Postgresql源码(135)生成执行计划——Var的调整set_plan_references
1 总结
- set_plan_references主要有两个功能:
- 拉平:生成拉平后的RTE列表(add_rtes_to_flat_rtable)。
- 调整:调整前每一层计划中varno的引用都是相对于本层RTE的偏移量。放在一个整体计划后,需要指向一个统一的RTE列表,所以需要把varno调整下指向拉平后的RTE表。
- 例如下面计划中,RTE记录了6张表:
- 1 → `{rtekind = RTE_RELATION, relid = 16656, inh = false, relkind = 114 ‘r’} -> student
- 2 → `{rtekind = RTE_RELATION, relid = 16671, inh = false, relkind = 114 ‘r’} -> score
- 3 → `{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0 } -> {score join student}
- 4 → `{rtekind = RTE_RELATION, relid = 16661, inh = false, relkind = 114 ‘r’} -> course
- 5 → `{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0 } -> {被优化掉的join course}
- Result节点的第一列是STUDENT.sname,他的varno一开始是1,varattno是2,显然他不应该直接引用RTE中的某一张表,因为Result节点的数据应该使用下面SORT节点中取出来的,所以:
- varno被调整为-2(表示引用OUTTER节点也就是LEFT树返回的结果)
- varattno被调整1,表示从结果中拿第一列。
explain
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY STUDENT.sno;QUERY PLAN
------------------------------------------------------------------------------------Result (cost=182.67..213.27 rows=2040 width=54)-> Sort (cost=182.67..187.77 rows=2040 width=46)Sort Key: student.sno-> Hash Right Join (cost=34.75..70.53 rows=2040 width=46)Hash Cond: (score.sno = student.sno)-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=12)-> Hash (cost=21.00..21.00 rows=1100 width=42)-> Seq Scan on student (cost=0.00..21.00 rows=1100 width=42)
上面用例经过set_plan_references调整前后的完整例子:

2 数据结构
PlannerInfo
当前查询优化的状态,包含了当前查询的所有信息:
- 当前查询的目标列表(target list)
- 子句(例如,WHERE、GROUP BY、ORDER BY 等)
- 范围表(range table)
- 可用的索引信息
- 统计信息
- 子查询和参数信息
- 优化器的各种临时数据和结果
PlannerGlobal
全局结构,包含了跨多个查询级别的信息。例如一个包含子查询或CTE的查询中,每个子查询都会有自己的 PlannerInfo结构,会共享同一个PlannerGlobal。包含了:
- 全局范围表(finalrtable)
- 全局子计划列表
- 全局初始化计划列表
- 全局参数表达式列表
- 重写规则和其他全局状态信息
varno宏
#define INNER_VAR (-1) /* reference to inner subplan */
#define OUTER_VAR (-2) /* reference to outer subplan */
#define INDEX_VAR (-3) /* reference to index column */
#define ROWID_VAR (-4) /* row identity column during planning */
3 set_plan_references
1 计算全局flat_rtable
set_plan_references → add_rtes_to_flat_rtable
首先把引用的rtable全部拉平到一个级别,重新排列RTE。
具体在PlannerGlobal中构造全局范围表finalrtable,所有子PlannerInfo共享的一套RTE。
p *root->glob->finalrtable
$7 = {type = T_List, length = 5, max_length = 5, elements = 0x3085520, initial_elements = 0x3085520}
add_rtes_to_flat_rtable后生成五个RTE:
- RangeTblEntry
{rtekind = RTE_RELATION, relid = 16656, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_RELATION, relid = 16671, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0} - RangeTblEntry
{rtekind = RTE_RELATION, relid = 16661, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0}
PlannerInfo→PlannerGlobal:
2 开始修正RTE的引用
set_plan_references → set_plan_refs
2.1 处理Result
-
set_plan_refs
- →
case T_Result:… 处理result子树 - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
-
根据内层的sort节点,重新排列result节点的三个var的varno和varattno,result已经是最外层节点了,当前使用到的var还是从sort节点继承的,需要修复下。
处理前 vs 处理后
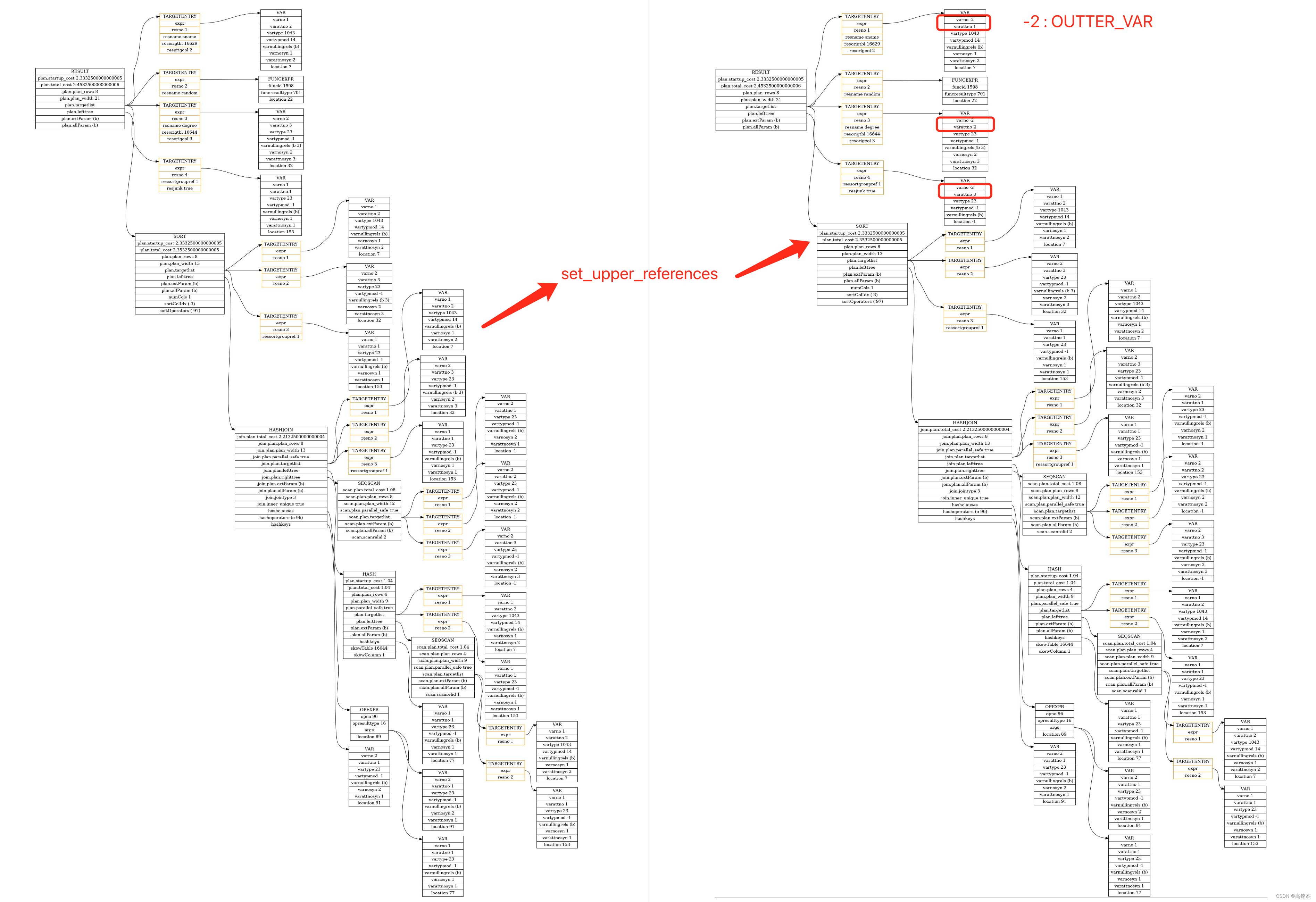
set_plan_refs处理T_Result节点:
set_plan_refs......case T_Result:Result *splan = (Result *) plan;if (splan->plan.lefttree != NULL)set_upper_references(root, plan, rtoffset);......// subplan 是 SORT节点// subplan->targetlist 中返回三列:STUDENT.sname, SCORE.degree, STUDENT.sno// 注意缺了一列random函数subplan_itlist = build_tlist_index(subplan->targetlist);
- subplan->targetlist
varno = 1, varattno = 2, vartype = 1043varno = 2, varattno = 3, vartype = 23varno = 1, varattno = 1, vartype = 23
- subplan_itlist
subplan_itlist->tlist = subplan->targetlistsubplan_itlist->vars[0] = {varno = 1, varattno = 2, resno = 1, varnullingrels = 0x0}subplan_itlist->vars[1] = {varno = 2, varattno = 3, resno = 2, varnullingrels = ...}subplan_itlist->vars[2] = {varno = 1, varattno = 1, resno = 3, varnullingrels = 0x0}
foreach(l, plan->targetlist)...newexpr = fix_upper_expr(...)...// 计算完成plan->targetlist = output_targetlist;
- output_targetlist
expr = 0x308f0c8, resno = 1, resname = 0x2f4d670 "sname"varno = OUTER_VAR = -2, varattno = 1, vartype = 1043
expr = 0x308f1b8, resno = 2, resname = 0x2f4d7e8 "random"funcid = 1598, funcresulttype = 701, funcretset = false
expr = 0x308f258, resno = 3, resname = 0x2f4d928 "degree"varno = OUTER_VAR = -2, varattno = 2, vartype = 23
expr = 0x308f2f8, resno = 4, resname = 0x0, ressortgroupref = 1varno = OUTER_VAR = -2, varattno = 3, vartype = 23
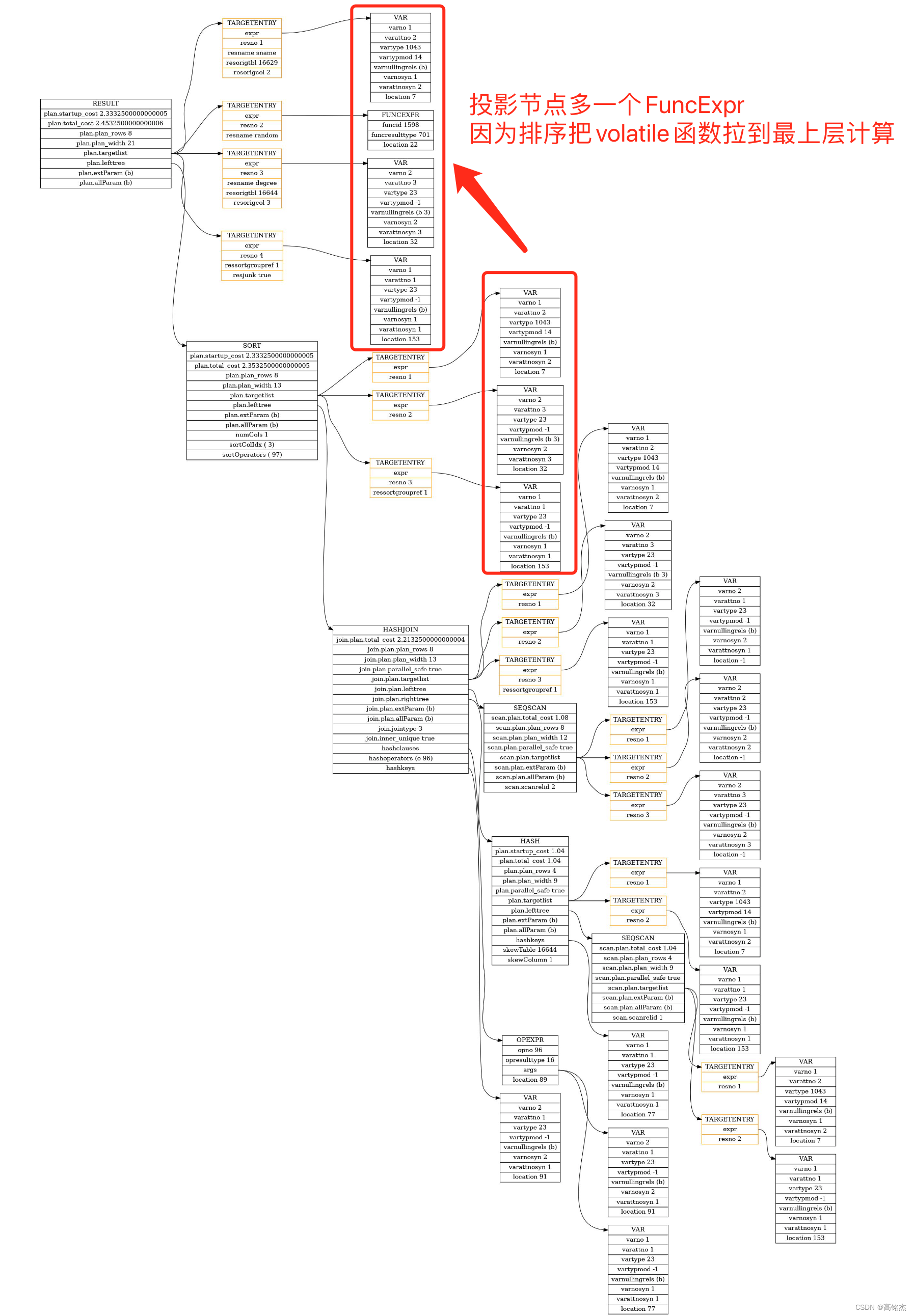
2.2 处理SORT
- set_plan_refs
- →
case T_Sort:… 处理sort子树set_dummy_tlist_references - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
排序只需要引用下面一层的结果即可。
// These plan types don't actually bother to evaluate their
// targetlists, because they just return their unmodified input
// tuples. Even though the targetlist won't be used by the
// executor, we fix it up for possible use by EXPLAIN (not to
// mention ease of debugging --- wrong varnos are very confusing).set_dummy_tlist_references
2.3 处理Hash Right Join
- set_plan_refs
- →
case T_HashJoin:… 处理join子树set_join_references - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
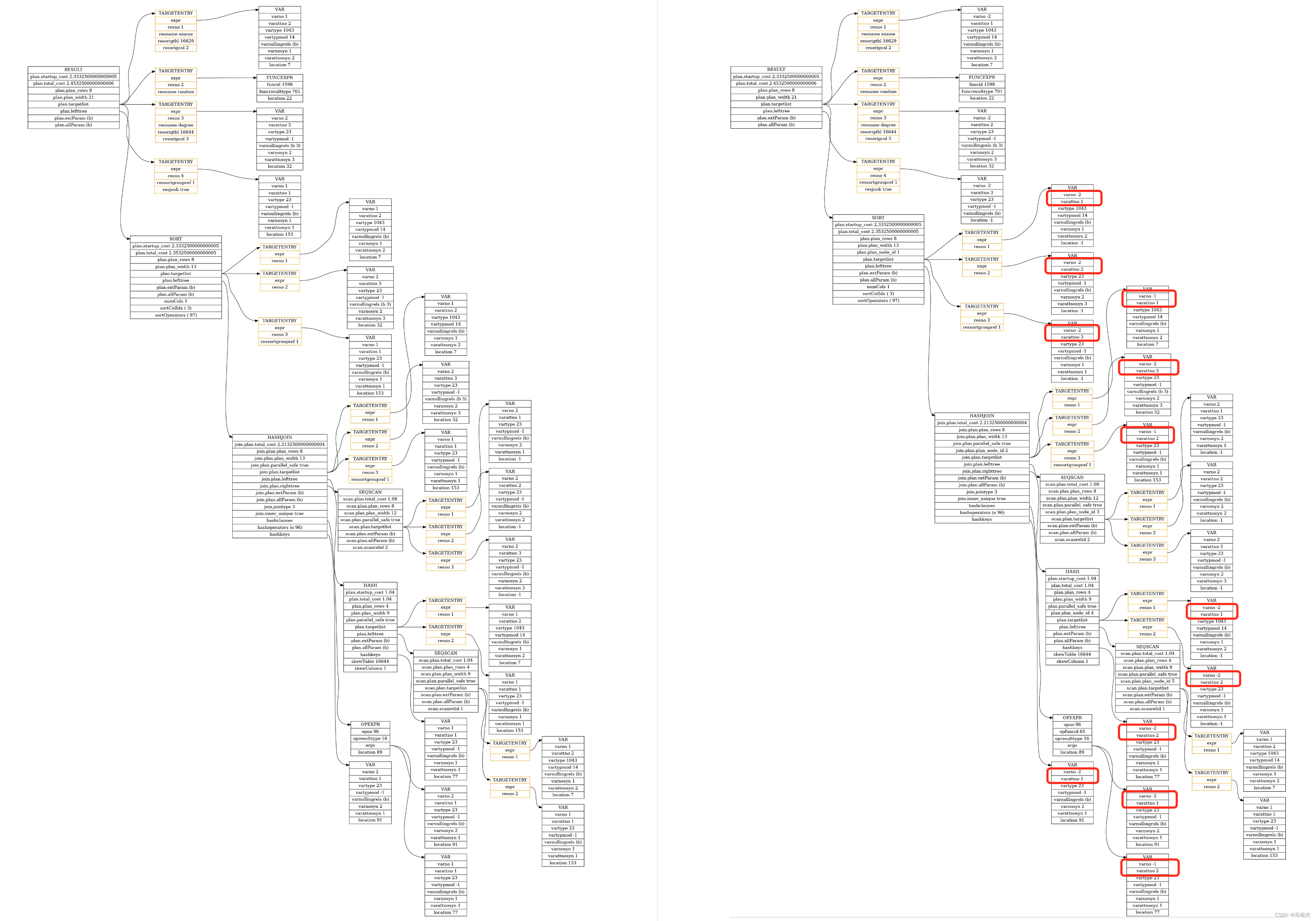
4 用例
explain
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY STUDENT.sno;QUERY PLAN
------------------------------------------------------------------------------------Result (cost=182.67..213.27 rows=2040 width=54)-> Sort (cost=182.67..187.77 rows=2040 width=46)Sort Key: student.sno-> Hash Right Join (cost=34.75..70.53 rows=2040 width=46)Hash Cond: (score.sno = student.sno)-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=12)-> Hash (cost=21.00..21.00 rows=1100 width=42)-> Seq Scan on student (cost=0.00..21.00 rows=1100 width=42)
相关文章:
Postgresql源码(135)生成执行计划——Var的调整set_plan_references
1 总结 set_plan_references主要有两个功能: 拉平:生成拉平后的RTE列表(add_rtes_to_flat_rtable)。调整:调整前每一层计划中varno的引用都是相对于本层RTE的偏移量。放在一个整体计划后,需要指向一个统一…...

Python魔法之旅专栏(导航)
目录 推荐阅读 1、Python筑基之旅 2、Python函数之旅 3、Python算法之旅 4、博客个人主页 首先,感谢老铁们一直以来对我的支持与厚爱,让我能坚持把Python魔法方法专栏更新完毕! 其次,为了方便大家查阅,我将此专栏…...
Python第二语言(五、Python文件相关操作)
目录 1. 文件编码的概念 2. 文件的读取操作 2.1 什么是文件 2.2 open()打开函数 2.3 mode常用的三种基础访问模式 2.4 文件操作及案例 3. 文件的写入操作及刷新文件:write与flush 4. 文件的追加操作 5. 文件操作的综合案例(文件备份操作&#x…...
)
Vue3 组合式 API:依赖注入(四)
provide() provide() 函数是用于依赖注入的一个关键部分。这个函数允许你在组件树中提供一个值或对象,使得任何子组件(无论层级多深)都能够通过 inject() 函数来访问这些值。 import { provide, ref } from vue; export default { setup(…...

Vue如何引入ElementUI并使用
Element UI详细介绍 Element UI是一个基于Vue 2.0的桌面端组件库,旨在构建简洁、快速的用户界面。由饿了么前端团队开发,提供丰富的组件和工具,帮助开发者快速构建高质量的Vue应用,并且以开放源代码的形式提供。 1. VueElementU…...
VS2019 QT无法打开 源 文件 “QTcpSocket“
VS2019 QT无法打开 源 文件 "QTcpSocket" QT5.15.2_msvc2019_64 严重性 代码 说明 项目 文件 行 禁止显示状态 错误(活动) E1696 无法打开 源 文件 "QTcpSocket" auto_pack_line_demo D:\vs_qt_project\auto_pack_line_de…...
【Golang】Map 稳定有序遍历的实现与探索:保序遍历之道
【Golang】Map 稳定有序遍历的实现与探索:保序遍历之道 大家好 我是寸铁👊 总结了一篇【Golang】Map 稳定有序遍历的实现与探索:保序遍历之道✨ 喜欢的小伙伴可以点点关注 💝 前言🍎 在计算机科学中,数据结…...

使用Nextjs学习(学习+项目完整版本)
创建项目 运行如下命令 npx create-next-app next-create创建项目中出现的各种提示直接走默认的就行,一直回车就行了 创建完成后进入到项目运行localhost:3000访问页面,如果和我下面页面一样就是创建项目成功了 整理项目 将app/globals.css里面的样式都删除,只留下最上面三…...

KUKA机器人KRC5控制柜面板LED显示
对于KUKA机器人新系列控制柜KRC5控制柜来说,其控制柜面板LED布局如下图: 其中①②③④分别为: 1、机器人控制柜处于不同状态时,LED显示如下: 2、机器人控制柜正在运行时: 3、机器人控制柜运行时出现的故障…...

为什么选择Python作为AI开发语言
为什么Python适合AI 在当前的科技浪潮中,人工智能(AI)无疑是最热门的话题之一。无论是自动驾驶、智能推荐还是自然语言处理,AI都在不断改变我们的生活。而在这场技术革命中,Python作为主要的编程语言之一,…...

【算法篇】求最长公共前缀JavaScript版本
题目描述 给你一个大小为 n 的字符串数组 strs ,其中包含n个字符串 , 编写一个函数来查找字符串数组中的最长公共前缀,返回这个公共前缀。 数据范围: 数据范围:0<n<5000,0<len(strsi)< 5000 进阶:空间复杂度 O(1)&a…...
搭建RocketMQ主从异步集群
搭建RocketMQ主从异步集群 1、RocketMQ集群模式 为了追求更好的性能,RocketMQ的最佳实践方式都是在集群模式下完成的。RocketMQ官方提供了三种集群搭建方式: 2主2从异步通信方式:使用异步方式进行主从之间的数据复制。吞吐量大,…...

最大子段和问题
最大子段和问题 分数 15 全屏浏览 切换布局 作者 王东 单位 贵州师范学院 最大子段和问题。给定由n个整数组成的序列,求序列中子段的最大和,若所有整数均为负整数时定义最大子段和为0。 输入格式: 第一行输入整数个数n(1≤n≤1000&…...
Vue3中的常见组件通信之mitt
Vue3中的常见组件通信之mitt 概述 在vue3中常见的组件通信有props、mitt、v-model、 r e f s 、 refs、 refs、parent、provide、inject、pinia、slot等。不同的组件关系用不同的传递方式。常见的撘配形式如下表所示。 组件关系传递方式父传子1. props2. v-model3. $refs…...
MySQL快速入门(极简)
SQL 介绍及 MySQL 安装 一、实验简介 本课程为实验楼提供的 MySQL 实验教程,所有的步骤都在实验楼在线实验环境中完成,学习中请按照实验步骤依次操作。 本课程为 SQL 基本语法及 MySQL 基本操作的实验,理论内容较少,动手实践多…...

CentOS7安装NVIDIA显卡驱动指引【笔记】
CentOS7安装NVIDIA显卡驱动指引【笔记】 实践设备:华硕FX-PRO(NVIDIA GeForce GTX 960M) 环境准备: 1、将系统安装到设备上正常运行; 2、设备网络调试,可以正常访问外网; 3、配置ssh服务(非必要,根据实际情况)。 说明: 本文档所提供的指引和参考主要基于特定实践…...
【RabbitMQ】RabbitMQ配置与交换机学习
【RabbitMQ】RabbitMQ配置与交换机学习 文章目录 【RabbitMQ】RabbitMQ配置与交换机学习简介安装和部署1. 安装RabbitMQ2.创建virtual-host3. 添加依赖4.修改配置文件 WorkQueues模型1.编写消息发送测试类2.编写消息接收(监听)类3. 实现能者多劳 交换机F…...

常见排序算法,快排,希尔,归并,堆排
后面的排序中都要用到的函数 //交换 void Swap(int* p1, int* p2) {int* tmp *p1;*p1 *p2;*p2 tmp; } 包含的头文件 "Sort.h" #pragma once #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<time.h> #include<s…...
)
语法的时态1——一般现在时(1)
定义:一般现在时用来表示经常发生的动作,以及客观事实。 一般现在时的构成以及标志词 1.一般现在时的结构 (1)主系表结构 构成:主语be(am,is,ear)其他。属于状态句。 I…...
JAVA:在IDEA引入本地jar包的方法并解决打包scope为system时发布无法打包进lib的方案
一.引入本地Jar包的步骤 有时maven依耐的包是本地的jar包,此时需要进行以下步骤设置。 步骤1.在pom.xml中添加插件设置,将system范围包含进来,此设置是为了在打包时,本地jar包自动生成到部署包里。(若无法打进包,请参考下文的方…...

51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址
51单片机内存空间全解析:从data、xdata到far,手把手教你用Keil C51访问任意地址 在嵌入式开发领域,51单片机因其经典架构和广泛的应用基础,依然是许多工程师入门的首选。然而,当开发者从简单的GPIO控制进阶到复杂的内存…...

基于Next.js与Prisma构建宠物社区应用:全栈开发实战解析
1. 项目概述:一个为宠物爱好者打造的社区应用最近在GitHub上闲逛,发现了一个挺有意思的开源项目,叫jtsang4/happypaw。光看名字,“Happy Paw”(快乐的爪子),就能猜到这八成是和宠物相关的。点进…...

Easydict:基于Raycast的智能翻译与查词插件,提升开发效率
1. 项目概述:一个为效率而生的翻译与查词工具如果你和我一样,是个常年和外语资料打交道的程序员、学生或研究者,那么“查词”和“翻译”这两件事,大概率是你工作流里最频繁、也最容易被中断的环节。传统的操作路径是什么ÿ…...

为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法 Gemini 生成的技术文档常被诟病为“语法正确但语义失焦”——术语堆砌、逻辑断层、人机语感割裂。根本原因在于模…...

线束工程化实践:从设计到测试的自动化工具链与开源资源
1. 项目概述:从“Awesome”清单到工程化实践在开源世界里,“Awesome”系列清单就像一个个精心整理的藏宝图,指引着开发者们快速找到某个领域内的优质资源。今天要聊的这个项目fastbeast2023-netizen/awesome-harness-engineering,…...

不同CFD网格建模软件-动网格-自适应网格划分技术-课程推荐。
不同CFD网格建模软件-动网格-自适应网格划分技术-课程推荐。 数值模拟网格生成技术-01课程概览_哔哩哔哩_bilibili...

AI编程助手实战指南:从GitHub Copilot到全流程开发效率提升
1. 项目概述:当AI遇见编码的“氛围感”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫Sunil6512/awesome-ai-vibe-coding。光看名字,awesome-ai-vibe-coding,就透着一股子新潮味儿。它不是一个具体的工具或者框架&am…...

Cursor AI 编程助手配置优化:一键安装与自定义指南
1. 项目概述:为什么需要一套现成的 Cursor 配置?如果你和我一样,是 Cursor 的重度用户,那么你肯定经历过这样的阶段:刚上手时,觉得这个 AI 驱动的 IDE 简直是神器,但随着项目越来越复杂…...

非确定有限自动机—计算机等级考试—软件设计师考前备忘录—东方仙盟
1. 先明确:圆圈里的数字是什么?圆圈里的 0,1,2,3,4,5 是状态编号,不是输入符号,也不是要识别的字符串内容。比如 状态0 是起始状态,状态5 是终止(接受)状态。箭头边上的 0,1,ε 才是输入符号&am…...

绩效考核的量化迷思:如何衡量不可直接测量的技术贡献
一、量化绩效考核的困境:软件测试的“隐形”价值在软件行业的绩效考核体系中,量化指标似乎成了“公平”与“高效”的代名词。代码行数、Bug数量、测试用例覆盖率……这些清晰可统计的数字,被当作衡量技术人员贡献的核心标尺。然而,…...