Python8 使用结巴(jieba)分词并展示词云
Python的结巴(jieba)库是一个中文分词工具,主要用于对中文文本进行分词处理。它可以将输入的中文文本切分成一个个独立的词语,为后续的文本处理、分析、挖掘等任务提供基础支持。结巴库具有以下功能和特点:
-
中文分词: 将中文文本按照一定的规则和算法切分成独立的词语,方便后续的文本处理和分析。
-
支持不同分词模式: 结巴库支持精确模式、全模式和搜索引擎模式等不同的分词模式,满足不同场景下的需求。
-
支持自定义词典: 用户可以根据实际需求自定义词典,增加、删除或修改词语,提高分词的准确性。
-
高效处理: 结巴库采用了基于前缀词典的分词算法,具有较高的分词速度和效率。
-
开源免费: 结巴库是一个开源项目,可以免费获取并在各种应用中使用,广泛应用于文本处理、自然语言处理等领域。
本次将展示一个使用jieba库生成16首歌曲歌词文本关键词词云的示例,演示的形象化表达如下:

1.用jieba库进行不同模式的分词
示例代码:
import jieba # 导入结巴模块
seg_list=jieba.cut('我来到北京清华大学',cut_all=True) # 使用全模式分词将文本"我来到北京清华大学"进行分词
# (cut_all=True)将使用全模式将句子中所有可能的词语都进行分词,可能会产生大量的冗余词语,这种模式适用于对文本进行初步分析或者处理速度要求较高的场景
print("全模式:"+"/".join(seg_list))seg_list = jieba.cut("我来到北京清华大学", cut_all=False) # (cut_all=False或者不指定参数)将使用精准模式分词将文本"我来到北京清华大学"进行分词
print("精准模式:"+"/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精准模式
print(','.join(seg_list))seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
# 搜索引擎模式是在精准模式的基础上,对长词再次切分,以适应搜索引擎的需求,这种模式适用于对文本进行搜索引擎优化或者需要更多精准匹配的场景
print(','.join(seg_list))
运行结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\26320\AppData\Local\Temp\jieba.cache
Loading model cost 0.398 seconds.
Prefix dict has been built successfully.全模式:我/来到/北京/清华/清华大学/华大/大学
精准模式:我/来到/北京/清华大学
他,来到,了,网易,杭研,大厦
小明,硕士,毕业,于,中国,科学,学院,科学院,中国科学院,计算,计算所,,,后,在,日本,京都,大学,日本京都大学,深造
2.根据歌词文本文件使用jieba库分析功能生成词云
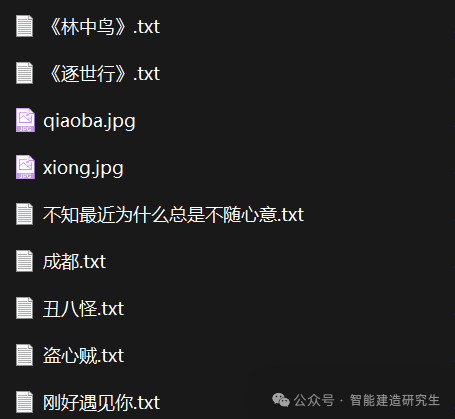
将指定文件夹‘lyric’中的所有文本文件的内容合并到一个字符串中,并打印出这个字符串。该文件夹中共有16首歌曲的歌词文本文件和两张图片。
import os # os模块用于处理文件路径
content='' # 定义空字符串content用于存储所有文本文件的内容
content_path=r'F:\桌面\python100\files\lyric' # 设置变量content_path为指定的文件夹路径
files=os.listdir(content_path) # 使用os.listdir()函数列出指定文件夹中的所有文件和子文件夹,将结果存储在列表files中
for file in files: # 遍历files列表中的每一个文件或子文件夹full_path=os.path.join(content_path,file) # 使用os.path.join()函数将文件夹路径和文件名拼接成完整的文件路径,存储在变量full_path中print(full_path)if full_path.endswith('.txt'): # 如果文件路径以.txt结尾f=open(full_path,'r',encoding='utf-8') # 使用open()函数以只读模式打开文本文件,指定编码为UTF-8,返回文件对象fcontent+=f.read() # 读取文件对象f的内容,并将其追加到content字符串中else: # 如果文件不是文本文件(不以.txt结尾),则跳过pass
print(content) # 打印合并后的所有文本文件的内容字符串
F:\桌面\python100\files\lyric\qiaoba.jpg
F:\桌面\python100\files\lyric\xiong.jpg
F:\桌面\python100\files\lyric\《林中鸟》.txt
F:\桌面\python100\files\lyric\《逐世行》.txt
F:\桌面\python100\files\lyric\三生三世.txt
···
F:\桌面\python100\files\lyric\灵主不悔.txt
F:\桌面\python100\files\lyric\盗心贼.txt
《林中鸟》
词曲:高进
演唱:葛林
编曲:张亮
混音:侯春阳
来不及祈祷就开始奔跑
总觉得外面世界有多美好
···
盗心的贼
我的一腔热血就化作眼泪
不要再让我悲伤 如痴如醉
再爱一回
将上面的读取指定文件夹中的所有文本文件(.txt)并将它们的内容读取并合并到一个字符串中的操作完整地封装成一个 read_content()函数。
import os
# 读取指定路径下的所有文件,返回所文件接起来的内容
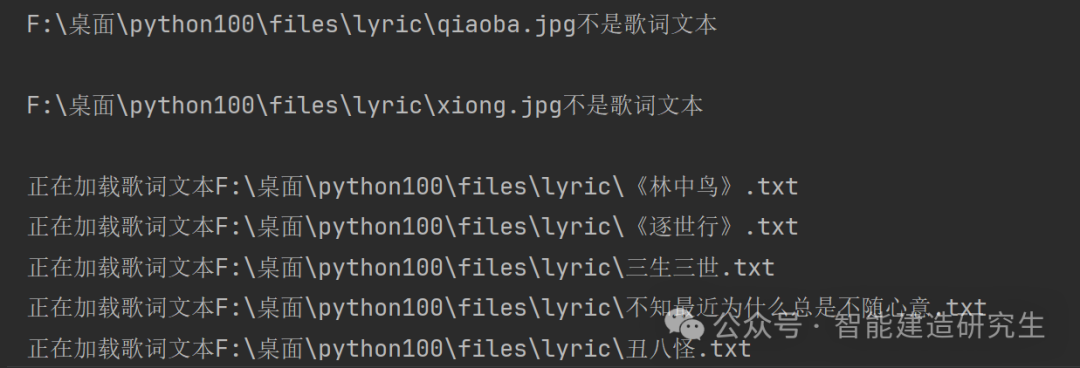
def read_content(content_path):# 初始化内容为空content=''# print(os.listdir(file_path))files=os.listdir(content_path) # 使用os.listdir()函数列出‘content_path’中的所有文件和子文件夹,将结果存储在列表files中for file in files: # 列表中的每一个文件或子文件夹# 拼接完整路径full_path=os.path.join(content_path,file) # 使用os.path.join()函数将文件夹路径和文件名拼接成完整的文件路径,存储在变量full_path中if os.path.isfile(full_path): # 判断full_path是否是一个文件,而非目录if full_path.endswith('.txt'): # 进一步判断文件是否以.txt结尾print('正在加载歌词文本{}'.format(full_path)) # 打印正在加载的文件名content+=open(full_path,'r',encoding='utf8').read() # 读取文件内容并追加到content变量中content += '\n' # 在每个文件内容后添加换行符以便区分不同文件的内容else: # 对于非.txt文件print('{}不是歌词文本\n'.format(full_path)) # 打印文件不是歌词文本的信息print('加载歌词完毕\n')return content # 函数返回最终拼接的内容
content=read_content(r'F:\桌面\python100\files\lyric')
print(content)
在得到所有文本组合成的字符串后,利用TextRank算法提取歌词字符串中的关键词。这是一种基于图的排序算法,用于从文本中提取关键词,根据词与词之间的共现关系来确定每个词的重要性。这种方法适用于自动提取文本关键信息,常用于文本摘要、关键词提取等自然语言处理任务。下面的代码示例使用结巴(jieba)库的 analyse 模块来提取文本中的关键词,并计算它们的重要性。
import jieba.analyse # 专门用于文本关键词提取的模块#使用jieba的textrank提取出1000个关键词及其比重
result=jieba.analyse.textrank(content,topK=1000,withWeight=True) # 使用 textrank 方法从变量 content(应该包含所有文本内容的字符串)中提取前1000个关键词。参数 withWeight=True 表示返回关键词及其相应的权重(重要性)
print(result)
keywords = dict() # 初始化一个空字典 keywords,用于存储关键词及其权重
for i in result: # 每个元素i是一个元组,其中i[0]是关键词i[1]是该关键词的权重keywords[i[0]] = i[1] # 将关键词和其权重添加到字典 keywords 中
# print(i[0])
print(keywords)
运行结果(部分):

结果可视化,生成一个基于文本关键词频率的词云,其中还结合了一个指定的图片形状‘熊大’和图片颜色。

from PIL import Image, ImageSequence # 导入图像处理模块
import numpy as np # np库常用于处理大型多维数组和矩阵
import matplotlib.pyplot as plt # 绘图模块
from wordcloud import WordCloud, ImageColorGenerator # 用于生成词云# 初始化图片
image = Image.open(r'F:\桌面\python100\files\lyric\xiong.jpg')
graph = np.array(image) # 图片转换为数组# 生成云图,指定字体路径,因为WordCloud默认不支持中文,所以需要指定中文字体
# 指定字体路径,因为WordCloud默认不支持中文,所以需要指定中文字体。background_color: 设置词云的背景颜色。max_words: 设置最多显示的词数。mask: 设置词云形状的掩模图像,此处使用之前转换的图片数组。
wc = WordCloud(font_path='C:/Windows/Fonts/STFANGSO.TTF',background_color='white', max_words=100, mask=graph) # 生成词云
wc.generate_from_frequencies(keywords)
# 创建一个颜色生成器,它会基于提供的图片数组来为词云生成颜色
image_color = ImageColorGenerator(graph)
# 显示图片
plt.imshow(wc)
plt.imshow(wc.recolor(color_func=image_color))
plt.axis("off") # 关闭图像坐标系
plt.show()

以上内容总结自网络,如有帮助欢迎转发,我们下次再见!
相关文章:
Python8 使用结巴(jieba)分词并展示词云
Python的结巴(jieba)库是一个中文分词工具,主要用于对中文文本进行分词处理。它可以将输入的中文文本切分成一个个独立的词语,为后续的文本处理、分析、挖掘等任务提供基础支持。结巴库具有以下功能和特点: 中文分词&a…...

python中scrapy
安装环境 pip install scrapy 发现Twisted版本不匹配 卸载pip uninstall Twisted 安装 pip install Twisted22.10.0 新建scrapy项目 scrapy startproject 项目名 注意:项目名称不允许使用数字开头,也不能包含中文 eg: scrapy startproject scrapy_baidu_…...

基础语法总结 —— Python篇
1、环境搭建 建议直接安装 PyCharm (Community Edition) Python3.x版本,前者是一个很好用的编译器,后者是Python的运行环境之类的,安装参考https://mp.csdn.net/mp_blog/creation/editor/139511640 2、标识符 第一个…...
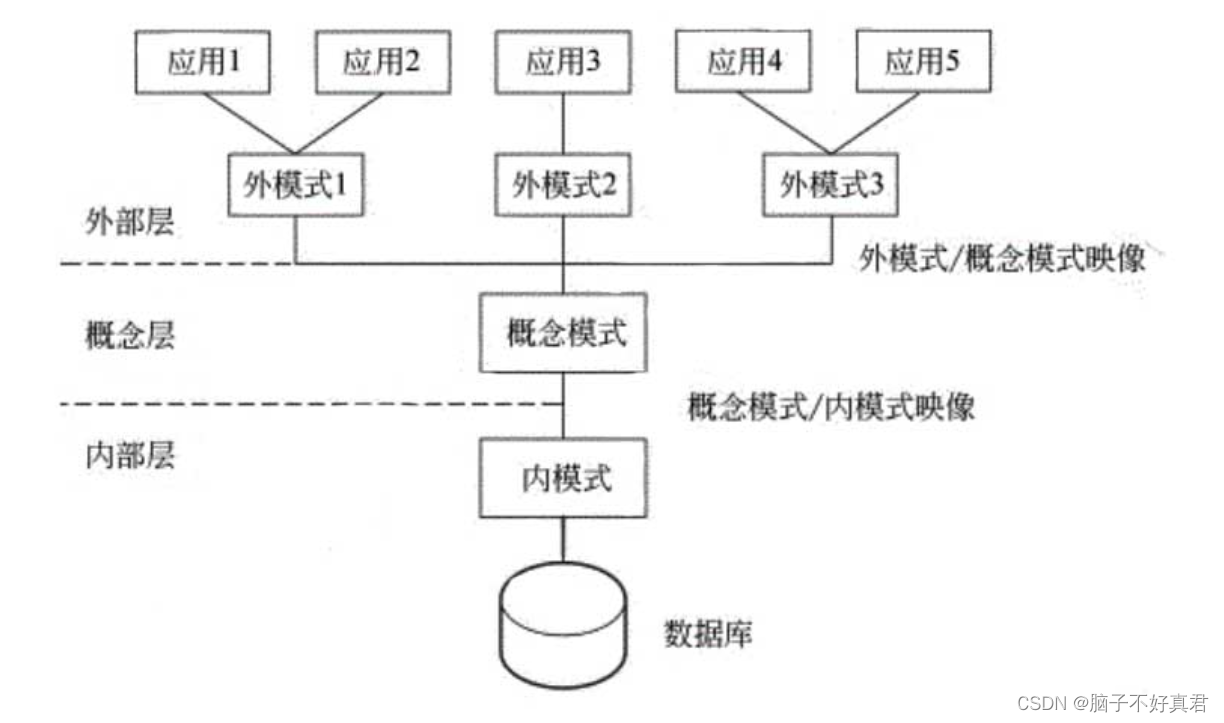
数据库系统概述选择简答概念复习
目录 一、组成数据库的三要素 二、关系数据库特点 三、三级模式、二级映像 四、视图和审计提供的安全性 审计(Auditing) 视图(Views) 五、grant、revoke GRANT REVOKE 六、三种完整性 实体完整性 参照完整性 自定义完整性 七、事务的特性ACDI 原子性(Atomicity)…...

template标签
在HTML中,<template> 标签是一个用于封装可重用内容的非显式元素。它不直接显示在网页上,而是作为一个模板,用来定义一组HTML结构和样式,可以在JavaScript中实例化多次,动态地插入到文档的不同位置。这在创建复杂…...
WPF 程序 分布式 自动更新 登录 打包
服务器server端 core api 客户端WPF // 检查应用更新 //1、获取最新文件列表 // var files fileService.GetUpgradeFiles(); // 2、文件判断,新增的直接下载;更新的直接下载;删除的直接删除 // 客户端本地需要一个记录…...
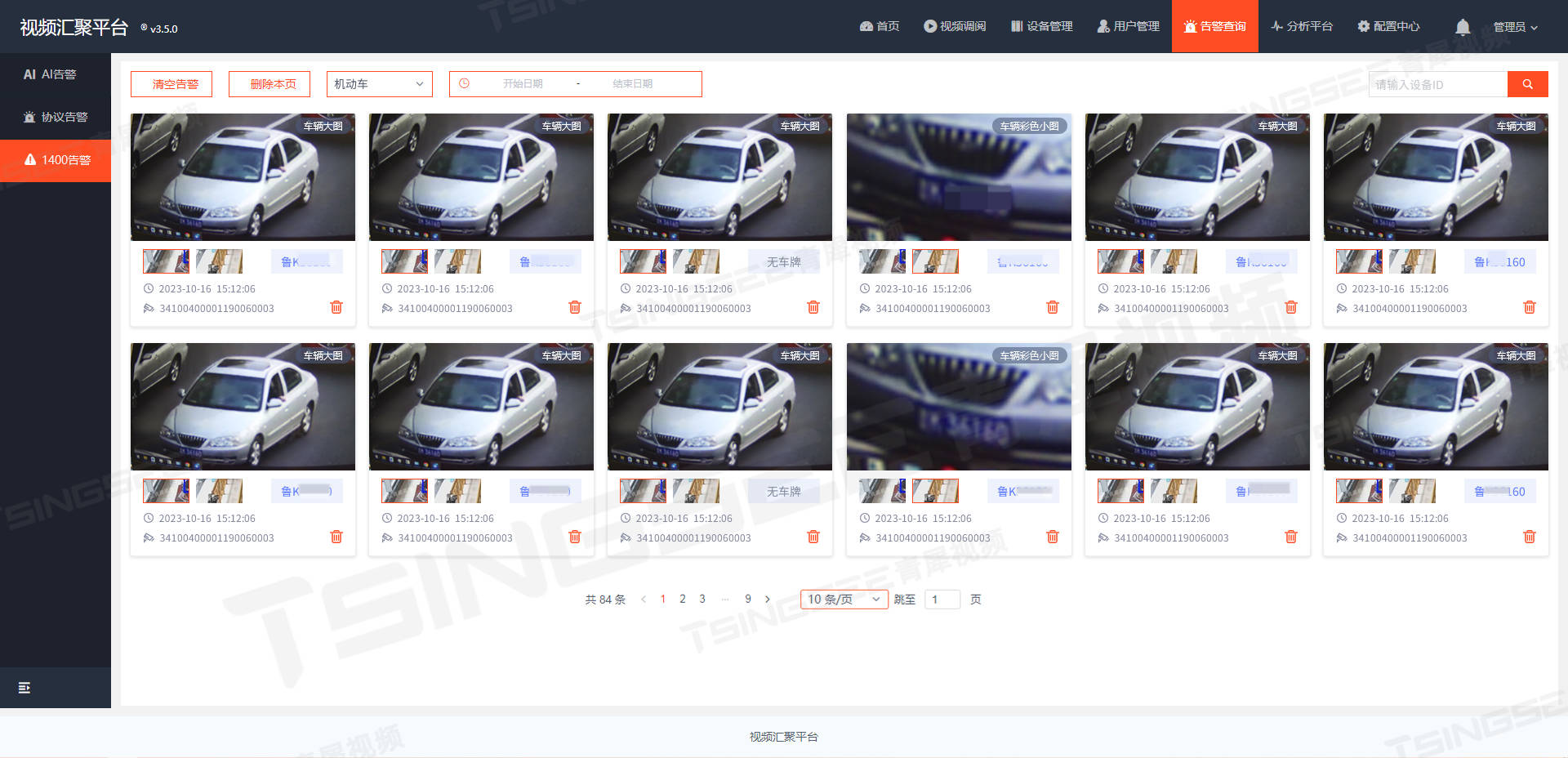
视频汇聚安防综合管理平台EasyCVR支持GA/T 1400视图库标准及设备接入配置
一、概述 视频汇聚安防综合管理平台EasyCVR视频监控系统已经与公安部GA/T 1400视图库标准协议实现了对接,即《公安视频图像信息应用系统》。 安防监控系统EasyCVR支持采用GA/T 1400进行对接,可实现人脸数据使用的标准化、合规化。其采用统一接口对接雪…...

pgsql给单独数据库制定账号权限
登录到PostgreSQL: 使用psql或其他PostgreSQL客户端,以具有足够权限的账号(如postgres或superuser)登录。 2. 创建新账号: sql复制代码 CREATE USER new_user WITH PASSWORD your_secure_password; 注意:将your_secure_passwor…...

【Docker安装】Ubuntu系统下部署Docker环境
【Docker安装】Ubuntu系统下部署Docker环境 前言一、本次实践介绍1.1 本次实践规划1.2 本次实践简介二、检查本地环境2.1 检查操作系统版本2.2 检查内核版本2.3 更新软件源三、卸载Docker四、部署Docker环境4.1 安装Docker4.2 检查Docker版本4.3 配置Docker镜像加速4.4 启动Doc…...

Flink Kafka获取数据写入到MongoDB中 样例
简述 Apache Flink 是一个流处理和批处理的开源框架,它允许从各种数据源(如 Kafka)读取数据,处理数据,然后将数据写入到不同的目标系统(如 MongoDB)。以下是一个简化的流程,描述如何…...

Android Jetpack Compose入门教程(二)
一、列表和动画 列表和动画在应用内随处可见。在本课中,您将学习如何利用 Compose 轻松创建列表并添加有趣的动画效果。 1、创建消息列表 只包含一条消息的聊天略显孤单,因此我们将更改对话,使其包含多条消息。您需要创建一个可显示多条消…...
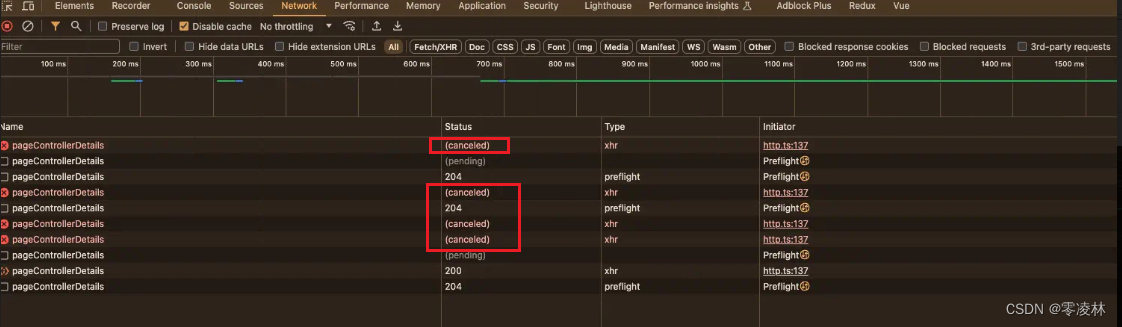
如何避免接口重复请求(axios推荐使用AbortController)
前言: 我们日常开发中,经常会遇到点击一个按钮或者进行搜索时,请求接口的需求。 如果我们不做优化,连续点击按钮或者进行搜索,接口会重复请求。 以axios为例,我们一般以以下几种方法为主: 1…...

算法设计与分析:网络流求解棒球赛淘汰问题C++
目录 一、实验目的 二、问题描述 三、实验要求 四、算法思想 1、明显的:win[i]+remain[i][j]<> 2、不明显的:最大流 3、操作 3.1 先读入相关信息(邻接矩阵**k),进行一遍“明显的”判断。 3.2 对剩下的“不明显的”的每个球队构建流网络(邻接表vector< ve…...

Linux Ubuntu 24.04 C语言gcc编译过程详解
下面是Hello World程序源代码文件hello.c的内容,我们将以它为例来说明源文件到可执行文件的形成过程,主要分4步:预处理、汇编、机器码、链接。 #include <stdio.h> int main () {printf ( "hello, world \n " );return 0; }…...

Python自动化办公篇—pandas操作Excel:读取+查看+选择+清洗+排序+筛选+函数+写入
目录 专栏导读库的介绍库的安装1、读取数据2、查看数据3、选择数据4、数据清洗5、数据排序6、数据筛选7、数据操作8、数据写入总结 专栏导读 文章名称链接Python自动化办公—pyautogui图像定位\点击功能,实现自动截取当前屏幕并检索点击(可制作为游戏点击脚本)点我进行跳转Pyt…...
数据库大作业——音乐平台数据库管理系统
W...Y的主页😊 代码仓库分享💕 《数据库系统》课程设计 :流行音乐管理平台数据库系统(本数据库大作业使用软件sql server、dreamweaver、power designer) 目录 系统需求设计 数据库概念结构设计 实体分析 属性分…...
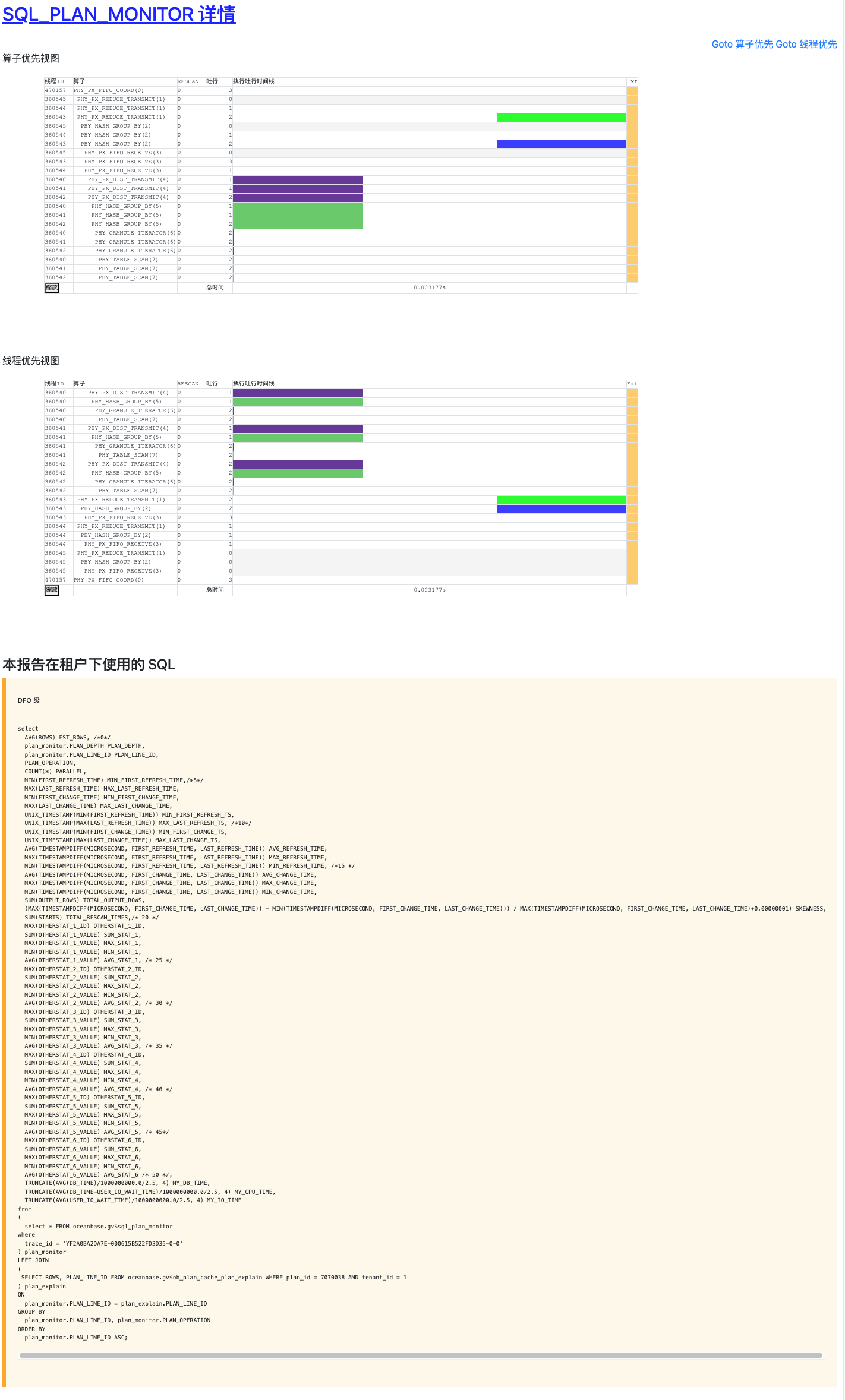
【DBA早下班系列】—— 并行SQL/慢SQL 问题该如何高效收集诊断信息
1. 前言 OceanBase论坛问答区或者提交工单支持的时候大部分时间都浪费在了诊断信息的获取交互上,今天我就其中大家比较头疼的SQL问题,给大家讲解一下如何一键收集并行SQL/慢SQL所需要的诊断信息,减少沟通成本,让大家早下班。 2. …...

用python实现多文件多文本替换功能
用python实现多文件多文本替换功能 今天修改单位项目代码时由于改变了一个数据结构名称,结果有几十个文件都要修改,一个个改实在太麻烦,又没有搜到比较靠谱的工具软件,于是干脆用python手撸了一个小工具,发现python在…...

【DevOps】深入探索Ubuntu操作系统:全面了解
引言 在开源软件的世界里,Ubuntu是一个闪耀的明星。它不仅是一个操作系统,更是一种社区精神、一种共享和协作的文化。Ubuntu操作系统基于强大的Linux内核,由世界各地的开发者共同维护和改进。在这篇博文中,我们将深入探索Ubuntu操…...
【Linux】—MySQL安装
文章目录 前言一、下载官方MySQL包二、下载完成后,通过xftp6上传到Linux服务器上三、解压MySQL安装包四、在安装目录下执行rpm安装,请按顺序依次执行。五、配置MySQL六、启动MySQL数据库七、退出,重新登录数据库 前言 本文主要介绍在Linux环境…...

VMware macOS解锁神器:Unlocker 3.0终极完整指南
VMware macOS解锁神器:Unlocker 3.0终极完整指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在Windows或Linux电脑上体验macOS系统,却苦于VMware默认不支持苹果系统&…...

基于Arduino HID与红外解码的遥控键鼠系统设计与实现
1. 项目概述如果你曾经想过,能不能用一个电视遥控器来控制电脑的鼠标光标,或者快速触发一些键盘快捷键,那么这个项目就是为你准备的。我最近基于Arduino平台,成功搭建了一个红外遥控鼠标和键盘系统,它不仅能让你在沙发…...

基于RAG与LLM的法律合规助手:架构、实现与工程实践
1. 项目概述:一个AI驱动的法律合规助手最近在GitHub上看到一个挺有意思的项目,叫ai-legal-compliance-assistant。光看名字,很多朋友可能觉得这又是一个蹭AI热点的“玩具”,或者是一个简单的规则匹配工具。但当我深入研究了它的架…...

Augustus核心功能深度解析:路障、劳动力池与仓库管理
Augustus核心功能深度解析:路障、劳动力池与仓库管理 【免费下载链接】augustus An open source re-implementation of Caesar III 项目地址: https://gitcode.com/gh_mirrors/au/augustus Augustus是一款开源的Caesar III重制版游戏,它通过精准的…...

GraphQL-WS服务器配置:完整参数详解与最佳实践
GraphQL-WS服务器配置:完整参数详解与最佳实践 【免费下载链接】graphql-ws Coherent, zero-dependency, lazy, simple, GraphQL over WebSocket Protocol compliant server and client. 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-ws GraphQL-WS…...

Blender到Unity模型导出的终极解决方案:免费插件完整指南
Blender到Unity模型导出的终极解决方案:免费插件完整指南 【免费下载链接】blender-to-unity-fbx-exporter FBX exporter addon for Blender compatible with Unitys coordinate and scaling system. 项目地址: https://gitcode.com/gh_mirrors/bl/blender-to-uni…...

基于AI宏观流动性监测框架的黄金三日连跌研究:美联储加息预期按兵不动后的市场重定价逻辑
摘要:本文通过AI宏观利率模型、美元流动性监测系统与黄金波动率因子分析,结合美通胀数据、美债收益率变化及市场利率预期重定价过程,分析黄金连续三日回落背后的核心驱动逻辑,并探讨当前“高利率持续”环境下黄金资产的阶段性压力…...

Android Recovery 模式工作原理与定制实战
Recovery 是 Android 的"救命系统",负责 OTA 升级、恢复出厂、用户数据加密管理。本文剖析 Recovery 的架构、启动流程、与主系统的通信机制,并演示如何修改并构建一个自定义 Recovery。一、Recovery 到底是什么? 很多人以为 Recovery 是 Android 系统的一个"模…...

控制理论实践:从PID到MPC的Python实现与仿真调试
1. 项目概述:从“Gonzo”看控制理论在开源项目中的实践最近在GitHub上看到一个挺有意思的项目,名字叫“control-theory/gonzo”。光看这个标题,你可能会有点摸不着头脑——“控制理论”和“Gonzo”有什么关系?Gonzo这个词…...

从C代码到汇编:图解函数调用栈中rsp和rbp的“职责分工”
从C代码到汇编:图解函数调用栈中rsp和rbp的"职责分工" 在计算机程序的执行过程中,函数调用是最基础也最核心的概念之一。当我们从高级语言如C/C深入到汇编层面时,会发现函数调用的背后隐藏着一套精密的栈帧管理机制。本文将带您走进…...