python -- series和 DataFrame增删改数据
学习目标
-
知道df添加新列的操作
-
知道insert函数插入列数据
-
知道drop函数删除df的行或列数据
-
知道drop_duplicates函数对df或series进行数据去重
-
知道unique函数对series进行数据去重
-
知道apply函数的使用方法
1 DataFrame添加列
注意:本文用到的数据集在文章顶部
1.1 直接赋值添加列数据
通过
df[列名]=新值或df[列名]=series对象/list对象添加新的一列, 新列添加到df的最后
-
添加列名为
城市的一列, 值都为北京import pandas as pd # 加载数据集 df = pd.read_csv('../data/LJdata.csv') # 获取前5条数据并复制一份 temp_df = df.head().copy() # 添加一列数据都是固定值 temp_df['省份'] = '北京' print(temp_df) # 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数 城市 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 北京 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 北京 2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34 北京 3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 北京 4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30 北京 -
添加列名为
区县的一列, 值分别是朝阳区、朝阳区、西城区、昌平区、朝阳区# 列表的数据数量必须和df的行数相等 temp_df['区县'] = ['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'] print(temp_df) # 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数 省份 区县 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 北京 朝阳区 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 北京 朝阳区 2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34 北京 西城区 3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 北京 昌平区 4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30 北京 朝阳区 -
添加列名为
新价格的一列, 值比原价格列的值多1000元# 新增数据为series对象 # print(temp_df['价格'] + 1000) temp_df['新价格'] = temp_df['价格'] + 1000 print(temp_df) # 输出结果如下区域 地址 户型 面积 价格 ... 更新时间 看房人数 省份 区县 新价格 0 燕莎租房 新源街 2室1厅 50 5800 ... 2017.07.21 26 北京 朝阳区 6800 1 望京租房 澳洲康都 2室1厅 79 7800 ... 2017.07.23 33 北京 朝阳区 8800 2 广安门租房 远见名苑 2室1厅 86 8000 ... 2017.07.20 34 北京 西城区 9000 3 天通苑租房 天通苑北一区 2室1厅 103 5300 ... 2017.07.25 30 北京 昌平区 6300 4 团结湖租房 团结湖北口 2室1厅 63 6400 ... 2017.07.26 30 北京 朝阳区 7400
1.2 insert函数添加列数据
通过
df.insert(loc=,column=,value=)方法在指定位置添加列loc: 指定列位置下标数字
column: 添加列的列名
value: 添加列的所有值, series对象、列表对象、常数等
-
在区域列后添加列名为
城市的一列, 值都为北京# 获取前5条数据 new_df = df.head().copy() print(new_df) new_df.insert(loc=1, column='城市', value='北京') print(new_df) # 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30区域 城市 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 北京 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 北京 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 广安门租房 北京 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 天通苑租房 北京 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 团结湖租房 北京 团结湖北口 2室1厅 63 6400 南 2017.07.26 30 -
在城市列后添加列名为
区县的一列, 值分别是朝阳区、朝阳区、西城区、昌平区、朝阳区new_df.insert(loc=2, column='区县', value=['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']) print(new_df) # 输出结果如下区域 城市 区县 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 北京 朝阳区 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 北京 朝阳区 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 广安门租房 北京 西城区 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 天通苑租房 北京 昌平区 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 团结湖租房 北京 朝阳区 团结湖北口 2室1厅 63 6400 南 2017.07.26 30 -
在价格列后添加列名为
新价格的一列, 值比原价格列的值多1000元pd.set_option('display.max_columns', None) # 展示所有列 pd.set_option('display.width', None) # 不换行显示 new_df.insert(loc=7, column='新价格', value=new_df['价格'] + 1000) print(new_df) # 输出结果如下区域 城市 区县 地址 户型 面积 价格 新价格 朝向 更新时间 看房人数 0 燕莎租房 北京 朝阳区 新源街 2室1厅 50 5800 6800 南 2017.07.21 26 1 望京租房 北京 朝阳区 澳洲康都 2室1厅 79 7800 8800 东 2017.07.23 33 2 广安门租房 北京 西城区 远见名苑 2室1厅 86 8000 9000 东 2017.07.20 34 3 天通苑租房 北京 昌平区 天通苑北一区 2室1厅 103 5300 6300 东南 2017.07.25 30 4 团结湖租房 北京 朝阳区 团结湖北口 2室1厅 63 6400 7400 南 2017.07.26 30
2 DataFrame删除行列
通过
df.drop(labels=, axis=, inplace=)方法删除行列数据labels: 行索引值或列名列表
axis: 删除行->
0或index, 删除列->1或columns, 默认0inplace:
True或False, 是否在原数据上删除, 默认False
# 删除一行数据, 原df上并没有删除
print(temp_df.drop(labels=[0]))
# 删除多行数据, 原df上删除
temp_df.drop(labels=[0, 2, 4], axis='index', inplace=True)
print(temp_df)
# 删除一列数据, 原df上并没有删除
print(temp_df.drop(labels=['新价格'], axis=1))
# 删除多列数据, 原df上删除
temp_df.drop(labels=['新价格', '区县', '省份'], axis='columns', inplace=True)
print(temp_df)
# 输出结果如下区域 地址 户型 面积 价格 ... 更新时间 看房人数 省份 区县 新价格
1 望京租房 澳洲康都 2室1厅 79 7800 ... 2017.07.23 33 北京 朝阳区 8800
2 广安门租房 远见名苑 2室1厅 86 8000 ... 2017.07.20 34 北京 西城区 9000
3 天通苑租房 天通苑北一区 2室1厅 103 5300 ... 2017.07.25 30 北京 昌平区 6300
4 团结湖租房 团结湖北口 2室1厅 63 6400 ... 2017.07.26 30 北京 朝阳区 7400
[4 rows x 11 columns]区域 地址 户型 面积 价格 ... 更新时间 看房人数 省份 区县 新价格
1 望京租房 澳洲康都 2室1厅 79 7800 ... 2017.07.23 33 北京 朝阳区 8800
3 天通苑租房 天通苑北一区 2室1厅 103 5300 ... 2017.07.25 30 北京 昌平区 6300
[2 rows x 11 columns]区域 地址 户型 面积 价格 朝向 更新时间 看房人数 省份 区县
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 北京 朝阳区
3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 北京 昌平区区域 地址 户型 面积 价格 朝向 更新时间 看房人数
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33
3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 303 Series或DataFrame数据去重
通过
<s/df>.drop_duplicates(subset=,keep=,inplace=)方法对数据去重subset: df的参数, 传入列名列表, 对指定列进行去重, 不写此参数默认对所有列进行去重
keep: 保留哪条重复数据,
first->保留第一条,last->保留最后一条,False->都不保留, 默认firstinplace:
True或False, 是否在原数据上去重, 默认False
-
DataFrame数据去重 duplicates
temp_df = df.head().copy() # 对df所有列去重, 当前df没有重复的行数据 print(temp_df.drop_duplicates()) # 根据指定列对df去重, 默认保留第一条数据 # 第1行和第5行、第2行和第3行重复 print(temp_df.drop_duplicates(subset=['户型', '朝向'])) # 保留最后一条数据 # print(temp_df.drop_duplicates(subset=['户型', '朝向'], keep='last')) # 重复数据都不保留 # print(temp_df.drop_duplicates(subset=['户型', '朝向'], keep=False)) # 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30区域 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 -
Series数据去重
print('-------------去重之后返回Series对象--------------------') # 默认保留第一条数据 print(temp_df['朝向'].drop_duplicates()) # 保留最后一条数据 print(temp_df['朝向'].drop_duplicates(keep='last')) # 重复数据都不保留 print(temp_df['朝向'].drop_duplicates(keep=False)) print('-------------去重之后返回数组--------------------') # series对象还可以使用unique函数去重, 返回ndarray数组 print(temp_df['朝向'].unique()) # nunique函数实现去重计数操作, 类似 count(distinct) print(temp_df['朝向'].nunique()) # 输出结果如下 0 南 1 东 3 东南 Name: 朝向, dtype: object 2 东 3 东南 4 南 Name: 朝向, dtype: object 3 东南 Name: 朝向, dtype: object ['南' '东' '东南'] 3
4 Series或DataFrame数据修改
4.1 直接修改数据
通过
df[列名]=新值或s[行索引]=新值修改数据
# 获取前5条数据并复制一份
temp_df = df.head().copy()
# 获取价格列, 得到series对象, 复制一份数据
s1 = temp_df['价格'].copy()
print(s1)
# series修改数据
s1[0] = 7000
print(s1)
# dataframe修改数据, 列表数据数量要和行数相等
temp_df['价格'] = [6800, 8800, 9000, 6300, 6400]
print(temp_df)
# 输出结果如下
0 5800
1 7800
2 8000
3 5300
4 6400
Name: 价格, dtype: int64
0 7000
1 7800
2 8000
3 5300
4 6400
Name: 价格, dtype: int64区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 6800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 8800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 9000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 6300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 304.2 replace函数替换数据
通过
<s/df>.replace(to_replace=, value=, inplace=)方法替换数据to_replace: 需要替换的数据
value: 替换后的数据
inplace:
True或False, 是否在原数据上替换, 默认False
# 获取前5条数据并复制一份
temp_df = df.head().copy()
# 替换series的数据
print(temp_df['价格'].replace(to_replace=5300, value=6000))
temp_df['朝向'].replace('东南', '西', inplace=True)
print(temp_df)
# 替换dataframe的数据
print(temp_df.replace(to_replace='2室1厅', value='3室2厅'))
# 输出结果如下
0 5800
1 7800
2 8000
3 6000
4 6400
Name: 价格, dtype: int64区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 5300 西 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 3室2厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 3室2厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 3室2厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 3室2厅 103 5300 西 2017.07.25 30
4 团结湖租房 团结湖北口 3室2厅 63 6400 南 2017.07.26 304.3执行自定义函数修改数据
有时需要我们对df或s对象中的数据做更加精细化的修改动作,并将修改操作封装成为一个自定义的函数;这时我们就可以利用
<s/df>.apply(函数名)来调用我们自定义的函数s或df对象可以借助apply函数执行自定义函数, 内置函数无法处理需求时就需要使用自定义函数来处理
4.3.1s.apply()函数遍历每一个值同时执行自定义函数
-
Series对象使用apply调用自定义的函数,返回新的Series对象
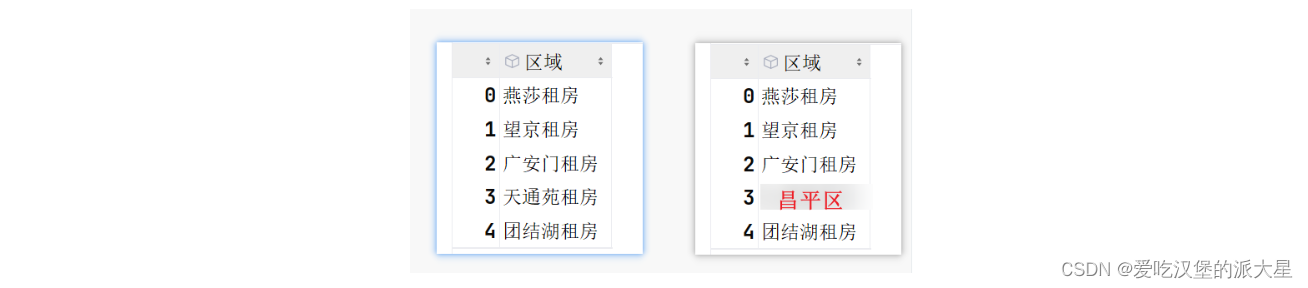
# 加载数据集 df = pd.read_csv('../data/LJdata.csv') # 获取前5条数据并复制一份 temp_df = df.head().copy() # 自定义函数, 最少接收一个参数 def func(x):# x此时是s对象中一个数据值:燕莎租房、望京租房print('x的值是->', x)# 本自定义函数返回的也是一个数据if x == '天通苑租房':return '昌平区'return x temp_df['区域'] = temp_df['区域'].apply(func) print(temp_df) # 输出结果如下 x的值是-> 燕莎租房 x的值是-> 望京租房 x的值是-> 广安门租房 x的值是-> 天通苑租房 x的值是-> 团结湖租房区域 地址 户型 面积 价格 朝向 更新时间 看房人数 0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26 1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 昌平区 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30 -
Series对象使用apply调用自定义的函数,并向自定义函数中传入其他参数
# 获取前5条数据 temp_df = df.head().copy() # 自定义函数, 最少接收一个参数 def func(x, arg1, arg2):# x此时是s对象中一个数据print('x的值是->', x)# 本自定义函数返回的也是一个数据if x == '天通苑租房':return arg1return arg2 # args: 传入其他参数值, 元组类型 temp_df['区域'] = temp_df['区域'].apply(func, args=('昌平区', '其他区')) # apply中其他参数名和自定义函数中其他形参名相同 # temp_df['区域'] = temp_df['区域'].apply(func1, arg1='昌平区', arg2='其他区') print(temp_df) # 输出结果如下 x的值是-> 燕莎租房 x的值是-> 望京租房 x的值是-> 广安门租房 x的值是-> 天通苑租房 x的值是-> 团结湖租房区域 地址 户型 面积 价格 朝向 更新时间 看房人数 0 其他区 新源街 2室1厅 50 5800 南 2017.07.21 26 1 其他区 澳洲康都 2室1厅 79 7800 东 2017.07.23 33 2 其他区 远见名苑 2室1厅 86 8000 东 2017.07.20 34 3 昌平区 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30 4 其他区 团结湖北口 2室1厅 63 6400 南 2017.07.26 30
4.3.2 df.apply()函数遍历每一行/列同时执行自定义函数
# 获取前5条数据
temp_df = df.head().copy()
print(temp_df)
def func1(s, arg1):# 此时s参数就是df中的一列数据, s对象# print('s的值是->', s)# print('s的类型是->', type(s))# 本自定义函数也必须返回一列数据, s对象# print(s.__dict__)if s._name == '价格':return s + arg1else:return s
# 默认遍历df每列, axis=0
print(temp_df.apply(func1, args=(1000,), axis=0))
def func2(s, arg1):# 此时s参数就是df中的一行数据, s对象# print('s的值是->', s)# print('s的类型是->', type(s))# 本自定义函数也必须返回一列数据, s对象# print(s.__dict__)if s['区域'] == '天通苑租房':# 修改价格对应的值s['价格'] = s['价格'] + arg1return selse:return s
# 遍历df每行, axis=1
print(temp_df.apply(func2, arg1=1000, axis=1))
# 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 6800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 8800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 9000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 6300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 7400 南 2017.07.26 30区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 6300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 304.3.3 df.applymap()函数遍历每一个值同时执行自定义函数
# 获取前5条数据
temp_df = df.head().copy()
print(temp_df)
# 自定义函数只能接收一个参数
def func(x):# 此时x参数就是df中的每个数据# print('x的值是->', x)# 本自定义函数也必须返回一个数据if x == '2室1厅':return '3室2厅'else:return x
print(temp_df.applymap(func))
# 输出结果如下区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 2室1厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 2室1厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 2室1厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 2室1厅 103 5300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 2室1厅 63 6400 南 2017.07.26 30区域 地址 户型 面积 价格 朝向 更新时间 看房人数
0 燕莎租房 新源街 3室2厅 50 5800 南 2017.07.21 26
1 望京租房 澳洲康都 3室2厅 79 7800 东 2017.07.23 33
2 广安门租房 远见名苑 3室2厅 86 8000 东 2017.07.20 34
3 天通苑租房 天通苑北一区 3室2厅 103 5300 东南 2017.07.25 30
4 团结湖租房 团结湖北口 3室2厅 63 6400 南 2017.07.26 30总结
请对下列API 有印象、能找到、能理解、能看懂
-
df['列名'] = 标量或向量修改或添加列 -
df.insert(列下标数字, 列名, 该列所有值)指定位置添加列 -
<df/s>.drop([索引值1, 索引值2, ...])根据索引删除行数据 -
df.drop([列名1, 列名2, ...], axis=1)根据列名删除列数据 -
<df/s>.drop_duplicates()df或s对象去除重复的行数据 -
s.unique()s对象去除重复的数据 -
<df/s>.replace('原数据', '新数据', inplace=True)替换数据-
df或series对象替换数据,返回的还是原来相同类型的对象,不会对原来的df造成修改
-
如果加上inplace=True参数,则会修改原始df
-
-
apply函数-
s.apply(自定义函数名, arg1=xx, ...)对s对象中的每一个值,都执行自定义函数,且该自定义函数除了固定接收每一个值作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ...)对df对象中的每一列,都执行自定义函数,且该自定义函数除了固定接收列对象作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ..., axis=1)对df对象中的每一行,都执行自定义函数,且该自定义函数除了固定接收行对象作为第一参数以外,还可以接收其他自定义参数
-
-
applymap函数-
df.applymap(自定义函数名)对df对象中的每个值, 都执行自定义函数, 且该自定义函数只能接收每个值作为参数, 不能接收其他自定义参数
-
相关文章:
python -- series和 DataFrame增删改数据
学习目标 知道df添加新列的操作 知道insert函数插入列数据 知道drop函数删除df的行或列数据 知道drop_duplicates函数对df或series进行数据去重 知道unique函数对series进行数据去重 知道apply函数的使用方法 1 DataFrame添加列 注意:本文用到的数据集在文章顶部 1.1 直…...
 清除定时器)
window.clearInterval(timer) 清除定时器
window.clearInterval(timer)是用来清除定时器的方法。在JavaScript中,使用定时器可以在指定的时间间隔执行一段代码。通常,使用setTimeout()方法可以在一定时间后执行一次代码,而使用setInterval()方法可以在每个时间间隔执行一次代码。 使…...
Java项目如何外发告警日志到企业微信
前言 最近领导交代了一个需求,就是有些许客户不单单满足平台告警日志外发到邮箱、短信的形式,还要以消息聊天的形式外发给企业微信。 具体操作 1、注册企业微信。 2、登录企业微信,找到应用管理,创建应用。 3、创建完之后需要记录以下图片中两个值的信息。 4、然后记录下…...

NLP--关键词
在去停用词后的文本中进行词频统计和关键词统计以及词云图显示,来进行文本的关键词提取,让人一目了然。 1.词频统计 统计文本中多次出现的词语,来寻找文章中的关键词,因为多次出现很可能就是关键内容。调用统计数量的Counter库和…...

Qt5学习笔记
一、基础知识 1、基本控件类型 水平弹簧与垂直弹簧的父类都是QSpaceItem。关于PushButton相关的控件类型: QPushButton:最基础的按钮类型。QToolButton:可以控制图片、文字任意组合的显示方式的按钮类型。QRadioButton:就像rad…...
数据结构与算法笔记:基础篇 - 散列表(下):为什么散列表和链表经常会一起使用?
概述 已经学习了这么多章节了,你有没有发现,两种数据结构,散列表和链表,经常会被放在一起使用。你还记得,前面的章节中都有哪些地方讲到散列表和链表的组合使用吗? 在链表那一节,我讲到如何用…...
读AI未来进行式笔记06自动驾驶技术
1. 跃层冲击 1.1. 每个社会其实都处于不同的楼层,往往处于更低楼层的社会,要承受来自更高楼层的社会发展带来的更大冲击 2. 驾驶 2.1. 开车时最关键的不是车,而是路 2.2. 人是比机器更脆弱的生命&am…...

SpringAOP 常见应用场景
文章目录 SpringAOP1 概念2 常见应用场景3 AOP的几种通知类型分别有什么常见的应用场景4 AOP实现 性能监控4.1 首先,定义一个切面类,用于实现性能监控逻辑:4.2 定义自定义注解4.3 注解修饰监控的方法 5 AOP实现 API调用统计5.1 定义切面类&am…...

html+css示例
HTML HTML(超文本标记语言)和CSS(层叠样式表)是构建和设计网页的两种主要技术。HTML用于创建网页的结构和内容,而CSS用于控制其外观和布局。 HTML基础 HTML使用标签来标记网页中的不同部分。每个标签通常有一个开始…...

Day51 动态规划part10+Day52 动态规划part11
LC121买卖股票的最佳时机(未掌握) 暴力:双层循环寻找最优间距,每一次都确定一个起点,遍历剩余节点当作终点 贪心:取最左最小值,不断遍历那么得到的差值最最大值就是最大利润。 动态规划 dp数组…...
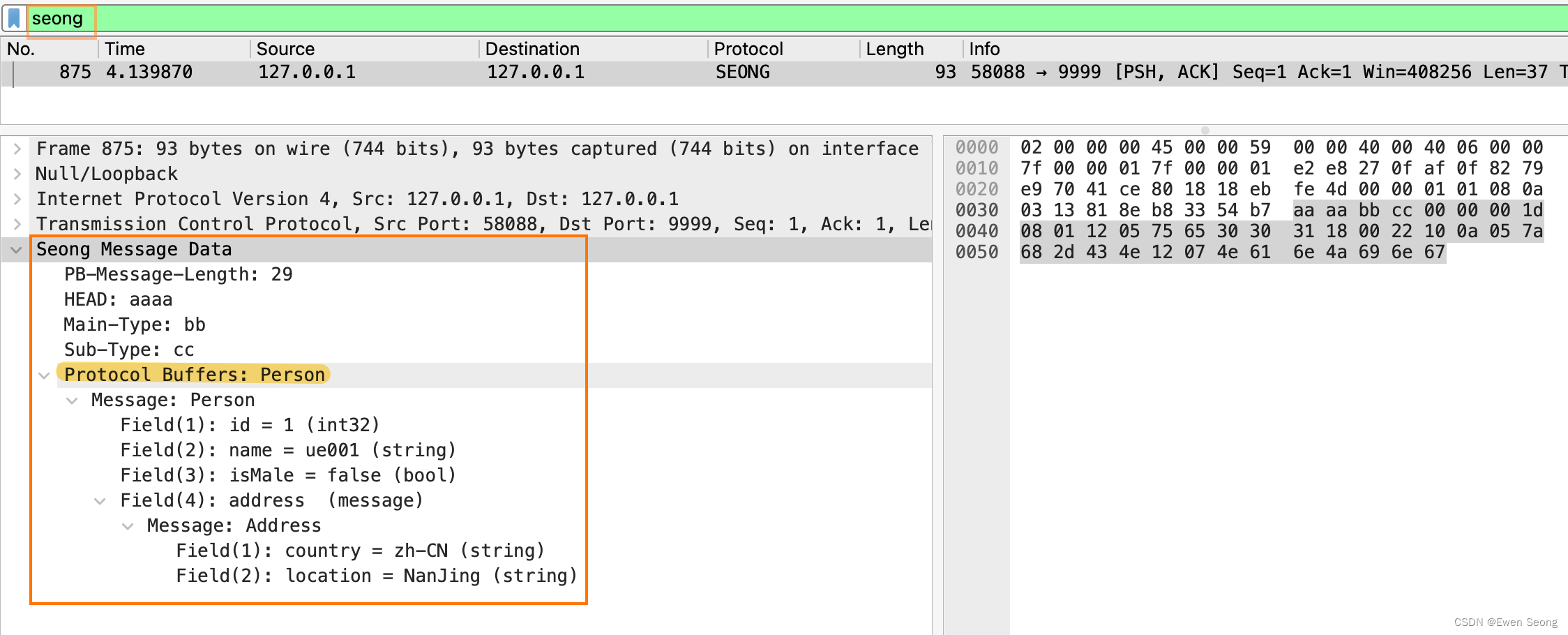
Wireshark自定义Lua插件
背景: 常见的抓包工具有tcpdump和wireshark,二者可基于网卡进行抓包:tcpdump用于Linux环境抓包,而wireshark用于windows环境。抓包后需借助包分析工具对数据进行解析,将不可读的二进制数转换为可读的数据结构。 wires…...

商城项目【尚品汇】07分布式锁-2 Redisson篇
文章目录 1 Redisson功能介绍2 Redisson在Springboot中快速入门(代码)2.1 导入依赖2.2 Redisson配置2.3 将自定义锁setnx换成Redisson实现(可重入锁) 3 可重入锁原理3.1 自定义分布式锁setnx为什么不可以重入3.2 redisson为什么可…...

Adobe Illustrator 矢量图设计软件下载安装,Illustrator 轻松创建各种矢量图形
Adobe Illustrator,它不仅仅是一个简单的图形编辑工具,更是一个拥有丰富功能和强大性能的设计利器。 在这款软件中,用户可以通过各种精心设计的工具,轻松创建和编辑基于矢量路径的图形文件。这些矢量图形不仅具有高度的可编辑性&a…...

Nvidia/算能 +FPGA+AI大算力边缘计算盒子:中国舰船研究院
中国舰船研究院又称中国船舶重工集团公司第七研究院,隶属于中国船舶重工集团公司,是专门从事舰船研究、设计、开发的科学技术研究机构,是中国船舶重工集团公司的军品技术研究中心、科技开发中心;主要从事舰船武器装备发展战略研究…...
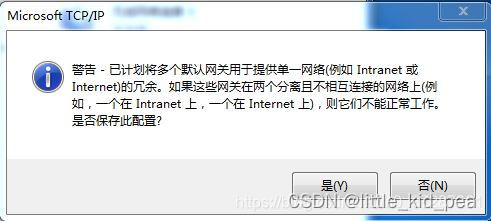
双网卡配置IP和路由总结
1.在网络适配器属性IPv4中设置默认网关(记网关地址为A),将会在本地路由表中新增一条记录: 网络号子网掩码网关地址0.0.0.00.0.0.0A 2.如果有两个网卡(假设一个连接内网,一个连接互联网)&#…...

【纯血鸿蒙】——自适应布局如何实现?
界面级一多能力有 2 类: 自适应布局: 略微调整界面结构 响应式布局:比较大的界面调整 本文章先主要讲解自适应布局,响应式布局再后面文章再细讲。话不多说,开始了。 自适应布局 针对常见的开发场景,方舟开发框架提…...

Qt5学习笔记(一):Qt Widgets Application项目初探
笔者长期使用MFC开发Windows GUI软件。随着软件向Linux平台迁移的趋势越发明朗,GUI程序的跨平台需求也越来越多。因此笔者计划重新抓一下Qt来实现跨平台GUI程序的实现。 0x01. 看看Qt Widgets Application项目结构 打开Qt5,点击“ New”按钮新建项目。…...

Linux网络编程:数据链路层协议
目录 前言: 1.以太网 1.1.以太网帧格式 1.2.MTU(最大传输单元) 1.2.1.IP协议和MTU 1.2.2.UDP协议和MTU 1.2.3.TCP协议和MTU 2.ARP协议(地址解析协议) 2.1.ARP在局域网通信的角色 2.2.ARP报文格式 2.3.ARP报文…...

企业估值的三种方法
估值模型三剑客—DCF、P/E、EV /EBITDA 三种主要估值模型的优缺点: DCF 优点:通过对自由现金流的折现计算,反映了公司内在价值的本质,是最重要与最合理的估值方法。 缺点:未来自由现金流的估计不准确,受折现率影响…...

比亚迪正式签约国际皮划艇联合会和中国皮划艇协会,助推龙舟入奥新阶段
6月5日,比亚迪与国际皮划艇联合会、中国皮划艇协会在深圳共同签署合作协议,国际皮划艇联合会主席托马斯科涅茨科,国际皮划艇联合会秘书长理查德派蒂特,中国皮划艇协会秘书长张茵,比亚迪品牌及公关处总经理李云飞&#…...

如何轻松解密Widevine加密视频:完整免费指南
如何轻松解密Widevine加密视频:完整免费指南 【免费下载链接】video_decrypter Decrypt video from a streaming site with MPEG-DASH Widevine DRM encryption. 项目地址: https://gitcode.com/gh_mirrors/vi/video_decrypter 还在为付费视频无法离线保存而…...

Wat完整使用教程:从基础语法到高级修饰符
Wat完整使用教程:从基础语法到高级修饰符 【免费下载链接】wat Deep inspection of Python objects 项目地址: https://gitcode.com/gh_mirrors/wat2/wat Wat是一款强大的Python对象深度检查工具,能帮助开发者快速获取任何Python对象的详细信息&a…...

009、NPU、TPU与硬件加速器在TinyML中的作用
009、NPU、TPU与硬件加速器在TinyML中的作用 去年冬天调试一个智能门锁的唤醒词模型,模型在PC上跑得飞起,量化后只有48KB,自信满满地烧进STM32F4。结果呢?唤醒延迟从预期的200ms直接飙到1.2秒,电池续航从三个月缩水到两周。拆开示波器一看,CPU在跑模型的时候几乎被占满,…...

Arm LCM安全架构与密钥管理实战解析
1. Arm LCM安全架构深度解析在嵌入式安全领域,生命周期管理(LCM)是确保设备从产线到报废全流程安全的核心机制。Arm LCM通过硬件状态机实现了一套完整的控制体系,其核心架构包含三个关键层级:1.1 硬件安全基础层OTP(One-Time Programmable)存…...

X-TRACK开源GPS自行车码表终极指南:从硬件组装到软件配置的完整教程
X-TRACK开源GPS自行车码表终极指南:从硬件组装到软件配置的完整教程 【免费下载链接】X-TRACK A GPS bicycle speedometer that supports offline maps and track recording 项目地址: https://gitcode.com/gh_mirrors/xt/X-TRACK X-TRACK是一款功能强大的开…...

05 - rocrtst 功能测试详解
本文档深入介绍 rocrtst 功能测试套件(suites/functional/)中的各个测试模块,帮助你理解每个测试验证的 HSA API 功能。 1. 功能测试概览 功能测试注册在 rocrtstFunc 测试套件下,共 26 个源码模块,涵盖 ROCr Runtim…...

别再用filter了!MATLAB bandpass函数一键搞定信号滤波,附音乐合成与降噪实战
别再用filter了!MATLAB bandpass函数一键搞定信号滤波,附音乐合成与降噪实战 信号处理工程师的日常,往往伴随着无数个深夜调试滤波器的痛苦回忆。从设计滤波器系数到手动补偿群延迟,再到反复调整截止频率,传统filter和…...

Tetgen网格剖分结果怎么看?.node/.ele/.face文件详解与在ParaView中的可视化
Tetgen网格剖分结果解析与ParaView可视化实战指南 当你第一次运行Tetgen并看到那些.node、.ele和.face文件时,可能会感到困惑——这些看似简单的文本文件如何转化为直观的三维网格?本文将带你深入理解这些文件的内部结构,掌握网格质量评估的关…...

LinkedOM与JSDOM性能对比:10倍速度提升的秘诀
LinkedOM与JSDOM性能对比:10倍速度提升的秘诀 【免费下载链接】linkedom A triple-linked lists based DOM implementation. 项目地址: https://gitcode.com/gh_mirrors/li/linkedom 在现代Web开发中,DOM解析和操作性能直接影响应用响应速度。Lin…...

终极Visual C++运行库修复指南:一劳永逸解决Windows软件兼容性问题
终极Visual C运行库修复指南:一劳永逸解决Windows软件兼容性问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库修复工具是解决Windo…...