【博客720】时序数据库基石:LSM Tree的辅助优化
时序数据库基石:LSM Tree的辅助优化
场景:
LSM Tree其实本质是一种思想,而具体是否需要WAL,内存表用什么有序数据结构来组织,磁盘上的SSTable用什么结构来存放,是否需要布隆过滤器来加快不存在数据的判断等都需要根据业务场景来做特定优化
常见优化:
提示写性能:
-
假如对写操作的吞吐量比较敏感,可采用日志策略(顺序读写,只追加不修改)来提升写性能。存在问题:数据查找需要倒序扫描,花费很多时间。比如,预写日志WAL,WAL的中心概念是数据文件(存储着表和索引)的修改必须在这些动作被日志记录之后才被写入,即在描述这些改变的日志记录被刷到持久存储以后。如果我们遵循这种过程,我们不需要在每个事务提交时刷写数据页面到磁盘,因为我们知道在发生崩溃时可以使用日志来恢复数据库:任何还没有被应用到数据页面的改变可以根据其日志记录重做(这是前滚恢复,也被称为REDO)。使用WAL可以显著降低磁盘的写次数,因为只有日志文件需要被刷出到磁盘以保证事务被提交,而被事务改变的每一个数据文件则不必被刷出。
-
压缩:对数据block进行压缩,通过增加占用CPU压缩和解压缩资源来降低数据block磁盘空间占用和读写时间。
-
批量写:LSM Tree数据写入性能已经很高了,但是批量操作时可以节省网络传输RTT时间。
-
将数据进行分片(对于网盘尤为合适,其不同文件在不同后端存储集群节点,可以并发写):这样多个分片可以并行写,如果数据路由处理得当,也可以提升数据查询速度。但是增加了维护多个分片数据读写的复杂度。
-
设计合理的多级索引
-
在允许情况下关闭自动SSTable合并,在业务量低的时间段强制执行SSTable合并。
提升读性能:
-
二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。分为文件名的二分查找和内容的二分查找
-
稀疏索引:文件内容如果都是有序的,那么针对文件里的内容的key建立其offset的稀疏索引就可以实现快速文件内容查找
-
倒排索引:将数据里的关键信息用倒排索引存起来,这样根据倒排索引能知道哪些关键信息在哪些文件,从而定向读取
-
布隆过滤器:进行查询时,首先检查布隆过滤器。如果布隆过滤器报告数据不存在,则直接返回不存在。否则,按照从新到老的顺序依次查询每个 segment。
-
TableCache:如:LevelDB 不仅提供了Bloom Filter 减少查询过程的磁盘 I/O,还利用缓存将频繁读取的 SSTable 驻留在内存中。因为程序在运行时对内存的访问具有局部性的特点,程序在对某一块的内存请求会非常频繁,如果这一块内存在第一次请求之后就被缓存,那么会大大提升之后的数据读取速度。所以,缓存设计的是否合理有效,在于缓存的命中率高不高。
相关文章:

【博客720】时序数据库基石:LSM Tree的辅助优化
时序数据库基石:LSM Tree的辅助优化 场景: LSM Tree其实本质是一种思想,而具体是否需要WAL,内存表用什么有序数据结构来组织,磁盘上的SSTable用什么结构来存放,是否需要布隆过滤器来加快不存在数据的判断等…...
C++前期概念(重)
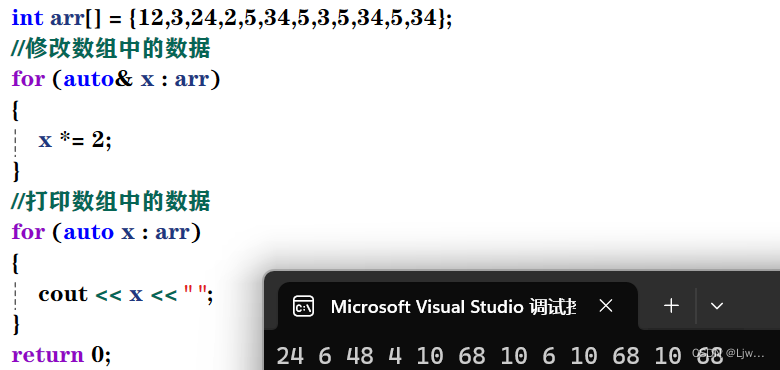
目录 命名空间 命名空间定义 1. 正常的命名空间定义 2. 命名空间可以嵌套 3.头文件中的合并 命名空间使用 命名空间的使用有三种方式: 1:加命名空间名称及作用域限定符(::) 2:用using将命名空间中某个成员引入 3:使用using namespa…...

Java字符串加密HMAC-SHA1密钥,转换成Base64编码
新建一个maven测试项目,直接把代码复制过去就行,把data和secretKey的值替换成想加密的值。 package test;import javax.crypto.Mac; import javax.crypto.spec.SecretKeySpec; import java.security.InvalidKeyException; import java.security.NoSuchA…...
【网络架构】Nginx
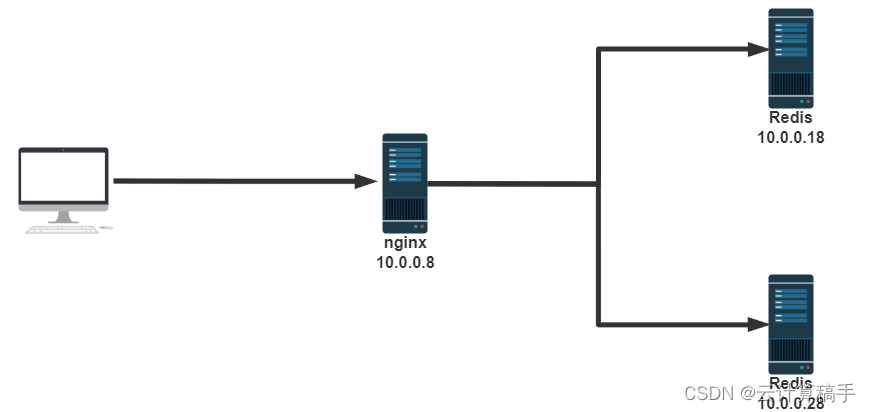
目录 一、I/O模型 1.1 Linux 的 I/O 1.2 零拷贝技术 1.3 网络IO模型 1.3.1 阻塞型 I/O 模型(blocking IO)编辑 1.3.2非阻塞型 I/O 模型 (nonblocking IO)编辑 1.3.3 多路复用 I/O 型 ( I/O multiplexing )编辑 1.3.4 信号驱动式 I/O 模型 …...

C# OpenCvSharp 逻辑运算-bitwise_and、bitwise_or、bitwise_not、bitwise_xor
bitwise_and 函数 🤝 作用或原理: 将两幅图像进行与运算,通过逻辑与运算可以单独提取图像中的某些感兴趣区域。如果有掩码参数,则只计算掩码覆盖的图像区域。 示例: 在实际应用中,可以用 bitwise_and 来提取图像中的某些部分。例如,我们可以从图像中提取出一个特定的颜…...
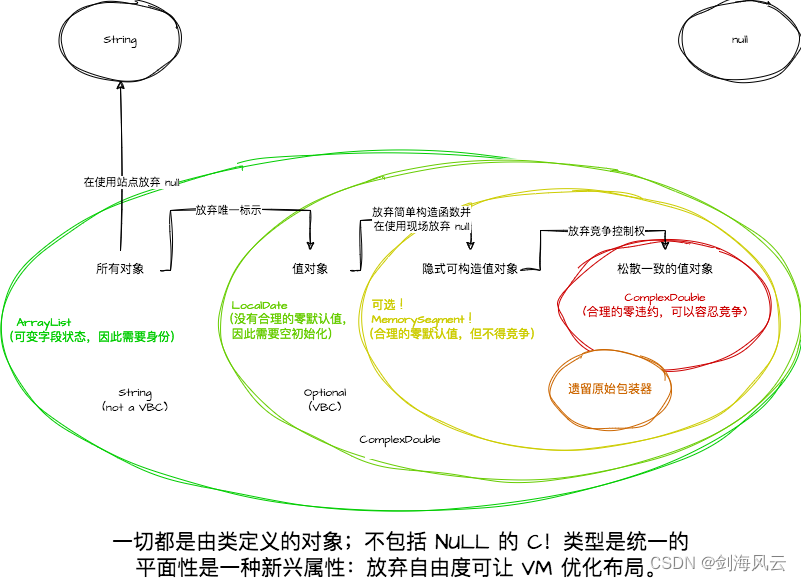
JVM常用概念之扁平化堆容器
扁平化堆容器是OpenJDK Valhalla 项目提出的,其主要目标为将值对象扁平化到其堆容器中,同时支持这些容器的所有指定行为,从而达到不影响原有功能的情况下,显著减少内存空间的占用(理想条件下可以减少24倍)。…...
)
python面试题5:浅拷贝和深拷贝之间有什么区别?(难度--中等)
文章目录 题目回答1.浅拷贝2.深拷贝 题目 浅拷贝和深拷贝之间有什么区别? 回答 1.浅拷贝 浅拷贝对于不可变数据,如字符串,整数,数组,往往是直接复制其的值。对于可变对象如列表,则是指向同一个地址。这…...

Jetson Linux 上安装ZMQ
1. 安装ZMQ 框架 apt-get install libzmq3-dev 2. 或者自己build ZMQ https://github.com/zeromq/libzmq.git 参考官网教程 3. 安装CPPZMQ CPPZMQ 是ZMQ 的友好的C封装,只需要一个zmq.hpp 头文件即可 git clone https://github.com/zeromq/cppzmq.git cd cppz…...
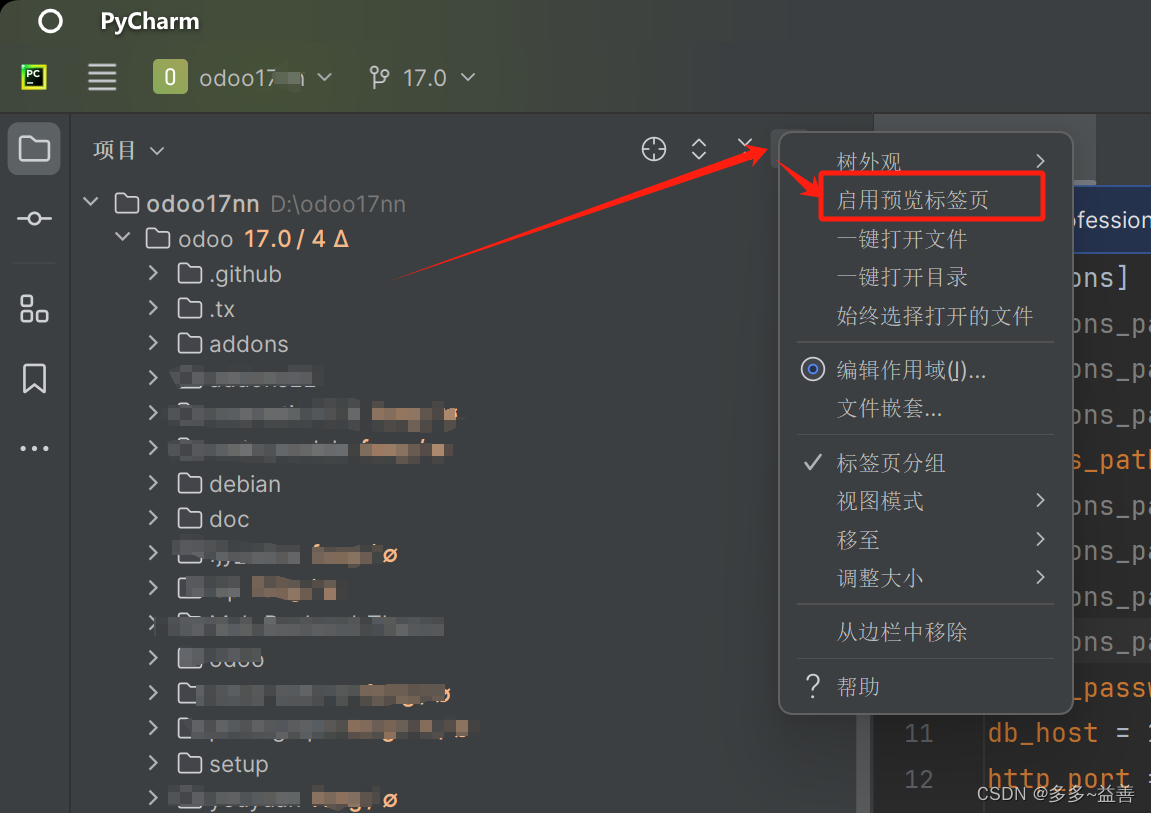
【Pycharm】设置双击打开文件
概要 习惯真可怕。很多小伙伴用习惯了VsCode开发,或者其他一些开发工具,然后某些开发工具是单击目录文件就能打开预览的,而换到pycharm后,发现目录是双击才能打开预览,那么这个用起来就特别不习惯。 解决办法 只需一…...

Web前端后端架构:构建高效、稳定与可扩展的互联网应用
Web前端后端架构:构建高效、稳定与可扩展的互联网应用 在构建互联网应用的过程中,Web前端与后端架构的设计与实施至关重要。一个优秀的架构能够确保应用的稳定性、高效性和可扩展性,为用户提供流畅、安全的体验。本文将从四个方面、五个方面…...

数据仓库核心:事实表深度解析与设计指南
文章目录 1. 引言1.1基本概念1.2 事实表定义 2. 设计原则2.1 原则一:全面覆盖业务相关事实2.2 原则二:精选与业务过程紧密相关的事实2.3 原则三:拆分不可加事实为可加度量2.4 原则四:明确声明事实表的粒度2.5 原则五:避…...

Reactor和epoll
Reactor模式和epoll都是与事件驱动的网络编程相关的术语,但它们属于不同的概念层面: Reactor模式 Reactor模式是一种事件驱动的编程模型,用于处理并发的I/O事件。这种模式使用一个或多个输入源(如套接字),…...
Mybatis-Plus多种批量插入方案对比
背景 六月某日上线了一个日报表任务,因是第一次上线,故需要为历史所有日期都初始化一次报表数据 在执行过程中发现新增特别的慢:插入十万条左右的数据,SQL执行耗费高达三分多钟 因很早就听闻过mybatis-plus的[伪]批量新增的问题&…...

数据库面试
1. 简单介绍一下Spring中的事务管理。 答:事务就是对一系列的数据库操作(比如将insert,delete,update,select多条sql语句)作为一个整体执行,进行统一的提交或回滚操作,如果这组sql语…...

探索Web Components
title: 探索Web Components date: 2024/6/16 updated: 2024/6/16 author: cmdragon excerpt: 这篇文章介绍了Web Components技术,它允许开发者创建可复用、封装良好的自定义HTML元素,并直接在浏览器中运行,无需依赖外部库。通过组合HTML模…...

摄影师在人工智能竞赛中与机器较量并获胜
摄影师在人工智能竞赛中与机器较量并获胜 自从生成式人工智能出现以来,由来已久的人机大战显然呈现出一边倒的态势。但是有一位摄影师,一心想证明用人眼拍摄的照片是有道理的,他向算法驱动的竞争对手发起了挑战,并取得了胜利。 迈…...

CMU最新论文:机器人智慧流畅的躲避障碍物论文详细讲解
CMU华人博士生Tairan He最新论文:Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion 代码开源:Code: https://github.com/LeCAR-Lab/ABS B站实际效果展示视频地址:bilibili效果地址 我会详细解读论文的内容,让我们开始吧…...

Spring中自定义注解进行类方法增强
说明 说到对类方法增强,第一时间想到自定义注解,通过aop切面进行实现。这是一种常用做法,但是在某些场景下,如开发公共组件,定义aop切面可能不是最优方案。以后通过原生aop方式,自定义注解,对类…...

TS:元组
问: 解释下什么是元组 回答: 元组(Tuple)是一种数据结构,类似于数组,但与数组不同的是,元组中的元素类型可以各不相同,且元组的长度是固定的。元组在许多编程语言中都有实现,包括 TypeScript…...

微服务 | Springboot整合Dubbo+Nacos实现RPC调用
官网:Apache Dubbo 随着互联网技术的飞速发展,越来越多的企业和开发者开始关注微服务架构。微服务架构可以将一个大型的应用拆分成多个独立、可扩展、可维护的小型服务,每个服务负责实现应用的一部分功能。这种架构方式可以提高开发效率&…...

为什么你的DeepSeek Terraform配置总在CI/CD中崩溃?5个被官方文档隐藏的state锁机制真相
更多请点击: https://intelliparadigm.com 第一章:为什么你的DeepSeek Terraform配置总在CI/CD中崩溃?5个被官方文档隐藏的state锁机制真相 DeepSeek 与 Terraform 的深度集成虽提升了 AI 基础设施编排能力,但其 state 锁行为在 …...
轻量级车联网音视频集群)
基于 JTT1078MediaServer 的集群方案实践(Nginx + 溯源模式)轻量级车联网音视频集群
基于JTT1078MediaServer的集群方案实践(Nginx溯源模式)轻量级车联网音视频集群 在车联网JT/T1078音视频平台开发与部署中,单机JTT1078MediaServer在设备量少、并发低时可稳定运行,但随着接入设备增多、多路视频同时播放࿰…...

粒子群灰狼优化算法稀疏码设计【附代码】
✨ 长期致力于稀疏码多址接入、星型正交振幅调制、功率不平衡码本、粒子群算法、混合粒子群灰狼优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...

ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件
ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM格式文件无法在普通…...

基于LLM的多智能体协作框架:从原理到实践构建自主开发团队
1. 项目概述与核心价值最近在开源社区里,一个名为zxkane/autonomous-dev-team的项目引起了我的注意。乍一看这个标题,你可能会联想到科幻电影里的全自动机器人编程,或者是一些过于理想化的“AI接管开发”的噱头。但在我花时间深入研究和实践之…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

对比体验Taotoken平台不同大模型在创意生成上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验Taotoken平台不同大模型在创意生成上的差异 对于内容创作者而言,大模型是激发灵感、提升效率的得力工具。然而…...

告别训练中断:在PyCharm中利用Tmux实现远程GPU服务器的持久化会话
1. 为什么需要持久化训练会话? 作为一名长期在深度学习领域摸爬滚打的工程师,我最头疼的就是训练过程中突然断网或者需要关闭电脑的情况。想象一下,你正在用PyCharm远程连接公司的GPU服务器训练一个需要48小时的模型,突然家里停电…...

使用Taotoken CLI工具一键配置多开发环境下的API访问密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的API访问密钥 在团队协作或个人多设备开发场景中,为不同的AI开发工具&…...