大模型基础——从零实现一个Transformer(3)
大模型基础——从零实现一个Transformer(1)-CSDN博客
一、前言
之前两篇文章已经讲了Transformer的Embedding,Tokenizer,Attention,Position Encoding,
本文我们继续了解Transformer中剩下的其他组件.
二、归一化
2.1 Layer Normalization

layerNorm是针对序列数据提出的一种归一化方法,主要在layer维度进行归一化,即对整个序列进行归一化。
layerNorm会计算一个layer的所有activation的均值和方差,利用均值和方差进行归一化。
𝜇=∑𝑖=1𝑑𝑥𝑖
𝜎=1𝑑∑𝑖=1𝑑(𝑥𝑖−𝜇)2
归一化后的激活值如下:
𝑦=𝑥−𝜇𝜎+𝜖𝛾+𝛽
其中 𝛾 和 𝛽 是可训练的模型参数。 𝛾 是缩放参数,新分布的方差 𝛾2 ; 𝛽 是平移系数,新分布的均值为 𝛽 。 𝜖 为一个小数,添加到方差上,避免分母为0。
2.2 LayerNormalization 代码实现
import torch
import torch.nn as nnclass LayerNorm(nn.Module):def __init__(self,num_features,eps=1e-6):super().__init__()self.gamma = nn.Parameter(torch.ones(num_features))self.beta = nn.Parameter(torch.zeros(num_features))self.eps = epsdef forward(self,x):"""Args:x (Tensor): (batch_size, seq_length, d_model)Returns:Tensor: (batch_size, seq_length, d_model)"""mean = x.mean(dim=-1,keepdim=True)std = x.std(dim=-1,keepdim=True,unbiased=False)normalized_x = (x - mean) / (std + self.eps)return self.gamma * normalized_x + self.betaif __name__ == '__main__':batch_size = 2seqlen = 3hidden_dim = 4# 初始化一个随机tensorx = torch.randn(batch_size,seqlen,hidden_dim)print(x)# 初始化LayerNormlayer_norm = LayerNorm(num_features=hidden_dim)output_tensor = layer_norm(x)print("output after layer norm:\n,",output_tensor)torch_layer_norm = torch.nn.LayerNorm(normalized_shape=hidden_dim)torch_output_tensor = torch_layer_norm(x)print("output after torch layer norm:\n",torch_output_tensor)三、残差连接
残差连接(residual connection,skip residual,也称为残差块)其实很简单

x为网络层的输入,该网络层包含非线性激活函数,记为F(x),用公式描述的话就是:

代码简单实现
x = x + layer(x)四、前馈神经网络
4.1 Position-wise Feed Forward
Position-wise Feed Forward(FFN),逐位置的前馈网络,其实就是一个全连接前馈网络。目的是为了增加非线性,增强模型的表示能力。
它一个简单的两层全连接神经网络,不是将整个嵌入序列处理成单个向量,而是独立地处理每个位置的嵌入。所以称为position-wise前馈网络层。也可以看为核大小为1的一维卷积。
目的是把输入投影到特定的空间,再投影回输入维度。
FFN具体的公式如下:
𝐹𝐹𝑁(𝑥)=𝑓(𝑥𝑊1+𝑏1)𝑊2+𝑏2
上述公式对应FFN中的向量变换操作,其中f为非线性激活函数。
4.2 FFN代码实现
from torch import nn,Tensor
from torch.nn import functional as Fclass PositonWiseFeedForward(nn.Module):def __init__(self,d_model:int ,d_ff: int ,dropout: float=0.1) -> None:''':param d_model: dimension of embeddings:param d_ff: dimension of feed-forward network:param dropout: dropout ratio'''super().__init__()self.ff1 = nn.Linear(d_model,d_ff)self.ff2 = nn.Linear(d_ff,d_model)self.dropout = nn.Dropout(dropout)def forward(self,x: Tensor) -> Tensor:''':param x: (batch_size, seq_length, d_model) output from attention:return: (batch_size, seq_length, d_model)'''return self.ff2(self.dropout(F.relu(self.ff1(x))))五、Transformer Encoder Block

如图所示,编码器(Encoder)由N个编码器块(Encoder Block)堆叠而成,我们依次实现。
from torch import nn,Tensor
## 之前实现的函数引入
from llm_base.attention.MultiHeadAttention1 import MultiHeadAttention
from llm_base.layer_norm.normal_layernorm import LayerNorm
from llm_base.ffn.PositionWiseFeedForward import PositonWiseFeedForwardfrom typing import *class EncoderBlock(nn.Module):def __init__(self,d_model: int,n_heads: int,d_ff: int,dropout: float,norm_first: bool = False):''':param d_model: dimension of embeddings:param n_heads: number of heads:param d_ff: dimension of inner feed-forward network:param dropout:dropout ratio:param norm_first : if True, layer norm is done prior to attention and feedforward operations(Pre-Norm).Otherwise it's done after(Post-Norm). Default to False.'''super().__init__()self.norm_first = norm_firstself.attention = MultiHeadAttention(d_model,n_heads,dropout)self.norm1 = LayerNorm(d_model)self.ff = PositonWiseFeedForward(d_model,d_ff,dropout)self.norm2 = LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)# self attention sub layerdef _self_attention_sub_layer(self,x: Tensor, attn_mask: Tensor, keep_attentions: bool) -> Tensor:x = self.attention(x,x,x,attn_mask,keep_attentions)return self.dropout1(x)# ffn sub layerdef _ffn_sub_layer(self,x: Tensor) -> Tensor:x = self.ff(x)return self.dropout2(x)def forward(self,src: Tensor,src_mask: Tensor == None,keep_attentions: bool= False) -> Tuple[Tensor,Tensor]:''':param src: (batch_size, seq_length, d_model):param src_mask: (batch_size, 1, seq_length):param keep_attentions:whether keep attention weigths or not. Defaults to False.:return:(batch_size, seq_length, d_model) output of encoder block'''# pass througth multi-head attention# src (batch_size, seq_length, d_model)# attn_score (batch_size, n_heads, seq_length, k_length)x = src# post LN or pre LNif self.norm_first:# pre LNx = x + self._self_attention_sub_layer(self.norm1(x),src_mask,keep_attentions)x = x + self._ffn_sub_layer(self.norm2(x))else:x = self.norm1(x + self._self_attention_sub_layer(x,src_mask,keep_attentions))x = self.norm2(x + self._ffn_sub_layer(x))return x
5.1 Post Norm Vs Pre Norm
公式区别
Pre Norm 和 Post Norm 的式子分别如下:

在大模型的区别
Post-LN :是在 Transformer 的原始版本中使用的归一化方案。在此方案中,每个子层(例如,自注意力机制或前馈网络)的输出先通过子层自身的操作,然后再通过层归一化(Layer Normalization)
Pre-LN:是先对输入进行层归一化,然后再传递到子层操作中。这样的顺序对于训练更深的网络可能更稳定,因为归一化的输入可以帮助缓解训练过程中的梯度消失和梯度爆炸问题。

5.2为什么Pre效果弱于Post

相关文章:
大模型基础——从零实现一个Transformer(3)
大模型基础——从零实现一个Transformer(1)-CSDN博客 一、前言 之前两篇文章已经讲了Transformer的Embedding,Tokenizer,Attention,Position Encoding, 本文我们继续了解Transformer中剩下的其他组件. 二、归一化 2.1 Layer Normalization layerNorm是针对序列数据提出的一种…...

一二三应用开发平台应用开发示例——概述、应用开发示例简介及创建前后端模块
概述 对于应用开发平台的核心基石——系统管理模块,我精心撰写了一份详尽的说明手册。该手册旨在从使用者的角度出发,不仅全面阐述系统的各项属性和功能,更着重强调使用过程中的注意事项和最佳实践。 在手册的编写过程中,我特别…...

springboot+minio+kkfileview实现文件的在线预览
在原来的文章中已经讲述过springbootminio的开发过程,这里不做讲述。 原文章地址: https://blog.csdn.net/qq_39990869/article/details/131598884?spm1001.2014.3001.5501 如果你的项目只是需要在线预览图片或者视频那么可以使用minio自己的预览地址进…...

HTML5+CSS3小实例:粘性文字的滚动效果
实例:粘性文字的滚动效果 技术栈:HTML+CSS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-sca…...

Java 关于抽象 -- Java 语言的抽象类、接口和函数式接口
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 008 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自…...

用 Notepad++ 写 Java 程序
安装包 百度网盘 提取码:6666 安装步骤 双击安装包开始安装。 安装完成: 配置编码 用 NotePad 写 Java 程序时,需要设置编码。 在 设置,首选项,新建 中进行设置,可以对每一个新建的文件起作用。 Note…...

malloc brk mmap
malloc 是一个库函数,通常在 C 标准库中实现,用于动态内存分配。malloc 的具体实现可能因库、操作系统和平台而异,但通常它会与底层操作系统提供的内存管理功能进行交互。 对于大多数现代操作系统(如 Unix、Linux、Windows 等&am…...

java多线程相关概念
在Java多线程编程中,有几个关键的术语需要理解: 1.线程(Thread):线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。 2.进程(Process):进程是系统进行资源分配和调度…...

【html】简单网页模板源码
大家每一次在写网页的时候会不会因为布局而困扰今天就给大家带来一个我自己亲自编写的网页的基本的模板大家可以直接去利用,大家也可以利用自己的想法去做空间的美化和完善。 源码: html: <!DOCTYPE html> <html lang"zh"><…...
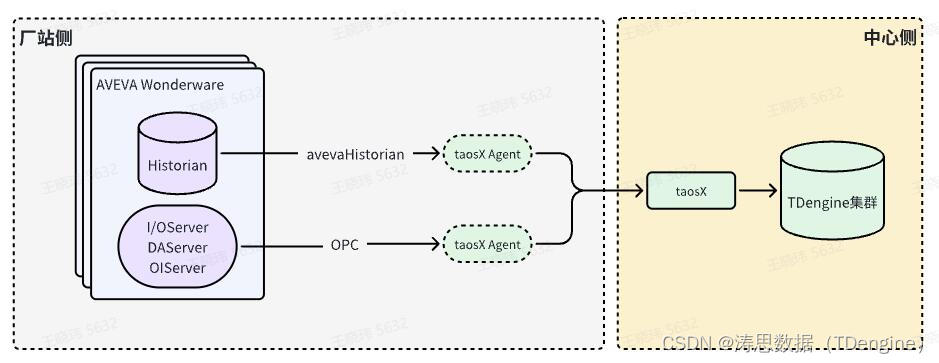
借助Historian Connector + TDengine,打造工业创新底座
在工业自动化的领域中,数据的采集、存储和分析是实现高效决策和操作的基石。AVEVA Historian (原 Wonderware Historian) 作为领先的工业实时数据库,专注于收集和存储高保真度的历史工艺数据。与此同时,TDengine 作为一款专为时序数据打造的高…...

51单片机-实机演示(LED点阵)
目录 前言: 一.线位置 二.扩展 三.总结 前言: 这是一篇关于51单片机实机LED点阵的插线图和代码说明.另外还有一篇我写的仿真的连接在这:http://t.csdnimg.cn/ZNLCl,欢迎大家的点赞,评论,关注. 一.线位置 接线实机图. 引脚位置注意: 1. *-* P00->RE8 P01->RE7 …...

STM32硬件接口I2C应用(基于MP6050)
目录 概述 1 STM32Cube控制配置I2C 1.1 I2C参数配置 1.2 使用STM32Cube产生工程 2 HAL库函数介绍 2.1 初始化函数 2.2 写数据函数 2.3 读数据函数 3 认识MP6050 3.1 MP6050功能介绍 3.2 加速计测量寄存器 编辑3.3 温度计量寄存器 3.4 陀螺仪测量寄存器 4 MP60…...
基于JSP的贝儿米幼儿教育管理系统
开头语: 你好呀,我是计算机学长猫哥!如果您对本系统感兴趣或者有相关需求,文末可以找到我的联系方式。 开发语言: Java 数据库: MySQL 技术: JSP技术 工具: IDEA/Eclipse、…...

数字化与文化交融,树莓集团助力园区文化升级
树莓集团在产业园运营领域建设了特色空间布局,包括产业实训基地、产业办公中心、业务资源平台、产学研中心、数字资产空间、双创孵化空间、产业实验室和人才项目转化中心等八大板块,共同构建了一个全面而深入的产业支撑体系,为园区文化建设提…...
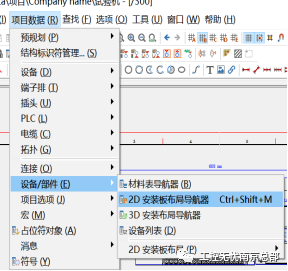
【原创课程】如何制作安装板
具体步骤如下: 第一步:新建页类型为“安装板布局图(交互式)”并修改页描述为“安装板布局图”。 第二步:新建安装板 第三步:设置图纸上符号元件的部件,双击符号,弹出常规设备窗口,点击部件进行选择 第四步:打开2D安装板导航器,将图纸中的设备拖拽到安装板上 第五步…...

简单聊聊【java.util.Stream】,更新中
public class Main {public static void main(String[] args) {List<Integer> numbers Arrays.asList(1, 2, 3, 4, 5, 6); // 原始容器:java.util.Arrays.ArrayList#ArrayList// 创建一个 Stream,过滤出偶数,并打印它们numbers.str…...
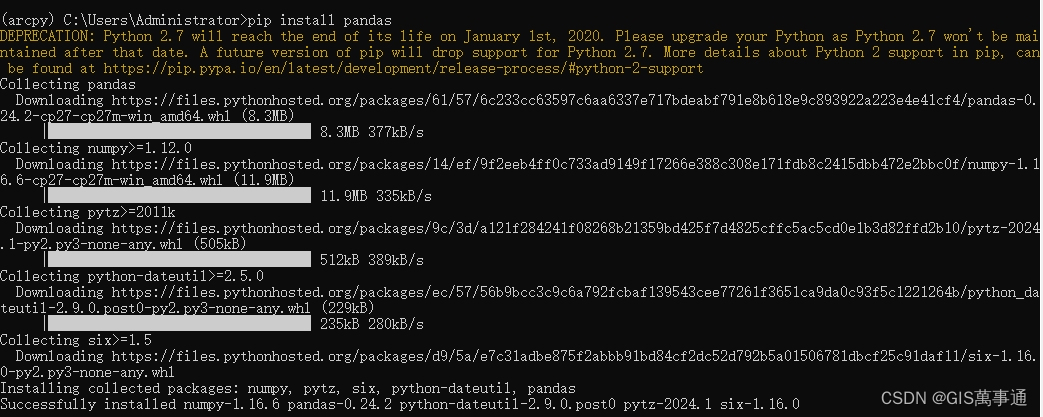
GIS之arcgis系列07:conda环境下安装arcpy环境
首先将python27环境下的“Desktop10.8.pth”拷贝到anaconda环境下。 路径如下(仅参考): C:\Python27\ArcGIS10.8\Lib\site-packages\Desktop10.8.pth D:\Anaconda\Lib\site-packages 在anaconda prompt中穿创建一个新环境 conda create -…...
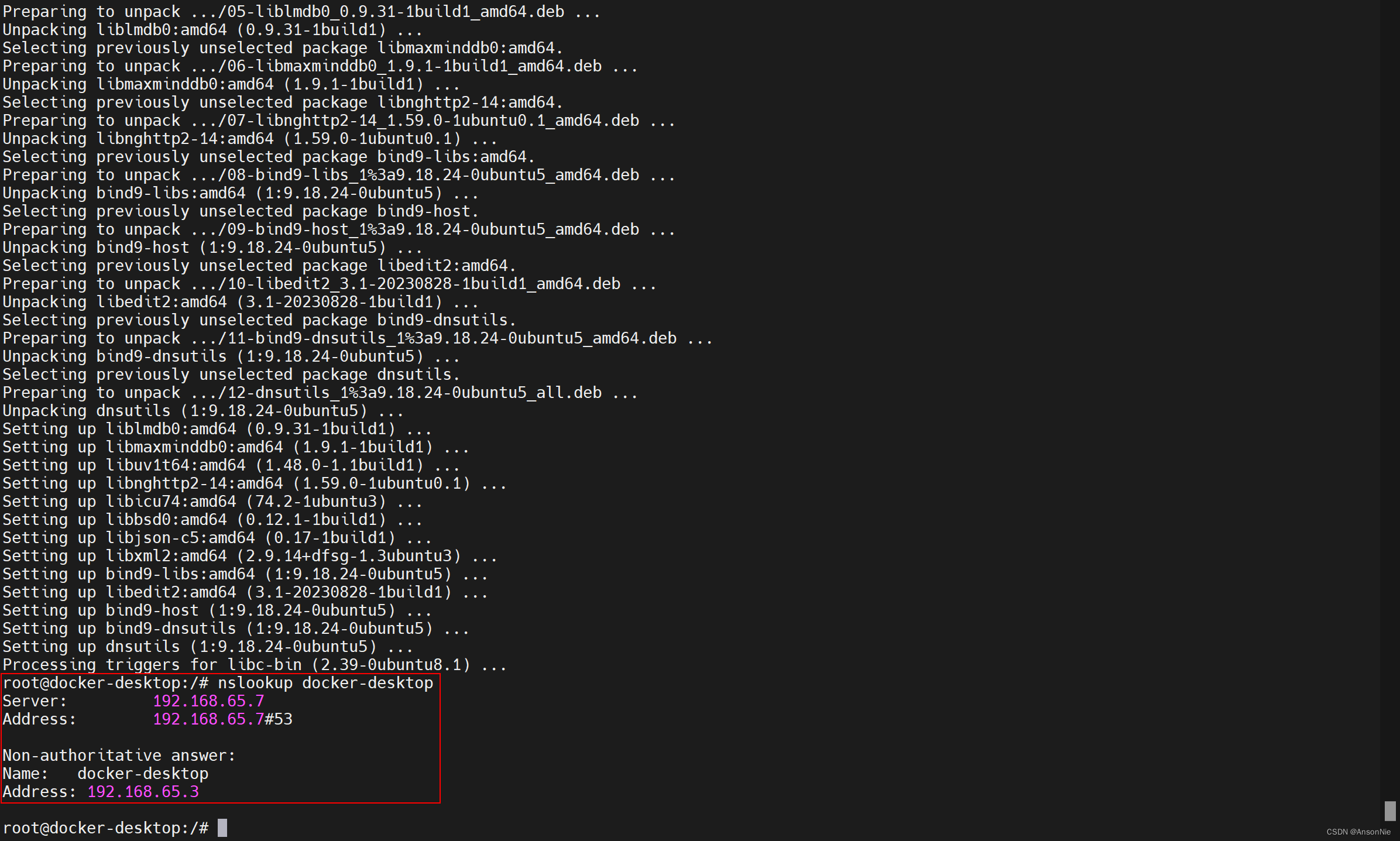
容器运行nslookup提示bash: nslookup: command not found【笔记】
在容器中提示bash: nslookup: command not found,表示容器中没有安装nslookup命令。 可以通过以下命令安装nslookup: 对于基于Debian/Ubuntu的容器,使用以下命令: apt-get update apt-get install -y dnsutils对于基于CentOS/R…...

解析 Spring 框架中的三种 BeanName 生成策略
在 Spring 框架中,定义 Bean 时不一定需要指定名称,Spring 会智能生成默认名称。本文将介绍 Spring 的三种 BeanName 生成器,包括在 XML 配置、Java 注解和组件扫描中使用的情况,并解释它们如何自动创建和管理 Bean 名称。 1. Be…...
细说ARM MCU的串口接收数据的实现过程
目录 一、硬件及工程 1、硬件 2、软件目的 3、创建.ioc工程 二、 代码修改 1、串口初始化函数MX_USART2_UART_Init() (1)MX_USART2_UART_Init()串口参数初始化函数 (2)HAL_UART_MspInit()串口功能模块初始化函数 2、串口…...

BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃?
BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃? 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager BG3ModMana…...

API中转站稳定性怎么判断?中小企业选平台别只看SLA数字
API中转站稳定性怎么判断?中小企业选平台别只看SLA数字 摘要 :选择Claude API中转站时,稳定性是核心考量。但"稳定"对不同用户含义不同,本文从不同用户视角分析如何评估API中转站的稳定性。 中转站稳定吗 稳定是相对的&…...

SmartNIC如何优化AI流水线与网络计算卸载
1. SmartNIC与AI流水线的联姻:网络计算卸载的技术革命 在分布式AI推理场景中,我们常常遇到一个令人头疼的现象:当GPU计算单元满载运行时,CPU利用率也常常飙升至90%以上。这种资源争用并非来自模型推理本身,而是源于那些…...

可观测性技术栈选型指南:从Prometheus到OpenTelemetry的实践路径
1. 项目概述:一个可观测性技术栈的“藏宝图”如果你正在构建或维护一个现代化的、需要高可靠性的软件系统,那么“可观测性”这个词对你来说一定不陌生。它早已超越了传统的监控,成为确保系统健康、快速定位问题的核心能力。然而,当…...

Yaskawa JACP-317800输入输出模块
安川JACP-317800是一款高性能逻辑输入输出模块,隶属于安川CP-317系列PLC系统,专为工业自动化领域的数字信号采集与控制而设计。产品特点:产品类型为逻辑输入输出模块,作为PLC与现场设备之间的信号接口模块重量仅0.3公斤࿰…...

Python爬虫实战:构建智能职位信息聚合工具JobClaw
1. 项目概述:一个面向开发者的智能职位信息聚合与解析工具最近在帮团队招聘和看机会的朋友聊天,发现一个挺普遍的问题:大家找技术岗位,要么在几个主流招聘App上反复刷,信息分散且格式不一;要么就是盯着几个…...

共筑智能传播信息安全域,新华社国家重点实验室与北京时光不语达成合作
新华社媒体融合生产技术与系统国家重点实验室与北京时光不语科技有限公司(TIMUS.AI)正式建立研发生态伙伴关系,并联合推出面向智能传播环境的“新华智信感知平台”,深化智能传播领域科研创新与成果转化,共同构建负责任…...
)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码) 在QT开发中,QComboBox可能是最容易被低估的控件之一。很多开发者仅仅把它当作一个简单的下拉选择框,用addItem()填充几个静态选项就草草了事。但实…...

AI大模型学习路线!手把手带你入门_AI大模型学习路线及相关资源推荐
本文详细介绍了AI大模型的基础信息、主要特点、类型,并提供了完整的学习路线图及丰富资源。内容涵盖数学、编程、机器学习、深度学习、自然语言处理等基础知识,以及Transformer模型、预训练模型等核心技术。此外,还强调了理论学习、实践操作和…...

从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设
从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设 在FPGA和数字IC设计领域,AMBA总线协议就像城市中的交通网络,负责协调各个功能模块之间的数据流动。而APB(Advanced Peripheral Bus)作为AMBA家族…...