【Week-R3】天气预测,引入探索式数据分析方法(EDA)
文章目录
- 1. 导入模块
- 2. 导入数据
- 3.探索式数据分析方法(EDA)
- 3.1 数据相关性探索
- 3.2 是否会下雨
- 3.3 地理位置与下雨的关系
- 3.4 湿度和压力对下雨的影响
- 3.5 气温对下雨的影响
- 4.数据预处理
- 4.1 处理缺损值
- 4.2 构建数据集
- 5 预测是否会下雨
- 5.1 构建神经网络
- 5.2 模型训练
- 5.3 结果可视化
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
本次学习引入了探索式数据分析(EDA),可用于分析数据表内各数据之间的关系
本次学习使用的数据集:来自澳大利亚许多地点的大约10年的每日天气观测数据。
本次学习的任务:根据提供的数据,对明天是否下雨(RainTomorrow)进行预测。
语言环境:Python 3.12
编译器:VSCode
深度学习框架:Tensorflow 2.11.0
1. 导入模块
print("*****************# 1. 导入模块************************")
# 1. 导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore')import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error, mean_squared_error
print("*****************# 1. 导入模块 End************************")2. 导入数据
# 2. 导入数据
print("*****************# 2. 导入数据************************")
data = pd.read_csv("D:\\jupyter notebook\\DL-100-days\\RNN\\weatherAUS.csv")
df = data.copy()
print("data.head():\n", data.head())

print("data.describe():\n", data.describe())

print("data.dtypes:\n", data.dtypes)
data['Date'] = pd.to_datetime(data['Date'])
print("data['Date']:\n", data['Date'])
data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.day
print("data.head():\n", data.head())

data.drop('Date', axis=1, inplace=True)
print("data.columns:\n", data.columns)
print("*****************# 2. 导入数据 End************************")
3.探索式数据分析方法(EDA)
探索性数据分析(Exploratory Data Analysis,简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律了解数据集,了解变量间的相互关系以及变量与预测值之间的关系的一种数据分析方法。
【探索式数据分析方法(EDA)】
3.1 数据相关性探索
print("*****************3.探索式数据分析方法(EDA)************************")
# 3.探索式数据分析方法(EDA)
# 3.1 数据相关性探索
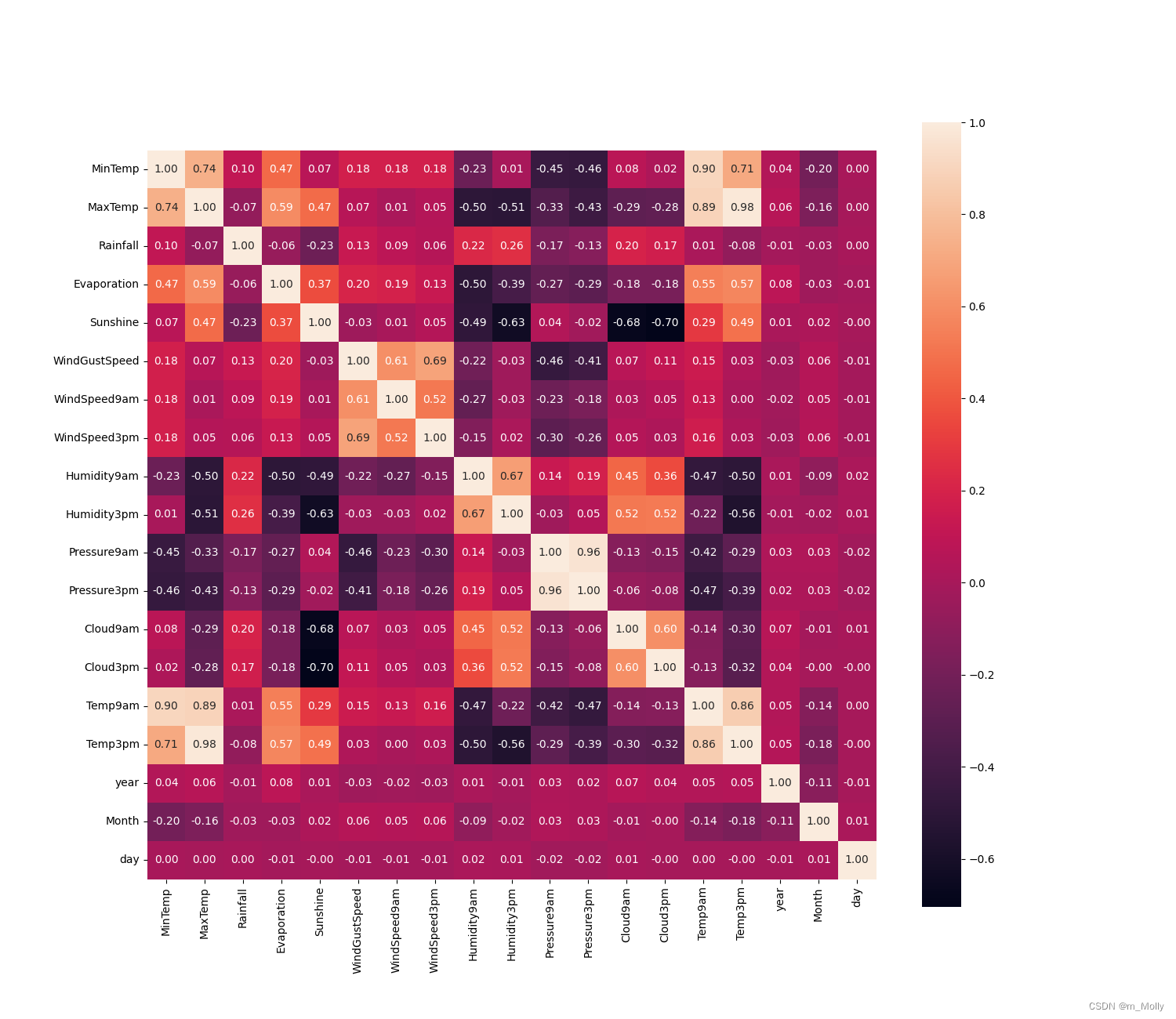
plt.figure(figsize=(15,13))
# data.corr()表示了data中的两个变量之间的相关性
ax = sns.heatmap(data.corr(),square=True, annot=True, fmt='.2f')
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
plt.savefig("3.1 数据相关性探索热力图.png")
plt.show()
3.2 是否会下雨
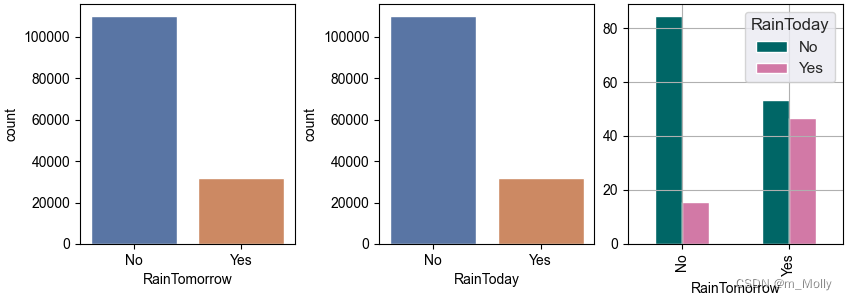
# 3.2 是否会下雨
fig,ax = plt.subplots(1,3,constrained_layout = True , figsize = (14,3))
sns.set_theme(style="darkgrid")
#plt.figure(figsize=(4,3))
sns.countplot(x='RainTomorrow', data=data, ax=ax[0])
#plt.savefig("3.2 明天是否会下雨.png")#plt.figure(figsize=(4,3))
sns.countplot(x='RainToday', data=data, ax=ax[1])
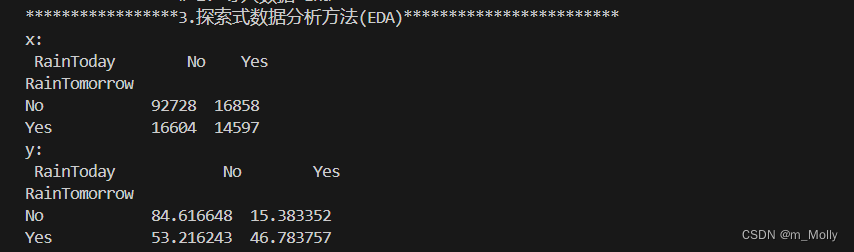
#plt.savefig("3.2 今天是否会下雨.png")x = pd.crosstab(data['RainTomorrow'], data['RainToday'])
print("x: \n", x)
# 计算百分比
y = x/x.transpose().sum().values.reshape(2,1)*100
print("y: \n", y)y.plot(kind="bar", figsize=(4,3), color=['#006666','#d279a6'], ax=ax[2])
plt.savefig("3.2 是否会下雨.png")
(左)明天是否下雨
(中)今天是否下雨
(右)今天是否下雨 & 明天是否下雨 的关系
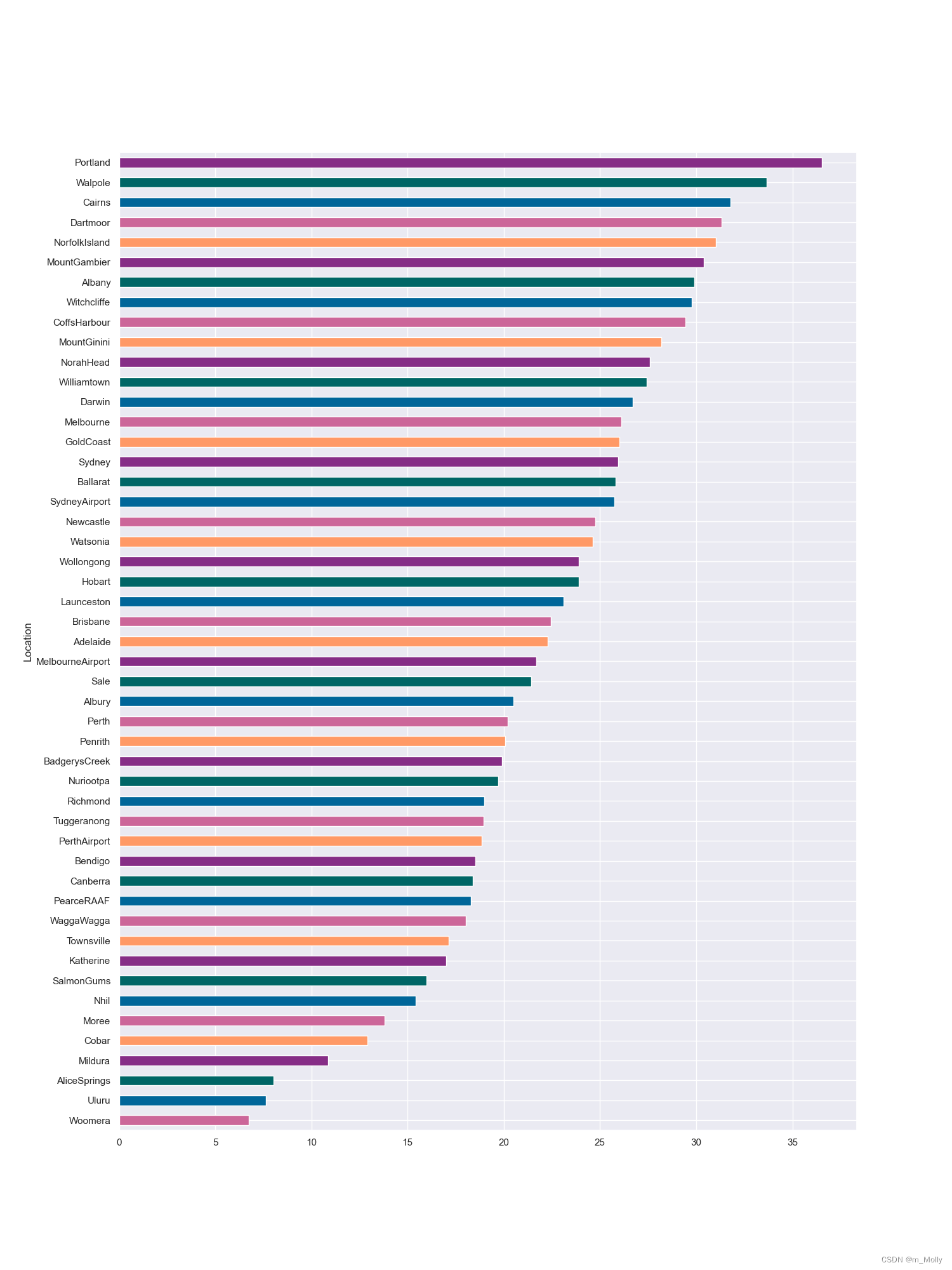
3.3 地理位置与下雨的关系
plt.figure(figsize=(15,20))
# 3.3 地理位置与下雨的关系
x = pd.crosstab(data['Location'], data['RainToday'])
# 获取每个城市下雨天数和非下雨天数的百分比
y = x/x.transpose().sum().values.reshape((-1,1))*100
# 按每个城市雨天的百分比排序
y = y.sort_values(by='Yes', ascending=True)
color = ['#cc6699', '#006699', '#006666', '#862d86', '#ff9966']
y.Yes.plot(kind="bath", figsize=(15,20), color=color)
plt.savefig("3.3 地理位置与下雨的关系.png")
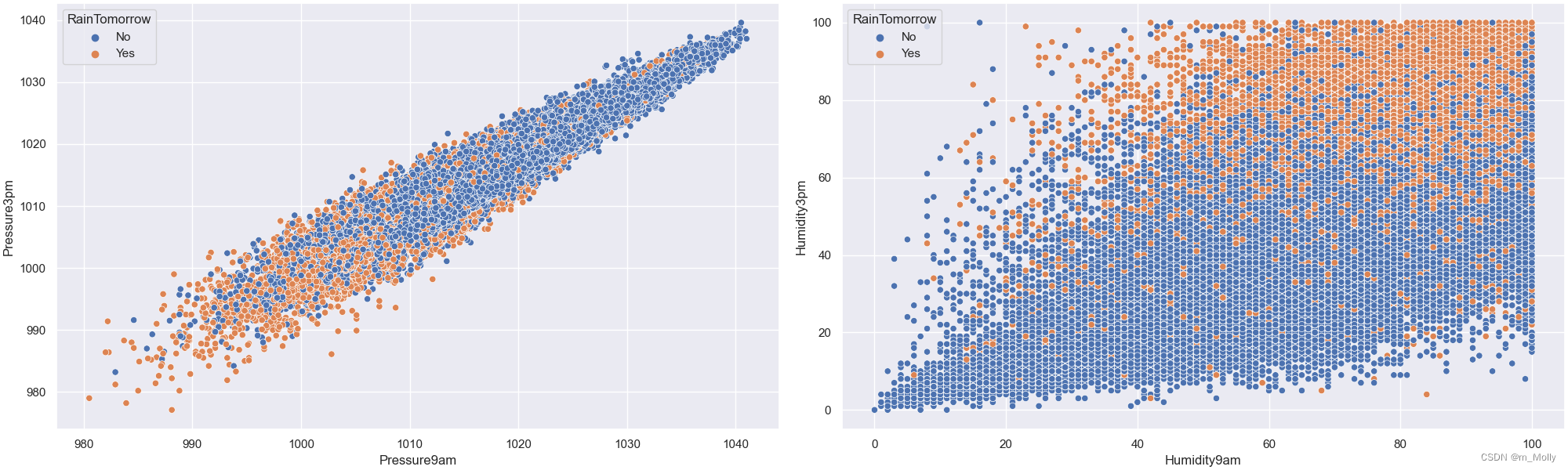
3.4 湿度和压力对下雨的影响
# 3.4 湿度和压力对下雨的影响
data.columns
# 绘制明天早上9点到下午3点的气压下是否下雨的散点图
fig,ax = plt.subplots(1,2,constrained_layout = True , figsize = (20,6))
#plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='Pressure9am', y='Pressure3pm',hue='RainTomorrow', ax=ax[0])
#plt.savefig("3.4 压力对下雨的影响.png")
# 绘制明天早上9点到下午3点的湿度下是否下雨的散点图
#plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='Humidity9am', y='Humidity3pm',hue='RainTomorrow', ax=ax[1])
plt.savefig("3.4 压力、湿度对下雨的影响.png")
输出:(左)压力对下雨的影响 (右)湿度对下雨的影响
3.5 气温对下雨的影响
# 3.5 气温对下雨的影响
plt.figure(figsize=(8,6))
sns.scatterplot(data=data, x='MinTemp', y='MaxTemp',hue='RainTomorrow')
plt.savefig("3.5 气温对下雨的影响.png")
print("*****************3.探索式数据分析方法(EDA) End************************")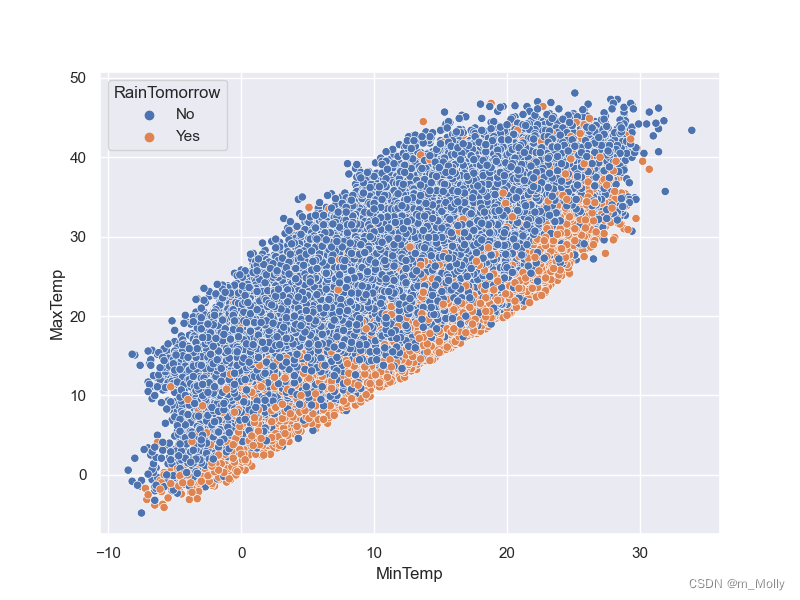
4.数据预处理
4.1 处理缺损值
print("*****************# 4.数据预处理************************")
# 4.数据预处理
# 4.1 处理缺损值
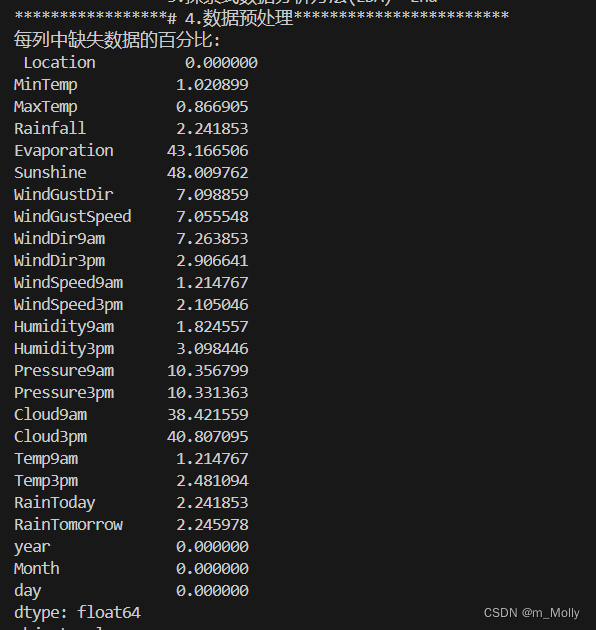
# 每列中缺失数据的百分比
print("每列中缺失数据的百分比: \n", data.isnull().sum()/data.shape[0]*100)
# 在该列中随机选择数进行填充
lst = ['Evaporation', 'Sunshine', 'Cloud9am', 'Cloud3pm']
for col in lst:fill_list = data[col].dropna()data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list, size=len(data.index))))
s = (data.dtypes == "object")
object_cols = list(s[s].index)
print("object_cols: \n", object_cols)

# inplace=True: 直接修改原对象,不创建副本
# data[i].mode()[0]: 返回频率出现最高的选项,众数
for i in object_cols:data[i].fillna(data[i].mode()[0], inplace=True)
t = (data.dtypes == "float64")
num_cols = list(t[t].index)
print("num_cols: \n", num_cols)

# .median(): 中位数
for i in num_cols:data[i].fillna(data[i].median(), inplace=True)
data.isnull().sum()
4.2 构建数据集
LabelEncoder 是 sklearn.preprocessing 模块中的一个工具,用于将分类特征的标签转换为整数。
# 4.2 构建数据集
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
for i in object_cols:data[i] = label_encoder.fit_transform(data[i])
x = data.drop(['RainTomorrow', 'day'], axis=1).values
y = data['RainTomorrow'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=101)
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
print("*****************# 4.数据预处理 End************************")报错:

原因:LabelEncoder是sklearn的模块,不是keras的。

5 预测是否会下雨
5.1 构建神经网络
print("*****************# 5 预测是否会下雨************************")
# 5 预测是否会下雨
# 5.1 构建神经网络
from keras.optimizers import Adam
model = Sequential()
model.add(Dense(units=24, activation='tanh',))
model.add(Dense(units=18, activation='tanh'))
model.add(Dense(units=23, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=12, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(units=1, activation='tanh'))
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy',optimizer=optimizer,metrics="accuracy")
early_stop = EarlyStopping(monitor='val_loss',mode='min',min_delta=0.001,verbose=1,patience=25,restore_best_weights=True)
5.2 模型训练
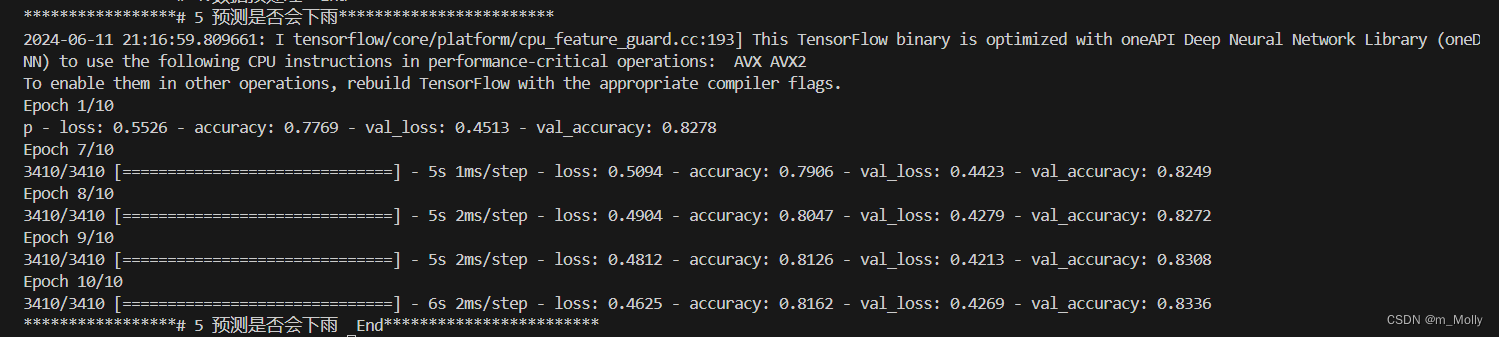
# 5.2 模型训练
model.fit(x=x_train,y=y_train,validation_data=(x_test, y_test), verbose=1,callbacks=[early_stop],epochs=10,batch_size=32)
5.3 结果可视化
# 5.3 结果可视化
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
epochs_range = range(10)plt.figure(figsize=(14,4))plt.subplot(1,2,1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title("Training and Validation Accuracy")plt.subplot(1,2,2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="lower right")
plt.title("Training and Validation Loss")
plt.savefig("# 5.3 结果可视化.png")
plt.show()
print("*****************# 5 预测是否会下雨 End************************")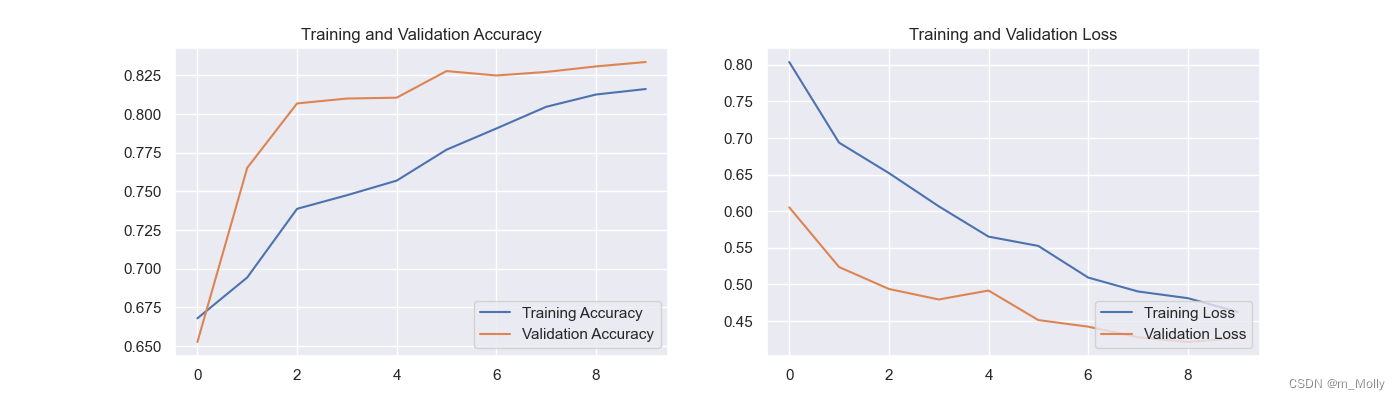
相关文章:
【Week-R3】天气预测,引入探索式数据分析方法(EDA)
文章目录 1. 导入模块2. 导入数据3.探索式数据分析方法(EDA)3.1 数据相关性探索3.2 是否会下雨3.3 地理位置与下雨的关系3.4 湿度和压力对下雨的影响3.5 气温对下雨的影响 4.数据预处理4.1 处理缺损值4.2 构建数据集 5 预测是否会下雨5.1 构建神经网络5.…...
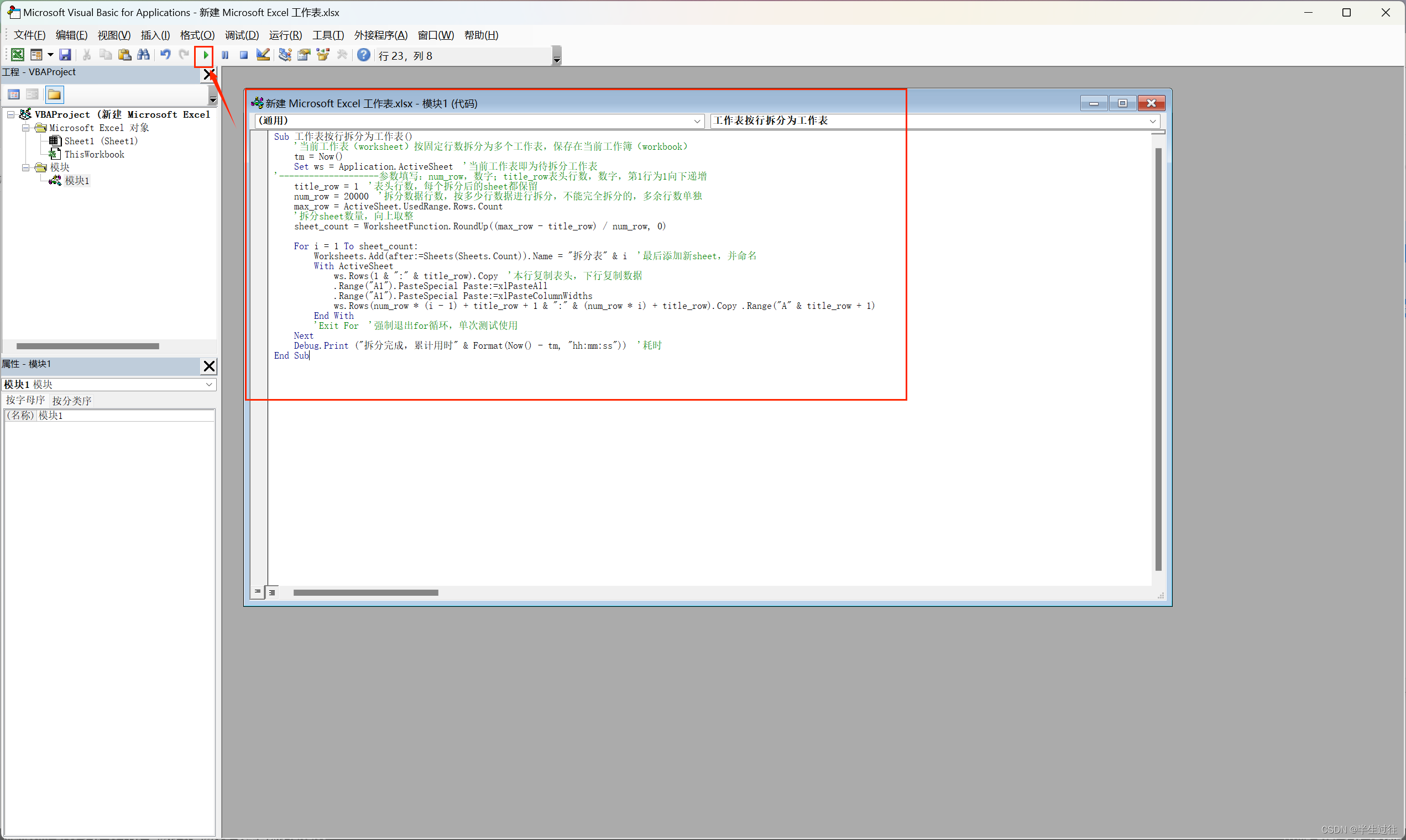
VBA excel 表格将多行拆分成多个表格或 文件 或者合并 多个表格
excel 表格 拆分 合并 拆分工作表按行拆分为工作表工作表按行拆分为工作薄 合并操作步骤 拆分 为了将Excel中的数万行数据拆分成多个个每个固定行数的独立工作表,并且保留每个工作表的表头,你可以使用以下VBA脚本。这个脚本会复制表头到每个新的工作表&…...

利用Redis的队列模式实现消息的发送和订阅,适合分布式场景,Java实现代码
在Redis中,通常使用发布/订阅模式(Pub/Sub)来进行消息的实时通信。然而,标准的Redis发布/订阅模式并不直接支持确保一条消息只被一台机器消费。在这种模式下,所有订阅了特定频道的客户端都会收到发布的消息。 但是&…...

软件下载安装【汇总】
软件下载安装【汇总】 前言版权推荐软件安装【汇总】最后 前言 2024-5-12 21:38:34 以下内容源自《【汇总】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是https://jsss-1.blog.csdn.net 禁止其他平台发布…...
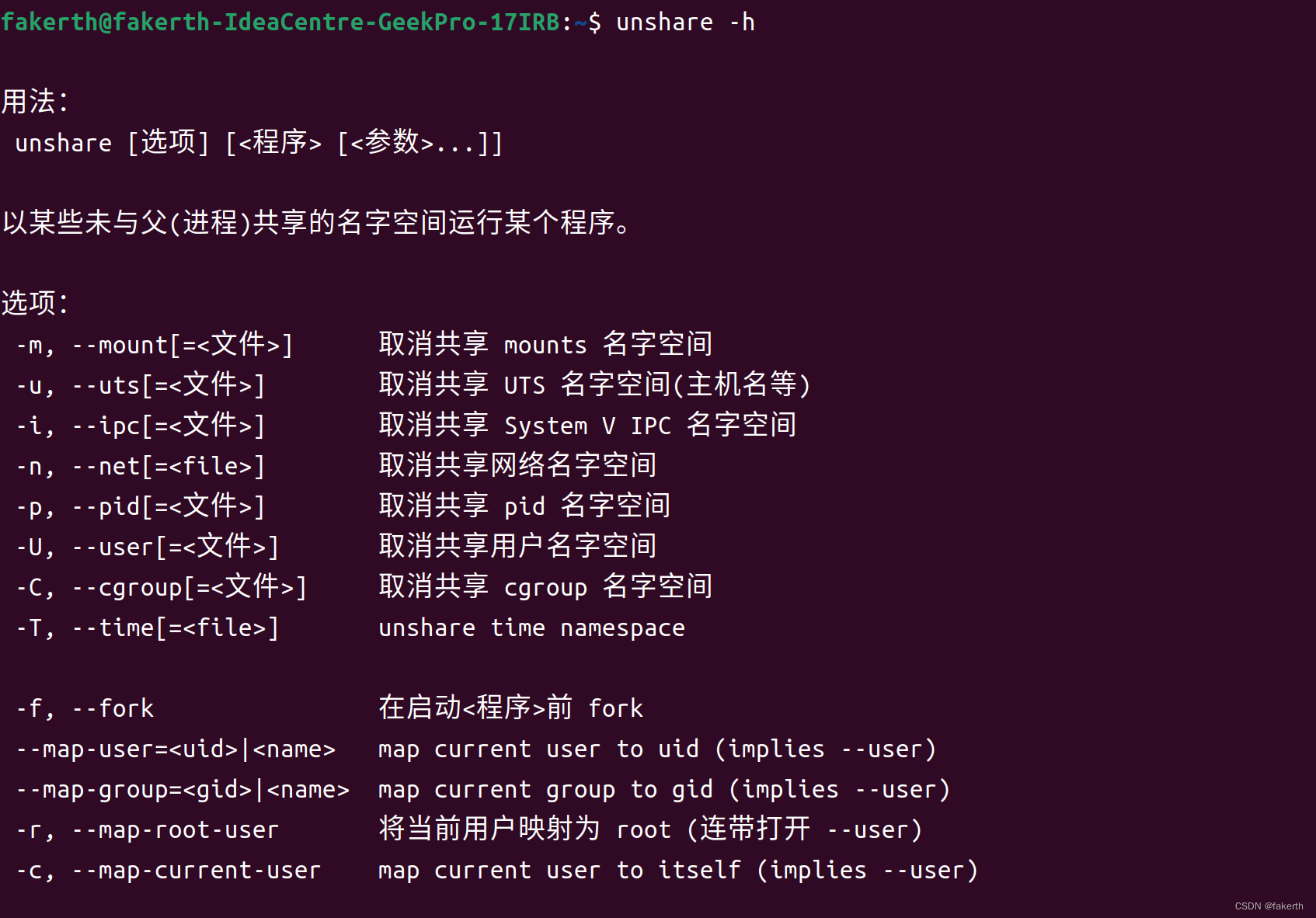
重定向文件访问(Redirect file access)
重定向文件访问 重定向文件访问是指通过修改文件系统的路径,使对某个文件或目录的访问请求被转到另一个文件或目录。这在系统管理、测试和开发中非常有用,因为它允许您在不修改应用程序或服务配置的情况下,改变文件的实际存储位置。 proot …...
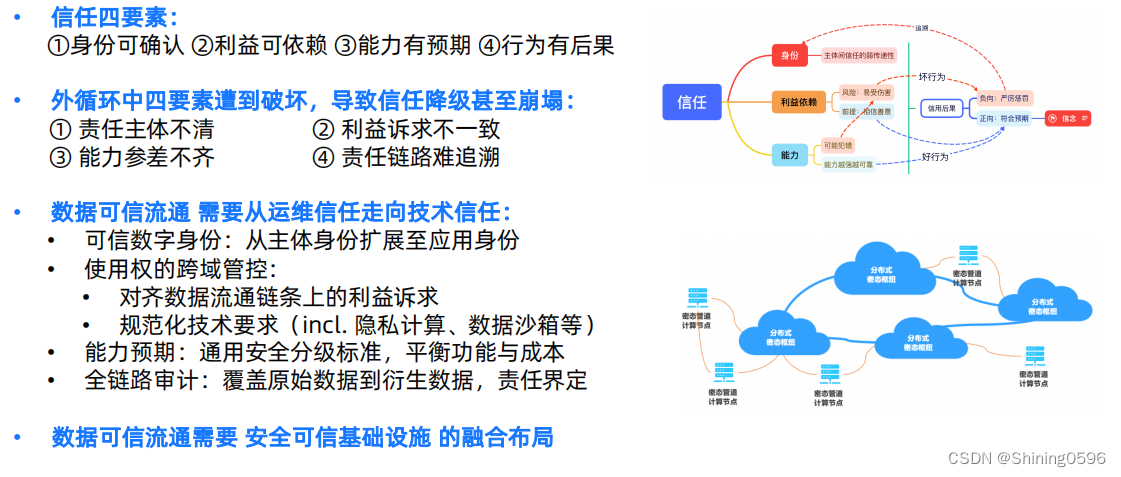
隐私计算(1)数据可信流通
目录 1. 数据可信流通体系 2. 信任的基石 3.数据流通中的不可信风险 可信链条的级联失效,以至于崩塌 4.数据内循环与外循环:传统数据安全的信任基础 4.1内循环 4.2外循环 5. 技术信任 6. 密态计算 7.技术信任 7.1可信数字身份 7.2 使用权跨域…...

果汁机锂电池充电,5V升压12.7V 升压恒压芯片SL1571B
在现代化的日常生活中,果汁机已经逐渐成为了许多家庭厨房的必备电器。随着科技的不断进步,果汁机的性能也在不断提升,其中锂电池的应用更是为果汁机带来了前所未有的便利。而5V升压12.7V升压恒压芯片SL1571B,作为果汁机锂电池充电…...

多个线程多个锁:如何确保线程安全和避免竞争条件
目录 前言 一、确定需要多个锁的场景 1.独立资源保护 2.部分依赖资源 二、避免死锁 三、锁粒度与并发性能 1. 粗粒度锁定 2.细粒度锁定 四、设计策略:减少资源依赖 1.资源分离 2.无锁设计 3.锁合并 五、Demo讲解 总结: 前言 当多个线程需要…...

Linux-笔记 设备树插件
目录 前言: 设备树插件的书写规范: 设备树插件的编译: 内核配置: 应用背景: 举例: 前言: 设备树插件(Device Tree Blob Overlay,简称 DTBO)是Linux内核和嵌入式系统…...

【排序算法】总结篇
✨✨这些 排序算法都是指的 需要进行比较的排序算法 ✨✨下面都是略微讲解一下思路,如果需要详细了解哪一个排序,点击👉链接即可 ✨✨对于时间、空间复杂度、稳定性,希望你🧑🎓能够理解记忆🧑…...

鸿蒙开发文件管理:【@ohos.fileio (文件管理)】
文件管理 该模块提供文件存储管理能力,包括文件基本管理、文件目录管理、文件信息统计、文件流式读写等常用功能。 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 impor…...

硬件工程师学习规划
背景介绍 当前电子行业中,互联网因为中国人口基数大,得到很快的发展,一越成为世界第一梯队,互联网软件薪资要高于传统制造业硬件的薪资,从各大招聘软件上就能看到,那么为什么软件发展要好于硬件࿱…...

esp32 8行代码实现蓝牙音响
目录 硬件准备: 具体代码: 接线: 备注: 八行代码实现简易版蓝牙音响,亲测有效: esp32 DIY蓝牙音响_哔哩哔哩_bilibili 硬件准备: ESP32-wroom、MAX98357音频放大器模块、4欧3瓦小喇叭、杜…...

注册用户如何防止缓存穿透?
注册用户如何防止缓存穿透? 先说明用户注册为什么会发送缓存穿透:用户注册时,需要验证用户名是否已存在,先查缓存,没有再查数据库,还没有才验证通过。高并发的情况下就可能有大量用户同时注册,…...

Presto基础知识
Presto缓存 引入Presto缓存之前 BackgroundHiveSplitLoader 使用底层的文件系统直接进行数据的读写; 引入Presto缓存机制之后,底层的文件系统被被CachingFileSystem 代理一层 CachingFileSystem 有两个子类,根据你选用的底层缓存引擎的不同…...

Ajax + Easy Excel 通过Blob实现导出excel
前端代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><script src"./js/jquery-3.6.0.min.js"></script></head><body><div><button onclick"exportF…...

Qt+qss动态属性改变控件状态切换的样式
先说点基础的吧,qt的样式实现,常见的主要有三种方式,分别为: 1.ui界面中右键样式表直接添加 2.代码中对控件设置样式setStyleSheet 3.外部预设好qss文件,代码中加载后设置样式 实际工作开发中,我推荐使用优…...

纷享销客安全体系:安全运维运营
安全运维运营(Security Operations,SecOps)是指在信息安全管理中负责监控、检测、响应和恢复安全事件的一系列运营活动。它旨在保护组织的信息系统和数据免受安全威胁和攻击的损害。 通过有效的安全运维运营,组织可以及时发现和应对安全威胁,减少安全事…...

富瀚微FH8322 ISP图像调试—BLC校正
1、简单介绍 目录 1、简单介绍 2、调试方法 3、输出结果 富瀚微平台调试有一段时间了,一直没有总结,我们调试ISP的时候,首先一步时确定好sensor的黑电平值,黑电平如果不准,则会影响到后面的颜色及对比度相关模块。…...
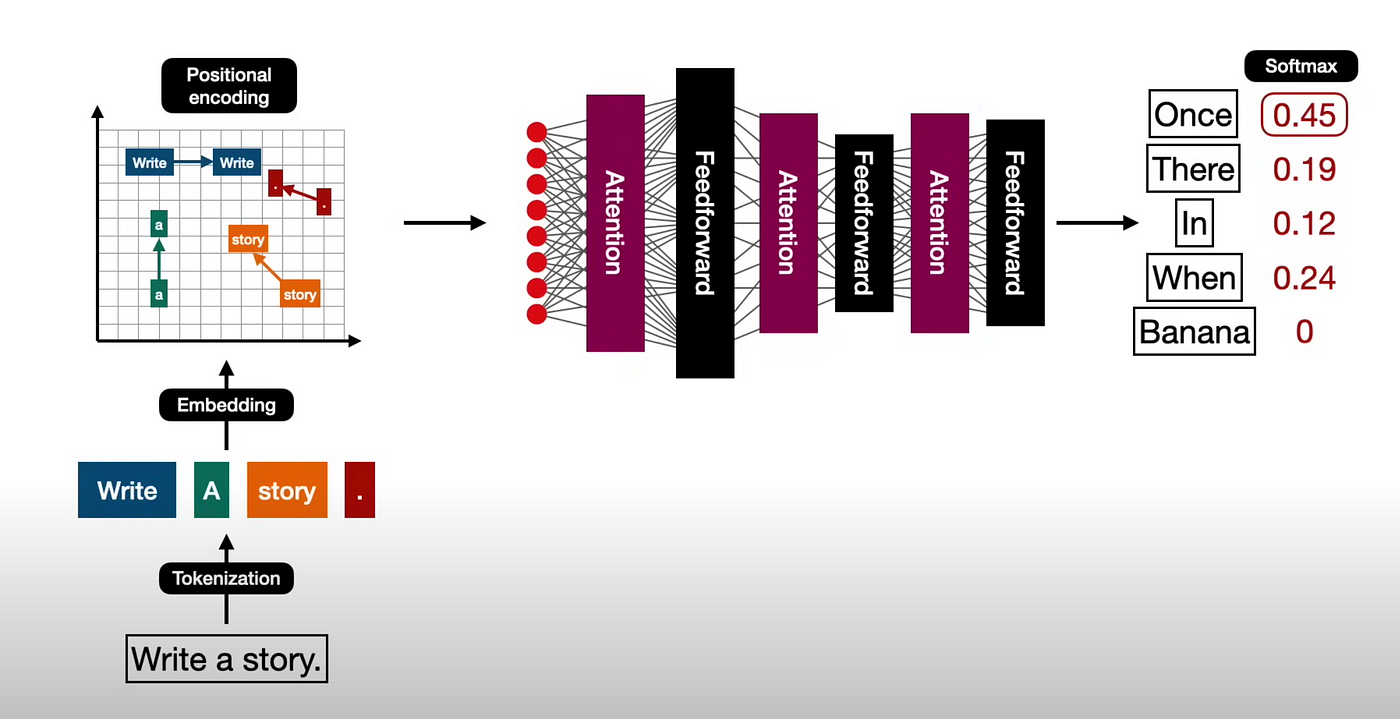
什么是大型语言模型 ?
引言 在本文[1]中,我们将从高层次概述大型语言模型 (LLM) 的具体含义。 背景 2023年11月,我偶然间听闻了OpenAI的开发者大会,这个大会展示了人工智能领域的革命性进展,让我深深着迷。怀着对这一领域的浓厚兴趣,我加入了…...
)
别再让FTP匿名登录成后门!手把手教你加固vsftpd服务(附CentOS 7实战配置)
企业级vsftpd安全加固实战指南:从匿名登录风险到全方位防护 FTP服务作为企业文件传输的经典解决方案,至今仍在许多组织的IT架构中扮演重要角色。然而,默认配置下的vsftpd服务往往隐藏着致命的安全隐患——匿名登录功能如同一扇未上锁的后门&a…...
)
WinForm弹窗进阶:手把手教你封装一个通用的MessageBoxHelper工具类(.NET Framework/C#)
WinForm弹窗进阶:打造高复用性的MessageBoxHelper工具类 在WinForm开发中,MessageBox.Show()就像空气一样无处不在——从简单的操作确认到复杂的错误处理,这个基础组件承担了太多交互职责。但当你第20次写下MessageBox.Show("操作成功&q…...

深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术
深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术 【免费下载链接】battery-charging-data-of-on-road-electric-vehicles This repository is transfered from the personal account of Dr. Zhognwei Deng (Michael Teng) 项目地址: …...

Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 [特殊字符]
Meshroom终极指南:免费开源3D重建软件,从照片到三维模型的完整解决方案 🚀 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款革命性的开源3D重…...

基于SpringBoot的核酸检测与报告查询系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的核酸检测与报告查询系统以解决当前核酸检测流程中存在的信息孤岛现象数据分散管理问题以及传统人工操作导致的效率低下…...

ESP8266+STM32远程控制实战:如何通过华为云中转指令与数据
ESP8266STM32远程控制实战:华为云物联网全链路开发指南 在智能家居和工业监控领域,远程设备控制一直是核心技术痛点。当ESP8266遇上STM32,再通过华为云物联网平台搭建通信桥梁,这个组合能爆发出怎样的生产力?本文将带您…...
OpenMMLab MMTracking 目标跟踪算法库
MMTracking是OpenMMLab(商汤科技与港中文MMLab联合推出)体系下的一款开源视频目标感知工具箱。你可以把它理解为“视频版”的MMDetection,它将该领域内纷繁复杂的算法、数据集和评估标准,统一整合到了一个高效、模块化的框架中。 …...

【DeepSeek API接入实战指南】:20年架构师亲授5大避坑法则与3小时极速接入方案
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API接入开发教程 DeepSeek 提供了稳定、高性能的大模型 API 接口,支持文本生成、对话补全与函数调用等多种能力。开发者需通过 RESTful 方式调用其 OpenAPI v1 接口,所…...

嵌入式开发中的编程规范实践与行业标准解析
1. 编程规范的本质与价值在嵌入式汽车电子领域干了十五年,我见过太多因为代码不规范导致的惨痛教训。有一次,某车企的ECU控制模块在零下30度环境突然死机,排查三周后发现是未初始化的指针在低温环境下产生了非预期行为——这种问题本可以通过…...

如何在5分钟内快速上手LeRobot机器人AI控制框架:从零到一的完整指南
如何在5分钟内快速上手LeRobot机器人AI控制框架:从零到一的完整指南 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 还在为…...