Flink Sql:四种Join方式详解(基于flink1.15官方文档)
JOINs
flink sql主要有四种连接方式,分别是Regular Joins、Interval Joins、Temporal Joins、lookup join
1、Regular Joins(常规连接 )
这种连接方式和hive sql中的join是一样的,包括inner join,left join,right join,full join
1、指定数据源建立students表
CREATE TABLE students (id STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置为最新生成的数据'format' = 'csv' -- 指定数据的格式
);2、kafka生产students表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班3、创建关联表scores
CREATE TABLE scores (sid STRING, cid STRING, --学科idscore INT
) WITH ('connector' = 'kafka','topic' = 'scores', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置'format' = 'csv' -- 指定数据的格式
);4、kafka生产scores数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,56
1500100002,1000001,139
1500100002,1000002,102
1500100004,1000001,42
1500100004,1000002,142-- inner jion 两边数据都不为null的才会关联
select
a.id,a.name,b.sid,b.score
from
students as a
inner join
scores as b
on a.id=b.sid;-- left join/right join 保证左边/右边数据的完整性
select
a.id,a.name,b.sid,b.score
from
students as a
right join
scores as b
on a.id=b.sid;-- full join 保证两边数据的完整性
select
a.id,a.name,b.sid,b.score
from
students as a
full join
scores as b
on a.id=b.sid;-- 注意:
-- 常规连接,会将两个表的数据一直保存在状态中,时间长了,状态会越来越大,导致任务执行失败,通常在批处理中使用,因为批处理没有状态这个概念。为了避免状态过大可能会导致的任务失败问题,我们可以设置状态有效期
-- 状态有效期,状态在flink中保存的时间,但是如果sql中除了关联操作还有聚合这样也需要将数据保存在状态中的操作,状态有效期设置的太短可能会让聚合这样的操作失败,设置的太长延迟也会增加。所以,状态保留多久需要根据实际业务分析
SET 'table.exec.state.ttl' = '20000';
设置该参数后,那么只有在20秒内到达的数据才会被保存到状态中进行关联。inner join结果:

left join 结果:
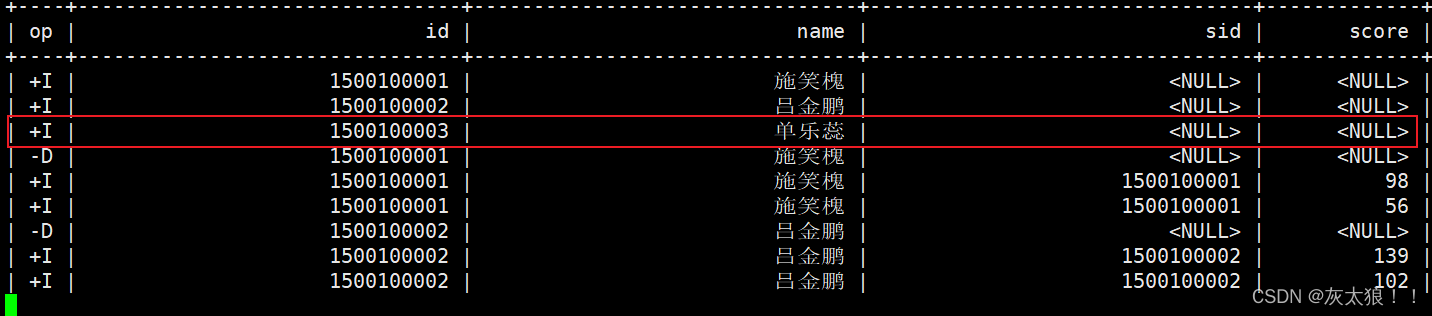
right join结果:

full join结果:
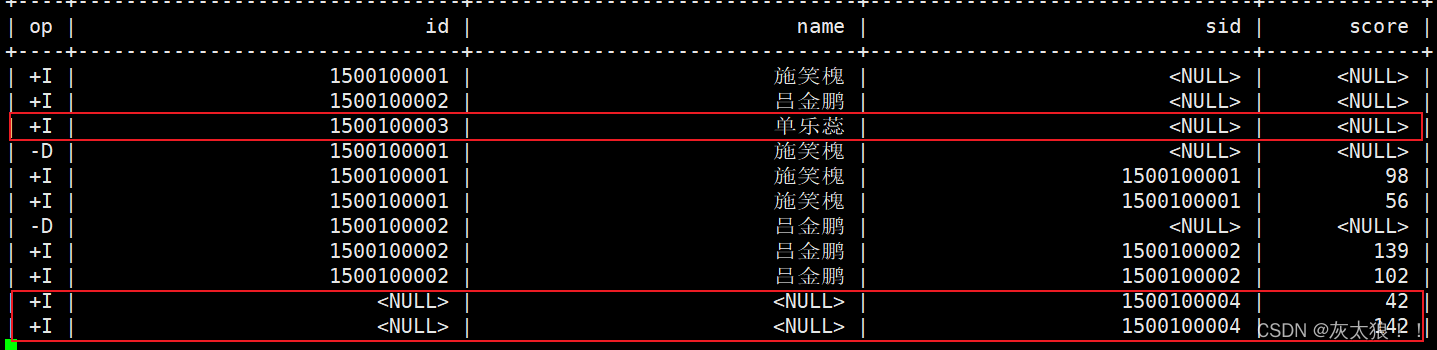
2、Interval Joins(间隔连接)
Interval Joins:在一段时间内关联
对于流式查询,与常规连接相比,间隔连接仅支持具有时间属性的追加表。由于时间属性是拟单调递增的,因此 Flink 可以从其状态中删除旧值,而不会影响结果的正确性。
这种方式可以变相弥补Regular Joins中时间长了状态过大的问题。
CREATE TABLE students_proctime (id STRING,name STRING,age INT,sex STRING,clazz STRING,proctime AS PROCTIME()
) WITH ('connector' = 'kafka','topic' = 'students', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置'format' = 'csv' -- 指定数据的格式
);kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班CREATE TABLE scores_proctime (sid STRING,cid STRING,score INT,proctime AS PROCTIME()
) WITH ('connector' = 'kafka','topic' = 'scores', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置'format' = 'csv' -- 指定数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,56
1500100002,1000001,139
1500100002,1000002,102
1500100004,1000001,42
1500100004,1000002,142select a.id,a.name,b.sid,b.score from
students_proctime a, scores_proctime b
where a.id=b.sid
-- a表的时间需要在b表时间10秒内或b表的时间需要在a表时间10秒内
and (a.proctime BETWEEN b.proctime - INTERVAL '10' SECOND AND b.proctimeor b.proctime BETWEEN a.proctime - INTERVAL '10' SECOND AND a.proctime
);
3、Temporal Joins(时态连接)
这种关联方式是专门用来关联时态表的。
- Temporal Joins(时态连接)是在流式计算或数据处理中,对两个或多个随时间变化的表(也称为动态表或时态表)进行连接的操作。这些表包含随时间变化的数据,并且行与一个或多个时态周期相关联。
在我们生活中最常见的时态表就是汇率表,汇率随着时间变化而变化。
案例:
例如,假设我们有一张订单表,每张订单的价格都采用不同的货币。为了正确地将此表标准化为单一货币(如美元),每张订单都需要与下订单时相应的货币兑换率相结合。
1、创建订单表
CREATE TABLE orders (order_id STRING,price DECIMAL(32,2),currency STRING, --币种order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time
) WITH ('connector' = 'kafka','topic' = 'orders', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置'format' = 'csv' -- 指定数据的格式
);2、订单表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic orders
o_001,1,EUR,2024-06-06 12:00:00
o_002,100,EUR,2024-06-06 12:00:07
o_003,200,EUR,2024-06-06 12:00:16
o_004,10,EUR,2024-06-06 12:00:21
o_005,20,EUR,2024-06-06 12:00:253、创建汇率表
CREATE TABLE currency_rates (currency STRING,conversion_rate DECIMAL(32, 2),update_time TIMESTAMP(3),WATERMARK FOR update_time AS update_time,PRIMARY KEY(currency) NOT ENFORCED -- 主键,区分不同的汇率
) WITH ('connector' = 'kafka','topic' = 'currency_rates1', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置'format' = 'canal-json' -- 指定数据的格式
);4、向汇率表中添加数据
insert into currency_rates
values
('EUR',0.12,TIMESTAMP'2024-06-06 12:00:00'),
('EUR',0.11,TIMESTAMP'2024-06-06 12:00:09'),
('EUR',0.15,TIMESTAMP'2024-06-06 12:00:17'),
('EUR',0.14,TIMESTAMP'2024-06-06 12:00:23');kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic currency_rates-- 使用常规关联方式关联时态表只能关联到最新的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates as b
on a.currency=b.currency;-- 时态表join
-- FOR SYSTEM_TIME AS OF a.order_time: 使用a表的时间到b表中查询对应时间段的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates FOR SYSTEM_TIME AS OF a.order_time as b
on a.currency=b.currency;常规join结果:

时态join结果:
4、lookup join(查找连接)
Lookup Join,也称为维表 Join,通常用于从外部系统查询的数据表。连接要求一个表具有处理时间属性,另一个表由查找源连接器支持。
具体来说:
lookup join用于流表(动态表)关联维度表
流表:动态表
维度表:不怎么变化的变,维度表的数据一般可以放在hdfs或者mysql等外部数据源
扩展:流表、事实表、维度表
-- 流表(动态表)
1、流表的数据来源通常是实时数据流,这些数据流可以来自各种数据源,如 Kafka、RabbitMQ、Kinesis 等。Flink可以通过数据源连接器(Source Connectors)将这些实时数据流接入到 Flink 系统中
2、与传统数据库中的表不同,流表的行是动态生成的,随着数据流的持续产生而不断增加-- 维度表
1、主要提供数据的分析角度,包含了描述业务环境的属性信息,如时间、地理、产品等。
2、维度表:通常比较宽(包含多个属性列),但行数相对较少,因为维度表中的每一行通常代表一个具体的业务实体或类别,如一个商品、一个客户、一个日期等。
3、维度表与事实表之间通过外键相关联,共同构成了星型模型或雪花模型。事实表中的外键用于与维度表中的主键相匹配,从而提供数据的上下文和分类信息。
4、维度表存储的是对数据的描述性信息,这些信息通常不随时间变化,或者变化不频繁。例如,商品的品牌、型号、颜色等属性一旦确定后很少会发生变化。但在某些情况下,如新产品上市或促销活动,可能需要更新维度表以添加新的维度成员。-- 事实表
1、存储了实际的数据度量值,如销售额、订单数量等。事实表是数据分析的核心,包含了所有用于分析的数据指标。
2、通常比较窄(包含较少的列),但行数非常多,因为事实表中的每一行通常代表一个具体的事件或交易,如一个订单、一次点击等。
3、事实表存储的是度量数据(即指标),这些数据会随时间变化,并且经常需要被汇总和分析。例如,销售额、订单数量、点击量等指标会随着业务活动的进行而不断更新。
4、事实表的数据更新频率通常较高,因为事实数据会随着业务活动的进行而不断产生。例如,每当有新的订单产生时,都需要在事实表中插入一条新的记录。
1、创建分数表
CREATE TABLE scores (sid INT,cid STRING,score INT,proctime AS PROCTIME()
) WITH ('connector' = 'kafka','topic' = 'scores', -- 指定topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表'properties.group.id' = 'testGroup', -- 指定消费者组'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置'format' = 'csv' -- 指定数据的格式
);2、生产分数表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000003,1373、建立学生表,我们将学生表当作维度表放在mysql中
CREATE TABLE students_test (id INT,name STRING,age INT,gender STRING,clazz STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/bigdata29','table-name' = 'students_test','username' ='root','password' = '123456','lookup.cache.max-rows' = '1000', -- 最大缓存行数'lookup.cache.ttl' ='10000' -- 缓存过期时间
);学生表数据
1500100001,施笑槐,22,女,文科六班-- 使用常规关联方式
-- 维表的数据只在任务启动的时候读取一次,后面不再实时读取,
-- 只能关联到任务启动时读取的数据
-- 一旦mysql中的学生表更新数据,但是关联的学生表数据却是任务启动时从mysql读取的,这就有错误了,lookup join可以解决该问题。
select a.sid,a.score,b.id,b.name from
scores as a
left join
students_test as b
on a.sid=b.id;-- lookup join
-- 当流表每来一条数据时,使用关联字段到维表的数据源中查询
-- 优点:实时更新数据源,准确性高
-- 缺点:每一次都需要查询数据库,性能会降低
select a.sid,a.score,b.id,b.name from
scores as a
left join
students_test FOR SYSTEM_TIME AS OF a.proctime as b
on a.sid=b.id;此时我们修改更新mysql中的学生表数据
修改之前

修改后:

常规关联结果:

look up关联结果:

相关文章:
Flink Sql:四种Join方式详解(基于flink1.15官方文档)
JOINs flink sql主要有四种连接方式,分别是Regular Joins、Interval Joins、Temporal Joins、lookup join 1、Regular Joins(常规连接 ) 这种连接方式和hive sql中的join是一样的,包括inner join,left joinÿ…...
 Object Pascal 学习笔记---第14章泛型第3节(泛型约束))
(delphi11最新学习资料) Object Pascal 学习笔记---第14章泛型第3节(泛型约束)
14.3 泛型约束 正如我们所看到的,您在泛型类的方法中可以做的事情非常少。您可以传递它(即分配它)并执行上面我介绍的泛型类型函数允许的有限操作。 为了能够执行泛型类的实际操作,通常需要对其进行约束。例如,…...
C语言详解(预编译)
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...
解决el-table表格拖拽后,只改变了数据,表头没变的问题
先看看是不是你想要解决的问题 拖拽后表头不变的bug修复 这个问题一般是使用v-for对column的数据进行循环的时候,key值绑定的是个index导致的,请看我上篇文章:eleplus对el-table表格进行拖拽(使用sortablejs进行列拖拽和行拖拽):-…...
简单塔防小游戏
学习目标:熟悉塔防游戏核心战斗 游戏画面 项目结构目录 核心代码: if ( Input.GetMouseButtonDown(0)){if (EventSystem.current.IsPointerOverGameObject()false){//开发炮台的建造Ray ray Camera.main.ScreenPointToRay(Input.mousePosition);Rayca…...

高考之后第一张大流量卡应该怎么选?
高考之后第一张大流量卡应该怎么选? 高考结束后,选择一张合适的大流量卡对于准大学生来说非常重要,因为假期期间流量的使用可能会暴增。需要综合考虑多个因素,以确保选到最适合自己需求、性价比较高且稳定的套餐。以下是一些建议…...

如何从微软官方下载Edge浏览器的完整离线安装包
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 正文内容 📒🚀 官方直链下载🚬 手动选择下载🎈 获取方式 🎈⚓️ 相关链接 ⚓️📖 介绍 📖 在网上搜索Microsoft Edge浏览器的离线安装包时,很多用户都会发现大部分都是在线安装包,无法满足他们在无网络环境下进…...

git 常用的命令
git 常用的命令 一、基础命令1.1 初始化1.2 添加文件1.3 查看缓存区中的文件1.4 查看上次提交到缓存区中的文件1.5 文件从缓存区取出1.6 提交文件1.6 查看提交中包含的文件1.7 查看commit记录 二、回退命令2.1 git reset2.2 将文件从暂存区取出2.3 将文件从仓库取出2.3.1 保留工…...
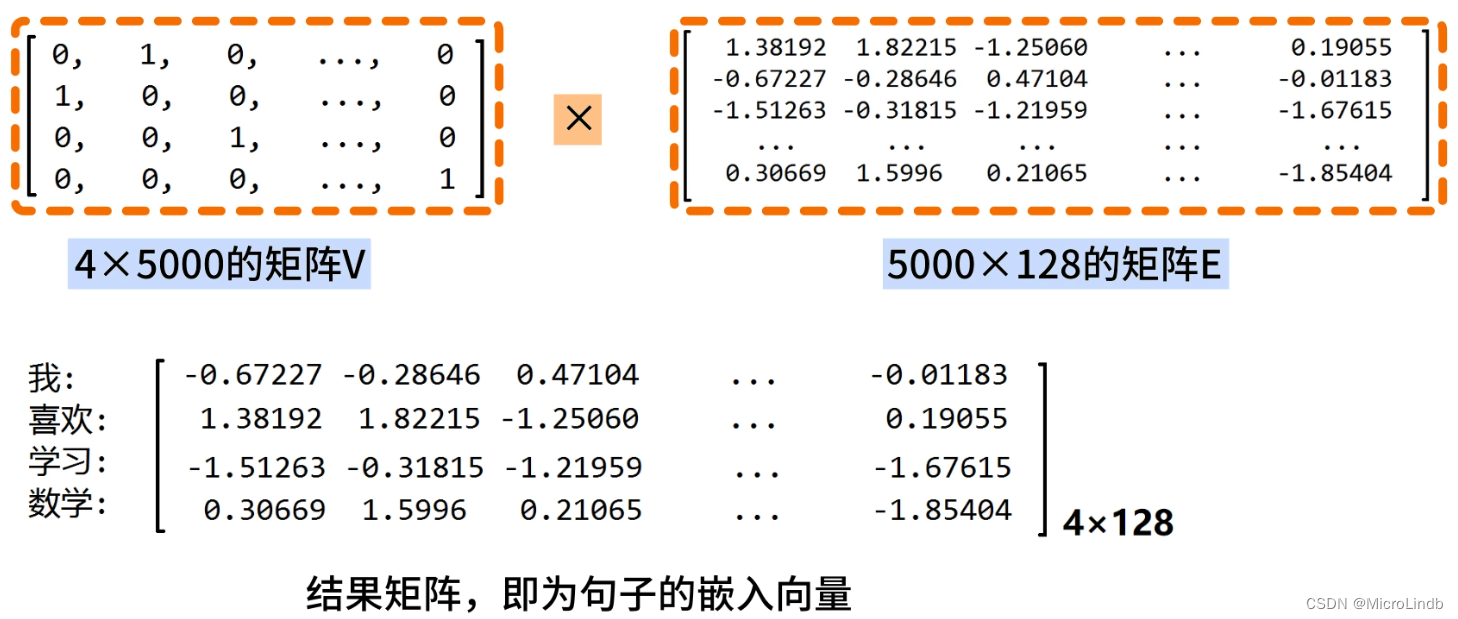
【StableDiffusion】Embedding 底层原理,Prompt Embedding,嵌入向量
Embedding 是什么? Embedding 是将自然语言词汇,映射为 固定长度 的词向量 的技术 说到这里,需要介绍一下 One-Hot 编码 是什么。 One-Hot 编码 使用了众多 5000 长度的1维矩阵,每个矩阵代表一个词语。 这有坏处,…...

计算机网络(2) 网络层:IP服务模型
一.Internet Protocol在TCP/IP四层模型中的作用 第三层网络层负责数据包从哪里来到哪里去的问题。传输层的数据段提交给网络层后,网络层负责添加IP段,包含数据包源地址与目的地址。将添加IP段的数据包交由数据链路层添加链路头形成最终在各节点传输中所需…...
)
新人学习笔记之(初识C语言)
一、C语言的简介 1.C语言:1978年1月1日美国贝尔实验室推出的一门非常哇塞计算机语言 2.计算机语言:人与计算机之间进行信息交流沟通的一种特殊语言 二、C语言能做什么 1.操作系统 2.驱动开发 3.引擎开发 4.游戏开发 5.嵌入式开发 三、学习C语言的好处 …...

Unity EasyRoads3D插件使用
一、插件介绍 描述 Unity 中的道路基础设施和参数化建模 在 Unity 中使用内置的可自定义动态交叉预制件和基于您自己导入的模型的自定义交叉预制件,直接创建独特的道路网络。 添加额外辅助对象,让你的场景栩栩如生:桥梁、安全护栏、栅栏、墙壁…...

Redis 地理散列GeoHash
用数据库来算附近的人 地图元素的位置数据使用二维的经纬度表示,经度范围(-180,180],纬度范围 (-90,90],纬度正负以赤道为界,北正南负,经度正负已本初子午线(英国格林尼…...

vim 显示行号
在 Vim 中,你可以通过几种不同的方式来显示行号。以下是两种常用的方法: 临时显示行号: 当你打开 Vim 并想要临时查看文件的行号时,你可以使用 :set number 命令。这个命令会在当前 Vim 会话中显示行号。如果你想要关闭行号显示&a…...

C++:调整数组顺序使奇数位于偶数前面【面试】
在C,如果要调整数组顺序使所有奇数位于偶数前面,这里提供一种简单且常用的方法:双指针技术。这种方法不需要额外的空间,并且时间复杂度为O(n)。 以下是使用双指针技术实现的示例代码: #include <iostream> #in…...
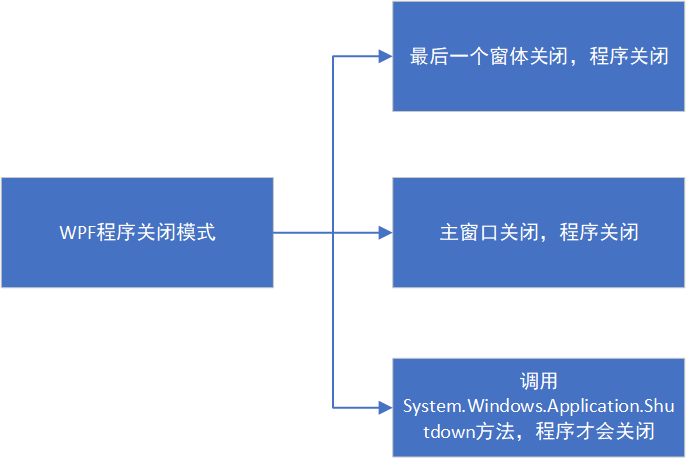
WPF/C#:程序关闭的三种模式
ShutdownMode枚举类型介绍 ShutdownMode是一个枚举类型,它定义了WPF应用程序的关闭方式。这个枚举类型有三个成员: OnLastWindowClose:当最后一个窗口关闭或者调用System.Windows.Application.Shutdown方法时,应用程序会关闭。O…...
登录/注册- 滑动拼图验证码(IOS/Swift)
本章介绍如何使用ios开发出滑动拼图验证码,分别OC代码和swift代码调用 1.导入项目model文件OC代码(下载完整Demo) 2.放入你需要显示的图片 一:OC调用 #import "ViewController.h" #import "CodeView.h"…...
MyBatis进行模糊查询时SQL语句拼接引起的异常问题
项目场景: CRM项目,本文遇到的问题是在实现根据页面表单中输入条件,在数据库中分页模糊查询数据,并在页面分页显示的功能时,出现的“诡异”bug。 开发环境如下: 操作系统:Windows11 Java&#…...
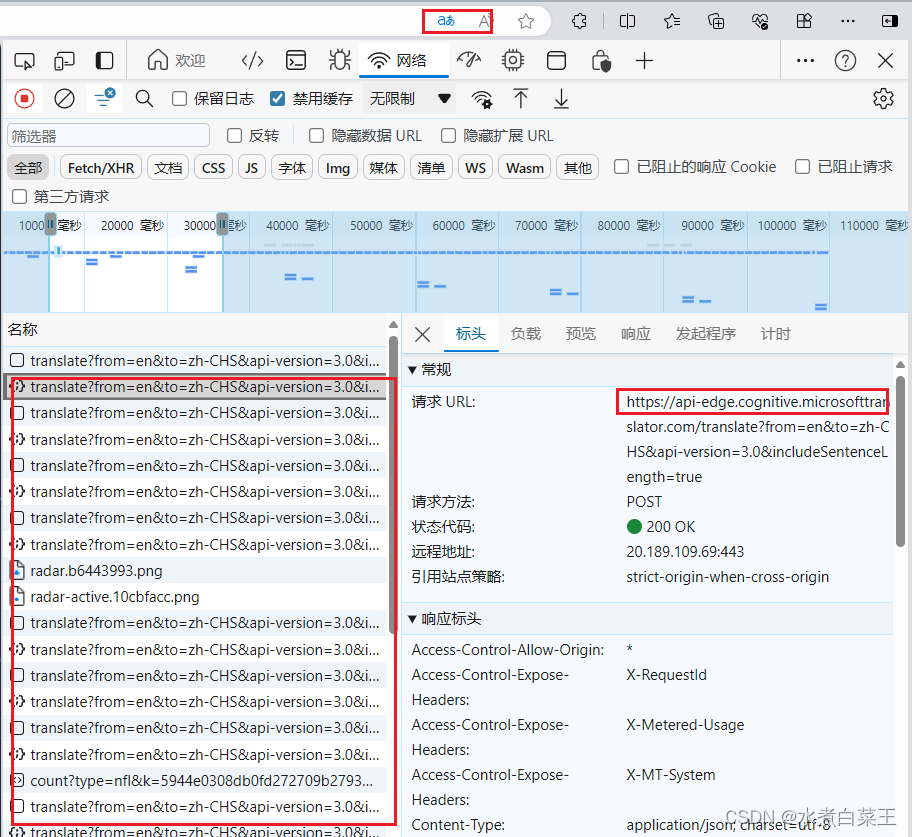
网站调用Edge浏览器API:https://api-edge.cognitive.microsofttranslator.com/translate
Edge浏览器有自带的翻译功能,在运行pc项目可能会遇到疯狂调用Edge的API https://api-edge.cognitive.microsofttranslator.com/translate 这个URL(https://api-edge.cognitive.microsofttranslator.com/translate)指向的是微软服务中的API接…...

css实现优惠券样式
实现优惠券效果: 实现思路: 需要三个盒子元素,使用 css 剪裁,利用 ellipse 属性,将两个盒子分别裁剪成两个半圆,位置固定在另一个盒子元素左右两边适当位置上。为另一个盒子设置想要的样式,圆角…...

如何快速掌握LyricsX:macOS终极歌词同步工具完整指南
如何快速掌握LyricsX:macOS终极歌词同步工具完整指南 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,能够自动同步音乐…...

从零到一:PyQt-Fluent-Widgets导航组件实战指南
从零到一:PyQt-Fluent-Widgets导航组件实战指南 【免费下载链接】PyQt-Fluent-Widgets A fluent design widgets library based on C Qt/PyQt/PySide. Make Qt Great Again. 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Fluent-Widgets 你是否曾经为P…...

ARM PMU性能监控架构与寄存器详解
1. ARM PMU性能监控架构概述 性能监控单元(Performance Monitoring Unit, PMU)是现代处理器中用于硬件级性能分析的关键模块。作为ARM架构的重要组成部分,PMU通过一组可编程计数器来记录处理器运行过程中发生的各类微架构事件,为系统性能分析和优化提供数…...

美国通信业去监管趋势下的技术生态变革与产业应对策略
1. 从“去监管”信号看美国通信业格局重塑 2017年初,当阿吉特派伊(Ajit Pai)正式接任美国联邦通信委员会(FCC)主席时,他的一项早期举措——为广播公司和有线电视运营商削减文书工作规定——几乎在所有人的预…...

Bevy引擎拾取系统:从射线检测到事件冒泡的完整交互方案
1. 项目概述与核心价值在构建交互式应用,尤其是游戏或3D编辑器时,一个基础且高频的需求就是让用户能够用鼠标、触摸屏等指针设备与屏幕上的物体进行交互。简单来说,就是“点选”功能。在Bevy引擎的早期版本中,这个看似简单的功能实…...

Gemini3.1Pro发布:多模态AI再进化
如果你最近也在跟踪 2026 年的 AI 动态,应该会发现一个很明显的变化:大模型的竞争重点,已经从“会不会生成内容”,转向“能不能真正理解复杂任务并参与工作流”。像KULAAI(dl.877ai.cn) 这类 AI 聚合平台&a…...

Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案
Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 为Adobe Photoshop添加AVIF格式支持不再…...

Anthropic新模型Mythos号称擅查漏洞,扫描curl代码却仅确认1个低危问题
Mythos高调亮相,扫描结果却令人意外 近期,Anthropic推出的AI安全分析模型Mythos引发广泛关注,该公司宣称其在发现源代码安全漏洞方面表现出色,甚至因此暂缓公开发布。然而,当Mythos扫描全球最广泛使用的开源命令行HTTP…...
)
STM32实战:用HAL库搞定RS485 Modbus液压传感器数据采集(附自动收发电路避坑)
STM32实战:HAL库驱动RS485 Modbus液压传感器全流程解析 液压系统压力监测的稳定性往往取决于传感器数据采集的可靠性。在工业现场,RS485总线搭配Modbus RTU协议已成为液压传感器数据传输的黄金标准。本文将深入探讨基于STM32 HAL库的完整解决方案&#x…...

ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程
ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: ht…...