tokenization(二)子词切分方法
文章目录
- 概述
- BPE
- 构建词表
- 词元化
- 代码实现
- WordPiece
- Unigram
- 估算概率(E)
- 删除词元(M)
- 参考资料
概述
接上回,子词词元化(Subwords tokenization)是平衡字符级别和词级别的一种方法,也是目前用得最多的方法。
子词词元化的目标有2个:
● 常见词不应该切分为更小的单元
● 罕见词应该被分解为有意义的子词
BPE
BPE(Byte-Pair Encoding)最早用于数据压缩[3],后面由论文[4]将其应用于切词。模型词表通过统计出现频次最高的词或子词而构成,可以达到子词词元化的2个目标。BPE分为两步:
● 构建词表:根据预料构建词表,可理解为训练。
● 词元化:对文本利用上述词表进行词元化,可理解为推理。
字节级(Byte-level)BPE 通过将字节视为合并的基本符号,用来改善多语言语料库(例如包含非ASCII字符的文本)的分词质量。GPT-2、BART 和 LLaMA 等大语言模型都采用了这种分词方法
构建词表
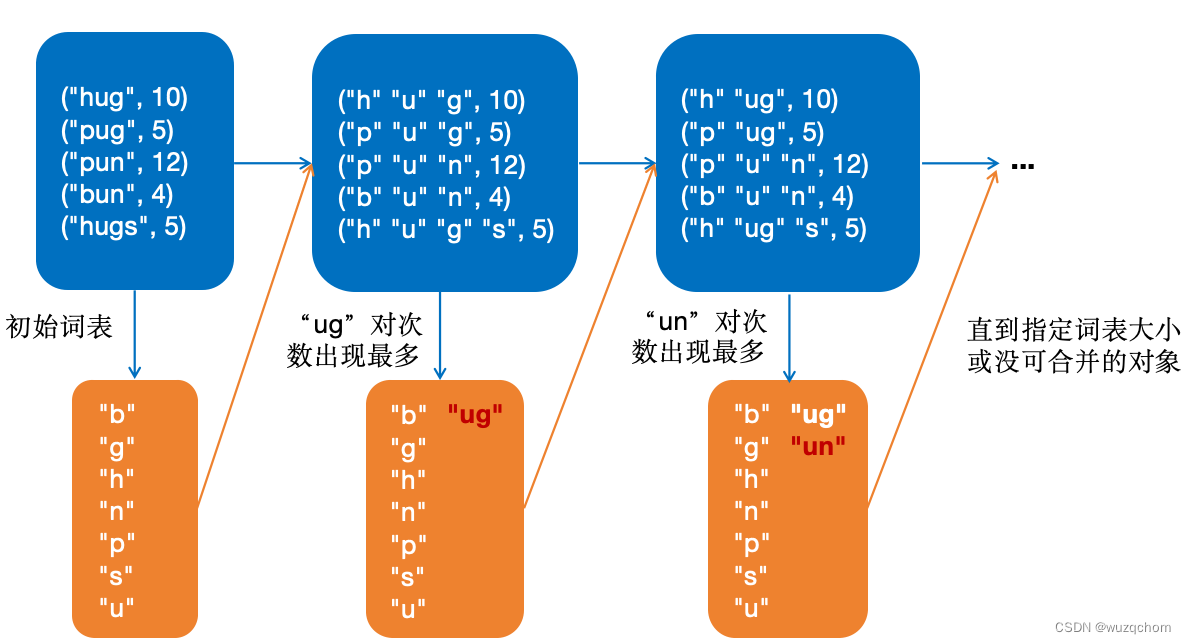
最初,BPE按照所有单词的字符表作为初始词表,将每个单词切分成字符序列,然后每次迭代选取出现次数最多的字符对加入词表,直到没有可合并的字符或者词表到预设的大小为止。
这里具体构建过程以Huggingface上的例子说明,假设单词和出现的频次如下:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
BPE构建词表过程如下图所示:
词元化
该过程可以理解为推理,应用上面的词表将新文本进行词元化。
代码实现
对Huggingface上的代码稍加整理、并增加了一些注释:
from collections import defaultdict
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("gpt2")corpus = ["This is the Hugging Face Course.","This chapter is about tokenization.","This section shows several tokenizer algorithms.","Hopefully, you will be able to understand how they are trained and generate tokens.",
]def stat_word_freqs():"""统计语料中的词频"""word_freqs = defaultdict(int)for text in corpus:words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)new_words = [word for word, offset in words_with_offsets]for word in new_words:word_freqs[word] += 1return word_freqsdef stat_alphabet(word_freqs):"""获取所有的字符"""alphabet = []for word in word_freqs.keys():for letter in word:if letter not in alphabet:alphabet.append(letter)alphabet.sort()return alphabetdef compute_pair_freqs(splits, word_freqs):"""统计每一个对出现的频次"""pair_freqs = defaultdict(int)for word, freq in word_freqs.items():split = splits[word]if len(split) == 1:continuefor i in range(len(split) - 1):pair = (split[i], split[i + 1])pair_freqs[pair] += freqreturn pair_freqsdef pick_best_pais(pair_freqs):best_pair = ""max_freq = None# 找到出现频次最多的对for pair, freq in pair_freqs.items():if max_freq is None or max_freq < freq:best_pair = pairmax_freq = freqreturn best_pair, max_freqdef merge_pair(a, b, splits, word_freqs):for word in word_freqs:split = splits[word]if len(split) == 1:continuei = 0while i < len(split) - 1:if split[i] == a and split[i + 1] == b:split = split[:i] + [a + b] + split[i + 2 :]else:i += 1splits[word] = splitreturn splitsdef make_vacab(vocab, merges, splits, word_freqs, vocab_size=20):"""制作词表"""while len(vocab) < vocab_size:pair_freqs = compute_pair_freqs(splits, word_freqs)best_pair, _ = pick_best_pais(pair_freqs)splits = merge_pair(*best_pair, splits, word_freqs)merges[best_pair] = best_pair[0] + best_pair[1]vocab.append(best_pair[0] + best_pair[1])def tokenize(text, merges):"""对文本进行词元切分"""pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)pre_tokenized_text = [word for word, offset in pre_tokenize_result]splits = [[l for l in word] for word in pre_tokenized_text]for pair, merge in merges.items():for idx, split in enumerate(splits):i = 0# 如果可以合并,则尽可能长while i < len(split) - 1:if split[i] == pair[0] and split[i + 1] == pair[1]:split = split[:i] + [merge] + split[i + 2 :]else:i += 1splits[idx] = splitreturn sum(splits, [])def main():# 1. 统计词频word_freqs = stat_word_freqs()print('word_freqs=', word_freqs)# 2. 统计字符表alphabet = stat_alphabet(word_freqs)vocab = ["<|endoftext|>"] + alphabet.copy()splits = {word: [c for c in word] for word in word_freqs.keys()}print('splits=', splits)print('alphabet=', alphabet)merges = {}# 3. 根据语料制作词表make_vacab(vocab, merges, splits, word_freqs)print('merges=', merges)print('vocab=', vocab)# 应用词元化res = tokenize("This is not a token.", merges)# 输出:['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']print(res)if __name__ == '__main__':main()
WordPiece
BERT中使用的WordPiece方法进行词元化,其思想和BPE类似。主要有以下不同点:
- 使用
##代表非开始字符,如“word”按照字符切分为:w ##o ##r ##d - 在合并字符对的时候,BPE使用的是出现最多的对,而“WordPiece”选择依据如下所示:
s c o r e = # p a i r # f i r s t _ e l e m e n t × # s e c o n d _ e l e m e n t score=\frac{\#pair}{\#first\_element \times \#second\_element} score=#first_element×#second_element#pair
使用BPE中的例子,切分后的语料如下所示:
按照上述计算方式,应该合并“##g”和“##s”。("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)- BPE选中的“ug”对得分为: s c o r e u g = 25 36 × 25 = 1 36 score_{ug}=\frac{25}{36 \times 25}=\frac{1}{36} scoreug=36×2525=361
- “gs”对得分为: s c o r e g s = 5 20 × 5 = 1 20 score_{gs}=\frac{5}{20 \times 5}=\frac{1}{20} scoregs=20×55=201
Unigram
T5、XLNet等模型使用Unigram词元化方法。Unigram的思想和前两种词元化方法截然不同,最刚开始尽可能找到所有的子词,然后不断地删除,直到达到设定的词表大小为止。
Unigram方法本质上是一个基于词袋的统计语言模型。
使用之前的例子:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
我们可以通过子串的方式得到最原始的词表:
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"]
然后通过不断地迭代删除词元,直到达到设定的词表大小为止。采用期望最大化(EM)算法进行迭代。
估算概率(E)
该步骤找到最佳的切分方式,即需要计算每一种可能切分的概率,选取概率最大的切分。概率计算方式为每个次元概率相乘,如对于“pug”,其中一种切分方式的概率计算如下:
p ( “ p " , “ u " , “ g " ) = p ( “ p " ) × p ( “ u " ) × p ( “ g " ) = 5 210 × 36 210 × 20 210 = 0.000389 p(“p", “u", “g")=p(“p")\times p(“u") \times p(“g")=\frac{5}{210} \times \frac{36}{210} \times \frac{20}{210}=0.000389 p(“p",“u",“g")=p(“p")×p(“u")×p(“g")=2105×21036×21020=0.000389
同理,可以计算出其它2种切分的概率:
["p", "u", "g"]: 0.000389
["p", "ug"]: 0.0022676
["pu", "g"]: 0.0022676
从以上选取概率最大的切分方式,如果一样泽随机选。在实际使用中,所有可能切分方式可以使用维特比算法得到。
删除词元(M)
即一次计算每一个词元的损失,然后删除损失最小的词元。我们使用-logP计算得到语料中每个词的词元切分及得分:
"hug": ["hug"] (score 0.071428)
"pug": ["pu", "g"] (score 0.007710)
"pun": ["pu", "n"] (score 0.006168)
"bun": ["bu", "n"] (score 0.001451)
"hugs": ["hug", "s"] (score 0.001701)
假设删除“hug”,相关词得分变化:
"hug": ["hu", "g"] (score 0.006802)
"hugs": ["hu", "gs"] (score 0.001701)
可以计算出该词元删除后增加的损失为:
- 10 * (-log(0.071428)) + 10 * (-log(0.006802)) = 23.5
同理可以计算出在这次的迭代中应该删除词元pu,使其总体损失最小。
不断迭代E-M,直到词表到设定大小为止。
参考资料
- Huggingface NLP course
- 大规模语言模型:从理论到实践 – 张奇、桂韬、郑锐、黄萱菁
- A New Algorithm for Data Compression
- Neural Machine Translation of Rare Words with Subword Units
相关文章:
tokenization(二)子词切分方法
文章目录 概述BPE构建词表词元化代码实现 WordPieceUnigram估算概率(E)删除词元(M) 参考资料 概述 接上回,子词词元化(Subwords tokenization)是平衡字符级别和词级别的一种方法,也…...
慈善组织管理系统设计
一、用户角色与权限 慈善组织管理系统设计首先需要考虑的是用户角色与权限的划分。系统应明确区分不同的用户角色,如管理员、项目负责人、财务人员、捐赠者等,并为每个角色分配相应的权限。管理员应拥有最高的权限,能够管理系统全局…...
大疆Pocket3手持记录仪格式化恢复方法
大疆Pocket系列是手持类产品,此类产品处理过不少像Pocket、Pocket2、Pocket3基本上涉及Pocket全系列,今天来看一个Pocket3误格式化之后的恢复方法。 故障存储: 120G存储卡 /文件系统:exFAT 故障现象: 在备份视频数据时由于操作失误导致初…...

Mybatis的面试题
1. 什么是一级缓存什么是二级缓存? MyBatis是一款优秀的持久层框架,它提供了一级缓存和二级缓存来提高数据库访问性能。 一级缓存 一级缓存是指在同一个SqlSession中进行的缓存。当MyBatis执行查询时,查询结果会被缓存在SqlSession的内存中…...
)
渗透测试之内核安全系列课程:Rootkit技术初探(五)
今天,我们来讲一下内核安全! 本文章仅提供学习,切勿将其用于不法手段! 目前,在渗透测试领域,主要分为了两个发展方向,分别为Web攻防领域和PWN(二进制安全)攻防领域。在…...
探索C嘎嘎的奇妙世界:第三关---缺省参数与函数重载
在c语言中,我们常常在对有参函数进行传参,这样的繁琐过程,C祖师爷对此进行了相关改进,多说无益,上干货: 1 缺省参数: 缺省参数是指在声明或定义函数时为函数的形参指定一个默认值(默认参数)。在调用该函数时,如果没有指定实参,则…...

docker拉取镜像太慢解决方案
前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 创建daemon.json文件,输入以下信息 vim /etc/docker/daemon.json{"registry-mirrors": ["https://9cpn8tt6.mirror…...
仅凭一图,即刻定位,AI图像定位技术
AI图像定位技术,解锁空间密码!仅凭一图,即刻定位,精准至经纬度坐标,让世界无处不晓。 试试看能否猜中这张自拍照的背景所在?可别低估了A的眼力,答案说不定会让你大吃一惊呢。 近期,…...

跟着刘二大人学pytorch(第---12---节课之RNN基础篇)
文章目录 0 前言0.1 课程视频链接:0.2 课件下载地址: 1 Basic RNN1.1 复习DNN和CNN1.2 直观认识RNN1.3 RNN Cell的内部计算方式 2 具体什么是一个RNN?3 使用pytorch构造一个RNN3.1 手动构造一个RNN Cell来实现RNN3.2 直接使用torch中现有的RN…...

父亲节 | 10位名家笔下的父亲,读懂那份孤独而深沉的父爱
Fathers Day 母爱如水,父爱如山。 相对于母爱的温柔,父亲的爱多了几分静默和深沉。 读完10位名家笔下的父亲,我们就会明白,到底亏欠了父亲多少。 不要让自己有“子欲养而亲不待”的后悔和遗憾, 多给父亲一些爱的表示&a…...

股市中的牛市和熊市是什么?它们是怎么来的?
中文版 股市中的牛市和熊市 定义 牛市: 牛市指的是金融市场中证券价格普遍上升或预期上升的时期。这个术语最常用于股票市场,但也可以适用于交易的其他资产,如债券、货币和商品。特征: 投资者信心增加。交易量上升。积极的经济指…...
基于51单片机万年历设计—显示温度农历
基于51单片机万年历设计 (仿真+程序+原理图+设计报告) 功能介绍 具体功能: 本系统采用单片机DS1302时钟芯片LCD1602液晶18b20温度传感器按键蜂鸣器设计而成。 1.可以显示年月日、时分秒、星期、温度值。…...

springboot-自定义properties文件
在springboot中,如果我们想加载外部的配置文件,但是又不想与其他的配置文件产生明显的耦合,那么我们可以把这些配置文件,单独弄成一个独立的配置文件,比如下面的配置文件,我们想把这些配置移动到user.prope…...

java类的访问权限
在java中,针对类,成员方法和属性,java提供了4种访问控制权限,分别是private,default,protected和public。 这四种访问控制权限按级别由低到高的次序排列分别是privae,default,protected,public private:私有访问权限,…...
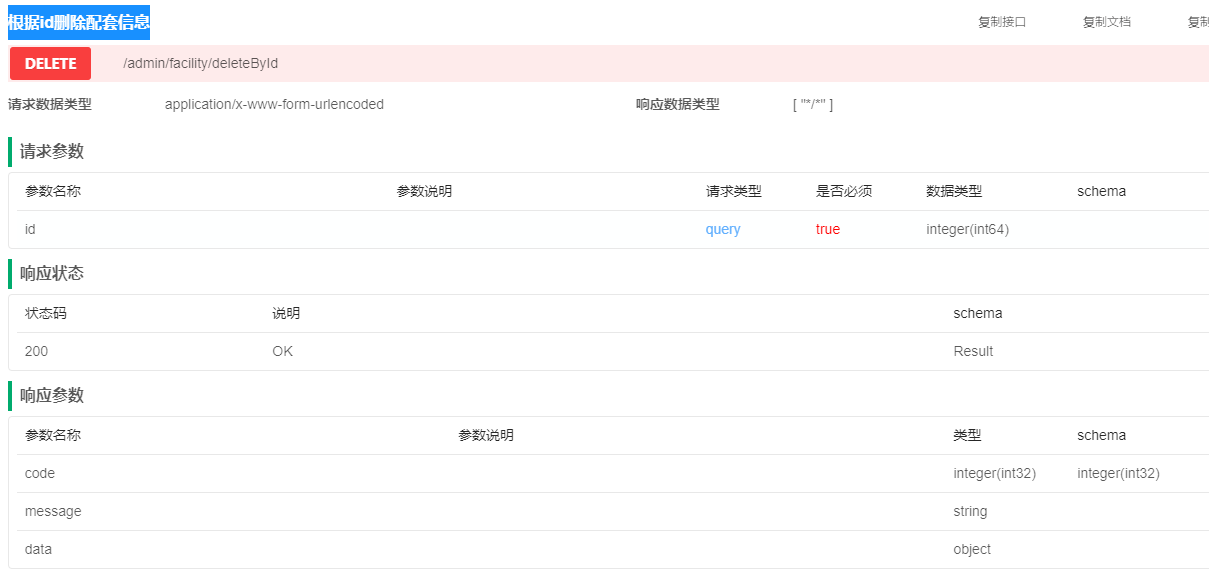
【SpringBoot + Vue 尚庭公寓实战】标签和配套管理接口实现接口实现(六)
【SpringBoot Vue 尚庭公寓实战】标签和配套管理接口实现接口实现(六) 文章目录 【SpringBoot Vue 尚庭公寓实战】标签和配套管理接口实现接口实现(六)1、保存或更新标签信息2、根据id删除标签信息3、根据类型查询配套列表4、新…...

Web前端中横线:深入探索与实际应用
Web前端中横线:深入探索与实际应用 在Web前端开发的广袤领域中,中横线这一看似简单的元素,实则蕴含着丰富的设计哲学和技术实现。本文将从四个方面、五个方面、六个方面和七个方面,对中横线在Web前端中的应用进行深入剖析&#x…...

鸿蒙 游戏来了 鸿蒙版 五子棋来了 我不允许你不会
团队介绍 作者:徐庆 团队:坚果派 公众号:“大前端之旅” 润开鸿生态技术专家,华为HDE,CSDN博客专家,CSDN超级个体,CSDN特邀嘉宾,InfoQ签约作者,OpenHarmony布道师,电子发烧友专家博客,51CTO博客专家,擅长HarmonyOS/OpenHarmony应用开发、熟悉服务卡片开发。欢迎合…...
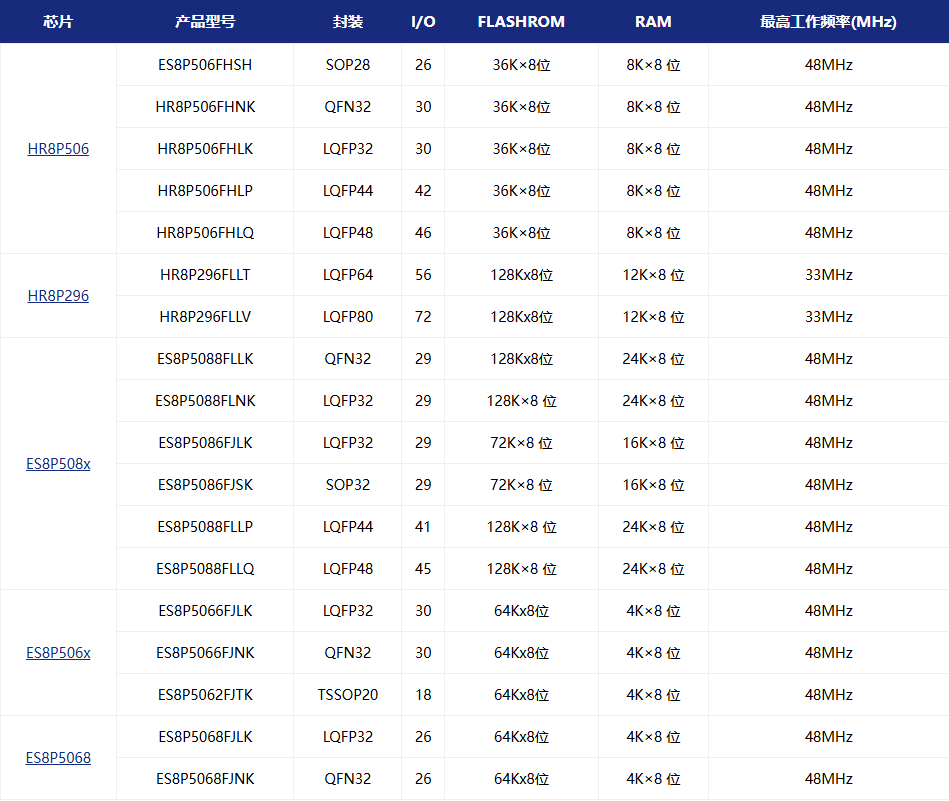
国产MCU芯片(2):东软MCU概览及触控MCU
前言: 国产芯片替代的一个主战场之一就是mcu,可以说很多国内芯片设计公司都打算或者已经在设计甚至有了一款或多款的量产产品了,这也是国际大背景决定的。过去的家电市场、过去的汽车电子市场,的确国产芯片的身影不是很常见,如今不同了,很多fabless投身这个行业,一种是…...

气膜馆的保温措施—轻空间
气膜馆是一种新型的建筑形式,广泛应用于体育场馆、仓储、展览等多个领域。其主要特点是通过气体压力支撑膜结构,实现大跨度无柱空间。为了保证气膜馆在不同气候条件下的使用舒适性和能源效率,保温措施至关重要。以下是气膜馆常见的保温措施及…...

UniVue更新日志:使用Carousel组件实现轮播图效果
github仓库 稳定版本仓库:https://github.com/Avalon712/UniVue 开发版本仓库:https://github.com/Avalon712/UniVue-Develop UniVue扩展框架-UniVue源生成器仓库:https://github.com/Avalon712/UniVue-SourceGenerator 更新说明 今天的更…...

Claude API开发实战:从模型选型到工具调用,一站式资源与代码详解
1. 项目概述与核心价值最近在折腾AI应用开发的朋友,估计没少为Claude API的调用和管理头疼。官方文档虽然详尽,但当你需要快速查找某个特定端点、对比不同模型参数,或者只是想找个现成的代码片段时,那种在多个页面间跳转、反复搜索…...

交完Essay才发现Turnitin更新了AI检测?我是这么应对的
上学期我的一个朋友被约谈了。 教授发邮件说:"你的Essay和AI生成文本相似度过高,请来办公室解释。" 他确实用了AI——谁没用呢——但他也认真改写了好几遍。问题是,Turnitin在2025年更新了AI检测模型,现在它不只看词汇…...

从机械奇观到数字逻辑:FPGA设计中的状态机与系统思维
1. 项目概述:当鲁布戈德堡机械遇见数字逻辑的灵魂我的一位老朋友杰伊道林最近给我分享了两段视频,看完之后,我的第一反应是“袜子都要被震飞了”——这让我认真考虑,是不是该换双带松紧带的袜子。这两段视频,一段是森林…...

边缘部署模式:在边缘位置部署应用
边缘部署模式:在边缘位置部署应用 一、边缘部署概述 1.1 边缘部署的定义 边缘部署是指将应用或服务部署在靠近用户或数据源的边缘位置,以减少延迟、提高性能、降低带宽消耗并增强数据隐私保护。 1.2 边缘部署的价值 低延迟:减少数据传输延迟高…...

Shoelace自动加载器:终极懒加载Web组件完整指南 [特殊字符]
Shoelace自动加载器:终极懒加载Web组件完整指南 🚀 【免费下载链接】shoelace Shoelace is now Web Awesome. Come see what’s new! 项目地址: https://gitcode.com/gh_mirrors/sh/shoelace Shoelace自动加载器是Shoelace Web组件库中一个革命性…...

GlosSI完全攻略:一键实现Steam控制器全局支持的终极方案
GlosSI完全攻略:一键实现Steam控制器全局支持的终极方案 【免费下载链接】GlosSI Tool for using Steam-Input controller rebinding at a system level alongside a global overlay 项目地址: https://gitcode.com/gh_mirrors/gl/GlosSI 有没有想过…...

小熊猫Dev-C++:零配置C/C++开发环境的终极指南
小熊猫Dev-C:零配置C/C开发环境的终极指南 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 小熊猫Dev-C(Red Panda Dev-C)是一款专为C/C开发者设计的现代化集成开发环境&…...

NSA 5G:从双连接到网络切片,解析5G组网演进之路
1. 非独立组网5G:一场关于“先有鸡还是先有蛋”的行业博弈如果你在2017年的世界移动通信大会(MWC)现场,可能会感到一丝困惑。前一年,整个行业还在为5G描绘一幅彻底颠覆4G、开启万物互联新纪元的宏伟蓝图。然而一年后&a…...

离散数学“黑话”指南:命题、谓词、群论,一次讲清程序员常遇到的术语
离散数学“黑话”指南:程序员视角下的概念破译 刚接触算法优化时,我盯着论文里的"幺半群"概念发愣——这和我在代码里写的if-else有什么关系?直到某天用状态机处理用户权限时突然顿悟:原来离散数学的抽象术语࿰…...

在Node.js后端服务中集成Taotoken调用大模型指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用大模型指南 将大模型能力集成到后端服务是现代应用开发的常见需求。Taotoken平台提供了OpenA…...