torchmetrics,一个无敌的 Python 库!
更多Python学习内容:ipengtao.com
大家好,今天为大家分享一个无敌的 Python 库 - torchmetrics。
Github地址:https://github.com/Lightning-AI/torchmetrics
在深度学习和机器学习项目中,模型评估是一个至关重要的环节。为了准确地评估模型的性能,开发者通常需要计算各种指标(metrics),如准确率、精确率、召回率、F1 分数等。torchmetrics 是一个用于 PyTorch 的开源库,提供了一组方便且高效的评估指标计算工具。本文将详细介绍 torchmetrics 库,包括其安装方法、主要特性、基本和高级功能,以及实际应用场景,帮助全面了解并掌握该库的使用。
安装
要使用 torchmetrics 库,首先需要安装它。可以通过 pip 工具方便地进行安装。
以下是安装步骤:
pip install torchmetrics安装完成后,可以通过导入 torchmetrics 库来验证是否安装成功:
import torchmetrics
print("torchmetrics 库安装成功!")特性
广泛的指标支持:提供多种评估指标,包括分类、回归、图像处理和生成模型等领域的常用指标。
模块化设计:指标可以像模块一样轻松集成到 PyTorch Lightning 或任何 PyTorch 项目中。
GPU 加速:支持 GPU 加速,能够高效处理大规模数据。
易于扩展:用户可以自定义指标并轻松集成到现有项目中。
高效计算:优化的计算方法,确保在训练过程中实时计算指标,性能开销最小。
基本功能
计算准确率
使用 torchmetrics 库,可以方便地计算分类任务的准确率。
import torch
import torchmetrics# 创建 Accuracy 指标
accuracy = torchmetrics.Accuracy()# 模拟预测和真实标签
preds = torch.tensor([0, 2, 1, 3])
target = torch.tensor([0, 1, 2, 3])# 计算准确率
acc = accuracy(preds, target)
print(f"准确率:{acc}")计算精确率和召回率
torchmetrics 库可以计算分类任务的精确率和召回率。
import torch
import torchmetrics# 创建 Precision 和 Recall 指标
precision = torchmetrics.Precision(num_classes=4)
recall = torchmetrics.Recall(num_classes=4)# 模拟预测和真实标签
preds = torch.tensor([0, 2, 1, 3])
target = torch.tensor([0, 1, 2, 3])# 计算精确率和召回率
prec = precision(preds, target)
rec = recall(preds, target)
print(f"精确率:{prec}")
print(f"召回率:{rec}")计算 F1 分数
torchmetrics 库还可以计算分类任务的 F1 分数。
import torch
import torchmetrics# 创建 F1 指标
f1 = torchmetrics.F1(num_classes=4)# 模拟预测和真实标签
preds = torch.tensor([0, 2, 1, 3])
target = torch.tensor([0, 1, 2, 3])# 计算 F1 分数
f1_score = f1(preds, target)
print(f"F1 分数:{f1_score}")高级功能
自定义指标
torchmetrics 库允许用户自定义指标,以满足特定需求。
import torch
import torchmetricsclass CustomMetric(torchmetrics.Metric):def __init__(self):super().__init__()self.add_state("sum", default=torch.tensor(0), dist_reduce_fx="sum")self.add_state("count", default=torch.tensor(0), dist_reduce_fx="sum")def update(self, preds: torch.Tensor, target: torch.Tensor):self.sum += torch.sum(preds == target)self.count += target.numel()def compute(self):return self.sum.float() / self.count# 创建自定义指标
custom_metric = CustomMetric()# 模拟预测和真实标签
preds = torch.tensor([0, 2, 1, 3])
target = torch.tensor([0, 1, 2, 3])# 计算自定义指标
result = custom_metric(preds, target)
print(f"自定义指标结果:{result}")与 PyTorch Lightning 集成
torchmetrics 库可以无缝集成到 PyTorch Lightning 中,简化指标计算流程。
import torch
import torchmetrics
import pytorch_lightning as pl
from torch import nnclass LitModel(pl.LightningModule):def __init__(self):super().__init__()self.model = nn.Linear(10, 4)self.accuracy = torchmetrics.Accuracy()def forward(self, x):return self.model(x)def training_step(self, batch, batch_idx):x, y = batchpreds = self(x)loss = nn.functional.cross_entropy(preds, y)acc = self.accuracy(preds, y)self.log('train_acc', acc)return lossdef configure_optimizers(self):return torch.optim.Adam(self.parameters(), lr=0.001)# 示例数据
train_data = torch.utils.data.TensorDataset(torch.randn(100, 10), torch.randint(0, 4, (100,)))
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32)# 训练模型
model = LitModel()
trainer = pl.Trainer(max_epochs=5)
trainer.fit(model, train_loader)GPU 加速
torchmetrics 库支持 GPU 加速,可以在 GPU 上高效地计算指标。
import torch
import torchmetrics# 创建 Accuracy 指标并移动到 GPU
accuracy = torchmetrics.Accuracy().cuda()# 模拟预测和真实标签并移动到 GPU
preds = torch.tensor([0, 2, 1, 3]).cuda()
target = torch.tensor([0, 1, 2, 3]).cuda()# 计算准确率
acc = accuracy(preds, target)
print(f"准确率:{acc}")实际应用场景
图像分类任务中的指标计算
在图像分类任务中,需要计算各种评估指标,如准确率、精确率、召回率等。
import torch
import torchmetrics
import torchvision.models as models
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader# 加载数据
transform = transforms.Compose([transforms.ToTensor()])
train_data = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)# 创建模型和指标
model = models.resnet18(num_classes=10)
accuracy = torchmetrics.Accuracy()# 训练模型并计算准确率
for inputs, targets in train_loader:outputs = model(inputs)acc = accuracy(outputs, targets)print(f"批次准确率:{acc}")文本分类任务中的指标计算
在文本分类任务中,需要计算评估指标,如 F1 分数。
import torch
import torchmetrics
from transformers import BertTokenizer, BertForSequenceClassification# 加载模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 示例数据
texts = ["I love this!", "This is bad."]
labels = torch.tensor([1, 0])# 预处理数据
inputs = tokenizer(texts, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)# 创建 F1 指标
f1 = torchmetrics.F1(num_classes=2)# 计算 F1 分数
preds = torch.argmax(outputs.logits, dim=1)
f1_score = f1(preds, labels)
print(f"F1 分数:{f1_score}")生成对抗网络(GAN)中的指标计算
在生成对抗网络(GAN)的训练中,需要计算生成图片的质量指标,如 Frechet Inception Distance(FID)。
import torch
import torchmetrics
from torchvision.models import inception_v3
from torchvision.transforms import transforms
from torch.utils.data import DataLoader, TensorDataset# 创建生成对抗网络(GAN)的生成器模型
class Generator(torch.nn.Module):def __init__(self):super(Generator, self).__init__()self.fc = torch.nn.Linear(100, 128 * 7 * 7)self.deconv = torch.nn.Sequential(torch.nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),torch.nn.BatchNorm2d(64),torch.nn.ReLU(True),torch.nn.ConvTranspose2d(64, 1, 4, stride=2, padding=1),torch.nn.Tanh())def forward(self, x):x = self.fc(x).view(-1, 128, 7, 7)return self.deconv(x)# 创建生成器模型
generator = Generator()# 创建 FID 指标
fid = torchmetrics.image.fid.FrechetInceptionDistance(feature=64)# 模拟生成图片和真实图片
latent_vectors = torch.randn(100, 100)
generated_images = generator(latent_vectors)
real_images = torch.randn(100, 1, 28, 28)# 转换图片为 Inception V3 输入格式
transform = transforms.Compose([transforms.Resize((299, 299)),transforms.Normalize(mean=[0.5], std=[0.5])
])
generated_images = transform(generated_images)
real_images = transform(real_images)# 创建 DataLoader
generated_loader = DataLoader(TensorDataset(generated_images), batch_size=32)
real_loader = DataLoader(TensorDataset(real_images), batch_size=32)# 计算 FID
for gen_batch, real_batch in zip(generated_loader, real_loader):fid.update(real_batch[0], gen_batch[0])fid_value = fid.compute()
print(f"FID 分数:{fid_value}")总结
torchmetrics 库是一个功能强大且易于使用的评估指标计算工具,能够帮助开发者在深度学习和机器学习项目中高效地计算各种评估指标。通过支持广泛的指标、多种计算模式、GPU 加速和自定义扩展,torchmetrics 库能够满足各种复杂的评估需求。本文详细介绍了 torchmetrics 库的安装方法、主要特性、基本和高级功能,以及实际应用场景。希望本文能帮助大家全面掌握 torchmetrics 库的使用,并在实际项目中发挥其优势。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
如果想要系统学习Python、Python问题咨询,或者考虑做一些工作以外的副业,都可以扫描二维码添加微信,围观朋友圈一起交流学习。

我们还为大家准备了Python资料和副业项目合集,感兴趣的小伙伴快来找我领取一起交流学习哦!
往期推荐
历时一个月整理的 Python 爬虫学习手册全集PDF(免费开放下载)
Python基础学习常见的100个问题.pdf(附答案)
学习 数据结构与算法,这是我见过最友好的教程!(PDF免费下载)
Python办公自动化完全指南(免费PDF)
Python Web 开发常见的100个问题.PDF
肝了一周,整理了Python 从0到1学习路线(附思维导图和PDF下载)
相关文章:
torchmetrics,一个无敌的 Python 库!
更多Python学习内容:ipengtao.com 大家好,今天为大家分享一个无敌的 Python 库 - torchmetrics。 Github地址:https://github.com/Lightning-AI/torchmetrics 在深度学习和机器学习项目中,模型评估是一个至关重要的环节。为了准确…...

如何快速上手Python,成为一名数据分析师
如何快速上手Python,成为一名数据分析师 成为一名数据分析师需要掌握Python编程语言以及数据分析相关的知识和技能。以下是一些步骤和建议,帮助你快速上手Python并成为一名数据分析师: 学习Python基础知识:首先,你需要…...

MC服务器怎么搭建
MC服务器怎么搭建?随着《我的世界》(Minecraft,简称MC)的火爆,越来越多的玩家和社区开始搭建自己的MC服务器,与朋友共享创造的乐趣。但搭建一台稳定、高效的MC服务器并不是一件容易的事。今天,我们就来聊聊…...

JavaScript正则表达式
search()方法 用来检索与正则表达式相匹配的子字符串,并返回子字符串开始的位置。若结果为-1则表示没有与之匹配的子字符串例: var str"well pemper" var str1str.search(/em/g) console.log(str1) //返回6replace()方法 用于替换一个与正…...
Redis实战宝典:基础知识、实战技巧、应用场景及最佳实践全攻略
背景 在Java系统实现过程中,我们不可避免地会借助大量开源功能组件。然而,这些组件往往功能丰富且体系庞大,官方文档常常详尽至数百页。而在实际项目中,我们可能仅需使用其中的一小部分功能,这就造成了一个挑战&#…...

[FFmpeg学习]初级的SDL播放mp4测试
在之前的学习中,通过AVFrame来保存为图片来认识了AVFrame, [FFmpeg学习]从视频中获取图片_ffmpeg 获取图片-CSDN博客 在获取到AVFrame时,还可以调用SDL方法来进行展现,实现播放效果。 参考资料 SDL,ffmpeg实现简单…...

情景题之小明的Linux实习之旅:linux实战练习1(下)【基础命令,权限修改,日志查询,进程管理...】
小明的Linux实习之旅:基础指令练习情景练习题下 前景提要小明是怎么做的场景1:初识Linux,创建目录和文件场景2:权限管理,小明的权限困惑场景3:打包与解压,小明的备份操作场景4:使用G…...

k8s 证书更新
如何使用脚本更新Kubernetes集群证书 引言 Kubernetes集群中,由kubeadm初始化的证书有效期默认为一年。当这些证书接近或已经超过有效期时,它们必须被更新以保证集群的正常运作。本文将介绍如何使用特定脚本来更新这些证书,将它们的有效期延…...

Linux操作系统学习:day01
内容来自:Linux介绍 视频推荐:Linux基础入门教程-linux命令-vim-gcc/g -动态库/静态库 -makefile-gdb调试 day01 基础概念 Linux 是 UNIX 操作系统的一个克隆系统, 但是Linux是开源的。 Linux是一个基于文件的操作系统。操作系统需要和硬件进行交互…...

【Oracle生产运维】数据库服务器负载过高异常排查处理
说明 在Oracle数据库运维工作中,经常会遇到Oracle数据库服务器平均负载(load average)突然异常升高,如果放任不管,严重的情况下会出现数据库宕机、服务器重启等重大故障。因此,当发现数据库服务器平均负载…...
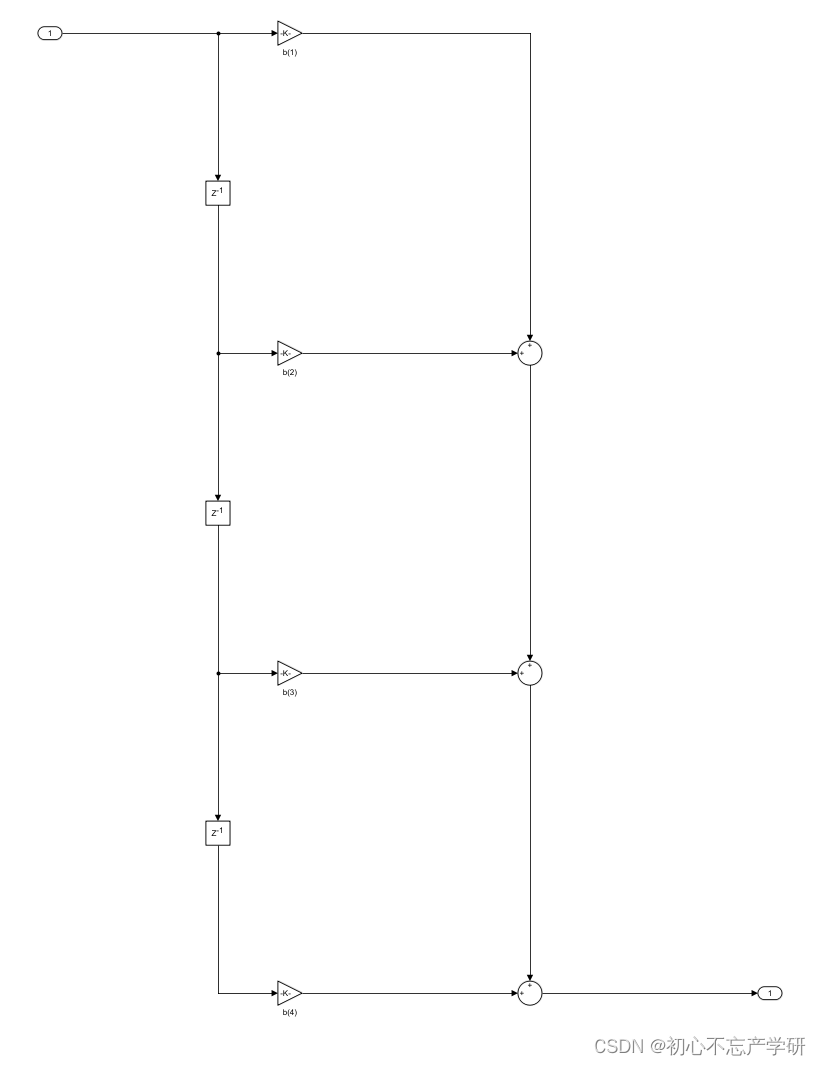
IIR和FIR两种滤波器有什么区别?
概念的区分 IIR(Infinite Impulse Response,无限脉冲响应)和FIR(Finite Impulse Response,有限脉冲响应)滤波器是两种常见的数字信号处理滤波器类型,它们在结构、性能和用途上有显著区别&#…...

让GNSSRTK不再难【第二天-第4部分】
第12讲 GNSS授时与PPS 12.1 为什么需要高精度时间 授时的传统理解就是时间传递或者对时。比如以前手机没这么方便时,大家还都使用石英钟手表看时间时,大家都习惯晚上七点准时对着中央一套的报时,来校准你家的机械钟或者挂钟,这就…...
「OC」UI练习(一)—— 登陆界面
「OC」登陆界面 明确要求 一个登陆界面的组成,用户名提示以及输入框,密码提示提示以及输入框,登陆按钮,以及注册按钮,根据以上要求我们将我们的组件设置为成员变量。 //viewControl.h #import <UIKit/UIKit.h>…...
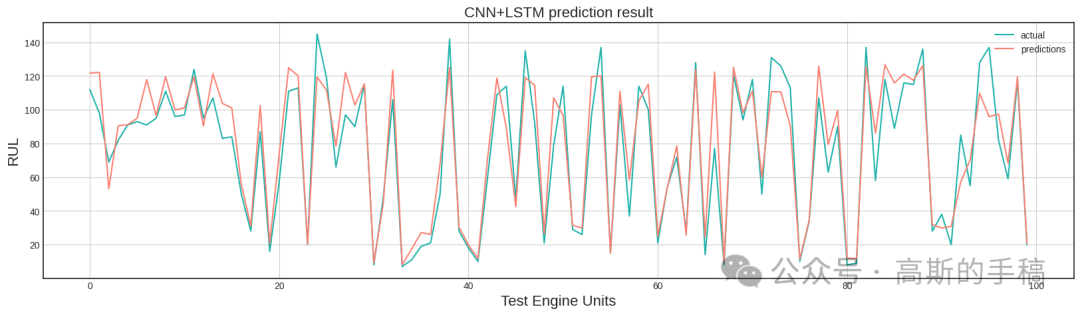
基于机器学习和深度学习的NASA涡扇发动机剩余使用寿命预测(C-MAPSS数据集,Python代码,ipynb 文件)
以美国航空航天局提供的航空涡扇发动机退化数据集为研究对象,该数据集包含多台发动机从启动到失效期间多个运行周期的多源传感器时序状态监测数据,它们共同表征了发动机的性能退化情况。为减小计算成本,需要对原始多源传感器监测数据进行数据…...
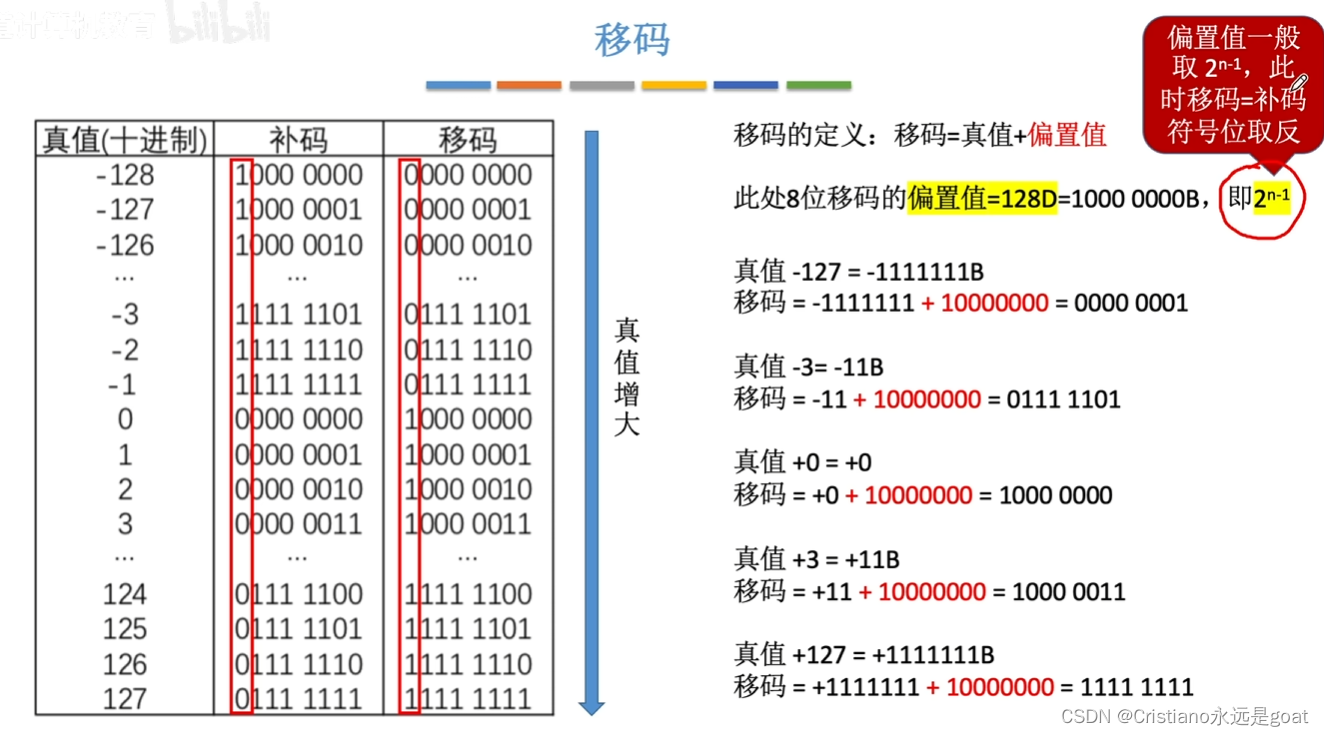
计算机组成原理-常见计算题含IEE754
一、补码加减运算 二、溢出判断 采用一位符号位 采用双符号位 三、定点数的移位运算 算术右移 算数左移 反码的算术移位 补码的算术移位 四、浮点数的表示 一个右规的例子 五、IEEE754 移码...

InnoDB存储引擎非常重要的一个机制--MVCC(多版本并发控制)
Mysql是如何实现隔离性的?(锁MVCC) 隔离性是指一个事务内部的操作以及操作的数据对正在进行的其他事务是隔离的,并发执行的各个事务之间不能相互干扰。隔离性可以防止多个事务并发执行时,可能存在交叉执行导致数据的不…...

【DevOps】服务器硬件基础知识
目录 前言 1、处理器(CPU):服务器的“大脑” 2、内存(RAM):服务器的“工作台” 3、存储(Storage):服务器的“仓库” 4、 网络接口(NIC)&…...

6.10 c语言
7.1 if-else语句 简化形式 if(表达式)语句块 阶梯形式 if(表达式1)语句块1 else if(表达式2)语句块2 嵌套形式 if() if() 语句1 else 语句2 else if() 语句3 else 语句4 表达式一般情况下为逻辑表达式或关系表达式 #include <stdio.h>//从小到大排序,输出顺…...

jenkins插件之Jdepend
JDepend插件是一个为构建生成JDepend报告的插件。 安装插件 JDepend Dashboard -->> 系统管理 -->> 插件管理 -->> Available plugins 搜索 Jdepend, 点击安装构建步骤新增执行shell #执行pdepend if docker exec phpfpm82 /tmp/composer/vendor/bin/pdepe…...

vue3之基于el-image实现图片预览
实现的功能: 图片可放大预览,支持放大、缩小、向左向右旋转查看可点击任意一张图后进行左右切换查看大图 主要使用的方法:splice和concat 主要代码 // template中 <div><el-imagev-for"(item, index) in imgsData":src&q…...

纸张计数技术深度解析:基于STM32与FDC2214的高精度电容传感系统架构剖析
纸张计数技术深度解析:基于STM32与FDC2214的高精度电容传感系统架构剖析 【免费下载链接】2019-Electronic-Design-Competition 【电赛】2019 全国大学生电子设计竞赛 (F题)纸张数量检测装置 (基于STM32F407 & FDC2214 & …...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...

[A2A协议与实现-01]借助A2A协议打破智能体孤岛
A2A协议是一个开放标准,它实现了Agent之间的无缝通信和协作。它为使用不同框架和由不同供应商构建的Agent提供了一种通用语言,从而促进了互操作性并打破了信息孤岛。A2A协议使得来自不同开发者、基于不同框架构建、并由不同组织拥有的Agent能够联合起来协…...

轻量化AI助手框架部署指南:基于Nectar-GPT构建社交场景智能机器人
1. 项目概述:一个面向社交场景的轻量化AI助手最近在GitHub上看到一个挺有意思的项目,叫socialtribexyz/Nectar-GPT。光看名字,你可能会觉得这又是一个基于GPT API的简单封装,或者是一个聊天机器人。但当我深入去研究它的代码结构、…...

PromptFlow:企业级AI应用编排与全生命周期管理工具详解
1. 项目概述:PromptFlow,一个被低估的AI应用编排利器如果你最近在折腾大语言模型应用,从简单的聊天机器人到复杂的多步推理工作流,大概率会听到“LangChain”、“LlamaIndex”这些名字。它们确实火,社区活跃࿰…...

别再只当扫码枪用了!用Python+GM861S模块,DIY一个智能物料盘点小工具
用PythonGM861S模块打造智能物料盘点系统 在仓库管理和生产制造场景中,物料盘点是项耗时又容易出错的工作。传统扫码枪往往只作为简单数据采集工具,而结合Python编程能力,我们可以将GM861S这类高性能扫码模块升级为智能终端。这个项目将展示如…...

在Ubuntu上快速搭建LVGL模拟器开发环境
1. 为什么选择Ubuntu搭建LVGL模拟器 LVGL作为当下最流行的嵌入式图形库之一,以其高度可裁剪性和低资源占用的特性赢得了广大开发者的青睐。在实际开发中,我们经常需要先在PC端完成界面原型设计,再移植到嵌入式设备。Ubuntu作为Linux发行版中的…...

Win10下VSCode与OpenCV环境搭建:从零到一的避坑指南
1. 环境准备:安装必要工具链 在Windows 10上搭建OpenCV开发环境,首先需要准备好三个核心工具:MinGW、CMake和VSCode。这三个工具就像盖房子需要的钢筋、水泥和施工图纸,缺一不可。 MinGW是Windows下的GNU工具集,相当…...
)
ESP32-C3驱动2寸ST7789屏幕?手把手教你搞定LVGL移植(附避坑代码)
ESP32-C3与ST7789屏幕的LVGL移植实战指南 在物联网设备开发中,显示交互界面往往是提升用户体验的关键一环。ESP32-C3作为乐鑫推出的高性价比RISC-V芯片,搭配ST7789驱动的2寸LCD屏幕,能够构建出性能稳定、成本可控的嵌入式显示方案。本文将带你…...

【Midjourney提示词黄金公式】:20年AI视觉专家亲授7大风格锚点+3层语义嵌套技巧
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词黄金公式的底层逻辑 Midjourney 的提示词(Prompt)并非自由文本堆砌,而是一套具有语法优先级与语义权重的结构化指令系统。其“黄金公式”——主体 …...