spring源码解析-(2)Bean的包扫描
包扫描的过程
测试代码:
// 扫描指定包下的所有类
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 扫描指定包下的所有类
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry);
scanner.scan("com.test.entity");
for (String beanDefinitionName : registry.getBeanDefinitionNames()) {System.err.println(beanDefinitionName);
}
注意:下述源码在阅读时应尽量避免死磕,先梳理整体流程,理解其动作的含义,具体细节可以在看完整体之后再细致打磨。如果整个流程因为一些细节而卡住,那就丧失了看源码的意义,我们需要的是掌握流程和优秀的设计理念,而不是一字一句的抄下来。
scan方法详解
源码如下:翻译通过CodeGeeX进行自动生成并自己进行修改。
public int scan(String... basePackages) {// 获取扫描开始时的BeanDefinition数量int beanCountAtScanStart = this.registry.getBeanDefinitionCount();// 执行扫描doScan(basePackages);// 如果需要,注册注解配置处理器if (this.includeAnnotationConfig) {AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);}// 返回扫描结束时的BeanDefinition数量与扫描开始时的数量之差return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
通过上面的代码,我们可以看到核心的方法为doScan,具体源码如下:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {// 确保至少传入一个基础包Assert.notEmpty(basePackages, "At least one base package must be specified");// 创建一个存放BeanDefinitionHolder的集合Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();for (String basePackage : basePackages) {// 1找出候选的组件Set<BeanDefinition> candidates = findCandidateComponents(basePackage);// 遍历候选的组件for (BeanDefinition candidate : candidates) {// 解析组件的作用域元数据ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);// 设置组件的作用域candidate.setScope(scopeMetadata.getScopeName());// 2生成组件的名称String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);// 如果候选的组件是抽象BeanDefinition的实例if (candidate instanceof AbstractBeanDefinition) {// 执行后处理器,对候选的组件进行处理postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}// 如果候选的组件是带有注解的BeanDefinition的实例if (candidate instanceof AnnotatedBeanDefinition) {// 3处理带有注解的BeanDefinition的公共定义AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}// 如果检查候选的组件if (checkCandidate(beanName, candidate)) {// 创建一个BeanDefinitionHolder,并将其添加到集合中BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);// 应用代理模式definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);// 将BeanDefinition注册到容器中registerBeanDefinition(definitionHolder, this.registry);}}}// 返回存放BeanDefinitionHolder的集合return beanDefinitions;
}
现在我们一步步的使用debug查看整个doScan的大体过程
1. 通过传入的路径扫描并得到对应的BeanDefinition
截取的部分代码片段如下:
for (String basePackage : basePackages) {// 找出候选的组件Set<BeanDefinition> candidates = findCandidateComponents(basePackage);// other
}
findCandidateComponents方法的源码:
从 Spring 5.0 开始新增了一个 @Indexed 注解(新特性,@Component 注解上面就添加了 @Indexed 注解), 这里不会去扫描指定路径下的 .class 文件,而是读取所有 META-INF/spring.components 文件中符合条件的类名,直接添加 .class 后缀就是编译文件,而不要去扫描。
public Set<BeanDefinition> findCandidateComponents(String basePackage) {// 如果componentsIndex不为空,并且indexSupportsIncludeFilters()为trueif (this.componentsIndex != null && indexSupportsIncludeFilters()) {// 从componentsIndex中添加候选组件return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);}// 否则else {// 扫描候选组件return scanCandidateComponents(basePackage);}
}
我们着重看scanCandidateComponents方法,源码如下:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {// 创建一个LinkedHashSet,用于存储扫描到的候选组件Set<BeanDefinition> candidates = new LinkedHashSet<>();try {// 1.1拼接包搜索路径String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;// 1.2获取资源Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);// 判断是否开启日志记录boolean traceEnabled = logger.isTraceEnabled();boolean debugEnabled = logger.isDebugEnabled();for (Resource resource : resources) {if (traceEnabled) {logger.trace("Scanning " + resource);}try {// 1.3获取元数据读取器MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);// 判断是否是候选组件if (isCandidateComponent(metadataReader)) {// 1.4创建一个ScannedGenericBeanDefinition,用于存储元数据读取器ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);// 判断是否是候选组件if (isCandidateComponent(sbd)) {if (debugEnabled) {logger.debug("Identified candidate component class: " + resource);}// 将候选组件添加到candidates中candidates.add(sbd);} else {if (debugEnabled) {logger.debug("Ignored because not a concrete top-level class: " + resource);}}} else {if (traceEnabled) {logger.trace("Ignored because not matching any filter: " + resource);}}} catch (FileNotFoundException ex) {if (traceEnabled) {logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());}} catch (Throwable ex) {throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);}}} catch (IOException ex) {throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);}return candidates;
}
1.1 拼接搜索路径
源码如下:
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;
简单的字符串拼接,其代码本身没有任何技术含量,但debug的时候,可以通过其显示的值来帮助我们更好的理解项目。

debug的结果为:classpath*:com/test/entity/**/*.class
可以看到,是从根路径的com.test.enetity下开始寻找所有的字节码文件。
1.2 根据包扫描路径获取资源
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
具体方法:
public Resource[] getResources(String locationPattern) throws IOException {// 断言locationPattern不能为空Assert.notNull(locationPattern, "Location pattern must not be null");// 如果locationPattern以CLASSPATH_ALL_URL_PREFIX开头if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {// 是一个类路径资源(同一个名称可能存在多个资源)if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {// 是一个类路径资源模式return findPathMatchingResources(locationPattern);}else {// 所有具有给定名称的类路径资源return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));}}else {// 通常只在后缀前加上前缀,// 并且在Tomcat中,只有在“war:”协议下,才会使用“*/”分隔符。int prefixEnd = (locationPattern.startsWith("war:") ? locationPattern.indexOf("*/") + 1 :locationPattern.indexOf(':') + 1);if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {// 是一个文件模式return findPathMatchingResources(locationPattern);}else {// 具有给定名称的单个资源return new Resource[] {getResourceLoader().getResource(locationPattern)};}}
}
接着我们进入到findPathMatchingResources的方法中,具体源码如下:
protected Resource[] findPathMatchingResources(String locationPattern) throws IOException {// 确定根目录路径String rootDirPath = determineRootDir(locationPattern);// 获取locationPattern中根目录路径之后的部分String subPattern = locationPattern.substring(rootDirPath.length());// 获取根目录资源Resource[] rootDirResources = getResources(rootDirPath);// 创建一个LinkedHashSet集合Set<Resource> result = new LinkedHashSet<>(16);// 遍历根目录资源for (Resource rootDirResource : rootDirResources) {// 解析根目录资源rootDirResource = resolveRootDirResource(rootDirResource);// 获取根目录资源的URLURL rootDirUrl = rootDirResource.getURL();// 如果存在equinoxResolveMethod且根目录URL的协议以"bundle"开头if (equinoxResolveMethod != null && rootDirUrl.getProtocol().startsWith("bundle")) {// 调用equinoxResolveMethod方法,获取解析后的URLURL resolvedUrl = (URL) ReflectionUtils.invokeMethod(equinoxResolveMethod, null, rootDirUrl);// 如果解析后的URL不为空if (resolvedUrl != null) {// 将解析后的URL赋值给rootDirUrlrootDirUrl = resolvedUrl;}// 将解析后的URL封装为ResourcerootDirResource = new UrlResource(rootDirUrl);}// 如果根目录URL的协议以"vfs"开头if (rootDirUrl.getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {// 调用VfsResourceMatchingDelegate的findMatchingResources方法,获取匹配的资源result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirUrl, subPattern, getPathMatcher()));}// 如果根目录URL是jar文件或者根目录资源是jar资源else if (ResourceUtils.isJarURL(rootDirUrl) || isJarResource(rootDirResource)) {// 调用doFindPathMatchingJarResources方法,获取匹配的jar资源result.addAll(doFindPathMatchingJarResources(rootDirResource, rootDirUrl, subPattern));}// 否则else {// 调用doFindPathMatchingFileResources方法,获取匹配的文件资源result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));}}// 如果存在日志日志功能if (logger.isTraceEnabled()) {// 打印日志logger.trace("Resolved location pattern [" + locationPattern + "] to resources " + result);}// 返回结果return result.toArray(new Resource[0]);
}
1.3 获取元数据
源码:可以看到通过1.2中获取到的资源将通过如下方法获取一个名为MetadataReader的对象,那么这个元数据读取器究竟是干什么的?
// getMetadataReaderFactory工厂模式构建MetadataReader
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
MetadataReader接口中只定义了三个方法,源码如下:
public interface MetadataReader {Resource getResource();ClassMetadata getClassMetadata();AnnotationMetadata getAnnotationMetadata();
}
根据debug追随到的源码,发现其进入到了MetadataReader的实现类SimpleMetadataReader中,其构造器如下:
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {// 这里使用到了经典的访问者模式,可以自行了解一下SimpleAnnotationMetadataReadingVisitor visitor = new SimpleAnnotationMetadataReadingVisitor(classLoader);getClassReader(resource).accept(visitor, PARSING_OPTIONS);this.resource = resource;this.annotationMetadata = visitor.getMetadata();
}
感兴趣的可以着重看下getClassReader(resource).accept(visitor, PARSING_OPTIONS);这句话中大概做了那些事情。
具体源码就不展示,这里大概就是将class文件读取并操作二进制代码。(可以通过《深入了解Java虚拟机》这本书来了解一下java的字节码相关内容)
1.4 创建ScannedGenericBeanDefinition
通过构造器的方式将MetadataReader中读取到的内容放入BeanDefinition中。
public ScannedGenericBeanDefinition(MetadataReader metadataReader) {Assert.notNull(metadataReader, "MetadataReader must not be null");this.metadata = metadataReader.getAnnotationMetadata();setBeanClassName(this.metadata.getClassName());setResource(metadataReader.getResource());
}
2. 获取Bean的名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
我们可以看一下spring是如何获取bean的名称的
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {if (definition instanceof AnnotatedBeanDefinition) {String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);if (StringUtils.hasText(beanName)) {// Explicit bean name found.return beanName;}}// Fallback: generate a unique default bean name.return buildDefaultBeanName(definition, registry);
}
可以看到该方法是有两个分支,如果通过注解中可以拿到名字,则直接返回,具体方法如下:
// 确定基于注解的bean名称
protected String determineBeanNameFromAnnotation(AnnotatedBeanDefinition annotatedDef) {// 获取注解的元数据AnnotationMetadata amd = annotatedDef.getMetadata();// 获取注解的类型Set<String> types = amd.getAnnotationTypes();// 初始化bean名称String beanName = null;// 遍历注解类型for (String type : types) {// 获取注解的属性AnnotationAttributes attributes = AnnotationConfigUtils.attributesFor(amd, type);if (attributes != null) {// 获取注解的元注解类型Set<String> metaTypes = this.metaAnnotationTypesCache.computeIfAbsent(type, key -> {Set<String> result = amd.getMetaAnnotationTypes(key);return (result.isEmpty() ? Collections.emptySet() : result);});// 判断注解是否为stereotype注解,并且包含name和value属性if (isStereotypeWithNameValue(type, metaTypes, attributes)) {// 获取name属性的值Object value = attributes.get("value");if (value instanceof String) {String strVal = (String) value;// 判断字符串长度是否大于0if (StringUtils.hasLength(strVal)) {// 判断beanName是否为空,或者与strVal不相等if (beanName != null && !strVal.equals(beanName)) {// 抛出异常throw new IllegalStateException("Stereotype annotations suggest inconsistent " +"component names: '" + beanName + "' versus '" + strVal + "'");}// 更新beanNamebeanName = strVal;}}}}}return beanName;
}
或者,根据类的class直接创建名称,代码如下:
protected String buildDefaultBeanName(BeanDefinition definition) {// 获取bean的类名String beanClassName = definition.getBeanClassName();// 断言bean的类名不能为空Assert.state(beanClassName != null, "No bean class name set");// 获取bean的简短名称String shortClassName = ClassUtils.getShortName(beanClassName);// 将简短名称的首字母转换为小写return Introspector.decapitalize(shortClassName);
}
3. 处理带有注解的BeanDefinition的公共定义
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
在此方法中,我们可以了解到,注册为Bean的类上可以添加的注解有几种,代码如下:
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);if (lazy != null) {abd.setLazyInit(lazy.getBoolean("value"));}else if (abd.getMetadata() != metadata) {lazy = attributesFor(abd.getMetadata(), Lazy.class);if (lazy != null) {abd.setLazyInit(lazy.getBoolean("value"));}}if (metadata.isAnnotated(Primary.class.getName())) {abd.setPrimary(true);}AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);if (dependsOn != null) {abd.setDependsOn(dependsOn.getStringArray("value"));}AnnotationAttributes role = attributesFor(metadata, Role.class);if (role != null) {abd.setRole(role.getNumber("value").intValue());}AnnotationAttributes description = attributesFor(metadata, Description.class);if (description != null) {abd.setDescription(description.getString("value"));}
}
4 将定义好的BeanDefinition放入set,并返回set。
if (checkCandidate(beanName, candidate)) {// 创建一个BeanDefinitionHolder,并将其添加到集合中BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);// 应用代理模式definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);// 将BeanDefinition注册到容器中registerBeanDefinition(definitionHolder, this.registry);
}
思考总结:
1、可以看到,在spring中使用了很多设计模式,设计模式在解决一系列问题上非常有帮助,如创建Bean的Bean工厂,访问并根据字节码操作的访问者模式,需要理解其思想,在遇到问题的时候,往设计模式上想一想。后续可能要深入的学习一下设计模式。
2、关于数据类型的使用,其实本人在实际开发的过程中大部分时间都使用list,Map,其中也遇到过很多次内存溢出,在合理的选择数据类型上,有必要仔细斟酌。
相关文章:
spring源码解析-(2)Bean的包扫描
包扫描的过程 测试代码: // 扫描指定包下的所有类 BeanDefinitionRegistry registry new SimpleBeanDefinitionRegistry(); // 扫描指定包下的所有类 ClassPathBeanDefinitionScanner scanner new ClassPathBeanDefinitionScanner(registry); scanner.scan(&quo…...

Java 数学计算 - Random类
在Java中,Random类用于生成伪随机数。这个类在java.util包中,你可以使用它来生成整数、浮点数等不同类型的随机数。以下是关于Random类的一些学习笔记和示例。 1. 创建Random对象 首先,你需要创建一个Random对象。默认情况下,如…...

Ubuntu22.04之解决:无法关机和重启问题(二百四十三)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
大学数字媒体艺术设计网页设计试题及答案,分享几个实用搜题和学习工具 #媒体#职场发展
现在读书可不像小时候,以前想要校对试题答案,都得找到对应的纸质版答案查看,而且有的还只有答案,没有解析,无法弄清楚答案的由来。但是现在不一样了,现在我们可以通过搜题软件,寻找试题的答案&a…...

【ArcGIS微课1000例】0119:TIFF与grid格式互相转换
文章目录 一、任务描述二、tiff转grid三、grid转tif四、注意事项一、任务描述 地理栅格数据常用TIFF格式和GRID格式进行存储。TIFF格式的栅格数据常以单文件形式存储,不仅存储有R、G、B三波段的像素值,还保存有地理坐标信息。GRID格式的栅格数据常以多文件的形式进行存储,且…...

B3870 [GESP202309 四级] 变长编码
[GESP202309 四级] 变长编码 题目描述 小明刚刚学习了三种整数编码方式:原码、反码、补码,并了解到计算机存储整数通常使用补码。但他总是觉得,生活中很少用到 2 31 − 1 2^{31}-1 231−1 这么大的数,生活中常用的 0 ∼ 100 0…...
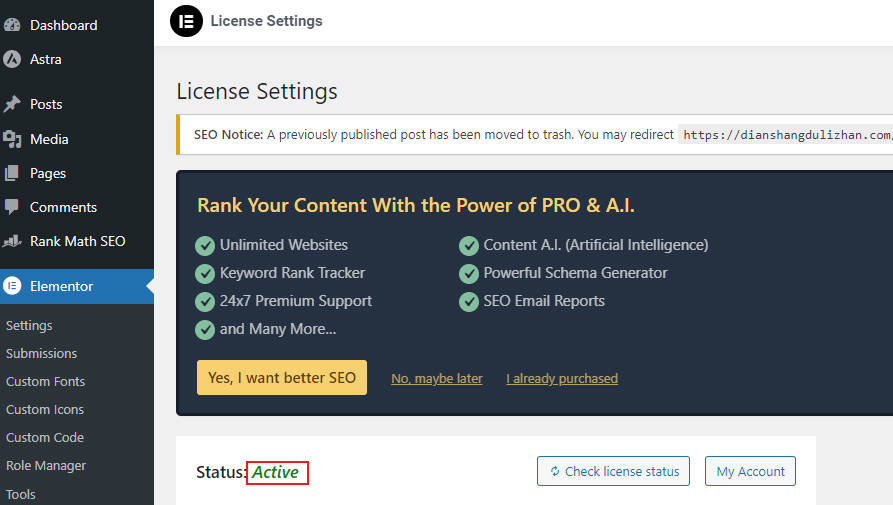
WordPress网站更换域名后如何重新激活elementor
在创建WordPress网站时,我们常常需要更改域名。但是,在更换域名后,你可能会遇到一个问题:WordPress后台中的Elementor插件授权状态会显示为不匹配。这时,就需要重新激活Elementor插件的授权。下面我会详细说明如何操作…...

linux cron 执行url
linux cron 执行url 在Linux中,你可以使用curl或wget来执行URL。如果你想要定期执行这个操作,可以使用cron来设置定时任务。 以下是一个使用curl在cron中执行URL的例子: 打开终端。 输入 crontab -e 命令来编辑你的cron作业。 添加一个新…...
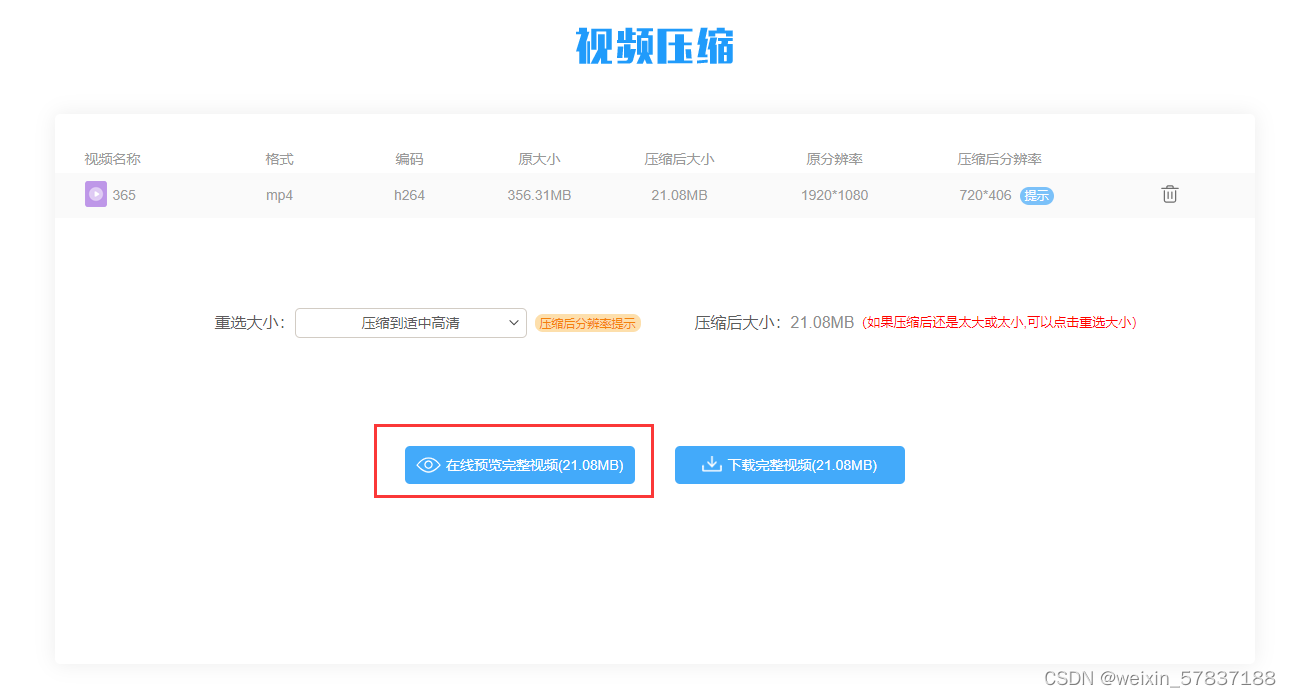
压缩视频在线压缩网站,压缩视频在线压缩工具软件
在数字化时代,视频成为了人们记录和分享生活的重要载体。然而,视频文件一般都非常大,这不仅占据了大量的存储空间,也给视频的传输和分享带来了不便。因此,压缩视频成为了许多人必须掌握的技能。本文将详细介绍如何压缩…...

linux经典例题编程
编写Shell脚本,计算1~100的和 首先vi 1.sh,创建一个名为1.sh的脚本,然后赋予这个脚本权限,使用命令chmod 755 1.sh,然后就可以在脚本中写程序,然后运行。 shell脚本内容 运行结果: 编写Shell脚本…...
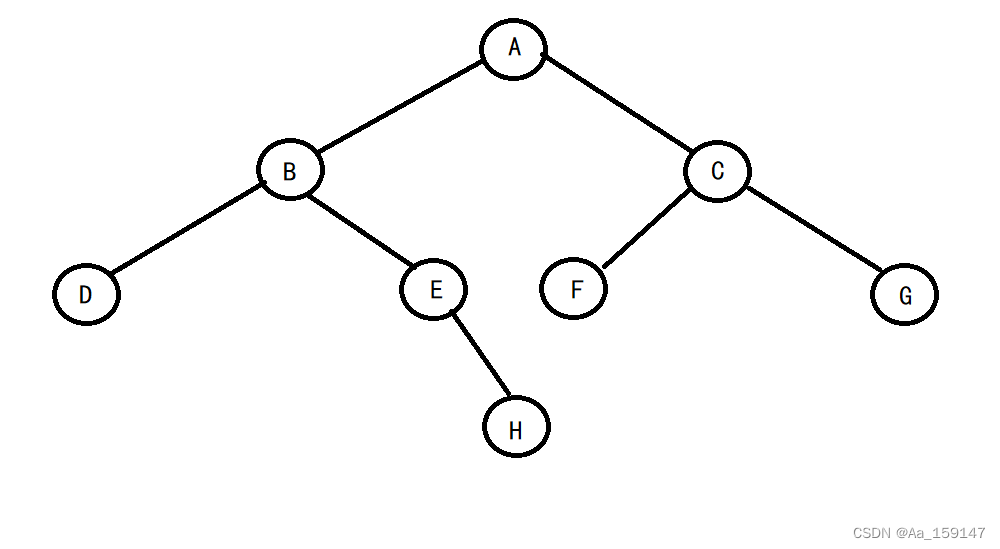
二叉树的实现(初阶数据结构)
1.二叉树的概念及结构 1.1 概念 一棵二叉树是结点的一个有限集合,该集合: 1.或者为空 2.由一个根结点加上两棵别称为左子树和右子树的二叉树组成 从上图可以看出: 1.二叉树不存在度大于2的结点 2.二叉树的子树有左右之分,次序不能…...
C++笔试强训day41
目录 1.棋子翻转 2.宵暗的妖怪 3.过桥 1.棋子翻转 链接https://www.nowcoder.com/practice/a8c89dc768c84ec29cbf9ca065e3f6b4?tpId128&tqId33769&ru/exam/oj (简单题)对题意进行简单模拟即可: class Solution { public:int dx[…...
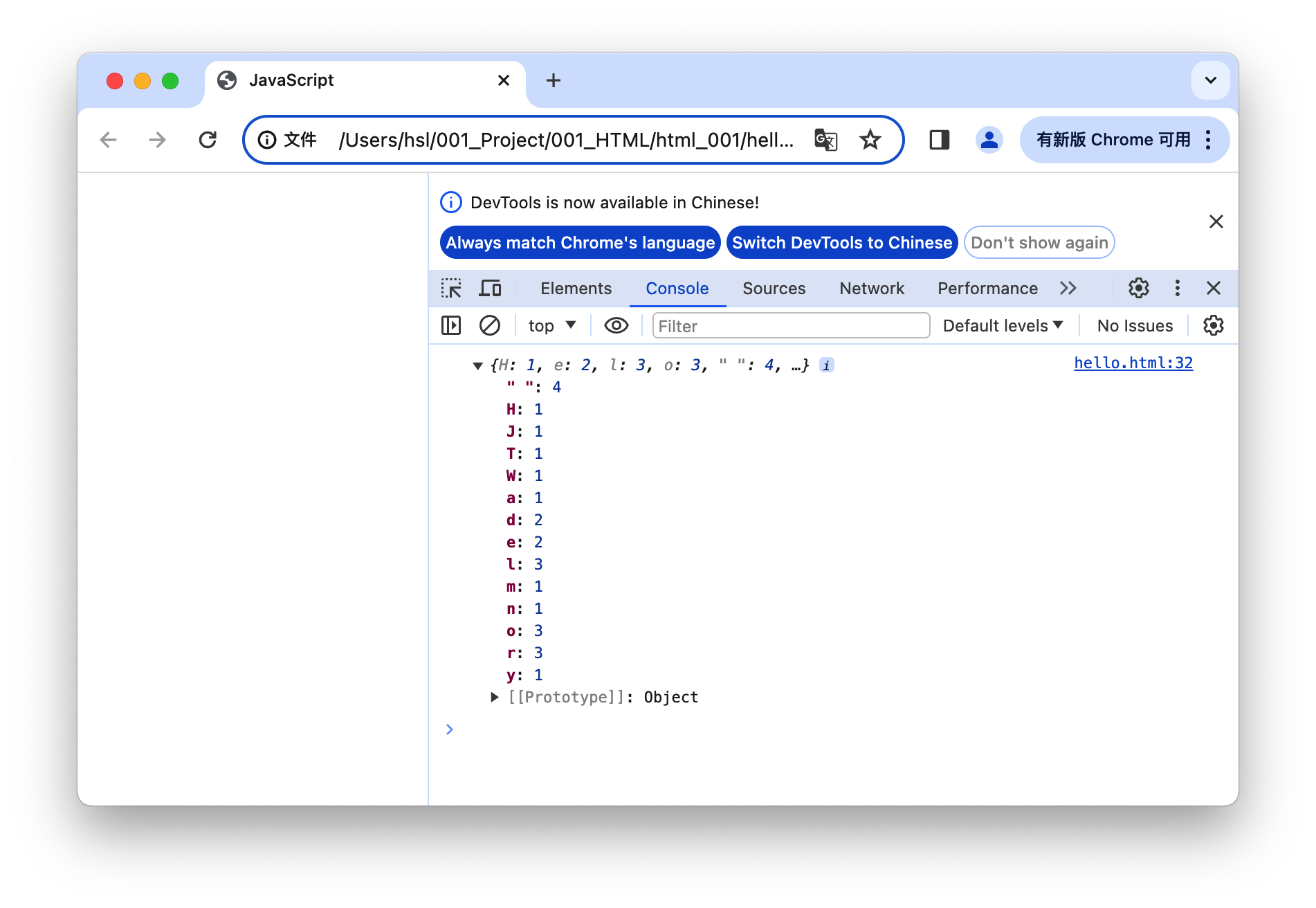
【JavaScript】内置对象 - 字符串对象 ⑤ ( 判断对象中是否有某个属性 | 统计字符串中每个字符出现的次数 )
文章目录 一、判断对象中是否有某个属性1、获取对象属性2、判定对象是否有某个属性 二、统计字符串中每个字符出现的次数1、算法分析2、代码示例 String 字符串对象参考文档 : https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String 一、判…...

Linux环境下测试服务器的DDR5内存性能
要在Linux环境下测试服务器的DDR5内存性能,可以采用以下几种方法和工具: ### 测试原理 内存性能测试主要关注以下几个关键指标: - **带宽**:内存每秒能传输的数据量。 - **延迟**:内存访问请求从发出到完成所需的时间…...

19、matlab信号预处理中的中值滤波(medfilt1()函数)和萨维茨基-戈雷滤波滤(sgolayfilt()函数)
1、中值滤波:medfilt1()函数 说明:一维中值滤波 1)语法 语法1:y medfilt1(x) 将输入向量x应用3阶一维中值滤波器。 语法2:y medfilt1(x,n) 将一个n阶一维中值滤波器应用于x。 语法3:y medfilt1(x,n…...
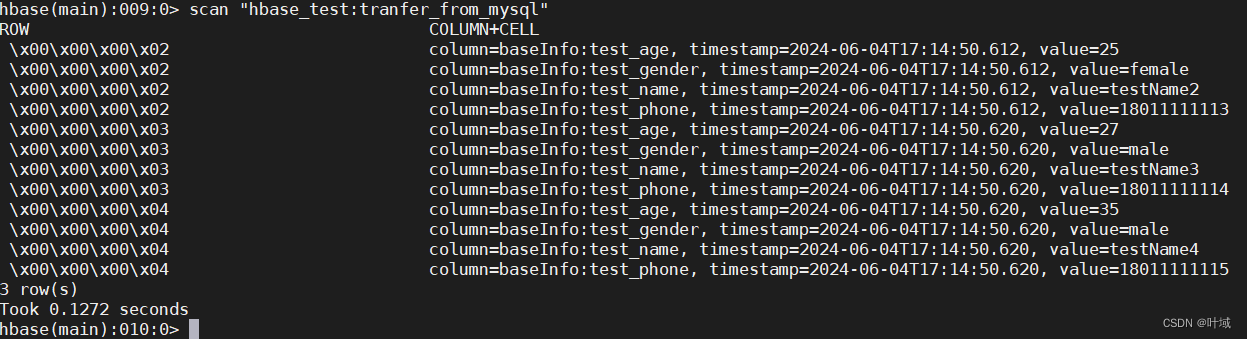
Scala 练习一 将Mysql表数据导入HBase
Scala 练习一 将Mysql表数据导入HBase 续第一篇:Java代码将Mysql表数据导入HBase表 源码仓库地址:https://gitee.com/leaf-domain/data-to-hbase 一、整体介绍二、依赖三、测试结果四、源码 一、整体介绍 HBase特质 连接HBase, 创建HBase执行对象 初始化…...

前端工程化:基于Vue.js 3.0的设计与实践
这里写目录标题 《前端工程化:基于Vue.js 3.0的设计与实践》书籍引言本书概述主要内容作者简介为什么选择这本书?结语 《前端工程化:基于Vue.js 3.0的设计与实践》书籍 够买连接—>https://item.jd.com/13952512.html 引言 在前端技术日…...
Linux☞进程控制
在终端执行命令时,Linux会建立进程,程序执行完,进程会被终止;Linux是一个多任务的OS,允许多个进程并发运行; Linxu中启动进程的两种途径: ①手动启动(前台进程(命令gedit)...后台进程(命令‘&’)) ②…...

mybatis离谱bug乱转类型
字符串传入的参数被转成了int: Param("online") String online<if test"online 0">and (heart_time is null or heart_time <![CDATA[ < ]]> UNIX_TIMESTAMP(SUBDATE(now(),INTERVAL 8 MINUTE)) )</if><if test"…...

视频监控管理平台LntonCVS视频汇聚平台充电桩视频监控应用方案
随着新能源汽车的广泛使用,公众对充电设施的安全性和可靠性日益重视。为了提高充电桩的安全管理和站点运营效率,LntonCVS公司推出了一套全面的新能源汽车充电桩视频监控与管理解决方案。 该方案通过安装高分辨率摄像头,对充电桩及其周边区域进…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...