战:跨VLAN通信配置与深度排错指南 当企业网络规模扩大时,VLAN隔离是保障安全性和广播域控制的必要手段。但实际业务中,不同部门间的数据交互需求常常需要跨越VLAN边界。在华为认证体系HCIA和HCIP的实验环境中,单…...

科哥二次开发AWPortrait-Z体验:批量生成人像,效率提升300%
科哥二次开发AWPortrait-Z体验:批量生成人像,效率提升300% 1. 为什么选择AWPortrait-Z进行人像生成? 在当今内容创作领域,高质量人像需求呈现爆发式增长。从电商产品展示到社交媒体内容,专业级人像已经成为刚需。然而…...

PowerPaint-V1 Gradio场景应用:从家庭照片修复到工作素材处理
PowerPaint-V1 Gradio场景应用:从家庭照片修复到工作素材处理 1. 引言:图像修复的日常革命 周末整理老照片时,发现珍贵的全家福上有几处划痕;准备工作报告时,急需一张专业配图却找不到合适素材;电商运营需…...

中山网站建设哪家好?从AI搜索变革看网站建设的规范流程
在讨论“中山网站建设哪家好”之前,有一个更底层的问题需要先理解:👉 网站的价值,正在被AI重新定义。一、信息获取路径正在发生根本变化过去二十年,用户获取信息的方式大致是:用户提出问题 → 打开搜索引擎…...

如何快速定制lightgallery.js画廊样式:SCSS变量终极指南
如何快速定制lightgallery.js画廊样式:SCSS变量终极指南 【免费下载链接】lightgallery.js Full featured JavaScript image & video gallery. No dependencies 项目地址: https://gitcode.com/gh_mirrors/li/lightgallery.js lightgallery.js 是一个功能…...

SecGPT-14B模型蒸馏:打造轻量级OpenClaw安全助手
SecGPT-14B模型蒸馏:打造轻量级OpenClaw安全助手 1. 为什么需要轻量级安全助手? 去年在为一个金融客户部署自动化安全监控系统时,我遇到了一个典型困境:他们的边缘设备只能提供4GB内存和2核CPU的算力,但SecGPT-14B这…...

Grove-I2C颜色传感器驱动开发与RGB色彩识别实践
1. Grove-I2C颜色传感器技术解析与嵌入式驱动开发实践 1.1 模块硬件架构与传感原理 Grove-I2C颜色传感器模块基于TAOS(现为ams OSRAM)TCS3414CS高精度数字颜色传感器芯片设计,其核心传感单元由16个微型光电二极管阵列构成,呈82物…...

百川2-13B-4bits量化版API优化:降低OpenClaw任务Token消耗20%
百川2-13B-4bits量化版API优化:降低OpenClaw任务Token消耗20% 1. 问题背景与优化动机 上周在调试OpenClaw自动化流程时,我发现一个奇怪现象:同样的文件整理任务,在不同时段运行时消耗的Token数量差异能达到30%。作为个人开发者&…...

代码分享】“基因集单通路的泛癌GSEA富集分析
【代码分享]基因集单通路的泛癌GSEA富集分析#资料 如图最近在整理TCGA多组学数据时,发现不少小伙伴对通路活性评估有需求。今天分享一个快速实现泛癌GSEA分析的方法,特别适合需要观察某个特定通路在多个癌症类型中激活状态的情况。这个方法不需要复杂的编…...