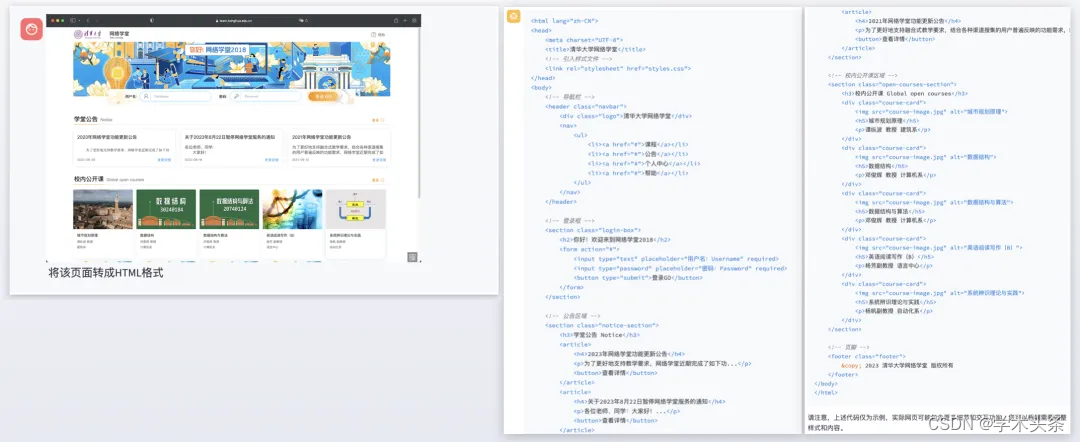
通过在idea上搭建虚拟hadoop环境使用MapReduce做词频去重
idea上的MapReduce
一般在开发中,若是等到环境搭配好了再进行测试或者统计数据,数据处理等操作,那会很耽误时间,所以一般都是2头跑,1波人去在客户机上搭建环境,1波人通过在idea上搭建虚拟hadoop环境,然后再虚拟环境下编写测试功能代码
使用Java API实现MapReduce经典案例
【案例1:数据去重】
1)配置windows下的hadoop环境变量
步骤1:将hadoop的安装包解压到指定位置(本例指定位置是:C:\Program Files)

步骤2:新建系统环境变量HADOOP_HOME

步骤3:编辑系统环境变量path

步骤4:添加windows系统的依赖文件,在hadoop安装路径下添加winutils.exe,winutils.pdb和hadoop.dll共3个文件

注意:
1)一定要重启电脑让以上配置生效(有时候不用重启也可以)
2)在命令提示符cmd中找不到hadoop的版本不影响后续编程

2)配置好Maven
步骤1:将maven相关文件夹apache-maven-3.6.0放在D盘的根目录
步骤2:使用idea新建maven项目,并做如下maven设置

3)编辑pom.xml文件,添加Maven库依赖

<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency>
</dependencies>
4)Map阶段的实现:编写DedupMapper.java代码 (教材P116

package com.xyzy;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import java.io.IOException;public class DedupDriver {public static void main (String[] args) throws IOException,ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(DedupDriver.class);job.setMapperClass(DedupMapper.class);job.setReducerClass(DedupReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job,new Path("D:/testdata/input"));FileOutputFormat.setOutputPath(job, new Path("D:/testdata/output2"));boolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}
5)Reduce阶段的实现:编写DedupReducer.java代码(教材P117)

package com.xyzy;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class DedupMapper extends Mapper<LongWritable, Text, Text,NullWritable> {private static Text field = new Text();@ Overrideprotected void map(LongWritable key, Text value , Context context)throws IOException, InterruptedException{field = value;context.write(field, NullWritable.get());}
}
6)驱动类的实现:编写DedupDriver.java代码(教材P117)

package com.xyzy;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class DedupReducer extends Reducer<Text,NullWritable, Text,NullWritable> {@ Overrideprotected void reduce(Text key, Iterable<NullWritable>value,Context context) throwsIOException, InterruptedException{context.write(key, NullWritable.get());}
}
7)要提前在d:/testdata/input中准备好素材(提醒一下output不是自己创建的文件夹,而是运行系统自动生成的!!!)

8)运行后的效果:

自动在d:/testdata/产生目录output,内容如下:

如果已经产生一次结果,若再想使用去重操作,则需要改写结果存储的文件夹名,例如将output改为output1即可
相关文章:
通过在idea上搭建虚拟hadoop环境使用MapReduce做词频去重
idea上的MapReduce 一般在开发中,若是等到环境搭配好了再进行测试或者统计数据,数据处理等操作,那会很耽误时间,所以一般都是2头跑,1波人去在客户机上搭建环境,1波人通过在idea上搭建虚拟hadoop环境&am…...

AI技术变革与企业服务创新
1、AI的技术变革 1)AI市场规模 2)AI大模型发展历程 3)AIGC发展背景 4)AIGC技术能力 AIGC的技术架构逻辑上分为基础层、技术层、能力层、应用层、终端层五大板块,其中核心技术层涵盖AI技术群和大模型的融合创新&#…...

探秘Facebook:社交媒体的未来之路
Facebook,作为全球最大的社交媒体平台之一,一直处于数字社交革命的前沿。然而,随着科技和社会的不断发展,Facebook正面临着新的挑战和机遇。本文将探索Facebook的未来之路,揭示社交媒体的新趋势和发展方向。 1. 深度社…...
)
rust的类型转换和一些智能指针用法(四)
基础类型 使用 as 关键字:用于基本数值类型之间的转换,例如将 i32 转换为 u32。 例子:let x: i32 10; let y: u64 x as u64; 使用标准库中的转换方法:如 from() 和 into() 方法,这些方法通常用于无风险的转换&#…...

探索大模型技术及其前沿应用——TextIn文档解析技术
前言 中国图象图形大会(CCIG 2024)于近期在西安召开,此次大会将面向开放创新、交叉融合的发展趋势,为图像图形相关领域的专家学者和产业界同仁,搭建一个展示创新成果、展望未来发展,集高度、深度、广度三位…...

Java HashMap 扩容机制深度解析
HashMap 的一个关键性能优化就是扩容机制,即在哈希表达到一定负载因子时,自动进行扩容,以保持检索效率。 在这篇文章中,我们将深入研究 HashMap 的扩容机制,了解其原理和影响因素。 1. 初始容量和负载因子 在深入了解…...

一、Electron 环境初步搭建
新建一个文件夹,然后进行 npm init -y 进行初始化,然后我们在进行 npm i electron --save-dev , 此时我们按照官网的教程进行一个初步的搭建, 1.在 package.json 文件进行修改 {"name": "electron-ui","version…...

ffmpeg编码器编码元数据的过程以及编码前后的差异
编码方式为avcodec_send_frame:将原始帧发送到编码器进行编码 编码过程完成于avcodec_receive_packet:从编码器接收编码后的压缩数据,也就是说已经编码压缩完成了,并存储到avpacket中,此时元数据被分割成多个NALU单元&…...
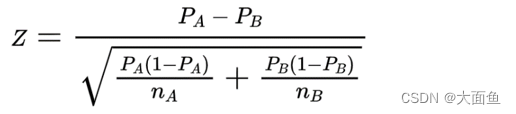
AB测试学习(附有相关代码)
目录 一、基本概念1. 定义2. 作用3. 原理 二、实验基本原则三、实验步骤四、实验步骤详解1. 确定实验目的2. 确定实验变量3. 实验指标设计3.1 实验指标类型(按作用区分)3.1.1 核心指标3.1.2 驱动指标(跟踪指标)3.1.3 护栏指标 3.2…...
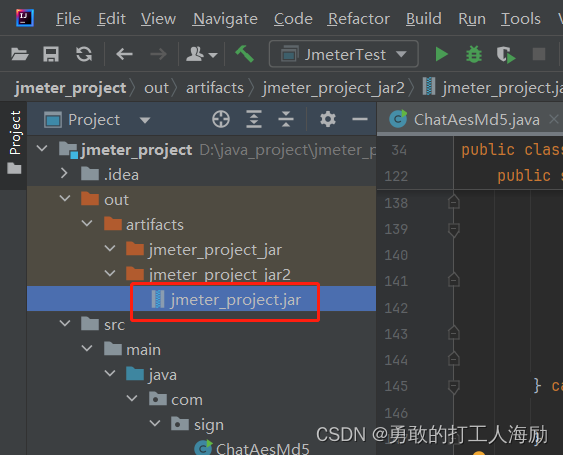
用idea将java文件打成jar包
一、用idea将java文件打成jar包 1、在idea上选择file—Project Structure 2、Artifacts —点–JAR—From modules with dependencies 3、选择要打包的java文件 4、Build — Build Artifacts 5、找到刚才添加的Artifacts直接Build 6、生成jar包文件...

Ansible——group模块
目录 参数总结 语法示例 创建用户组 删除用户组 设置组的 GID 创建系统组 修改组的 GID 添加用户组并附加其他组属性 删除指定 GID 的用户组 帮助信息 Playbook示例 基本示例 1. 创建用户组 2. 删除用户组 进阶示例 1. 修改组的 GID 2. 综合管理多个用户组 3…...
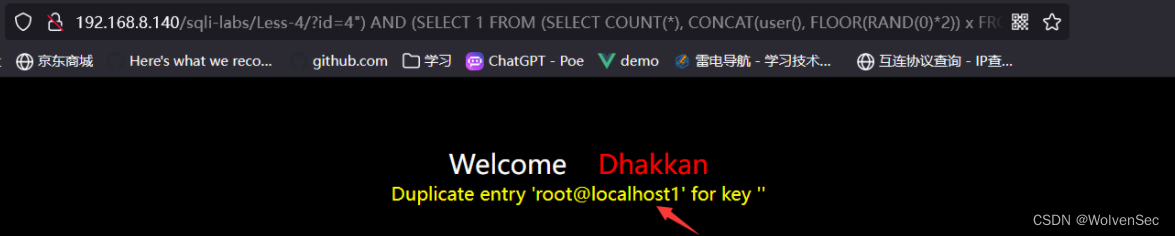
Sql注入-报错注入
报错注入(Error-Based Injection)是一种通过引起数据库报错并从错误信息中提取有用信息的SQL注入攻击手法;攻击者利用数据库在处理异常情况时返回的错误消息,来推断出数据库结构、字段名甚至数据内容;这种攻击方法依赖…...

pyqt 回车触发两次editingFinished的解决办法
在英文Qt论坛看到的解决办法 def editingFinished_triger(self):#self.sender() is the QlineEditif not self.sender().isModified(): returnself.sender().setModified(False)#treat code ...#treat code ...下面是一个错误使用editingFinished的例子 在上面界面中有一个文本…...
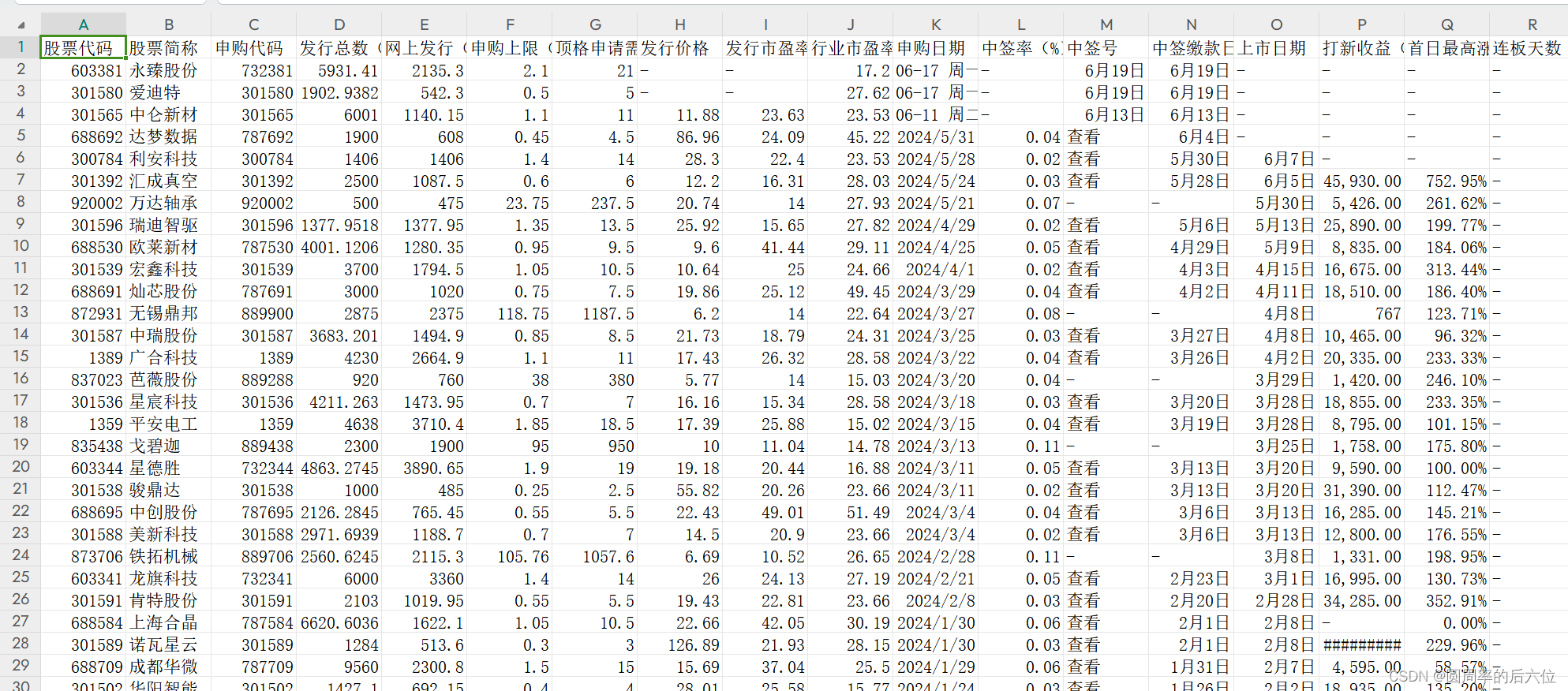
爬取股票数据python
最近在搜集数据要做分析,一般的数据来源是一手数据(生产的)和二手数据(来自其他地方的)。 今天我们爬取同花顺这个网站的数据。url为:https://data.10jqka.com.cn/ipo/xgsgyzq/ 话不多说直接上代码。有帮…...

每日新闻掌握【2024年6月4日 星期二】
2024年6月4日 星期二 农历四月廿八 TOP大新闻 张雪峰近2万元志愿填报服务已售罄 2024年高考临近,考生紧张的是考场上能否如常发挥,而考场之下,家长们已经开始为孩子的志愿填报焦心。峰学蔚来是由张雪峰打造专门提供高考志愿填报服务的APP&am…...
智谱AI 发布最新开源模型GLM-4-9B,通用能力超Llama-3-8B,多模态版本比肩GPT-4V
自 2023 年 3 月 14 日开源 ChatGLM-6B 以来,GLM 系列模型受到广泛关注和认可。特别是 ChatGLM3-6B 开源以后,开发者对智谱AI 第四代模型的开源充满期待。 为了使小模型(10B 以下)具备更加强大的能力,GLM 技术团队进行…...
从写简历到谈薪资的最全教程
从写简历到谈薪资的最全教程 目录简历注意事项举个例子写简历投递简历也有技巧模拟面试的重要性面试经验怎么刷不断迭代达越来越强斗智斗勇谈薪资拿到offer就结束了吗?我能给你的帮助 目录 大家好,我是一名普通本科毕业的学生,工作数年&#…...
)
Vue3 响应式API:高级函数(二)
shallowRef() shallowRef 是一个特殊的 ref 创建函数,它允许你创建一个只追踪顶层属性变化的响应式引用。与 ref 不同的是,shallowRef 创建的响应式引用对其内部值的深层嵌套属性是不敏感的,也就是说,只有当 shallowRef 的 .valu…...
攻击?)
『大模型笔记』什么是提示词注入(Prompt Injection)攻击?
什么是提示词注入(Prompt Injection)攻击? 文章目录 一. 什么是提示词注入(Prompt Injection)?二. 参考文献一. 什么是提示词注入(Prompt Injection)? 想花1美元买一辆新SUV吗?有人真的尝试过这样做。事实上,他们在一家特定汽车经销商的网站聊天机器人上进行了尝试。为了…...

SD-WAN与IPSec的对比
在现代企业中,随着网络环境的日益复杂,SD-WAN和IPSec作为两种关键的网络技术,各有其独特的优势和应用场景。那么,SD-WAN和IPSec究竟有什么不同?企业在不同情况下应该选择哪种技术呢? SD-WAN和IPSec的基本概…...

微信小程序物流信息对接实战:发货接口的完整实现指南
1. 微信小程序物流对接的核心价值 对于电商类小程序来说,物流信息同步是用户体验的关键环节。当用户下单后,最关心的就是"我的包裹到哪了"。传统做法需要用户手动复制单号到第三方平台查询,而通过微信官方物流接口,可以…...

Heritrix3源码深度解析:从CrawlURI到ProcessorChain的执行流程
Heritrix3源码深度解析:从CrawlURI到ProcessorChain的执行流程 【免费下载链接】heritrix3 Heritrix is the Internet Archives open-source, extensible, web-scale, archival-quality web crawler project. 项目地址: https://gitcode.com/gh_mirrors/he/herit…...

Unity资源提取技术解密:AssetRipper效能革命与实战指南
Unity资源提取技术解密:AssetRipper效能革命与实战指南 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在游戏开发迭代加速…...

保姆级教程:在Windows系统本地部署Qwen3-14B-Int4-AWQ对话模型
保姆级教程:在Windows系统本地部署Qwen3-14B-Int4-AWQ对话模型 1. 前言:为什么选择本地部署? 在个人电脑上运行大语言模型听起来可能有些遥不可及,但随着模型量化技术的进步,现在即使是消费级显卡也能流畅运行14B参数…...

小麦联合收割机的设计【说明书+SW三维+CAD图纸】
小麦联合收割机作为现代农业机械化的核心装备,其设计需兼顾效率、可靠性与适应性。该设备通过集成收割、脱粒、清选及集粮功能,实现小麦收获环节的连续作业,显著缩短田间作业周期,降低人工劳动强度。其核心作用体现在三方面&#…...
)
东华OJ-基础题-48-数列1(C++)
问题描述 思维的严密性是相当重要的,尤其是在程序设计中,一个小小的错误,就可能导致无法想象的后果。明明的爸爸是一名富有经验的程序设计专家,深知思维严密的重要性。于是在明明很小的时候,就通过游戏的方式训练明明的…...

Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例
Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例 1. 惊艳效果预览 Kandinsky-5.0-I2V-Lite-5s带来的建筑漫游视频生成效果令人印象深刻。想象一下,你有一张静态的建筑设计图纸,通过这个模型,只需简单描述…...

Z-Image-GGUF模型Java后端集成指南:SpringBoot微服务实战
Z-Image-GGUF模型Java后端集成指南:SpringBoot微服务实战 最近在做一个内容创作平台的后台重构,产品经理提了个需求,想给用户加个“AI一键生成文章配图”的功能。团队评估了几个方案,最终决定用Z-Image-GGUF这个模型,…...

Go Channel 缓冲区机制与性能影响
Go Channel 缓冲区机制与性能影响 在Go语言中,Channel是协程间通信的核心机制,而缓冲区的设置直接影响程序的并发性能和稳定性。理解缓冲区的运作原理及其对性能的影响,对于编写高效、可靠的并发程序至关重要。本文将从缓冲区的底层机制出发…...

别再死记硬背了!用这5个真实运维脚本,搞定90%的Shell面试题
5个实战Shell脚本:从面试题到真实运维场景的蜕变 在技术面试中,Shell脚本能力往往是区分普通候选人和优秀候选人的关键指标。但死记硬背面试题答案的时代已经过去,现代企业更看重候选人解决实际问题的能力。本文将带你通过5个真实运维场景中的…...