Python酷库之旅-比翼双飞情侣库(05)
目录
一、xlrd库的由来
二、xlrd库优缺点
1、优点
1-1、支持多种Excel文件格式
1-2、高效性
1-3、开源性
1-4、简单易用
1-5、良好的兼容性
2、缺点
2-1、对.xlsx格式支持有限
2-2、功能相对单一
2-3、更新和维护频率低
2-4、依赖外部资源
三、xlrd库的版本说明
1、xlrd 1.2.0版本
2、xlrd 2.0.1版本
3、xlrd3(非官方名称)
四、如何学好xlrd库?
1、获取xlrd库的属性和方法
2、获取xlrd库的帮助信息
3、用法精讲
3-13、xlrd.book.Book.sheet_by_name方法
3-13-1、语法
3-13-2、参数
3-13-3、功能
3-13-4、返回值
3-13-5、说明
3-13-6、用法
3-14、xlrd.book.Book.sheets方法
3-14-1、语法
3-14-2、参数
3-14-3、功能
3-14-4、返回值
3-14-5、说明
3-14-6、用法
3-15、xlrd.book.Book.sheet_names方法
3-15-1、语法
3-15-2、参数
3-15-3、功能
3-15-4、返回值
3-15-5、说明
3-15-6、用法
3-16、xlrd.book.Book.sheet_by_index方法
3-16-1、语法
3-16-2、参数
3-16-3、功能
3-16-4、返回值
3-16-5、说明
3-16-6、 用法
3-17、xlrd.book.Book.dump方法
3-17-1、语法
3-17-2、参数
3-17-3、功能
3-17-4、返回值
3-17-5、说明
3-17-6、 用法
五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、 博客个人主页



在Excel中,通常所说的“情侣键”并非官方术语,而是对某些常用且经常成对出现的快捷键的一种形象化的称呼。其中,最为人熟知和广泛使用的“情侣键”是“Ctrl+C”和“Ctrl+V”。
1、Ctrl+C:这个快捷键的作用是“拷贝”或“复制”。当你在Excel中选中某个单元格、一行、一列或整个工作表的内容后,按下Ctrl+C键,这些内容就会被复制到计算机的剪贴板中,等待下一步的粘贴操作。
2、Ctrl+V:这个快捷键的作用是“粘贴”。在你按下Ctrl+C键将内容复制到剪贴板后,可以通过按下Ctrl+V键将这些内容粘贴到Excel中的另一个位置,这两个操作经常是连续进行的,因此Ctrl+C和Ctrl+V就像一对“情侣”,总是成对出现。
除了这对常见的“情侣键”外,Excel中还有许多其他的快捷键可以帮助用户更高效地完成各种操作。然而,这些快捷键通常并没有像Ctrl+C和Ctrl+V那样形成特定的“情侣”关系。
然而,今天我不再展开介绍“情侣键”,而是要重点推介Python中的“情侣库”,即xlrd和xlwt两个第三方库。
一、xlrd库的由来
xlrd库是一种用于在Python中读取Excel文件的库,它的名称中的"xl"代表Excel,"rd"代表读取,其开发者是John Machin(注:库名字符拆分诠释,只是一种猜测)。
xlrd最初是在2005年开始开发的,是基于Python的开源项目(下载:xlrd库官网下载)。
由于Excel文件在数据处理和分析中的重要性,xlrd库填补了Python在处理Excel文件方面的空白,使得用户可以方便地在Python环境中读取Excel文件的内容,并进行进一步的数据操作和分析。
二、xlrd库优缺点
1、优点
1-1、支持多种Excel文件格式
xlrd库支持多种Excel文件格式,包括`.xls`和`.xlsx`(在旧版本中),这使得无论数据存储在哪种格式的Excel文件中,用户都可以使用xlrd库来读取。
1-2、高效性
xlrd库使用C语言编写,因此其性能非常高,即使面对非常大的Excel文件,xlrd也可以快速地读取其中的数据。
1-3、开源性
xlrd是完全开源的,可以在GitHub等平台上找到其源代码,这使得任何人都可以根据自己的需求对其进行修改和扩展。
1-4、简单易用
xlrd提供了简单直接的API来获取单元格数据、行列数等,使得从Excel文件中读取数据变得简单而高效。
1-5、良好的兼容性
xlrd库适配多种Python版本,包括Python 2.7(不包括3.0-3.3)或Python 3.4及以上版本,这为用户提供了广泛的兼容性选择。
2、缺点
2-1、对.xlsx格式支持有限
在xlrd 1.2.0之后的版本中(大约从2020年开始),xlrd库不再支持`.xlsx`文件格式,这限制了xlrd在新版Excel文件(主要是`.xlsx`格式)上的应用。
2-2、功能相对单一
xlrd库主要专注于从Excel文件中读取数据,而不提供写入或修改Excel文件的功能,这使得在处理需要写入或修改Excel文件的任务时,用户需要结合其他库(如`openpyxl`或`xlwt`)使用。
2-3、更新和维护频率低
由于xlrd库主要关注于读取Excel文件的功能,并且随着`.xlsx`格式的普及,其使用范围逐渐缩小,因此,xlrd库的更新和维护频率可能相对较低。
2-4、依赖外部资源
在某些情况下,xlrd库可能需要依赖外部资源或库来完全发挥其功能,这可能会增加用户在使用xlrd库时的复杂性和不确定性。
总之,xlrd库在读取Excel文件方面具有高效、开源和简单易用等优点,但在对`.xlsx`格式的支持、功能单一以及更新和维护频率等方面存在一些缺点,用户在选择使用xlrd库时需要根据自己的需求进行权衡和选择。
三、xlrd库的版本说明
xlrd库适配的Python版本根据库的不同版本而有所不同。以下是针对几个主要版本的说明:
1、xlrd 1.2.0版本
1-1、适配Python>=2.7(不包括3.0-3.3)或Python>=3.4。
1-2、该版本支持xlsx文件格式,并且是一个广泛使用的版本,因为它能够处理小到中等大小的Excel文件,并且具有较好的性能表现。
2、xlrd 2.0.1版本
2-1、适配Python>=2.7(不包括3.0-3.5)或Python>=3.6。
2-2、该版本不再支持xlsx文件格式,仅支持旧版的xls文件格式,因为在xlrd 2.0版本之后,xlrd移除了对xlsx格式的支持。
3、xlrd3(非官方名称)
xlrd3是xlrd的开源扩展库,提供了对xlsx文件格式的支持,然而,请注意,xlrd3并不是xlrd的官方名称(下载:GitHub - Dragon2fly/xlrd3)。
四、如何学好xlrd库?
1、获取xlrd库的属性和方法
用print()和dir()两个函数获取xlrd库所有属性和方法的列表
# ['Book', 'FILE_FORMAT_DESCRIPTIONS', 'FMLA_TYPE_ARRAY', 'FMLA_TYPE_CELL', 'FMLA_TYPE_COND_FMT', 'FMLA_TYPE_DATA_VAL',
# 'FMLA_TYPE_NAME', 'FMLA_TYPE_SHARED', 'Operand', 'PEEK_SIZE', 'Ref3D', 'XLDateError', 'XLRDError', 'XLS_SIGNATURE',
# 'XL_CELL_BLANK', 'XL_CELL_BOOLEAN', 'XL_CELL_DATE', 'XL_CELL_EMPTY', 'XL_CELL_ERROR', 'XL_CELL_NUMBER', 'XL_CELL_TEXT', 'ZIP_SIGNATURE',
# '__VERSION__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__',
# '__spec__', '__version__',
# 'biff_text_from_num', 'biffh', 'book', 'cellname', 'cellnameabs', 'colname', 'compdoc', 'count_records', 'decompile_formula',
# 'dump', 'dump_formula', 'empty_cell', 'error_text_from_code', 'evaluate_name_formula', 'formatting', 'formula', 'info',
# 'inspect_format', 'oBOOL', 'oERR', 'oNUM', 'oREF', 'oREL', 'oSTRG', 'oUNK', 'okind_dict', 'open_workbook', 'open_workbook_xls',
# 'os', 'pprint', 'rangename3d', 'rangename3drel', 'sheet', 'sys', 'timemachine', 'xldate', 'xldate_as_datetime', 'xldate_as_tuple', 'zipfile']2、获取xlrd库的帮助信息
用help()函数获取xlrd库的帮助信息
Help on package xlrd:NAMExlrdDESCRIPTION# Copyright (c) 2005-2012 Stephen John Machin, Lingfo Pty Ltd# This module is part of the xlrd package, which is released under a# BSD-style licence.PACKAGE CONTENTSbiffhbookcompdocformattingformulainfosheettimemachinexldateFUNCTIONScount_records(filename, outfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>)For debugging and analysis: summarise the file's BIFF records.ie: produce a sorted file of ``(record_name, count)``.:param filename: The path to the file to be summarised.:param outfile: An open file, to which the summary is written.dump(filename, outfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>, unnumbered=False)For debugging: dump an XLS file's BIFF records in char & hex.:param filename: The path to the file to be dumped.:param outfile: An open file, to which the dump is written.:param unnumbered: If true, omit offsets (for meaningful diffs).inspect_format(path=None, content=None)Inspect the content at the supplied path or the :class:`bytes` content providedand return the file's type as a :class:`str`, or ``None`` if it cannotbe determined.:param path:A :class:`string <str>` path containing the content to inspect.``~`` will be expanded.:param content:The :class:`bytes` content to inspect.:returns:A :class:`str`, or ``None`` if the format cannot be determined.The return value can always be looked up in :data:`FILE_FORMAT_DESCRIPTIONS`to return a human-readable description of the format found.open_workbook(filename=None, logfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>, verbosity=0, use_mmap=True, file_contents=None, encoding_override=None, formatting_info=False, on_demand=False, ragged_rows=False, ignore_workbook_corruption=False)Open a spreadsheet file for data extraction.:param filename: The path to the spreadsheet file to be opened.:param logfile: An open file to which messages and diagnostics are written.:param verbosity: Increases the volume of trace material written to thelogfile.:param use_mmap:Whether to use the mmap module is determined heuristically.Use this arg to override the result.Current heuristic: mmap is used if it exists.:param file_contents:A string or an :class:`mmap.mmap` object or some other behave-alikeobject. If ``file_contents`` is supplied, ``filename`` will not be used,except (possibly) in messages.:param encoding_override:Used to overcome missing or bad codepage informationin older-version files. See :doc:`unicode`.:param formatting_info:The default is ``False``, which saves memory.In this case, "Blank" cells, which are those with their own formattinginformation but no data, are treated as empty by ignoring the file's``BLANK`` and ``MULBLANK`` records.This cuts off any bottom or right "margin" of rows of empty or blankcells.Only :meth:`~xlrd.sheet.Sheet.cell_value` and:meth:`~xlrd.sheet.Sheet.cell_type` are available.When ``True``, formatting information will be read from the spreadsheetfile. This provides all cells, including empty and blank cells.Formatting information is available for each cell.Note that this will raise a NotImplementedError when used with anxlsx file.:param on_demand:Governs whether sheets are all loaded initially or when demandedby the caller. See :doc:`on_demand`.:param ragged_rows:The default of ``False`` means all rows are padded out with empty cells sothat all rows have the same size as found in:attr:`~xlrd.sheet.Sheet.ncols`.``True`` means that there are no empty cells at the ends of rows.This can result in substantial memory savings if rows are of widelyvarying sizes. See also the :meth:`~xlrd.sheet.Sheet.row_len` method.:param ignore_workbook_corruption:This option allows to read corrupted workbooks.When ``False`` you may face CompDocError: Workbook corruption.When ``True`` that exception will be ignored.:returns: An instance of the :class:`~xlrd.book.Book` class.DATAFILE_FORMAT_DESCRIPTIONS = {'xls': 'Excel xls', 'xlsb': 'Excel 2007 xl...FMLA_TYPE_ARRAY = 4FMLA_TYPE_CELL = 1FMLA_TYPE_COND_FMT = 8FMLA_TYPE_DATA_VAL = 16FMLA_TYPE_NAME = 32FMLA_TYPE_SHARED = 2PEEK_SIZE = 8XLS_SIGNATURE = b'\xd0\xcf\x11\xe0\xa1\xb1\x1a\xe1'XL_CELL_BLANK = 6XL_CELL_BOOLEAN = 4XL_CELL_DATE = 3XL_CELL_EMPTY = 0XL_CELL_ERROR = 5XL_CELL_NUMBER = 2XL_CELL_TEXT = 1ZIP_SIGNATURE = b'PK\x03\x04'__VERSION__ = '2.0.1'biff_text_from_num = {0: '(not BIFF)', 20: '2.0', 21: '2.1', 30: '3', ...empty_cell = empty:''error_text_from_code = {0: '#NULL!', 7: '#DIV/0!', 15: '#VALUE!', 23: ...oBOOL = 3oERR = 4oNUM = 2oREF = -1oREL = -2oSTRG = 1oUNK = 0okind_dict = {-2: 'oREL', -1: 'oREF', 0: 'oUNK', 1: 'oSTRG', 2: 'oNUM'...VERSION2.0.1FILEe:\python_workspace\pythonproject\lib\site-packages\xlrd\__init__.py3、用法精讲
3-13、xlrd.book.Book.sheet_by_name方法
3-13-1、语法
sheet_by_name(self, sheet_name):param sheet_name: Name of the sheet required.:returns: A :class:`~xlrd.sheet.Sheet`.
3-13-2、参数
3-13-2-1、self(必须):一个对实例对象本身的引用,在类的所有方法中都会自动传递。
3-13-2-2、sheet_name(必须):一个字符串,表示要检索的工作表的名称。
3-13-3、功能
用于通过工作表名称获取工作表对象。
3-13-4、返回值
3-13-4-1、如果找到了具有给定名称的工作表,则返回该工作表对象(通常是xlrd.sheet.Sheet类型的一个实例)。
3-13-4-2、如果没有找到具有给定名称的工作表,则会抛出一个异常(如xlrd.biffh.XLRDError)。
3-13-5、说明
无
3-13-6、用法
# 13、xlrd.book.Book.sheet_by_name方法
import xlrd
# 打开 Excel 文件
workbook = xlrd.open_workbook('example.xls')
# 通过名称获取工作表
sheet = workbook.sheet_by_name('Sheet1')
# 现在你可以使用 sheet 对象来访问和操作该工作表中的数据3-14、xlrd.book.Book.sheets方法
3-14-1、语法
sheets(self):returns: A list of all sheets in the book.All sheets not already loaded will be loaded.3-14-2、参数
3-14-2-1、self(必须):一个对实例对象本身的引用,在类的所有方法中都会自动传递。
3-14-3、功能
用于获取 Excel 工作簿(Workbook)中的所有工作表(Worksheet)对象。
3-14-4、返回值
返回的是一个Python列表,该列表包含了工作簿中所有工作表对象的引用,每个工作表对象都是xlrd.sheet.Sheet类的实例,代表了Excel文件中的一个工作表。
3-14-5、说明
无
3-14-6、用法
# 14、xlrd.book.Book.sheets方法
import xlrd
# 打开 Excel 文件
workbook = xlrd.open_workbook('example.xls')
# 获取所有工作表对象列表
sheets = workbook.sheets()
# 遍历工作表列表
for sheet in sheets: print(sheet.name) # 打印每个工作表的名称 print(sheet.nrows) # 打印每个工作表的行数 print(sheet.ncols) # 打印每个工作表的列数 # ... 其他操作 ...3-15、xlrd.book.Book.sheet_names方法
3-15-1、语法
sheet_names(self):returns:A list of the names of all the worksheets in the workbook file.This information is available even when no sheets have yet beenloaded.
3-15-2、参数
3-15-2-1、self(必须):一个对实例对象本身的引用,在类的所有方法中都会自动传递。
3-15-3、功能
用于获取 Excel 工作簿(Workbook)中所有工作表(Worksheet)的名称。
3-15-4、返回值
返回的是一个Python列表,该列表包含了工作簿中所有工作表的名称,每个名称都是字符串类型。
3-15-5、说明
无
3-15-6、用法
# 15、xlrd.book.Book.sheet_names方法
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook('example.xls')
# 获取所有工作表的名称列表
sheet_names = workbook.sheet_names()
# 遍历并打印工作表名称
for name in sheet_names: print(name)3-16、xlrd.book.Book.sheet_by_index方法
3-16-1、语法
sheet_by_index(self, sheetx):param sheetx: Sheet index in ``range(nsheets)``:returns: A :class:`~xlrd.sheet.Sheet`.3-16-2、参数
3-16-2-1、self(必须):一个对实例对象本身的引用,在类的所有方法中都会自动传递。
3-16-2-2、sheetx(必须):一个非负整数,表示工作表的索引号,默认从0开始。
3-16-3、功能
用于通过索引获取Excel工作簿(Workbook)中的工作表(Worksheet)对象。
3-16-4、返回值
返回的是一个xlrd.sheet.Sheet类的实例,代表了Excel文件中的一个工作表。
3-16-5、说明
索引值必须是一个非负整数,并且不能超过工作簿中工作表的总数。如果索引值超出范围,xlrd会抛出一个IndexError异常。
3-16-6、 用法
# 16、xlrd.book.Book.sheet_by_index方法
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook('example.xls')
# 通过索引获取工作表对象
sheet = workbook.sheet_by_index(0) # 获取第一个工作表,索引从0开始
# 现在你可以使用 sheet 对象来访问和操作该工作表中的数据
print(sheet.name) # 打印工作表的名称
print(sheet.nrows) # 打印工作表的行数
print(sheet.ncols) # 打印工作表的列数3-17、xlrd.book.Book.dump方法
3-17-1、语法
dump(self, f=None, header=None, footer=None, indent=0):param f: open file object, to which the dump is written:param header: text to write before the dump:param footer: text to write after the dump:param indent: number of leading spaces (for recursive calls)3-17-2、参数
3-17-2-1、self(必须):一个对实例对象本身的引用,在类的所有方法中都会自动传递。
3-17-2-2、f(可选):一个打开的文件对象,用于写入转储(dump)内容。
3-17-2-3、header(可选):一个字符串,表示在转储内容之前写入的文本。
3-17-2-4、footer(可选):一个字符串,表示在转储内容之后写入的文本。
3-17-2-5、indent(可选):一个整数,用于指定在输出结构化数据时(如JSON、YAML等)的缩进级别,默认值为0,表示不添加任何缩进。
3-17-3、功能
将某个对象(通常是类实例的某些数据)以特定的格式写入到指定的文件或输出流中。
3-17-4、返回值
不返回任何值(即返回None)。它的主要目的是将数据写入到某个位置,而不是生成一个可以返回的结果。
3-17-5、说明
无
3-17-6、 用法
# 17、xlrd.book.Book.dump方法
import sys
import json
class MyClass:def __init__(self, data):self.data = datadef dump(self, f=None, header="Data Dump", footer="End of Data Dump", indent=2):if f is None:f = sys.stdout # 使用标准输出f.write(header + "\n")# 调用data_to_string方法将self.data转换为字符串f.write(self.data_to_string(indent=indent))f.write(footer + "\n")def data_to_string(self, indent):# 使用json.dumps将self.data转换为格式化的字符串return json.dumps(self.data, indent=indent, ensure_ascii=False)
if __name__ == '__main__':obj = MyClass({"key": "value"})obj.dump(indent=4) # 输出到控制台,并使用4个空格的缩进
# 输出:
# Data Dump
# {
# "key": "value"
# }End of Data Dump五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、 博客个人主页
相关文章:
Python酷库之旅-比翼双飞情侣库(05)
目录 一、xlrd库的由来 二、xlrd库优缺点 1、优点 1-1、支持多种Excel文件格式 1-2、高效性 1-3、开源性 1-4、简单易用 1-5、良好的兼容性 2、缺点 2-1、对.xlsx格式支持有限 2-2、功能相对单一 2-3、更新和维护频率低 2-4、依赖外部资源 三、xlrd库的版本说明 …...
numpy数组transpose方法的基本原理
背景:记录一下numpy数组维度顺序操作 一、具体示例 transpose方法用于交换数组的轴,改变数组的维度顺序。方法的参数是一个代表新轴顺序的元组。 假设你有一个三维数组,其形状是 (a, b, c),即有 a 个块,每个块中有 b…...
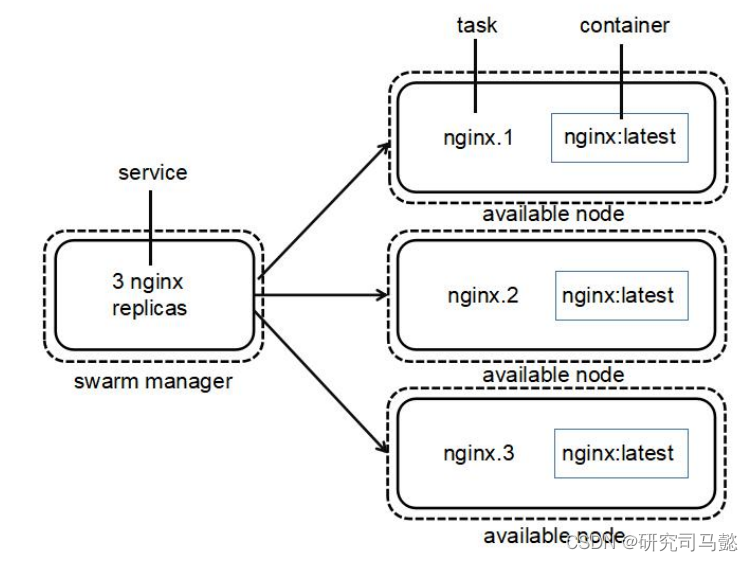
Docker Swarm集群部署管理
Docker Swarm集群管理 文章目录 Docker Swarm集群管理资源列表基础环境一、安装Docker二、部署Docker Swarm集群2.1、创建Docker Swarm集群2.2、添加Worker节点到Swarm集群2.3、查看Swarm集群中Node节点的详细状态信息 三、Docker Swarm管理3.1、案例概述3.2、Docker Swarm中的…...
碎片化知识如何被系统性地吸收?
一、方法论 碎片化知识指的是通过各种渠道快速获取的零散信息和知识点,这些信息由于其不完整性和孤立性,不易于记忆和应用。为了系统性地吸收碎片化知识,可以采用以下策略: 1. **构建知识框架**: - 在开始吸收之前&am…...

安鸾学院靶场——安全基础
文章目录 1、Burp抓包2、指纹识别3、压缩包解密4、Nginx整数溢出漏洞5、PHP代码基础6、linux基础命令7、Mysql数据库基础8、目录扫描9、端口扫描10、docker容器基础11、文件类型 1、Burp抓包 抓取http://47.100.220.113:8007/的返回包,可以拿到包含flag的txt文件。…...

ChatGPT:自然语言处理的新纪元与OpenAI的深度融合
随着人工智能技术的蓬勃发展,自然语言处理(NLP)领域取得了显著的进步。OpenAI作为这一领域的领军者,以其卓越的技术实力和创新能力,不断推动着NLP领域向前发展。其中ChatGPT作为OpenAI的重要成果更是在全球范围内引起了…...

AI引领项目管理新时代:效率与智能并驾齐驱
在数字化浪潮的推动下,项目管理领域正迎来一场由AI技术引领的革新。从自动化任务执行到智能决策支持,AI技术的应用正让项目管理变得更加高效、精准和智能化。本文将探讨项目管理人员及其实施团队如何运用AI技术,以及这些技术如何助力项目管理…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-电池管理系统中 CAN 通信模块的设计与应用(中)
目录 2.3 BMS 中 CAN 通信模块软硬件设计 2.3.1 CAN 通信模块硬件电路设计 2.3.2 CAN 通信模块软件设计 2.3.2.1 CAN 底层程序设计 2.3.2.2 CAN 底层初始化 2.3.2.3 CAN 底层接收 3.3.1.3 CAN 底层发送 2.4 通信协议的实现 2.4.1 整车通信协议的实现 2.4.2 充电机通信协议的实现…...
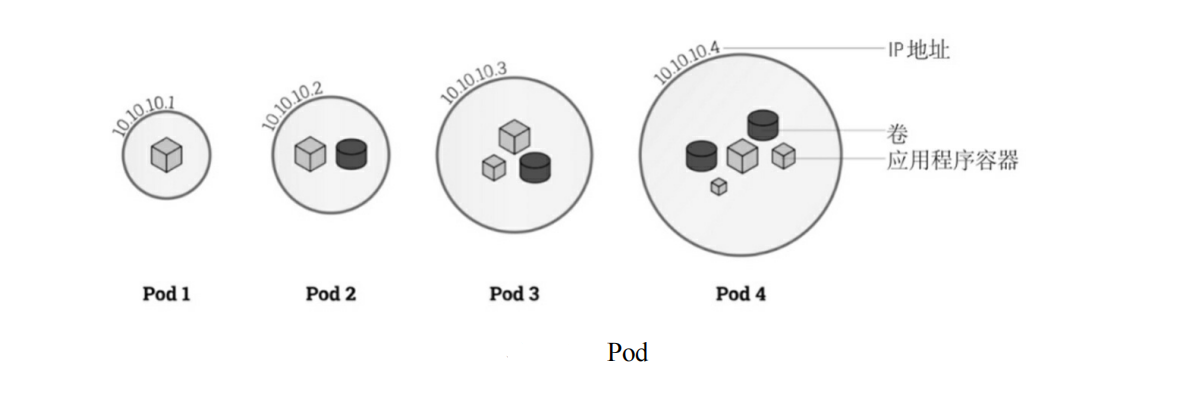
k8s概述
文章目录 一、什么是Kubernetes1、官网链接2、概述3、特点4、功能 二、Kubernetes架构1、架构图2、核心组件2.1、控制平面组件(Control Plane Components)2.1.1、kube-apiserver2.1.2、etcd2.1.3、kube-scheduler2.1.4、kube-controller-manager 2.2、No…...

多线程的运用
在现代软件开发中,多线程编程是一个非常重要的技能。多线程编程不仅可以提高应用程序的性能,还可以提升用户体验,特别是在需要处理大量数据或执行复杂计算的情况下。本文将详细介绍Java中的多线程编程,包括其基本概念、实现方法、…...
算法)
TF-IDF(Term Frequency-Inverse Document Frequency)算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的统计方法,主要用于评估一个单词在一个文档或一组文档中的重要性。它结合了词频(TF)和逆文档频率(IDF)两个指…...

富格林:细心发现虚假确保安全
富格林指出,现货黄金市场内蕴藏着丰富的盈利机会,然而并非所有人都能够抓住这些机会。要想从市场中获取丰厚的利润并且保障交易的安全,必须要求我们掌握一些交易技巧利用此去发现虚假陷阱。当我们不断汲取技巧过后,才可利用此来发…...

6.2 文件的缓存位置
1. 文件的缓冲 1.1 缓冲说明 将文件内容写入到硬件设备时, 则需要进行系统调用, 这类I/O操作的耗时很长, 为了减少I/O操作的次数, 文件通常使用缓冲区. 当需要写入的字节数不足一个块时, 将数据放入缓冲区, 当数据凑够一个块的大小后才进行系统调用(即I/O操作).系统调用: 向…...
是用于数据筛选的一种机制)
在Elasticsearch中,过滤器(Filter)是用于数据筛选的一种机制
在Elasticsearch中,过滤器(Filter)是用于数据筛选的一种机制,它通常用于结构化数据的精确匹配,如数字范围、日期范围、布尔值、前缀匹配等。过滤器不计算相关性评分,因此比查询(Query࿰…...

MySQL----主键、唯一、普通索引的创建与删除
创建索引 CREATE INDEX index_name ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);CREATE INDEX: 用于创建普通索引的关键字。index_name: 指定要创建的索引的名称。索引名称在表中必须是唯一的。table_name: 指定要在哪个表上创建索引。(column1, column2, ……...

css预处理是什么?作用是什么?
CSS预处理器是一种增强和扩展标准CSS的工具。它们允许开发者使用变量、嵌套规则、Mixin(混合)以及函数等高级功能,以更模块化和可维护的方式编写CSS代码。预处理器如Sass(SCSS)、Less和Stylus等,通过引入这…...

镜像拉取失败:[ERROR] Failed to pull docker image
问题描述 执行 bash docker/scripts/dev_start.sh 命令提示错误: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post “http://%2Fvar%2Frun%2Fdocker.sock/v1.45/images/create?fromImageregistry.b…...
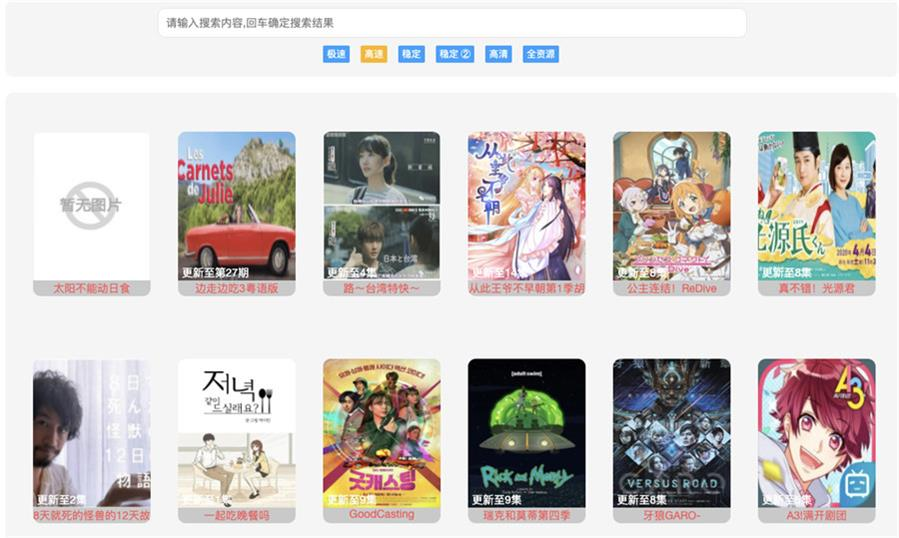
FM全网自动采集聚合影视搜索源码
源码介绍 FM 全网聚合影视搜索(响应式布局),基于 TP5.1 开发的聚合影视搜索程序,本程序无数据库,本程序内置P2P 版播放器,承诺无广告无捆绑。片源内部滚动广告与本站无关,谨防上当受骗,资源搜索全部来自于网络。 环境…...

【DevOps】什么是 pfSense?免费构建SDWAN
目录 一、详细介绍pfSense 1、 什么是 pfSense? 2、原理 3、 特点 4、 优点 5、 缺点 6、应用场景 7、 典型部署 二、pfSense实战:免费构建企业SD-WAN 1、拓扑图 2、准备工作 3、安装和基本配置pfSense 4、配置VPN 配置IPsec VPN 配置OpenV…...

elementui table超出两行显示...鼠标已入tip显示
elementui el-table超出两行显示…鼠标已入tip显示 方式一 <el-table-column label"描述"prop"note"class-name"myNoteBox"><template slot-scope"scope"><!-- tips悬浮提示 --><el-tooltip placement"to…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

高效视频帧提取终极指南:为深度学习构建专业数据集
高效视频帧提取终极指南:为深度学习构建专业数据集 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

WipperSnapper+Adafruit IO:无代码物联网开发实战,从传感器到云端自动化
1. 项目概述与核心价值如果你和我一样,在物联网(IoT)项目初期,常常被复杂的嵌入式编程、网络协议和云平台对接搞得焦头烂额,那么今天分享的这个实战项目,或许能让你眼前一亮。我们这次不谈复杂的代码&#…...

AI模型GUI开发实战:从架构设计到部署的完整指南
1. 项目概述:一个为AI模型打造的图形化交互界面最近在GitHub上看到一个挺有意思的项目,叫GrahamMiranda-AI/openclaw-model-gui。光看名字,就能猜个八九不离十:这大概率是一个为某个名为“OpenClaw”的AI模型配套开发的图形用户界…...