【机器学习】LightGBM: 优化机器学习的高效梯度提升决策树


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- LightGBM: 优化机器学习的高效梯度提升决策树
- 引言
- 一、LightGBM概览
- 二、核心技术解析
- 1. 直方图近似(Histogram Approximation)
- 2. 基于梯度的单边采样(Gradient-Based One-Side Sampling, GOSS)
- 3. 特征并行与数据并行
- 三、与其他GBDT实现的对比
- 四、实践应用与调参技巧
- 五、结论
LightGBM: 优化机器学习的高效梯度提升决策树
引言
在机器学习领域,梯度提升决策树(Gradient Boosting Decision Tree, GBDT)因其强大的预测能力和解释性而备受推崇。随着数据规模的日益增大,对模型训练速度和效率的需求也愈发迫切。在此背景下,Microsoft Research于2017年开源的LightGBM项目,凭借其高速度、高效率以及优秀的性能,在众多GBDT框架中脱颖而出,成为业界和学术界的新宠。本文将深入探讨LightGBM的核心优势、工作原理、关键特性和应用场景,旨在为读者提供一份全面而深入的理解指南。

一、LightGBM概览
诞生背景:面对传统GBDT在处理大规模数据集时遇到的内存消耗大、训练时间长等问题,LightGBM应运而生,它通过一系列创新算法设计显著提高了训练效率。
核心特点:
- 高效性:利用直方图近似和基于梯度的单边采样等技术,大幅减少计算量。
- 低内存消耗:通过叶子权重直方图存储方式,极大降低了内存使用。
- 高并行性:支持特征并行、数据并行和投票并行等多种并行策略,加速训练过程。
- 灵活性:支持自定义目标函数和评估指标,满足多样化需求。
二、核心技术解析
1. 直方图近似(Histogram Approximation)
传统的GBDT方法在每一轮迭代中需要遍历所有数据来计算梯度,这在大数据场景下极为耗时。LightGBM引入了直方图的概念,将连续的特征值离散化为几个区间,仅需统计每个区间内的样本数量和梯度统计量,从而大大减少了计算量,加速了训练过程。
2. 基于梯度的单边采样(Gradient-Based One-Side Sampling, GOSS)
GOSS是一种有效的样本抽样策略,它根据样本的梯度大小进行有偏抽样,保留梯度较大的样本和一部分梯度较小的样本,这样既保留了重要信息,又大幅度减少了计算量,进一步提升了效率。
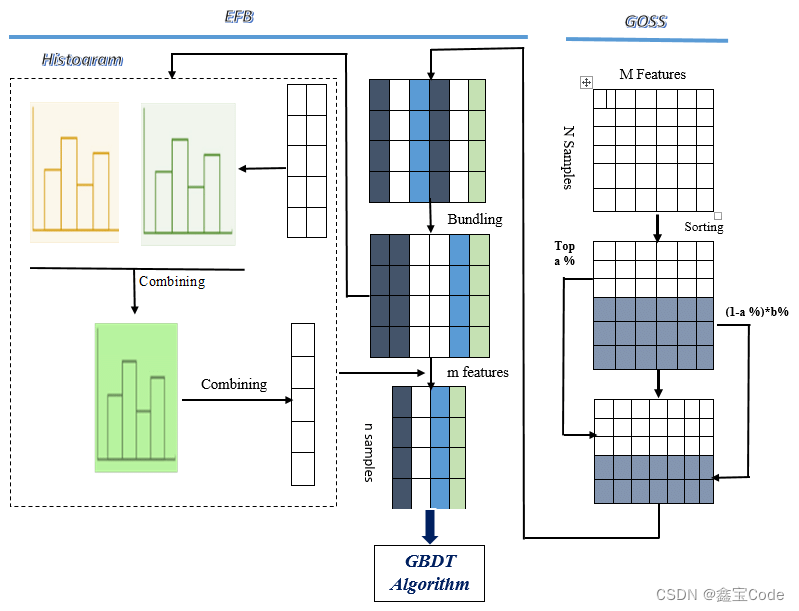
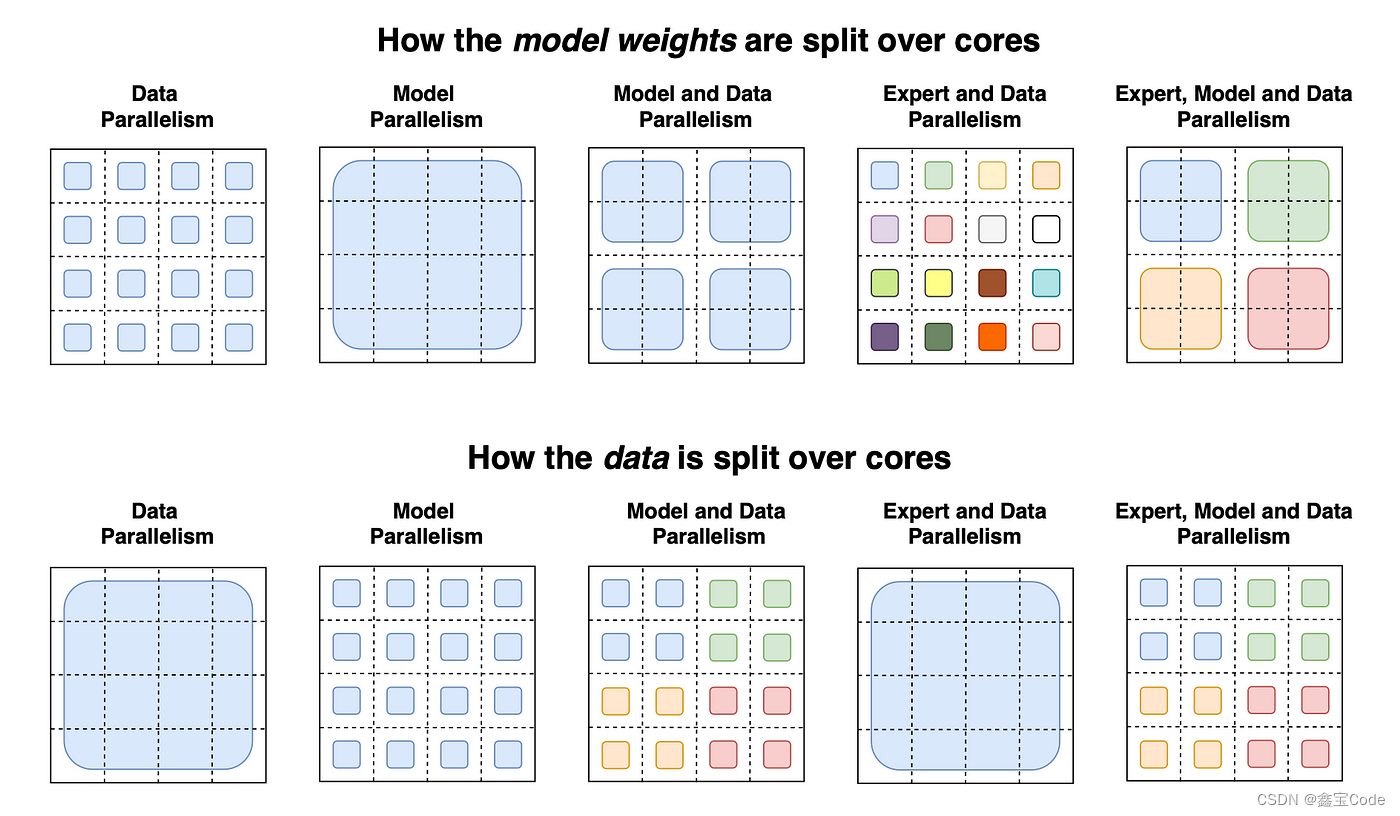
3. 特征并行与数据并行
- 特征并行:将特征分配到不同的机器上进行独立的直方图构建,然后合并这些直方图,适用于特征维度较高的情况。
- 数据并行:将数据集分割到不同机器,每台机器上分别建立自己的决策树,最后汇总决策树结果,适用于大数据集。
三、与其他GBDT实现的对比
与XGBoost相比,LightGBM在训练速度和内存使用上通常表现更优,特别是在数据量较大时。然而,XGBoost提供了更多的调参选项,对于高度定制化的任务可能更为灵活。两者各有千秋,选择应依据具体任务需求。
四、实践应用与调参技巧
应用领域:LightGBM广泛应用于推荐系统、搜索引擎排名、金融风控、医疗诊断等多个领域,以其高效、准确的特性解决了一系列实际问题。
调参建议:
- 学习率:初始值可设为0.1,过拟合时减小。
- 树的最大深度:默认31,可根据数据复杂度调整。
- 叶子节点最小样本数:控制模型复杂度,避免过拟合。
- 特征抽样比例:通过调整
feature_fraction参数平衡模型复杂度与性能。
以下是一个使用Python和LightGBM库进行分类任务的基本示例代码。这个例子中,我们将使用经典的鸢尾花(Iris)数据集来训练一个简单的LightGBM模型,并进行基本的模型评估。代码仅供参考🐶
# 导入所需库
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 转换数据格式为LightGBM所需的类型
lgb_train = lgb.Dataset(X_train, label=y_train)
lgb_eval = lgb.Dataset(X_test, label=y_test, reference=lgb_train)# 设置参数
params = {'boosting_type': 'gbdt','objective': 'multiclass','num_class': 3, # 因为鸢尾花数据集有3个类别'metric': 'multi_logloss','num_leaves': 31,'learning_rate': 0.1,'feature_fraction': 0.9,'bagging_fraction': 0.8,'bagging_freq': 5,'verbose': 0
}# 训练模型
gbm = lgb.train(params,lgb_train,num_boost_round=20, # 可以根据需要调整迭代轮数valid_sets=lgb_eval,early_stopping_rounds=5)# 预测
y_pred = gbm.predict(X_test)
y_pred_class = y_pred.argmax(axis=1) # 将概率转换为类别# 评估
accuracy = accuracy_score(y_test, y_pred_class)
print("Accuracy:", accuracy)
print("\nClassification Report:\n", classification_report(y_test, y_pred_class))
这段代码首先导入必要的库和数据集,然后划分训练集和测试集。接着,它将数据转换为LightGBM可以处理的格式,并定义了模型的参数。之后,模型通过训练数据进行训练,并在测试集上进行预测。最后,我们计算并打印出模型的准确率和分类报告,以便评估模型的表现。
五、结论
LightGBM作为GBDT家族中的佼佼者,凭借其高效的算法设计和优异的性能表现,成为了现代机器学习领域不可或缺的工具之一。无论是处理大规模数据集,还是追求模型训练速度与资源效率的平衡,LightGBM都展现出了强大的竞争力。随着算法的持续优化和社区的不断贡献,我们有理由相信,LightGBM将在未来机器学习的探索之路上扮演更加重要的角色。


相关文章:
【机器学习】LightGBM: 优化机器学习的高效梯度提升决策树
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 LightGBM: 优化机器学习的高效梯度提升决策树引言一、LightGBM概览二、核心技术…...
【会议征稿,IEEE出版】第六届物联网、自动化和人工智能国际学术会议(IoTAAI 2024,7月26-28)
第六届物联网、自动化和人工智能国际会议(IoTAAI 2024)将于2024年07月26-28日在中国广州召开。 会议旨在拓展国际科技学术交流渠道,搭建学术资源共享平台,促进全球范围内的科技创新,提升中外学术合作。会议还鼓励不同领…...

Flask-Logging
Flask-Logging 教程 概述 flask-logging 是一个用于在 Flask 应用中实现高级日志记录功能的库。它能够帮助开发者轻松地配置和管理日志,适用于开发和生产环境。通过使用 flask-logging,可以更好地监控应用的运行状态和调试问题。 官方文档 Flask-Log…...

go匿名函数
【1】Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数 【2】匿名函数使用方式: (1)在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次(用的多) &am…...
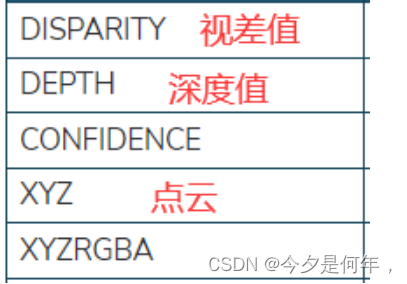
ZED双目相机环境配置
官方资料:stereolabs/zed-python-api: Python API for the ZED SDK (github.com) 1,配置ZED相机环境 1.安装CUDA 查看电脑是否安装CUDA,安装过程可参考以下博文: 如何选择匹配的CUDA版本:https://blog.csdn.net/iam…...
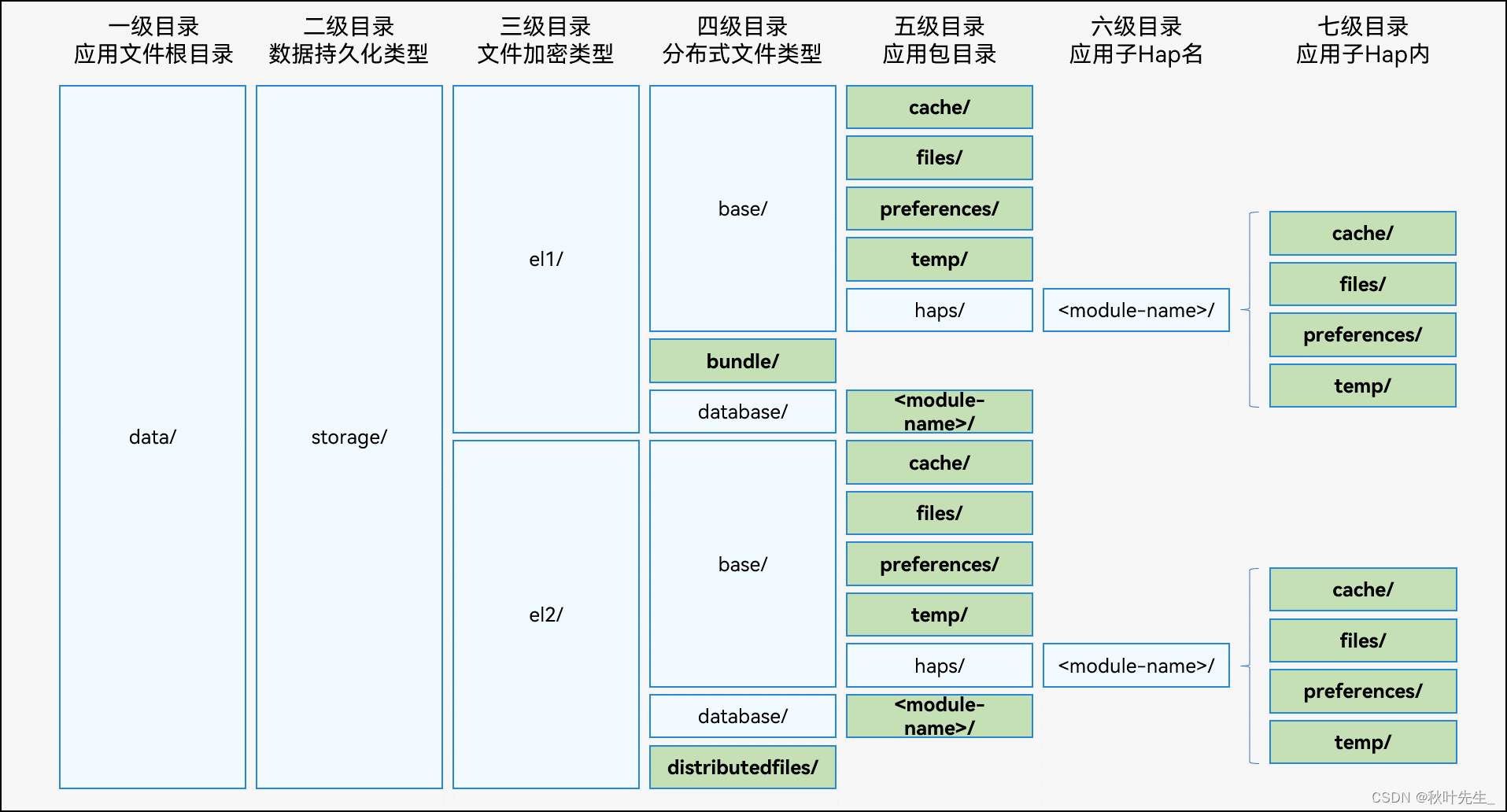
【最新鸿蒙应开发】——HarmonyOS沙箱目录
鸿蒙应用沙箱目录 1. 应用沙箱概念 应用沙箱是一种以安全防护为目的的隔离机制,避免数据受到恶意路径穿越访问。在这种沙箱的保护机制下,应用可见的目录范围即为应用沙箱目录。 对于每个应用,系统会在内部存储空间映射出一个专属的应用沙箱…...
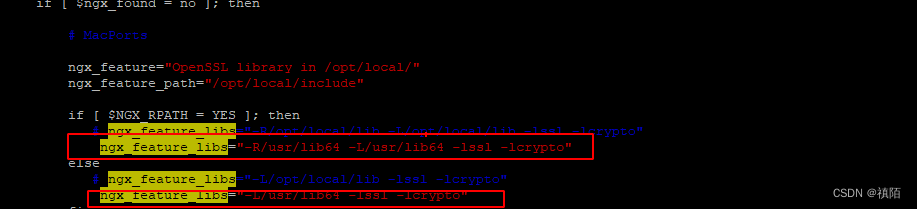
SringBoot 如何使用HTTPS请求及Nginx配置Https
SringBoot 如何使用HTTPS请求及Nginx配置Https SringBoot 如何使用HTTPS请求生成证书导入证书及配制创建配置类将pfx转成.key和.pem Nginx 安装SSL依赖./configure 安装依赖编译安装完openssl后报了新错 Nginx配置 SringBoot 如何使用HTTPS请求 生成证书 由于业务数据在传输过…...
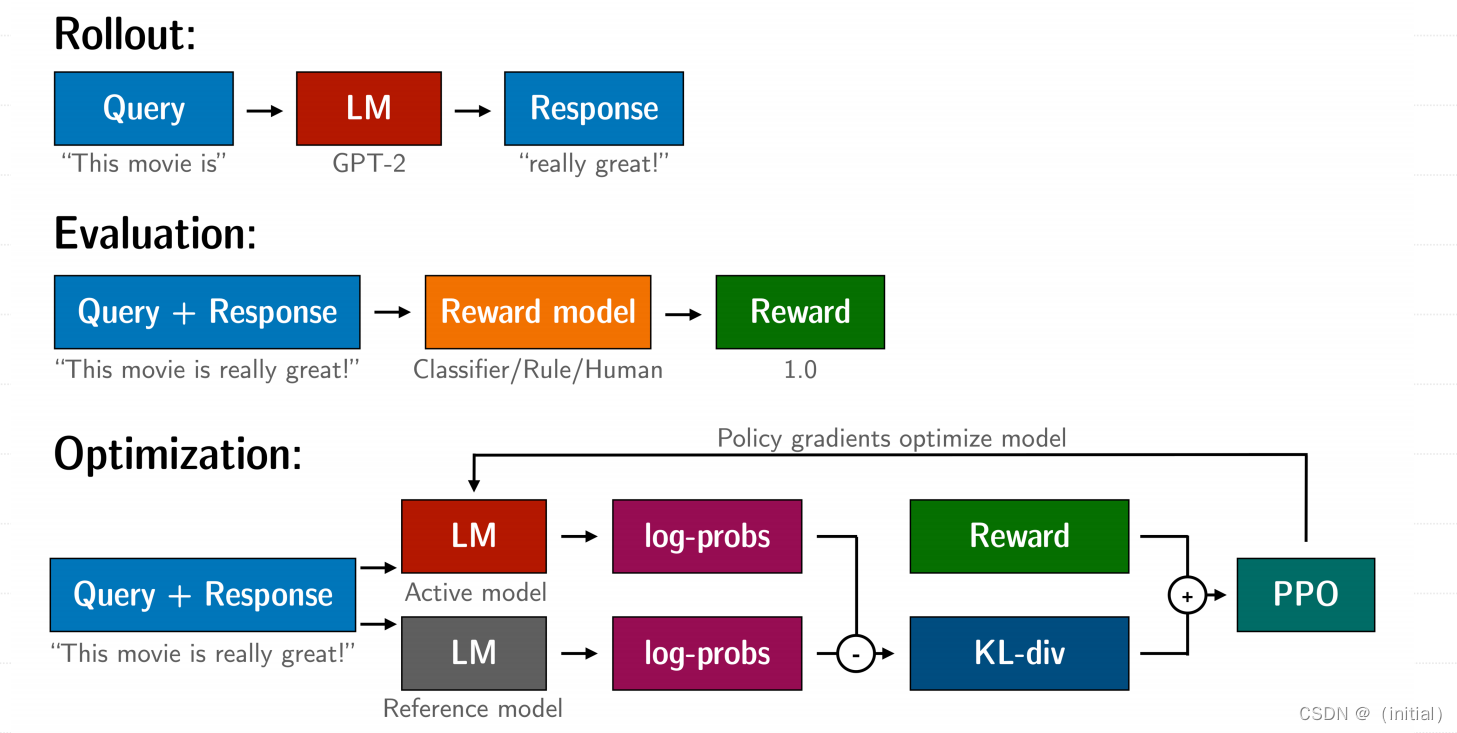
14.基于人类反馈的强化学习(RLHF)技术详解
基于人类反馈的强化学习(RLHF)技术详解 RLHF 技术拆解 RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,我们按三个步骤分解: 预训练一个语言模型 (LM) ;训练一个奖励模型 (Reward Model,RM) …...
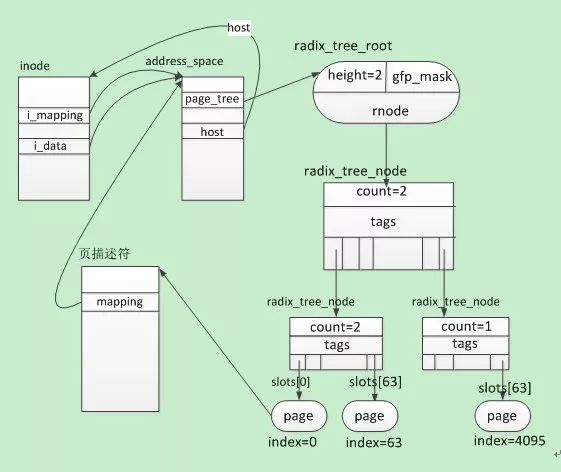
Linux Radix tree简介
文章目录 前言一、Radix tree简介二、Operations2.1 Lookup2.2 Insertion2.3 Deletion 三、Linux内核API3.1 初始化3.2 radix_tree_insert/delete3.3 radix_tree_preload3.4 radix_tree_lookup3.5 radix_tree_tag_set3.6 radix_tree_tagged 四、address_space4.1 简介4.2 相应数…...

maven 下载jar包加载顺序
在 Maven 构建过程中,依赖的下载源取决于你的 pom.xml 文件中的 配置、settings.xml 文件中的 和 配置,以及你的 Nexus 仓库的设置。以下是决定 Maven 从哪个仓库下载依赖的关键点: 仓库配置优先级 项目 pom.xml 文件中的仓库配置ÿ…...

新增多种图表类型,新增视频、流媒体、跑马灯组件,DataEase开源数据可视化分析工具v2.7.0发布
2024年6月11日,人人可用的开源数据可视化分析工具DataEase正式发布v2.7.0版本。 这一版本的功能变动包括:图表方面,新增对称条形图、桑基图、流向地图、进度条等图表类型,并对已有的仪表盘、指标卡、明细表、汇总表、水波图、象限…...
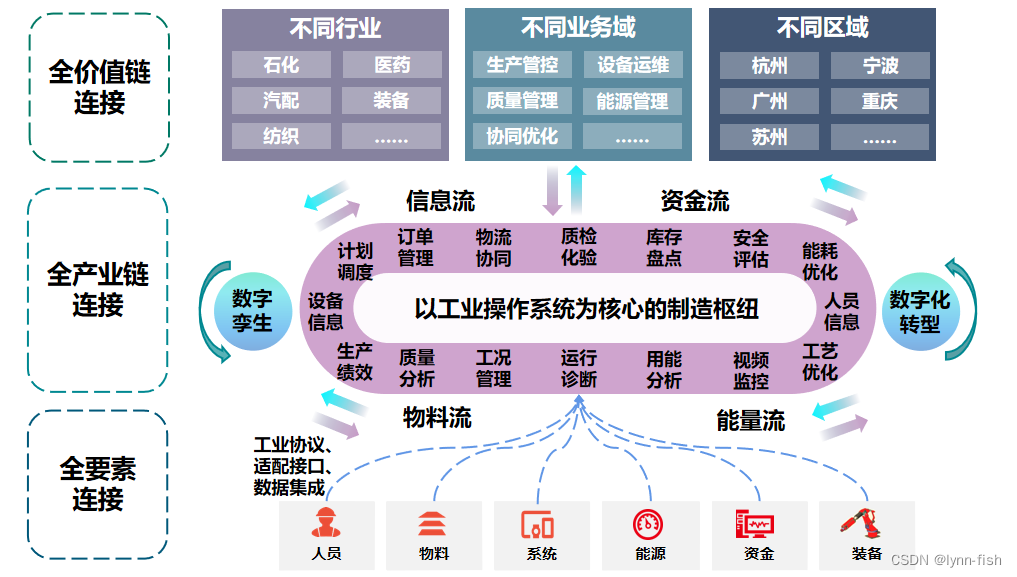
supOS工业操作系统的由来
作为“世界制造工厂”,我国拥有最庞大、最完整的工业企业集群与产业链,其中既有众多全球性制造巨头,又有数以百万计的中小型工厂。但这些企业的制造工厂在推进数字化、网络化、智能化进程时普遍受阻:1)系统软件定制程度…...

6spark期末复习
1)var a:Double5;var b:Int7;那么print(a*b) 2) var a:Int5; var bif(a>6) 7 println(b) 3)var a:Int16; var b:Int13; var cif(a>b) 5 else 7; println(c) 4. object TestDemo { print("B") def main(args: Array[String]): Unit { } } 5 def mai…...

C语言背景⾊、线条颜⾊和填充颜⾊有什么区别?何时使⽤?
一、问题 背景⾊、线条颜⾊和填充颜⾊,这⼏种颜⾊有什么区别?什么时候使⽤? 二、解答 背景⾊:是整个屏幕的底⾊,设置之后,屏幕空⽩区域都变成该颜⾊。 线条颜⾊:是画线时所⽤的颜⾊。⽂字输出也…...

Python 植物大战僵尸游戏【含Python源码 MX_012期】
简介: "植物大战僵尸"(Plants vs. Zombies)是一款由PopCap Games开发的流行塔防游戏,最初于2009年发布。游戏的概念是在僵尸入侵的情境下,玩家通过种植不同种类的植物来保护他们的房屋免受僵尸的侵袭。在游…...

搜索文档的好助手
搜索文档的好助手 AnyTXT SearcherEverything AnyTXT Searcher 文本内容搜索 下载:AnyTXT Searcher Everything 它能够基于文件名快速定文件和文件夹位置 下载:Everything...

如何计算 GPT 的 Tokens 数量?
基本介绍 随着人工智能大模型技术的迅速发展,一种创新的计费模式正在逐渐普及,即以“令牌”(Token)作为衡量使用成本的单位。那么,究竟什么是Token呢? Token 是一种将自然语言文本转化为计算机可以理解的…...

在远程服务器上安装虚拟环境
一、Anaconda环境安装 先下载Anaconda Linux版,并将其重命名为anaconda2020.sh wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2020.07-Linux-x86_64.sh --header"User-Agent: Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.11 (K…...

《站在2024年的十字路口:计算机专业是否仍是高考生的明智之选?》
文章目录 每日一句正能量前言行业竞争现状行业饱和度和竞争激烈程度[^3^]新兴技术的影响[^3^]人才需求的变化[^3^]行业创新动态如何保持竞争力 专业与个人的匹配度判断专业所需的技术能力专业核心课程对学生的要求个人兴趣和性格特点专业对口的职业发展要求实践和经验个人价值观…...

从零手写实现 nginx-23-nginx 对于 cookie 的操作
前言 大家好,我是老马。很高兴遇到你。 我们为 java 开发者实现了 java 版本的 nginx https://github.com/houbb/nginx4j 如果你想知道 servlet 如何处理的,可以参考我的另一个项目: 手写从零实现简易版 tomcat minicat 手写 nginx 系列 …...

Botty:暗黑2重制版自动化助手,告别重复刷图的终极方案
Botty:暗黑2重制版自动化助手,告别重复刷图的终极方案 【免费下载链接】botty D2R Pixel Bot 项目地址: https://gitcode.com/gh_mirrors/bo/botty 你是否厌倦了在《暗黑破坏神2:重制版》中反复刷图、手动拾取、机械操作?每…...

PromptHub:本地优先的提示词管理工具,提升AI应用开发效率
1. 项目概述与核心价值 最近在折腾AI应用开发,特别是基于大语言模型(LLM)的智能体(Agent)和自动化流程时,我发现一个普遍存在的痛点: 提示词(Prompt)的管理与复用 。无…...

Vibeproxy:轻量级可编程HTTP代理,实现API Mock与故障注入
1. 项目概述:一个轻量级的HTTP代理工具最近在折腾一些需要模拟不同网络环境或者进行API测试的项目时,我一直在寻找一个足够轻量、灵活且易于集成的HTTP代理工具。市面上成熟的代理方案很多,但要么功能过于臃肿,要么配置起来相当繁…...

开源、有文档、能上线的 .NET + Vue 通用权限系统
前言在日常项目开发中,权限管理几乎是每个系统都绕不开的基础模块。从用户登录、菜单控制到数据隔离,一套稳定、灵活、可扩展的权限体系,往往决定了整个项目的成败。然而,从零开始搭建这样的平台,不仅耗时耗力…...

基于STM32G474高精度定时器HRTIM的高频开关电源移相控制实现
1. STM32G474的HRTIM为何是高频电源设计的利器 第一次接触STM32G474的高精度定时器HRTIM时,我正被DSP28335的分辨率问题困扰。当时做的1MHz开关电源项目,150MHz主频的DSP每个时钟周期只能提供150个计数点,调节精度捉襟见肘。直到发现HRTIM的5…...

飞凌T507核心板开发实战:开机LOGO、电阻屏校准与双屏异显配置详解
1. 项目概述与核心板简介最近在做一个车载信息娱乐终端的项目,硬件平台选用了飞凌嵌入式的FETT507-C核心板。这块板子基于全志T507这颗四核车规级处理器,Cortex-A53架构,主频1.5GHz,集成了G31 GPU,标配2GB DDR3L内存和…...

Apple Silicon Mac原生Linux游戏体验:Asahi Linux驱动突破与实战指南
1. 项目概述:当Apple Silicon Mac遇见原生Linux游戏如果你和我一样,既是Mac用户,又对在Linux系统上折腾抱有热情,那么最近Asahi Linux项目的进展绝对会让你心跳加速。长久以来,在搭载Apple Silicon(M1、M2、…...

从零打造互动徽章:激光切割与电容触摸的软硬件融合实践
1. 项目概述与核心思路如果你参加过技术大会或者创客市集,一定对那些闪烁着酷炫灯光、能与人互动的徽章印象深刻。这类被称为“Badge”的可穿戴设备,早已超越了单纯的身份标识功能,成为了展示技术、创意和社群文化的微型平台。今天要分享的&a…...

双碳目标下太阳辐射预报模式【WRF-SOLAR】模拟方法及改进技术在气象、农林生态、电力等相关领域中的实践应用
太阳能是一种清洁能源,合理有效开发太阳能资源对减少污染、保护环境以及应对气候变化和能源安全具有非常重要的实际意义,为了实现能源和环境的可持续发展,近年来世界各国都高度重视太阳能资源的开发利用;另外太阳辐射的光谱成分、…...

不止是记事本!Win10右键新建菜单终极自定义指南:排序、删除、添加任意文件类型
不止是记事本!Win10右键新建菜单终极自定义指南:排序、删除、添加任意文件类型 在Windows 10的日常使用中,右键新建菜单可能是最容易被忽视却高频使用的功能之一。想象一下这样的场景:你刚刚安装了一款专业设计软件,却…...