深度学习必备知识——模型数据集Yolo与Voc格式文件相互转化
在深度学习中,第一步要做的往往就是处理数据集,尤其是学习百度飞桨PaddlePaddle的小伙伴,数据集经常要用Voc格式的,比如性能突出的ppyolo等模型。所以学会数据集转化的本领是十分必要的。这篇博客就带你一起进行Yolo与Voc格式的相互转化,附详细代码!
文章目录
- YOLO数据集介绍
- VOC数据集介绍
- Yolo转VOC
- VOC转Yolo
- from lxml import etree
- classes=["ball"]
YOLO数据集介绍
Yolo数据集主要是txt文件,一般包括train文件夹和val文件夹,每一个文件夹下有与图片同名的txt文件,基本结构如下:

|–image
- ||–train
- ||–val
|–label
- ||–train
- ||–val
txt的标签如下图所示:
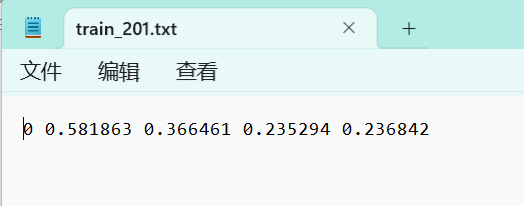
第一列为目标类别,后面四个数字为方框左上角与右下角的坐标,可以看到都是小于1的数字,是因为对应的整张图片的比例,所以就算图像被拉伸放缩,这种txt格式的标签也可以找到相应的目标。
VOC数据集介绍
VOC格式数据集一般有着如下的目录结构:
VOC_ROOT #根目录├── JPEGImages # 存放源图片│ ├── aaaa.jpg │ ├── bbbb.jpg │ └── cccc.jpg├── Annotations # 存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等│ ├── aaaa.xml │ ├── bbbb.xml │ └── cccc.xml └── ImageSets └── Main├── train.txt # txt文件中每一行包含一个图片的名称└── val.txt其中JPEGImages目录中存放的是源图片的数据,(当然图片并不一定要是.jpg格式的,只是规定文件夹名字叫JPEGImages);Annotations目录中存放的是标注数据,VOC的标注是xml格式的,文件名与JPEGImages中的图片一一对应。
重点看下xml格式的标注格式:
<annotation><folder>VOC_ROOT</folder> <filename>aaaa.jpg</filename> # 文件名<size> # 图像尺寸(长宽以及通道数) <width>500</width><height>332</height><depth>3</depth></size><segmented>1</segmented> # 是否用于分割(在图像物体识别中无所谓)<object> # 检测到的物体<name>horse</name> # 物体类别<pose>Unspecified</pose> # 拍摄角度,如果是自己的数据集就Unspecified<truncated>0</truncated> # 是否被截断(0表示完整)<difficult>0</difficult> # 目标是否难以识别(0表示容易识别)<bndbox> # bounding-box(包含左下角和右上角xy坐标)<xmin>100</xmin><ymin>96</ymin><xmax>355</xmax><ymax>324</ymax></bndbox></object><object> # 检测到多个物体<name>person</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>198</xmin><ymin>58</ymin><xmax>286</xmax><ymax>197</ymax></bndbox></object>
</annotation>
Yolo转VOC
文件结构如下:
Yolo转VOC #根目录├── dataset │ ├── Annotations │ ├── image └──image图像│ └── label└──txt文件├── Yolo转VOC.py # 代码文件具体代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@Project :Yolo与VOC转化
@File :Yolo转Voc.py
@IDE :PyCharm
@Author :咋
@Date :2023/3/6 16:45
"""
from xml.dom.minidom import Document
import os
import cv2# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件"""dic = {'0': "blue", # 创建字典用来对类型进行转换'1': "red", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致}files = os.listdir(txtPath)for i, name in enumerate(files):xmlBuilder = Document()annotation = xmlBuilder.createElement("annotation") # 创建annotation标签xmlBuilder.appendChild(annotation)txtFile = open(txtPath + name)txtList = txtFile.readlines()img = cv2.imread(picPath + name[0:-4] + ".jpg")Pheight, Pwidth, Pdepth = img.shapefolder = xmlBuilder.createElement("folder") # folder标签foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")folder.appendChild(foldercontent)annotation.appendChild(folder) # folder标签结束filename = xmlBuilder.createElement("filename") # filename标签filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")filename.appendChild(filenamecontent)annotation.appendChild(filename) # filename标签结束size = xmlBuilder.createElement("size") # size标签width = xmlBuilder.createElement("width") # size子标签widthwidthcontent = xmlBuilder.createTextNode(str(Pwidth))width.appendChild(widthcontent)size.appendChild(width) # size子标签width结束height = xmlBuilder.createElement("height") # size子标签heightheightcontent = xmlBuilder.createTextNode(str(Pheight))height.appendChild(heightcontent)size.appendChild(height) # size子标签height结束depth = xmlBuilder.createElement("depth") # size子标签depthdepthcontent = xmlBuilder.createTextNode(str(Pdepth))depth.appendChild(depthcontent)size.appendChild(depth) # size子标签depth结束annotation.appendChild(size) # size标签结束for j in txtList:oneline = j.strip().split(" ")object = xmlBuilder.createElement("object") # object 标签picname = xmlBuilder.createElement("name") # name标签namecontent = xmlBuilder.createTextNode(dic[oneline[0]])picname.appendChild(namecontent)object.appendChild(picname) # name标签结束pose = xmlBuilder.createElement("pose") # pose标签posecontent = xmlBuilder.createTextNode("Unspecified")pose.appendChild(posecontent)object.appendChild(pose) # pose标签结束truncated = xmlBuilder.createElement("truncated") # truncated标签truncatedContent = xmlBuilder.createTextNode("0")truncated.appendChild(truncatedContent)object.appendChild(truncated) # truncated标签结束difficult = xmlBuilder.createElement("difficult") # difficult标签difficultcontent = xmlBuilder.createTextNode("0")difficult.appendChild(difficultcontent)object.appendChild(difficult) # difficult标签结束bndbox = xmlBuilder.createElement("bndbox") # bndbox标签xmin = xmlBuilder.createElement("xmin") # xmin标签mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)xminContent = xmlBuilder.createTextNode(str(mathData))xmin.appendChild(xminContent)bndbox.appendChild(xmin) # xmin标签结束ymin = xmlBuilder.createElement("ymin") # ymin标签mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)yminContent = xmlBuilder.createTextNode(str(mathData))ymin.appendChild(yminContent)bndbox.appendChild(ymin) # ymin标签结束xmax = xmlBuilder.createElement("xmax") # xmax标签mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)xmaxContent = xmlBuilder.createTextNode(str(mathData))xmax.appendChild(xmaxContent)bndbox.appendChild(xmax) # xmax标签结束ymax = xmlBuilder.createElement("ymax") # ymax标签mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)ymaxContent = xmlBuilder.createTextNode(str(mathData))ymax.appendChild(ymaxContent)bndbox.appendChild(ymax) # ymax标签结束object.appendChild(bndbox) # bndbox标签结束annotation.appendChild(object) # object标签结束f = open(xmlPath + name[0:-4] + ".xml", 'w')xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')f.close()if __name__ == "__main__":picPath = "dataset/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上txtPath = "dataset/YOLOLables/" # txt所在文件夹路径,后面的/一定要带上xmlPath = "dataset/annotations/" # xml文件保存路径,后面的/一定要带上makexml(picPath, txtPath, xmlPath)VOC转Yolo
相当于上述操作的逆运算,这里直接给出代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
from lxml import etree
#自己的类别
classes = [“0”, “1”,‘2’,‘3’,‘person’]
classes=[“ball”]
TRAIN_RATIO = 80 #训练集比例
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith(“._”):
os.remove(abspath)
else:
clear_hidden_files(abspath)
#数据转换
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
#编写格式
def convert_annotation(image_id):
in_file = open(‘./dataset/annotations/%s.xml’ % image_id)
out_file = open(‘./dataset/YOLOLabels/%s.txt’ % image_id, ‘w’)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find(‘size’)
w = int(size.find(‘width’).text)
h = int(size.find(‘height’).text)
for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
#创建上述目录结构
wd = os.getcwd()
work_sapce_dir = os.path.join(wd, “dataset/”)
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, “annotations/”)
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, “JPEGImages/”)
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, “YOLOLabels/”)
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(work_sapce_dir, “images/”)
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(work_sapce_dir, “labels/”)
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, “train/”)
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, “val/”)
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, “train/”)
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, “val/”)
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
#创建两个记录照片名字的文件
train_file = open(os.path.join(yolov5_images_dir, “yolov5_train.txt”), ‘w’)
test_file = open(os.path.join(yolov5_images_dir, “yolov5_val.txt”), ‘w’)
train_file.close()
test_file.close()
train_file = open(os.path.join(yolov5_images_dir, “yolov5_train.txt”), ‘a’)
test_file = open(os.path.join(yolov5_images_dir, “yolov5_val.txt”), ‘a’)
#随机划分
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print(“Probability: %d” % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + ‘.xml’
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + ‘.txt’
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print(“Probability: %d” % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + ‘\n’)
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + ‘\n’)
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
相关文章:
深度学习必备知识——模型数据集Yolo与Voc格式文件相互转化
在深度学习中,第一步要做的往往就是处理数据集,尤其是学习百度飞桨PaddlePaddle的小伙伴,数据集经常要用Voc格式的,比如性能突出的ppyolo等模型。所以学会数据集转化的本领是十分必要的。这篇博客就带你一起进行Yolo与Voc格式的相互转化&…...

数据、数据资源及数据资产管理的区别
整理不易,转发请注明出处,请勿直接剽窃! 点赞、关注、不迷路! 摘要:数据、数据资源、数据资产 数据、数据资源及数据资产的区别 举例 CRM系统建设完成后会有很多数据,这些数据就是原始数据,业务…...
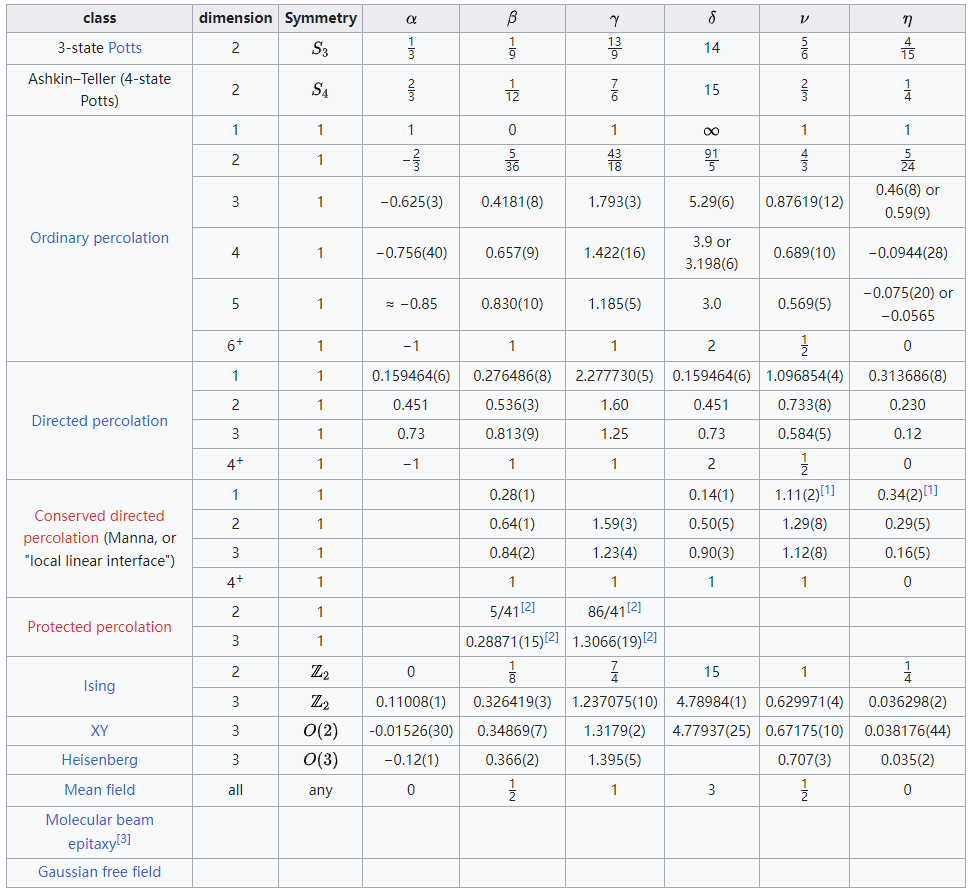
标度不变性(scale invariance)与无标度(scale-free)概念辨析
文章目录标度标度种类名义标度序级标度等距标度比率标度常用标度方法不足标度不变性标度不变(Scale-invariant)曲线和自相似性(self-similarity)射影几何分形随机过程中的标度不变性标度不变的 Tweedie distribution普适性&#x…...

WMS仓库管理系统解决方案,实现仓库管理一体化
仓库是企业的核心环节,若没有对库存的合理控制和送货,将会造成成本的上升,服务品质的难以得到保证,进而降低企业的竞争能力。WMS仓库管理系统包括基本信息,标签,入库,上架,领料&…...

css常见定位、居中方案_css定位居中
一、 定位分类 1、静态定位 position:static;(默认,具备标准流条件) 2、相对定位 position:relative; 通过 top 或者 bottom 来设置 Y 轴位置 通过 left 或者 right 来设置 X 轴位置 特点: 相对定位不会脱离文档流相对于自…...

【微信小程序】-- 自定义组件 -- 创建与引用 样式(三十二)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...
ArangoDB——AQL编辑器
AQL 编辑器 ArangoDB 的查询语言称为 AQL。AQL与关系数据库管理系统 (RDBMS)区别在于其更像一种编程语言,更自然地适合无模式模型,并使查询语言非常强大,同时保持易于读写。数据建模概念 数据库是集合的集合。集合存储记录,称为文…...
Lesson 9.1 集成学习的三大关键领域、Bagging 方法的基本思想和 RandomForestRegressor 的实现
文章目录一、 集成学习的三大关键领域二、Bagging 方法的基本思想三、RandomForestRegressor 的实现在开始学习之前,先导入我们需要的库,并查看库的版本。 import numpy as np import pandas as pd import sklearn import matplotlib as mlp import sea…...
basic1.0链码部署(基于test-network 环境ubuntu20.04腾讯云)
解决了官方示例指令需要科学上网才能运行的问题(通过手动下载二进制文件和拉取官方fabric-samples)。具体的将bootstrap.sh脚本解读了一遍 具体可以参照我的博客 fabric中bootstrap.sh到底帮助我们干了什么?(curl -sSL https://bi…...

Android---系统启动流程
目录 Android 系统启动流程 init 进程分析 init.rc 解析 Zygote 概叙 Zygote 触发过程 Zygote 启动过程 什么时Runtime? System Server 启动流程 Fork 函数 总结 面试题 Android 是 google 公司开发的一款基于 Linux 的开源操作系统。 Android 系统启动…...
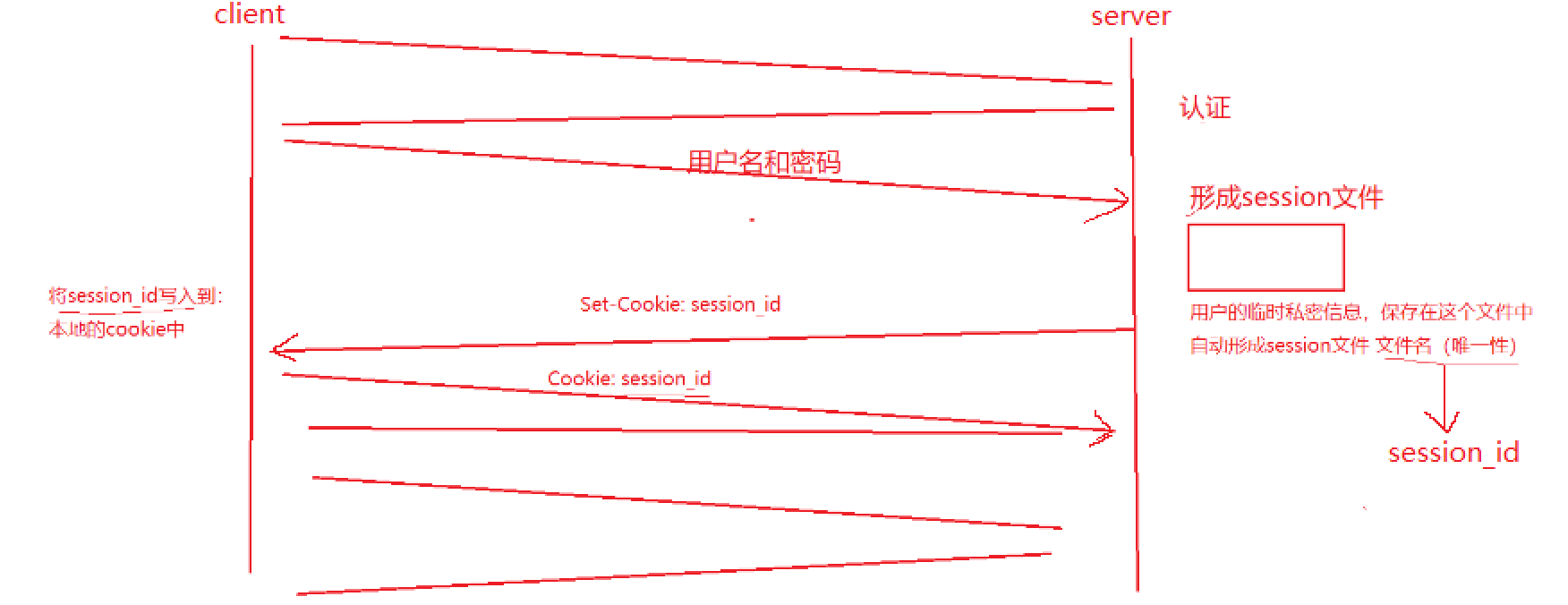
【网络】http协议
🥁作者: 华丞臧. 📕专栏:【网络】 各位读者老爷如果觉得博主写的不错,请诸位多多支持(点赞收藏关注)。如果有错误的地方,欢迎在评论区指出。 推荐一款刷题网站 👉 LeetCode刷题网站 文章…...
 什么意思? 如何中断线程?)
Thread::interrupted() 什么意思? 如何中断线程?
1、答: Thread::interrupted() 是一个静态方法,用于判断当前线程是否被中断,并清除中断标志位。 具体来说,当一个线程被中断后,它的中断状态将被设置为 true。如果在接下来的某个时间点内调用了该线程的 interrupted…...

Oracle OCP 19c 考试(1Z0-083)中关于Oracle不完全恢复的考点(文末附录像)
欢迎试看博主的专著《MySQL 8.0运维与优化》 下面是Oracle 19c OCP考试(1Z0-083)中关于Oracle不完全恢复的题目: A database is configured in ARCHIVELOG mode A full RMAN backup exists but no control file backup to trace has been taken A media…...
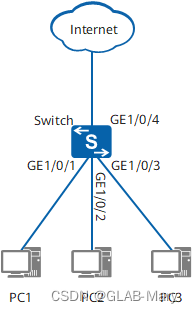
一起来学习配置Combo接口吧!
Combo接口是一个光电复用的逻辑接口,一个Combo接口对应设备面板上一个GE电接口和一个GE光接口。电接口与其对应的光接口是光电复用关系,两者不能同时工作(当激活其中一个接口时,另一个接口就自动处于禁用状态)…...
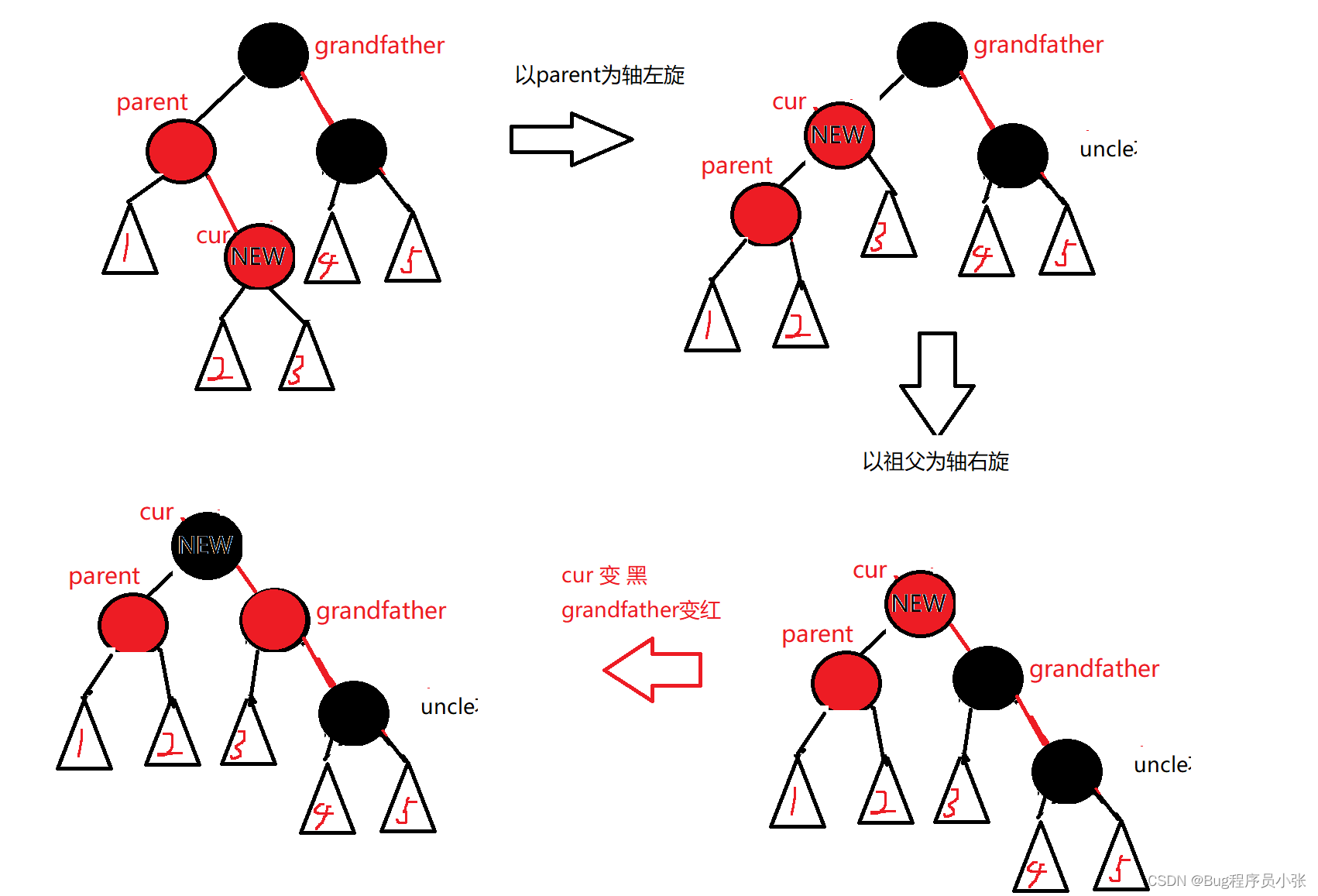
C++模拟实现红黑树
目录 介绍----什么是红黑树 甲鱼的臀部----规定 分析思考 绘图解析代码实现 节点部分 插入部分分步解析 ●父亲在祖父的左,叔叔在祖父的右: ●父亲在祖父的右,叔叔在祖父的左: 测试部分 整体代码 介绍----什么是红黑树 红…...

HTTPS协议之SSL/TLS详解(下)
目录 前言: SSL/TLS详解 HTTP协议传输安全性分析 对称加密 非对称加密 证书 小结: 前言: 在网络世界中,存在着运营商劫持和一些黑客的攻击。如果明文传输数据是很危险的操作,因为我们不清楚中间传输过程中就被哪…...
OLE对象是什么?为什么要在CAD图形中插入OLE对象?
OLE对象是什么?OLE对象的意思是指对象连接与嵌入。那为什么要在CAD图形中插入OLE对象?一般情况下,在CAD图形中插入OLE对象,是为了将不同应用程序的数据合并到一个文档中。本节内容小编就来给大家分享一下在CAD图形中插入OLE对象的…...
【微信小程序】-- 自定义组件 -- 数据、方法和属性(三十三)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

【Spring 深入学习】AOP的前世今生之代理模式
AOP的前世今生之代理模式1. 概述 什么是代理模式呢??? 在不修改原有代码 或是 无法修改原有代码的情况下,增强对象功能,替代原来的对象去完成功能,从而达成了拓展的目的。 先给大家看下 JavaScript中实现方…...
操作系统复试
2017软学 给出操作系统的定义,分别从资源管理,任务调度,用户接口等三个方面论述操作系统的职能 操作系统是位于硬件层之上、所有其他系统软件层之下的一个系统软件,使得管理系统中的各种软件和硬件资源得以充分利用,方…...

SkillPilot:AI编程助手技能一键管理与安全部署实战
1. 项目概述与核心价值最近在折腾AI编程助手的时候,发现了一个挺有意思的痛点:虽然Claude Code、Cursor这些工具都支持通过SKILL.md文件来扩展功能,但每次想找个新技能,都得手动去GitHub上翻找、下载、配置,还得担心代…...

3个核心机制解密:如何让视频PPT提取工具智能识别每一页幻灯片
3个核心机制解密:如何让视频PPT提取工具智能识别每一页幻灯片 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾经面对长达数小时的会议录像,需要从中提…...

Arm编译器浮点运算实现与优化实践
1. Arm编译器中的浮点运算实现机制在嵌入式开发领域,浮点运算的实现质量直接影响着数值计算的精度和系统性能。Arm编译器通过深度整合IEEE 754标准,为开发者提供了可靠的浮点运算支持。让我们先看一个典型场景:当使用printf输出浮点数时&…...

手把手教你用C8051F330自制BLheli电调:从测绘XP-12A到暴力测试70涵道
从零构建BLheli电调:C8051F330硬件逆向与70涵道暴力测试全指南 当你拆开一台现成的航模电调,看到里面密密麻麻的元件时,是否想过自己也能从头打造一个?本文将带你深入电调硬件设计的核心,从测绘商业电调XP-12A开始&…...

Linux下Cursor AI编辑器自动化安装脚本设计与实现
1. 项目概述:为什么我们需要一个Cursor的Linux安装脚本如果你是一个在Linux环境下工作的开发者,并且对AI辅助编程工具感兴趣,那么Cursor这个名字你一定不陌生。作为一款集成了强大AI能力的代码编辑器,它正迅速成为许多程序员的新宠…...

基于Next.js与Prisma构建宠物社区应用:全栈开发实战解析
1. 项目概述:一个为宠物爱好者打造的社区应用最近在GitHub上闲逛,发现了一个挺有意思的开源项目,叫jtsang4/happypaw。光看名字,“Happy Paw”(快乐的爪子),就能猜到这八成是和宠物相关的。点进…...

嵌入式系统安全设计:挑战、原则与微内核实践
1. 嵌入式系统安全的设计挑战与核心原则在万物互联的时代背景下,嵌入式系统已从封闭的独立设备转变为网络化智能节点。这种转变带来了前所未有的安全挑战——根据工业安全机构的统计,2022年针对工业控制系统的网络攻击同比增加了87%,其中针对…...

从ARM到FPGA:手把手教你用Vivado双口RAM IP核搭建跨芯片通信桥
从ARM到FPGA:构建高性能双口RAM通信桥的工程实践 在异构计算架构中,FPGA与处理器的协同工作已成为提升系统性能的关键方案。Xilinx Vivado工具链中的双口RAM IP核,为解决跨芯片数据交换提供了硬件级的优雅实现。本文将深入探讨如何将这一技术…...

Wireshark 命令行实战指南 ———— 自动化抓包与高效分析
1. 为什么需要Wireshark命令行模式 很多网络工程师第一次接触Wireshark时,都是通过图形界面进行操作。鼠标点点就能开始抓包,确实很方便。但当你需要处理以下场景时,图形界面就显得力不从心了: 服务器环境没有图形界面,…...

腾讯位置服务开发者征文大赛:“独行侠”智能路线官
一个关于城市夜跑者、算法盲区与AI情感化路线推荐的真实技术实践 关键词:Go、地图SDK抽象、LLM Agent、Prompt工程、情感化推荐 目录 背景需求:都市独行侠的运动品质困境痛点诊断:为什么传统地图工具"听不懂人话"Module-SDK&#…...