助力草莓智能自动化采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建果园种植采摘场景下草莓成熟度智能检测识别系统
随着科技的飞速发展,人工智能(AI)技术已经渗透到我们生活的方方面面,从智能家居到自动驾驶,再到医疗健康,其影响力无处不在。然而,当我们把目光转向中国的农业领域时,一个令人惊讶的事实映入眼帘——在这片广袤的土地上,农业生产仍然大量依赖人力,而非智能机械化。与此同时,国外的农业生产模式早已进入全面机械化的新时代。面对这一现状,我们不禁要思考:如何将AI技术融入农业,引领农业生产走向数字化、智能化?
草莓的采摘是农业生产中的一项重要工作,其效率和质量直接影响到产品的市场竞争力。传统的采摘方式主要依赖人力,存在诸多问题:一是效率低下,难以满足大规模生产的需求;二是成本高昂,增加了产品的成本;三是随着人口老龄化,劳动力短缺问题日益严重,使得采摘工作更加困难。因此,探索草莓采摘的智能化解决方案显得尤为重要。深度学习技术的快速发展为草莓采摘的智能化提供了可能。通过结合机械设计和AI智能模型,我们可以实现采摘的完全智能机械化。具体来说,智能采摘系统可以通过前端连接的摄像头对果树上的果实进行实时检测识别。利用深度学习算法,系统能够准确地分辨出已经成熟和未成熟的果实,并根据果实的成熟度进行分拣。一旦识别出成熟的果实,系统便会将信号传递给机械臂,机械臂则会自动完成采摘动作。智能采摘系统大大提高了采摘效率,减少了人力成本;其次,由于机械臂的精准操作,可以减少对果树的伤害,保护果树资源;此外,智能采摘系统还可以根据果实的成熟度进行分拣,提高产品的品质和市场竞争力。
本文正是基于这样的背景思考下,想要从软件实验实践分析的角度出发,来实际探索分析此举落地应用的可行性,在前面系列博文中,我们已经进行了一些实践工作,感兴趣的话可以自行移步阅读即可:
《助力草莓智能自动化采摘,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建果园种植采摘场景下草莓成熟度智能检测识别系统》
本文则是相应基于经典的YOLOv5来完成相应的实践开发,首先看下实例效果:
接下来简单看下实例数据集:


本文是选择的是YOLOv5算法模型来完成本文项目的开发构建。相较于前两代的算法模型,YOLOv5可谓是集大成者,达到了SOTA的水平,下面简单对v3-v5系列模型的演变进行简单介绍总结方便对比分析学习:
【YOLOv3】
YOLOv3(You Only Look Once version 3)是一种基于深度学习的快速目标检测算法,由Joseph Redmon等人于2018年提出。它的核心技术原理和亮点如下:
技术原理:
YOLOv3采用单个神经网络模型来完成目标检测任务。与传统的目标检测方法不同,YOLOv3将目标检测问题转化为一个回归问题,通过卷积神经网络输出图像中存在的目标的边界框坐标和类别概率。
YOLOv3使用Darknet-53作为骨干网络,用来提取图像特征。检测头(detection head)负责将提取的特征映射到目标边界框和类别预测。
亮点:
YOLOv3在保持较高的检测精度的同时,能够实现非常快的检测速度。相较于一些基于候选区域的目标检测算法(如Faster R-CNN、SSD等),YOLOv3具有更高的实时性能。
YOLOv3对小目标和密集目标的检测效果较好,同时在大目标的检测精度上也有不错的表现。
YOLOv3具有较好的通用性和适应性,适用于各种目标检测任务,包括车辆检测、行人检测等。
【YOLOv4】
YOLOv4是一种实时目标检测模型,它在速度和准确度上都有显著的提高。相比于其前一代模型YOLOv3,YOLOv4在保持较高的检测精度的同时,还提高了检测速度。这主要得益于其采用的CSPDarknet53网络结构,主要有三个方面的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。YOLOv4的目标检测策略采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。这种方法不需要额外再设计一个区域提议网络(RPN),从而减少了训练的负担。然而,尽管YOLOv4在许多方面都表现出色,但它仍然存在一些不足。例如,小目标检测效果较差。此外,当需要在资源受限的设备上部署像YOLOv4这样的大模型时,模型压缩是研究人员重新调整较大模型所需资源消耗的有用工具。
优点:
速度:YOLOv4 保持了 YOLO 算法一贯的实时性,能够在检测速度和精度之间实现良好的平衡。
精度:YOLOv4 采用了 CSPDarknet 和 PANet 两种先进的技术,提高了检测精度,特别是在检测小型物体方面有显著提升。
通用性:YOLOv4 适用于多种任务,如行人检测、车辆检测、人脸检测等,具有较高的通用性。
模块化设计:YOLOv4 中的组件可以方便地更换和扩展,便于进一步优化和适应不同场景。
缺点:
内存占用:YOLOv4 模型参数较多,因此需要较大的内存来存储和运行模型,这对于部分硬件设备来说可能是一个限制因素。
训练成本:YOLOv4 模型需要大量的训练数据和计算资源才能达到理想的性能,这可能导致训练成本较高。
精确度与速度的权衡:虽然 YOLOv4 在速度和精度之间取得了较好的平衡,但在极端情况下,例如检测高速移动的物体或复杂背景下的物体时,性能可能会受到影响。
误检和漏检:由于 YOLOv4 采用单一网络对整个图像进行预测,可能会导致一些误检和漏检现象。
【YOLOv5】
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
技术原理:
YOLOv5同样采用单个神经网络模型来完成目标检测任务,但采用了新的神经网络架构,融合了领先的轻量级模型设计理念。YOLOv5使用较小的骨干网络和新的检测头设计,以实现更快的推断速度,并在不降低精度的前提下提高目标检测的准确性。
亮点:
YOLOv5在模型结构上进行了改进,引入了更先进的轻量级网络架构,因此在速度和精度上都有所提升。
YOLOv5支持更灵活的模型大小和预训练选项,可以根据任务需求选择不同大小的模型,同时提供丰富的数据增强扩展、模型集成等方法来提高检测精度。YOLOv5通过使用更简洁的代码实现,提高了模型的易用性和可扩展性。
训练数据配置文件如下:
# Dataset
path: ./dataset
train:- images/train
val:- images/test
test:- images/test# Classes
names:0: ripe1: unripe实验截止目前,本文将YOLOv5系列五款不同参数量级的模型均进行了开发评测,接下来看下模型详情:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.33, 1.25, 1024]# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)]在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待漫长的训练完成后,来整体进行评测对比分析。
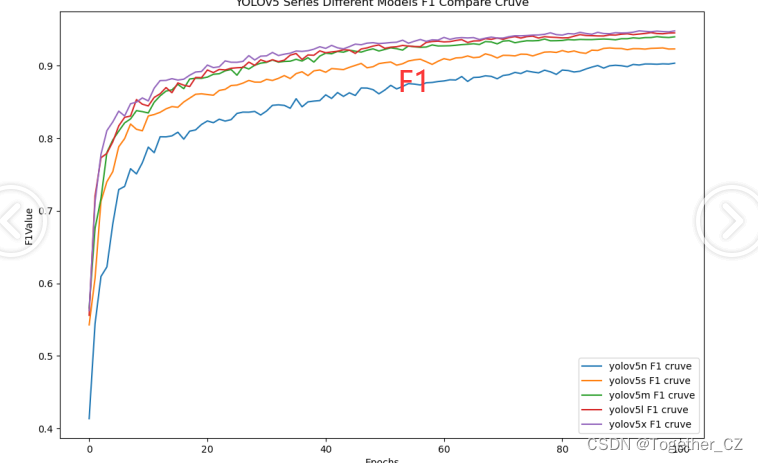
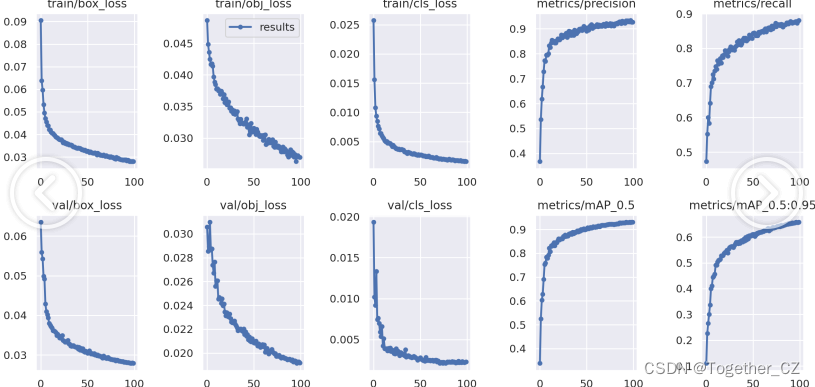
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
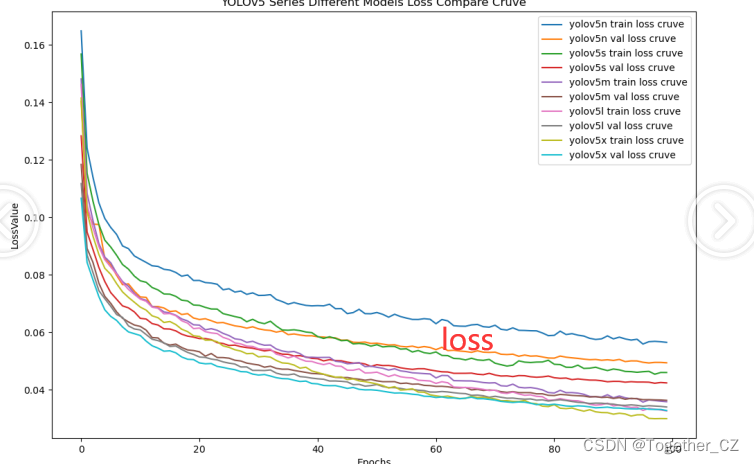
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
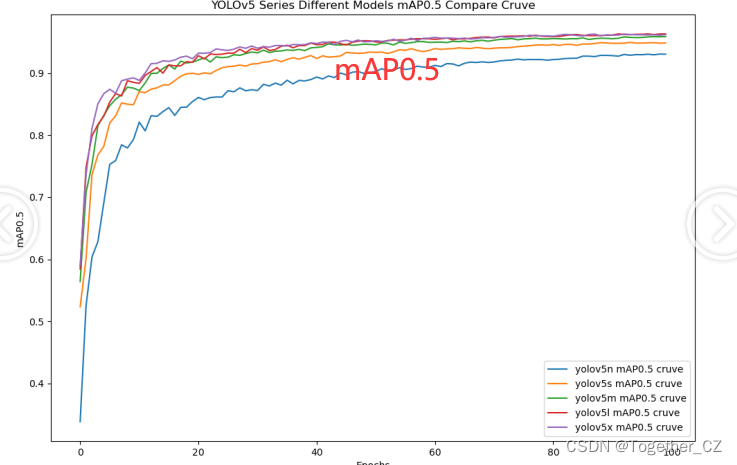
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。

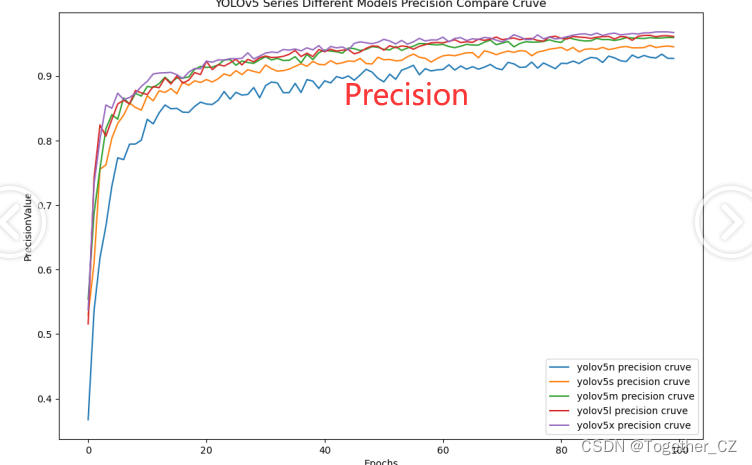
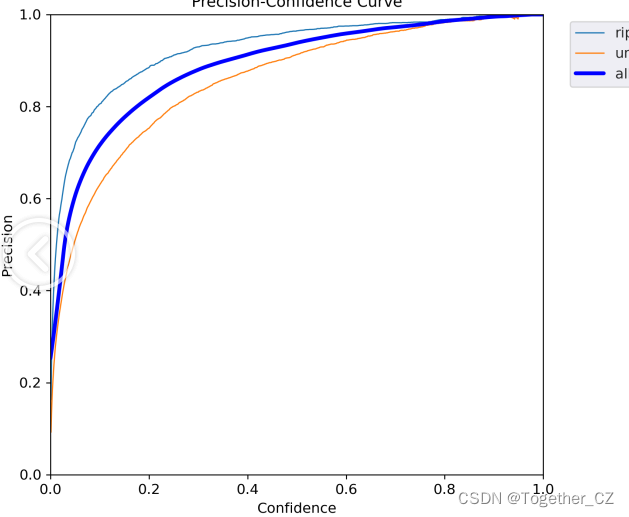
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。

整体5款模型对比结果来看,n系列的模型效果最差,s系列模型效果次之,m系列模型效果略逊于l和x两款模型,l和x两款模型则达到了十分相近的效果,这里我们综合考虑使用m系列的模型作为最终的推理模型。
接下来看下m系列模型的详情。
【离线推理实例】

【热力图可视化】

【Batch实例】

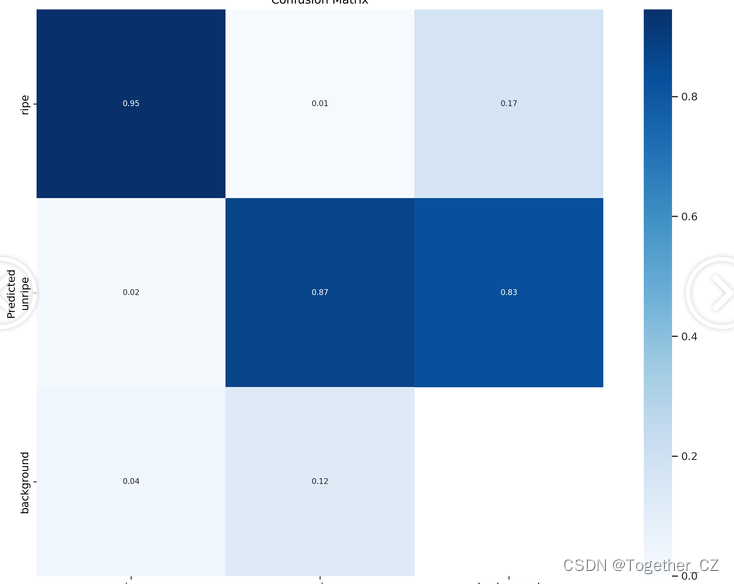
【混淆矩阵】
【F1值曲线】

【Precision曲线】
【Recall曲线】

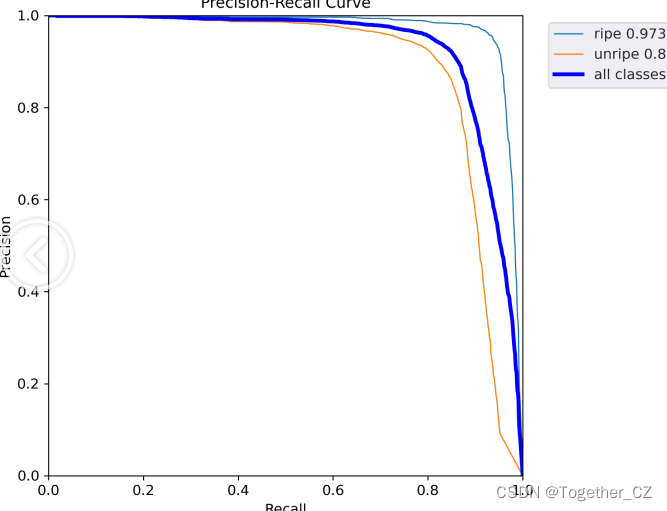
【PR曲线】
【训练可视化】
通过对草莓采摘智能化的探索和实践分析,我们可以看到AI技术在农业领域具有巨大的潜力和应用价值。通过结合机械设计和AI智能模型,我们可以实现采摘的完全智能机械化,提高采摘效率和质量,降低人力成本。未来,随着技术的不断进步和应用场景的拓展,AI技术将在农业领域发挥更加重要的作用,推动农业生产向数字化、智能化方向发展。
本文也仅作为抛砖引玉,智能机械化是农业生产未来的发展方向。通过结合机械设计和AI技术,我们可以实现农业生产的智能化,推动农业生产向数字化、智能化迈进。让我们共同期待这一天的到来!
相关文章:
助力草莓智能自动化采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建果园种植采摘场景下草莓成熟度智能检测识别系统
随着科技的飞速发展,人工智能(AI)技术已经渗透到我们生活的方方面面,从智能家居到自动驾驶,再到医疗健康,其影响力无处不在。然而,当我们把目光转向中国的农业领域时,一个令人惊讶的…...

C++中的生成器模式
目录 生成器模式(Builder Pattern) 实际应用 构建一辆汽车 构建一台计算机 构建一个房子 总结 生成器模式(Builder Pattern) 生成器模式是一种创建型设计模式,它允许你分步骤创建复杂对象。与其他创建型模式不同…...

基于python的PDF文件解析器汇总
基于python的PDF文件解析器汇总 大多数已发表的科学文献目前以 PDF 格式存在,这是一种轻量级、普遍的文件格式,能够保持一致的文本布局和格式。对于人类读者而言, PDF格式的文件内容展示整洁且一致的布局有助于阅读,可以很容易地…...
C++多线程同步总结
C多线程同步总结 关于C多线程同步 一、C11规范下的线程库 1、C11 线程库的基本用法:创建线程、分离线程 #include<iostream> #include<thread> #include<windows.h> using namespace std; void threadProc() {cout<<"this is in t…...

【机器学习】基于CNN-RNN模型的验证码图片识别
1. 引言 1.1. OCR技术研究的背景 1.1.1. OCR技术能够提升互联网体验 随着互联网应用的广泛普及,用户在日常操作中频繁遇到需要输入验证码的场景,无论是在登录、注册、支付还是其他敏感操作中,验证码都扮演着重要角色来确保安全性。然而&am…...

一文读懂Samtec分离式线缆组件选型 | 快速攻略
【摘要/前言】 2023年,全球线缆组件市场规模大致在2100多亿美元。汽车和电信行业是线缆组件最大的两个市场,中国和北美是最大的两个制造地区。有趣的是,特定应用(即定制)和矩形组件是两个最大的产品组。 【Samtec产品…...

批量申请SSL证书如何做到既方便成本又最低
假如您手头拥有1千个域名,并且打算为每一个域名搭建网站,那么在当前的网络环境下,您必须确保这些网站通过https的方式提供服务。这意味着,您将为每一个域名申请SSL证书,以确保网站数据传输的安全性和可信度。那么&…...
)
Python 设计模式(创建型)
文章目录 抽象工厂模式场景示例 单例模式场景实现方式 工厂方法模式场景示例 简单工厂模式场景示例 建造者模式场景示例 原型模式场景示例 抽象工厂模式 抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一种将一组相关…...

PyTorch 索引与切片-Tensor基本操作
以如下 tensor a 为例,展示常用的 indxing, slicing 及其他高阶操作 >>> a torch.rand(4,3,28,28) >>> a.shape torch.Size([4, 3, 28, 28])Indexing: 使用索引获取目标对象,[x,x,x,....] >>> a[0].shape torch.Size([3, 2…...

深入浅出 LangChain 与智能 Agent:构建下一代 AI 助手
我们小时候都玩过乐高积木。通过堆砌各种颜色和形状的积木,我们可以构建出城堡、飞机、甚至整个城市。现在,想象一下如果有一个数字世界的乐高,我们可以用这样的“积木”来构建智能程序,这些程序能够阅读、理解和撰写文本…...

scss是什么安装使⽤的步骤
当谈到SCSS时,我们首先需要了解它是什么。SCSS,也称为Sassy CSS,是Sass(Syntactically Awesome Stylesheets)的一种语法,它是CSS的预处理器,允许你使用变量、嵌套规则、混合(mixin&a…...

Pspark从hive读数据写到Pgsql数据库
前提条件 要使用PySpark从Hive读取数据并写入到PostgreSQL数据库,你需要确保以下几点: 你的PySpark环境已经配置好,并且能够连接到你的Hive数据。 PostgreSQL JDBC驱动程序已经添加到你的PySpark环境中。 你已经在PostgreSQL中创建好了相应…...

Pixi.js学习 (六)数组
目录 前言 一、数组 1.1 定义数组 1.2 数组存取与删除 1.3 使用数组统一操作敌机 二、实战 例题一:使用数组统一操作敌机 例题一代码: 总结 前言 为了提高作者的代码编辑水品,作者在使用博客的时候使用的集成工具为 HBuilderX。 下文所有截…...

操作系统复习-Linux的文件系统
文件系统概述 FAT FAT(File Allocation Table)FAT16、FAT32等,微软Dos/Windows使用的文件系统使用一张表保存盘块的信息 NTFS NTFS (New Technology File System)WindowsNT环境的文件系统NTFS对FAT进行了改进,取代了日的文件系统 EXT EXT(Extended…...

代码随想录算法训练营第三十六天| 860.柠檬水找零、 406.根据身高重建队列、 452. 用最少数量的箭引爆气球
LeetCode 860.柠檬水找零 题目链接:https://leetcode.cn/problems/lemonade-change/description/ 文章链接:https://programmercarl.com/0860.%E6%9F%A0%E6%AA%AC%E6%B0%B4%E6%89%BE%E9%9B%B6.html 思路 贪心算法:遇见20的时候有两种找零的…...

如何在C#中实现多线程
在C#中实现多线程有多种方式,包括使用System.Threading.Thread类、System.Threading.Tasks.Task类、System.Threading.Tasks.Parallel类以及异步编程模型(async和await)。下面我将为你展示每种方法的基本用法。 1. 使用System.Threading.Thread类 using System; using Syst…...

【LLM】快速了解Dify 0.6.10的核心功能:知识库检索、Agent创建和工作流编排(二)
【LLM】快速了解Dify 0.6.10的核心功能:知识库检索、Agent创建和工作流编排(二) 文章目录 【LLM】快速了解Dify 0.6.10的核心功能:知识库检索、Agent创建和工作流编排(二)一、创建一个简单的聊天助手&#…...

【介绍下Pandas,什么是Pandas?】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...

linux系统安装anaconda,并通过java程序调用python程序
虚拟环境准备 首先准备一块空的分区,安装anaconda至少要20g以上才能执行简单程序,这里准备20G的磁盘空间 创建分区,执行以下步骤,之后执行reboot重启 fdisk /dev/sda p n 回车 回车 w查看当前系统创建的分区,我这里是名为sda3的…...

Stable diffusion的SDXL模型,针不错!(含实操)
与之前的SD1.5大模型不同,这次的SDXL在架构上采用了“两步走”的生图方式: 以往SD1.5大模型,生成步骤为 Prompt → Base → Image,比较简单直接;而这次的SDXL大模型则是在中间加了一步 Refiner。Refiner的作用是什么呢…...

自治性、反应性、学习能力:AI Agent的关键特性
自治性、反应性、学习能力:AI Agent的关键特性——从蚂蚁觅食到通用智能体的进化之路 关键词 AI Agent, 自治性, 反应性, 强化学习, 记忆机制, 环境交互, 通用人工智能萌芽 摘要 想象一下:你有一个能自己帮你规划周末露营路线(自治性)、中途遇到暴雨自动切换到附近民宿…...

FinFET与FD-SOI工艺下的IC可靠性验证关键技术
1. 集成电路可靠性验证的挑战与演进在28nm工艺节点之前,芯片设计工程师面临的选择相对简单——只需沿着摩尔定律的轨迹向下一个工艺节点迁移。但随着FinFET和FD-SOI等新型晶体管结构的出现,以及台积电、三星等代工厂推出的多样化工艺节点选项,…...

网安信息收集
声明:任何个人和组织不得从事非法侵入他人网络、干扰他人网络正常功能、窃取网络数据等危害网络安全 的活动;不得提供专门用于从事侵入网络、干扰网络正常功能及防护措施、窃取网络数据等危害网络安全活动的程序、工具;明知他人从事危害网络安…...

【JVM】面试题-有哪些垃圾回收器
【JVM】面试题-有哪些垃圾回收器 在JVM的内存管理中,垃圾收集算法是内存回收的核心逻辑与方法论,而垃圾收集器则是将这套方法论落地实现的具体工具。 不同的垃圾收集器针对JVM堆的不同分代(新生代、老年代)设计,具备不…...

南京彩钢瓦屋面防水供应商
在南京,彩钢瓦屋面广泛应用于各类建筑,然而其防水问题一直是困扰众多业主的难题。选择一家靠谱的彩钢瓦屋面防水供应商至关重要。今天就为大家详细介绍雨中行修缮工程有限公司,同时也对比其他一些大厂,看看雨中行修缮为何能在市场…...

Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验
Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验 【免费下载链接】Windows11DragAndDropToTaskbarFix "Windows 11 Drag & Drop to the Taskbar (Fix)" fixes the missing "Drag & Drop to the Taskbar" support in Windows…...

ARM CoreSight DAP-Lite调试架构与双协议切换技术
1. ARM CoreSight DAP-Lite技术架构解析作为ARM调试体系的核心组件,DAP-Lite(Debug Access Port Lite)是嵌入式系统开发中连接调试工具与片上资源的桥梁。我在实际芯片调试中发现,这个仅约2mm面积的IP模块,却能实现传统…...

云端AI模型基准测试:从参数迷信到效能优先的选型实战
1. 项目概述:一次颠覆认知的云端AI模型基准测试作为一名长期在本地部署AI智能体(我用的是OpenClaw)的实践者,模型选型一直是我工作流中的核心决策。过去几个月,我默认使用的都是阿里云出品的qwen3.5:397b-cloud。这个模…...

在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用 将大模型能力集成到后端服务是现代应用开发的常见需求。对于Node.js开发…...

AI决策公平性:司法审查下的技术实践与算法治理
1. 项目概述:当算法成为“法官”,公平如何被审查?最近几年,我参与和观察了不少涉及算法决策的项目,从信贷审批到招聘筛选,再到内容推荐。一个越来越无法回避的问题是:当AI系统代替人类做出影响个…...