生成对抗网络——GAN深度卷积实现(代码+理解)
本篇博客为 上篇博客的 另一个实现版本,训练流程相同,所以只实现代码,感兴趣可以跳转看一下。
生成对抗网络—GAN(代码+理解)
http://t.csdnimg.cn/HDfLO
http://t.csdnimg.cn/HDfLO
目录
一、GAN深度卷积实现
1. 模型结构
(1)生成器(Generator)
(2)判别器(Discriminator)
2. 代码实现
3. 运行结果展示
二、学习中产生的疑问,及文心一言回答
1. 模型初始化
2. 模型训练时
3. 优化器定义
4. 训练数据
5. 模型结构
(1)生成器
(2)判别器
一、GAN深度卷积实现
1. 模型结构
(1)生成器(Generator)

(2)判别器(Discriminator)

2. 代码实现
import torch
import torch.nn as nn
import argparse
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import datasets
import numpy as npparser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=20, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)# 加载数据
dataloader = torch.utils.data.DataLoader(datasets.MNIST("./others/",train=False,download=False,transform=transforms.Compose([transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),),batch_size=opt.batch_size,shuffle=True,
)def weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm2d") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02) # 给定均值和标准差的正态分布N(mean,std)中生成值torch.nn.init.constant_(m.bias.data, 0.0)class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.init_size = opt.img_size // 4 # 原为28*28,现为32*32,两边各多了2self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128), # 调整数据的分布,使其 更适合于 下一层的 激活函数或学习nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, z):out = self.l1(z)out = out.view(out.shape[0], 128, self.init_size, self.init_size)img = self.conv_blocks(out)return imgclass Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),nn.LeakyReLU(0.2, inplace=True),nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.model = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# 下采样(图片进行 4次卷积操作,变为ds_size * ds_size尺寸大小)ds_size = opt.img_size // 2 ** 4self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1),nn.Sigmoid())def forward(self, img):out = self.model(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)return validity# 实例化
generator = Generator()
discriminator = Discriminator()# 初始化参数
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))# 交叉熵损失函数
adversarial_loss = torch.nn.BCELoss()def gen_img_plot(model, epoch, text_input):prediction = np.squeeze(model(text_input).detach().cpu().numpy()[:16])plt.figure(figsize=(4, 4))for i in range(16):plt.subplot(4, 4, i + 1)plt.imshow((prediction[i] + 1) / 2)plt.axis('off')plt.show()# ----------
# Training
# ----------
D_loss_ = [] # 记录训练过程中判别器的损失
G_loss_ = [] # 记录训练过程中生成器的损失
for epoch in range(opt.n_epochs):# 初始化损失值D_epoch_loss = 0G_epoch_loss = 0count = len(dataloader) # 返回批次数for i, (imgs, _) in enumerate(dataloader):valid = torch.ones(imgs.shape[0], 1)fake = torch.zeros(imgs.shape[0], 1)# -----------------# Train Generator# -----------------optimizer_G.zero_grad()z = torch.randn(imgs.shape[0], opt.latent_dim)gen_imgs = generator(z)g_loss = adversarial_loss(discriminator(gen_imgs), valid)g_loss.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()real_loss = adversarial_loss(discriminator(imgs), valid)fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)d_loss = (real_loss + fake_loss) / 2d_loss.backward()optimizer_D.step()print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item()))# batches_done = epoch * len(dataloader) + i# if batches_done % opt.sample_interval == 0:# save_image(gen_imgs.data[:25], "others/images/%d.png" % batches_done, nrow=5, normalize=True)# 累计每一个批次的losswith torch.no_grad():D_epoch_loss += d_lossG_epoch_loss += g_loss# 求平均损失with torch.no_grad():D_epoch_loss /= countG_epoch_loss /= countD_loss_.append(D_epoch_loss.item())G_loss_.append(G_epoch_loss.item())text_input = torch.randn(opt.batch_size, opt.latent_dim)gen_img_plot(generator, epoch, text_input)x = [epoch + 1 for epoch in range(opt.n_epochs)]
plt.figure()
plt.plot(x, G_loss_, 'r')
plt.plot(x, D_loss_, 'b')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['G_loss','D_loss'])
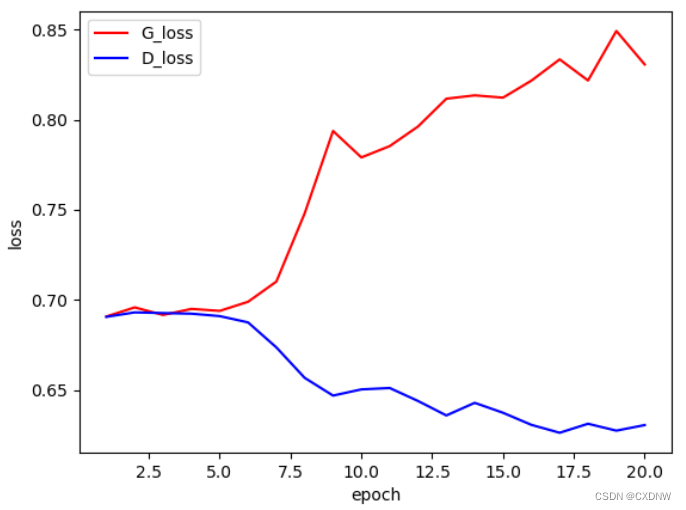
plt.show()3. 运行结果展示


二、学习中产生的疑问,及文心一言回答
1. 模型初始化
函数 weights_init_normal 用于初始化 模型参数,为什么要 以 均值和标准差 的正态分布中采样的数 为标准?

2. 模型训练时
这里“d_loss = (real_loss + fake_loss) / 2” 中的 “/ 2” 操作,在 实际训练中 有什么作用?

由(real_loss + fake_loss) / 2的 得到 的 d_loss 与(real_loss+fake_loss)得到的 d_loss 进行 回溯,两者结果会 有什么不同吗?

3. 优化器定义
设置 betas=(opt.b1, opt.b2) 有什么 实际的作用?通俗易懂的讲一下

betas=(opt.b1, opt.b2) 是怎样 更新学习率的?

4. 训练数据
这里我们用的data为 MNIST,为什么img_size设置为 32,不是 28?

5. 模型结构
(1)生成器
解释一下为什么是“Upsample, Conv2d, BatchNorm2d, LeakyReLU ”这种顺序?


(2)判别器
模型的 基本 运算步骤是什么?其中为什么需要 “Dropout2d( p=0.25, inplace=False)”这一步?

关于“ds_size” 和 “128 * ds_size ** 2”的实际意义?

后续更新 GAN的其他模型结构。
相关文章:

生成对抗网络——GAN深度卷积实现(代码+理解)
本篇博客为 上篇博客的 另一个实现版本,训练流程相同,所以只实现代码,感兴趣可以跳转看一下。 生成对抗网络—GAN(代码理解) http://t.csdnimg.cn/HDfLOhttp://t.csdnimg.cn/HDfLO 目录 一、GAN深度卷积实现 1. 模型…...
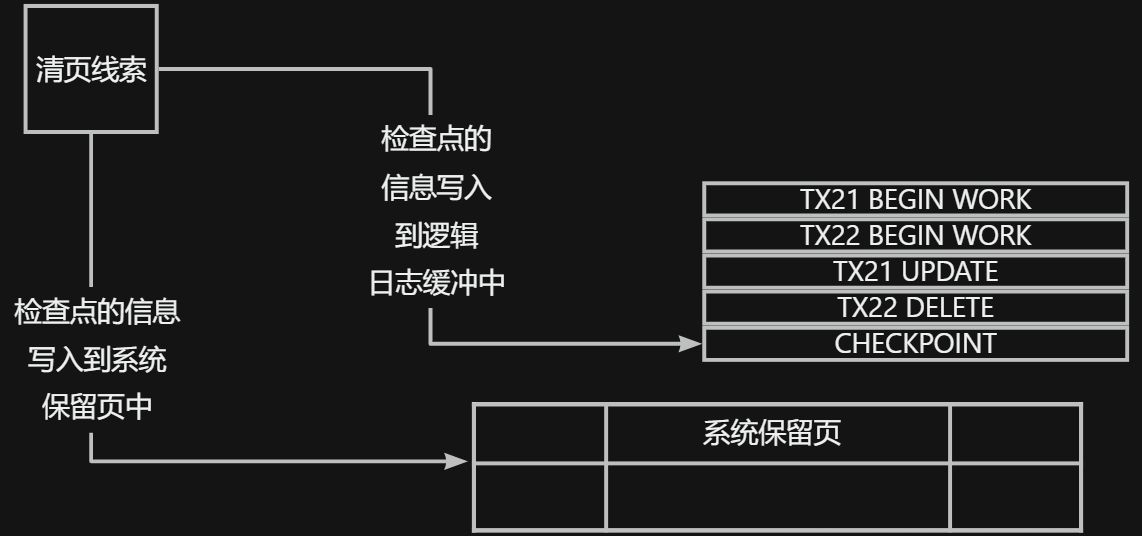
gbase8s数据库阻塞检查点和非阻塞检查点的执行机制
1. 检查点的描述 为了便于数据库系统的复原和逻辑恢复,数据库服务器生成的一致性标志点,称为检查点,其是建立在数据库系统的已知和一致状态时日志中的某个时间点检查点的目的在于定期将逻辑日志中的重新启动点向前移动 如果存在检查点&#…...

ARM32开发--串口库封装(初级)
知不足而奋进望远山而前行 目录 文章目录 前言 目标 内容 开发流程 文件目录创建 分组创建 接口定义 完整代码 总结 前言 在嵌入式软件开发中,封装抽取流程和抽取封装策略是非常重要的技术,能够提高代码的复用性和可维护性。本文将介绍如何在文…...

统一管理:Vue公共组件/公共样式/全局自定义指令
main.js 引入存放公共文件的文件路径 import "./plugins";src/plugins文件夹下的index.js 在处理公共文件中分别引入 /* 公共引入,勿随意修改,修改时需经过确认 */ import Vue from "vue";import "/icons"; // 图标 import ByuiQueryForm fr…...
Linux之旅: 基础知识点的终极指南
文章目录 1、Linux的目录结构2、ls命令3、管理文件和目录4、linux命令使用细节和技巧5、权限管理基本命令6、搜索命令7、管道符与重定向8、压缩和解压命令9、用户及vim编辑器10、用户和用户组管理一、Linux系统用户账号的基本管理二、Linux系统用户组的管理 1、Linux的目录结构…...

C#部分方法有什么用处?和传统方法有什么区别?什么时候用合适?
在C#中,部分类(partial class)和部分方法(partial method)是两个不同的概念,但它们经常一起使用,特别是在代码生成和框架设计中。下面我将分别解释这两个概念,并讨论它们的用处、与传…...

elasticsearch hanlp插件远程词典配置
elasticsearch hanlp插件远程词典配置 背景远程词典配置新增远程词典文件修改hanlp-remote.xml自动加载词典 远程词典测试 背景 在使用elasticsearch的过程中,总会遇到与分词相关的需求,这里将针对常用的elasticsearch hanlp(后面统称为 es …...

力扣每日一题 6/18 字符串/模拟
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 2288.价格减免 【中等】 题目: 句子 是由若干个单词组成的字符…...

架构设计 - Nginx Proxy Cache 缓存配置
摘要: web 应用业务缓存通常3级: 一级缓存:JVM 本地缓存 二级缓存:Redis集中式缓存 三级缓存:Nginx Proxy Cache 缓存 或 Nginx Lua 缓存 四级缓存:静态资源CDN缓存 本文主要分享 Nginx Proxy Cache 缓…...

【前端】HTML5基础
目录 0 参考1 网页1.1 什么是网页1.2 什么是HTML1.3 网页的形成 2 浏览器2.1 常用的浏览器2.2 浏览器内核 3 Web标准3.1 为什么需要Web标准3.2 Web标准的构成 4 HTML 标签4.1 HTML语法规范4.1.1 基本语法概述4.1.2 标签关系4.1.2.1 包含关系4.1.2.2 并列关系 4.2 HTML基本结构标…...

9个最佳性能测试工具(2024)
1、前言 性能测试检查软件程序在预期工作负载下的速度、响应时间、可靠性、资源使用情况和可扩展性。性能测试的目的不是发现功能缺陷,而是消除软件或设备中的性能瓶颈。 性能测试为利益相关者提供有关其应用程序的速度、稳定性和可扩展性的信息。更重要的是&…...
RTthread+STM32F407ZGTx+烟雾报警检测+蜂鸣器报警+LED闪烁||使用RTthread Studio
目录 实验背景 1.安装环境 2.配置环境 3.先编译下载实例程序2,观察DS0是否闪烁 4.实验方法 5.实例代码 6.硬件连接 7.实验效果 8.关于这次开发遇到的问题 1.反应慢,都熄灭1分钟多了,才报的问题? 2.关于rt_pin_mode(KEY…...
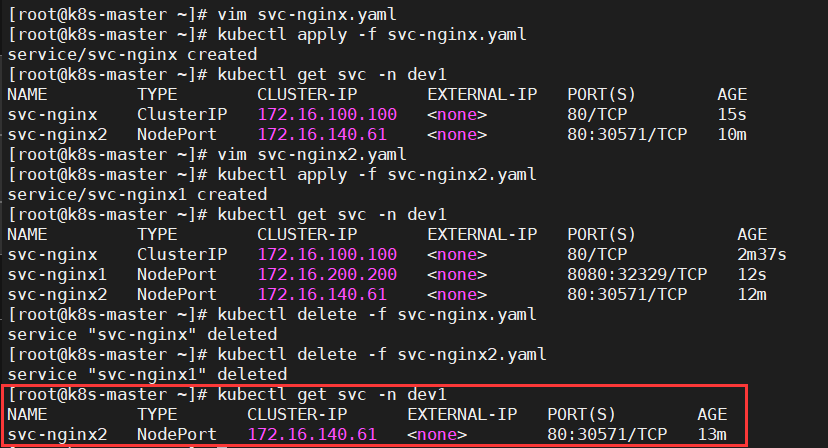
k8s资源的基本操作
文章目录 一、Namespace1、概述2、预定义的k8s命名空间2.1、default2.2、kube-public2.3、kube-system2.4、kube-node-lease 3、命名空间基本操作3.1、查看3.1.1、查看所有的命名空间3.1.2、查看指定的命名空间3.1.3、指定输出格式3.1.4、查看ns详情 3.2、创建3.2.1、命令行创建…...
19.面包屑导航制作
面包屑导航制作 官网:组件 | Element 1. 在layout下新建BreadCrumb.vue BreadCrumb.vue <template><div class"bread-text"><el-breadcrumb class"bred"separator"/"><el-breadcrumb-item v-for"item in…...
做动画?Animatediff 和 ComfyUI 更配哦!
如果从工作流和内存利用率的角度来说,Animatediff 和 ComfyUI 可能更配一些,毕竟制作动画是一个很吃内存的操作。 首先,我们需要在管理器中下载 Animatediff 插件,当然也可以直接导入听雨的工作流,然后在管理器的安装…...

笔记-python里面的xlrd模块详解
那我就一下面积个问题对xlrd模块进行学习一下: 1.什么是xlrd模块? 2.为什么使用xlrd模块? 3.怎样使用xlrd模块? 1.什么是xlrd模块? ♦python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel&…...

oracle将字符串中的字符和数字拆分开等功能
将字符串中的字符和数字拆分开 create or replace procedure F_GetNumber1( inString IN VARCHAR2,n_return1 out varchar2, n_return2 out varchar2) ISDCHAR VARCHAR2(1024); OUTCHAR VARCHAR2(1024); j number default 0; ulen number; BEGINOUTCHAR:;DCHAR:TRIM(inStr…...
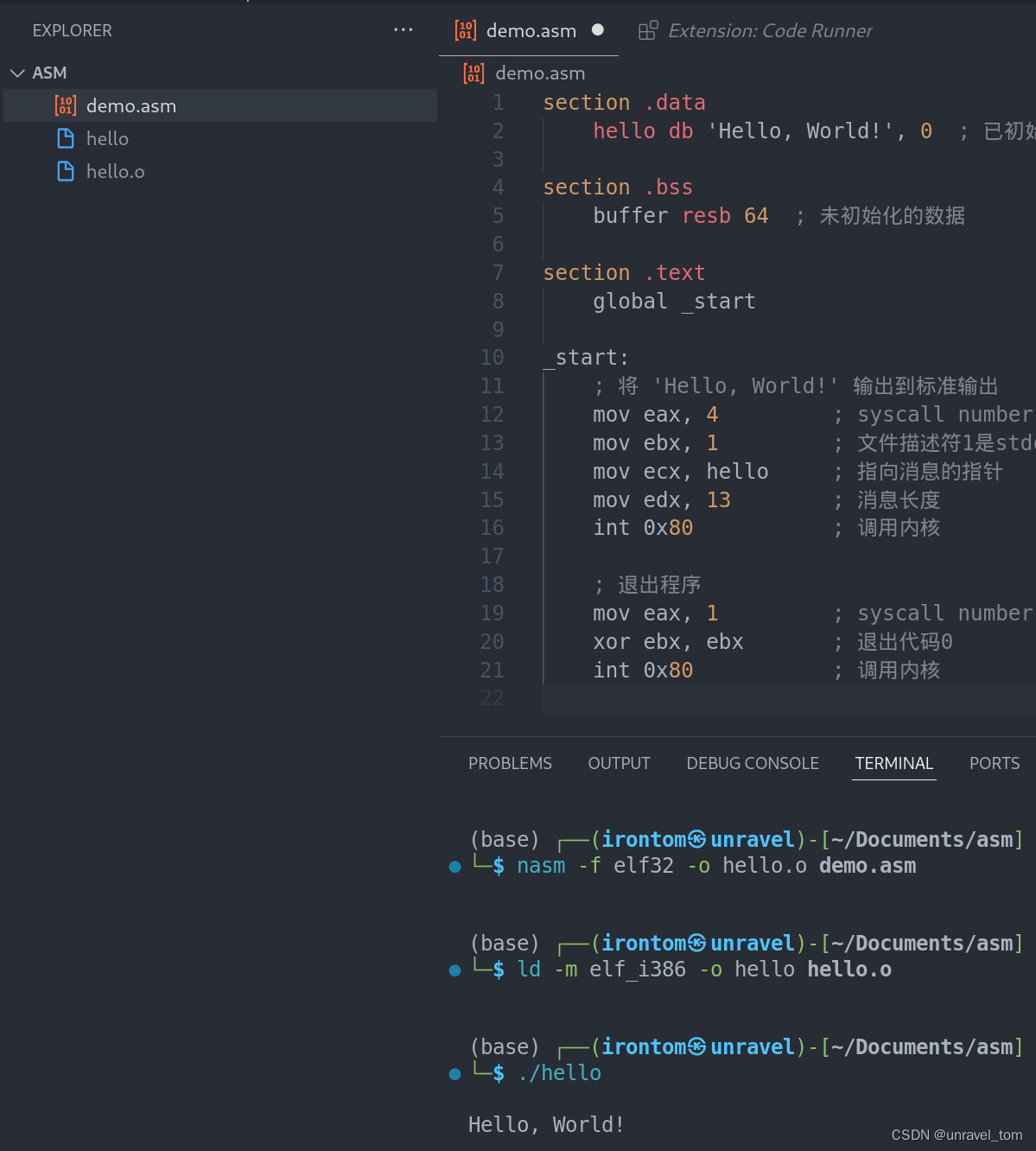
汇编基础之使用vscode写hello world
汇编语言(Assembly Language) 概述 汇编语言(Assembly Language)是一种低级编程语言,它直接对应于计算机的机器代码(machine code),但使用了更易读的文本符号。每台个人计算机都有…...

APS计划排程系统如何打破装备使用约束
APS计划排程系统是离散制造型企业在计划控制方向的重要支撑,它提供的是交期预测、订单排产计划、物料采购计划、人力分配计划等等。近些几年来,多品种、小批量、多订单的生产模式,让企业的计划员应接不暇、疲累不堪,传统的人工经验…...

gigachad - suid
gigachadeasyftp利用、google反图搜索、 suid提权、s-nail 提权 主机发现 ┌──(kali㉿kali)-[~/桌面/OSCP] └─$ sudo netdiscover -i eth0 -r 192.168.44.138/24服务探测 ┌──(kali㉿kali)-[~/桌面/OSCP] └─$ sudo nmap -sV -A -T 4 -p- 192.168.44.138 |_/kingchad…...

开源、有文档、能上线的 .NET + Vue 通用权限系统
前言在日常项目开发中,权限管理几乎是每个系统都绕不开的基础模块。从用户登录、菜单控制到数据隔离,一套稳定、灵活、可扩展的权限体系,往往决定了整个项目的成败。然而,从零开始搭建这样的平台,不仅耗时耗力…...

构建AI涌现式判断系统:从智能体工作流到技术评审实践
1. 项目概述:当AI学会“判断”而非“计算”最近在GitHub上看到一个名为“emergent-judgment”的项目,由thebrierfox发起。初看标题,你可能会觉得这又是一个关于AI伦理或决策系统的抽象讨论。但深入探究后,我发现它指向了一个更具体…...

基于Docker Compose的容器化数据抓取平台OpenClaw部署与实战
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一些数据采集和自动化处理的工作流,发现一个挺有意思的项目:alexleach/openclaw-compose。光看名字,openclaw直译是“开放之爪”,compose则明确指向了 Doc…...

深圳市2026年打造人工智能先锋城市项目扶持计划申请指南
本项目扶持计划下设十个项目类别,均采用事后奖补类支持方式。1、申报单位需同时满足基础申报条件和专项申报条件。基础申报条件如下:(一)申报单位为在深圳市内(含深汕特别合作区)从事生产经营活动ÿ…...

Apple Silicon Mac原生Linux游戏体验:Asahi Linux驱动突破与实战指南
1. 项目概述:当Apple Silicon Mac遇见原生Linux游戏如果你和我一样,既是Mac用户,又对在Linux系统上折腾抱有热情,那么最近Asahi Linux项目的进展绝对会让你心跳加速。长久以来,在搭载Apple Silicon(M1、M2、…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

STM32驱动安信可Rd-04毫米波雷达:硬件改造、I2C驱动移植与参数调优全攻略
1. 项目概述:从零开始驱动安信可Rd-04雷达模组最近在做一个智能感应的小项目,需要用到人体存在检测,对比了几种方案后,最终选择了安信可的Rd-04毫米波雷达模组。这玩意儿体积小、功耗低,最关键的是价格相当亲民&#x…...

对比直接使用官方API体验Taotoken在稳定性与成本上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在稳定性与成本上的差异 在将大模型能力集成到个人项目或小团队工作流中时,开发者通常…...
管理)
表空间(Tablespace)管理
1.1、表空间类型类型用途说明永久表空间存储用户数据SYSTEM, SYSAUX, USERS, 自定义UNDO表空间事务回滚和读一致性自动管理,12c支持多UNDO临时表空间排序、哈希等临时操作TEMP,不产生redo大文件表空间单个数据文件可达128TBBigfile Tablespace加密表空间…...

从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍
从Excel到Python:用Pandas的fillna优雅处理缺失值,数据分析效率翻倍 当你在Excel中处理上千行数据时,是否曾被那些零散的#N/A或空白单元格折磨得焦头烂额?CtrlF查找替换、IFERROR函数嵌套、手动拖拽填充柄...这些操作在小型数据集…...